一种敲除PD1的靶向ROR1的嵌合抗原受体T细胞及其制备方法和应用与流程
本发明涉及医学生物领域,特别涉及一种敲除pd1的靶向ror1的嵌合抗原受体t细胞及其制备方法和应用。
背景技术:
恶性肿瘤是最为严重危害人类健康的疾病,每年中国大约三百万人被诊断为新发肿瘤患者,二百万人死于癌症。最近的研究显示,酪氨酸蛋白激酶跨膜受体(receptortyrosinekinaselikeorphanreceptor1,ror1)在多种b细胞恶性肿瘤上被表达的,并且随后在包括套细胞淋巴瘤(mcl)、急性淋巴母细胞性白血病(all)和肺癌、乳腺癌、结肠癌、胰腺癌、肾癌和卵巢癌亚组在内的许多癌症的表面上鉴定了ror1。此外,ror1会在癌症干细胞如卵巢癌干细胞上高表达,并介导其迁移和侵袭。因此,ror1是一种肿瘤特异性高,并在各类肿瘤中具有广谱表达的较为理想的肿瘤靶抗原。
嵌合抗原受体t细胞技术(chimericantigenreceptor–modifiedtcells,car-t)作为当前最新的免疫细胞技术之一,因其能够在体内能激活自身免疫系统,持续性地靶向肿瘤细胞进行杀伤,最终达到完全清除恶性肿瘤细胞,受到广泛的关注和研究。但是,cart技术目前的应用还局限于血液瘤,还未有对肺癌等多数实体瘤的相关研究。
程序性死亡蛋白(pd1)是免疫检查点抑制(immunecheckpointinhibition)中的代表性分子,在机体免疫中通过阻止t细胞激活来负向调节免疫反应,以防止自身免疫疾病并保证自体耐受。在肿瘤微环境中,pd1会抑制杀伤性t细胞的活性,从而使肿瘤细胞逃脱免疫监视。目前还未有敲除pd1的靶向ror1的嵌合抗原受体t细胞且可避免肿瘤细胞逃脱免疫监视的研究。
技术实现要素:
有鉴于此,本发明提供了一种敲除pd1的靶向ror1的嵌合抗原受体t细胞,所述敲除pd1的靶向ror1的嵌合抗原受体t细胞敲除了pd1基因,有利于t细胞在患者体内的扩增,避免肿瘤细胞逃脱免疫监视,具有高效且特异性识别表面具有ror1蛋白的肿瘤细胞,并激活t细胞的免疫作用对ror1阳性肿瘤细胞进行杀伤,具有更加持久细胞活力和杀伤力,并且对正常细胞不会造成损伤。
第一方面,本发明提供了一种敲除pd1的靶向ror1的嵌合抗原受体t细胞的制备方法,包括:
(1)提供嵌合抗原受体car-ror1的编码基因,包括从5’端到3’端顺次连接的信号肽的编码基因、靶向ror1的单链抗体的编码基因、胞外铰链区的编码基因、跨膜区的编码基因、胞内信号区的编码基因,其中,所述靶向ror1的单链抗体的编码基因包括编码如seqidno:1所示的氨基酸序列的核苷酸序列;
(2)将所述car-ror1的编码基因插入到pwpxld载体中,得到pwpxld-car-ror1重组质粒;
(3)包装所述pwpxld-car-ror1重组质粒,得到重组慢病毒;
(4)将所述重组慢病毒转染cd3阳性t淋巴细胞,获得嵌合抗原受体t细胞;
(5)敲除所述嵌合抗原受体t细胞的pd1基因,获得敲除pd1的靶向ror1的嵌合抗原受体t细胞。
可选的,所述靶向ror1的单链抗体的氨基酸序列包括如seqidno:1所示的氨基酸序列。
可选的,所述靶向ror1的单链抗体的氨基酸序列的编码基因包括如seqidno:5所示的核苷酸序列。
可选的,所述靶向ror1的单链抗体的氨基酸序列的编码基因应该考虑简并碱基,即如seqidno:1所示的氨基酸序列的编码基因包括如seqidno:5所示的核苷酸序列,保护范围还应该保护与seqidno:5具有碱基简并性质的核苷酸序列,这些核苷酸序列对应的氨基酸序列仍然为seqidno:1。
本发明中,所述信号肽用于指导所述嵌合抗原受体car-ror1表达到细胞表面,所述信号肽在蛋白翻译成熟过程中被信号肽酶切割。
可选的,所述信号肽的氨基酸序列包括如seqidno:7所示的氨基酸序列。
可选的,所述信号肽的氨基酸序列的编码基因包括如seqidno:8所示的核苷酸序列。
可选的,所述信号肽的氨基酸序列的编码基因应该考虑简并碱基,即如seqidno:7所示的氨基酸序列的编码基因包括如seqidno:8所示的核苷酸序列,保护范围还应该保护与seqidno:8具有碱基简并性质的核苷酸序列,这些核苷酸序列对应的氨基酸序列仍然为seqidno:7。
本发明中,所述胞外铰链区用于促进所述靶向ror1的单链抗体与肿瘤上的ror1结合。
可选的,所述胞外铰链区包括cd8α铰链区、cd28铰链区、cd4铰链区、cd5铰链区、cd134铰链区、cd137铰链区、icos铰链区中的一种或多种的组合。
进一步可选的,所述胞外铰链区包括cd8α铰链区。
可选的,所述cd8α铰链区的氨基酸序列包括如seqidno:9所示的氨基酸序列。
可选的,所述cd8α铰链区的氨基酸序列的编码基因包括如seqidno:10所示的核苷酸序列。
可选的,所述cd8α铰链区的氨基酸序列的编码基因应该考虑简并碱基,即如seqidno:9所示的氨基酸序列的编码基因包括如seqidno:10所示的核苷酸序列,保护范围还应该保护与seqidno:10具有碱基简并性质的核苷酸序列,这些核苷酸序列对应的氨基酸序列仍然为seqidno:9。
本发明中,所述跨膜区用于固定所述嵌合抗原受体car-ror1。
可选的,所述跨膜区包括cd3跨膜区、cd4跨膜区、cd8跨膜区、cd28跨膜区中的一种或多种的组合。
进一步可选的,所述跨膜区包括cd8跨膜区。
可选的,所述cd8跨膜区的氨基酸序列包括如seqidno:11所示的氨基酸序列。
可选的,所述cd8跨膜区的氨基酸序列的编码基因包括如seqidno:12所示的核苷酸序列。
可选的,所述cd8跨膜区的氨基酸序列的编码基因应该考虑简并碱基,即如seqidno:11所示的氨基酸序列的编码基因包括如seqidno:12所示的核苷酸序列,保护范围还应该保护与seqidno:12具有碱基简并性质的核苷酸序列,这些核苷酸序列对应的氨基酸序列仍然为seqidno:11。
本发明中,所述胞内信号区用于提供t细胞活化的信号,维持t细胞的生存时间和激活t细胞增殖信号通路。
可选的,所述胞内信号区包括4-1bb信号区、cd3ζ信号区、icos信号区、cd27信号区、ox40信号区、cd27信号区、cd28信号区、il1r1信号区、cd70信号区、tnfrsf19l信号区中的一种或多种的组合。
可选的,所述胞内信号区包括4-1bb信号区和cd3ζ信号区。
可选的,所述4-1bb信号区的氨基酸序列包括如seqidno:13所示的氨基酸序列。
可选的,所述4-1bb信号区的氨基酸序列的编码基因包括如seqidno:14所示的核苷酸序列。
