固体支持物上的样品制备的制作方法
相关申请
本申请要求于2013年1月9日提交的美国临时申请号61/750,682的优先权,其在此通过引用以其整体并入。
背景
存在很多期望从双链DNA(dsDNA)靶分子产生片段化并加标签的DNA分子文库的方法和应用。通常,目的是从大的dsDNA分子产生较小的DNA分子(例如,DNA片段),用于用作DNA测序反应中的模板。
目前用于双链DNA的片段化和加标签用于在下一代测序中使用的很多方法浪费DNA,需要用于片段化的昂贵的设备,并且片段化、加标签和回收加标签的DNA片段的过程困难、冗长、费力、耗时、低效、昂贵、需要相对大量的样品核酸。另外,这些方法中的很多产生加标签的DNA片段,所述加标签的DNA片段不完全代表包含于加标签的DNA片段从其产生的样品核酸中的序列。因此,本领域需要的是提供当从靶DNA产生加标签的DNA片段文库时快速且方便使用的方法,其能容易地应用到核酸分析方法,诸如下一代测序和扩增方法。
概述
本文提供了用于固体支持物上的核酸样品制备的方法和组合物。所述方法和组合物特别地涉及用于使用固定至固体支持物的转座子组合物片段化DNA并使DNA加标签的方法和组合物。本文提供的方法和组合物是有用的,例如,用于产生在下一代测序方法等中使用的加标签的DNA片段文库。在一些优选的实施方案中,本发明涉及在固体支持物上从来自任何来源的靶DNA制备线性ssDNA片段,用于基因组、亚基因组、转录组、或宏基因组分析,或RNA表达分析,所述靶DNA包括任何感兴趣的dsDNA(包括从RNA制备的双链cDNA)。
相应地,本发明提供了制备加标签的DNA片段的固定的文库(immobilized library of tagged DNA)的方法,所述方法包括:(a)提供具有转座体复合物(transposome complex)固定于其上的固体支持物,其中转座体复合物包含结合至第一多核苷酸的转座酶,所述第一多核苷酸包含(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域;和(b)在靶DNA藉以被转座体复合物片段化,并且第一多核苷酸的3'转座子末端序列藉以转移至片段的至少一条链的5'末端的条件下,将靶DNA施加于固体支持物;从而产生双链片段的固定的文库,其中至少一条链是用第一标签在5'-加标签的。在一些实施方案中,转座体复合物包含第二多核苷酸,所述第二多核苷酸包含与所述转座子末端序列互补的区域。所述方法还包括(c)提供溶液中的转座体复合物,并在靶DNA藉以被溶液中的转座体复合物片段化的条件下使转座体复合物与固定的片段接触;从而获得具有一个末端在溶液中的固定的核酸片段。在一些实施方案中,溶液中的转座体复合物可包含第二标签,以使得所述方法产生具有第二标签的固定的核酸片段,所述第二标签在溶液中。第一标签和第二标签可以是不同的或相同的。
本文还提供了根据以上方法或其他方法制备的具有加标签的DNA片段的文库固定于其上的固体支持物。例如,本文提供了具有转座体复合物固定于其上的固体支持物,其中转座体复合物包含结合至第一多核苷酸的转座酶,多核苷酸包含(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域;
本文还提供了产生流通池(flowcell)的方法,包括将多个转座体复合物固定至固体支持物,所述转座体复合物包含结合至第一多核苷酸的转座酶,第一多核苷酸包含(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域。
所述方法还可包括提供具有多个第一多核苷酸固定于其上的固体支持物,以及使固体支持物与转座酶全酶和第二多核苷酸接触,所述第二多核苷酸包含与转座子末端序列互补的区域。在所述方法的一些实施方案中,所述固定包括(a)提供具有扩增引物偶联至其的固体支持物;(b)使第二多核苷酸与扩增引物之一杂交,所述第二寡核苷酸包含与转座子末端序列互补的区域,以及与第一标签互补的区域;(c)使用聚合酶延伸扩增引物以产生包含与第二多核苷酸杂交的第一多核苷酸的双链体,所述第一多核苷酸直接地固定至固体支持物;以及(d)使固体支持物与转座酶全酶接触,从而在固体支持物上组装转座体复合物。
本文还提供了一种微粒群体,所述微粒群体具有固定至其的转座体复合物,所述转座体复合物包含结合至第一多核苷酸的转座酶和第二多核苷酸;其中第一多核苷酸在其5'末端被固定至微粒的表面并且第二多核苷酸与第一多核苷酸的3'末端杂交;并且其中第一多核苷酸包含:(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域。本文还提供了产生加标签的DNA片段的固定的文库的方法,所述方法包括使靶DNA与以上微粒群体接触以产生固定的加标签的DNA片段。
本文还提供了产生加标签的DNA片段文库的方法,所述加标签的DNA片段文库用于索引定向的组装为较长的序列读段,所述方法包括:提供具有转座体复合物固定至其的微粒群体,所述转座体复合物包含结合至第一多核苷酸的转座酶和第二多核苷酸,所述第一多核苷酸包含与微粒缔合的索引域;将靶DNA施加于微粒群体,从而产生用索引域加标签的固定的DNA片段。在以上方法的某些实施方案中,第一多核苷酸在其5'末端被固定至微粒的表面并且第二多核苷酸与第一多核苷酸的3'末端杂交;并且其中第一多核苷酸包含:(i)3'部分,所述3'部分包含转座子末端序列,和(ii)索引域;并且其中微粒群体包括至少多个索引域,并且其中单个微粒上的第一多核苷酸共用相同的索引域。
本文还提供了用于对多个靶DNA分子测序的方法,所述方法包括:在靶DNA藉以被转座体复合物片段化的条件下,将多个靶DNA施加至具有转座体复合物固定至其上的固体支持物上;从而产生双链片段的固定的文库,其中每个靶DNA的第一部分在所述固体支持物上的第一位置处被附接至所述固体支持物,并且每个靶DNA的第二部分在所述固体支持物上的第二位置处被附接至所述固体支持物;以及绘制所述双链片段的固定的文库的图谱以产生由每个靶DNA连接的位置的组;确定靶DNA的所述第一部分和所述第二部分的序列;以及关联所述位置的组以确定第一部分和第二部分的哪些被所述靶DNA连接,并确定靶DNA分子的序列。
在本文提供的方法和组合物的一些实施方案中,转座体复合物以至少103、104、105、106个复合物每mm2的密度存在于固体支持物上。在一些实施方案中,转座体复合物包含超活性转座酶,诸如Tn5转座酶。
在本文提供的方法和组合物的一些实施方案中,标签域可包含例如用于簇扩增的区域。在一些实施方案中,标签域可包含用于引发测序反应的区域。
在本文提供的方法和组合物的一些实施方案中,固体支持物可包括例如微粒、模式化的表面、孔等。在一些实施方案中,转座体复合物在固体支持物上随机地分布。在一些实施方案中,转座体复合物在模式化的表面上随机地分布。
一个或更多个实施方案的细节在附图和以下的说明中被描述。其他的特征、目标、和优势将由说明书和附图,以及由权利要求而明显。
本申请提供了以下内容:
项目1.一种制备加标签的DNA片段的固定的文库的方法,所述方法包括:(a)提供具有转座体复合物固定于其上的固体支持物,其中所述转座体复合物包含结合至第一多核苷酸的转座酶,所述第一多核苷酸包含(i)3’部分,所述3’部分包含转座子末端序列,以及(ii)第一标签,所述第一标签包含第一标签域;(b)在靶DNA藉以被所述转座体复合物片段化,并且所述第一多核苷酸的3'转座子末端序列藉以转移至所述片段的至少一条链的5'末端的条件下,将所述靶DNA施加于所述固体支持物;从而产生双链片段的固定的文库,其中至少一条链是用所述第一标签在5'-加标签的。
项目2.根据项目1所述的方法,其中所述第一多核苷酸被固定至所述固体支持物。
项目3.根据项目1所述的方法,其中所述转座体复合物包含第二多核苷酸,所述第二多核苷酸包含与所述转座子末端序列互补的区域。
项目4.根据项目1所述的方法,所述方法还包括洗涤所述固体支持物以移除任何未结合的核酸。
项目5.根据项目1所述的方法,其中所述转座体复合物以至少103、104、105、106个复合物每mm2的密度存在于所述固体支持物上。
项目6.根据项目1所述的方法,其中所述转座体复合物包含超活性Tn5转座酶。
项目7.根据项目1所述的方法,其中所述固定的文库中的所述双链片段的长度通过增加或减少存在于所述固体支持物上的转座体复合物的密度来调整。
项目8.根据项目1所述的方法,其中存在于所述固体支持物上的至少50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%的所述标签包含相同的标签域。
项目9.根据项目1所述的方法,所述方法还包括:(c)提供溶液中的转座体复合物,并在所述靶DNA藉以被转座体复合物溶液片段化的条件下使所述转座体复合物与所述固定的片段接触;从而获得具有一个末端在溶液中的固定的核酸片段。
项目10.根据项目9所述的方法,其中所述溶液中的转座体复合物包含第二标签,从而产生具有第二标签在溶液中的固定的核酸片段。
项目11.根据项目10所述的方法,其中所述第一标签和所述第二标签是不同的。
项目12.根据项目9所述的方法,其中溶液中的至少50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%的所述转座体复合物包含第二标签,所述第二标签包含第二标签域。
项目13.根据项目9所述的方法,所述方法还包括通过提供聚合酶和对应于所述第一多核苷酸的部分的扩增引物来扩增所述固体表面上的所述片段。
项目14.根据项目1所述的方法,其中所述标签域包含用于簇扩增的区域。
项目15.根据项目1所述的方法,其中所述标签域包含用于引发测序反应的区域。
项目16.根据项目1所述的方法,其中所述固体支持物包括微粒。
项目17.根据项目1所述的方法,其中所述固体支持物包括模式化的表面。
项目18.根据项目1所述的方法,其中所述固体支持物包括孔。
项目19.根据项目1所述的方法,所述方法还包括将嵌入染料施加于所述固定的片段的至少一部分以获得染色的固定的片段的组;并获得所述染色的固定的片段的图像。
项目20.根据项目1所述的方法,其中施加靶DNA包括将生物样品添加至所述固体支持物。
项目21.根据项目20所述的方法,其中所述生物样品包括细胞裂解物。
项目22.根据项目20所述的方法,其中所述生物样品包括全细胞。
项目23.根据项目20所述的方法,其中所述生物样品选自由以下组成的组:血液、血浆、血清、淋巴液、粘液、痰、尿液、精液、脑脊液、支气管抽出物、排泄物和浸渍的组织。
项目24.根据项目1-23中任一项所述的方法制备的具有加标签的DNA片段的文库固定于其上的固体支持物。
项目25.一种固体支持物,所述固体支持物具有转座体复合物固定于其上,其中所述转座体复合物包含结合至第一多核苷酸的转座酶,所述多核苷酸包含(i)3’部分,所述3’部分包含转座子末端序列,以及(ii)第一标签,所述第一标签包含第一标签域。
项目26.根据项目25所述的固体支持物,其中所述转座体复合物以至少103、104、105、106个复合物每mm2的密度存在于所述固体支持物上。
项目27.根据项目25所述的固体支持物,其中所述转座体复合物结合至固定的寡核苷酸。
项目28.根据项目25所述的固体支持物,其中所述标签域包括用于簇扩增的区域。
项目29.根据项目25所述的固体支持物,其中所述标签域包括用于引发测序反应的区域。
项目30.根据项目25所述的固体支持物,其中所述转座体复合物包含超活性Tn5转座酶。
项目31.根据项目25所述的固体支持物,其中所述固体支持物包括微粒。
