CNGC2基因和其编码的氨基酸序列在培育植物新品种中的应用的制作方法
本发明属于植物生物技术领域,具体涉及CNGC2基因和其编码的氨基酸序列在培育植物新品种中的应用。
背景技术:
Ca是植物生长发育的必需矿质元素。2011年我国生态学家方精云院士领导的科研小组测定了1227种中国植物叶子中11种营养元素的含量,发现Ca的含量为9g/kg,仅次于氮(20g/kg)和钾(10g/kg),是植物体内第三大矿质元素。对美国不同森林土壤中Ca含量进行长达26,54和74年的测定,发现土壤Ca含量下降50%到78%。土壤中植物可以利用的Ca的流失主要是两个因素造成的:一是酸雨在世界范围内的大量发生,导致大量非游离态Ca溶解在水中成为游离态Ca而流失;二是植物通过根吸收土壤中的Ca,其中的大部分构成了植物细胞壁,被固定在木材及树皮当中,收获农作物、砍伐森林使土壤中的Ca不能被循环利用,从而导致环境中Ca的缺失。植物是吸收土壤Ca的主体。植物Ca营养的两个根本问题是根对Ca营养的吸收和Ca在叶片中的分布。
从全球大趋势而言,酸雨影响使土壤中可利用Ca2+量越来越少,这就使植物吸收Ca2+能力问题成为了热点话题,但是,目前关于影响植物Ca2+分布基因的研究程度还较低,达不到产业应用的水平。
技术实现要素:
为了解决现有技术存在的上述问题,本发明提供了CNGC2基因和其编码的氨基酸序列在培育植物新品种中的应用。经本申请的发明人研究发现,所述CNGC2基因能够影响植物Ca2+分布,促进植物对Ca2+的吸收,从而应用于培育植物新品种中。
本发明所采用的技术方案为:一种影响植物Ca2+分布的基因,定名为CNGC2基因。所述CNGC2基因的序列如SEQ ID NO:1所示。
与所述CNGC2基因序列对应的,其编码的氨基酸序列如SEQ ID NO:2所示。
本申请的发明人,通过植物生理、细胞和遗传学方法,确定一个编码环核苷酸门控的阳离子通道基因,即CNGC2基因,是调节植物植物叶细胞钙营养的核心基因。所述CNGC2基因在叶子小叶脉末端周边的叶肉细胞内表达,这个位置是木质部中的钙离子释放到叶肉细胞外间隙的位点。缺失所述CNGC2基因的拟南芥突变体在低钙水培条件下可以正常生长,但是在相对高钙环境下,叶子的生长受到显著抑制,同时叶子出现早衰、局部叶肉细胞死亡和光合暗反应受抑制的表型。利用钙离子特异性膜不通透性荧光染料,结合荧光显微镜,本申请的发明人发现,在缺失CNGC2基因的植物叶子内,因为叶肉细胞对钙离子的吸收被阻断,大量钙离子在细胞外积累,说明CNGC2基因编码的蛋白是调节钙离子在植物叶子内正确分布必需的重要因子。
基于以上原理,本发明还公开了所述CNGC2基因和其编码的氨基酸序列在培育植物新品种中的应用。
本发明的有益效果为:本发明提供了CNGC2基因和其编码的氨基酸序列在培育植物新品种中的应用,所述CNGC2基因能够影响植物Ca2+分布,促进植物对Ca2+的吸收,从而应用于培育植物新品种中。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
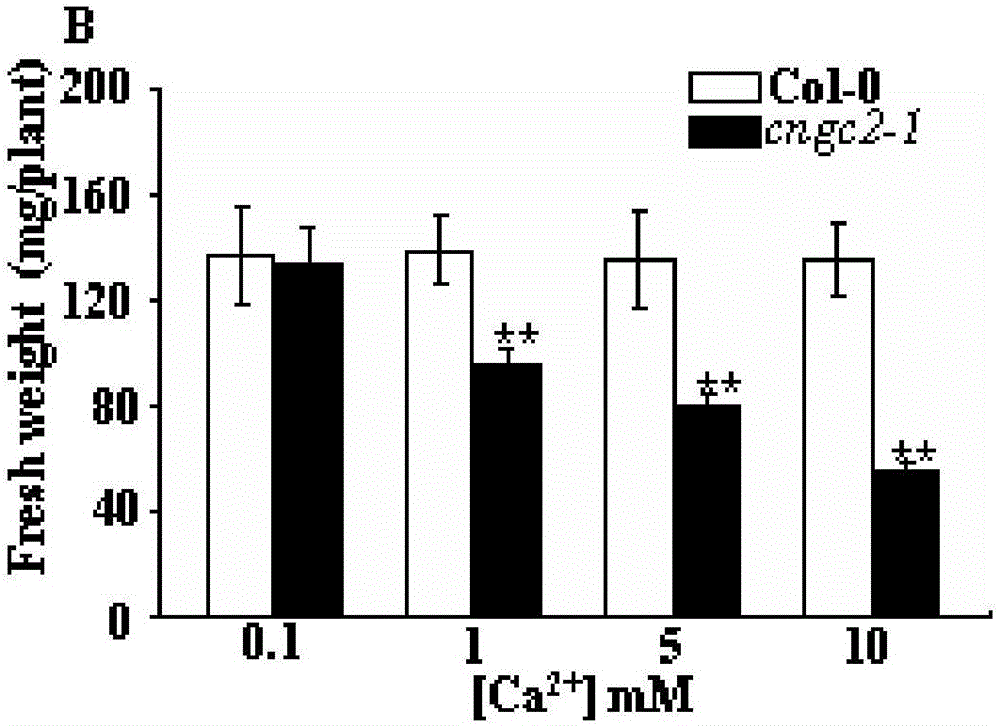
图1是正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培溶液中培养3个星期,然后水培溶液更换为0.1,1,5或10mM Ca2+,继续培养8天后,植物地上部分鲜重的统计分析图;
图2是正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培溶液中培养3个星期,然后水培溶液更换为0.1,1或10mM Ca2+,继续培养8天后,叶中的Ca含量的统计分析图;
图3是正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培溶液中培养3个星期,然后水培溶液更换为0.1,1或10mM Ca2+,继续培养8天后,根中的Ca含量的统计分析图;
