单核苷酸多态性rs145562243在筛查麻风患者中的应用的制作方法
本发明涉及生物技术领域中单核苷酸多态性rs145562243在筛查麻风患者中的应用。
背景技术:
麻风,又名Hansen’s病,是一种由麻风分枝杆菌(M.Leprae)引起的传染性疾病,主要侵犯皮肤和周围神经。2014年,全球有213,889例新发病例。尽管目前存在有效的治疗方法,但在一些国家,特别是发展中国家,麻风仍是致畸和导致一些社会问题的主要原因。为了解麻风易感性的遗传学基础,麻风的全基因组关联分析(GWAS)定位了17个常见变异位点,揭示了固有免疫与适应性免疫在麻风发病中的作用。然而,这些常见的风险变异位点大部分位于非编码区,仅能够部分解释麻风的发病风险。目前,还没有对蛋白编码区域的变异,特别是低频变异和罕见变异,进行系统研究。而这些变异已证实与一些疾病的遗传易感性相关。
技术实现要素:
本发明所要解决的技术问题是如何筛查麻风患者与检测麻风易感性。
为解决上述技术问题,本发明首先提供了下述任一用途:
A1)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在制备筛查麻风患者产品中的应用;
A2)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在制备检测麻风易感性产品中的应用;
A3)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在制备检测与麻风相关的单核苷酸多态性的产品中的应用;
A4)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在制备鉴定或辅助鉴定与麻风相关的单核苷酸多态性的产品中的应用;
B1)人基因组中rs145562243的多态性(即等位基因)或基因型在制备筛查麻风患者产品中的应用;
B2)人基因组中rs145562243的多态性(即等位基因)或基因型在制备检测麻风易感性产品中的应用;
B3)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在筛查麻风患者中的应用;
B4)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在检测麻风易感性中的应用;
B5)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在检测与麻风相关的单核苷酸多态性的中的应用;
B6)检测人基因组中rs145562243的多态性(即等位基因)或基因型的物质在鉴定或辅助鉴定与麻风相关的单核苷酸多态性的中的应用;
B7)人基因组中rs145562243的多态性(即等位基因)或基因型在筛查麻风患者中的应用;
B8)人基因组中rs145562243的多态性(即等位基因)或基因型在检测麻风易感性中的应用。
rs145562243是人染色体3p21.31上的一个二等位多态性的SNP位点,属于罕见突变(MAF=0.4%),位于NCKIPSD基因的外显子中,该变异是转换(C/T,在其互补链上则为G/A)。所述rs145562243基因型是CC、TC或TT。所述CC是rs145562243位点为C的纯合型,所述TT是rs145562243位点为T的纯合型,所述TC是rs145562243位点为C和T的杂合型。所述检测人基因组中rs145562243的多态性(即等位基因)或基因型具体可为检测rs145562243的核苷酸种类。
上述用途中,所述检测人基因组中rs145562243的多态性或基因型的物质可为扩增包括rs145562243在内的基因组DNA片段的PCR引物和/或单碱基延伸引物。
上述用途中,所述TC基因型的个体在麻风患者群体中的比例高于所述TC基因型的个体在正常人群体中的比例。所述产品可包括所述PCR引物和/或所述单碱基延伸引物。
上述用途中,所述麻风具体可为中国人群麻风。
为解决上述技术问题,本发明还提供了含有检测人基因组中rs145562243的多态性或基因型的物质的产品。
本发明所提供的含有检测人基因组中rs145562243的多态性或基因型的物质的产品,为a)-d)中的任一种产品:
a)检测与麻风相关的单核苷酸多态性(即等位基因)或基因型的产品;
b)鉴定或辅助鉴定与麻风相关的单核苷酸多态性(即等位基因)或基因型的产品;
c)筛查麻风患者产品;
d)检测麻风易感性产品。
上述产品中,所述检测人基因组中rs145562243的多态性或基因型的物质可为扩增包括rs145562243在内的基因组DNA片段的PCR引物和/或单碱基延伸引物。
上述产品中,所述麻风具体可为中国人群麻风。
为解决上述技术问题,本发明还提供了下述M1)或M2)的方法:
M1)筛查麻风患者的方法,包括:检测待测对象基因组中rs145562243位点的基因型,如rs145562243位点的基因型为CC基因型,所述待测对象为或候选为非麻风患者;如rs145562243位点的基因型为TC基因型,所述待测对象为或候选为麻风患者;如rs145562243位点的基因型为TT基因型,所述待测对象为或候选为麻风患者;
M2)检测麻风易感性的方法,包括:检测待测对象基因组中rs145562243位点的基因型,如rs145562243位点的基因型为CC基因型,所述待测对象不易感或候选不易感麻风;如rs145562243位点的基因型为TC基因型,所述待测对象易感或候选易感麻风;如rs145562243位点的基因型为TT基因型,所述待测对象易感或候选易感麻风。
上述方法中,检测待测对象基因组中rs145562243位点的基因型可采用所述检测rs145562243的多态性或基因型的物质进行。
上述方法中,所述麻风具体可为中国人群麻风。