项目32.根据项目25所述的固体支持物,其中所述固体支持物包括模式化的表面。
项目33.根据项目25所述的固体支持物,其中所述固体支持物包括孔。
项目34.根据项目25所述的固体支持物,其中所述转座体复合物包含超活性Tn5转座酶。
项目35.一种产生流通池的方法,所述方法包括将多个转座体复合物固定至固体支持物,所述转座体复合物包含结合至第一多核苷酸的转座酶,所述第一多核苷酸包含(i)3’部分,所述3’部分包含转座子末端序列,以及(ii)第一标签,所述第一标签包含第一标签域。
项目36.根据项目35所述的方法,其中所述固定包括(a)提供具有多个所述第一多核苷酸固定于其上的固体支持物,以及(b)使所述固体支持物与转座酶全酶和第二多核苷酸接触,所述第二多核苷酸包含与所述转座子末端序列互补的区域。
项目37.根据项目36所述的方法,其中在所述第二多核苷酸与所述第一多核苷酸杂交之后,使转座酶全酶与所述固体支持物接触。
项目38.根据项目36所述的方法,其中转座酶全酶和所述第二多核苷酸同时与所述固体支持物接触。
项目39.根据项目35所述的方法,其中所述转座体复合物在溶液中被组装,并且所述固定包括将所述第一多核苷酸与夹板寡核苷酸连接,所述夹板寡核苷酸被偶联至所述固体支持物。
项目40.根据项目35所述的方法,其中所述第一多核苷酸首先被固定至所述固体支持物,并与具有第一末端和第二末端的带环的寡核苷酸杂交,所述带环的寡核苷酸在所述第一末端与所述固定的第一多核苷酸杂交,并在所述第二末端与溶液相第一多核苷酸杂交。
项目41.根据项目40所述的方法,其中所述固定的第一多核苷酸和所述溶液相第一多核苷酸包含不同的转座子末端序列并且所述带环的寡核苷酸在所述第一末端和所述第二末端包含与所述不同的转座子末端序列的每个互补的序列。
项目42.根据项目35所述的方法,其中所述固定包括(a)提供具有扩增引物偶联至其的固体支持物;(b)使第二多核苷酸与所述扩增引物之一杂交,所述第二寡核苷酸包含与转座子末端序列互补的区域和与所述第一标签互补的区域;(c)使用聚合酶延伸所述扩增引物以产生包含与所述第二多核苷酸杂交的所述第一多核苷酸的双链体,所述第一多核苷酸直接地固定至所述固体支持物;以及(d)使所述固体支持物与转座酶全酶接触,从而在所述固体支持物上组装转座体复合物。
项目43.根据项目35所述的方法,其中所述标签域包括用于簇扩增的区域。
项目44.根据项目35所述的方法,其中所述标签域包括用于引发测序反应的区域。
项目45.根据项目35所述的方法,其中所述转座体复合物包含超活性Tn5转座酶。
项目46.根据项目35所述的方法,其中所述固体支持物包括微粒。
项目47.根据项目35所述的方法,其中所述固体支持物包括模式化的表面。
项目48.根据项目35所述的方法,其中所述固体支持物包括孔。
项目49.根据项目35所述的方法,其中所述转座体复合物以至少103、104、105、106个复合物每mm2的密度存在于所述固体支持物上。
项目50.一种流通池,所述流通池利用根据项目35-49中任一项所述的方法制备。
项目51.一种微粒群体,所述微粒群体具有固定至其的转座体复合物,所述转座体复合物包含结合至第一多核苷酸的转座酶和第二多核苷酸;其中所述第一多核苷酸在其5'末端被固定至所述微粒的表面并且所述第二多核苷酸与所述第一多核苷酸的3'末端杂交;并且其中所述第一多核苷酸包含:(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域。
项目52.根据项目51所述的微粒群体,其中所述第二多核苷酸包含与所述转座子末端序列互补的区域。
项目53.根据项目51所述的微粒群体,其中所述第二多核苷酸的长约10、11、12、13、14、15、16、17、18、19、20bp。
项目54.根据项目51所述的微粒群体,其中所述第二多核苷酸在其5'末端被磷酸化。
项目55.根据项目51所述的微粒群体,其中每个微粒包括多个所述转座酶复合物。
项目56.根据项目55所述的微粒群体,每个微粒包括第一多核苷酸的第一子群体和第二子群体,其中所述第一子群体包括第一标签域并且所述第二子群体包括第二标签域。
项目57.根据项目51所述的微粒群体,其中每个微粒包括不多于一个所述转座酶复合物。
项目58.根据项目51所述的微粒群体,所述第一多核苷酸还包含索引域。
项目59.根据项目58所述的微粒群体,所述群体包括多个在所述第一多核苷酸上的索引域。
项目60.根据项目51所述的微粒群体,其中所述转座体复合物包含超活性Tn5转座酶。
项目61.根据项目51所述的微粒群体,其中所述微粒为珠。
项目62.根据项目51所述的微粒群体,其中所述微粒为顺磁性的。
项目63.根据项目51所述的微粒群体,其中所述微粒群体还包括缺少转座酶的微粒的子群体。
项目64.根据项目51所述的微粒群体,其中所述微粒群体还包括缺少所述第一多核苷酸的微粒的子群体。
项目65.一种制备加标签的DNA片段的固定的文库的方法,所述方法包括使靶DNA与项目51-64中任一项所述的微粒群体接触,以产生固定的加标签的DNA片段。
项目66.根据项目65所述的方法,其中所述接触包括将所述DNA沉淀至一个或更多个所述微粒上。
项目67.根据项目65所述的方法,所述方法还包括固定所述微粒。
项目68.根据项目66所述的方法,其中所述微粒是顺磁性的并且所述固定包括将外部磁场施加至所述微粒。
项目69.根据项目65所述的方法,所述方法还包括从所述固体支持物释放所述固定的加标签的DNA片段。
项目70.根据项目69所述的方法,其中所述释放包括从所述固体支持物裂解所述标签域。
项目71.根据项目69所述的方法,其中所述释放包括进行抑制PCR。
项目72.一种产生加标签的DNA片段文库的方法,所述加标签的DNA片段文库用于索引定向的组装为较长的序列读段,所述方法包括:提供具有转座体复合物固定至其的微粒群体,所述转座体复合物包含结合至第一多核苷酸的转座酶和第二多核苷酸,所述第一多核苷酸包含与所述微粒缔合的索引域;将靶DNA施加至所述微粒群体,从而产生用所述索引域加标签的固定的DNA片段。
项目73.根据项目72所述的方法,其中所述第一多核苷酸在其5'末端被固定至所述微粒的表面并且所述第二多核苷酸与所述第一多核苷酸的3'末端杂交;并且其中所述第一多核苷酸包含:(i)3’部分,所述3’部分包含转座子末端序列,以及(ii)所述索引域;并且其中所述微粒群体包括至少多个索引域,并且其中单个微粒上的所述第一多核苷酸共用相同的索引域。
项目74.根据项目72所述的方法,所述方法还包括从所述微粒释放所述加标签的DNA片段。
项目75.根据项目74所述的方法,其中所述释放包括裂解所述第一多核苷酸。
项目76.根据项目74所述的方法,其中所述释放包括进行抑制PCR。
项目77.根据项目72所述的方法,其中所述第一多核苷酸包含用于从所述微粒释放所述第一多核苷酸的裂解域。
项目78.根据项目72所述的方法,其中所述第一多核苷酸包含用于簇扩增的区域。
项目79.根据项目72所述的方法,其中所述第一多核苷酸包含用于引发测序反应的区域。
项目80.根据项目72所述的方法,其中所述转座体复合物包含超活性Tn5转座酶。
项目81.根据项目72所述的方法,其中所述微粒群体分布于固体表面上。
项目82.根据项目81所述的方法,其中所述固体表面包括孔的阵列。
项目83.根据项目82所述的方法,其中多个所述孔包括每孔一个微粒。
项目84.根据项目73所述的方法,其中通过将外部磁场施加至所述微粒来使群体分布。
项目85.根据项目72所述的方法,所述方法还包括进行测序反应以确定所述索引域和所述加标签的DNA片段的至少一部分的序列。
项目86.根据项目85所述的方法,所述方法还包括组装共有共同的索引域的DNA序列,从而产生包含多个子片段的较长的序列读段。
项目87.根据项目85所述的方法,所述方法还包括确定所述序列读段中的定相SNP。
项目88.根据项目72所述的方法,其中所述施加包括将所述DNA沉淀至一个或更多个所述微粒上。
项目89.一种用于测序多个靶DNA分子的方法,所述方法包括:a)在靶DNA藉以被转座体复合物片段化的条件下,将多个所述靶DNA施加至具有所述转座体复合物固定至其上的固体支持物上;从而产生双链片段的固定文库,其中每个靶DNA的第一部分在所述固体支持物上的第一位置处被附接至所述固体支持物,并且每个靶DNA的第二部分在所述固体支持物上的第二位置处被附接至所述固体支持物;以及b)绘制所述双链片段的固定的文库的图谱以产生由每个靶DNA连接的位置的组;c)确定所述靶DNA的所述第一部分和所述第二部分的序列;以及d)关联所述位置的组以确定第一部分和第二部分的哪些被所述靶DNA连接,以及确定所述靶DNA分子的序列。
项目90.根据项目89所述的方法,其中步骤c)包括裂解所述固定的双链片段以释放游离末端。
项目91.根据项目90所述的方法,其中所述裂解包括裂解可裂解位点。
项目92.根据项目91所述的方法,其中所述可裂解位点包含修饰的核苷酸或为限制性酶切位点。
项目93.根据项目90所述的方法,其中所述裂解包括使固定的双链片段与溶液相转座酶复合物接触。
项目94.根据项目89所述的方法,其中绘制图谱包括产生所述固定的DNA的物理图谱。
项目95.根据项目94所述的方法,其中所述物理图谱通过成像DNA来产生以确立跨所述固体表面的所述固定的DNA分子的位置。
项目96.根据项目95所述的方法,其中固定的多核苷酸通过将成像剂添加至所述固体支持物并检测来自所述成像剂的信号来成像。
项目97.根据项目96所述的方法,其中所述成像剂包括可检测的标记物。
项目98.根据项目96所述的方法,其中所述成像剂包括嵌入染料。
项目99.根据项目89所述的方法,其中所述固体支持物包括流通池。
项目100.根据项目99所述的方法,其中所述固体支持物包括纳米通道。
项目101.根据项目99所述的方法,其中所述固体支持物包括具有多个分开的纳米通道的流通池。
项目102.根据项目99所述的方法,其中所述固体支持物包括至少10、50、100、200、500、1000、3000、5000、10000、30000、50000、80000或至少100000个纳米通道。
项目103.根据项目101所述的方法,其中每个纳米通道包括不多于1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、30、40、50、60、70、80、90、100、200、300、400、500、600、700、800、900或不多于1000个单独的长链靶DNA每纳米通道。
附图简述
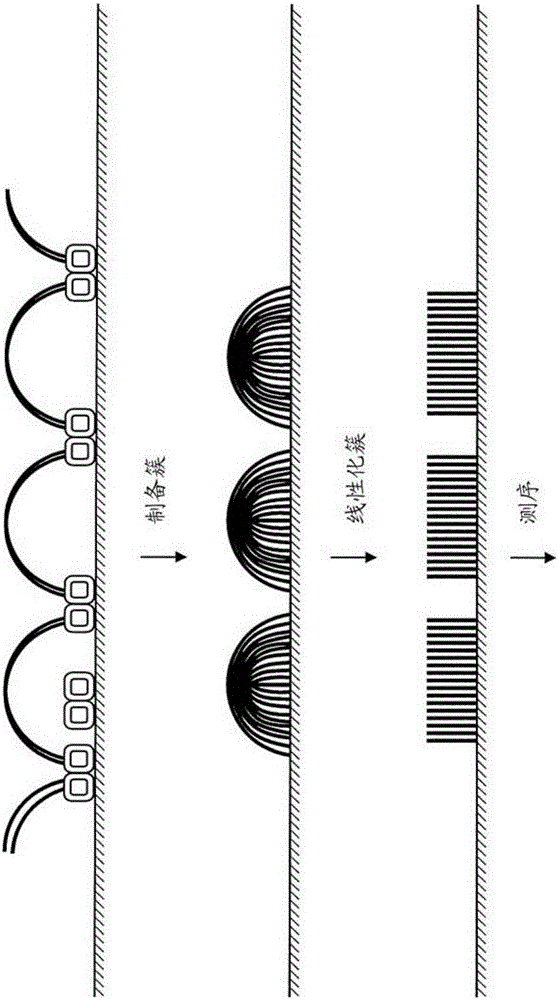
图1a显示了根据一个实施方案的一般性概念。图1b显示了根据一个实施方案的一般性概念。
图2a是阐述标签化(tagmentation)反应的示意图。
图2b是重绘得到的桥以阐明得到的桥的性质的示意图。
图3a阐述了其中两种形式的转座体被组装在流通池的表面上的实施方案。将DNA添加至流通池导致DNA的标签化以及将DNA偶联至转座体。在图3a中还显示了不同类型的得到的簇:P7:P7、P5:P5和P5:P7簇。3b阐述了其中两种形式的转座体被组装在流通池的表面上的实施方案。
图4a阐述了另一个实施方案。在图4a中,只存在一种形式的表面结合的转座体(例如,P5转座体),得到在每个末端具有相同的标签序列的桥。添加另外的转座体以进一步片段化桥结构并且并入另外的标签序列(P7)。
图4b显示了扩增以产生从每个转座体残余部分(stump)得到的簇的对,所述簇的对代表了起始的完整的DNA样品中两个相邻的片段(图4b)。