图4是正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培溶液中培养3个星期,然后水培溶液更换为0.1或10mM Ca2+,继续培养3天,植物叶子的叶柄插入含有膜不通透性、低亲和性钙离子荧光染料,Oregon Green BAPTA 488 5N(OGB)荧光染料的溶液中,在不同时间点,在蓝色激光条件下,利用荧光显微镜观察依赖钙离子的绿色激发光的分布统计分析图;
图5是正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培溶液中培养3个星期,然后水培溶液更换为0.1或10mM Ca2+,继续培养3天,快速收集各处理条件下成熟叶子进行液氮速冻,经过真空冷冻干燥以后,利用偶联X能谱仪场发射扫描电子显微镜(Hitachi S-4800)测定叶片中表皮毛中的相对Ca含量的统计分析图;
图6是正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培溶液中培养3个星期,然后水培溶液更换为0.1或10mM Ca2+,继续培养3天,快速收集各处理条件下成熟叶子进行液氮速冻,经过真空冷冻干燥以后,利用偶联X能谱仪场发射扫描电子显微镜(Hitachi S-4800)测定叶片中各类细胞中的相对Ca含量的统计分析图;
图中,**表示显著性差异,p<0.01。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范 围。
在本发明中,若非特指,所有的份、百分比均为重量单位,所有的设备和原料等均可从市场购得或是本行业常用的。下述实施例中的方法,如无特别说明,均为本领域的常规方法。
实施例1
本实施例为CNGC2基因和其编码的氨基酸序列对植物Ca2+分布的影响的验证。
1.实验材料与方法
1.1实验材料
本实施例所用的材料为拟南芥野生型材料和cngc2-1拟南芥突变体,其中cngc2-1拟南芥突变体为不含有CNGC2基因的拟南芥植株,大肠杆菌菌株DH5α和根癌农杆菌菌株GV3101均由市场购得;Primer Star HS DNA Polymerase购自TaKaRa;EasyTaq PCR Supermix DNA聚合酶和T4DNA连接酶购自全式金公司;实验所用MQA药品及浓度为:5mM KNO3;1mM H3PO4;1mM MgSO4;0.1或10mM CaCl2;1/2MS微量元素;1/2MS Fe盐;5mM MES;BTP调pH至5.7。
1.2实验方法
1.2.1种子消毒与植株培养
分装适量干燥好的拟南芥种子放于2ml离心管中,向管中加入1.8ml 75%乙醇并放置摇床上摇晃消毒20分钟,然后在超净工作台中弃掉离心管中75%乙醇,倒入100%乙醇摇晃,将种子和乙醇倒在无菌滤纸上晾干,晾干后,用酒精灯火焰烧过的无菌镊子点播在MQA固体培养基上,用医用胶带封皿放于4℃冰箱避光处理3天,最后将培养皿放在培养室培养,光周期为12小时光照/12小时黑暗,光强为75-100μmol m-2 s-1,培养温度为22-25℃。
1.2.2拟南芥的水培培养
水培体系使用4×8的32孔4ml离心管盒为主要支持物。将同管架大小一 致并预先打孔的黑胶纸贴在离心管盒的管架上,孔大小随苗大小而定,确保幼苗地上部分不可通过即可(一般是0.6mm×0.6mm圆形孔),盒里加入水培溶液650ml,将培养皿上生长10天的幼苗的根全部放入孔内的溶液中,幼苗地上部分架于溶液上,幼苗全部放好后盖上离心管盒盖,用于保湿。待植株再生长15-25天即可用于实验。
1.2.6荧光染料观察细胞外钙的实验方法
(1)用双面刀片从叶柄基部剪取生长在MQA 0.1mM Ca2+水培溶液中的Col-0和cngc2-1拟南芥突变体叶片,将Col-0和cngc2-1叶柄分别插入到含有20μM Oregon Green 488BAPTA-5N(OGB)荧光染料的MQA 0.1mM Ca2+和MQA 10mM Ca2+溶液中,置于避光盒子内;
(2)在不同时间点将叶片用镊子轻轻取出,放置在30%甘油铺平的载玻片上,轻轻盖上盖玻片,用倒置荧光显微镜观察,Oregon Green 488BAPTA-5N激发光为494nm。采用波长收集范围是460-480nm,发射光收集范围是500-560nm的滤光片进行拍照。
