一种高灵敏的SNPs检测体系及应用的制作方法
本发明属于生物医学领域,具体涉及一种高灵敏的snps检测体系及应用。
背景技术:
单核苷酸多态性即snps是指基因组dna序列中由于单个核苷酸(a,g,c,t)替换而引起的多态性,是新一代多态性遗传标记。snps在生物基因组中广泛存在,如人类30亿个碱基中每千个碱基出现一次,在整个基因组共有300万以上的snps。snps和疾病的发生发展密切相关。目前市面上针对snps检测的方法有许多,包括一代测序、二代测序,基因芯片、荧光定量pcr(qpcr)技术等。但是在较高的野生型模板的背景下,针对稀有的snps的检测能力有限。
稀有snps,指的是存在大于量野生基因序列背景中的极为稀少的基因序列。在癌症病人或是治疗后病人血液中含有少量的肿瘤突变dna(ct-dna);孕妇外周血含有少量的胎儿dna等,这些情况都属于大量野生型背景下的稀有基因检测。许多引起肿瘤的体细胞突变都是掺杂在野生型细胞内的,所提的dna也是带有大量野生型dna,同样需要采用稀有snps的检测方法。因此,稀有snps的检测在癌症筛查和预后跟踪、无创产前筛查等具有十分重要的意义。
和测序技术检测snps相比,qpcr技术具有迅速、方便、价格低等优点,可以做到对snps的高灵敏检测。评价snps检测方法的优劣包括:灵敏度、特异性、简便程度等。灵敏度是指在大量野生型dna背景下能够检测到的最小突变型的量;特异性是指不被检测到的最大突变型的量。基于pcr技术的稀有snps的特异性扩增的检测方法可以归为两类:(1)特异性引物扩增方法;(2)非特异性引物加特异性blockers的方法.第一类的特异性引物扩增的方法有arms(amplificationrefractorymutationsystem),asb-pcr(allele-specificblockerpcr),以及castpcr(competitiveallelespecifictaqmanpcr).第二类方法包括pnablockerpcr和cold-pcr(co-amplificationatlowerdenaturationtemperaturepcr)等。以上的方法有的需要碱基的修饰、特殊的反应试剂或特殊的反应程序,有的检测灵敏度不够高等,所以我们需要一种简单的、灵敏度更高的检测方法。
技术实现要素:
为了克服上述缺陷,本发明提供一种基于qpcr的高灵敏的snps检测体系及应用,其能够方便、高灵敏、定量地检测稀有突变,可应用于液体活检、无创产前筛查等。
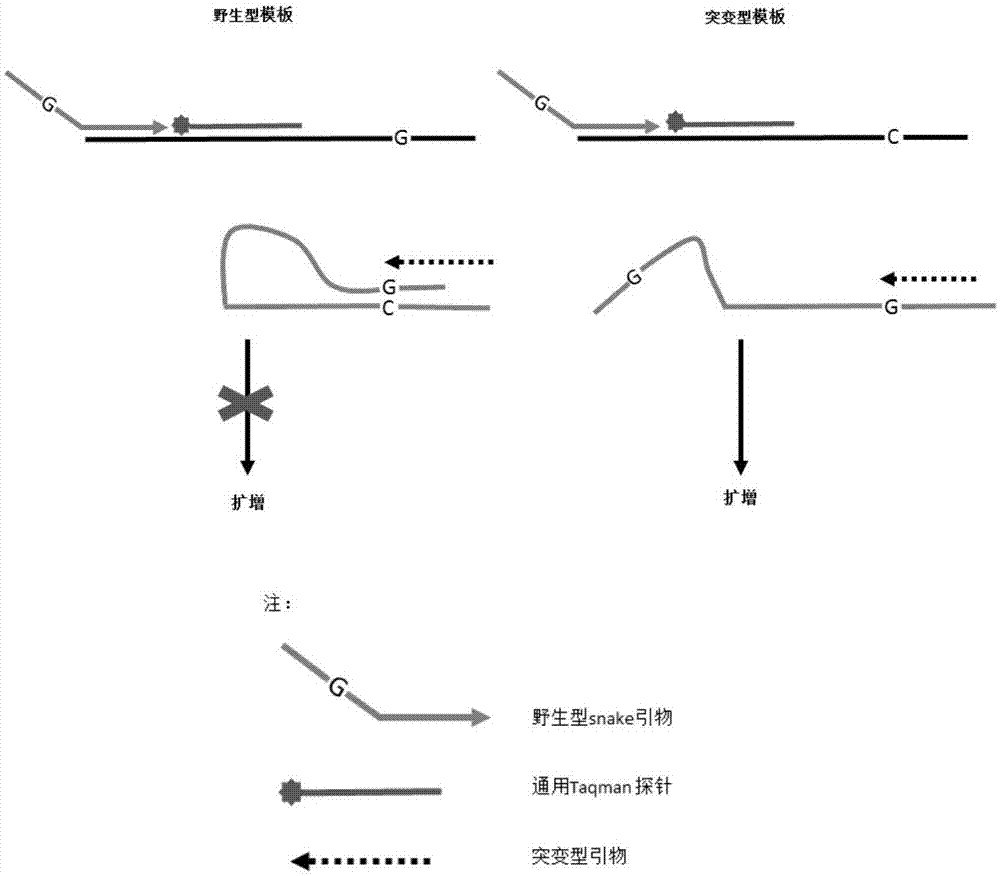
为解决上述技术问题,本发明采用如下技术方案:一种高灵敏的snps的检测体系,包括分别针对野生型、突变型基因的野生型snake引物、突变型的snake引物,以及分别针对野生型、突变型基因的野生型引物、突变型引物;野生型snake引物、突变型引物、通用发光探针构成第一引物组合,用于特异性扩增突变型模板;突变型snake引物、野生型引物、通用发光探针构成第二引物组合,用于特异性扩增野生型模板。通用发光探针为taqman探针或molecularbeacon探针。
所述的检测体系为pcr扩增体系。
野生型snake引物的3’端是长度为不少于15个碱基的与模板(该段碱基序列跟突变型和野生型模板均互补)互补的引物序列,5’端是与延伸出的野生型扩增子互补而形成二级结构的拖尾或突出序列,长度在6-20个碱基;
突变型snake引物的3’端是长度为不少于15个碱基的与模板(该段碱基序列跟突变型和野生型模板均互补)互补的引物序列,5’端是与延伸出的突变型扩增子互补而形成二级结构的拖尾或突出序列,长度在6-20个碱基;野生型snake引物和突变型snake引物,只有拖尾或突出序列中的一个碱基不同,其它碱基均相同;此不同碱基位于野生型snake引物和突变型snake引物的5’端的拖尾或突出序列第一个碱基与最后一个碱基之间的任意位置。
突变型引物和突变型模板互补,野生型引物和野生型模板互补;突变型和野生型引物在3’端或中间位置有一个碱基的不同;野生型引物和野生型引物的长度不少于15个碱基。