图5a、5b、5c和5d阐述了用于组装表面结合的转座体复合物的不同的方法。图5a显示了这种用于组装表面结合的转座体复合物的方法的一个实施方案。图5b显示了在溶液中组装的转座体复合物并且固定包括将第一多核苷酸与夹板(splint)寡核苷酸连接的另外的步骤,所述夹板寡核苷酸偶联至固体支持物。图5c显示了转座体二聚体通过使带环的寡核苷酸(looped oligonucleotide)与固定的第一多核苷酸杂交来组装。图5d显示转座体复合物可被组装在具有扩增引物固定至其上的标准成对末端流通池上。
图6a阐述了用于作为实施例1提出的实验的设计。图6b阐述了用于作为实施例1提出的实验的设计。
图7阐述了在根据实施例1中提出的设计进行的实验中获得的代表性数据。
图8阐述了在根据实施例1中提出的设计进行的实验中获得的代表性数据。
图9是根据一个实施方案组装珠结合的转座体并且随后标签化的图解。
图10是根据一个实施方案组装珠结合的转座体并且随后标签化的图解。
图11是根据一个实施方案组装珠结合的转座体并且随后标签化的图解。
图12是根据一个实施方案组装珠结合的转座体并且随后标签化的图解。
图13是根据一个实施方案的表面结合的转座体的图解。
图14是根据一个实施方案在珠结合的转座体上进行标签化的图解。
图15是根据一个实施方案在珠结合的转座体上进行子片段的标签化和条形码化的图解。
图16是根据一个实施方案在珠结合的转座体上进行子片段的标签化和条形码化的图解。
图17是如在实施例3中描述的转座体组装的图解。
图18a是如在实施例3中描述的转座体组装的图解。
图18b阐述了如在实施例3中描述的利用转座体组装的结果。
详述
用于测序核酸样品的现有方案常规地使用将DNA或RNA转换为模板文库的样品制备方法。这些方法可导致DNA样品的丢失并且通常需要用于片段化的昂贵的设备。另外,样品制备方法通常是困难、冗长且低效的。
在标准样品制备方法中,每个模板在任一插入物末端含有适体并且通常需要很多步骤以修饰DNA或RNA并纯化期望的修饰反应产物。在将适合的片段添加至流通池之前,在溶液中进行这些步骤,其中适合的片段通过引物延伸反应被偶联至表面,所述引物延伸反应将杂交的片段拷贝至共价地附接至表面的引物的末端。然后这些‘接种’模板通过若干个循环的扩增产生拷贝的模板的单克隆簇。
在溶液中将DNA转化成适体修饰的模板,为形成簇和测序做准备所需要的步骤的数目可通过使用转座酶介导的片段化和加标签来最小化。本文被称作“标签化(tagmentation)”的该方法通常包括DNA通过包含与含有转座子末端序列的适体复合的转座酶的转座体复合物的修饰。标签化导致同时的DNA的片段化和适体与双链体片段的两条链的5’末端的连接。纯化步骤去除转座酶之后,另外的序列通过PCR被添加至适合的片段的末端。
基于溶液的标签化具有缺点并且需要若干劳动密集的步骤。另外,在PCR扩增步骤期间可引入偏倚。本文提供的方法和组合物克服了这些缺点并且允许无偏倚样品制备、簇形成和测序发生在单固体支持物上,对样品操作或转移的需求最小。
本公开内容涉及出乎意料的发现,预偶联至流通池的表面的转座体复合物可在流通池内有效地片段化、加标签并固定完整的DNA。在特定的实施方案中,包含转座体适体的一个或更多条链经由其5'末端被附接至流通池的表面。当完整的DNA被泵至流通池上时,标签化反应以与在基于溶液的标签化反应中发生的相同方式发生,但是得到的产物片段通过其末端物理地附接至流通池的表面。转座体适体序列可包含使随后能够产生簇并测序的序列。
本文提供的方法和组合物提供了超过基于溶液的标签化方法的若干优势。例如,纯化的、部分纯化的或甚至未纯化的完整的DNA模板可被直接地上样至流通池,用于产生簇,而无之前的样品制备。另外,初始的完整DNA中序列信息的连续性可通过在流通池表面上并置标签化的(tagmented)片段来物理地保存。作为另外的优势,DNA被物理地连接至流通池的表面,所以在DNA的进一步操作之后反应物的纯化可通过流通池通道中的流通缓冲液交换来完成。
固体支持物上的标签化
根据以上,本文提供了制备加标签的DNA片段的固定的文库的方法。在一些实施方案中,方法可包括:(a)提供具有转座体复合物固定于其上的固体支持物,其中转座体复合物包含结合至第一多核苷酸的转座酶,第一多核苷酸包含(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域;和(b)在靶DNA藉以被转座体复合物片段化,并且第一多核苷酸的3'转座子末端序列藉以被转移至片段的至少一条链的5'末端的条件下,将靶DNA施于固体支持物;从而产生双链片段的固定的文库,其中至少一条链是用第一标签在5'-加标签的。
如本文使用的,术语“转座体复合物”通常地指非共价地结合至双链核酸的转座酶。例如,复合物可以是在支持非共价复合物形成的条件下与双链转座子DNA预孵育的转座酶。双链转座子DNA可包括但不限于Tn5 DNA、Tn5 DNA的部分、转座子末端成分、转座子末端成分的混合物或能与转座酶诸如超活性Tn5转座酶相互作用的其他双链DNA。
“转座酶”指能与含有转座子末端的成分(例如,转座子、转座子末端、转座子末端成分)形成功能性复合物且例如能在体外转座反应中催化含转座子末端的成分插入或转座至与其一起孵育的双链靶DNA的酶。如本文提供的转座酶还可包括来自逆转录转座子和逆转录病毒的整合酶。转座酶、转座体和转座体复合物通常地是为本领域技术人员所熟知的,如由US 2010/0120098的公开内容所例证的,通过引用其内容全部并入本文。尽管本文描述的很多实施方案涉及Tn5转座酶和/或超活性Tn5转座酶,但是将领会能以足够的效率将转座子末端插入5'-标签并片段化靶DNA的任何转座系统为了其意图的目的可在本发明中使用。在特定的实施方案中,优选的转座系统能以随机或几乎随机的方式将转座子末端插入至5'-标签并片段化靶DNA。
术语“转座子末端”指仅展现核苷酸序列(“转座子末端序列”)的双链核酸DNA,所述核苷酸序列对于与在体外转座反应中是功能性的转座酶或整合酶形成复合物是必要的。在一些实施方案中,转座子末端能与转座反应中的转座酶形成功能性的复合物。作为非限制性实例,转座子末端可包括19-bp外末端(“OE”)转座子末端、内末端(“IE”)转座子末端、或被野生型或突变Tn5转座酶识别的“马赛克(mosaic)末端”(“ME”)转座子末端、或如在US 2010/0120098的公开内容中描述的R1和R2转座子末端,其内容通过引用将其全部并入本文。转座子末端可包括适于在体外转座反应中与转座酶或整合酶形成功能性复合物的核酸或核酸类似物。例如,转座子末端可包括DNA、RNA、修饰碱基、非天然碱基、修饰的骨架,并且可在一条或两条链中包含缺口。尽管术语“DNA”贯穿本公开内容与转座子末端的成分相连使用,但是应理解任何合适的核酸或核酸类似物可在转座子末端中被使用。
术语“转移链(transferred strand)”指两个转座子末端的转移部分。相似地,术语“非转移链(non-transferred strand)”指两个“转座子末端”的非转移部分。转移链的3'-末端在体外转座反应中被连接或转移至靶DNA。展现出与转移的转座子末端序列互补的转座子末端序列的非转移链在体外转座反应中不被连接或转移至靶DNA。
在一些实施方案中,转移链和非转移链被共价地连接。例如,在一些实施方案中,在单寡核苷酸上提供转移链序列和非转移链序列,所述单寡核苷酸例如,在发卡构造中。像这样,尽管非转移链的自由末端不通过转座反应直接地连接至靶DNA,但是非转移链变成间接地附接至DNA片段,因为非转移链通过发卡结构的环连接至转移链。转座体结构的另外的实例以及制备和使用转座体的方法可发现于US 2010/0120098的公开内容中,其内容通过引用将其全部并入本文。
如本文使用的术语“标签”和“标签域”指展现出用于期望的意图的目的或应用的序列的多核苷酸的部分或域。本文提供的一些实施方案包括如下转座体复合物:所述转座体复合物包含多核苷酸,所述多核苷酸具有含有转座子末端序列的3'部分和含有标签域的标签。标签域可包含提供任何期望的目的的任何序列。例如,在一些实施方案中,标签域包含一个或更多个限制性内切核酸酶识别位点。在一些实施方案中,标签域包含适于与用于簇扩增反应的引物杂交的一个或更多个区域。在一些实施方案中,标签域包含适于与用于测序反应的引物杂交的一个或更多个区域。将领会任何其他合适的特征可被并入标签域。在一些实施方案中,标签域包含具有5和200bp之间的长度的序列。在一些实施方案中,标签域包含具有10和100bp之间的长度的序列。在一些实施方案中,标签域包含具有20和50bp之间的长度的序列。在一些实施方案中,标签域包含具有5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、150和200bp之间的长度的序列。
在本文提供的方法和组合物中,转座体复合物被固定至固体支持物上。在一些实施方案中,转座体复合物经由一个或更多个多核苷酸被固定至支持物,所述多核苷酸诸如包含转座子末端序列的多核苷酸。在一些实施方案中,转座体复合物可经由将转座酶偶联至固体支持物的接头分子被固定。在一些实施方案中,转座酶和多核苷酸两者均被固定至固体支持物。当提及将分子(例如,核酸)固定至固体支持物时,术语“固定”和“附接”在本文是可互换地使用的,并且两个术语均意图涵盖直接或间接的、共价或非共价的附接,除非另有明确地或通过上下文的指示。在本发明的某些实施方案中,共价附接可以是优选的,但是通常地所有需要的是,分子(例如,核酸)在于其中意图使用支持物的条件下保持固定或附接至支持物,例如在需要核酸扩增和/或测序的应用中。
本发明的某些实施方案可使用包括惰性基底或基质(例如,载玻片、聚合物珠等)的固体支持物,所述惰性基底或基质已例如通过应用含有活性基团的中间材料的层或包衣而被功能化,所述活性基团允许共价附接至诸如多核苷酸的生物分子。此类支持物的实例包括但不限于负载于诸如玻璃的惰性基底上的聚丙烯酰胺水凝胶,特别是WO 2005/065814和US 2008/0280773中描述的聚丙烯酰胺水凝胶,其内容通过引用将其全部并入本文。在此类实施方案中,生物分子(例如多核苷酸)可被直接地共价地附接至中间材料(例如水凝胶),但是中间材料其自身可被非共价地附接至基底或基质(例如,玻璃基底)。术语“共价附接至固体支持物”要相应地理解为包括这种排列类型。
本文中术语“固体表面”、“固体支持物”和其他语法等同物指适合于或可被修饰以适合用于附接转座体复合物的任何材料。如本领域人员将领会的,可能的基底的数目是很巨大的。可能的基底包括但不限于:玻璃和改性的或功能化的玻璃、塑料(包括丙烯酸树脂、聚苯乙烯以及苯乙烯和其他材料的共聚物、聚丙烯、聚乙烯、聚丁烯、聚氨酯、TeflonTM等)、多糖、尼龙或硝酸纤维素、陶瓷、树脂、二氧化硅或基于二氧化硅的材料包括硅和改性的硅、碳、金属、无机玻璃、塑料、光学纤维束、和很多其他聚合物。对于一些实施方案特别地有用的固体支持物和固体表面位于流通池装置内。示例性流通池在以下被更详细地描述。
在一些实施方案中,固体支持物包括适于以有序的模式固定转座体复合物的模式化的表面。“模式化的表面”指在固体支持物的暴露层中或暴露层上不同区域的排列。例如,区域中的一个或更多个可以是其中存在一个或更多个转座体复合物的特征。特征可被其中不存在转座体复合物的间隙区域分开。在一些实施方案中,模式可以是行和列形式的形状的x-y格式。在一些实施方案中,模式可以是特征和/或间隙区域的重复排列。在一些实施方案中,模式可以是特征和/或间隙区域的随机排列。在一些实施方案中,转座体复合物在固体支持物上随机地分布。在一些实施方案中,转座体复合物在模式化的表面上分布。可在本文描述的方法和组合物中使用的示例性模式化的表面被描述于美国系列号13/661,524或美国专利申请公布2012/0316086 A1中,通过引用将其每个并入本文。
