ATM基因突变体及其应用的制作方法
本发明涉及
技术领域:
。具体而言,本发明涉及ATM基因突变体及其应用。
背景技术:
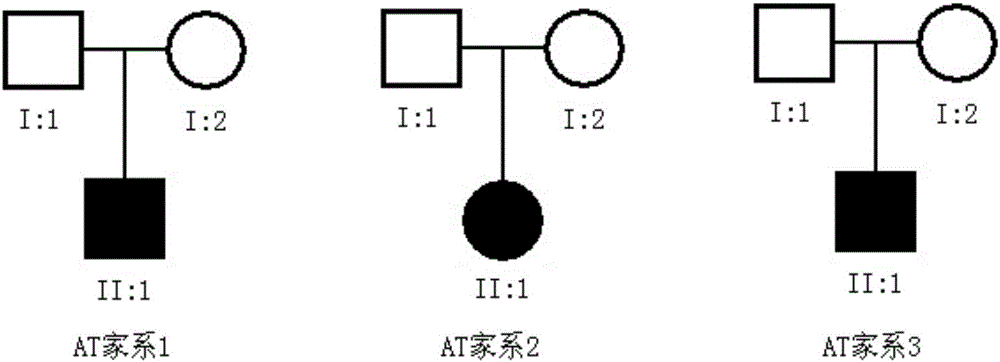
:共济失调毛细血管扩张症(ataxia-telangiectasia,AT)是一种罕见的常染色体隐性遗传(autosomalrecessiveinherited,AR)病,又叫Louis-Bar综合征,于1941年由Louis-Bar首先报道。AT发病率约1/4万~1/10万,多于儿童期起病,临床主要表现为进行性发展的小脑性共济失调,眼球结膜和面部皮肤的毛细血管扩张,反复发作的呼吸道感染;同时还具有对射线的杀伤作用异常敏感,染色体不稳定性,易患恶性肿瘤,免疫缺陷和抗射线的DNA复制合成等特征。Savitsky和Uziel等率先克隆AT的疾病基因(ATM),并将其定位于11q22.3。ATM是AT唯一的致病基因,全长约150kb,而编码序列只有12kb,共有66个外显子,编码一个有3056个氨基酸残基,分子质量为350000的蛋白质。ATM基因产物ATM编码蛋白作为直接感受DNA双链断裂(DSBs)损伤信号的上游分子,以其激酶活性,催化多种重要功能底物蛋白的磷酸化,使受损的DNA停止于细胞周期检测点并对其进行修复,对维持染色体的稳定性起重要作用。ATM基因的克隆为AT的基因诊断和症状前诊断奠定了基础,并且很大程度上解决了该病临床诊断困难的问题。ATM蛋白在胎儿和成人组织内均有广泛表达,其功能域包括磷酯酰肌醇3-激酶(phosphoinositide-3kinase,PI3K)、Rad3、亮氨酸拉链(leucinezipper,LZ)、局部的连接区域(focaladhesiontarget,FAT)、局部的连接区域C端(FATC)等。PI3K蛋白家族成员和具有Rad3结构域的蛋白家族成员参与了激活细胞周期关卡,控制端粒长度和应答DNA损伤等重要的生物学过程。AT最显著的病理学表现是基因组的不稳定性,主要反应在高频率的染色体断裂,自发染色体末端融合和染色体内同源重组及染色体易位,以及体内、外染色体自发畸变率和辐射诱发染色体畸变率的异常增加。作为DNA损伤信号传导通路中最早的传感和中枢调控基因,ATM编码的ATM蛋白在电离辐射的诱导下被激活,并磷酸化其下游蛋白,通过调控细胞周期关卡、DNA损伤修复、细胞凋亡等维持基因组稳定性。AT细胞由于ATM基因突变,缺失了ATM蛋白,丧失了对下游基因的调控作用,使受损的DNA的合成受抑,阻碍DNA的修复过程,从而导致染色体的断裂和基因组不稳定。ATM基因的突变具有极高的异质性,突变方式和突变检测都极为复杂。到目前为止,国外已经报道了400余种ATM基因突变,绝大多数AT患者为复合性杂合突变,突变形式有错义突变、无义突变、剪切位点突变、小片段插入突变、小片段缺失突变、大片段缺失和同义突变等,突变位点遍布基因全长,无突变热点。因而,目前对共济失调毛细血管扩张症的致病基因ATM突变基因的研究仍有待深入。技术实现要素:本发明旨在至少在一定程度上解决上述技术问题之一。为此,本发明的一个目的在于提出一种能够有效筛选易患共济失调毛细血管扩张症的生物样品的方法。本发明是基于发明人的下列工作完成的:发明人通过高通量外显子组测序联合候选基因突变验证的方法确定了共济失调毛细血管扩张症新的致病基因突变位点(ATM基因的c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del突变)。根据本发明的第一方面,本发明提出了一种分离的编码ATM基因突变体的核酸。根据本发明的实施例,所述核酸与SEQIDNO:1相比,具有选自下列的至少一种突变:c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)。即相对于野生型ATM基因,本发明的ATM基因具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)的至少一种。根据本发明的实施例,发明人确定了ATM基因的新突变体,该突变体与共济失调毛细血管扩张症的发病密切相关,从而通过检测该新突变体在生物样品中是否存在,可以有效地检测生物样品是否易患共济失调毛细血管扩张症。根据本发明的第二个方面,本发明提出了一种分离的多肽,该多肽与SEQIDNO:2相比,具有选自下列的至少一种突变:p.Cys1899X、p.Glu2950fs、p.Trp1026Cys、p.Val2662del、p.Ile159fs和p.2951_2995del,通过检测生物样品中是否表达该多肽,可以有效地检测生物样品是否易患共济失调毛细血管扩张症。根据本发明的实施例,该多肽是由上述核酸编码的。根据本发明的地三个方面,本发明提出了一种筛选易患共济失调毛细血管扩张症的生物样品的方法,该方法包括以下步骤:从所述生物样品提取核酸样本;确定所述核酸样本的核酸序列;所述核酸样本的核酸序列与SEQIDNO:1相比,具有选自c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)的至少一种突变是所述生物样品易患共济失调毛细血管扩张症的指示,任选地,所述生物样品为选自人体血液,任选地,所述核酸样本为全基因组DNA,任选地,所述共济失调毛细血管扩张症是常染色体隐性遗传疾病。通过根据本发明实施例的筛选易感共济失调毛细血管扩张症的生物样品的方法,可以有效地筛选易感共济失调毛细血管扩张症的生物样品。根据本发明的第四方面,本发明提出了一种筛选易患共济失调毛细血管扩张症的生物样品的系统,该系统包括:核酸提取装置,所述核酸提取装置用于从所述生物样品提取核酸样本;核酸序列确定装置,所述核酸序列确定装置与所述核酸提取装置相连,用于对所述核酸样本进行分析,以便确定所述核酸样本的核酸序列;判断装置,所述判断装置与所述核酸序列确定装置相连,以便基于所述核酸样本的核酸序列与SEQIDNO:1相比,是否具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)的至少一种突变,判断所述生物样品是否易患共济失调毛细血管扩张症;任选地,所述共济失调毛细血管扩张症是常染色体隐性遗传疾病。利用该系统,能够有效地实施前述筛选易感共济失调毛细血管扩张症的生物样品的方法,从而可以有效地筛选易感共济失调毛细血管扩张症的生物样品。根据本发明的第五方面,本发明提出了一种用于筛选易患共济失调毛细血管扩张症的生物样品的试剂盒,该试剂盒含有:适于检测ATM基因突变体的试剂,其中与SEQIDNO:1相比,所述ATM基因突变体具有选自下列的至少一种突变:c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del),任选地,所述试剂为核酸探针或引物,任选地,所述核酸探针或引物具有如SEQIDNO:7-16所示的核苷酸序列,任选地,所述是常染色体隐性遗传疾病。根据本发明的第六方面,本发明还提出了一种构建体。根据本发明的实施例,该构建体包含前面所述的分离的编码ATM基因突变体的核酸。需要说明的是,“构建体包含前面所述的分离的编码ATM基因突变体的核酸”表示,本发明的构建体包含与SEQIDNO:1相比具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)至少一种突变。由此,利用本发明的构建体转化受体细胞获得的重组细胞,能够有效地用作共济失调毛细血管扩张症相关研究的模型。根据本发明的第七方面,本发明还提出了一种重组细胞。根据本发明的实施例,该重组细胞是通过前面所述的构建体转化受体细胞而获得的。根据本发明的一些实施例,本发明的重组细胞,能够有效地用作共济失调毛细血管扩张症相关研究的模型。对于本发明中所述核酸,本领域技术人员应当理解,实际包括互补双链的任意一条,或者两条。为了方便,在本发明的实施例中,虽然多数情况下只给出了一条链,但实际上也公开了与之互补的另一条链。例如,提及SEQIDNO:1,实际包括其互补序列。本领域技术人员还可以理解,利用一条链可以检测另一条链,反之亦然。本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。附图说明本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:图1:显示了根据本发明一个实施例的筛选易患共济失调毛细血管扩张症的生物样品的系统及其组成部分的示意图,其中,A为根据本发明实施例的筛选易患共济失调毛细血管扩张症患者的生物样品的系统的示意图,B为根据本发明实施例的核酸提取装置的示意图,C为根据本发明实施例的核酸序列确定装置的示意图。图2:显示了根据本发明一个实施例的共济失调毛细血管扩张症患者的家系图谱。图3:显示了根据本发明一个实施例的AT家系1的ATM基因突变体的Sanger法测序结果。图4:显示了根据本发明一个实施例的AT家系2的ATM基因突变体的Sanger法测序结果。图5:显示了根据本发明一个实施例的AT家系3的ATM基因突变体的Sanger法测序结果。图6:显示了根据本发明一个实施例的AT家系1的ATM基因突变体的QPCR的结果图。图7:显示了根据本发明一个实施例的AT家系2的ATM基因突变体的Sanger法测序结果。具体实施方式下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。ATM基因突变体根据本发明的第一方面,本发明提出了一种分离的编码ATM基因突变体的核酸。根据本发明的实施例,所述核酸与SEQIDNO:1相比,具有选自下列的至少一种突变:c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)。即相对于野生型ATM基因,本发明的ATM基因具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)突变的至少一种。根据本发明的实施例,发明人确定了ATM基因的新突变体,该突变体与共济失调毛细血管扩张症的发病密切相关,从而通过检测该新突变体在生物样品中是否存在,可以有效地检测生物样品是否易患共济失调毛细血管扩张症。在本文中所使用的表达方式“编码ATM突变体的核酸”,是指与编码ATM突变体的基因相对应的核酸物质,即核酸的类型不受特别限制,可以是任何包含与ATM突变体的编码基因相对应的脱氧核糖核苷酸和/或核糖核苷酸的聚合物,包括但不限于DNA、RNA或cDNA。根据本发明的一个具体示例,前面所述的编码ATM突变体的核酸为DNA。