检测体系中,模板为提取的含有稀有突变或野生型基因的生物样本dna、逆转录所得的cdna、合成的质粒dna、单链dna;检测体系还包括热启动聚合酶,聚合酶buffer、dntps、mgcl2、snake引物、引物与通用发光探针。野生型snake引物、突变型引物、通用发光探针、突变型snake引物、野生型引物的引物或探针的浓度均在0.01-2μm。引物为合成的单链dna或是经过修饰的改变杂交亲和力的dna,包括锁核酸(lna)、肽核酸(pna或dna小沟结合物(mgb)等一种以及一种以上的组合。
检测时,用一定浓度的野生型snake引物、突变型的snake引物,突变型和野生型引物,通用发光探针以及pcr所需要的其它原料组成pcr体系,对样本进行定量pcr检测;野生型snake引物、突变型引物和通用发光探针组成一管,特异性扩增突变型模板;突变型snake引物、野生型引物和通用发光探针组成另一管,特异性扩增野生型模板。通过定量曲线分析以及与标准品曲线对比即可知道稀有突变的频率和拷贝数。
所述的定量pcr检测中,使用taqman探针、分子信标或其他发光探针获取信号。
本发明还提供包括至少两个容器的试剂盒,所述容器包含独立分配于至少两个容器中的下列成分:突变型snake引物或野生型snake引物、突变型或野生型引物、通用发光探针、样本dna、热启动聚合酶、聚合酶buffer、dntps、mgcl2,以及可以使pcr进行的合适反应程序。不同容器中分别装有野生型snake引物、突变型引物和通用发光探针的组合或突变型snake引物、野生型引物和通用发光探针的组合。
所述的试剂盒用于单重或多重检测snps位点。
试剂盒具体包含以下三组序列中的至少一组:
每组序列中,野生型snake引物-1、野生型snake引物-2中任选一个,突变型snake引物-1、突变型snake引物-2中任选一个,野生型引物-1、野生型引物-2中任选一个,突变型引物-1、突变型引物-2中任选一个。
本发明还提供前述的检测体系在制备snps突变检测试剂中的应用。
申请人发明了一种基于qpcr技术的特异性snake引物和和另一引物竞争杂交的检测方法cosp(competitivesnakeprimerpcr),具有较高的检测灵敏度和特异性。检测突变型模板时,在含有snake引物的扩增子中,特异性snake引物的突出部分与野生型模板互补配对形成发卡结构,而与突变型不互补从而不形成发卡结构或发卡结构较弱,发卡结构阻碍了另一引物与野生型模板的杂交,而与突变型模板杂交不受阻碍或阻碍较小,使得突变型模板得到扩增,而野生型模板的扩增得到抑制,从而起到了高灵敏检测snps的目的。本方法可以检测千分之一及以上的稀有snps,灵敏度高,使用方便。
本发明通过特异性snake引物和和另一引物竞争杂交方法,提高了检测的特异性和灵敏度。通过标准品以及标准曲线的绘制,很好的避免了假阳性和假阴性结果。可以不需要特殊反应试剂和碱基特殊修饰,成本低;不需要特殊反应程序,操作简单。
附图说明
图1:cosp检测snps流程图;
图2:cosp野生型snake引物合并突变型下游引物检测野生型和突变型模板的定量曲线图;
图3:cosp检测lpl基因snps的灵敏度示意图;
图4:cosp检测lpl基因不同比例突变型模板的定量曲线;
图5:cosp检测l858rsnps的灵敏度示意图;
图6:cosp检测l858r不同比例突变型模板的定量曲线;
图7:cosp检测t790msnps的灵敏度示意图;
图8:cosp检测t790m不同比例突变型模板的定量曲线。
具体实施方式
下面结合实施例对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
1.本发明高灵敏的snps检测方法cosp(competitivesnakeprimerpcr)选择性扩增目标核酸序列,可应用于检测核酸变异体的试剂盒中,广泛适用核酸扩增、肿瘤体外诊断、基因分型等领域。针对野生型和突变型基因设计的野生型和突变型的snake上游或下游引物,野生型和突变型下游或上游引物。用一定浓度的野生型和突变型的snake引物,突变型和野生型引物,通用发光探针以及其他反应原料组成pcr体系,对样本进行定量pcr检测。