在一些实施方案中,固体支持物包括表面中的孔或凹的阵列。如本领域普遍所知的,这可利用多种技术被制造,包括但不限于照相平板印刷术、冲压技术、塑模技术和显微蚀刻技术。如将被本领域人员所领会的,使用的技术将取决于阵列基底的组成和形状。
固体支持物的组成和几何结构可随其使用而不同。在一些实施方案中,固体支持物是平面结构,诸如载片、芯片、微芯片和/或阵列。像这样,基底的表面可以是平面层的形式。在一些实施方案中,固体支持物包括流通池的一个或更多个表面。如本文使用的术语“流通池”指包含固体表面的室,一种或更多种流体试剂可流动穿过所述室。可在本公开内容的方法中容易地使用的流通池和相关流体系统和检测平台的实例被描述于例如Bentley等人,Nature 456:53-59(2008);WO 04/018497;US 7,057,026;WO 91/06678;WO 07/123744;US 7,329,492;US 7,211,414;US 7,315,019;US 7,405,281和US 2008/0108082中,通过引用将其每个并入本文。
在一些实施方案中,固体支持物或其表面是非平面的,诸如管或容器的内表面或外表面。在一些实施方案中,固体支持物包括微球或珠。本文中“微球”或“珠”或“颗粒”或语法上的等同物是指小的离散颗粒。合适的珠成分包括但不限于塑料、陶瓷、玻璃、聚苯乙烯、甲基苯乙烯、丙烯酸聚合物、顺磁材料、二氧化钍溶胶、碳石墨、二氧化钛、乳胶或交联葡聚糖诸如Sepharose、纤维素、尼龙、交联胶束和teflon,以及本文概述用于固体支持物的任何其他材料可全部被使用。来自Bangs Laboratories,Fishers Ind.的“微球检测指南(Microsphere Detection Guide)”是有用的指南。在某些实施方案中,微球为磁性微球或珠。
珠不必是球形的;不规则颗粒可被使用。可选地或另外的,珠可以是多孔的。珠大小范围从纳米即100nm至毫米即1mm,从约0.2微米至约200微米的珠是优选的,并且从约0.5至约5微米的珠是特别地优选的,尽管在一些实施方案中,更小或更大的珠可被使用。
图1a和1b一般性地阐述了根据一个实施方案的方法。显示了用接枝的寡核苷酸包被的固体支持物,其一些含有ME序列,在Tn5的存在下将形成物理地偶联至固体支持物的活性转座体复合物。这些表面结合的转座体的密度可通过改变含ME序列的接枝寡核苷酸的密度或通过添加至固体支持物的转座酶的量来调整。例如,在一些实施方案中,转座体复合物以至少103、104、105、或至少106个复合物每mm2的密度存在于固体支持物上。
当双链DNA被添加至固体支持物上时,转座体复合物将对添加的DNA标签化,从而产生在表面的两端偶联的双链片段。在一些实施方案中,桥接的片段的长度可通过改变表面上的转座体复合物的密度而变化。在某些实施方案中,得到的桥接片段的长度小于100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1000bp、1100bp、1200bp、1300bp、1400bp、1500bp、1600bp、1700bp、1800bp、1900bp、2000bp、2100bp、2200bp、2300bp、2400bp、2500bp、2600bp、2700bp、2800bp、2900bp、3000bp、3100bp、3200bp、3300bp、3400bp、3500bp、3600bp、3700bp、3800bp、3900bp、4000bp、4100bp、4200bp、4300bp、4400bp、4500bp、4600bp、4700bp、4800bp、4900bp、5000bp、10000bp、30000bp或小于100,000bp。在此类实施方案中,然后桥接的片段可利用标准簇化学反应被扩增入簇中,如通过美国专利号7,985,565和7,115,400的公开内容所例证的,其每个的内容通过引用将其全部并入本文。
在一些实施方案中,模板的长度比利用标准簇化学反应可合适地扩增的长。例如,在一些实施方案中,模板的长度长于100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1000bp、1100bp、1200bp、1300bp、1400bp、1500bp、1600bp、1700bp、1800bp、1900bp、2000bp、2100bp、2200bp、2300bp、2400bp、2500bp、2600bp、2700bp、2800bp、2900bp、3000bp、3100bp、3200bp、3300bp、3400bp、3500bp、3600bp、3700bp、3800bp、3900bp、4000bp、4100bp、4200bp、4300bp、4400bp、4500bp、4600bp、4700bp、4800bp、4900bp、5000bp、10000bp、30000bp或长于100,000bp。在此类实施方案中,然后可通过添加来自溶液的转座体进行第二标签化反应,所述第二标签化反应使桥进一步片段化,如例如在图4a中阐述的。第二标签化反应可因此移除桥的内跨部分(span),留下短的残余部分锚至表面,所述短的残余部分能转变成簇为进一步的测序步骤做准备。在特定的实施方案中,模板的长度可在由选自以上示例性的这些的上限和下限界定的范围内。
在某些实施方案中,在簇产生之前,通过表面标签化来固定的DNA可被成像。例如,固定的DNA可用嵌入染料染色并成像以保存表面上的DNA分子的骨架的位置的记录。簇产生和测序之后,簇的坐标可与其在原始骨架上的位置相关,从而有助于沿着分子的读段的比对以及基因组组装。
在一些实施方案中,施加靶DNA的步骤包括将生物样品添加至所述固体支持物。生物样品可以是含有DNA的任何类型并且其可被放置于固体支持物上用于标签化。例如,样品可包含多种纯化状态的DNA,所述多种纯化状态的DNA包括纯化的DNA。但是,样品不需是完全地纯化的,并且可包括例如与蛋白混合的DNA、其他核酸种类、其他细胞组分和/或任何其他污染物。如在以下实施例2中证实的,在一些实施方案中,生物样品包括以如在体内发现的大约相同的比例存在的DNA、蛋白质、其他核酸种类、其他细胞组分和/或任何其他污染物的混合物。例如,在一些实施方案中,组分以与在完整的细胞中发现的相同的比例被发现。在一些实施方案中,生物样品具有小于2.0、1.9、1.8、1.7、1.6、1.5、1.4、1.3、1.2、1.1、1.0、0.9、0.8、0.7或小于0.60的260/280比率。在一些实施方案中,生物样品具有至少2.0、1.9、1.8、1.7、1.6、1.5、1.4、1.3、1.2、1.1、1.0、0.9、0.8、0.7或至少0.60的260/280比率。因为本文提供的方法允许DNA被结合至固体支持物,所以其他污染物只能通过在表面结合的标签化发生之后洗涤固体支持物来移除。生物样品可包括例如粗制细胞裂解物或全细胞。例如,以本文描述的方法施于固体支持物的粗制细胞裂解物不需已经受一个或更多个分离步骤,所述分离步骤常规地被用来从其它细胞组分分离核酸。示例性分离步骤被描述于Maniatis等人,Molecular Cloning:A Laboratory Manual,第二版,1989,和Short Protocols in Molecular Biology,编著Ausubel等人中,通过引用在此并入。
因此,在一些实施方案中,生物材料可包括例如血液、血浆、血清、淋巴液、粘液、痰、尿液、精液、脑脊液、支气管抽出物、排泄物和浸渍的组织,或其裂解物,或含有DNA的任何其他生物样品。本文提供的方法和组合物的一个优势是生物样品可被添加至流通池并且随后的裂解和纯化步骤可简单地通过使必需的反应物流入流通池而全部发生于流通池中,而无另外的转移或操作步骤。以下的实施例1和2证实粗制细胞裂解物成功的应用到本文提供的方法和组合物。
图2a和2b还阐述了根据一个实施方案的标签化反应。如在图2a中显示的,转座体包括Tn5的二聚体,每个单体结合双链分子,即ME适体。ME适体的一条链被共价地附接至流通池的表面。转座体结合靶DNA并在DNA骨架中产生两个缺口,在任一链上相距9个碱基。尽管图2a显示了缺口之间的9bp空隙,但是在其他实施方案中,转座体可在缺口之间产生7、8、9、10、11或12bp的空隙。每个ME适体的两条链中只有一条在每个缺口位置被连接至5'链。这种链“转移链”经由其5'末端被接枝至流通池的表面。在图2b中重绘了表面标签化得到的桥以阐明得到的桥的性质。
图3a和3b阐述了发明应用于实践的实例。3b阐述了其中两种形式的转座体被组装在流通池的表面上。第一形式包括P7转座体,其中ME适体的‘转移链’包含将转座体连接至包含扩增域(P7)和测序引物(S2)的表面的延伸的寡核苷酸序列。第二形式包括P5转座体,其中ME适体的‘转移链’包含将转座体连接至包含扩增域(P5)和测序引物(S1)的表面的延伸的寡核苷酸序列。将DNA添加至流通池导致DNA的标签化以及将DNA偶联至转座体。三种类型的桥结果:P5-P5、P7-P7和P5-P7。在簇形成和线性化之后(图3b),P5-P5或P7-P7簇被移除(取决于线性化)。如在图3b中显示的,如果线性化经由P5发生,则只有P5-P7和P7-P7桥保留。P7-P7簇不通过该反应线性化,并且因此将不会被测序。在用于测序的读段2线性化期间,随后移除P7-P7簇。
本文提供的方法还可包括在溶液中提供转座体复合物,并在靶DNA藉以被转座体复合物溶液片段化的条件下使固相转座体复合物与固定的片段接触的另外的步骤;从而获得具有一个末端在溶液中的固定的核酸片段。在一些实施方案中,溶液中的转座体复合物可包含第二标签,以使得所述方法产生具有第二标签的固定的核酸片段,所述第二标签在溶液中。第一和第二标签可以是不同的或相同的。
在一些实施方案中,一种形式的表面结合的转座体主要地存在于固体支持物上。例如,在一些实施方案中,存在于所述固体支持物上的至少50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或至少99%的标签包含相同的标签域。在此类实施方案中,在用表面结合的转座体的初始标签化反应之后,至少50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或至少99%的桥结构在桥的每个末端包含相同的标签域。可通过添加来自溶液的转座体进行第二标签化反应,所述第二标签化反应使桥进一步片段化。在一些实施方案中,大多数或全部的溶液相转座体包含不同于存在于第一标签化反应中产生的桥结构上的标签域的标签域。例如,在一些实施方案中,存在于溶液相转座体中的至少50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或至少99%的标签包含不同于存在于第一标签化反应中产生的桥结构上的标签域的标签域。
图4a和4b阐述了该实施方案。在图4a中显示的固体支持物只包括含有单一类型的标签序列(例如,P5转座体)的表面结合的转座体。在该实例中,所有标签化的桥为P5-P5桥。从溶液添加P7转座体并标签化至桥中,使所有表面结合的分子为P5-P7模板。表面结合的片段可随后地转换为簇(参见例如图4b)。此外,一对簇将从每个转座体残余部分产生,所述转座体残余部分代表了起始的完整DNA样品中两个相邻的片段(图4b)。