根据本发明的实施例,发明人确定了ATM基因的新突变体,这些新突变体与共济失调毛细血管扩张症的发病密切相关,从而通过检测该新突变体在生物样品中是否存在,可以有效地检测生物样品是否易患共济失调毛细血管扩张症,也可以通过检测这些突变体在生物体中是否存在,可以有效地预测生物体是否易患共济失调毛细血管扩张症。该编码ATM突变体的核酸,是本申请的发明人通过高通量外显子组测序联合候选基因突变验证的方法确定的共济失调毛细血管扩张症的致病基因上的新突变。该突变位点在现有技术中并未被提到。其中,野生型ATM基因的cDNA具有如下所示的核苷酸序列:ATGAGTCTAGTACTTAATGATCTGCTTATCTGCTGCCGTCAACTAGAACATGATAGAGCTACAGAACGAAAGAAAGAAGTTGAGAAATTTAAGCGCCTGATTCGAGATCCTGAAACAATTAAACATCTAGATCGGCATTCAGATTCCAAACAAGGAAAATATTTGAATTGGGATGCTGTTTTTAGATTTTTACAGAAATATATTCAGAAAGAAACAGAATGTCTGAGAATAGCAAAACCAAATGTATCAGCCTCAACACAAGCCTCCAGGCAGAAAAAGATGCAGGAAATCAGTAGTTTGGTCAAATACTTCATCAAATGTGCAAACAGAAGAGCACCTAGGCTAAAATGTCAAGAACTCTTAAATTATATCATGGATACAGTGAAAGATTCATCTAATGGTGCTATTTACGGAGCTGATTGTAGCAACATACTACTCAAAGACATTCTTTCTGTGAGAAAATACTGGTGTGAAATATCTCAGCAACAGTGGTTAGAATTGTTCTCTGTGTACTTCAGGCTCTATCTGAAACCTTCACAAGATGTTCATAGAGTTTTAGTGGCTAGAATAATTCATGCTGTTACCAAAGGATGCTGTTCTCAGACTGACGGATTAAATTCCAAATTTTTGGACTTTTTTTCCAAGGCTATTCAGTGTGCGAGACAAGAAAAGAGCTCTTCAGGTCTAAATCATATCTTAGCAGCTCTTACTATCTTCCTCAAGACTTTGGCTGTCAACTTTCGAATTCGAGTGTGTGAATTAGGAGATGAAATTCTTCCCACTTTGCTTTATATTTGGACTCAACATAGGCTTAATGATTCTTTAAAAGAAGTCATTATTGAATTATTTCAACTGCAAATTTATATCCATCATCCGAAAGGAGCCAAAACCCAAGAAAAAGGTGCTTATGAATCAACAAAATGGAGAAGTATTTTATACAACTTATATGATCTGCTAGTGAATGAGATAAGTCATATAGGAAGTAGAGGAAAGTATTCTTCAGGATTTCGTAATATTGCCGTCAAAGAAAATTTGATTGAATTGATGGCAGATATCTGTCACCAGGTTTTTAATGAAGATACCAGATCCTTGGAGATTTCTCAATCTTACACTACTACACAAAGAGAATCTAGTGATTACAGTGTCCCTTGCAAAAGGAAGAAAATAGAACTAGGCTGGGAAGTAATAAAAGATCACCTTCAGAAGTCACAGAATGATTTTGATCTTGTGCCTTGGCTACAGATTGCAACCCAATTAATATCAAAGTATCCTGCAAGTTTACCTAACTGTGAGCTGTCTCCATTACTGATGATACTATCTCAGCTTCTACCCCAACAGCGACATGGGGAACGTACACCATATGTGTTACGATGCCTTACGGAAGTTGCATTGTGTCAAGACAAGAGGTCAAACCTAGAAAGCTCACAAAAGTCAGATTTATTAAAACTCTGGAATAAAATTTGGTGTATTACCTTTCGTGGTATAAGTTCTGAGCAAATACAAGCTGAAAACTTTGGCTTACTTGGAGCCATAATTCAGGGTAGTTTAGTTGAGGTTGACAGAGAATTCTGGAAGTTATTTACTGGGTCAGCCTGCAGACCTTCATGTCCTGCAGTATGCTGTTTGACTTTGGCACTGACCACCAGTATAGTTCCAGGAACGGTAAAAATGGGAATAGAGCAAAATATGTGTGAAGTAAATAGAAGCTTTTCTTTAAAGGAATCAATAATGAAATGGCTCTTATTCTATCAGTTAGAGGGTGACTTAGAAAATAGCACAGAAGTGCCTCCAATTCTTCACAGTAATTTTCCTCATCTTGTACTGGAGAAAATTCTTGTGAGTCTCACTATGAAAAACTGTAAAGCTGCAATGAATTTTTTCCAAAGCGTGCCAGAATGTGAACACCACCAAAAAGATAAAGAAGAACTTTCATTCTCAGAAGTAGAAGAACTATTTCTTCAGACAACTTTTGACAAGATGGACTTTTTAACCATTGTGAGAGAATGTGGTATAGAAAAGCACCAGTCCAGTATTGGCTTCTCTGTCCACCAGAATCTCAAGGAATCACTGGATCGCTGTCTTCTGGGATTATCAGAACAGCTTCTGAATAATTACTCATCTGAGATTACAAATTCAGAAACTCTTGTCCGGTGTTCACGTCTTTTGGTGGGTGTCCTTGGCTGCTACTGTTACATGGGTGTAATAGCTGAAGAGGAAGCATATAAGTCAGAATTATTCCAGAAAGCCAAGTCTCTAATGCAATGTGCAGGAGAAAGTATCACTCTGTTTAAAAATAAGACAAATGAGGAATTCAGAATTGGTTCCTTGAGAAATATGATGCAGCTATGTACACGTTGCTTGAGCAACTGTACCAAGAAGAGTCCAAATAAGATTGCATCTGGCTTTTTCCTGCGATTGTTAACATCAAAGCTAATGAATGACATTGCAGATATTTGTAAAAGTTTAGCATCCTTCATCAAAAAGCCATTTGACCGTGGAGAAGTAGAATCAATGGAAGATGATACTAATGGAAATCTAATGGAGGTGGAGGATCAGTCATCCATGAATCTATTTAACGATTACCCTGATAGTAGTGTTAGTGATGCAAACGAACCTGGAGAGAGCCAAAGTACCATAGGTGCCATTAATCCTTTAGCTGAAGAATATCTGTCAAAGCAAGATCTACTTTTCTTAGACATGCTCAAGTTCTTGTGTTTGTGTGTAACTACTGCTCAGACCAATACTGTGTCCTTTAGGGCAGCTGATATTCGGAGGAAATTGTTAATGTTAATTGATTCTAGCACGCTAGAACCTACCAAATCCCTCCACCTGCATATGTATCTAATGCTTTTAAAGGAGCTTCCTGGAGAAGAGTACCCCTTGCCAATGGAAGATGTTCTTGAACTTCTGAAACCACTATCCAATGTGTGTTCTTTGTATCGTCGTGACCAAGATGTTTGTAAAACTATTTTAAACCATGTCCTTCATGTAGTGAAAAACCTAGGTCAAAGCAATATGGACTCTGAGAACACAAGGGATGCTCAAGGACAGTTTCTTACAGTAATTGGAGCATTTTGGCATCTAACAAAGGAGAGGAAATATATATTCTCTGTAAGAATGGCCCTAGTAAATTGCCTTAAAACTTTGCTTGAGGCTGATCCTTATTCAAAATGGGCCATTCTTAATGTAATGGGAAAAGACTTTCCTGTAAATGAAGTATTTACACAATTTCTTGCTGACAATCATCACCAAGTTCGCATGTTGGCTGCAGAGTCAATCAATAGATTGTTCCAGGACACGAAGGGAGATTCTTCCAGGTTACTGAAAGCACTTCCTTTGAAGCTTCAGCAAACAGCTTTTGAAAATGCATACTTGAAAGCTCAGGAAGGAATGAGAGAAATGTCCCATAGTGCTGAGAACCCTGAAACTTTGGATGAAATTTATAATAGAAAATCTGTTTTACTGACGTTGATAGCTGTGGTTTTATCCTGTAGCCCTATCTGCGAAAAACAGGCTTTGTTTGCCCTGTGTAAATCTGTGAAAGAGAATGGATTAGAACCTCACCTTGTGAAAAAGGTTTTAGAGAAAGTTTCTGAAACTTTTGGATATAGACGTTTAGAAGACTTTATGGCATCTCATTTAGATTATCTGGTTTTGGAATGGCTAAATCTTCAAGATACTGAATACAACTTATCTTCTTTTCCTTTTATTTTATTAAACTACACAAATATTGAGGATTTCTATAGATCTTGTTATAAGGTTTTGATTCCACATCTGGTGATTAGAAGTCATTTTGATGAGGTGAAGTCCATTGCTAATCAGATTCAAGAGGACTGGAAAAGTCTTCTAACAGACTGCTTTCCAAAGATTCTTGTAAATATTCTTCCTTATTTTGCCTATGAGGGTACCAGAGACAGTGGGATGGCACAGCAAAGAGAGACTGCTACCAAGGTCTATGATATGCTTAAAAGTGAAAACTTATTGGGAAAACAGATTGATCACTTATTCATTAGTAATTTACCAGAGATTGTGGTGGAGTTATTGATGACGTTACATGAGCCAGCAAATTCTAGTGCCAGTCAGAGCACTGACCTCTGTGACTTTTCAGGGGATTTGGATCCTGCTCCTAATCCACCTCATTTTCCATCGCATGTGATTAAAGCAACATTTGCCTATATCAGCAATTGTCATAAAACCAAGTTAAAAAGCATTTTAGAAATTCTTTCCAAAAGCCCTGATTCCTATCAGAAAATTCTTCTTGCCATATGTGAGCAAGCAGCTGAAACAAATAATGTTTATAAGAAGCACAGAATTCTTAAAATATATCACCTGTTTGTTAGTTTATTACTGAAAGATATAAAAAGTGGCTTAGGAGGAGCTTGGGCCTTTGTTCTTCGAGACGTTATTTATACTTTGATTCACTATATCAACCAAAGGCCTTCTTGTATCATGGATGTGTCATTACGTAGCTTCTCCCTTTGTTGTGACTTATTAAGTCAGGTTTGCCAGACAGCCGTGACTTACTGTAAGGATGCTCTAGAAAACCATCTTCATGTTATTGTTGGTACACTTATACCCCTTGTGTATGAGCAGGTGGAGGTTCAGAAACAGGTATTGGACTTGTTGAAATACTTAGTGATAGATAACAAGGATAATGAAAACCTCTATATCACGATTAAGCTTTTAGATCCTTTTCCTGACCATGTTGTTTTTAAGGATTTGCGTATTACTCAGCAAAAAATCAAATACAGTAGAGGACCCTTTTCACTCTTGGAGGAAATTAACCATTTTCTCTCAGTAAGTGTTTATGATGCACTTCCATTGACAAGACTTGAAGGACTAAAGGATCTTCGAAGACAACTGGAACTACATAAAGATCAGATGGTGGACATTATGAGAGCTTCTCAGGATAATCCGCAAGATGGGATTATGGTGAAACTAGTTGTCAATTTGTTGCAGTTATCCAAGATGGCAATAAACCACACTGGTGAAAAAGAAGTTCTAGAGGCTGTTGGAAGCTGCTTGGGAGAAGTGGGTCCTATAGATTTCTCTACCATAGCTATACAACATAGTAAAGATGCATCTTATACCAAGGCCCTTAAGTTATTTGAAGATAAAGAACTTCAGTGGACCTTCATAATGCTGACCTACCTGAATAACACACTGGTAGAAGATTGTGTCAAAGTTCGATCAGCAGCTGTTACCTGTTTGAAAAACATTTTAGCCACAAAGACTGGACATAGTTTCTGGGAGATTTATAAGATGACAACAGATCCAATGCTGGCCTATCTACAGCCTTTTAGAACATCAAGAAAAAAGTTTTTAGAAGTACCCAGATTTGACAAAGAAAACCCTTTTGAAGGCCTGGATGATATAAATCTGTGGATTCCTCTAAGTGAAAATCATGACATTTGGATAAAGACACTGACTTGTGCTTTTTTGGACAGTGGAGGCACAAAATGTGAAATTCTTCAATTATTAAAGCCAATGTGTGAAGTGAAAACTGACTTTTGTCAGACTGTACTTCCATACTTGATTCATGATATTTTACTCCAAGATACAAATGAATCATGGAGAAATCTGCTTTCTACACATGTTCAGGGATTTTTCACCAGCTGTCTTCGACACTTCTCGCAAACGAGCCGATCCACAACCCCTGCAAACTTGGATTCAGAGTCAGAGCACTTTTTCCGATGCTGTTTGGATAAAAAATCACAAAGAACAATGCTTGCTGTTGTGGACTACATGAGAAGACAAAAGAGACCTTCTTCAGGAACAATTTTTAATGATGCTTTCTGGCTGGATTTAAATTATCTAGAAGTTGCCAAGGTAGCTCAGTCTTGTGCTGCTCACTTTACAGCTTTACTCTATGCAGAAATCTATGCAGATAAGAAAAGTATGGATGATCAAGAGAAAAGAAGTCTTGCATTTGAAGAAGGAAGCCAGAATACAACTATTTCTAGCTTGAGTGAAAAAAGTAAAGAAGAAACTGGAATAAGTTTACAGGATCTTCTCTTAGAAATCTACAGAAGTATAGGGGAGCCAGATAGTTTGTATGGCTGTGGTGGAGGGAAGATGTTACAACCCATTACTAGACTACGAACATATGAACACGAAGCAATGTGGGGCAAAGCCCTAGTAACATATGACCTCGAAACAGCAATCCCCTCATCAACACGCCAGGCAGGAATCATTCAGGCCTTGCAGAATTTGGGACTCTGCCATATTCTTTCCGTCTATTTAAAAGGATTGGATTATGAAAATAAAGACTGGTGTCCTGAACTAGAAGAACTTCATTACCAAGCAGCATGGAGGAATATGCAGTGGGACCATTGCACTTCCGTCAGCAAAGAAGTAGAAGGAACCAGTTACCATGAATCATTGTACAATGCTCTACAATCTCTAAGAGACAGAGAATTCTCTACATTTTATGAAAGTCTCAAATATGCCAGAGTAAAAGAAGTGGAAGAGATGTGTAAGCGCAGCCTTGAGTCTGTGTATTCGCTCTATCCCACACTTAGCAGGTTGCAGGCCATTGGAGAGCTGGAAAGCATTGGGGAGCTTTTCTCAAGATCAGTCACACATAGACAACTCTCTGAAGTATATATTAAGTGGCAGAAACACTCCCAGCTTCTCAAGGACAGTGATTTTAGTTTTCAGGAGCCTATCATGGCTCTACGCACAGTCATTTTGGAGATCCTGATGGAAAAGGAAATGGACAACTCACAAAGAGAATGTATTAAGGACATTCTCACCAAACACCTTGTAGAACTCTCTATACTGGCCAGAACTTTCAAGAACACTCAGCTCCCTGAAAGGGCAATATTTCAAATTAAACAGTACAATTCAGTTAGCTGTGGAGTCTCTGAGTGGCAGCTGGAAGAAGCACAAGTATTCTGGGCAAAAAAGGAGCAGAGTCTTGCCCTGAGTATTCTCAAGCAAATGATCAAGAAGTTGGATGCCAGCTGTGCAGCGAACAATCCCAGCCTAAAACTTACATACACAGAATGTCTGAGGGTTTGTGGCAACTGGTTAGCAGAAACGTGCTTAGAAAATCCTGCGGTCATCATGCAGACCTATCTAGAAAAGGCAGTAGAAGTTGCTGGAAATTATGATGGAGAAAGTAGTGATGAGCTAAGAAATGGAAAAATGAAGGCATTTCTCTCATTAGCCCGGTTTTCAGATACTCAATACCAAAGAATTGAAAACTACATGAAATCATCGGAATTTGAAAACAAGCAAGCTCTCCTGAAAAGAGCCAAAGAGGAAGTAGGTCTCCTTAGGGAACATAAAATTCAGACAAACAGATACACAGTAAAGGTTCAGCGAGAGCTGGAGTTGGATGAATTAGCCCTGCGTGCACTGAAAGAGGATCGTAAACGCTTCTTATGTAAAGCAGTTGAAAATTATATCAACTGCTTATTAAGTGGAGAAGAACATGATATGTGGGTATTCCGACTTTGTTCCCTCTGGCTTGAAAATTCTGGAGTTTCTGAAGTCAATGGCATGATGAAGAGAGACGGAATGAAGATTCCAACATATAAATTTTTGCCTCTTATGTACCAATTGGCTGCTAGAATGGGGACCAAGATGATGGGAGGCCTAGGATTTCATGAAGTCCTCAATAATCTAATCTCTAGAATTTCAATGGATCACCCCCATCACACTTTGTTTATTATACTGGCCTTAGCAAATGCAAACAGAGATGAATTTCTGACTAAACCAGAGGTAGCCAGAAGAAGCAGAATAACTAAAAATGTGCCTAAACAAAGCTCTCAGCTTGATGAGGATCGAACAGAGGCTGCAAATAGAATAATATGTACTATCAGAAGTAGGAGACCTCAGATGGTCAGAAGTGTTGAGGCACTTTGTGATGCTTATATTATATTAGCAAACTTAGATGCCACTCAGTGGAAGACTCAGAGAAAAGGCATAAATATTCCAGCAGACCAGCCAATTACTAAACTTAAGAATTTAGAAGATGTTGTTGTCCCTACTATGGAAATTAAGGTGGACCACACAGGAGAATATGGAAATCTGGTGACTATACAGTCATTTAAAGCAGAATTTCGCTTAGCAGGAGGTGTAAATTTACCAAAAATAATAGATTGTGTAGGTTCCGATGGCAAGGAGAGGAGACAGCTTGTTAAGGGCCGTGATGACCTGAGACAAGATGCTGTCATGCAACAGGTCTTCCAGATGTGTAATACATTACTGCAGAGAAACACGGAAACTAGGAAGAGGAAATTAACTATCTGTACTTATAAGGTGGTTCCCCTCTCTCAGCGAAGTGGTGTTCTTGAATGGTGCACAGGAACTGTCCCCATTGGTGAATTTCTTGTTAACAATGAAGATGGTGCTCATAAAAGATACAGGCCAAATGATTTCAGTGCCTTTCAGTGCCAAAAGAAAATGATGGAGGTGCAAAAAAAGTCTTTTGAAGAGAAATATGAAGTCTTCATGGATGTTTGCCAAAATTTTCAACCAGTTTTCCGTTACTTCTGCATGGAAAAATTCTTGGATCCAGCTATTTGGTTTGAGAAGCGATTGGCTTATACGCGCAGTGTAGCTACTTCTTCTATTGTTGGTTACATACTTGGACTTGGTGATAGACATGTACAGAATATCTTGATAAATGAGCAGTCAGCAGAACTTGTACATATAGATCTAGGTGTTGCTTTTGAACAGGGCAAAATCCTTCCTACTCCTGAGACAGTTCCTTTTAGACTCACCAGAGATATTGTGGATGGCATGGGCATTACGGGTGTTGAAGGTGTCTTCAGAAGATGCTGTGAGAAAACCATGGAAGTGATGAGAAACTCTCAGGAAACTCTGTTAACCATTGTAGAGGTCCTTCTATATGATCCACTCTTTGACTGGACCATGAATCCTTTGAAAGCTTTGTATTTACAGCAGAGGCCGGAAGATGAAACTGAGCTTCACCCTACTCTGAATGCAGATGACCAAGAATGCAAACGAAATCTCAGTGATATTGACCAGAGTTTCAACAAAGTAGCTGAACGTGTCTTAATGAGACTACAAGAGAAACTGAAAGGAGTGGAAGAAGGCACTGTGCTCAGTGTTGGTGGACAAGTGAATTTGCTCATACAGCAGGCCATAGACCCCAAAAATCTCAGCCGACTTTTCCCAGGATGGAAAGCTTGGGTGTGA(SEQIDNO:1),其编码的蛋白质具有如下所示的氨基酸序列:MSLVLNDLLICCRQLEHDRATERKKEVEKFKRLIRDPETIKHLDRHSDSKQGKYLNWDAVFRFLQKYIQKETECLRIAKPNVSASTQASRQKKMQEISSLVKYFIKCANRRAPRLKCQELLNYIMDTVKDSSNGAIYGADCSNILLKDILSVRKYWCEISQQQWLELFSVYFRLYLKPSQDVHRVLVARIIHAVTKGCCSQTDGLNSKFLDFFSKAIQCARQEKSSSGLNHILAALTIFLKTLAVNFRIRVCELGDEILPTLLYIWTQHRLNDSLKEVIIELFQLQIYIHHPKGAKTQEKGAYESTKWRSILYNLYDLLVNEISHIGSRGKYSSGFRNIAVKENLIELMADICHQVFNEDTRSLEISQSYTTTQRESSDYSVPCKRKKIELGWEVIKDHLQKSQNDFDLVPWLQIATQLISKYPASLPNCELSPLLMILSQLLPQQRHGERTPYVLRCLTEVALCQDKRSNLESSQKSDLLKLWNKIWCITFRGISSEQIQAENFGLLGAIIQGSLVEVDREFWKLFTGSACRPSCPAVCCLTLALTTSIVPGTVKMGIEQNMCEVNRSFSLKESIMKWLLFYQLEGDLENSTEVPPILHSNFPHLVLEKILVSLTMKNCKAAMNFFQSVPECEHHQKDKEELSFSEVEELFLQTTFDKMDFLTIVRECGIEKHQSSIGFSVHQNLKESLDRCLLGLSEQLLNNYSSEITNSETLVRCSRLLVGVLGCYCYMGVIAEEEAYKSELFQKAKSLMQCAGESITLFKNKTNEEFRIGSLRNMMQLCTRCLSNCTKKSPNKIASGFFLRLLTSKLMNDIADICKSLASFIKKPFDRGEVESMEDDTNGNLMEVEDQSSMNLFNDYPDSSVSDANEPGESQSTIGAINPLAEEYLSKQDLLFLDMLKFLCLCVTTAQTNTVSFRAADIRRKLLMLIDSSTLEPTKSLHLHMYLMLLKELPGEEYPLPMEDVLELLKPLSNVCSLYRRDQDVCKTILNHVLHVVKNLGQSNMDSENTRDAQGQFLTVIGAFWHLTKERKYIFSVRMALVNCLKTLLEADPYSKWAILNVMGKDFPVNEVFTQFLADNHHQVRMLAAESINRLFQDTKGDSSRLLKALPLKLQQTAFENAYLKAQEGMREMSHSAENPETLDEIYNRKSVLLTLIAVVLSCSPICEKQALFALCKSVKENGLEPHLVKKVLEKVSETFGYRRLEDFMASHLDYLVLEWLNLQDTEYNLSSFPFILLNYTNIEDFYRSCYKVLIPHLVIRSHFDEVKSIANQIQEDWKSLLTDCFPKILVNILPYFAYEGTRDSGMAQQRETATKVYDMLKSENLLGKQIDHLFISNLPEIVVELLMTLHEPANSSASQSTDLCDFSGDLDPAPNPPHFPSHVIKATFAYISNCHKTKLKSILEILSKSPDSYQKILLAICEQAAETNNVYKKHRILKIYHLFVSLLLKDIKSGLGGAWAFVLRDVIYTLIHYINQRPSCIMDVSLRSFSLCCDLLSQVCQTAVTYCKDALENHLHVIVGTLIPLVYEQVEVQKQVLDLLKYLVIDNKDNENLYITIKLLDPFPDHVVFKDLRITQQKIKYSRGPFSLLEEINHFLSVSVYDALPLTRLEGLKDLRRQLELHKDQMVDIMRASQDNPQDGIMVKLVVNLLQLSKMAINHTGEKEVLEAVGSCLGEVGPIDFSTIAIQHSKDASYTKALKLFEDKELQWTFIMLTYLNNTLVEDCVKVRSAAVTCLKNILATKTGHSFWEIYKMTTDPMLAYLQPFRTSRKKFLEVPRFDKENPFEGLDDINLWIPLSENHDIWIKTLTCAFLDSGGTKCEILQLLKPMCEVKTDFCQTVLPYLIHDILLQDTNESWRNLLSTHVQGFFTSCLRHFSQTSRSTTPANLDSESEHFFRCCLDKKSQRTMLAVVDYMRRQKRPSSGTIFNDAFWLDLNYLEVAKVAQSCAAHFTALLYAEIYADKKSMDDQEKRSLAFEEGSQNTTISSLSEKSKEETGISLQDLLLEIYRSIGEPDSLYGCGGGKMLQPITRLRTYEHEAMWGKALVTYDLETAIPSSTRQAGIIQALQNLGLCHILSVYLKGLDYENKDWCPELEELHYQAAWRNMQWDHCTSVSKEVEGTSYHESLYNALQSLRDREFSTFYESLKYARVKEVEEMCKRSLESVYSLYPTLSRLQAIGELESIGELFSRSVTHRQLSEVYIKWQKHSQLLKDSDFSFQEPIMALRTVILEILMEKEMDNSQRECIKDILTKHLVELSILARTFKNTQLPERAIFQIKQYNSVSCGVSEWQLEEAQVFWAKKEQSLALSILKQMIKKLDASCAANNPSLKLTYTECLRVCGNWLAETCLENPAVIMQTYLEKAVEVAGNYDGESSDELRNGKMKAFLSLARFSDTQYQRIENYMKSSEFENKQALLKRAKEEVGLLREHKIQTNRYTVKVQRELELDELALRALKEDRKRFLCKAVENYINCLLSGEEHDMWVFRLCSLWLENSGVSEVNGMMKRDGMKIPTYKFLPLMYQLAARMGTKMMGGLGFHEVLNNLISRISMDHPHHTLFIILALANANRDEFLTKPEVARRSRITKNVPKQSSQLDEDRTEAANRIICTIRSRRPQMVRSVEALCDAYIILANLDATQWKTQRKGINIPADQPITKLKNLEDVVVPTMEIKVDHTGEYGNLVTIQSFKAEFRLAGGVNLPKIIDCVGSDGKERRQLVKGRDDLRQDAVMQQVFQMCNTLLQRNTETRKRKLTICTYKVVPLSQRSGVLEWCTGTVPIGEFLVNNEDGAHKRYRPNDFSAFQCQKKMMEVQKKSFEEKYEVFMDVCQNFQPVFRYFCMEKFLDPAIWFEKRLAYTRSVATSSIVGYILGLGDRHVQNILINEQSAELVHIDLGVAFEQGKILPTPETVPFRLTRDIVDGMGITGVEGVFRRCCEKTMEVMRNSQETLLTIVEVLLYDPLFDWTMNPLKALYLQQRPEDETELHPTLNADDQECKRNLSDIDQSFNKVAERVLMRLQEKLKGVEEGTVLSVGGQVNLLIQQAIDPKNLSRLFPGWKAWV(SEQIDNO:2)。与野生型ATM基因的cDNA相比,c.477_481delATCTC突变基因的cDNA具有如下所示的核苷酸序列:ATGAGTCTAGTACTTAATGATCTGCTTATCTGCTGCCGTCAACTAGAACATGATAGAGCTACAGAACGAAAGAAAGAAGTTGAGAAATTTAAGCGCCTGATTCGAGATCCTGAAACAATTAAACATCTAGATCGGCATTCAGATTCCAAACAAGGAAAATATTTGAATTGGGATGCTGTTTTTAGATTTTTACAGAAATATATTCAGAAAGAAACAGAATGTCTGAGAATAGCAAAACCAAATGTATCAGCCTCAACACAAGCCTCCAGGCAGAAAAAGATGCAGGAAATCAGTAGTTTGGTCAAATACTTCATCAAATGTGCAAACAGAAGAGCACCTAGGCTAAAATGTCAAGAACTCTTAAATTATATCATGGATACAGTGAAAGATTCATCTAATGGTGCTATTTACGGAGCTGATTGTAGCAACATACTACTCAAAGACATTCTTTCTGTGAGAAAATACTGGTGTGAAATAGCAACAGTGGTTAGAATTGTTCTCTGTGTACTTCAGGCTCTATCTGAAACCTTCACAAGATGTTCA(SEQIDNO:3),上述c.477_481delATCTC突变基因编码的氨基酸序列如下:MSLVLNDLLICCRQLEHDRATERKKEVEKFKRLIRDPETIKHLDRHSDSKQGKYLNWDAVFRFLQKYIQKETECLRIAKPNVSASTQASRQKKMQEISSLVKYFIKCANRRAPRLKCQELLNYIMDTVKDSSNGAIYGADCSNILLKDILSVRKYWCEIATVVRIVLCVLQALSETFTRCS(SEQIDNO:4)。