2.实验验证:
2.1缺失CNGC2基因的cngc2-1拟南芥突变体具有高钙离子敏感表型
将种子播种在0.1mM Ca2+浓度下的培养皿中,生长21天后,移到0.1mM Ca2+水培溶液中生长21天,第22天更换0.1,1,5或10mM Ca2+溶液生长8天后采集数据,结果发现缺失CNGC2基因的cngc2-1拟南芥突变体在1mM Ca2+浓度下生长矮小,叶片边缘黄化;生长在5,10mM Ca2+条件下的cngc2-1拟南芥突变体黄化及矮小现象更严重。对地上部分鲜重进行称量,并对同一个浓度下的Col-0和cngc2-1拟南芥突变体进行统计学分析,结果如图1所示,在0.1mM Ca2+浓度下,Col-0和cngc2-1拟南芥突变体鲜重相似,统计学分析没有差异;在1,5,10mM Ca2+浓度下的水培体系下生长,cngc2-1拟南芥突变体植株鲜重明显小于Col-0,统计学分析两者具有显著差异(p<0.01)。说明缺失CNGC2基因的cngc2-1拟南芥突变体具有高钙离子敏感表型,所述CNGC2基 因能够影响植物Ca2+分布,促进植物对Ca2+的吸收,从而应用于培育植物新品种中。
2.2缺失CNGC2基因的cngc2-1拟南芥突变体叶Ca含量显著降低
将正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培条件下培养3个星期,然后分别给予植物0.1,1和10mM Ca2+处理,3天以后,利用原子吸收光谱分别测定叶和根的Ca含量,结果如图2和图3所示,图2表示,0.1mM和1mM Ca2+浓度下Col-0和cngc2-1拟南芥突变体叶Ca含量没有显著区别,但是在10mM Ca2+浓度下,cngc2-1拟南芥突变体叶的Ca含量显著低于Col-0;图3表示,正常植物Col-0和cngc2-1拟南芥突变体根的Ca含量在三种不同Ca浓度培养条件下都没有区别。这说明,CNGC2基因主要负责植物叶Ca的积累。
2.3高Ca2+条件下,Ca2+在cngc2-1拟南芥突变体细胞外过量积累
植物根吸收的营养元素通过维管系统向上运输到叶片中,而后将营养物质卸载到质外体空间被叶片不同细胞吸收。Ca2+从细胞外空间到叶肉细胞转运的过程,叶肉细胞对Ca2+吸收能力的减弱将会导致更多的Ca2+积累在细胞外空间。在增加Ca2+浓度下cngc2-1拟南芥突变体叶片早衰,可能原因是,叶肉细胞不能吸收Ca2+从而导致叶肉细胞Ca2+含量低而更多Ca2+积累在细胞外空间。为了验证这个假说,本申请的发明人通过与Ca2+结合的荧光染料OGB观察细胞外空间Ca2+的分布,将离体叶片放入能够染细胞外Ca2+且不能跨细胞质膜的Ca2+特异性染料Oregon Green BAPTA 488 5N中,激发光波长/发射光波长=488nm/521nm,结果如图4所示,10mM Ca2+浓度下,0分钟时Col-0和cngc2-1拟南芥突变体的叶片均没有检测到荧光,20分钟后能够清晰的看到Col-0和cngc2-1拟南芥突变体的荧光,荧光表达的位置反应Ca2+的分布位置。2小时后0.1mM Ca2+浓度下,Col-0和cngc2-1拟南芥突变体细胞质外Ca2+主要分布在三级叶脉和小叶脉上,4小时后的观察结果更为明显,Col-0和cngc2-1拟南芥突变体荧光位置相似。在Col-0和cngc2-1拟南芥突变体的非叶脉区域没有荧光信 号,说明Ca2+从维管束卸载到叶肉细胞是非常精准的过程使得游离于细胞外的Ca2+很少。
然而10mM Ca2+浓度下,我们观测2小时和4小时处理后的荧光发现,cngc2-1拟南芥突变体叶脉与叶脉周围都有很强的荧光信号值,在小叶脉周围也检测到较多的荧光信号。而Col-0在小叶脉周围没有检测到信号,并且Col-0的荧光区域与非荧光区域有非常明确的界限,而cngc2-1拟南芥突变体中看不到明显的界限。这说明cngc2-1拟南芥突变体非叶脉组织的细胞外空间中积累了更多的Ca2+,也说明在Ca2+从细胞外空间到叶肉细胞的分布过程中CNGC2基因扮演着重要的角色。
2.4.缺失CNGC2基因导致叶子中的Ca向叶表皮毛积累。