2.野生型snake引物由两部分组成,3’端是一段不少于15个碱基的与模板互补的引物序列,5’端是一段与延伸出的野生型扩增子互补而形成二级结构的拖尾序列,长度在6-20个碱基。突变型snake引物也由两部分组成,3’端是一段不少于15个碱基的与模板互补的引物序列,5’端是一段与延伸出的突变型扩增子互补而形成二级结构的拖尾序列,长度在6-20个碱基。野生型和突变型snake引物只有拖尾序列(又称为突出序列)中的一个碱基不同,其他碱基均相同。此不同的碱基位于5’端的拖尾序列中的第一个碱基与最后一个碱基之间的任意位置(不包括第一个碱基、最后一个碱基)。
突变型引物和突变型模板互补、野生型引物和野生型模板互补。突变型和野生型引物在3’端或中间位置有一个碱基的不同。长度不少于15个碱基。
野生型snake引物、突变型snake引物、突变型引物、野生型引物、通用发光探针均为合成的单链dna或是经过修饰的改变杂交亲和力的dna,包括锁核酸(lna)、肽核酸(pna)或dna小沟结合物(mgb)等一种以及一种以上的组合。
3.在pcr反应中,野生型snake引物、突变型引物和通用发光探针组成一管,特异性扩增突变型模板;突变型snake引物、野生型引物和通用发光探针组成另一管,特异性扩增野生型模板。通过定量曲线分析以及与标准品曲线对比即可知道稀有突变的频率和拷贝数。
4.所述的定量pcr检测中,使用taqman探针、分子信标或其他发光探针获取信号。
5.定量pcr检测反应体系中包括snake引物(野生型snake引物、突变型snake引物)和引物(突变型引物、野生型引物),snake引物、引物之中,其中一个为上游引物,另一个为下游引物;比如野生型snake引物为上游引物,则突变型引物为下游引物。上下游的引物浓度在0.01-2μm左右。模板为提取的含有稀有突变或野生型基因的样本dna,逆转录所得的cdna,合成的质粒dna,单链dna等,反应体系还包括热启动聚合酶,聚合酶buffer、dntps、mgcl2,以及可以使pcr进行的合适的反应温度。此方法可以单重或多重检测snps位点。
本发明高灵敏检测snps的原理如下:
特异性snake引物和和另一引物竞争杂交的检测方法cosp(competitivesnakeprimerpcr),具有较高的检测灵敏度和特异性。检测突变型模板时,在含有snake引物的扩增子中,特异性野生型snake引物的突出部分与野生型模板互补配对形成二级结构,而与突变型不互补从而不会形成二级结构或二级结构较弱,二级结构阻碍了另一引物(突变型引物)与野生型模板的杂交,而与突变型模板杂交不受阻碍或阻碍较小,使得突变型模板得到扩增,而野生型模板的扩增得到抑制,从而起到了高灵敏检测snps的目的。本方法可以检测千分之一及以上的稀有snps,灵敏度高,使用方便。与标准品曲线对比,可以确定稀有snps的频率和拷贝数,很好的避免了假阳性和假阴性。
实施例一:
1.snake引物和引物设计:
根据野生型模板和突变型模板设计野生型和突变型的上游snake引物,野生型和突变型下游引物(表1)。使用本方法检测lpl基因的4号外显子区域的一个碱基的突变。序列如下:
表1实施例一所用引物
其中,引物-1、2均为可用引物,在使用时任选其一均可实现发明目的。且引物-1可与引物-1或引物-2组合使用。
2.cosp中野生型snake引物合并突变型引物检测突变型模板的灵敏度:
cosp反应体系总体积为30ul,含有2mmmgcl2,50mmkcl,0.3mmdntps,特异性引物0.1μm,0.05u/ul热启动聚合酶,各梯度模板5ul。经95℃酶激活15min,再95℃变性15s,56℃退火延伸1min,45个循环。使用7500fast系统进行pcr以及信号采集。从图3、图4(其中图4中百分比为各梯度模板中,突变型模板占总模板的质量百分比)看出,cosp具备检测万分之一snps的能力。
实施例二:
1.snake引物和引物设计:
根据野生型模板和突变型模板设计野生型和突变型的上游snake引物,野生型和突变型下游引物(表2)。使用本方法检测egfr基因的l858r(2573t-g)突变。
表2实施例二所用引物
其中,引物-1、2均为可用引物,在使用时任选其一均可实现发明目的。且引物-1可与引物-1或引物-2组合使用。
2.cosp检测l858r突变的灵敏度:
cosp反应体系的总体积为30ul,含有1.5mmmgcl2,50mmkcl,0.2mmdntps,特异性引物0.025μm,0.02u/ul热启动聚合酶,各梯度模板10ul。经95℃酶激活15min,再95℃变性15s,57℃退火延伸30s,65个循环。使用7500fast系统进行pcr以及信号采集。从图5和图6(其中图6百分比为各梯度模板中,突变型模板占突变型模板和野生型模板之和的质量百分比;m指模板仅为突变型模板,w指模板仅为野生型模板,m、w对应曲线源自图2)看出,cosp检测千分之一snps。
实施例三:
1.snake引物和引物设计:
根据野生型模板和突变型模板设计野生型和突变型的上游snake引物,野生型和突变型下游引物(表3)。使用本方法检测egfr基因的t790m()突变。
表3实施例三所用引物
其中,引物-1、2均为可用引物,在使用时任选其一均可实现发明目的。且引物-1可与引物-1或引物-2组合使用。
2.cosp检测l858r突变的灵敏度:
cosp反应体系的总体积为30ul,含有1.3mmmgcl2,50mmkcl,0.2mmdntps,特异性引物0.04μm,0.02u/ul热启动聚合酶,各梯度模板10ul。经95℃酶激活15min,再95℃变性15s,57℃退火延伸30s,65个循环。使用7500fast系统进行pcr以及信号采集。从图7、图8(其中图8百分比为各梯度模板中,突变型模板占突变型模板和野生型模板之和的质量百分比;m指模板仅为突变型模板,w指模板仅为野生型模板,m、w对应曲线源自图2)看出,cosp检测千分之一snps。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节。
序列表
<110>苏州唯善生物科技有限公司
<120>一种高灵敏的snps的检测体系及应用
<130>xhx2018121801
<141>2018-12-18
<160>27
<170>siposequencelisting1.0
<210>17
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>17
ctgaaaagtacctccattcgggt23
<210>2
<211>27
<212>dna
<213>人工序列(artificialsequence)
<400>2
caatcacgcaccagttgggcatgttga27
<210>3
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>3
gcaatcacgcaccagttgggcatgttga28
<210>4
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>4
ccaagtcctctctctgcaatc21
<210>5
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>5
caagtcctctctctgcaatc20
<210>6
<211>27
<212>dna
<213>人工序列(artificialsequence)
<400>6
caatgacgcaccagttgggcatgttga27
<210>7
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>7
gcaatgacgcaccagttgggcatgttga28
<210>8
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>8
ccaagtcctctctctgcaatg21