与野生型ATM基因的cDNA相比,c.4777-2A>T的突变基因的cDNA具有如下所示的核苷酸序列:ATGAGTCTAGTACTTAATGATCTGCTTATCTGCTGCCGTCAACTAGAACATGATAGAGCTACAGAACGAAAGAAAGAAGTTGAGAAATTTAAGCGCCTGATTCGAGATCCTGAAACAATTAAACATCTAGATCGGCATTCAGATTCCAAACAAGGAAAATATTTGAATTGGGATGCTGTTTTTAGATTTTTACAGAAATATATTCAGAAAGAAACAGAATGTCTGAGAATAGCAAAACCAAATGTATCAGCCTCAACACAAGCCTCCAGGCAGAAAAAGATGCAGGAAATCAGTAGTTTGGTCAAATACTTCATCAAATGTGCAAACAGAAGAGCACCTAGGCTAAAATGTCAAGAACTCTTAAATTATATCATGGATACAGTGAAAGATTCATCTAATGGTGCTATTTACGGAGCTGATTGTAGCAACATACTACTCAAAGACATTCTTTCTGTGAGAAAATACTGGTGTGAAATATCTCAGCAACAGTGGTTAGAATTGTTCTCTGTGTACTTCAGGCTCTATCTGAAACCTTCACAAGATGTTCATAGAGTTTTAGTGGCTAGAATAATTCATGCTGTTACCAAAGGATGCTGTTCTCAGACTGACGGATTAAATTCCAAATTTTTGGACTTTTTTTCCAAGGCTATTCAGTGTGCGAGACAAGAAAAGAGCTCTTCAGGTCTAAATCATATCTTAGCAGCTCTTACTATCTTCCTCAAGACTTTGGCTGTCAACTTTCGAATTCGAGTGTGTGAATTAGGAGATGAAATTCTTCCCACTTTGCTTTATATTTGGACTCAACATAGGCTTAATGATTCTTTAAAAGAAGTCATTATTGAATTATTTCAACTGCAAATTTATATCCATCATCCGAAAGGAGCCAAAACCCAAGAAAAAGGTGCTTATGAATCAACAAAATGGAGAAGTATTTTATACAACTTATATGATCTGCTAGTGAATGAGATAAGTCATATAGGAAGTAGAGGAAAGTATTCTTCAGGATTTCGTAATATTGCCGTCAAAGAAAATTTGATTGAATTGATGGCAGATATCTGTCACCAGGTTTTTAATGAAGATACCAGATCCTTGGAGATTTCTCAATCTTACACTACTACACAAAGAGAATCTAGTGATTACAGTGTCCCTTGCAAAAGGAAGAAAATAGAACTAGGCTGGGAAGTAATAAAAGATCACCTTCAGAAGTCACAGAATGATTTTGATCTTGTGCCTTGGCTACAGATTGCAACCCAATTAATATCAAAGTATCCTGCAAGTTTACCTAACTGTGAGCTGTCTCCATTACTGATGATACTATCTCAGCTTCTACCCCAACAGCGACATGGGGAACGTACACCATATGTGTTACGATGCCTTACGGAAGTTGCATTGTGTCAAGACAAGAGGTCAAACCTAGAAAGCTCACAAAAGTCAGATTTATTAAAACTCTGGAATAAAATTTGGTGTATTACCTTTCGTGGTATAAGTTCTGAGCAAATACAAGCTGAAAACTTTGGCTTACTTGGAGCCATAATTCAGGGTAGTTTAGTTGAGGTTGACAGAGAATTCTGGAAGTTATTTACTGGGTCAGCCTGCAGACCTTCATGTCCTGCAGTATGCTGTTTGACTTTGGCACTGACCACCAGTATAGTTCCAGGAACGGTAAAAATGGGAATAGAGCAAAATATGTGTGAAGTAAATAGAAGCTTTTCTTTAAAGGAATCAATAATGAAATGGCTCTTATTCTATCAGTTAGAGGGTGACTTAGAAAATAGCACAGAAGTGCCTCCAATTCTTCACAGTAATTTTCCTCATCTTGTACTGGAGAAAATTCTTGTGAGTCTCACTATGAAAAACTGTAAAGCTGCAATGAATTTTTTCCAAAGCGTGCCAGAATGTGAACACCACCAAAAAGATAAAGAAGAACTTTCATTCTCAGAAGTAGAAGAACTATTTCTTCAGACAACTTTTGACAAGATGGACTTTTTAACCATTGTGAGAGAATGTGGTATAGAAAAGCACCAGTCCAGTATTGGCTTCTCTGTCCACCAGAATCTCAAGGAATCACTGGATCGCTGTCTTCTGGGATTATCAGAACAGCTTCTGAATAATTACTCATCTGAGATTACAAATTCAGAAACTCTTGTCCGGTGTTCACGTCTTTTGGTGGGTGTCCTTGGCTGCTACTGTTACATGGGTGTAATAGCTGAAGAGGAAGCATATAAGTCAGAATTATTCCAGAAAGCCAAGTCTCTAATGCAATGTGCAGGAGAAAGTATCACTCTGTTTAAAAATAAGACAAATGAGGAATTCAGAATTGGTTCCTTGAGAAATATGATGCAGCTATGTACACGTTGCTTGAGCAACTGTACCAAGAAGAGTCCAAATAAGATTGCATCTGGCTTTTTCCTGCGATTGTTAACATCAAAGCTAATGAATGACATTGCAGATATTTGTAAAAGTTTAGCATCCTTCATCAAAAAGCCATTTGACCGTGGAGAAGTAGAATCAATGGAAGATGATACTAATGGAAATCTAATGGAGGTGGAGGATCAGTCATCCATGAATCTATTTAACGATTACCCTGATAGTAGTGTTAGTGATGCAAACGAACCTGGAGAGAGCCAAAGTACCATAGGTGCCATTAATCCTTTAGCTGAAGAATATCTGTCAAAGCAAGATCTACTTTTCTTAGACATGCTCAAGTTCTTGTGTTTGTGTGTAACTACTGCTCAGACCAATACTGTGTCCTTTAGGGCAGCTGATATTCGGAGGAAATTGTTAATGTTAATTGATTCTAGCACGCTAGAACCTACCAAATCCCTCCACCTGCATATGTATCTAATGCTTTTAAAGGAGCTTCCTGGAGAAGAGTACCCCTTGCCAATGGAAGATGTTCTTGAACTTCTGAAACCACTATCCAATGTGTGTTCTTTGTATCGTCGTGACCAAGATGTTTGTAAAACTATTTTAAACCATGTCCTTCATGTAGTGAAAAACCTAGGTCAAAGCAATATGGACTCTGAGAACACAAGGGATGCTCAAGGACAGTTTCTTACAGTAATTGGAGCATTTTGGCATCTAACAAAGGAGAGGAAATATATATTCTCTGTAAGAATGGCCCTAGTAAATTGCCTTAAAACTTTGCTTGAGGCTGATCCTTATTCAAAATGGGCCATTCTTAATGTAATGGGAAAAGACTTTCCTGTAAATGAAGTATTTACACAATTTCTTGCTGACAATCATCACCAAGTTCGCATGTTGGCTGCAGAGTCAATCAATAGATTGTTCCAGGACACGAAGGGAGATTCTTCCAGGTTACTGAAAGCACTTCCTTTGAAGCTTCAGCAAACAGCTTTTGAAAATGCATACTTGAAAGCTCAGGAAGGAATGAGAGAAATGTCCCATAGTGCTGAGAACCCTGAAACTTTGGATGAAATTTATAATAGAAAATCTGTTTTACTGACGTTGATAGCTGTGGTTTTATCCTGTAGCCCTATCTGCGAAAAACAGGCTTTGTTTGCCCTGTGTAAATCTGTGAAAGAGAATGGATTAGAACCTCACCTTGTGAAAAAGGTTTTAGAGAAAGTTTCTGAAACTTTTGGATATAGACGTTTAGAAGACTTTATGGCATCTCATTTAGATTATCTGGTTTTGGAATGGCTAAATCTTCAAGATACTGAATACAACTTATCTTCTTTTCCTTTTATTTTATTAAACTACACAAATATTGAGGATTTCTATAGATCTTGTTATAAGGTTTTGATTCCACATCTGGTGATTAGAAGTCATTTTGATGAGGTGAAGTCCATTGCTAATCAGATTCAAGAGGACTGGAAAAGTCTTCTAACAGACTGCTTTCCAAAGATTCTTGTAAATATTCTTCCTTATTTTGCCTATGAGGGTACCAGAGACAGTGGGATGGCACAGCAAAGAGAGACTGCTACCAAGGTCTATGATATGCTTAAAAGTGAAAACTTATTGGGAAAACAGATTGATCACTTATTCATTAGTAATTTACCAGAGATTGTGGTGGAGTTATTGATGACGTTACATGAGCCAGCAAATTCTAGTGCCAGTCAGAGCACTGACCTCTGTGACTTTTCAGGGGATTTGGATCCTGCTCCTAATCCACCTCATTTTCCATCGCATGTGATTAAAGCAACATTTGCCTATATCAGCAATTGTCATAAAACCAAGTTAAAAAGCATTTTAGAAATTCTTTCCAAAAGCCCTGATTCCTATCAGAAAATTCTTCTTGCCATATGTGAGCAAGCAGCTGAAACAAATAATGTTTATAAGAAGCACAGAATTCTTAAAATATATCACCTGTTTGTTAGTTTATTACTGAAAGATATAAAAAGTGGCTTAGGAGGAGCTTGGGCCTTTGTTCTTCGAGACGTTATTTATACTTTGATTCACTATATCAACCAAAGGCCTTCTTGTATCATGGATGTGTCATTACGTAGCTTCTCCCTTTGTTGTGACTTATTAAGTCAGGTTTGCCAGACAGCCGTGACTTACTGTAAGGATGCTCTAGAAAACCATCTTCATGTTATTGTTGGTACACTTATACCCCTTGTGTATGAGCAGGTGGAGGTTCAGAAACAGGTATTGGACTTGTTGAAATACTTAGTGATAGATAACAAGGATAATGAAAACCTCTATATCACGATTAAGCTTTTAGATCCTTTTCCTGACCATGTTGTTTTTAAGGATTTGCGTATTACTCAGCAAAAAATCAAATACAGTAGAGGACCCTTTTCACTCTTGGAGTTCTCAGGA(SEQIDNO:5),上述c.4777-2A>T的突变基因编码的氨基酸序列如下:MSLVLNDLLICCRQLEHDRATERKKEVEKFKRLIRDPETIKHLDRHSDSKQGKYLNWDAVFRFLQKYIQKETECLRIAKPNVSASTQASRQKKMQEISSLVKYFIKCANRRAPRLKCQELLNYIMDTVKDSSNGAIYGADCSNILLKDILSVRKYWCEISQQQWLELFSVYFRLYLKPSQDVHRVLVARIIHAVTKGCCSQTDGLNSKFLDFFSKAIQCARQEKSSSGLNHILAALTIFLKTLAVNFRIRVCELGDEILPTLLYIWTQHRLNDSLKEVIIELFQLQIYIHHPKGAKTQEKGAYESTKWRSILYNLYDLLVNEISHIGSRGKYSSGFRNIAVKENLIELMADICHQVFNEDTRSLEISQSYTTTQRESSDYSVPCKRKKIELGWEVIKDHLQKSQNDFDLVPWLQIATQLISKYPASLPNCELSPLLMILSQLLPQQRHGERTPYVLRCLTEVALCQDKRSNLESSQKSDLLKLWNKIWCITFRGISSEQIQAENFGLLGAIIQGSLVEVDREFWKLFTGSACRPSCPAVCCLTLALTTSIVPGTVKMGIEQNMCEVNRSFSLKESIMKWLLFYQLEGDLENSTEVPPILHSNFPHLVLEKILVSLTMKNCKAAMNFFQSVPECEHHQKDKEELSFSEVEELFLQTTFDKMDFLTIVRECGIEKHQSSIGFSVHQNLKESLDRCLLGLSEQLLNNYSSEITNSETLVRCSRLLVGVLGCYCYMGVIAEEEAYKSELFQKAKSLMQCAGESITLFKNKTNEEFRIGSLRNMMQLCTRCLSNCTKKSPNKIASGFFLRLLTSKLMNDIADICKSLASFIKKPFDRGEVESMEDDTNGNLMEVEDQSSMNLFNDYPDSSVSDANEPGESQSTIGAINPLAEEYLSKQDLLFLDMLKFLCLCVTTAQTNTVSFRAADIRRKLLMLIDSSTLEPTKSLHLHMYLMLLKELPGEEYPLPMEDVLELLKPLSNVCSLYRRDQDVCKTILNHVLHVVKNLGQSNMDSENTRDAQGQFLTVIGAFWHLTKERKYIFSVRMALVNCLKTLLEADPYSKWAILNVMGKDFPVNEVFTQFLADNHHQVRMLAAESINRLFQDTKGDSSRLLKALPLKLQQTAFENAYLKAQEGMREMSHSAENPETLDEIYNRKSVLLTLIAVVLSCSPICEKQALFALCKSVKENGLEPHLVKKVLEKVSETFGYRRLEDFMASHLDYLVLEWLNLQDTEYNLSSFPFILLNYTNIEDFYRSCYKVLIPHLVIRSHFDEVKSIANQIQEDWKSLLTDCFPKILVNILPYFAYEGTRDSGMAQQRETATKVYDMLKSENLLGKQIDHLFISNLPEIVVELLMTLHEPANSSASQSTDLCDFSGDLDPAPNPPHFPSHVIKATFAYISNCHKTKLKSILEILSKSPDSYQKILLAICEQAAETNNVYKKHRILKIYHLFVSLLLKDIKSGLGGAWAFVLRDVIYTLIHYINQRPSCIMDVSLRSFSLCCDLLSQVCQTAVTYCKDALENHLHVIVGTLIPLVYEQVEVQKQVLDLLKYLVIDNKDNENLYITIKLLDPFPDHVVFKDLRITQQKIKYSRGPFSLLEFSG(SEQIDNO:6)。发明人发现的ATM基因突变体与SEQIDNO:1相比,本发明的ATM基因具有一个c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC、exon65del突变的至少一种。具体地,ATM基因突变体的c.5697C>A突变相对于野生型ATM基因的cDNA的第5697位的C突变为A,由此,导致其编码的蛋白发生p.Cys1899X无义突变。c.4777-2A>T突变后的基因序列为SEQIDNO:5,p.Glu2950fs突变蛋白的序列为SEQIDNO:6。c.3078G>T突变相对于野生型ATM基因的cDNA的第3078位的G突变为T,由此,导致其编码的蛋白发生了p.Trp1026Cys错义突变。c.7983_7985delTGT突变相对于野生型ATM基因cDNA的第7983_7985位的TGT缺失了,因而导致其编码的蛋白发生了p.Val2662del的缺失突变。c.477_481delATCTC突变相对于野生型ATM基因的cDNA的第477_481位的ATCTC缺失了,因而发生了移码突变p.Ile159fs,其突变后的基因以及蛋序列为SEQIDNO:3和SEQIDNO:4。c.8851_8987del(exon65del)突变相对于野生型ATM基因的cDNA的第8851-8987位的基因序列:GTCCTTCTATATGATCCACTCTTTGACTGGACCATGAATCCTTTGAAAGCTTTGTATTTACAGCAGAGGCCGGAAGATGAAACTGAGCTTCACCCTACTCTGAATGCAGATGACCAAGAATGCAAACGAAATCTCAG缺失了,在缺失序列后即是终止密码子TGA,突变的cDNA包含8853个碱基;由此导致编码的蛋白在第2951-2995位的VLLYDPLFDWTMNPLKALYLQQRPEDETELHPTLNADDQECKRNL缺失,并随即翻译终止,突变蛋白包含2950个氨基酸,即p.2951_2995del。因此根据本发明的具体实施例,共济失调毛细血管扩张症是常染色体隐性遗传病,具有上述至少一种突变为共济失调毛细血管扩张症疾病的携带者或者患者。根据本发明的一个实施例,通过检测是否具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC、c.8851_8987del的至少一种突变,可以准确有效地预测生物体是否患常染色体隐性遗传型共济失调毛细血管扩张症。根据本发明的第二个方面,本发明提出了一种分离的多肽。根据本发明的实施例,与SEQIDNO:2相比,该多肽具有选自下列的至少一种突变:p.Cys1899X、p.Glu2950fs、p.Trp1026Cys、p.Val2662del、p.Ile159fs、p.2951_2995del。根据本发明的具体实施例,该多肽是由前述分离的编码ATM基因突变体的核酸编码的。通过检测生物样品中是否表达该多肽,可以有效地检测生物样品是否易感共济失调毛细血管扩张症,也可以通过检测这些多肽在生物体中是否存在,可以有效地预测生物体是否易感共济失调毛细血管扩张症。筛选易患共济失调毛细血管扩张症的生物样品的方法根据本发明的第三个方面,本发明提出了一种筛选易患共济失调毛细血管扩张症的生物样品的方法。根据本发明的实施例,该筛选易患共济失调毛细血管扩张症的生物样品的方法可以包括以下步骤:首先,从所述生物样品提取核酸样本。根据本发明的实施例,生物样品的类型并不受特别限制,只要从该生物样品中能够提取到反映生物样品ATM是否存在突变的核酸样本即可。根据本发明的实施例,生物样品可以为选自人体血液。由此,可以方便地进行取样和检测,从而能够进一步提高筛选易患共济失调毛细血管扩张症的生物样品的效率。根据本发明的实施例,这里所使用的术语“核酸样本”应做广义理解,其可以是任何能够反映生物样品中ATM是否存在突变的样本,例如可以是从生物样品中直接提取的全基因组DNA,也可以是该全基因组中包含ATM编码序列的一部分,可以是从生物样品中提取的总RNA,也可以是从生物样品中提取的mRNA。根据本发明的一个实施例,所述核酸样本为全基因组DNA。由此,可以扩大生物样品的来源范围,并且可以同时对生物样品的多种信息进行确定,从而能够提高筛选易患共济失调毛细血管扩张症的生物样品的效率。另外,根据本发明的实施例,针对采用RNA作为核酸样本,从生物样品提取核酸样本可以进一步包括:从生物样品提取RNA样本,优选RNA样本为mRNA;以及基于所得到的RNA样本,通过反转录反应,获得cDNA样本,所得到的cDNA样本构成核酸样本。由此,可以进一步提高利用RNA作为核酸样本筛选易患共济失调毛细血管扩张症的生物样品的效率。接下来,在得到核酸样本之后,可以对核酸样本进行分析,从而能够确定所得到核酸样本的核酸序列。根据本发明的实施例,确定所得到核酸样本的核酸序列的方法和设备并不受特别限制。根据本发明的具体实施例,可以通过测序方法,确定核酸样本的核酸序列。根据本发明的实施例,可以用于进行测序的方法和设备并不受特别限制。根据本发明的实施例,可以采用第二代测序技术,也可以采用第三代以及第四代或者更先进的测序技术。根据本发明的具体示例,可以利用选自Hiseq2000、SOLiD、454和单分子测序装置的至少一种对核酸序列进行测序。由此,结合最新的测序技术,针对单个位点可以达到较高的测序深度,检测灵敏度和准确性大大提高,因而能够利用这些测序装置的高通量、深度测序的特点,进一步提高对核酸样本进行检测分析的效率。从而,能够提高后续对测序数据进行分析时的精确性和准确度。由此,根据本发明的实施例,确定核酸样本的核酸序列可以进一步包括:首先,针对所得到的核酸样本,构建核酸测序文库;以及对所得到的核酸测序文库进行测序,以便获得由多个测序数据构成的测序结果。根据本发明的一些实施例,可以采用选自Hiseq2000、SOLiD、454和单分子测序装置的至少一种对所得到的核酸测序文库进行测序。另外,根据本发明的实施例,可以对核酸样本进行筛选,富集ATM外显子,该筛选富集可以在构建测序文库之前,构建测序文库过程中,或者构建测序文库之后进行。根据本发明的一个实施例,针对核酸样本,构建核酸测序文库进一步包括:利用ATM基因外显子特异性引物,对核酸样本进行PCR扩增;以及针对所得到的扩增产物,构建核酸测序文库。由此,可以通过PCR扩增,富集ATM基因外显子,从而能够进一步提高筛选易感共济失调毛细血管扩张症的生物样品的效率。根据本发明的实施例,ATM基因外显子特异性引物的序列不受特别限制,根据本发明的优选实施例,这些ATM基因外显子特异性引物具有如下表所示的核苷酸序列,即SEQIDNO:7-16所示的核苷酸序列。