可选的,所述4-1bb信号区的氨基酸序列的编码基因应该考虑简并碱基,即如seqidno:13所示的氨基酸序列的编码基因包括如seqidno:14所示的核苷酸序列,保护范围还应该保护与seqidno:14具有碱基简并性质的核苷酸序列,这些核苷酸序列对应的氨基酸序列仍然为seqidno:13。
可选的,所述cd3ζ信号区的氨基酸序列包括如seqidno:15所示的氨基酸序列。
可选的,所述cd3ζ信号区的氨基酸序列的编码基因包括如seqidno:16所示的核苷酸序列。
可选的,所述cd3ζ信号区的氨基酸序列的编码基因应该考虑简并碱基,即如seqidno:15所示的氨基酸序列的编码基因包括如seqidno:16所示的核苷酸序列,保护范围还应该保护与seqidno:16具有碱基简并性质的核苷酸序列,这些核苷酸序列对应的氨基酸序列仍然为seqidno:15。
可选的,所述嵌合抗原受体car-ror1的编码基因包括如seqidno:2所示的核苷酸序列。seqidno:2所示的核苷酸序列包含了所述信号肽的编码基因,所述信号肽在蛋白翻译成熟过程中被信号肽酶切割。
所述car-ror1的编码基因插入到pwpxld载体中bamhⅰ和ecorⅰ酶切位点之间,且位于pwpxld载体的延伸因子1α(ef1α)之后,以ef1α为启动子。所述car-ror1的编码基因插入到pwpxld载体时,所述car-ror1的编码基因的5’端可加入起始密码子(如atg)与pwpxld载体中bamh1酶切位点相连,3’端可加入终止密码子(如taa)与pwpxld载体中ecor1酶切位点相连。
可选的,所述靶向嵌合抗原受体car-ror1的氨基酸序列包括如seqidno:4所示的氨基酸序列。
可选的,所述包装所述pwpxld-car-ror1重组质粒,得到重组慢病毒包括:
将所述pwpxld-car-ror1重组质粒与包膜质粒和包装质粒共同转染宿主细胞,得到所述重组慢病毒。
可选的,所述包膜质粒为pmd2g,所述包装质粒为pspax2。
所述包膜质粒pmd2g编码水疱性口炎病毒糖蛋白衣壳,所述水疱性口炎病毒糖蛋白衣壳协助重组慢病毒向细胞膜粘附,并保持重组慢病毒的感染性。
可选地,所述宿主细胞可以包括hek293t细胞、293细胞、293t细胞、293ft细胞、sw480细胞、u87mg细胞、hos细胞、cos1细胞或cos7细胞。
进一步可选的,所述宿主细胞为hek293t细胞。
本发明所述重组慢病毒可以进一步含有来自其它病毒的被膜蛋白。例如,作为这种蛋白质,最好是来自感染人类细胞的病毒被膜蛋白。对这种蛋白质没有特别的限定,可例举出逆转录病毒的兼嗜性病毒手皮膜蛋白等,例如可以使用来自小鼠白血病病毒(mumlv)4070a株的被膜蛋白。另外,也可以使用来自mumlv10al的被膜蛋白。另外,作为疱疹病毒科的蛋白,可以举出例如,单纯性疱疹病毒的gb、gd、gh、gp85蛋白,eb病毒的gp350、gp220蛋白等。作为嗜肝病毒科的蛋白,可以例举出b型肝炎病毒的s蛋白等。所述被膜蛋白还可为麻疹病毒糖蛋白与其他单链抗体融合后形成。
重组慢病毒的包装通常采用瞬时转染或采用细胞系包装。瞬时转染时可以用作包装细胞使用的人类细胞株,例如包括293细胞、293t细胞、293ft细胞、293ltv细胞、293ebna细胞及其他的从293细胞分离的克隆;sw480细胞、u87mg细胞、hos细胞、c8166细胞、mt-4细胞、molt-4细胞、hela细胞、ht1080细胞、te671细胞等。也可以采用来源于猴子的细胞株,例如,cos1细胞、cos7细胞、cv-1细胞、bmt10细胞等。而且,通常采用的磷酸钙和pei转染试剂,还有一些转染试剂如lipofectamine2000、fugene和s93fectin也被经常使用。
重组慢病毒的包装也采用一些慢病毒包装细胞系,如使用最普遍的env糖蛋白、vsvg蛋白或hiv-1gag-pol蛋白所产生的稳定细胞系。
为了安全起见,大规模使用的慢病毒载体系统都是采用分割基因组的方法,即将起不同辅助功能的基因定位于不同的质粒。目前有四质粒系统(编码gag-pol基因、rev基因、vsvg基因、sin转移基因分别位于四个不同的质粒)、三质粒系统(去掉了编码rev基因的质粒,在gag-pol质粒中gag-pol基因采用了在人细胞中偏爱性的密码子)和二质粒系统(慢病毒载体包装所必需的辅助基因位于同一个质粒上,这些辅助基因是单一的基因序列;另一个则是转基因质粒)。也有超过四质粒系统的慢病毒包装系统在使用。
可选的,步骤(4)中,所述cd3阳性t淋巴细胞是从人源外周血单个核细胞中分离获得。
可选的,所述人源外周血单个核细胞来源于自体静脉血、自体骨髓、脐带血和胎盘血等。
进一步可选的,来源于癌症患者手术一个月后、放化疗一个月后采集的新鲜外周血或骨髓。
具体的,所述cd3阳性t淋巴细胞的获得过程如下:向外周血单个核细胞中按一定比例加入cd3/cd28免疫磁珠,孵育一段时间后,放入磁铁进行筛选,得到免疫磁珠包被的cd3阳性t淋巴细胞,去除磁珠后,获得cd3阳性t淋巴细胞。
可选的,所述敲除所述嵌合抗原受体t细胞的pd1基因采用电转染和crispr/cas9技术敲除所述嵌合抗原受体t细胞的pd1基因。
进一步地,所述敲除所述嵌合抗原受体t细胞的pd1基因,包括以下步骤:
将所述cas9的编码基因插入至pcdna3.1载体中,得到pcdna3.1-cas9重组质粒,以所述pcdna3.1-cas9重组质粒为模板进行体外转录得到cas9mrna;
提供靶向pd1基因的sgrna对应的基因序列;将所述靶向pd1基因的sgrna对应的基因序列插入至pcdna3.1载体中,得到pcdna3.1-pd1-sgrna重组质粒,以所述pcdna3.1-pd1-sgrna重组质粒为模板进行体外转录得到sgrna;
将所述cas9mrna和所述靶向pd1基因的sgrna与所述嵌合抗原受体t细胞进行混合,并置于电转仪中进行电转,完成所述嵌合抗原受体t细胞的pd1基因的敲除。
可选的,所述靶向pd1基因的sgrna对应的基因序列包括如seqidno:3所示的核苷酸序列。
可选的,所述cas9mrna和所述pd1基因的sgrna的质量比为1:1-1:5。
进一步可选的,所述cas9mrna和所述pd1基因的sgrna的质量比为1:3。
本发明中,步骤(5)中,获得的敲除pd1的靶向ror1的嵌合抗原受体t细胞,是在步骤(4)中的嵌合抗原受体t细胞的基础上敲除了细胞的pd1基因。步骤(4)中的嵌合抗原受体t细胞也具有一定的靶向ror1的作用,但可能会出现肿瘤细胞逃脱免疫监视的现象。敲除pd1基因获得的敲除pd1的靶向ror1的嵌合抗原受体t细胞对肿瘤细胞的靶向性更强,且避免了肿瘤细胞逃脱免疫监视的情况。