实验证明,rs145562243的风险等位基因为T,该等位基因在麻风患者群体中的比例比该等位基因在正常健康人群中的比例高875.00%。rs145562243的P值是1.71×10-9,且rs145562243的相对危险度是4.35,说明rs145562243是与麻风相关的单核苷酸多态性。rs145562243的三个基因型中,TC基因型的个体在麻风患者群体中的比例高于对应的基因型的个体在正常人群体中的比例,CC基因型的个体在麻风患者群体中的比例低于该基因型的个体在正常人群体中的比例。
本发明在实际应用中,可将检测rs145562243的多态性(即等位基因)或基因型的物质与其它物质(如检测其它的与麻风相关的单核苷酸多态性或基因型的物质)联合在一起制备筛查麻风患者的产品。
其中,检测人基因组中rs145562243的多态性或基因型的物质可为通过下述至少一种方法确定rs145562243的多态性或基因型所需的试剂和/或仪器:DNA测序、限制性酶切片段长度多态性、单链构象多态性、变性高效液相色谱、SNP芯片、TaqMan探针技术和Sequenom MassArray技术。其中,利用Sequenom MassArray技术确定rs145562243的多态性或基因型所需的试剂和/或仪器包括PCR引物对、基于单碱基延伸反应的延伸引物、磷酸酶、树脂、芯片、MALDI-TOF(matrix-assisted laser desorption/ionization–time of fligh,基质辅助激光解吸附电离飞行时间质谱)和/或Sequenom MassArray技术所需要的其他试剂和仪器;利用TaqMan探针技术确定rs145562243的多态性或基因型所需的试剂和/或仪器包括TaqMan探针、PCR引物对、定量PCR仪、进行基因分型的模块和/或TaqMan探针技术所需要的其他试剂;SNP芯片包括基于核酸杂交反应的芯片、基于单碱基延伸反应的芯片、基于等位基因特异性引物延伸反应的芯片、基于“一步法”反应的芯片、基于引物连接反应的芯片、基于限制性内切酶反应的芯片、基于蛋白DNA结合反应的芯片和/或基于荧光分子DNA结合反应的芯片。在本发明的一个实施例中,利用的是Illumina公司的Infinium Human Exome BeadChip芯片。
所述产品可为试剂或试剂盒,还可为由试剂或试剂盒和仪器组成的系统,如由引物和DNA测序仪组成的系统,由PCR试剂和DNA测序试剂和DNA测序仪组成的系统,由TaqMan探针、PCR引物对、定量PCR仪和进行基因分型的模块以及TaqMan探针技术所需要的其他试剂组成的系统,由探针、PCR引物对以及连接酶检测反应(LDR)所需要的其他试剂和仪器组成的系统,由PCR引物对、单碱基延伸引物、芯片、PCR仪、进行基因分型的模块和/或Sequenom MassArray技术所需要的其他试剂和仪器组成的系统。
采用PCR引物扩增包括rs145562243在内的基因组DNA片段,以得到的PCR扩增产物为模板,采用单碱基延伸引物进行单碱基延伸反应,对得到的延伸产物的序列进行检测,确定rs145562243的多态性(即等位基因)和基因型。所述PCR引物在序列上没有特殊要求,只要能扩增出包括rs145562243在内的基因组DNA片段即可。所述延伸引物可根据人基因组中rs145562243上游(不包括该SNP位点)设计,所述延伸引物的最后1位核苷酸对应于人基因组中rs145562243的前1位核苷酸。所述延伸引物也可根据人基因组中rs145562243下游(不包括该SNP位点)设计,所述延伸引物的第1位核苷酸对应于人基因组中rs145562243的后1位核苷酸。
本发明中,所述PCR引物可由rs145562243-F和rs145562243-R组成;
所述rs145562243-F是如下a1)至a4)中的任一种单链DNA:
a1)序列表中序列1所示的单链DNA;
a2)在a1)的5′端和/或3′端添加一个或几个核苷酸得到的单链DNA;
a3)与a1)或a2)限定的单链DNA具有85%以上的同一性的单链DNA;
a4)在严格条件下与a1)或a2)限定的单链DNA杂交的单链DNA;
所述rs145562243-R是如下b1)至b4)中的任一种单链DNA:
b1)序列表中序列2所示的单链DNA;
b2)在b1)的5′端和/或3′端添加一个或几个核苷酸得到的单链DNA;
b3)与b1)或b2)限定的单链DNA具有85%以上的同一性的单链DNA;
b4)在严格条件下与b1)或b2)限定的单链DNA杂交的单链DNA。
所述单碱基延伸引物(rs145562243-E)可为如下c1)至c4)中的任一种单链DNA:
c1)序列表中序列3所示的单链DNA;
c2)在c1)的5′端和/或3′端添加一个或几个核苷酸得到的单链DNA;
c3)与c1)或c2)限定的单链DNA具有85%以上的同一性的单链DNA;
c4)在严格条件下与c1)或c2)限定的单链DNA杂交的单链DNA。
a2)所述在a1)的5′端和/或3′端添加一个或几个核苷酸得到的单链DNA为在序列1所示的单链DNA的5′端和/或3′端添加一至十个核苷酸得到的单链DNA。b2)所述在b1)的5′端和/或3′端添加一个或几个核苷酸得到的单链DNA为在序列2所示的单链DNA的5′端和/或3′端添加一至十个核苷酸得到的单链DNA。c2)所述在c1)的5′端和/或3′端添加一个或几个核苷酸得到的单链DNA为在序列3所示的单链DNA的5′端和/或3′端添加一至十个核苷酸得到的单链DNA。
这里使用的术语“同一性”指与天然核酸序列的序列相似性。“同一性”包括与本发明的序列1、序列2或序列3所示的核苷酸序列具有85%或更高,或90%或更高,或95%或更高同一性的核苷酸序列。同一性可以用肉眼或计算机软件进行评价。使用计算机软件,两个或多个序列之间的同一性可以用百分比(%)表示,其可以用来评价相关序列之间的同一性。
