产生广藿香醇和榄香醇、以及优选地还有广藿香奥醇的萜烯合成酶的制作方法
本发明涉及广藿香醇合成酶,编码所述广藿香醇合成酶的核酸,包含该核酸的表达载体,包含所述表达载体的宿主细胞,制备广藿香醇和榄香醇、以及优选地还有广藿香奥醇的方法,以及制备广藿香醇合成酶的方法。
背景技术:
许多生物都有能力生产各种各样的萜烯和类萜。萜烯实际上或概念上由2-甲基丁烷残基(通常称为异戊二烯单元)构建而成,其分子式为c5h8。人们可以将异戊二烯单元视为自然界的常见组成部分之一。萜烯的基本分子式是该分子式的倍数:(c5h8)n,其中,n是连接的异戊二烯单元的数目。这称为异戊二烯规则,因此,萜烯也称为异戊二烯类。异戊二烯单元可以“头对尾”连接在一起以形成线性链,或者可以布置成形成环。在其生物合成中,萜烯由通用的5碳前体异戊烯基二磷酸酯(ipp)及其异构体二磷酸二甲基烯丙酯(dmapp)形成。因此,萜烯的碳骨架通常包含5个碳原子的倍数。最常见的是5碳、10碳、15碳、20碳、30碳和40碳的萜烯,它们分别称为半萜、单萜、倍半萜、二萜、三萜和四萜。除了“头对尾”连接之外,三萜和四萜在它们的中心还包含“尾对尾”连接。萜烯可以包含其他官能团,例如醇及其糖苷、醚、醛、酮、羧酸和酯。这些官能化的萜烯在本文中称为类萜。像萜烯一样,类萜通常具有5个碳原子的倍数的碳骨架。应该注意的是,类萜化合物中的碳总数不必是5的倍数,例如官能团可以是包含具有任何碳原子数的烷基的酯基。
除了上面给出的定义,重要的是要注意,术语“萜烯”、“类萜”和“异戊二烯”在公开和专利文献中经常互换使用。
广藿香醇是天然存在的倍半萜烯醇,在特定的植物中产生,例如广藿香(pogostemoncablin)、薄荷科的草本植物(唇形科)。广藿香醇是广藿香油的主要成分。广藿香油是通过对刺蕊草属的干燥叶进行蒸汽蒸馏而获得的重要香料成分。广藿香油是一种重要的香料成分,用于高级香水、化妆品如护肤霜、口红、粉、洗发水、剃须膏、发油和肥皂香料中。广藿香油具有特征性的气味特征,已被描述为温暖、草本、樟脑和木质。广藿香醇不仅是广藿香油的主要成分,而且还是主要的气味成分(
发现来自广藿香的单一广藿香醇合成酶可产生大部分广藿香油成分(deguerry等,archivesofbiochemistryandbiophysics(2006):454:123–36)。可以使用化学方法生产对映体广藿香醇(
已经提出了微生物学上的广藿香醇的制备,其利用通过合并编码具有广藿香醇合成酶活性的蛋白质的基因而被基因修饰的微生物。广藿香醇合成酶可用于由fpp制备广藿香醇,该转化可以作为分离的反应(体外)或作为更长的代谢途径的一部分进行,最终导致由糖产生广藿香醇(体内)。
us20090205060描述了使用来自广藿香的广藿香醇合成酶生产广藿香醇的方法。美国专利8992284、wo2011141855描述了来自蜘蛛香(valerianajatamansi)的萜烯合成酶,其同时产生广藿香醇和7-表-α-芹子烯。
芬美意(firmenich)在2014年推出了clearwoodtm的广藿香油替代品,该替代品源自糖的发酵生产,被描述“天然油中发现的柔和、干净的广藿香版,没有泥土、皮革和橡胶味”(leffingwell等,leffingwellreports(2015)7:1–11)。
到目前为止,在刺蕊草属和缬草属中已鉴定出已知唯一形成广藿香醇的萜烯合成酶。然而,已经描述了其他植物可以生产一些广藿香醇型的倍半萜烯(choudhury等,india.j.essent.res.(1996):8,633),但是相应的合成酶是未知的。