本发明第一方面提供的敲除pd1的靶向ror1的嵌合抗原受体t细胞的制备方法,通过制备靶向ror1的嵌合抗原受体得到嵌合抗原受体t细胞,并敲除t细胞上的pd1基因制得敲除pd1的靶向ror1的嵌合抗原受体t细胞,该制备方法有利于t细胞在患者体内的扩增,避免肿瘤细胞逃脱免疫监视,使其具有高效且特异性的杀伤肿瘤细胞的性能,尤其适用于ror1阳性肿瘤细胞或组织。
在本发明的另一实施方式中,也可以采用以下方法来制备敲除pd1的靶向ror1的嵌合抗原受体t细胞,包括以下步骤:
(1)提供cd3阳性t淋巴细胞,敲除所述cd3阳性t淋巴细胞的pd1基因,得到敲除pd1的cd3阳性t淋巴细胞;
(2)提供靶向ror1的嵌合抗原受体car-ror1的编码基因,包括从5’端到3’端顺次连接的信号肽的编码基因、靶向ror1的单链抗体的编码基因、胞外铰链区的编码基因、跨膜区的编码基因、胞内信号区的编码基因,其中,所述靶向ror1的单链抗体的编码基因包括编码如seqidno:1所示的氨基酸序列的基因序列;
(3)将所述car-ror1的编码基因插入到pwpxld载体中,得到pwpxld-car-ror1重组质粒;
(4)包装所述pwpxld-car-ror1重组质粒,得到重组慢病毒;
(5)将所述重组慢病毒转染所述敲除pd1的cd3阳性t淋巴细胞,得到敲除pd1的靶向ror1的嵌合抗原受体t细胞。
本发明中,所述敲除pd1的靶向ror1的嵌合抗原受体t细胞的制备过程中,敲除过程可以针对所述cd3阳性t淋巴细胞时进行,也可以在获得敲除pd1的靶向ror1的嵌合抗原受体t细胞后进行。在本发明中对敲除顺序不作限定,只要可以达到获得敲除pd1的靶向ror1的嵌合抗原受体t细胞的目的即可。
第二方面,本发明提供了采用如第一方面所述的制备方法制备得到的敲除pd1的靶向ror1的嵌合抗原受体t细胞,所述敲除pd1的靶向ror1的嵌合抗原受体t细胞不包括pd1基因,所述敲除pd1的靶向ror1的嵌合抗原受体t细胞包括靶向ror1的嵌合抗原受体car-ror1,所述靶向ror1的嵌合抗原受体car-ror1包括从氨基端到羧基端顺次连接的靶向ror1的单链抗体、胞外铰链区、跨膜区和胞内信号区的氨基酸序列,其中,所述靶向ror1的单链抗体包括如seqidno:1所示的氨基酸序列。
上述“从氨基端到羧基端顺次连接”具体为:所述靶向ror1的单链抗体的氨基酸序列的羧基端与所述胞外铰链区的氨基酸序列的氨基端相连,所述胞外铰链区的氨基酸序列的羧基端与所述跨膜区的氨基酸序列的氨基端相连,所述跨膜区的氨基酸序列的羧基端与所述胞内信号区的氨基酸序列的氨基端相连。
其中,所述靶向ror1的单链抗体、胞外铰链区、跨膜区、胞内信号区的具体选择及相应的氨基酸序列如本发明第一方面部分所述,在此不再赘述。
可选的,所述靶向嵌合抗原受体car-ror1的氨基酸序列包括如seqidno:4所示的氨基酸序列。
可选的,所述靶向嵌合抗原受体car-ror1的氨基酸序列的编码基因包括如seqidno:6所示的核苷酸序列。
可选的,所述car-ror1的氨基酸序列的编码基因应该考虑简并碱基,即如seqidno:4所示的氨基酸序列的编码基因包括如seqidno:6所示的核苷酸序列,保护范围还应该保护与seqidno:6具有碱基简并性质的核苷酸序列,这些核苷酸序列对应的氨基酸序列仍然为seqidno:4。
优选地,所述嵌合抗原受体car-ror1的编码基因包括如seqidno:2所示的核苷酸序列。seqidno:2所示的核苷酸序列包含了所述信号肽的编码基因,所述信号肽能指导所述嵌合抗原受体car-ror1表达到细胞表面,但信号肽在蛋白翻译成熟过程中被信号肽酶切割。
本发明第二方面提供的所述敲除pd1的靶向ror1的嵌合抗原受体t细胞,可以专一性的靶向ror1,尤其是表达ror1的实体瘤细胞。在car-ror1与ror1结合后,所述t细胞的胞内信号区被激活,促进t细胞在患者体内的扩增,高效且特异性的杀伤肿瘤细胞,而对正常细胞几乎不会造成损伤;此外,基于靶向ror1的单链抗体为人源化单链抗体,这使得该t细胞避免引起人机体的免疫反应,持久地维持细胞的活力和杀伤力;所述t细胞敲除了pd1基因,可以避免肿瘤细胞逃脱免疫监视,使其具有高效且特异性的杀伤肿瘤细胞的性能。本发明所述靶向her2的嵌合抗原受体t细胞可以高效识别并杀伤包括急性淋巴母细胞性白血病和乳腺癌、结肠癌、胰腺癌、肾癌和卵巢癌等表达有ror1的癌细胞,尤其适用于ror1阳性的肺癌细胞或组织。
第三方面,本发明提供了一种如第一方面所述的制备方法制备得到的或如第二方面所述的一种敲除pd1的靶向ror1的嵌合抗原受体t细胞在制备预防、诊断和治疗恶性肿瘤的药物中的应用。特定地,可用于预防、诊断和治疗多种肿瘤,包括急性淋巴母细胞性白血病和乳腺癌、结肠癌、胰腺癌、肾癌和卵巢癌等表达有ror1的癌细胞,尤其适用于ror1阳性的肺癌细胞或组织。
所述应用具体为:提供了一种试剂盒,所述试剂盒包括如第一方面所述的制备方法制备得到的或如第二方面所述的一种敲除pd1的靶向ror1的嵌合抗原受体t细胞。
本发明的有益效果:
本发明提供的敲除pd1的靶向ror1的嵌合抗原受体t细胞可以专一性的靶向ror1,促进t细胞在患者体内的扩增,能够高效且特异性的杀伤肿瘤细胞,同时ror1在肿瘤细胞中广泛表达,而在普通细胞中表达很微弱,因此敲除pd1的靶向ror1的嵌合抗原受体t细胞可以特异性的结合表面具有ror1抗原的肿瘤细胞,对ror1阳性肿瘤细胞产生杀伤效果,对正常细胞不会造成损伤,同时敲除了t细胞的pd1基因,有利于t细胞在患者体内的扩增,避免肿瘤细胞逃脱免疫监视,使其具有高效且特异性的杀伤肿瘤细胞的性能,促使t细胞具有持久的活力和杀伤力。
附图说明
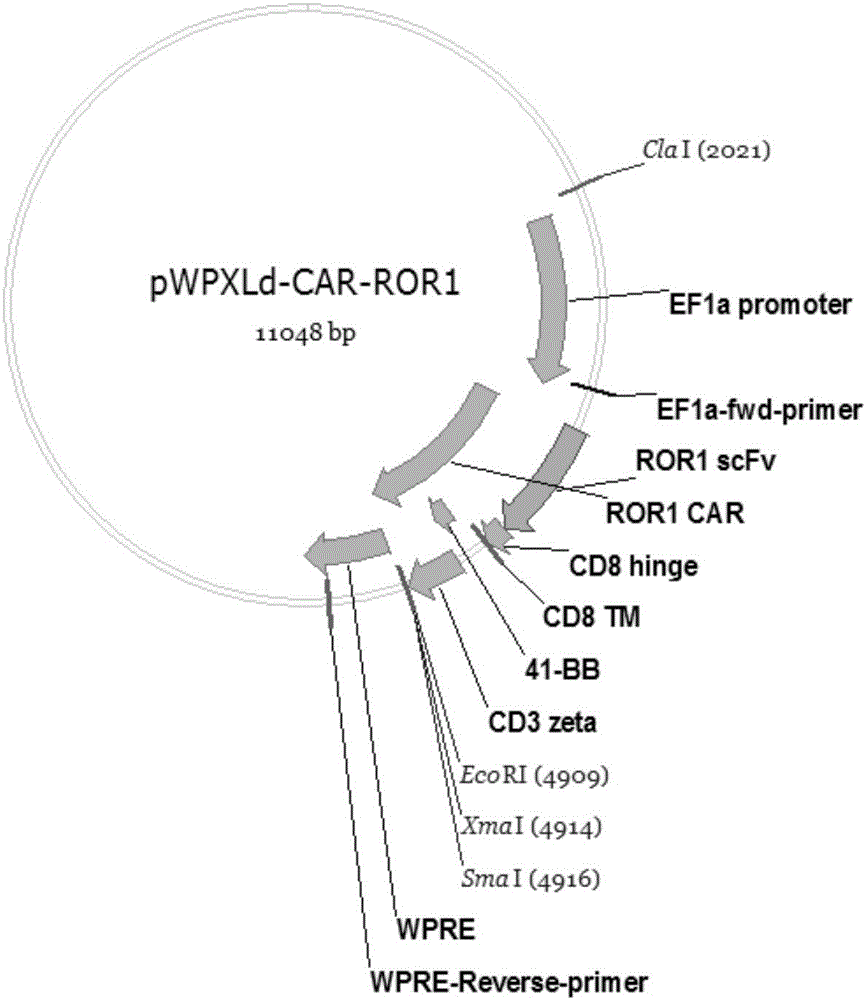
图1为本发明实施例提供的pwpxld-car-ror1重组质粒的质粒图谱。
图2为本发明实施例提供的敲除pd1的靶向ror1的嵌合抗原受体t细胞的阳性率;图2中(a)为阴性对照组,图2中(b)为本发明实施例提供的敲除pd1的靶向ror1的嵌合抗原受体t细胞的实验组。
图3为本发明实施例提供的敲除pd1的靶向ror1的嵌合抗原受体t细胞的体外肿瘤细胞杀伤效果图。
图4为本发明实施例提供的敲除pd1的靶向ror1的嵌合抗原受体t细胞治疗肿瘤小鼠的效果图。
具体实施方式
以下所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
实施例一
一种敲除pd1的靶向ror1的嵌合抗原受体t细胞的制备方法,包括以下步骤:
(1)制备靶向ror1的嵌合抗原受体car-ror1的基因序列
分别制备信号肽、靶向ror1的单链抗体、cd8α铰链区、cd8跨膜区、4-1bb信号区和cd3ζ信号区的编码基因,所述信号肽的编码基因如seqidno:8所示,所述靶向ror1的单链抗体的编码基因如seqidno:5所示,所述cd8α铰链区的编码基因如seqidno:10所示,所述cd8跨膜区的编码基因如seqidno:12所示,所述4-1bb信号区的编码基因如seqidno:14所示,所述cd3ζ信号区的编码基因如seqidno:16所示。
通过pcr的方法将上述信号肽、靶向ror1的单链抗体、cd8α铰链区、cd8跨膜区、4-1bb信号区和cd3ζ信号区的编码基因依次从5’端到3’端连接到一起,得到靶向ror1的嵌合抗原受体car-ror1的编码基因,所述car-ror1的编码基因如seqidno:2所示。
(2)构建pwpxld-car-ror1重组质粒
将car-ror1的编码基因插入到pwpxld载体的bamh1和ecor1酶切位点之间,并在pwpxld载体的ef1α之后,以ef1α为启动子。所述car-ror1的编码基因插入到pwpxld载体时,所述car-ror1的编码基因的5’端添加起始密码子(如atg)与pwpxld载体中bamh1酶切位点相连,3’端还添加有终止密码子(如taa)与pwpxld载体中ecor1酶切位点相连。然后转入大肠杆菌感受态细胞dh5α,进行阳性克隆pcr鉴定和测序鉴定。经过pcr产物凝胶电泳检测和测序鉴定符合目的片段大小和序列,成功构建如图1所示的pwpxld-car-ror1重组质粒。
(3)重组慢病毒构建
将pwpxld-car-ror1重组质粒、包装质粒pspax2、包膜质粒pmd2g三者共转染入培养好的hek293t细胞。第48h收获含病毒的上清,经0.45μm滤膜过滤,-80℃超低温冰箱中保存;第72h二次收获含病毒的上清,0.45μm滤膜过滤,与第48h收获的病毒上清合并一起加入超速离心管中,逐一放入至beckman超速离心机内,设置离心参数为25000rpm,离心时间为2h,离心温度控制在4℃;离心结束后,弃去上清,尽量去除残留在管壁上的液体,加入病毒保存液,轻轻反复吹打重悬;经充分溶解后,高速离心10000rpm,离心5min后,取上清荧光法测定滴度,病毒按照100μl,2×108个/ml分装,保存于-80℃超低温冰箱,得到重组慢病毒。
(4)嵌合抗原受体t细胞的制备
a)pbmc(外周血单个核细胞)的分离
pbmc来源于自体静脉血、自体骨髓、脐带血和胎盘血等。最好是来源于癌症患者手术一个月后、放化疗一个月后采集的新鲜外周血或骨髓。
抽取病人血液,送样至血液分离室;采集外周血单个核细胞,ficoll离心分离后取中间层细胞;经pbs洗涤后,得到pbmc。
b)免疫磁珠法分离抗原特异性t淋巴细胞
取上述pbmc,加入不含血清的基础培养基,配成细胞悬液;按磁珠与细胞的比例为3:1,加入cd3/cd28免疫磁珠,室温孵1-2h;采用磁铁对孵育好磁珠的细胞进行筛选;pbs洗涤,去除免疫磁珠后,得到cd3阳性t淋巴细胞。
c)病毒转染法制备抗原特异性t淋巴细胞
取上述经过免疫磁珠分离法得到的cd3阳性t淋巴细胞,加入与cd3阳性细胞数相应的病毒滴度的所述重组慢病毒进行培养。
培养的第3天,进行细胞计数和换液,调整细胞浓度为1×106个/ml,接种,培养;培养的第5天,观察细胞状态,如果细胞密度增大,则稀释细胞浓度为1×106个/ml,检测细胞活性,继续培养。扩增培养到第9-11天,收集细胞,得到嵌合抗原受体t细胞。
d)敲除pd1基因
将所述cas9的编码基因插入至pcdna3.1载体中,得到pcdna3.1-cas9重组质粒,以所述pcdna3.1-cas9重组质粒为模板,利用mmessage
提供靶向pd1基因的sgrna对应的基因序列,其序列如seqidno:3所示;将所述靶向pd1基因的sgrna对应的基因序列插入至pcdna3.1载体中,得到pcdna3.1-pd1-sgrna重组质粒,以所述pcdna3.1-pd1-sgrna重组质粒为模板进行体外转录得到sgrna;
将所述cas9mrna和所述靶向pd1基因的sgrna序列与上述得到嵌合抗原受体t细胞进行混合,并置于电转仪中进行电转,敲除t细胞的pd1基因;将电转后的t细胞进行培养,得到敲除pd1的靶向ror1的嵌合抗原受体t细胞。
利用流式细胞仪测定上述敲除pd1的靶向ror1的嵌合抗原受体t细胞的pd1表达量,计算敲除率,结果发现敲除pd1的靶向ror1的嵌合抗原受体t细胞中pd1基因的敲除率达79%。
为了评估本发明所描述的上述方法制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞效果,进行如下效果实施例。
效果实施例一:评估本发明所制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞的阳性率
将经过本发明方法制备敲除pd1的靶向ror1的嵌合抗原受体t细胞(实验组)与未经制备的t淋巴细胞(阴性对照组),使用流式细胞仪检测其阳性率,结果如图2所示,其中图2中(a)为阴性对照组,即未经制备的t细胞,图2中(b)为实验组,即为本发明制得的敲除pd1的靶向ror1的嵌合抗原受体t细胞。由图2中(a)与(b)比较可得到,本发明所制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞的阳性率为49.9%。
效果实施例二:评估敲除pd1的靶向ror1的嵌合抗原受体t细胞的体外肿瘤细胞杀伤情况
将经过本发明方法制得的敲除pd1的靶向ror1的嵌合抗原受体t细胞(实验组)与未经制备的t淋巴细胞(阴性对照组)的体外肿瘤杀伤效果进行比较,具体的:在体外将效应细胞(敲除pd1的靶向ror1的嵌合抗原受体t细胞或未经制备的t淋巴细胞)与靶细胞(h526细胞)按数量比为1:10、1:3、1:1、3:1和10:1比例,在37℃,5%co2下进行共培养,在培养后的第15-18小时,收集细胞,进行流式染色,检测细胞杀伤情况,结果如图3所示。从图3中可看出,添加的敲除pd1的靶向ror1的嵌合抗原受体t细胞越多,它们对肿瘤细胞的杀伤力越强。经过本发明所述的方法制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞的肿瘤杀伤力均在20%以上,甚至可达45%,远远高于阴性对照组,这说明经本发明方法制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞具有强的肿瘤杀伤能力。
效果实施例三:评估敲除pd1的靶向ror1的嵌合抗原受体t细胞的小鼠体内肿瘤细胞杀伤情况