所述严格条件是在2×SSC,0.1%SDS的溶液中,在68℃下杂交并洗膜2次,每次5min,又于0.5×SSC,0.1%SDS的溶液中,在68℃下杂交并洗膜2次,每次15min;或,0.1×SSPE(或0.1×SSC)、0.1%SDS的溶液中,65℃条件下杂交并洗膜。
上述85%以上同一性,可为85%、90%或95%以上的同一性。
在本发明的实施例中,rs145562243应用SEQUENOM基因分型平台即分子量阵列技术,SequenomSNP检测过程结合多重PCR技术、MassARRAY iPLEX单碱基延伸技术,和基质辅助激光解吸附电离飞行时间质谱分析质谱技术(matrix-assisted laser desorption/ionization–time of flight,MALDI-TOF)进行分型检测。将包含SNP位点区域的DNA模板通过PCR技术扩增,再使用特异的延伸引物与PCR产物进行单碱基延伸反应。由于多态性位点碱基不同,延伸产物不同的末端碱基将导致延伸后的产物分子量的差异,因此由SNP多态性引起的碱基差异通过分子量的差异而体现,通过基质辅助激光解吸附电离飞行时间质谱分析质谱技术,检测延伸产物分子量的大小,应用专用的分析软件,通过判断分子量的差异而进行SNP分型检测。
本发明在一个来自中国人群的样本(7048例麻风患者和14398例健康者)中发现rs145562243是与麻风相关的单核苷酸多态性。可将检测rs145562243的多态性(即等位基因)或基因型的物质与其它物质(如检测其它的与麻风相关的单核苷酸多态性(即等位基因)或基因型的物质)联合在一起制备筛查麻风患者的产品。
附图说明
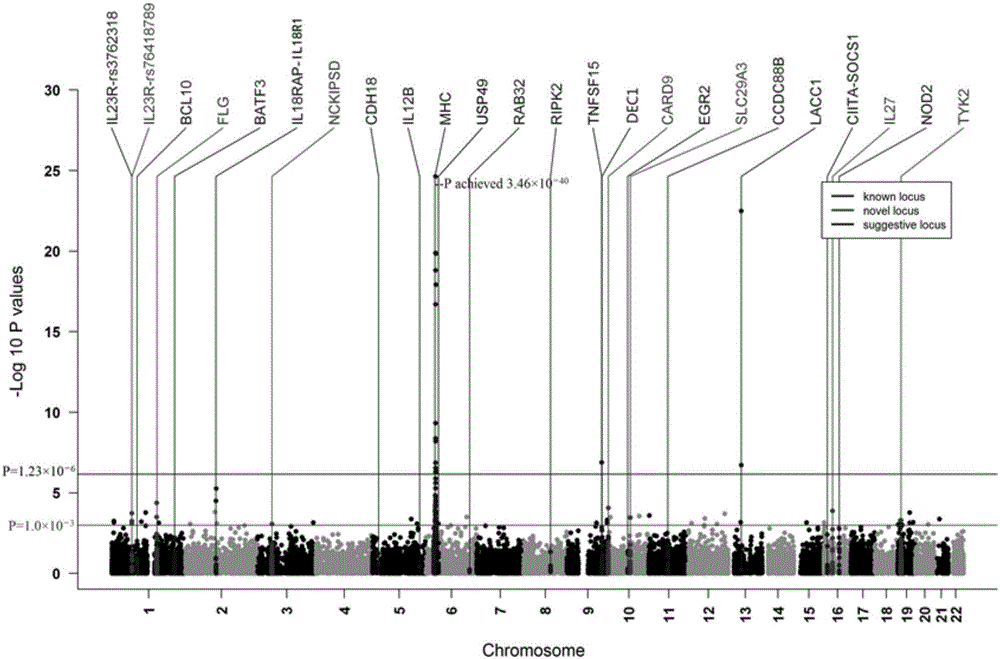
图1为应用固定效果模型对所有样本(7,048例病例和14,398例健康对照)进行meta分析的结果。
具体实施方式
下面结合具体实施方式对本发明进行进一步的详细描述,给出的实施例仅为了阐明本发明,而不是为了限制本发明的范围。
下述实施例中的实验方法,如无特殊说明,均为常规方法。
下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
实施例1、rs145562243、rs149308743、rs76418789、rs146466242、rs55882956、rs780668和rs181206是与麻风相关的单核苷酸多态性
方法:发明人通过三个阶段对中国人群中的7,048例麻风患者及14,398例正常对照进行蛋白编码区域的全基因组关联分析研究。首先,通过外显子芯片对1,648例麻风患者和2,318例正常对照的40,491个编码区域的SNP位点(MAF>0.1%)进行分析(第一阶段)。然后在中国北方人群(3,169例麻风患者和9,814例正常对照)中对34个候选SNP位点进行验证(第二阶段)。最后在另外选取的中国南方人群(2,231例麻风患者和2,266例正常对照)以及第一、二阶段的所有样本中对8个候选位点进行验证(第三阶段)。
研究对象
外显子芯片发现阶段(第一阶段)的研究对象为中国北方地区的1,670例麻风患者和2,321例正常对照。验证阶段(第二阶段)将39个变异位点在中国北方地区的另外的3,169例麻风患者和9,814例正常对照中进行验证。最终对筛选出的8个变异位点的重复验证阶段(第三阶段)选择的研究对象为中国南方地区的三个独立样本以及第一、二阶段的所有样本:(1)四川省906例麻风患者和878例正常对照;(2)云南省829例麻风患者和589例正常对照;(3)贵州省496例麻风患者和799例正常对照。麻风患者和正常对照均为中国汉族人群,并且在地域上是相匹配的。研究对象的临床信息见表1。
表1、研究对象信息
其中,麻风患者的诊断标准是符合下述4条中的2条或2条以上,或符合第3条者确立诊断:1、皮损伴有感觉障碍及闭汗,或有麻木区;2、周围神经受累,表现为神经干粗大伴相应功能障碍;3、皮损组织切片或组织液涂片查到麻风杆菌;4、病理可见特征性改变。
正常对照(正常健康人)的诊断标准:无麻风史且无麻风的家族史(包括麻风患者的一级、二级和三级亲属);无其他传染病病史;无其他自身免疫性疾病病史、系统性疾病病史及家族史。
本研究已通过山东省医学科学院、山东省皮肤病性病防治研究所伦理审查委员会批准。
分型与质控
选用Illumina公司的Infinium Human Exome BeadChip芯片对1,670例麻风患者及2,321例正常对照进行分型,芯片上共有对1,998例中国人样本进行全外显子组测序鉴定出的27,089个(在>1例样本中存在)非同义编码区域变异。排除非编码区变异和MAF<0.1%的变异,对40,491个编码区域变异进行关联分析。在验证阶段和重复验证阶段,选用Sequenom MassARRAY system(Agena Bioscience),QuantStudioTM 12K Flex Real-Time PCR(Applied Biosystems)和7900HT Fasr Real-Time PCR System(Applied Biosystems)进行分型研究。质控过滤标准如下:排除不确定群体的变异、检出率<90%且不符合Hardy-Weinberg平衡定律(P<1×10-3)、样本检出率<95%的情况。
统计学分析