当前已知的广藿香醇合成酶具有许多明显的缺点,当将它们应用到工业广藿香醇生产方法中时,这是特别不希望的,在该方法中,广藿香醇是由fpp制备的,可以在分离的反应中(体外)进行,例如使用分离的广藿香醇合成酶或(透化的)全细胞,或者以其他方式进行,例如在发酵过程中作为更长的代谢途径的一部分。因此,需要可用于制备广藿香醇的另一种广藿香醇合成酶。特别地,需要至少在选定的宿主细胞中显示出表达改善的替代的广藿香醇合成酶;一种至少在特定条件下(例如在中性或碱性ph下)和/或在其胞内产生的细胞内的具有高酶促活性的广藿香醇合成酶;和/或对于至少在特定条件下(例如在大约中性或碱性ph下和/或在其已胞内产生的细胞内)催化fpp向广藿香醇其他广藿香醇类萜烯的转化,替代的广藿香醇合成酶,其具有高特异性,特别是与来自广藿香的广藿香醇合成酶相比具有改善的特异性。
已经发现迄今未知的特定多肽具有广藿香醇合成酶活性,并且该多肽可用作催化剂,可以用作已知广藿香醇合成酶的替代物。还发现该广藿香醇合成酶还产生倍半萜醇广藿香奥醇和榄香醇。迄今为止还未知还可以合成榄香醇的广藿香醇合成酶,并且该广藿香醇和榄香醇伴随合成,这种新型广藿香醇合成酶对于工业广藿香醇生产工艺特别有利。榄香醇已被描述为具有甜木香的气味,富含榄香醇的香精油馏分(例如来自榄香油和香茅油)在香料厂中用作固定剂、混合剂或改性剂(ansari&curtis,j.soc.cosmetchem(1974):25,203-231)。
技术实现要素:
因此,本发明涉及包含如seqidno:4所示的氨基酸序列的广藿香醇合成酶或其功能同源物,所述功能同源物是包含与seqidno:4具有至少75%的序列同一性的氨基酸序列的广藿香醇合成酶。所述同源物尤其可以是包含与seqidno:4具有至少80%、至少85%、至少90%、至少95%、至少98%或至少99%的序列同一性的氨基酸序列的广藿香醇合成酶。
本发明进一步涉及一种核酸,其包含编码根据本发明的广藿香醇合成酶的核酸序列,或包含与所述编码序列互补的核酸序列。特别地,该核酸可以选自包含如seqidno:3或seqidno:5所示的核酸序列的核酸,以及编码根据本发明的广藿香醇合成酶的其他核酸序列,所述其他序列包括与seqidno:3或seqidno:5所示的核酸序列具有至少75%、特别是至少80%、至少85%、至少90%、至少95%、至少98%或至少99%的序列同一性的核酸序列,或分别与其互补的核酸。在下文中,可以将根据本发明的编码广藿香醇合成酶的所述其他核酸序列称为功能类似物。
根据本发明的广藿香醇合成酶或核酸可以是天然化合物或从其天然来源(例如匙叶甘松(nardostachysjatamansi))分离的化合物的片段是化学或酶促合成的化合物或化合物片段或在重组细胞中产生的化合物或化合物片段,其可能存在于重组细胞中,也可能从中分离出来。
本发明进一步涉及包含根据本发明的核酸的表达载体。
本发明进一步涉及宿主细胞,其可以是生物本身或多细胞生物的一部分,该宿主细胞包含表达载体,所述表达载体包含根据本发明的核酸,优选与所述宿主细胞异源的核酸。宿主细胞优选选自细菌细胞、真菌细胞(包括酵母)和植物细胞。
本发明进一步涉及一种制备广藿香醇和榄香醇、优选地还有广藿香奥醇的方法,包括在存在根据本发明的广藿香醇合成酶的情况下将fpp转化为广藿香醇和榄香醇、以及优选地还有广藿香奥醇。可以存在四种不同的fpp几何异构体,即2e,6e-fpp、2z,6e-fpp、2e,6z-fpp、和2z,6z-fpp。尽管原则上fpp的任何其他异构体可以是根据本发明的酶的合适底物,但是使用2e,6e-fpp已经获得了良好的结果。
本发明进一步涉及用于产生根据本发明的广藿香醇合成酶的方法,该方法包括在有利于产生广藿香醇合成酶的条件下培养根据本发明的宿主细胞,以及任选地从宿主细胞回收广藿香醇合成酶。
令人惊奇地发现,根据本发明的广藿香醇合成酶可产生广藿香醇和榄香醇。在本发明之前,尚无可产生广藿香醇和榄香醇的萜烯合成酶。此外,根据本发明的广藿香醇合成酶产生广藿香奥醇。因此,与例如获得自广藿香的广藿香醇合成酶相比,根据本发明的广藿香醇合成酶具有有利的产物谱,特别是中性ph下或附近的在体外测定法或在其中广藿香醇和榄香醇、以及优选地还有广藿香奥醇在被基因修饰以分别产生根据本发明的广藿香醇合成酶以及广藿香的广藿香醇合成酶的宿主细胞中的胞内合成的方法中。因此,优选地,根据本发明的广藿香醇合成酶产生广藿香醇和榄香醇,优选地,其榄香醇与广藿香醇的比例为1:5-1:9,优选为1:6-1:8,更优选为1:6.5-1:7.5,最优选约1:6.9。