将经过本发明方法制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞(实验组)、未经制备的t淋巴细胞(阴性对照组)以及生理盐水(空白对照组),在小鼠肿瘤模型中,给每只小鼠尾静脉注射1×106个h526细胞(n=9),绘制小鼠的生存曲线,结果如图4所示。从图4可以看出,经过本方法制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞使得小鼠在培养50天时存活率还高于50%,在培养80天及更长时间时的存活率超过20%,远远超过阴性对照组和空白对照组。图4的结果表明,经过本方法制备的敲除pd1的靶向ror1的嵌合抗原受体t细胞能够更好的保护小鼠免于因肿瘤导致的死亡。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
序列表
<110>深圳宾德生物技术有限公司
<120>一种敲除pd1的靶向ror1的嵌合抗原受体t细胞及其制备方法和应用
<160>16
<170>siposequencelisting1.0
<210>1
<211>332
<212>prt
<213>人工序列(artificialsequence)
<400>1
cysproproglyhishisilesergluaspglyargaspcysileser
151015
cyslystyrglyglnasptyrserthrhistrpasnaspleuleuphe
202530
cysleuargcysthrargcysaspserglygluvalgluleuserpro
354045
cysthrthrthrargasnthrvalcysglncysglugluglythrphe
505560
argglugluaspserproglumetcysarglyscysargthrglycys
65707580
proargglymetvallysvalglyaspcysthrprotrpseraspile
859095
glucysvalhislysglugluprolyssercysasplysthrhisthr
100105110
cysproprocysproalaprogluleuleuglyglyproservalphe
115120125
leupheproprolysprolysaspthrleumetileserargthrpro
130135140
gluvalthrcysvalvalvalaspvalserhisgluaspprogluval
145150155160
lyspheasntrptyrvalaspglyvalgluvalhisasnalalysthr
165170175
lysproargglugluglntyrasnserthrtyrargvalvalserval
180185190
leuthrvalleuhisglnasptrpleuasnglylysglutyrlyscys
195200205
lysvalserasnlysalaleuproalaproileglulysthrileser
210215220
lysalalysglyglnproarggluproglnvaltyrthrleupropro
225230235240
serargaspgluleuthrlysasnglnvalserleuthrcysleuval
245250255
lysglyphetyrproseraspilealavalglutrpgluserasngly
260265270
glnprogluasnasntyrlysthrthrproprovalleuaspserasp
275280285
glyserphepheleutyrserlysleuthrvalasplysserargtrp
290295300
glnglnglyasnvalphesercysservalmethisglualaleuhis
305310315320
asnhistyrthrglnlysserleuserleuserpro
325330
<210>2
<211>575
<212>prt
<213>人工序列(artificialsequence)
<400>2
alaleuprovalthralaleuleuleuproleualaleuleuleuhis
151015
alaalaargprocysproproglyhishisilesergluaspglyarg
202530
aspcysilesercyslystyrglyglnasptyrserthrhistrpasn
354045
aspleuleuphecysleuargcysthrargcysaspserglygluval
505560
gluleuserprocysthrthrthrargasnthrvalcysglncysglu
65707580
gluglythrpheargglugluaspserproglumetcysarglyscys
859095
argthrglycysproargglymetvallysvalglyaspcysthrpro
100105110
trpseraspileglucysvalhislysglugluprolyssercysasp
115120125
lysthrhisthrcysproprocysproalaprogluleuleuglygly
130135140
proservalpheleupheproprolysprolysaspthrleumetile
145150155160
serargthrprogluvalthrcysvalvalvalaspvalserhisglu
165170175
aspprogluvallyspheasntrptyrvalaspglyvalgluvalhis
180185190
asnalalysthrlysproargglugluglntyrasnserthrtyrarg
195200205
valvalservalleuthrvalleuhisglnasptrpleuasnglylys
210215220
glutyrlyscyslysvalserasnlysalaleuproalaproileglu
225230235240
lysthrileserlysalalysglyglnproarggluproglnvaltyr
245250255
thrleuproproserargaspgluleuthrlysasnglnvalserleu
260265270
thrcysleuvallysglyphetyrproseraspilealavalglutrp