为了研究缺失CNGC2基因以后是否会影响植物叶和根的Ca含量,将正常植物Col-0和cngc2-1拟南芥突变体在含有0.1mM Ca2+的水培条件下培养3个星期,然后用含有0.1mM Ca2+和10mM Ca2+的水培溶液处理三天,剪下叶片,液氮速冻,用冷冻干燥机(EYELA FDU-2110)干燥24小时。用偶联X能谱仪场发射扫描电子显微镜(Hitachi S-4800)测定叶片中某特定细胞的Ca含量,结果如图5所示,cngc2-1拟南芥突变体叶表皮毛内的Ca含量显著高于正常植物Col-0,这说明,缺失CNGC2基因以后,植物叶细胞吸收Ca的能力下降,更多的Ca积累到了叶表皮毛中。进一步对叶表面其他细胞内Ca含量进行测定,结果如图5所示,在10mM Ca2+培养条件下,cngc2-1拟南芥突变体叶子表面如下细胞内的Ca含量显著低于正常植物Col-0:叶表皮毛旁的莲座细胞;叶表皮莲座细胞旁叶肉细胞;独立的叶肉细胞。这进一步证明,CNGC2调控Ca在植物叶片的分布。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
SEQUENCE LISTING
<110> 内蒙古和盛生态科技研究院有限公司
<120> CNGC2基因和其编码的氨基酸序列在培育植物新品种中的应用
<130> 2010
<160> 2
<170> PatentIn version 3.3
<210> 1
<211> 2181
<212> DNA
<213> 未知
<400> 1
atgccctctc accccaactt catcttcagg tggattggac tgttttccga taagttccgt 60
cgacaaacga ctgggatcga tgaaaacagt aacctccaaa tcaacggtgg agattcgagc 120
agcagcggca gcgatgagac gccggtgcta agctccgtcg agtgttacgc ttgcacacaa 180
gtaggcgtcc cagctttcca ttcaactagc tgcgatcaag ctcacgcgcc ggagtggcgt 240
gcctccgccg gctcttctct agttccgatc caggaaggat ctgtccctaa cccagcccga 300
accagattcc gacgtctcaa aggtccgttt ggtgaagttc tcgatcctag gagcaagcgc 360
gtgcagagat ggaaccgcgc gttgctttta gctcgtggga tggctttagc ggtggatccg 420
ctcttcttct acgcgctttc catcggccga actaccggac cggcgtgtct ttacatggat 480
ggtgcgttcg ccgcggtggt cacggtgctc cgcacgtgtc tcgatgctgt tcatctttgg 540
cacgtgtggc ttcaattcag actggcctac gtctcgagag agtcgcttgt cgttggttgt 600
gggaagctcg tttgggatcc acgcgccatc gcgtctcact acgcacgctc tctcactggc 660
ttctggtttg atgttatcgt catcctccct gtccctcagg cagtgttttg gttagttgtg 720
ccgaaactga taagagaaga gaaggttaag ctgataatga cgattctgct gctaatattc 780
ttgttccagt tcctccccaa gatttatcac tgcatctgtt tgatgagaag gatgcagaag 840
gtcactggtt acatttttgg aactatttgg tggggttttg ctcttaatct catcgcatat 900
ttcatcgctt ctcatgttgc tgggggatgt tggtatgttc tcgcaataca gcgtgttgct 960