优选地,根据本发明的广藿香醇合成酶还产生广藿香奥醇,优选地广藿香奥醇与广藿香醇的比例为1:4-1:7,优选地为1:4.5-1:6.5,更优选地为1:5-1-1:6,最优选为约1:5.6。更优选地,榄香醇与广藿香奥醇的比例在1:0.7-1:2.25之间,优选在1:0.9-1:1.75之间,更优选在1:1.1-1:1.5之间,最优选为约1:1.3。
根据本发明,已经发现可以在不同的生物体中以良好的产率表达广藿香醇合成酶。例如,已发现广藿香醇合成酶在大肠杆菌(e.coli)、类球红细菌(rhodobactersphaeroides)和本生烟(nicotianabenthamiana)植物中表达良好。
因此,在一个有利的实施方案中,本发明提供了一种广藿香醇合成酶,当其在用于制备广藿香醇和榄香醇、以及优选地还有广藿香奥醇的方法中时,特别是与来自广藿香的广藿香醇合成酶或根据本文引用的现有技术中的其他广藿香醇合成酶相比,具有针对广藿香醇合成的催化具有改进的特异性并且对于广藿香醇和榄香醇、以及优选地还有广藿香奥醇具有改进的生产率。
在一个优选的实施方案中,提供了一种制备根据本发明的广藿香醇和榄香醇、以及优选地还有广藿香奥醇的方法,其中所述广藿香醇和榄香醇、以及优选地还有广藿香奥醇是在表达所述广藿香醇合成酶的根据本发明的宿主细胞、植物或植物培养物、或者蘑菇或蘑菇培养物中制备。优选地,根据本发明的用于制备广藿香醇和榄香醇、以及优选地还有广藿香奥醇的方法中还包括从所述宿主细胞、植物或植物培养物、或者蘑菇或蘑菇培养物中分离该广藿香醇、广藿香奥醇和/或榄香醇。优选地,根据本发明的制备广藿香醇的方法产生的广藿香奥醇与广藿香醇的比例为1:4-1:7,优选地为1:4.5-1:6.5,更优选地为1:5-1.6,最优选地为约1:5.6,榄香醇与广藿香醇之比为1:5-1:9,优选为1:6-1:8,更优选为1:6.5-1:7.5,最优选为约1:6.9,和/或榄香醇与广藿香奥醇的比例为1:0.7-1:2.25,优选为1:0.9-1:1.75,更优选为1:1.1-1:1.5,最优选为约1:1.3。
不受理论的束缚,据认为对于在细胞内制备广藿香醇的方法,在中性或弱碱性ph下对广藿香醇合成的催化具有高特异性是特别期望的,因为认为各种宿主细胞具有中性或微碱性的细胞内ph,例如7.0-8.5的ph(关于细菌的细胞内ph值,参见:booth,microbiologicalreviews(1985)49:359-378)。例如,当大肠杆菌细胞暴露于5.5至8.0的ph值时,细胞内ph值在7.1至7.9之间(olsen等,appl.environ.microbiol.(2002)68:4145–4147)。这可以解释本发明的广藿香醇合成酶(也在细胞内的)对广藿香醇的合成的改进的特异性。
除非另有说明,否则本文使用的术语“或”定义为“和/或”。
除非另有说明,否则本文所用的术语“一个”定义为“至少一个”。
当以单数形式指代名词(例如,化合物、添加剂等)时,意在包括复数。
本文可互换使用的术语法尼基二磷酸和法尼基焦磷酸(均缩写为fpp)是指化合物3,7,11-三甲基-2,6,10-十二碳三烯-1-基焦磷酸,并包括该化合物的所有已知异构体。
如本文所用,与重组细胞、载体、核酸等有关的术语“重组”是指含有非天然存在于该细胞、载体、核酸等和/或不在同一位置自然发生的核酸的细胞、载体、核酸等。通常,已使用重组dna技术将所述核酸引入该菌株(细胞)。