275280285
gluserasnglyglnprogluasnasntyrlysthrthrproproval
290295300
leuaspseraspglyserphepheleutyrserlysleuthrvalasp
305310315320
lysserargtrpglnglnglyasnvalphesercysservalmethis
325330335
glualaleuhisasnhistyrthrglnlysserleuserleuserpro
340345350
thrthrthrproalaproargproprothrproalaprothrileala
355360365
serglnproleuserleuargproglualacysargproalaalagly
370375380
glyalavalhisthrargglyleuaspphealacysaspiletyrile
385390395400
trpalaproleualaglythrcysglyvalleuleuleuserleuval
405410415
ilethrleutyrcyslysargglyarglyslysleuleutyrilephe
420425430
lysglnprophemetargprovalglnthrthrglnglugluaspgly
435440445
cyssercysargpheproglugluglugluglyglycysgluleuarg
450455460
vallyspheserargseralaaspalaproalatyrlysglnglygln
465470475480
asnglnleutyrasngluleuasnleuglyargarggluglutyrasp
485490495
valleuasplysargargglyargaspproglumetglyglylyspro
500505510
argarglysasnproglngluglyleutyrasngluleuglnlysasp
515520525
lysmetalaglualatyrsergluileglymetlysglygluargarg
530535540
argglylysglyhisaspglyleutyrglnglyleuserthralathr
545550555560
lysaspthrtyraspalaleuhismetglnalaleuproproarg
565570575
<210>3
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>3
cacgaagctctccgatgtgttgg23
<210>4
<211>555
<212>prt
<213>人工序列(artificialsequence)
<400>4
cysproproglyhishisilesergluaspglyargaspcysileser
151015
cyslystyrglyglnasptyrserthrhistrpasnaspleuleuphe
202530
cysleuargcysthrargcysaspserglygluvalgluleuserpro
354045
cysthrthrthrargasnthrvalcysglncysglugluglythrphe
505560
argglugluaspserproglumetcysarglyscysargthrglycys
65707580
proargglymetvallysvalglyaspcysthrprotrpseraspile
859095
glucysvalhislysglugluprolyssercysasplysthrhisthr
100105110
cysproprocysproalaprogluleuleuglyglyproservalphe
115120125
leupheproprolysprolysaspthrleumetileserargthrpro
130135140
gluvalthrcysvalvalvalaspvalserhisgluaspprogluval
145150155160
lyspheasntrptyrvalaspglyvalgluvalhisasnalalysthr
165170175
lysproargglugluglntyrasnserthrtyrargvalvalserval
180185190
leuthrvalleuhisglnasptrpleuasnglylysglutyrlyscys
195200205
lysvalserasnlysalaleuproalaproileglulysthrileser
210215220
lysalalysglyglnproarggluproglnvaltyrthrleupropro
225230235240
serargaspgluleuthrlysasnglnvalserleuthrcysleuval
245250255
lysglyphetyrproseraspilealavalglutrpgluserasngly
260265270
glnprogluasnasntyrlysthrthrproprovalleuaspserasp
275280285
glyserphepheleutyrserlysleuthrvalasplysserargtrp
290295300
glnglnglyasnvalphesercysservalmethisglualaleuhis
305310315320
asnhistyrthrglnlysserleuserleuserprothrthrthrpro
325330335
alaproargproprothrproalaprothrilealaserglnproleu
340345350
serleuargproglualacysargproalaalaglyglyalavalhis
355360365
thrargglyleuaspphealacysaspiletyriletrpalaproleu
370375380
alaglythrcysglyvalleuleuleuserleuvalilethrleutyr
385390395400
cyslysargglyarglyslysleuleutyrilephelysglnprophe
405410415
metargprovalglnthrthrglnglugluaspglycyssercysarg
420425430