tcttgcataa gacaacaatg tatgagaacc gggaactgca atctgagtct ggcttgcaaa 1020
gaagaggtct gttaccaatt tgtgtcaccg acaagcacag ttggatatcc atgcttatct 1080
ggaaacctta ccagtgtggt caataagcct atgtgcttag actctaacgg accattccga 1140
tatggtatct accgttgggc acttccagtc atctccagca actctcttgc ggttaagatc 1200
ctttacccca tcttctgggg cctaatgact ctcagcacat ttgcgaatga tcttgagccc 1260
acaagcaact ggctcgaggt tattttcagt atagttatgg ttctaagtgg cttgttactt 1320
ttcacgctgt tgataggaaa cattcaggtg tttttgcatg cggtaatggc gaaaaaaagg 1380
aaaatgcaga tacggtgtag ggatatggaa tggtggatga aacgtaggca gttaccttcc 1440
cggttaagac agagggttag gcgatttgag cggcagagat ggaatgcctt gggtggtgaa 1500
gacgagctag aacttataca tgatttgcct ccgggtcttc gaagagatat caaacgatat 1560
ctttgctttg atctcattaa caaggtgcca ttgttcaggg gcatggacga cttgatcctc 1620
gacaacattt gcgatcgggc taagcctcga gtcttctcta aagacgaaaa gatcatccgt 1680
gaaggagatc ctgtacagag aatgatattc atcatgcgtg gacgagtcaa acgtatacag 1740
agcctaagca aaggcgtcct agccactagt acactagaac caggcggtta cttgggcgac 1800
gagctactct catggtgcct acgtcgcccg tttctggacc gtcttccccc ttcctcagca 1860
acatttgtct gcctagaaaa catcgaggca ttctccctcg gatccgaaga tcttaggtac 1920
attaccgatc atttccgtta taaattcgcg aacgagcggc ttaagcggac cgcaagatac 1980
tattcctcaa actggaggac gtgggcagcg gtaaatattc agatggcgtg gcgccggcgt 2040
aggaaaagaa cccgtggtga aaacatcggc ggttcgatga gtcctgtgtc ggagaatagc 2100
attgaaggta acagtgaacg ccggttactt cagtatgcag ctatgttcat gtccattcga 2160
ccgcatgatc atctcgaata a 2181
<210> 2
<211> 726
<212> PRT
<213> 未知
<400> 2
Met Pro Ser His Pro Asn Phe Ile Phe Arg Trp Ile Gly Leu Phe Ser
1 5 10 15
Asp Lys Phe Arg Arg Gln Thr Thr Gly Ile Asp Glu Asn Ser Asn Leu
20 25 30
Gln Ile Asn Gly Gly Asp Ser Ser Ser Ser Gly Ser Asp Glu Thr Pro
35 40 45
Val Leu Ser Ser Val Glu Cys Tyr Ala Cys Thr Gln Val Gly Val Pro