发明人惊奇地发现,通过采用这些引物,可以在PCR反应体系中显著有效地完成对ATM外显子尤其是c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)突变所在的外显子序列的扩增。需要说明的是,这些SEQIDNO:7-16所示的核苷酸序列是本发明的发明人在付出了艰苦的劳动后,意外获得的。根据本发明的具体实施例,上述的共济失调毛细血管扩张症是常染色体隐性遗传疾病。关于针对核酸样本,构建测序文库的方法和流程,本领域技术人员可以根据不同的测序技术进行适当选择,关于流程的细节,可以参见测序仪器的厂商例如Illumina公司所提供的规程,例如参见Illumina公司MultiplexingSamplePreparationGuide(Part#1005361;Feb2010)或Paired-EndSamplePrepGuide(Part#1005063;Feb2010),通过参照将其并入本文。根据本发明的实施例,从生物样品提取核酸样本的方法和设备,也不受特别限制,可以采用商品化的核酸提取试剂盒进行。需要说明的是,在这里所使用的术语“核酸序列”应作广义理解,其可以是在对核酸样本进行测序得到的测序数据进行组装后,得到的完整的核酸序列信息,也可以是直接采用通过对核酸样本进行测序所得到的测序数据(reads)作为核酸序列,只要这些核酸序列中含有对应ATM基因的编码序列即可。最后,在确定核酸样本的核酸序列之后,将所得到的核酸样本的核酸序列与SEQIDNO:1的序列相比对。如果在所得到的核酸序列中具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)突变的至少一种,则指示生物样品易患共济失调毛细血管扩张症。由此,通过根据本发明实施例的筛选易患共济失调毛细血管扩张症的生物样品的方法,可以有效地筛选易患共济失调毛细血管扩张症的生物样品。根据本发明的实施例,对核酸序列与SEQIDNO:1进行比对的方法和设备并不受特别限制,可以采用任意常规的软件进行操作,根据本发明的具体实例,可以采用SOAP软件进行比对。需要说明的是,根据本发明实施例的“筛选易患共济失调毛细血管扩张症的生物样品的方法”的用途不受特别限制,例如可以用作非诊断目的的筛选方法。筛选易患共济失调毛细血管扩张症的生物样品的系统和试剂盒根据本发明的第四个方面,本发明提出了一种筛选易患共济失调毛细血管扩张症的生物样品的系统。参考图1,根据本发明的实施例,该筛选易患共济失调毛细血管扩张症的生物样品的系统1000包括核酸提取装置100、核酸序列确定装置200以及判断装置300。根据本发明的实施例,核酸提取装置100用于从生物样品提取核酸样本。如前所述,根据本发明的实施例,核酸样本的类型并不受特别限制,对于采用RNA作为核酸样本,则核酸提取装置进一步包括RNA提取单元101和反转录单元102,其中,提取单元101用于从生物样品提取RNA样本,反转录单元102与RNA提取单元101相连,用于对RNA样本进行反转录反应,以便获得cDNA样本,所得到的cDNA样本构成核酸样本。根据本发明的实施例,核酸序列确定装置200与核酸提取装置100相连,用于对核酸样本进行分析,以便确定核酸样本的核酸序列。如前所示,可以采用测序的方法确定核酸样本的核酸序列。由此,根据本发明的一个实施例,所述核酸序列确定装置200可以进一步包括:文库构建单元201以及测序单元202。文库构建单元201用于针对核酸样本,构建核酸测序文库;测序单元202与文库构建单元201相连,用于对核酸测序文库进行测序,以便获得由多个测序数据构成的测序结果。如前所述,可以通过PCR扩增,富集ATM外显子,进一步提高筛选易患共济失调毛细血管扩张症的生物样品的效率。由此,文库构建单元201可以进一步包括PCR扩增模块(图中未示出),在该PCR扩增模块中设置有ATM外显子特异性引物,以便利用ATM外显子特异性引物,对所述核酸样本进行PCR扩增,根据本发明的具体实施例,ATM基因外显子特异性引物具有如SEQIDNO:7-16所示的核苷酸序列。根据本发明的实施例,测序单元202可以包括选自HISEQ2000、SOLiD、454和单分子测序装置的至少一种。由此,结合最新的测序技术,针对单个位点可以达到较高的测序深度,检测灵敏度和准确性大大提高,因而能够利用这些测序装置的高通量、深度测序的特点,进一步提高对核酸样本进行检测分析的效率。从而,提高后续对测序数据进行分析时的精确性和准确度。根据本发明的实施例,判断装置300与核酸序列确定装置200相连,适于将核酸样本的核酸序列进行比对,以便基于核酸样本的核酸序列与SEQIDNO:1的区别判断生物样品是否易患共济失调毛细血管扩张症。具体地,基于核酸样本的核酸序列与SEQIDNO:1相比,是否具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)的至少一种突变,判断生物样品是否易患共济失调毛细血管扩张症。如前所述,根据本发明的一个实施例,核酸样本的核酸序列与SEQIDNO:1相比,具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)的至少一种突变,是生物样品易患共济失调毛细血管扩张症的指示。如前所述,根据本发明的实施例,对核酸序列与SEQIDNO:1进行比对的设备并不受特别限制,可以采用任意常规的软件进行操作,根据本发明的具体实例,可以采用SOAP软件进行比对。由此,利用该系统,能够有效地实施前述筛选易患共济失调毛细血管扩张症的生物样品的方法,从而可以有效地筛选易患共济失调毛细血管扩张症的生物样品。根据本发明的第五方面,本发明提出了一种用于筛选易患共济失调毛细血管扩张症的生物样品的试剂盒。根据本发明的实施例,该用于筛选易患共济失调毛细血管扩张症的生物样品的试剂盒包括:适于检测ATM基因突变体的试剂,其中与SEQIDNO:1相比,该ATM基因突变体具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)的至少一种突变。利用根据本发明的实施例的试剂盒,能够有效地筛选易患共济失调毛细血管扩张症的生物样品。在本文中,所使用的术语“适于检测ATM基因突变体的试剂”应做广义理解,即可以是检测ATM编码基因的试剂,也可以是检测ATM突变体多肽的试剂,例如可以采用识别特异性位点的抗体。根据本发明的一个实施例,所述试剂为核酸探针,由此,可以高效地筛选易患共济失调毛细血管扩张症的生物样品。根据本发明的具体实施例,上述共济失调毛细血管扩张症为常染色体隐性遗传疾病。需要说明的是,在本文前面筛选易患共济失调毛细血管扩张症的生物样品的方法部分中所描述的特征和优点,同样适用于筛选易患共济失调毛细血管扩张症的生物样品的系统或者试剂盒,在此不再赘述。构建体及重组细胞根据本发明的第六方面,本发明还提出了一种构建体。根据本发明的实施例,该构建体包含前面所述的分离的编码ATM基因突变体的核酸。需要说明的是,“构建体包含前面所述的分离的编码ATM基因突变体的核酸”表示,本发明的构建体包含与SEQIDNO:1相比具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)至少一种突变。由此,利用本发明的构建体转化受体细胞获得的重组细胞,能够有效地用作共济失调毛细血管扩张症相关研究的模型。其中,所述受体细胞的种类不受特别限制,例如可以为大肠杆菌细胞、哺乳动物细胞,优选该受体细胞来源于哺乳动物。在本发明中所使用的术语“构建体”是指这样的一种遗传载体,其包含特定核酸序列,并且能够将目的核酸序列转入宿主细胞中,以获得重组细胞。根据本发明的实施例,构建体的形式不受特别限制。根据本发明的实施例,其可以为质粒、噬菌体、人工染色体、粘粒(Cosmid)、病毒的至少一种,优选质粒。质粒作为遗传载体,具有操作简单,可以携带较大片段的性质,便于操作和处理。质粒的形式也不受特别限制,既可以是环形质粒,也可以是线性质粒,即可以是单链的,也可以是双链的。本领域技术人员可以根据需要进行选择。在本发明中所使用的术语“核酸”可以是任何包含脱氧核糖核苷酸或者核糖核苷酸的聚合物,包括但不限于经过修饰的或者未经修饰的DNA、RNA,其长度不受任何特别限制。对于用于构建重组细胞的构建体,优选所述核酸为DNA,因为DNA相对于RNA而言,其更稳定,并且易于操作。根据本发明的第七方面,本发明还提出了一种重组细胞。根据本发明的实施例,该重组细胞是通过前面所述的构建体转化受体细胞而获得的。从而,本发明的重组细胞能够有效表达构建体所携带的ATM基因突变体。根据本发明的一些实施例,本发明的重组细胞,能够有效地用作共济失调毛细血管扩张症相关研究的模型。根据本发明的实施例,受体细胞的种类不受特别限制,例如可以为大肠杆菌细胞、哺乳动物细胞,优选所述受体细胞来源于非人哺乳动物。对于本发明中所述核酸,本领域技术人员应当理解,实际包括互补双链的任意一条,或者两条。为了方便,在本发明的实施例中,虽然多数情况下只给出了一条链,但实际上也公开了与之互补的另一条链。例如,提及SEQIDNO:1,实际包括其互补序列。本领域技术人员还可以理解,利用一条链可以检测另一条链,反之亦然。下面参考具体实施例,对本发明进行说明,需要说明的是,这些实施例仅仅是说明性的,而不能理解为对本发明的限制。若未特别指明,实施例中所采用的技术手段为本领域技术人员所熟知的常规手段,可以参照《分子克隆实验指南》第三版或者相关产品进行,所采用的试剂和产品也均为可商业获得的。未详细描述的各种过程和方法是本领域中公知的常规方法,所用试剂的来源、商品名以及有必要列出其组成成分者,均在首次出现时标明,其后所用相同试剂如无特殊说明,均与首次标明的内容相同。实施例1确定共济失调毛细血管扩张症的致病基因1、样本收集发明人收集到了三个两代的共济失调毛细血管扩张症(本文中也可以称将共济失调毛细血管扩张症简称为AT)的患者家系,以及随即收集的该家系外的500名正常人的基因。图2显示了AT家系1、AT家系2以及AT家系3的家系图谱。如图2所示,其中,□表示正常男性,○表示正常女性,■表示男性患者,●表示女性患者。由图2可知,每个家系共有3名成员,其中第二代子女为AT患者,第一代的父母为正常成员。三个家系中的三名患者均表现为儿童期出现行走不稳症状,同时伴有眼球结膜处血丝,面部和关节多处色素沉着及皮肤结节形成。体检发现体态偏瘦,多处明显色素沉着,尤其在耳后和双肘关节等处可见结痂形成;明显的眼球结膜毛细血管扩张和面颊部毛细血管扩张,并且对头部进行核磁共振检查(MRI)发现小脑萎缩。1、DNA提取采用OMEGABloodDNAMidiKit全血DNA提取试剂盒从外周血样品中提取DNA,提取步骤如下:1)取2ml全血样本,加入150ulOBProtease,2.1mlBufferBL和20ulRNaseA,最大速度漩涡1分钟,彻底混匀。