本文还提供了根据以上方法制备的具有加标签的DNA片段文库固定于其上的固体支持物。
固定的多核苷酸分子的物理图谱
本文还提供了产生固定的多核苷酸的物理图谱的方法。所述方法可有益地被用来鉴定可能含有连接的序列(即,来自相同的靶多核苷酸分子的第一部分和第二部分)的簇。来源于固定的多核苷酸的任何两个簇的相对距离因此提供对于从两个簇获得的序列信息的比对有用的信息。特别地,固体表面上任何两个给定的簇之间的距离与两个簇来自相同的靶多核苷酸分子的可能性成正相关,如在WO 2012/025250中更详细的描述的,通过引用将其全部并入本文。
作为实例,在一些实施方案中,在流通池的表面上伸出的长的dsDNA分子被原位(in situ)标签化,产生跨流通池的表面的一行连接的dsDNA桥。另外,然后可产生固定的DNA的物理图谱。在扩增固定的DNA后,物理图谱因此关联簇的物理关系。特别地,物理图谱被用来计算从任何两个簇获得的序列数据是关联的可能性,如在并入材料WO 2012/025250中描述的。
在一些实施方案中,物理图谱通过成像DNA来产生以确立跨固体表面的固定的DNA分子的位置。在一些实施方案中,固定的DNA通过将成像剂添加至固体支持物,并检测来自成像剂的信号来成像。在一些实施方案中,成像剂为可检测的标签。合适的可检测标签包括但不限于质子、半抗原、放射性核素、酶、荧光标记物、化学发光标记物、和/或显色剂。例如,在一些实施方案中,成像剂为嵌入染料或非嵌入DNA结合剂。本领域已知的任何合适的嵌入染料或非嵌入DNA结合剂可被使用,包括但不限于在U.S.2012/0282617中描述的那些,通过引用将其并入本文。
在一些实施方案中,在簇产生(图4b)之前,固定的双链片段被进一步片段化以释放出游离末端(参见图4a)。可利用本领域已知的任何合适的方法进行裂解桥接结构,如通过WO 2012/025250的并入材料所例证的。例如,裂解可通过并入修饰的核苷酸,诸如在WO 2012/025250中描述的尿嘧啶;通过并入限制性内切核酸酶位点;或通过将溶液相转座体复合物施加至桥接DNA结构发生,如本文别处描述的。
在某些实施方案中,多个靶DNA分子流至包含多个纳米通道的流通池上,所述纳米通道具有固定至其的多个转座体复合物。如本文使用的,术语纳米通道指长的线性DNA分子流至其中的狭窄通道。在一些实施方案中,不多于1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、30、40、50、60、70、80、90、100、200、300、400、500、600、700、800、900或不多于1000个单独的长链靶DNA(individuallong strands of target DNA)流入每个纳米通道中。在一些实施方案中,单个纳米通道被物理屏障分开,所述物理屏障防止单独的长链靶DNA与多个纳米通道相互作用。在一些实施方案中,固体支持物包括至少10、50、100、200、500、1000、3000、5000、10000、30000、50000、80000或至少100000个纳米通道。在一些实施方案中,结合至纳米通道的表面的转座体将DNA标签化。然后可例如通过按照沿着这些通道之一的长度的簇来进行连续图谱绘制。在一些实施方案中,长链靶DNA的长可以至少0.1kb、1kb、2kb、3kb、4kb、5kb、6kb、7kb、8kb、9kb、10kb、15kb、20kb、25kb、30kb、35kb、40kb、45kb、50kb、55kb、60kb、65kb、70kb、75kb、80kb、85kb、90kb、95kb、100kb、150kb、200kb、250kb、300kb、350kb、400kb、450kb、500kb、550kb、600kb、650kb、700kb、750kb、800kb、850kb、900kb、950kb、1000kb、5000kb、10000kb、20000kb、30000kb、或至少50000kb。在一些实施方案中,长链靶DNA的长可以不多于0.1kb、1kb、2kb、3kb、4kb、5kb、6kb、7kb、8kb、9kb、10kb、15kb、20kb、25kb、30kb、35kb、40kb、45kb、50kb、55kb、60kb、65kb、70kb、75kb、80kb、85kb、90kb、95kb、100kb、150kb、200kb、250kb、300kb、350kb、400kb、450kb、500kb、550kb、600kb、650kb、700kb、750kb、800kb、850kb、900kb、950kb,或不多于1000kb。作为实例,具有1000个或更多个纳米通道、在纳米通道中绘制的固定的标签化产物的图谱的流通池可被用来以短的‘定位的’读段测序生物体的基因组。在一些实施方案中,纳米通道中的绘制的固定的标签化产物的图谱可被用来分析单倍型。在一些实施方案中,纳米通道中的绘制的固定的标签化产物的图谱可被用来解决定相问题。
扩增并测序固定的DNA片段
扩增.本公开内容还涉及根据本文提供的方法产生的固定的DNA片段的扩增。由表面结合的转座体介导的标签化产生的固定的DNA片段可根据本领域已知的任何合适的扩增方法来扩增。在一些实施方案中,在固体支持物上扩增固定的DNA片段。在一些实施方案中,固体支持物是与表面结合的标签化于其上发生的固体支持物相同的固体支持物。在此类实施方案中,本文提供的方法和组合物允许从最初的样品引入步骤至扩增且任选地至测序步骤,样品制备在相同的固体支持物上进行。
例如,在一些实施方案中,固定的DNA片段利用簇扩增方法来扩增,如由美国专利号7,985,565和7,115,400的公开内容所例证的,其每个的内容通过引用以全文并入本文。美国专利号7,985,565和7,115,400的并入的材料描述了固相核酸扩增的方法,其允许扩增产物被固定在固体支持物上,以形成包括固定的核酸分子的簇或“集群”的阵列。在如此阵列上的每个簇或集群从多个相同的固定的多核苷酸链和多个相同的固定的互补多核苷酸链形成。如此形成的阵列本文中通常地被称作“成簇的阵列”。固相扩增反应的产物诸如在美国专利号7,985,565和7,115,400中描述的那些是通过固定的多核苷酸链对和固定的互补的链的退火形成的所谓的“桥接的”结构,两种链在5'末端被固定在固体支持物上,优选地经由共价附接。簇扩增方法是方法的实例,其中固定的核酸模板被用来产生固定的扩增子。其他合适的方法也可被用来从根据本文提供的方法产生的固定的DNA片段产生固定的扩增子。例如一个或更多个簇或集群可经由固相PCR来形成,每对扩增引物中的一个或两个引物是被固定的。
在其他的实施方案中,在溶液中扩增固定的DNA片段。例如,在一些实施方案中,固定的DNA片段被裂解或者以其他方式从固体支持物释放,并且然后扩增引物在溶液中与释放的分子杂交。在其他的实施方案中,对于一个或更多个初始扩增步骤,扩增引物被与固定的DNA片段杂交,然后是随后在溶液中的扩增步骤。因此,在一些实施方案中,固定的核酸模板可被用来产生溶液相扩增子。
将领会的是,本文描述的或本领域一般已知的任何扩增方法可与通用的或靶特异的引物一起使用以扩增固定的DNA片段。用于扩增的合适的方法包括但不限于聚合酶链式反应(PCR)、链置换扩增(SDA)、转录介导的扩增(TMA)和基于核酸序列的扩增(NASBA),如在美国专利号8,003,354中描述的,通过引用以其全文并入本文。以上扩增方法可被用来扩增一个或更多个感兴趣的核酸。例如,PCR包括多路复用PCR、SDA、TMA、NASBA等可被用来扩增固定的DNA片段。在一些实施方案中,将特异地针对感兴趣的核酸的引物包括在扩增反应中。
用于核酸扩增的其他合适方法可包括寡核苷酸延伸和连接技术、滚环扩增(RCA)技术(Lizardi等人,Nat.Genet.19:225-232(1998),通过引用将其并入本文)和寡核苷酸连接测定(OLA)技术(通常参见美国专利号7,582,420、5,185,243、5,679,524和5,573,907;EP 0 320 308 B1;EP 0 336 731 B1;EP 0 439 182 B1;WO 90/01069;WO 89/12696和WO 89/09835,通过引用将其所有并入本文)。将领会这些扩增方法可被设计为扩增固定的DNA片段。例如,在一些实施方案中,扩增方法可包括连接探针扩增或寡核苷酸连接测定(OLA)反应,其包括特异地针对感兴趣的核酸的引物。在一些实施方案中,扩增方法可包括引物延伸-连接反应,其包括特异地针对感兴趣的核酸的引物。作为引物延伸和连接引物的非限制性实例,其可被特异地设计为扩增感兴趣的核酸,扩增可包括用于GoldenGate测定(Illumina,Inc.,San Diego,CA)的引物,如由美国专利号7,582,420和7,611,869所例证的,通过引用将其每个以其全文并入本文。
可在本公开内容的方法中使用的示例性等温扩增方法包括但不限于多重置换扩增(MDA),如由例如Dean等人,Proc.Natl.Acad.Sci.USA 99:5261-66(2002)所例证的,或由例如美国专利号6,214,587所例证的等温链置换核酸扩增,通过引用将其每个以其全文并入本文。可在本公开内容中使用的其他的非基于PCR的方法包括例如链置换扩增(SDA),其在例如Walker等人,Molecular Methods for Virus Detection,Academic Press,Inc.,1995,美国专利号5,455,166和5,130,238,以及Walker等人,Nucl.Acids Res.20:1691-96(1992)中被描述;或超支化链置换扩增,其在例如Lage等人,Genome Research 13:294-307(2003)中被描述,通过引用将其每个以其全文并入本文。等温扩增方法可与用于基因组DNA的随机引物扩增的链置换Phi 29聚合酶或Bst DNA聚合酶大片段5'->3'外切一起使用。这些聚合酶的使用运用其高的持续性和链置换活性。高的持续性允许聚合酶产生长10-20kb的片段。如以上描述的,可在等温条件下使用具有低的持性和链置换活性的聚合酶诸如Klenow聚合酶产生较小的片段。在美国专利号7,670,810的公开内容中详细描述了扩增反应、条件和组分的另外的描述,通过引用以其全文并入本文。
在本公开内容中有用的另一个核酸扩增方法是加标签的PCR,其使用具有恒定的5'区域接着是随机的3'区域的双域引物的群体,例如在Grothues等人,Nucleic Acids Res.21(5):1321-2(1993)中描述的,通过引用以其全文并入本文。进行第一轮扩增以允许在热变性的DNA上基于从随机合成的3'区域单独杂交的大量起始。由于3'区域的性质,所以起始位点预期是遍及基因组随机的。其后,未结合的引物可被移除并且另外的复制可使用与恒定的5’区域互补的引物发生。
测序.本公开内容还涉及根据本文提供的方法产生的固定的DNA片段的测序。由表面结合的转座体介导的标签化产生的固定的DNA片段可根据任何合适的测序方法而被测序,诸如直接测序,包括合成测序、连接测序、杂交测序、纳米孔测序等。在一些实施方案中,在固体支持物上测序固定的DNA片段。在一些实施方案中,用于测序的固体支持物是与于其上表面结合的标签化发生的固体支持物相同的固体支持物。在一些实施方案中,用于测序的固体支持物是与于其上扩增发生的固体支持物相同的固体支持物。
一种优选的测序方法是合成测序法(SBS)。在SBS中,监测核酸引物沿着核酸模板(例如,靶核酸或其扩增子)的延伸以确定模板中核苷酸的序列。潜在的化学方法可以是聚合作用(例如,如被聚合酶催化)。在特定的基于聚合酶的SBS实施方案中,荧光标记的核苷酸以模板依赖模式被添加至引物(从而延伸引物),以使得检测添加至引物的核苷酸的顺序和类型可被用来确定模板的序列。