50 55 60
Ala Phe His Ser Thr Ser Cys Asp Gln Ala His Ala Pro Glu Trp Arg
65 70 75 80
Ala Ser Ala Gly Ser Ser Leu Val Pro Ile Gln Glu Gly Ser Val Pro
85 90 95
Asn Pro Ala Arg Thr Arg Phe Arg Arg Leu Lys Gly Pro Phe Gly Glu
100 105 110
Val Leu Asp Pro Arg Ser Lys Arg Val Gln Arg Trp Asn Arg Ala Leu
115 120 125
Leu Leu Ala Arg Gly Met Ala Leu Ala Val Asp Pro Leu Phe Phe Tyr
130 135 140
Ala Leu Ser Ile Gly Arg Thr Thr Gly Pro Ala Cys Leu Tyr Met Asp
145 150 155 160
Gly Ala Phe Ala Ala Val Val Thr Val Leu Arg Thr Cys Leu Asp Ala
165 170 175
Val His Leu Trp His Val Trp Leu Gln Phe Arg Leu Ala Tyr Val Ser
180 185 190
Arg Glu Ser Leu Val Val Gly Cys Gly Lys Leu Val Trp Asp Pro Arg
195 200 205
Ala Ile Ala Ser His Tyr Ala Arg Ser Leu Thr Gly Phe Trp Phe Asp
210 215 220
Val Ile Val Ile Leu Pro Val Pro Gln Ala Val Phe Trp Leu Val Val
225 230 235 240
Pro Lys Leu Ile Arg Glu Glu Lys Val Lys Leu Ile Met Thr Ile Leu
245 250 255
Leu Leu Ile Phe Leu Phe Gln Phe Leu Pro Lys Ile Tyr His Cys Ile
260 265 270
Cys Leu Met Arg Arg Met Gln Lys Val Thr Gly Tyr Ile Phe Gly Thr
275 280 285
Ile Trp Trp Gly Phe Ala Leu Asn Leu Ile Ala Tyr Phe Ile Ala Ser
290 295 300
His Val Ala Gly Gly Cys Trp Tyr Val Leu Ala Ile Gln Arg Val Ala
305 310 315 320
Ser Cys Ile Arg Gln Gln Cys Met Arg Thr Gly Asn Cys Asn Leu Ser
325 330 335
Leu Ala Cys Lys Glu Glu Val Cys Tyr Gln Phe Val Ser Pro Thr Ser
340 345 350
Thr Val Gly Tyr Pro Cys Leu Ser Gly Asn Leu Thr Ser Val Val Asn
355 360 365
Lys Pro Met Cys Leu Asp Ser Asn Gly Pro Phe Arg Tyr Gly Ile Tyr
370 375 380
Arg Trp Ala Leu Pro Val Ile Ser Ser Asn Ser Leu Ala Val Lys Ile
385 390 395 400
Leu Tyr Pro Ile Phe Trp Gly Leu Met Thr Leu Ser Thr Phe Ala Asn
405 410 415
Asp Leu Glu Pro Thr Ser Asn Trp Leu Glu Val Ile Phe Ser Ile Val
420 425 430