2)65摄氏度水浴15-20分钟,并在水浴过程中漩涡5次。3)加入2.2ml无水乙醇,最大速度漩涡30秒,彻底混匀。4)将3.5ml裂解液移入带过滤柱的15ml离心管,4000转离心5分钟,取出过滤柱,倒掉过滤液体,放回过滤柱。5)将第3步剩余裂解液加入带过滤柱的15ml离心管,4000转离心5分钟,取出过滤柱,倒掉过滤液体,放回过滤柱。6)加入3mlHBBuffer,洗涤过滤柱,4000转离心5分钟,取出过滤柱,倒掉过滤液体,放回过滤柱。7)加入3mlDNAWashBuffer,4000转离心5分钟,取出过滤柱,倒掉过滤液体,放回过滤柱。8)再次加入3mlDNAWashBuffer,4000转离心5分钟,取出过滤柱,倒掉过滤液体,放回过滤柱。9)4000转离心15分钟,甩干过滤柱。10)将过滤柱移至新的15ml离心管,加入500ul70摄氏度的ElutionBuffer,室温静置5分钟,4000转离心5分钟,收集含有DNA的过滤液。11)再次将过滤柱移至新的15ml离心管,加入500ul70摄氏度的ElutionBuffer,室温静置5分钟,4000转离心5分钟,收集含有DNA的过滤液。2、外显子捕获与测序我们挑选了三名患者进行外显子组测序及数据分析,具体做法如下。随后,发明人用AgilentSureSelectHumanAllExonKit结合Solexa高通量测序技术对病例AT家系1-II:1、AT家系2-II:1、AT家系3-II:1的外显子组序列进行了测序,具体如下:1)将基因组DNA随机打断成150-200bp左右的片段,随后在片段两端分别连接上接头制备杂交文库(参见http://www.illumina.com/提供的Illumina/Solexa标准建库说明书)。2)文库经纯化后经过ligation-mediatedPCR(LM-PCR)的线性扩增与SureSelectBiotinylatedRNALibrary(BAITS)进行杂交富集,再经过LM-PCR的线性扩增后进行上机测序。测序平台为IlluminaHiseq2000,读取长度为90bp,每个样本的平均测序深度最少为80×。3)测序后获得的原始数据由IlluminabasecallingSoftware1.7进行处理,经过过滤去污染、使用SOAPaligner2.20比对参考基因组,获得比对到基因组上的Uniquemappedreads。靶区域的基因型由SOAPsnp。3、结论在病例AT家系1-II:1中均发现有60711个单核苷酸多态性(SNPs)和3916处的插入/缺失。在病例AT家系2-II:1中发现了62518个单核苷酸多态性(SNPs)和4118处的插入/缺失,病例AT家系3-II:1中发现了58283个单核苷酸多态性(SNPs)和3687处的插入/缺失,将结果与dbSNP数据库(http://hgdownload.cse.ucsc.edu/goldenPath/hg19/database/snp132.txt.gz),HapMap数据库(ftp://ftp.ncbi.nlm.nih.gov/hapmap),千人基因组数据库(ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp),炎黄数据库(http://yh.genomics.org.cn/)等公共数据库进行比较,过滤掉所有已知变异。利用SIFT软件进行SNP功能预测.分别发现患者AT家系1-II:1在ATM基因存在一个复合杂合的突变c.5697C>A(p.Cys1899X,无义突变)、exon65del,其中患者父亲携带杂合突变c.5697C>A,患者母亲携带杂合缺失exon65del。AT家系2-II:1在ATM基因存在一个复合杂合的突变c.477_481delATCTC(移码突变)、c.4777-2A>T(剪切位点突变),其中患者父亲携带杂合缺失c.477_481delATCTC,患者母亲携带杂合突变c.4777-2A>T。AT家系3-II:1在ATM基因存在一个复合杂合的突变c.3078G>T(p.Trp1026Cys,错义突变)、c.7983_7985delTGT,其中患者父亲携带杂合突变c.3078G>T,患者母亲携带杂合缺失c.7983_7985delTGT。研究表明,通过家族中疾病共分离和正常人SNP筛查,这三个复合杂合位点突变可引起常染色体隐性遗传性的AT疾病,因此可能是致病位点。实施例2Sanger法测序验证共济失调毛细血管扩张症的致病基因采集3例AT患者及其父母外周血,利用常规酚-氯仿法抽提外周血白细胞中的基因组DNA,利用分光光度计测量DNA的浓度及纯度,所得的每个标本基因组DNA的OD260/OD280均位于1.7-2.0之间,浓度不少于200ng/ul,总量不少于30μg。分别对3名患者(即图2中的患者II:1)、6名家系内正常人(即该3例患者的父母,均未发病)和500名家系外正常人(即与表中所有患者无血缘关系的对照)基因进行检测,针对ATM基因所有外显子序列设计引物,通过PCR扩增,产物纯化,测序的方法获得ATM有关序列,根据序列测定结果属于突变型还是野生型,验证ATM与AT疾病之间相关性。具体方法步骤如下:1、DNA提取:分别采取3名家系内患者、6名家系内正常人和500名家系外正常人外周静脉血按照上述方法提取基因组DNA,分光光度计测DNA含量。2、引物设计及PCR反应引物设计参考人类基因组序列数据库hg19/build37.1,具体见下。引物序列:b)反应体系:10μL试剂体积2×GCBufferⅠ5.0μldNTPs(10mM)0.4μlLATaq酶(5U/μl)0.1μlPrimers(100ng/μl)0.2μl/个gDNA模板(50ng/μl)1.0μlddH2OAddto10.0μlc)反应条件:3)将步骤2中获得的获自3例AT患者、6名家系内正常人和500名家系外正常人PCR扩增产物直接进行DNA测序。表1AT家系中的患者情况在患者家族成员中对ATM基因突变位点所在编码序列及侧翼序列进行突变排查,分别发现患者AT家系1-II:1在ATM基因存在一个复合杂合的突变c.5697C>A(p.Cys1899X,无义突变)、exon65del,其中患者父亲携带杂合突变c.5697C>A,患者母亲携带杂合缺失exon65del。AT家系2-II:1在ATM基因存在一个复合杂合的突变c.477_481delATCTC(移码突变)、c.4777-2A>T(剪切位点突变),其中患者父亲携带杂合缺失c.477_481delATCTC,患者母亲携带杂合突变c.4777-2A>T。AT家系3-II:1在ATM基因存在一个复合杂合的突变c.3078G>T(p.Trp1026Cys,错义突变)、c.7983_7985delTGT,其中患者父亲携带杂合突变c.3078G>T,患者母亲携带杂合缺失c.7983_7985delTGT。(见表2及图3-5)。同时,我们在500个家族外无关正常对照中排查未检测到的突变位点。表2AT家系成员的基因突变情况本发明的ATM基因中的是否具有c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)突变的至少一种,可判断此家族中未发病的人群患病的可能性,同时可用于家族后代患病几率的评估与诊断,为患者及家庭提供遗传咨询及产前诊断避免携带该突变的下一代出生。研究证实ATM基因突变可以引起共济失调毛细血管扩张症。我们的研究表明:ATM基因中的c.5697C>A、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT、c.477_481delATCTC和c.8851_8987del(exon65del)突变是引起常染色体隐性遗传性AT疾病的突变。本发明公开了六种已知耳聋基因(ATM)的新突变,证实了其为常染色体隐性遗传性的分子病因,在500例中国正常人群中进行该位点的筛查,均为阴性。本研究丰富了ATM基因突变谱,为开展遗传性AT疾病的分子诊断提供了基因学依据。实施例3检测试剂盒制备检测试剂盒,其中含有检测突变的c.5679C>A、c.477_481delATCTC、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT的引物对见下表:按照实施例1所述的方法提取待测者DNA,以所提取的DNA为模板与上述引物进行PCR反应,按照本领域常规方法对PCR产物纯化,将纯化的产物测序。观察测序所得到的序列是否有c.5679C>A、c.477_481delATCTC、c.4777-2A>T、c.3078G>T、c.7983_7985delTGT突变。实施例4分别对AT家系1内1个患者样本和1个患者的母亲(非患者)样本进行QPCR。具体方法步骤如下:1、DNA提取:采集患者和其母亲的外周静脉血用QIAampDNABloodMiNiKit(Qiagen,Hilden,Germany)方法提取基因组DNA。2、引物设计及PCR反应1)QPCR引物:2)QPCR实验仪器及条件:ABI7500荧光定量PCR仪3)实验用量及试剂:模板为1ul每个做三个平行样。3、最低循环数值(Ct)比较法计算ATM基因的65号外显子的相对拷贝数应用vvCt法,与内对照ALB基因比较可以得出ATM基因的65号外显子的相对拷贝数(图6)。在患者家族成员中对ATM基因突变位点所在编码序列及侧翼序列进行突变排查,分别发现患者AT家系1-II:1在ATM基因存在exon65del,其中患者父亲无该突变,患者母亲携带杂合缺失exon65del。实施例5c.4777-2A>T的验证分别对AT家系2内1个患者样本和2个非患者样本进行PCR。具体方法步骤如下:1、RNA提取以CDNA制备:采集患者和其父母亲的外周静脉血,使用QIAGEN公司生产的RNA提取试剂盒提取总RNA,并反转录为cDNA。2、引物设计及PCR反应a)AT家系2剪切位点变异位点验证引物b)反应体系:10μL试剂体积2×GCBufferⅠ5.0μldNTPs(10mM)0.4μlLATaq酶(5U/μl)0.1μlPrimers(100ng/μl)0.2μl/个gDNA模板(50ng/μl)1.0μlddH2OAddto10.0μlc)反应条件:3、将步骤1所得的cDNA进行PCR扩增然后直接进行DNA测序,发现患者及母亲的cDNA序列发生了杂合的改变,患者父亲未有改变(图7),由此认为该突变会造成cDNA序列的改变从而影响氨基酸的改变。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1