pheproglugluglugluglyglycysgluleuargvallyspheser
435440445
argseralaaspalaproalatyrlysglnglyglnasnglnleutyr
450455460
asngluleuasnleuglyargarggluglutyraspvalleuasplys
465470475480
argargglyargaspproglumetglyglylysproargarglysasn
485490495
proglngluglyleutyrasngluleuglnlysasplysmetalaglu
500505510
alatyrsergluileglymetlysglygluargargargglylysgly
515520525
hisaspglyleutyrglnglyleuserthralathrlysaspthrtyr
530535540
aspalaleuhismetglnalaleuproproarg
545550555
<210>5
<211>996
<212>dna
<213>人工序列(artificialsequence)
<400>5
tgtccacctggacaccatatctcagaagacggtagagattgcatctcctgcaaatatgga60
caggactatagcactcactggaatgacctccttttctgcttgcgctgcaccaggtgtgat120
tcaggtgaagtggagctaagtccctgcaccacgaccagaaacacagtgtgtcagtgcgaa180
gaaggcaccttccgggaagaagattctcctgagatgtgccggaagtgccgcacagggtgt240
cccagagggatggtcaaggtcggtgattgtacaccctggagtgacatcgaatgtgtccac300
aaagaagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaa360
ctcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatc420
tcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtc480
aagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggag540
gagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactgg600
ctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgag660
aaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgccccca720
tcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctat780
cccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagacc840
acgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggac900
aagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcac960
aaccactacacgcagaagagcctctccctgtctccg996
<210>4
<211>1665
<212>dna
<213>人工序列(artificialsequence)
<400>4
tgtccacctggacaccatatctcagaagacggtagagattgcatctcctgcaaatatgga60
caggactatagcactcactggaatgacctccttttctgcttgcgctgcaccaggtgtgat120
tcaggtgaagtggagctaagtccctgcaccacgaccagaaacacagtgtgtcagtgcgaa180
gaaggcaccttccgggaagaagattctcctgagatgtgccggaagtgccgcacagggtgt240
cccagagggatggtcaaggtcggtgattgtacaccctggagtgacatcgaatgtgtccac300
aaagaagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaa360
ctcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatc420
tcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtc480
aagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggag540
gagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactgg600
ctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgag660
aaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgccccca720
tcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctat780
cccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagacc840
acgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggac900
aagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcac960
aaccactacacgcagaagagcctctccctgtctccgaccactaccccagcaccgaggcca1020
cccaccccggctcctaccatcgcctcccagcctctgtccctgcgtccggaggcatgtaga1080
cccgcagctggtggggccgtgcatacccggggtcttgacttcgcctgcgatatctacatt1140