在第一阶段,通过GMMAT-v0.7进行表型和单个变异基因型之间的关联性分析。在第二、三阶段,通过PLINK中的线性回归模型对MAF>1%的SNPs进行关联性分析,利用PLINK中Fisher's确切概率法对MAF<1%的SNPs进行关联分析。利用固定效果模型(通过META-v7.0软件对MAF>1%的SNPs采用逆方差法,对MAF<1%的SNPs采用z-统计量组合方法进行分析)。对发现阶段、验证阶段、重复验证阶段三部分结合起来的数据进行meta分析。同时符合p<1.23×10-6(0.05/40,491)的变异为有统计学意义的外显子组的变异。对于第二和第三阶段的关联分析,p<0.05并且和发现阶段具有相同效应的变异为具有统计学意义的位点。利用Cochran’s Q检验对独立样本的异质性进行分析,p<0.05认为具有统计学意义。
外显子组发现阶段分析
对1,670例麻风患者和2,321例正常对照的273,028个变异位点进行分型。通过主成分分析确定所有样本均为中国血统,并且发现在麻风患者和正常对照中具有较好的基因型的匹配。经过一系列样本和变异位点的过滤,共发现40,491个MAF>0.1%的编码区变异位点(38,068个非同义突变和2,423个同义突变),后将其在1,648例麻风患者和2,318例健康对照中进行分析。
全外显子分析发现在MHC区域内有较强的关联性。去除MHC区域内的所有变异位点后,剩余SNP位点的Q-Q图符合零分布,表明将人群混杂因素导致的外显子关联分析结果的可能性降到最低(lambda value=0.99)。同时,对不同MAF阈值(MAF>0.5%,MAF>1%和MAF>5%)的SNP位点进行Q-Q图的分析,与上述结果一致。
通过研究发现,五个提示有关联性(P<1.0×10-3)的编码区域的变异位点(四个常见变异和一个低频变异)也包括在之前报道的GWAS发现的位点内。四个常见变异位点与之前报道的SNP位点有较强的连锁不平衡,仅有低频变异(IL-23R基因rs76418789)为独立的。另外,Q-Q图(去除MHC区域内SNP位点)尾端分布与标准零分布的Q-Q图存在偏差,表明存在新的关联位点,有38个新的编码区域内的变异位点被发现具有关联性(P<1.0×10-3)。
为进一步研究低频变异和罕见变异的作用,通过SKAT-O和berden-test的方法对排除MHC区域内的变异位点及已知位点中的5个编码区域的变异位点和38个新的编码区域内的变异位点(P<1.0×10-3)后的SNP位点进行分析。两种方法均证明基因关联性并非偶然。
验证阶段分析
在中国北方区域内的3,169例麻风患者和9,814例健康对照中对38个新发现的编码区域的变异位点及之前GWAS发现的一个低频编码区域的变异位点进行分型。有34个变异位点可成功分型,其中15个位点在发现阶段和验证阶段是一致的(在验证阶段,P<0.05,OR值的效应与发现阶段一致),6个位点在发现阶段和验证阶段均具有外显子组分析的统计学意义(P<1.23×10-6)且没有遗传异质性,这6个位点分别为:NCKIPSD基因rs145562243(P=1.44×10-8,OR=4.35),CARD9基因rs149308743(P=4.99×10-10,OR=4.75),IL23R基因rs76418789(P=6.28×10-9,OR=1.37),FLG基因rs146466242(P=1.44×10-10,OR=1.45),SLC29A3基因rs780668(P=2.89×10-7,OR=1.14)和IL27基因rs181206(P=5.92×10-7,OR=0.83)(表3)。
另外,两个编码区域的变异位点:TYK2基因rs55882956(P=2.75×10-5,OR=1.29)和USP49基因rs75746803(P=3.45×10-6,OR=1.28)在发现阶段和验证阶段与麻风均具有一致性和关联性,但仅刚刚达到外显子组分析的统计学意义(P<5.0×10-5)(表3)。
其中,对rs145562243、rs149308743、rs76418789、rs146466242、rs55882956、rs780668和rs181206分型采用Sequenom MassARRAY system(Agena Bioscience),QuantStudioTM 12K Flex Real-Time PCR(Applied Biosystems)和7900HT Fasr Real-Time PCR System(Applied Biosystems)进行,具体方法如下:
1.rs181206、rs780668、rs76418789、rs149308743、rs145562243和rs55882956的分型
rs181206、rs780668、rs76418789、rs149308743、rs145562243和rs55882956这6个SNP应用SEQUENOM基因分型平台即分子量阵列技术,SequenomSNP检测过程结合多重PCR技术、MassARRAY iPLEX单碱基延伸技术,和基质辅助激光解吸附电离飞行时间质谱分析质谱技术(matrix-assisted laser desorption/ionization–time of flight,MALDI-TOF)进行分型检测。将包含SNP位点区域的DNA模板通过PCR技术扩增,再使用特异的延伸引物与PCR产物(表2)进行单碱基延伸反应。由于多态性位点碱基不同,延伸产物不同的末端碱基将导致延伸后的产物分子量的差异,因此由SNP多态性引起的碱基差异通过分子量的差异而体现,通过基质辅助激光解吸附电离飞行时间质谱分析质谱技术,检测延伸产物分子量的大小,应用专用的分析软件,通过判断分子量的差异而进行SNP
分型检测。
表2、6个SNP分型引物
操作步骤如下:
6个SNP采用Sequenom MassArray(San Diego,USA)平台验证,每个样本约用到15ngDNA。首先提取外周血的基因组DNA,标准化后,样本DNA经多重PCR反应扩增包括SNP位点在内的基因组DNA片段,扩增产物进行SNP位点特异性单一链的延伸,延伸产物脱盐并转移到384孔的芯片上。质谱仪(MALDI-TOF MS)进行等位基因的检测,采用Sequenom MassARRAY分型软件对检测结果进行分析。
1.1、全血标本采集
在知情同意,并签署书面同意书的情况下采集研究对象外周静脉血5ml,放置于EDTANa2抗凝管中,置-80℃冰柜储存备用。
1.2、DNA浓度标准化包括如下步骤:
1)利用NanoDrop-1000浓度测试仪准确测定每一份需要标准化的样本DNA浓度和OD比值(A260/A280、A260/A230)。
2)建立电子表格,排定每个样本孔需要加入的DNA编号。
进行Sequenom MassArray分型的样本,在每96孔板上留有空白对照和重复样本对照。
3)按照电子表格的顺序,加入已测定浓度的DNA。
对于进行Sequenom MassArray分型的样本要求实验浓度为12-30ng/μl,一般以18ng/μl为佳。并且A260/A280比值介于1.5-2.0之间、A260/230介于1.5-2.3,如DNA浓度高于18ng/μl则加入适量FG3,将浓度标化至18ng/μl;如DNA浓度低于12ng/μl,则重新从血液提取合格的DNA。浓度在12-18ng/μl间直接加入。
离心后贴上粘性锡箔纸,并用标记笔标上样本板标号、样本类型、来源地等信息。
4)在平板离心机上,3000g离心3分钟,存放于-20℃备用。
1.3、利用各SNP的正向引物和反向引物进行多重PCR
1.4、SNP位点特异性单一链的延伸反应
其中,延伸引物根据人基因组中SNP位点上游(不包括该SNP位点)设计,所述延伸引物的最后1位核苷酸对应于人基因组中该SNP位点的前1位核苷酸。
1.5、数据质量控制
1)对分型的SNP进行call rate计算,去除call rate<95%的SNP或等位基因频率<0.01的SNPs;
2)对SNP进行遗传平衡检验,去除偏离遗传平衡定律的SNP(对照样本中Hardy-Weinberg平衡检验的P≦0.001)。
3)在Sequenom MassArray系统中查看SNP的分型聚类图,去除聚类图分堆不清的SNP。
4)样本质控:直接去除分型失败的样本。
将通过质控的样本和SNP进行统计分析。
1.6、数据统计分析
利用Plink 1.07软件对分型成功并通过质控的SNP在病例组和对照组做基因表型相关性分析,用Cochran-Armitage trend检验每个样本的基因型和表型的关联性,然后用Cochran-Mantel-Haenszel综合分析所有样本的基因型和表型的相关性。用Q检验来评价个体间的异质性,本次实验中,以p<0.05作为检验水准。多重logistic回归分析用于检测区域内的信号的独立性。检验水准α以0.05除以通过质量控制的SNP数目为检验水准。Q检验用于评估遗传异质性的显著性,对SNP校正检测后P值小于0.05者视为有显著遗传异质性。
2.rs146466242的分型
rs146466242应用7900HT/Taqman基因分型系统进行SNP分型。
引物及探针序列为:
正向引物rs146466242-F:CCACATAAACCTGGGTCCTTATTAA(序列19)
反向引物rs146466242-R:GGAAAGATCTGATATCTGTAAAGCAAGTG(序列20)
探针1rs146466242-P1:CTTGGATGATCTTTAC(序列21),5′端由报告荧光染料FAM标记,3′端由淬灭荧光染料NFQ标记
探针2rs146466242-P2:CTTGGATGATCTTAAC(序列22),5′端由报告荧光染料VIC标记,3′端由淬灭荧光染料NFQ标记
操作步骤如下:
分别抽取每个对象的外周静脉血5ml,提取基因组DNA,分别基因组DNA(DNA浓度均在50-100ng/微升之间)。
实时荧光定量PCR反应的反应体系为:基因组DNA 1μL、2×TaqMan GT master mix(Life technology公司)2.5μL、20×TaqMan探针混合物0.65μL、去离子水0.85μL。将上述反应体系加入96孔PCR板中,采用ABI 7900实时荧光定量PCR仪(Applied Biosystems公司)进行反应。反应条件为:95℃变性30秒,60℃退火1分钟,40个循环。
上述反应体系中,20×TaqMan探针混合物包括扩增包括rs146466242在内的基因组DNA片段的PCR引物对和成套探针,其中PCR引物对由上述正向引物和反向引物组成,成套探针由探针1和探针2组成。
反应结束后,采用7900System SDS software进行基因型分型,确定各研究对象rs146466242位点的基因型。
重复验证分析
为了进一步验证8个非同义变异位点(6个外显子组分析具有统计学意义的位点和2个提示可能相关的位点)是否具有关联性,又在中国南方区域选取三个独立样本共2,231例麻风患者和2,266例正常对照。然后对所有样本(7,048例病例和14,398例健康对照)进行分型,其中,对rs145562243、rs149308743、rs76418789、rs146466242、rs55882956、rs780668和rs181206分型采用的具体方法同验证阶段。