流通池提供了用于容纳由本公开内容的方法产生的扩增的DNA片段的方便的固体支持物。此格式中的一种或更多种扩增的DNA片段可经受SBS或涉及循环中反应物的重复递送的其他检测技术。例如,为了起始第一SBS循环,一个或更多个标记的核苷酸、DNA聚合酶等可流入/流经容纳一个或更多个扩增的核酸分子的流通池。其中引物延伸导致标记的核苷酸被并入的那些位点可被检测。任选地,核苷酸还可包括可逆终止特性,在核苷酸已被添加至引物后,其终止进一步的引物延伸。例如,具有可逆终止子部分的核苷酸类似物可被添加至引物,以使得随后的延伸不能发生,直到递送解封剂以移除该部分。因此,对于使用可逆终止的实施方案,可使解封剂递送至流通池(在检测发生之前或之后)。在多个递送步骤之间可进行洗涤。然后可重复循环n次,以将引物延伸n个核苷酸,从而检测长度n的序列。可容易地适于与由本公开内容的方法产生的扩增子一起使用的示例性SBS过程、流体系统和检测平台被描述于例如Bentley等人,Nature 456:53-59(2008);WO 04/018497;US 7,057,026;WO 91/06678;WO 07/123744;US 7,329,492;US 7,211,414;US 7,315,019;US 7,405,281和US 2008/0108082中,通过引用将其每个并入本文。
使用循环反应的其他测序过程可被利用,诸如焦磷酸测序。随着特定核苷酸被并入初生核酸链,焦磷酸测序检测无机焦磷酸盐(PPi)的释放(Ronaghi等人,Analytical Biochemistry 242(1),84-9(1996);Ronaghi,Genome Res.11(1),3-11(2001);Ronaghi等人Science 281(5375),363(1998);US 6,210,891;US 6,258,568和US.6,274,320,通过引用将其每个并入本文)。在焦磷酸测序中,释放的PPi可通过立即由ATP硫酸化酶转化成腺苷三磷酸(ATP)来检测,并且产生的ATP的水平可经由荧光素酶产生的质子来检测。因此,测序反应可经由冷光检测系统来监测。用于基于荧光的检测系统的激发放射源对于焦磷酸测序过程不是必需的。可适于将焦磷酸测序应用到根据本公开内容产生的扩增子的有用的流体系统、检测器和过程被描述于例如WIPO专利申请系列号PCT/US11/57111、US 2005/0191698A1、US 7,595,883和US 7,244,559中,通过引用将其每个并入本文。
一些实施方案可利用包括DNA聚合酶活性的实时监测的方法。例如,核苷酸并入可通过载有荧光团的聚合酶和γ-磷酸标记的核苷酸之间的荧光共振能量转移(FRET)相互作用,或用零模波导(ZMW)来检测。用于基于FRET的测序的技术和试剂被描述于例如Levene等人,Science 299,682–686(2003);Lundquist等人Opt.Lett.33,1026–1028(2008);Korlach等人Proc.Natl.Acad.Sci.USA 105,1176–1181(2008),通过引用将其公开内容并入本文。
一些SBS实施方案包括检测将核苷酸并入延伸产物后释放的质子。例如,基于检测释放的质子的测序可使用电子检测器和从Ion Torrent(Guilford,CT,a Life Technologies subsidiary)商业可得的相关技术,或在US 2009/0026082 A1、US 2009/0127589 A1、US 2010/0137143 A1或US 2010/0282617 A1中描述的测序方法和系统,通过引用将其每个并入本文。本文描述的用于使用动力学排除扩增靶核酸的方法可容易地应用于被用来检测质子的基底。更具体地,本文描述的方法可被用来产生用于检测质子的扩增子的克隆群体。
另一种有用的测序技术是纳米孔测序(参见例如Deamer等人Trends Biotechnol.18,147–151(2000);Deamer等人Acc.Chem.Res.35:817-825(2002);Li等人Nat.Mater.2:611–615(2003),通过引用将其公开内容并入本文。在一些纳米孔实施方案中,将靶核酸或从靶核酸移除的单个核苷酸通过纳米孔。随着核酸或核苷酸通过纳米孔,每个核苷酸类型可通过测量孔的电导率波动来鉴定。(美国专利号7,001,792;Soni等人Clin.Chem.53,1996–2001(2007);Healy,Nanomed.2,459–481(2007);Cockroft等人J.Am.Chem.Soc.130,818–820(2008),通过引用将其公开内容并入本文)。
可被应用于根据本公开内容的检测的用于基于阵列的表达和基因分型分析的示例性方法被描述于美国专利号7,582,420、6,890,741、6,913,884或6,355,431或美国专利公布号2005/0053980 A1、2009/0186349 A1或US 2005/0181440 A1,通过引用将其每个并入本文。
本文描述的方法的优势是,其提供了多个靶核酸的快速且有效的平行检测。相应地本公开内容提供了能利用本领域已知的技术诸如以上例证的那些制备并检测核酸的整合系统。因此,本公开内容的整合系统可包括能够将扩增试剂和/或测序试剂递送至一个或更多个固定的DNA片段的流体组分;系统包括泵、阀门、储液箱、射流线路等。流通池可被构造和/或在用于检测靶核酸的整合系统中使用。示例性流通池被描述于例如US 2010/0111768 A1和美国系列号13/273,666中,通过引用将其每个并入本文。作为流通池的例证,整合系统的一个或更多个流体组分可被用于扩增方法和用于检测方法。以核酸测序实施方案为例,整合系统中的一种或更多种流体组分可被用于本文描述的扩增方法并用于在诸如以上例证的那些的测序方法中递送测序试剂。可选地,整合系统可包括分隔流体系统以进行扩增方法和进行检测方法。能产生扩增的核酸且还能确定核酸的序列的整合测序系统的实例包括但不限于MiSeqTM平台(Illumina,Inc.,San Diego,CA)和在美国系列号13/273,666中描述的装置,通过引用将其每个并入本文。
具有固定的转座体的固体支持物及制备方法
本文提供的其他实施方案包括具有转座体复合物固定至其上的固体支持物,诸如流通池。在某些实施方案中,转座体复合物包含结合至第一多核苷酸的转座酶,多核苷酸包含(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域。这些表面结合的转座体的密度可变化。例如,在一些实施方案中,转座体复合物以至少103、104、105、或至少106个复合物每mm2的密度存在于固体支持物上。
本文还提供了产生用于标签化的流通池的方法。所述方法可包括例如将多个转座体复合物固定至固体支持物,所述转座体复合物包含结合至第一多核苷酸的转座酶,第一多核苷酸包含(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域。
转座体复合物可以多种方法固定至固体支持物,其将被本领域技术人员领会。在一个实施方案中,所述方法包括提供具有多个第一多核苷酸固定于其上的固体支持物,并且使固体支持物与转座酶全酶和第二多核苷酸接触,第二多核苷酸包含与转座子末端序列互补的区域。在一些实施方案中,在添加转座酶全酶之前,使第二多核苷酸与固定的第一多核苷酸杂交。在一些实施方案中,一起提供第二多核苷酸和转座酶全酶。图5a显示了这种用于组装表面结合转座体复合物的方法的一个实施方案。在一种方法中,连同ME适体的非转移链一起将转座酶全酶添加至含有寡核苷酸的流通池,所述寡核苷酸从5'表面接枝末端起包含:簇扩增引物(A.pr)和测序引物(S.pr)和ME序列(图5a)。可选地,非转移ME'链可与表面接枝的ME链杂交并且然后转座酶被添加至流通池。
在一些实施方案中,在溶液中组装转座体复合物并且固定包括将第一多核苷酸与夹板寡核苷酸连接的另外的步骤,所述夹板寡核苷酸偶联至固体支持物。在图5b中阐述了该实施方案。在一些实施方案中,在连接步骤发生之前,夹板寡核苷酸可利用聚合酶被延伸。
在一些实施方案中,转座体二聚体通过使带环的寡核苷酸与固定的第一多核苷酸杂交来组装。例如,带环的寡核苷酸可包含第一末端和第二末端,第一末端与第一多核苷酸的转座子末端序列互补。带环的寡核苷酸的第二末端可与第二转座子末端序列互补。第二转座子末端序列可例如为溶液相第一多核苷酸的部分。在一些实施方案中,固定的第一多核苷酸末端和溶液相第一多核苷酸可包括不同的转座子末端序列或其互补物。在一些此类实施方案中,带环的寡核苷酸在第一和第二末端包含与每个不同的转座子末端序列的每个互补的序列。在图5c中显示了该实施方案的图示。如在图5c中显示的,通过使两个寡核苷酸与表面结合寡核苷酸杂交来产生连续的适体对。这可通过使用两个不同的转座子末端序列(ME1和ME2)来完成。添加转座酶全酶重新组成活性“环”转座体复合物,其中只有每个转座体的两个适体之一被偶联至表面,图5c。
在另一个实施方案中,转座体复合物可在具有扩增引物固定于其的标准成对的末端流通池(例如,由Illumina Inc,San Diego,CA出售的HiSeq流通池或MiSeq流通池)上组装。这可通过例如使退火至表面接枝的扩增引物的一种或两种物质的‘夹板’寡核苷酸的杂交来完成。夹板起到模板的作用,然后用聚合酶和dNTP延伸接枝的表面引物,以形成含有表面扩增引物、测序引物和转座酶的转座子末端序列的寡核苷酸复合物。转座酶的添加组装表面的转座体。在图5d中阐述了该实施方案。
在本文提供的任何实施方案中,转座体复合物可以是同二聚体或异二聚体。例如,如在图11中阐述的,同二聚体转座体将在两个位点包括两个P5-ME适体或可选地两个P7-ME适体。相似地,异二聚体转座体复合物将包括P5-ME和P7-ME适体两者,如在图11中显示的。
使用转座体珠的标签化
本文提供的一个实施方案为具有转座体复合物固定至其的微粒群体。固体支持物诸如珠的使用可提供超越溶液相标签化的若干优势。例如,在标准溶液相标签化中,难以控制标签化反应的最终片段大小。片段大小是转座体的比例与DNA的量和大小以及与反应的持续时间的函数。即使这些参数是被控制的,通常需要大小选择片段化作为另外的步骤以移除过量的比组合的成对读段长度短的小片段。本文提供的方法避免了那些缺点。具体地,珠-固定的转座体允许选择最终片段大小作为结合的转座体的空间分离的函数,不依赖于添加至标签化反应的转座体珠的量。基于溶液的标签化的另外的局限是其通常在PCR扩增之前和之后均需要进行标签化反应产物的一些形式的纯化。这通常必须将反应从管至管的一些转移。与之相比,基于珠的转座体上的标签化产物可被洗涤,并且之后被释放用于扩增或其它下游处理,从而避免需要样品转移。例如,在转座体被组装在顺磁性珠上的实施方案中,标签化反应产物的纯化可容易地通过用磁体固定珠并洗涤来完成。因此,在一些实施方案中,标签化和其他下游处理诸如PCR扩增可全部在单个管、器皿、液滴或其它容器中被进行。在一些实施方案中,样品的标签化和下游处理发生在基于微流体液滴的装置上,如在于2012年11月6日提交题为“INTEGRATED SEQUENCING APPARATUSES AND METHODS OF USE”的美国申请系列号13/670,318的公开内容中例证的,通过引用以其全文并入本文。例如,在基于微流体液滴的装置中,含有靶核酸、洗涤缓冲液或其它试剂的液滴可通过含有固定的转座体复合物的表面。同样地,在基于微流体液滴的装置中,含有具有转座体固定至其上的珠的液滴可与靶核酸、洗涤缓冲液或其他试剂接触。