tgggcccctctggctggtacttgcggggtcctgctgctttcactcgtgatcactctttac1200
tgtaagcgcggtcggaagaagctgctgtacatctttaagcaacccttcatgaggcctgtg1260
cagactactcaagaggaggacggctgttcatgccggttcccagaggaggaggaaggcggc1320
tgcgaactgcgcgtgaaattcagccgcagcgcagatgctccagcctacaagcaggggcag1380
aaccagctctacaacgaactcaatcttggtcggagagaggagtacgacgtgctggacaag1440
cggagaggacgggacccagaaatgggcgggaagccgcgcagaaagaatccccaagagggc1500
ctgtacaacgagctccaaaaggataagatggcagaagcctatagcgagattggtatgaaa1560
ggggaacgcagaagaggcaaaggccacgacggactgtaccagggactcagcaccgccacc1620
aaggacacctatgacgctcttcacatgcaggccctgccgcctcgg1665
<210>7
<211>20
<212>prt
<213>人工序列(artificialsequence)
<400>7
alaleuprovalthralaleuleuleuproleualaleuleuleuhis
151015
alaalaargpro
20
<210>8
<211>60
<212>dna
<213>人工序列(artificialsequence)
<400>8
gccctccctgtcaccgccctgctgcttccgctggctcttctgctccacgccgctcggccc60
<210>9
<211>46
<212>prt
<213>人工序列(artificialsequence)
<400>9
thrthrthrproalaproargproprothrproalaprothrileala
151015
serglnproleuserleuargproglualacysargproalaalagly
202530
glyalavalhisthrargglyleuaspphealacysaspile
354045
<210>10
<211>138
<212>dna
<213>人工序列(artificialsequence)
<400>10
accactaccccagcaccgaggccacccaccccggctcctaccatcgcctcccagcctctg60
tccctgcgtccggaggcatgtagacccgcagctggtggggccgtgcatacccggggtctt120
gacttcgcctgcgatatc138
<210>11
<211>26
<212>prt
<213>人工序列(artificialsequence)
<400>11
tyriletrpalaproleualaglythrcysglyvalleuleuleuser
151015
leuvalilethrleutyrcyslysarggly
2025
<210>12
<211>78
<212>dna
<213>人工序列(artificialsequence)
<400>12
tacatttgggcccctctggctggtacttgcggggtcctgctgctttcactcgtgatcact60
ctttactgtaagcgcggt78
<210>13
<211>39
<212>prt
<213>人工序列(artificialsequence)
<400>13
arglyslysleuleutyrilephelysglnprophemetargproval
151015
glnthrthrglnglugluaspglycyssercysargpheprogluglu
202530
glugluglyglycysgluleu
35
<210>14
<211>117
<212>dna
<213>人工序列(artificialsequence)
<400>14
cggaagaagctgctgtacatctttaagcaacccttcatgaggcctgtgcagactactcaa60
gaggaggacggctgttcatgccggttcccagaggaggaggaaggcggctgcgaactg117
<210>15
<211>112
<212>prt
<213>人工序列(artificialsequence)
<400>15
argvallyspheserargseralaaspalaproalatyrlysglngly
151015
glnasnglnleutyrasngluleuasnleuglyargarggluglutyr
202530
aspvalleuasplysargargglyargaspproglumetglyglylys
354045
proargarglysasnproglngluglyleutyrasngluleuglnlys
505560
asplysmetalaglualatyrsergluileglymetlysglygluarg
65707580
argargglylysglyhisaspglyleutyrglnglyleuserthrala
859095
thrlysaspthrtyraspalaleuhismetglnalaleuproproarg
100105110
<210>16
<211>336
<212>dna
<213>人工序列(artificialsequence)
<400>16
cgcgtgaaattcagccgcagcgcagatgctccagcctacaagcaggggcagaaccagctc60
tacaacgaactcaatcttggtcggagagaggagtacgacgtgctggacaagcggagagga120
cgggacccagaaatgggcgggaagccgcgcagaaagaatccccaagagggcctgtacaac180
gagctccaaaaggataagatggcagaagcctatagcgagattggtatgaaaggggaacgc240
agaagaggcaaaggccacgacggactgtaccagggactcagcaccgccaccaaggacacc300
tatgacgctcttcacatgcaggccctgccgcctcgg336
- 还没有人留言评论。精彩留言会获得点赞!