然后应用固定效果模型对所有样本(7,048例病例和14,398例健康对照)进行meta分析。7个编码突变显示了三个阶段中的一致性关联,无异质性证据,并且在所有样本中有外显子的显著性差异(P<0.05/40,491=1.23×10-6):两个罕见突变,位于3p21.31的NCKIPSD基因rs145562243(MAF=0.4%,P=1.71×10-9,OR=4.35)和位于9q34.3的CARD9基因rs149308743(MAF=0.5%,P=2.09×10-8,OR=4.75);三个低频变异,位于1p31.3的IL23R基因rs76418789(MAF=4.32%,P=1.03×10-10,OR=1.36),位于1q21.3的FLG基因rs146466242(MAF=3.54%,P=3.39×10-12,OR=1.45)和位于19p13.2的TYK2基因rs55882956(MAF=3.63%,P=1.04×10-6,OR=1.30);两个常见变异,位于10q22.1的SLC29A3基因rs780668(MAF=42%,P=2.17×10-9,OR=1.14)和位于16p11.2的IL27基因rs181206(MAF=15%,P=1.08×10-7,OR=0.83)。虽然在所有独立性样本分析中,位于6p21.1的USP49基因rs75746803显示出一致性,但该位点低于外显子显著性水平(MAF=4.8%,P=3.57×10-6,OR=1.25)(表3和图1)。
7个SNP在7048例麻风患者和14398例正常对照中的基因型频率如表4和表5所示。结果表明:rs145562243的三个基因型中,TC基因型的个体在麻风患者群体中的比例高于对应的基因型的个体在正常人群体中的比例,CC基因型的个体在麻风患者群体中的比例低于该基因型的个体在正常人群体中的比例;
rs149308743的三个基因型中,TC基因型的个体在麻风患者群体中的比例高于对应的基因型的个体在正常人群体中的比例,CC基因型的个体在麻风患者群体中的比例低于该基因型的个体在正常人群体中的比例;
rs76418789的三个基因型中,AA基因型的个体和AG基因型的个体在麻风患者群体中的比例分别高于对应的基因型的个体在正常人群体中的比例,GG基因型的个体在麻风患者群体中的比例低于该基因型的个体在正常人群体中的比例;
rs146466242的三个基因型中,AA基因型的个体和AT基因型的个体在麻风患者群体中的比例分别高于对应的基因型的个体在正常人群体中的比例,TT基因型的个体在麻风患者群体中的比例低于该基因型的个体在正常人群体中的比例;
rs55882956的三个基因型中,AA基因型的个体和AG基因型的个体在麻风患者群体中的比例分别高于对应的基因型的个体在正常人群体中的比例,GG基因型的个体在麻风患者群体中的比例低于该基因型的个体在正常人群体中的比例;
rs780668的三个基因型中,TT基因型的个体和TC基因型的个体在麻风患者群体中的比例分别高于对应的基因型的个体在正常人群体中的比例,CC基因型的个体在麻风患者群体中的比例低于该基因型的个体在正常人群体中的比例;
rs181206的三个基因型中,AA基因型的个体在麻风患者群体中的比例高于对应的基因型的个体在正常人群体中的比例,GG基因型和AG基因型的个体在麻风患者群体中的比例分别低于对应基因型的个体在正常人群体中的比例。
表4、SNP在麻风患者和正常群体中的基因型个体数
表5、SNP在麻风患者和正常群体中的基因型频率
表6、SNP在麻风患者群体中的等位基因频率(%)和与对照相比的变化量
注表4和表5中,rs145562243的基因型中,A1*A1表示CC,A1*A2表示TC,A2*A2表示TT;
rs149308743的基因型中,A1*A1表示CC,A1*A2表示TC,A2*A2表示TT;
rs76418789的基因型中,A1*A1表示AA,A1*A2表示AG,A2*A2表示GG;
rs146466242的基因型中,A1*A1表示AA,A1*A2表示AT,A2*A2表示TT;
rs55882956的基因型中,A1*A1表示AA,A1*A2表示AG,A2*A2表示GG;
rs780668的基因型中,A1*A1表示TT,A1*A2表示TC,A2*A2表示CC;
rs181206的基因型中,A1*A1表示GG,A1*A2表示AG,A2*A2表示AA。
利用二分类的logistic回归模型(log-additive模型)计算麻风患者群体和正常人群体中基因频率差异性P值,确定SNP有无显著性意义,其中基因型采用可加模型进行统计。结果发现,rs145562243、rs149308743、rs76418789、rs146466242、rs55882956、rs780668和rs181206的各等位基因的基因频率在正常人群体和麻风患者群体中均有显著性差异。
由表6可知,rs145562243的风险等位基因为T,该等位基因在麻风患者中的基因频率为0.0039,在正常对照中的基因频率为0.0004,与正常对照相比,该等位基因在麻风患者中增加了875.00%;rs149308743的风险等位基因为T,该等位基因在麻风患者中的基因频率为0.0055,在正常对照中的基因频率为0.0006,与正常对照相比,该等位基因在麻风患者中增加了816.67%;rs76418789的风险等位基因为A,该等位基因在麻风患者中的基因频率为0.0610,在正常对照中的基因频率为0.0432,与正常对照相比,该等位基因在麻风患者中增加了41.20%;rs146466242的风险等位基因为A,该等位基因在麻风患者中的基因频率为0.0558,在正常对照中的基因频率为0.0354,与正常对照相比,该等位基因在麻风患者中增加了57.63%;rs55882956的风险等位基因为A,该等位基因在麻风患者中的基因频率为0.0529,在正常对照中的基因频率为0.0363,与正常对照相比,该等位基因在麻风患者中增加了45.73%;rs780668的风险等位基因为T,该等位基因在麻风患者中的基因频率为0.4648,在正常对照中的基因频率为0.4213,与正常对照相比,该等位基因在麻风患者中增加了10.33%;rs181206的风险等位基因为A,该等位基因在麻风患者中的基因频率为0.8829,在正常对照中的基因频率为0.8503,与正常对照相比,该等位基因在麻风患者中增加了3.83%。