<210>9
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>9
caagtcctctctctgcaatg20
<210>10
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>10
ctggcagccaggaacgtactggt23
<210>11
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>11
ttggccagcccagaccgtcgcttggtgca29
<210>12
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>12
ttggccagcccaagaccgtcgcttggtgca30
<210>13
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>13
cacccagcagtttggccc18
<210>14
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>14
acccagcagtttggccc17
<210>15
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>15
ttggcccgcccagaccgtcgcttggtgca29
<210>16
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>16
ttggcccgcccaagaccgtcgcttggtgca30
<210>17
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>17
cacccagcagtttggcca18
<210>18
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>18
acccagcagtttggcca17
<210>19
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>19
cggtggaggtgaggcagatgc21
<210>20
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>20
agctgcgtgatgaacgtgtgccgcctgct29
<210>21
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>21
aagctgcgtgatgacgtgtgccgcctgct29
<210>22
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>22
gcgaagggcatgagctg17
<210>23
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>23
ccgaacgcaccggagg16
<210>24
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>24
agctgcatgatgaacgtgtgccgcctgct29
<210>25
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>25
aagctgcatgatgacgtgtgccgcctgct29
<210>26
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>26
gcgaagggcatgagctgca19
<210>27
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>27
ccgaacgcaccggaggca18
- 还没有人留言评论。精彩留言会获得点赞!