在一些实施方案中,固定的转座体复合物包含结合至第一多核苷酸的转座酶和第二多核苷酸;其中第一多核苷酸在其5'末端被固定至微粒的表面并且第二多核苷酸与第一多核苷酸的3'末端杂交;并且其中第一多核苷酸包含:(i)3'部分,所述3'部分包含转座子末端序列,和(ii)第一标签,所述第一标签包含第一标签域。
图9-12提供了组装于顺磁性珠的表面的转座体的图示。图9显示了具有两个不同的第一多核苷酸固定至其的珠表面。显示的第一多核苷酸包含转座子末端序列(ME)。其中显示的第一多核苷酸之一包含标签域,所述标签域包含扩增引物序列(P5)和测序引物序列(读段1)。图9中显示的其他多核苷酸包含不同的扩增引物序列(P7)和测序引物序列(读段2)。第一多核苷酸还可包含索引标签。索引标签可对于珠是独特的,或其可与群体中的一个或更多个其他的珠共用。单个珠可只具有固定至其的单个索引标签,或其可具有固定至其的多个索引标签。
图10显示了与每个第一多核苷酸杂交的第二多核苷酸。第二多核苷酸含有与第一多核苷酸的转座子末端序列互补的区域。在一些实施方案中,第一多核苷酸长度为15bp。在一些实施方案中,第二多核苷酸长度可为大约10、11、12、13、14、15、16、17、18、19、20bp或多于20bp。在一些实施方案中,第二多核苷酸在其5'末端被磷酸化。
图11图示了在珠的表面上组装转座体,其中转座酶与固定的寡核苷酸接触。如图11中显示的,当转座酶被添加至珠时,形成三种类型的转座体复合物:P5:P5、P7:P7和P5:P7复合物(图11)。
当转座体珠在标签化缓冲液中被添加至靶DNA溶液时,发生标签化,将DNA与珠的表面连接。加标签的DNA片段的固定的文库产生。
图12图示了这样的实施方案:其中接连标签化至DNA中产生了转座体之间的桥接分子。当存在三种类型的转座体时(如图11中的),产生三种类型的桥接复合物:分别25:25:50比率的P5:P5、P7:P7和P5:P7复合物。
在一些实施方案中,桥接的片段的长度可由珠表面上的转座体的密度来决定。该密度是经由以下可调的:表面上的寡核苷酸的量,表面上的双链体转座子末端复合物的量以及在转座体组装期间添加的转座酶的量。标签化完成之后,P5:P7标签化产物可利用任何合适的方法从珠的表面释放。在一些实施方案中,标签化产物利用扩增方法诸如抑制PCR、step-out PCR等从珠释放。在一些实施方案中,标签化产物通过裂解从珠释放。裂解例如可以是化学的、酶促的、光化学的或其组合。将领会的是,用于从固体支持物释放一种或更多种标签化产物的任何合适的方法可被用于本文提供的方法。
DNA可利用增加接触的可能性的任何合适的方法来与表面结合的转座体有效地接触。例如,在一些实施方案中,将DNA沉淀在固体支持物上可被用来增加靶DNA和固体表面上的转座体复合物之间的接触。可利用本领域已知的用于使DNA与固体支持物接触的很多方法中的任一种,如由WO 2010/115122的公开内容所例证的,通过引用以其全文并入本文。如本领域技术人员将领会的是,DNA可通过添加PEG、乙醇或已知使DNA沉淀于表面上的多种其他试剂中的任一种被沉淀在固体支持物上,已知使DNA沉淀于表面上的多种其他试剂包括例如在固相可逆固定(SPRI)技术中使用的很多缓冲液中的任一种。
在一些实施方案中,负载固定的转座体复合物的珠的群体可与未负载转座体或寡核苷酸的过量的珠混合,从而降低跨两个或更多个不同的珠标签化的可能性。降低跨两个或更多个不同的珠标签化的可能性的另一种方法包括固定珠以使得珠之间的接触最小化。珠的固定可通过本领域已知的很多技术中的任一种来完成,包括例如经由磁力将珠固定至固体表面诸如微型离心管的侧部、或如由WO 2010/115122的并入材料例证的任何其他固定技术。
在一些实施方案中,转座体珠可被用来从单细胞诸如原核细胞或真核细胞分离和鉴定核酸。例如,在一些实施方案中,将颗粒诸如珠用索引转座体包被,所述索引转座体共有相同的索引(存在于特定珠上的全部转座体具有相同的索引,其与在另一个珠上存在的索引不同)。然后珠可通过本领域已知的多种方法中的任一种被放置于细胞内。例如,用于在细胞内递送珠的方法包括但不限于基因枪、光热纳米刀(photothermal nanoblades)(Wu等人Anal Chem.(2011)4:1321-7)、http://www.ncbi.nlm.nih.gov/pubmed/21247066以及连同细胞透化物质使用的肽(Nitin等人Ann Biomed Eng.(2009)37:2018-2027)等。将领会的是,用于使来自单细胞的DNA与负载索引的转座体的颗粒关联的任何合适的方法可被用于本文提供的方法。
在一些实施方案中,转座体可共价地附接至珠,如在本文以上详细的描述的。另外地或可选地,在应用化学或物理刺激以后,转座体可从珠释放。可引发转座体从固体支持物释放的刺激的一些实例包括光和/或温度变化。在一些实施方案中,转座体利用诸如限制性内切核酸酶的酶的活性从固体支持物释放。在某些实施方案中,转座体可从珠分离并在细胞内自由地移动。珠(或可选地,释放的转座体)得以与染色质或DNA接触之后,标签化可发生。将理解,在真核和原核系统中,并不是所有的基因组DNA对于标签化将总是可达的和/或可得的。在一些实施方案中,细胞中多达0.001%、0.01%、0.1%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%或99%或多于99%的总DNA被转座体标签化。独特地加标签的珠的使用使得通过将共有相同的索引的读段分组在一起来从相同的细胞鉴定读段成为可能。这些读段可被认为源自相同的珠(并且因此来自相同的细胞)。另外地或可选地,在一些实施方案中,可进行交联步骤以交联细胞DNA,同时其仍然在细胞核内。此步骤保证了来自单细胞的DNA被保持在一起。在从细胞提取DNA之后,然后其可与索引珠混合并经受标签化,如在本文以上详细描述的。另外地或可选地,方法的变化形式包括流式分选的染色体的标签化。流式分选的染色体可与以上描述的索引珠混合。特定的染色体将附着至一个珠并且通过标签化产生的片段可含有相同的索引。这可使能够从整个染色体定相SNP(phasing SNP)(单倍分型)。
在一些此类实施方案中,索引的总数比成功标签化的细胞总数大。在一些实施方案中,可执行双索引方法,例如,作为增加可能的索引组合的数目的方式。作为一个实例,两个8碱基索引的使用将给出48X 48=4.3X109个组合的理论数。
在一些实施方案中,可使用方法来确保单个细胞未被多个珠标签化。例如,一种方法是使用与细胞的大小相似大小的珠。这会确保细胞不能容纳多个珠。另外地或可选地,另一种方法是使用利于单细胞靶向的细胞与珠的比率。例如,如果细胞远多于珠,则细胞内珠的泊松分布意味着吸收单个珠的细胞远远超过吸收两个或更多个珠的细胞。
在一些实施方案中,以上描述的单细胞方法可被用来确定两个SNP(或结构重排)是否存在于相同的细胞中。例如,在癌症细胞的异质群体的情况中,知晓两个SNP是否存在于相同的细胞或不同的细胞中可有助于实行正确的癌症疗法。
在一些实施方案中,以上描述的单细胞方法可被用来研究RNA。例如,通过以用于反转录步骤的合适的酶(即,反转录酶)和寡核苷酸包被珠,可分析在单细胞水平的基因表达。在一个实施方案中,引入用反转录酶、寡核苷酸和转座体包被的珠之后,细胞质RNA可被转化成cDNA,加标签和细胞内制备。
使用固定的转座体上的条形码组装长的读段的方法
条形码协助的DNA片段组装使能够分离DNA分子群体内单独的长DNA分子并且将每个分子转换成独特的条形码化的子片段文库。当子片段化的DNA分子的整个群体被测序时,子片段可通过参考其包含的条形码被组装回其原始长分子。
单个DNA分子条形码化的多种方法是已知的。例如,‘稀释方法’通过极端稀释并分装入分开的区室(例如,平板的孔)来分离单个长分子,以使得每个孔只含有一个或只有几个DNA分子。因为每个孔是物理上分开的,所以文库制备可用独特的条形码在每个孔中进行。其后,孔的内容物被汇集并测序。另一种方法使用乳剂,其中每个液滴含有长DNA分子、文库制备试剂和对每个液滴独特的条形码。另一种方法使用索引带环的转座体复合物(looped tranasposome complex)的大的文库来沿着DNA的长度插入多个双胞胎条形码,同时保持分子的完整性。条形码‘双胞胎’之间的随后裂解得到可通过匹配双胞胎条形码来测序并重组的片段。以上提到的条形码化方法中的每个带有其缺点,该缺点被本文提供的条形码化方法克服。
本文提供了以上描述的分离和条形码化单个长分子的方法的可替代方法。本文提供的方法获得与乳剂方法相似的物理分离的优点,而不使用乳剂,并且同时提供比通过在稀释方法中使用的大量‘孔’提供的复杂性大的多的复杂性。本方法的独特的条形码在某种程度上类似于稀释方法中的‘孔’,除了在基于珠的方法中珠的数目通常可比稀释方法中孔的数目高的多。超越乳剂方法的另外的优点是在基于珠的方法中,条形码是确定性的分布的(即,每个珠一个条形码)且不是随机的(即,泊松分布)。本文提供的方法还获得分子完整性和连续性的相同的初始保留,但不需要环转座体复合物,如在一些其他方法中使用的。另外地,本文提供的方法不需要如在一些其他方法中所使用的大的码空间。
因此,在本文提供的一些实施方案中,条形码方法包括提供具有转座体复合物固定至其的微颗粒群体,所述转座体复合物包含结合至第一多核苷酸的转座酶和第二多核苷酸。在一些实施方案中,第一多核苷酸包含与微粒结合的索引域。在一些实施方案中,索引域可以是对微粒独特的。在一些实施方案中,微粒的群体包括至少多个索引域。在一些实施方案中,索引域存在于微粒群体中的多于一个微粒上。在一些实施方案中,微粒群体中的微粒包括多于一个的索引域。
本文提供的条形码方法还包括将靶DNA施加至微粒群体,从而产生用索引域加标签的固定的DNA片段。DNA可利用用于增加接触的可能性的任何合适的方法来与表面结合的转座体有效地接触,如本文以上讨论的,如由WO 2010/115122的并入材料例证的。
所述方法可利用多种已知格式中的任何一种来进行,例如用标签化试剂和用于文库制备的珠阵列的联合,随后是索引的测序运行和订制的数据分析。使珠保持彼此静态分离的任何其他合适的方法可被用来表面标签化和样品的加索引。例如,物理构造诸如基底中可保留珠的孔或小的凹槽,以使得微球可处于孔中,或其他力(磁力的或压缩力的),或使用化学改变或活性位点诸如化学功能化的位点、静电改变位点、疏水性和/或亲水性功能化位点,或粘附的点。
在一些实施方案中,微球为非共价地结合于孔中,尽管孔可另外地被通常化学上功能化,如以下描述的,但是交联剂可被使用,或物理屏障可被使用,例如珠上方的薄膜(film)或膜(member)。
在某些实施方案中,基底的表面被修饰为含有化学修饰位点,所述化学修饰位点可被用于使本发明的微球共价地或非共价地附接至离散位点或基底上的位置。在该上下文中“化学修饰位点”包括但不限于化学官能团模式的添加,化学官能团包括氨基、羧基、氧基和硫基,可被用来共价地附接微球,其通常地还含有相应的活性官能团;粘合剂模式的添加,其可被用来结合微球(通过在添加粘合剂之前先前化学功能化或直接添加粘合剂);带电荷基团模式的添加(与化学功能相似)用于微球的静电附接,例如当微球在位点相对处包含带电荷基团时;化学官能团模式的添加,其致使位点不同地疏水性或亲水性,以使得在合适的实验条件下相似地疏水性或亲水性微球的添加会导致微球基于水亲和性结合至位点。例如,在水系统中疏水位点和疏水珠的使用驱使珠优先地结合至位点上。如以上描述的,在这个意义上的“模式”包括使用表面的均一处理以允许在离散位点处珠的附接,以及导致离散位点的表面处理。如本领域技术人员将领会的是,这可以多种方式来完成。