实验结果表明,rs145562243、rs149308743、rs76418789、rs146466242、rs55882956、rs780668和rs181206的多态性或基因型或等位基因频率可用于麻风患者的筛查。
另外,通过对样本中年龄和性别信息进行联合检验,分析了年龄和性别比例的影响。两个常见突变和三个低频突变SNPs中的(年龄和性别)未调整和调整的ORs非常相似(表7),揭示了这些SNPs的关联性分析中,性别和年龄有较小的作用。
表7、性别和年龄对两个常见突变和三个低频突变SNP影响的分析结果
次等位基因/主等位基因;
OR,OR根据次等为基因计算;
(f)指固定效应模型。
<110> 山东省皮肤病性病防治研究所
<160> 22
<170> PatentIn version 3.5
<210> 1
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 1
acgttggatg accactccca gaggccatca 30
<210> 2
<211> 29
<212> DNA
<213> 人工序列
<220>
<223>
<400> 2
acgttggatg ttcccagatc ccaccacag 29
<210> 3
<211> 17
<212> DNA
<213> 人工序列
<220>
<223>
<400> 3
ttcaccacag cctcgcc 17
<210> 4
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 4
acgttggatg cctgcggtag ttctcaaaac 30
<210> 5
<211> 29
<212> DNA
<213> 人工序列
<220>
<223>
<400> 5
acgttggatg ttcccccttc tccaggacg 29
<210> 6
<211> 20
<212> DNA
<213> 人工序列
<220>
<223>
<400> 6
gctcaaaact ctctttgagg 20
<210> 7
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 7
acgttggatg tcaggcaaca tgacttgcac 30
<210> 8
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 8
acgttggatg gaggaagtga cctacctctt 30
<210> 9
<211> 18
<212> DNA
<213> 人工序列
<220>
<223>
<400> 9
ctatgtaggt gagcttcc 18
<210> 10
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 10
acgttggatg atcttccaag ccatgggcac 30
<210> 11
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 11
acgttggatg tggtgacaga gtacgtggag 30
<210> 12
<211> 20
<212> DNA
<213> 人工序列
<220>
<223>
<400> 12
atgtttggct gcggagggag 20
<210> 13
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 13
acgttggatg gccatcttca tggtgataac 30
<210> 14
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 14
acgttggatg tgaggatcac catgcagaca 30
<210> 15
<211> 16
<212> DNA
<213> 人工序列
<220>
<223>
<400> 15
gtgaaggtgg acactt 16
<210> 16
<211> 28
<212> DNA
<213> 人工序列
<220>
<223>
<400> 16
acgttggatg ccctgggtcc ccagccct 28
<210> 17
<211> 30
<212> DNA
<213> 人工序列
<220>
<223>
<400> 17
acgttggatg gagcgtctct gcttcatctc 30
<210> 18
<211> 15
<212> DNA
<213> 人工序列
<220>
<223>
<400> 18
agcccttcca tgccc 15
<210> 19
<211> 25
<212> DNA
<213> 人工序列
<220>
<223>
<400> 19
ccacataaac ctgggtcctt attaa 25
<210> 20
<211> 29
<212> DNA
<213> 人工序列
<220>
<223>
<400> 20
ggaaagatct gatatctgta aagcaagtg 29
<210> 21
<211> 16
<212> DNA
<213> 人工序列
<220>
<223>
<400> 21
cttggatgat ctttac 16
<210> 22
<211> 16
<212> DNA
<213> 人工序列
<220>
<223>
<400> 22
cttggatgat cttaac 16
- 还没有人留言评论。精彩留言会获得点赞!