Met Val Leu Ser Gly Leu Leu Leu Phe Thr Leu Leu Ile Gly Asn Ile
435 440 445
Gln Val Phe Leu His Ala Val Met Ala Lys Lys Arg Lys Met Gln Ile
450 455 460
Arg Cys Arg Asp Met Glu Trp Trp Met Lys Arg Arg Gln Leu Pro Ser
465 470 475 480
Arg Leu Arg Gln Arg Val Arg Arg Phe Glu Arg Gln Arg Trp Asn Ala
485 490 495
Leu Gly Gly Glu Asp Glu Leu Glu Leu Ile His Asp Leu Pro Pro Gly
500 505 510
Leu Arg Arg Asp Ile Lys Arg Tyr Leu Cys Phe Asp Leu Ile Asn Lys
515 520 525
Val Pro Leu Phe Arg Gly Met Asp Asp Leu Ile Leu Asp Asn Ile Cys
530 535 540
Asp Arg Ala Lys Pro Arg Val Phe Ser Lys Asp Glu Lys Ile Ile Arg
545 550 555 560
Glu Gly Asp Pro Val Gln Arg Met Ile Phe Ile Met Arg Gly Arg Val
565 570 575
Lys Arg Ile Gln Ser Leu Ser Lys Gly Val Leu Ala Thr Ser Thr Leu
580 585 590
Glu Pro Gly Gly Tyr Leu Gly Asp Glu Leu Leu Ser Trp Cys Leu Arg
595 600 605
Arg Pro Phe Leu Asp Arg Leu Pro Pro Ser Ser Ala Thr Phe Val Cys
610 615 620
Leu Glu Asn Ile Glu Ala Phe Ser Leu Gly Ser Glu Asp Leu Arg Tyr
625 630 635 640
Ile Thr Asp His Phe Arg Tyr Lys Phe Ala Asn Glu Arg Leu Lys Arg
645 650 655
Thr Ala Arg Tyr Tyr Ser Ser Asn Trp Arg Thr Trp Ala Ala Val Asn
660 665 670
Ile Gln Met Ala Trp Arg Arg Arg Arg Lys Arg Thr Arg Gly Glu Asn
675 680 685
Ile Gly Gly Ser Met Ser Pro Val Ser Glu Asn Ser Ile Glu Gly Asn
690 695 700
Ser Glu Arg Arg Leu Leu Gln Tyr Ala Ala Met Phe Met Ser Ile Arg
705 710 715 720
Pro His Asp His Leu Glu
725
- 还没有人留言评论。精彩留言会获得点赞!
- 新的重组型抗体及其cdr氨基酸序列和编码它们的基因的制作方法
- 包括一种抗原或包含氨基酸序列化合物的体内发生器的治疗性组合物的制作方法
- 针对CXCR4和其他GPCRs的氨基酸序列以及包含所述氨基酸序列的多肽的制作方法
- 鸡贫血病毒疫苗及诊断方法
- 用于控制致病体的核酸序列和氨基酸序列的制作方法
- 一种铁氢化酶基因及其编码的氨基酸序列和异源表达系统的制作方法
- 精氨酸在提高发酵培养氨基酸序列含有精氨酸-精氨酸的多肽的表达量中的应用及方法
- 一组可提高sod耐热温度和热稳定性的氨基酸序列及其应用的制作方法
- 菜豆几丁质酶基因及其编码产物的氨基酸序列的制作方法
- 一种中药有效成分的氨基酸序列获得方法及其所确定的具体氨基酸序列的制作方法