在某些实施方案中,产生了含有表面结合的转座体的众多珠,其中每个珠含有很多转座体,但是任何给定珠上的所有转座体均含有相同的条形码。可根据本领域已知的很多技术中的任何一种来进行产生珠上的单克隆条形码转座体寡核苷酸群体,如由U.S.5,604,097的公开内容所例证的,通过引用以其全文并入本文。
图13图示了一种实施方案,其中表面结合的转座体含有经由其5'末端附接至表面的长的寡核苷酸。如在图13中描述的,寡核苷酸的3'末端含有Tn5转座酶的马赛克末端(METS)序列。该序列的上游(较接近5'末端)为通常地长6-8个碱基的条形码序列。进一步的上游是引物序列。另外地,寡核苷酸还可包括裂解位点以使能够寡核苷酸从表面裂解下:对于总体方法,其在寡核苷酸中的存在是任选的。将第二短寡核苷酸(非转移链,MENTS)与长的表面接枝的寡核苷酸的3'末端的METS序列杂交。最后,转座酶二聚体在寡核苷酸的3'末端组装以形成功能性的转座体。
图14图示了孔阵列中的珠上的条形码。如在图14中显示的,当长的dsDNA分子被添加至珠固定的转座体的阵列时,给定的分子遇到珠并且被珠上的转座体进行多次标签化。每个片段变为固定至珠并用与该珠结合的条形码加标签。在图14中显示的特定的实施方案中,阵列芯片中的珠的物理分离阻止了DNA分子达到两个珠之间。在其他的实施方案中,珠紧密接触并且一个或更多个DNA分子可在两个或更多个珠之间延伸。在一些实施方案中,每珠可多于一个DNA分子被标签化。两个等位基因在相同的珠上被标签化的可能性是低的并且是添加的DNA的浓度、珠的数目和条形码的数目的函数。例如,为了避免在相同的孔中存在两个等位基因,0.1x单倍体等同物(50,000基因组等同物)需被加载至1百万个珠,每个珠具有独特的条形码。
图15图示了条形码加标签的分子被转移至测序反应。如在图15中显示的,标签化完成之后,DNA被从珠表面转移至溶液,以使得单个片段可被汇集并被制备用于测序。参考条形码测序并组装使初始的长的标签化的DNA分子的序列能够被重新产生,从而使能够长的或假长的读取和SNP的定相。
条形码化的表面标签化的片段释放至溶液可利用本领域已知的任何合适的方法来完成。例如,在一些实施方案中,标签化的分子可经由存在于表面结合的寡核苷酸的5'末端的裂解部分从珠的表面裂解下(参见图13)。裂解部分可以是适于将核酸链从固体支持物裂解的任何部分。利用裂解部分的方法的实例包括但不限于限制性内切核酸酶裂解、化学裂解、RNA酶裂解、光化学裂解等,包括WO 2006/064199中描述的那些裂解方法和裂解部分,通过引用以其全文并入。
利用裂解部分裂解得到具有以下格式的分子:
5’-引物-条形码-ME-插入物-ME-条形码-引物-3’
“引物”区域可被用作杂交点,以杂交PCR step-out引物(PCR step-out primer),其使能够添加另外的序列诸如扩增引物和测序引物。例如,可添加扩增引物P5和P7。添加后,可使用抑制PCR,例如以富集在一个末端具有P5适体且在另一个末端具有P7的分子。
在一些实施方案中,可用step-out引物直接地进行从珠扩增下来,其通过抑制PCR添加P5和P7适体序列。在另一个实施方案中,每个珠可具有两种类型的表面接枝的寡核苷酸,其中引物序列(如在图13中的)为P5-读段1测序引物或P7-读段2测序引物。这将导致混合的P5-P7转座体。这些可从珠裂解下并且然后通过抑制PCR以富集P5/P7分子或直接地从珠扩增下来,如以上描述的。
在一些实施方案中,单个转座体类型(例如P5-读段1-条形码)可存在于珠的表面上。表面标签化完成后,负载不同的扩增引物和/或测序引物的第二转座体可在溶液中被添加以裂解桥接的分子。这得到具有能从珠表面裂解或扩增下来的相同的适体格式的所有分子。另外的样品特异的条形码可被添加至溶液转座体以使得多个样品可通过所述方法汇集。图16是这种实施方案的图示。如在图16中显示的,负载P7扩增引物序列的溶液相转座体被添加至具有固定的桥接的标签化产物的珠。固定的片段用含有P5扩增引物序列和对珠独特的条形码索引标签(i9)的多核苷酸序列加标签。如在图16中显示的,第二标签化反应之后,每个片段具有负载P7引物序列的游离末端以及负载P5引物序列的固定的末端。
实施例1
流通池上的表面标签化
该实施例描述了确认图4a和4b中图示的实施方案(表面标签化然后溶液标签化)的实验。
利用一系列条件和对照进行8通道流通池上的实验,如在图6a和6b中显示的。通道6表明了该方法的完整的从头到尾的展示:未片段化的大肠杆菌(E.coli)基因组DNA被添加至流通池,其中其被表面结合的转座体标签化。接下来将热施加于流通池以选择性地使裸露的ME序列脱杂交,从而除去它们作为当转座体接下来从溶液被添加时第二标签化反应的靶。第二标签化反应之后,产生簇并进行‘成对的末端’测序(2x36碱基读段)。在图7(slide 7)中给出了测序指标,其显示在通道6中,73.14%的簇通过滤器并且这些中的74.69%是对齐的。这提供了足以获得插入物的间隙大小图和文库多样性的评价的数据(参见图8)。
其他通道包括以下列出的对照。
通道1包含PhiX DNA作为阳性对照以确保所有物质被正确地抽运并且簇产生和测序如所预期的进行。
通道2是另一个对照通道,并阐明在靶DNA不存在下标签化至表面结合的转座体中。流通池(FC)含有标准成对的末端FC,在其上将含有标签化引物序列和ME'序列(非转移ME'链)的寡核苷酸与P7表面寡核苷酸杂交。该寡核苷酸以饱和浓度被添加。第一延伸产生具有ME末端的双链转座子。P5转座体在溶液中被组装并流至FC上(6.25nM/通道)。P5转座体将双链的表面结合的转座子标签化。标签化产物随后地被转换成簇。
通道3图示了在靶DNA的不存在下标签化至表面结合的转座子中,只有在该实例中,FC已被加热至75℃以在从溶液添加P5转座体之前将双链的表面结合的转座子转化成单链寡核苷酸,以防止标签化至这些结构中,因为这将干扰靶DNA的标签化。
通道4图示了将表面结合的转座体添加至通道3的条件。在该通道中,含有标签化引物序列和ME'序列的寡核苷酸与P7表面寡核苷酸杂交。第一延伸产生具有ME末端的双链转座子。这之后,通过将Tn5酶以50X浓度添加至通道并在30℃下孵育30分钟,P7转座体被组装在FC的表面。然后在添加来自溶液的P5转座体之前,FC被加热至75℃。
通道5包括与通道4相同的条件,只是在该情况中不是添加来自溶液的P5转座体,而是添加大肠杆菌900bp文库(具有P5/P7末端)以确定在加热步骤之后P7表面结合的转座体是否保持活性。
通道6图示了本发明应用于实践的实例。在该实例中FC含有标准成对的末端FC,在其上将含有标签化引物序列和ME'序列的寡核苷酸与P7表面寡核苷酸杂交。第一延伸产生具有ME末端的双链转座子。通过将Tn5酶以50X浓度添加至通道并在30℃下孵育30分钟,P7转座体被组装在FC的表面。靶DNA(300ng未片段化的大肠杆菌基因组DNA)被添加至FC通道上并进行在55℃下孵育15min的步骤以发生标签化。使用PBI(Qiagen)将P7表面结合的转座体洗涤下来并且然后在添加来自溶液的P5转座体之前将FC加热至75℃。添加来自溶液的P5转座体以及在55℃下15min的孵育步骤之后,进行链置换延伸反应以填充由转座反应在DNA骨架中产生的9-bp空隙。链置换延伸反应包括添加Bst和dNTP混合物并在65℃下孵育5min。在最后步骤中将P5转座体洗涤下来。此时,所有表面结合的分子应为P5-P7模板并且可因此被转化成簇。
通道7含有与通道6相同的条件,只是在该实例中,加热步骤已被去除,以突出热对簇的数目和对齐%的影响。
通道8包括阴性对照,其中在双链的表面结合的转座子的饱和浓度的存在下P7转座体已以50X浓度被组装在表面上,但是未添加靶DNA。这允许评价表面结合的P7转座体是否将表面结合的转座子标签化至其邻近的双链(ds)中。
实施例2
从大肠杆菌刮取物(scrape)制备表面结合的样品
刮取大肠杆菌样品(从琼脂平板上的菌苔刮取5mm乘2mm)并重悬在含有水和玻璃珠的管中。利用涡旋混合器混合悬浮的细胞和珠以使细胞裂开并且然后离心以沉淀细胞碎片。上清液(含有细胞裂解物,包括蛋白质和核酸)被移除并添加至Genome Analyzer流通池(Illumina,Inc.,San Diego,CA),所述Genome Analyzer流通池具有根据实施例1中描述的方案的固定的转座体。
利用Cluster Station样品制备装置(Illumina,Inc.,San Diego,CA)在流通池上进行簇产生。簇产生之后,以在每个方向上36个碱基的读段来进行成对的末端测序运行。
对于读段1,58.99%的簇通过滤器并且这些中的92.16%对齐。对于读段2,58.99%的簇通过滤器并且这些中的55.08%对齐。这些数据证实,未纯化的细胞裂解物可被直接地添加至具有固定的转座体的流通池,具有出人意料的稳健的测序结果。
实施例3
该实施例描述了避免当溶液相转座体被添加至流通池时的表面结合的寡核苷酸双链体的标签化的方法。
用于在流通池的表面上组装转座体的一种方法是取标准成对末端流通池、使‘夹板’寡核苷酸与P5和/或P7表面接枝的寡核苷酸杂交,形成可延伸的突出部分,所述可延伸的突出部分可用聚合酶延伸以制备含有双链ME序列的双链体。在该阶段可添加转座酶以形成功能性的表面结合的转座体(图5d)。如果只有双链体的部分形成转座体,随后剩余的‘裸’ME双链体可通过邻近的表面结合的转座体或从溶液添加的转座体变成标签化的靶。而且,完全组装的表面转座体含有ME序列上游的dsDNA部分,其也可通过邻近的表面结合的转座体或从溶液添加的转座体变成标签化的靶。这种不期望的标签化自身显示通过纯化滤器的与靶基因组对齐的簇的百分比的减少。
这种影响的实例可通过比较图18b中的通道4和5与通道6和7观察到。在通道6和7中,如以上描述的用长的夹板寡核苷酸组装转座体,在延伸和转座体组装之后,长的夹板寡核苷酸产生具有至少50个双链碱基的表面结合的双链体。在用于表面标签化反应(图18a)和随后的测序之后,分别仅22.59%和15.52%的簇与靶大肠杆菌对齐(图18b)。
为了避免产生含有不与靶基因组DNA对齐的序列的簇的群体,如在图17中说明的进行转座体组装。‘夹板’寡核苷酸首先与P5和/或P7表面接枝的寡核苷酸杂交,形成可用聚合酶延伸的可延伸的突出部分,以制备具有双链ME序列的双链体。接下来,通过去退火和冲洗来移除夹板寡核苷酸,并且然后通过使小至12个碱基长但优选地16个碱基长的较短寡核苷酸与表面附接的ME寡核苷酸的3'末端杂交来置换。添加转座酶以组装不含任何暴露的dsDNA的转座体。不含结合的转座酶的任何‘裸’双链体通过在60℃下孵育流通池并在流动条件下洗涤来移除,以选择性地去退火并移除短的双链DNA。
该方法组装转座体的有益影响可在通道4和5中观察到,其中表面结合的转座体通过该方法组装并被用于表面标签化反应(图18a)。与大肠杆菌对齐的簇的百分比从分别对于通道6和7的22.59%和15.52%增加至分别对于通道4和5的96.47%和96.41%。
贯穿该申请已参考多个出版物、专利和/或专利申请。通过引用以其全文将这些出版物的公开内容在此并入该申请。
在本文中术语包括是开放式的,不仅包括提及的要素,另外还包括任何另外的要素。
已描述了很多实施方案。但是,将理解可进行多种改变。相应地,其他的实施方案在所附权利要求书的范围内。
- 还没有人留言评论。精彩留言会获得点赞!