- 一种胞苷脱氨酶基因单核苷酸多态性检测试剂盒的制作方法
- 基因单核苷酸多态性位点快速检测试剂盒的制作方法
- 一种基于黄牛Angptl8基因单核苷酸多态性的分子育种方法
- 肉鸭otxr基因单核苷酸多态性及其检测方法和应用
- 高血压易感基因SCN7A单核苷酸多态性位点rs7565062的检测试剂盒的制作方法
- 一种黄牛PPARβ基因单核苷酸多态性的检测方法及分子育种方法
- 一种检测黄牛Leptin基因单核苷酸多态性的方法
- 人PLIN1基因rs2289487位点多态性检测方法及试剂盒的制作方法
- 人PON1基因rs854560位点多态性检测方法及试剂盒的制作方法
- 测定人TERT基因rs4975605位点多态性的方法及试剂盒的制作方法
- CYP2C9*3基因多态性快速检测的引物、分子信标、试剂盒及其检测方法与流程
- 一种单核苷酸多态性位点在辅助鉴定大豆花叶病毒抗性中的应用的制造方法与工艺
- DHFR基因多态性检测体系及其试剂盒的制造方法与工艺
- ERCC1基因多态性检测体系及其试剂盒的制造方法与工艺
- 一种判定中国人群rs125055单核苷酸多态性与儿童IBD之间的相关性的方法与制造工艺
- 黄牛ADNCR基因单核苷酸多态性的四引物扩增受阻突变体系PCR检测方法及其应用与制造工艺
- 使用PNA探针的熔解曲线分析、使用熔解曲线分析用于分析核苷酸多态性的方法和试剂盒与制造工艺
- 人KRAS中单核苷酸多态性的检测的制造方法与工艺
- 一种InDel位点基因型分型的方法与制造工艺
- 单核苷酸多态性rs145562243在筛查麻风患者中的应用的制造方法与工艺
- 一种用于评估皮肤防御情况的引物和探针及试剂盒的制作方法
- 一种用于评估皮肤防晒情况的引物和探针及试剂盒的制作方法
- 一种用于评估皮肤抗皱情况的引物和探针及试剂盒的制作方法
- 人PLIN1基因rs2289487位点多态性检测方法及试剂盒的制作方法
- 测定人NEFM基因rs12515位点多态性的方法及试剂盒的制作方法
- 一种人TERF1基因rs3863242位点多态性检测技术的制作方法
- 测定人CCNH基因rs3093816位点多态性的方法及试剂盒的制作方法
- 测定人NEFL基因rs2979704位点多态性的方法及试剂盒的制作方法
- 测定人PON1基因rs854560位点多态性的方法及试剂盒的制作方法
- 测定人PON1基因rs662位点多态性的方法及试剂盒的制作方法
- CYP2C9*3基因多态性快速检测的引物、分子信标、试剂盒及其检测方法与流程
- 一种单核苷酸多态性位点在辅助鉴定大豆花叶病毒抗性中的应用的制造方法与工艺
- DHFR基因多态性检测体系及其试剂盒的制造方法与工艺
- ERCC1基因多态性检测体系及其试剂盒的制造方法与工艺
- 一种判定中国人群rs125055单核苷酸多态性与儿童IBD之间的相关性的方法与制造工艺
- 黄牛ADNCR基因单核苷酸多态性的四引物扩增受阻突变体系PCR检测方法及其应用与制造工艺
- 使用PNA探针的熔解曲线分析、使用熔解曲线分析用于分析核苷酸多态性的方法和试剂盒与制造工艺
- 人KRAS中单核苷酸多态性的检测的制造方法与工艺
- 一种InDel位点基因型分型的方法与制造工艺
- 单核苷酸多态性rs145562243在筛查麻风患者中的应用的制造方法与工艺
- 用于检测人类CYP2D6基因多态性的核酸、试剂盒及方法与流程
- 单核苷酸多态性位点rs2523607在筛查疱疹样皮炎患者中的应用的制作方法与工艺
- 核苷酸多态性检测方法与流程
- 单核苷酸多态性rs146466242在筛查麻风患者中的应用的制作方法与工艺
- 基于信号谱差异的混合样本单核苷酸多态性的检测方法与流程
- 一种检测牛PCAF基因单核苷酸多态性的RFLP方法及试剂盒与流程
- 秦川牛microRNA‑320a‑1基因单核苷酸多态性的检测方法及其应用与流程
- 单核苷酸多态性rs76418789在筛查麻风患者中的应用的制作方法与工艺
- 判定rs4676410和rs2531875单核苷酸多态性与AS之间相关性的方法与流程
- 一种可视化检测基因序列中单核苷酸多态性位点的反向探针、试剂盒及其检测方法与流程