当就核酸(dna或rna)或蛋白质使用时,术语“异源”是指核酸或蛋白不作为其所在的微生物、细胞、基因组或dna或rna序列的一部分而天然存在,或者指在不同于核酸或蛋白天然发现的细胞或基因组中一个或多个位点或dna或rna序列发现的核酸或蛋白。异源核酸或蛋白质对于引入它们的细胞不是内源的,而是已经从另一细胞获得或合成或重组产生。通常,尽管不是必须的,但是这种核酸编码通常由表达dna的细胞不产生的蛋白质。
对于特定宿主细胞是内源性但已通过例如使用dna改组从其天然形式进行修饰的基因也称为异源基因。术语“异源的”还包括天然存在的dna序列的非天然存在的多个拷贝。因此,术语“异源”可以指与细胞外源或异源,或与细胞同源但在宿主细胞核酸内的位置和/或数目中通常不发现该片段的dna片段。表达外源dna片段以产生外源多肽。“同源”dna序列是与导入它的宿主细胞天然相关的dna序列。
术语异源核酸或蛋白质涵盖了本领域技术人员会认识到的与表达其的细胞是异源或外来的任何核酸或蛋白质。
如本文所用,关于蛋白质或多肽的术语“突变的”或“突变”是指野生型或天然存在的蛋白质或多肽序列中的至少一个氨基酸已被不同的氨基酸替换,或被缺失或被插入通过诱变编码这些氨基酸的核酸进入序列。诱变是本领域中众所周知的方法,并且包括例如通过pcr或通过寡核苷酸介导的诱变进行定点诱变,例如描述于sambrook,j.,和russell,d.w.molecularcloning:alaboratorymanual.第三版,coldspringharborlaboratorypress,coldspringharbor,ny,(2001)。如本文所用,关于基因的术语“突变的”或“突变”是指该基因的核苷酸序列或其调节序列中的至少一个核苷酸通过突变已被不同的核苷酸取代或已从该核苷酸中缺失或插入到该序列中。
术语“开放阅读框”和“orf”是指在编码序列的翻译起始密码子和终止密码子之间编码的氨基酸序列。术语“起始密码子”和“终止密码子”是指三个相邻核苷酸的单位(“密码子”),其分别指定蛋白质合成(mrna翻译)的起始和链终止。
术语“基因”广泛用于指与生物学功能有关的核酸的任何区段。因此,基因包括其表达所需的编码序列和/或调节序列。例如,基因是指表达mrna或功能性rna或编码特定蛋白质的核酸片段,其包括调节序列。基因还包括未表达的dna片段,例如形成其他蛋白质的识别序列。基因可以从多种来源获得,包括从目标来源克隆或从已知或预测的序列信息合成,并且可以包括设计成具有所需参数的序列。
术语“嵌合基因”是指包含以下信息的任何基因:1)dna序列,包括调节序列和编码序列,这些序列在自然界中并不一起发现,或2)编码非天然结合的蛋白质部分的序列,或3)没有自然地相邻。因此,嵌合基因可包含衍生自不同来源的调节序列和编码序列,或包含衍生自相同来源但以与自然界不同的方式排列的调节序列和编码序列。
如本文所用,转基因细胞或生物的术语“转基因”是指含有如下核酸的生物或细胞(该细胞本身可以是微生物或分离出其的多细胞生物的细胞),该核酸非天然存在于该生物体或细胞中,并且已使用重组dna技术将核酸引入该生物体或细胞中(即已引入该生物体或细胞本身,或已引入该生物体的祖先或该细胞已被分离出的微生物的祖先微生物)。
“转基因”是指已经通过转化引入基因组中并且优选被稳定地维持的基因。转基因可包括例如与待转化的特定植物的基因异源或同源的基因。另外,转基因可包含插入非天然生物中的天然基因,或嵌合基因。术语“内源基因”是指在生物体基因组中其天然位置的天然基因。“外源”基因是指通常不在宿主生物中发现但通过基因转移引入的基因。
如本文所用,“转化”是指将异源核苷酸序列引入宿主细胞,而与用于插入的方法无关,例如直接摄取、转导、缀合、f-交配或电穿孔。可以将外源多核苷酸维持为非整合载体,例如质粒,或者可以整合至宿主细胞基因组中。
“编码序列”指编码特定氨基酸序列并排除非编码序列的dna或rna序列。它可以构成“不间断的编码序列”,包括缺少内含子,如在cdna中那样,或它可以包含由适宜剪接交界界定的一个或多个内含子。“内含子”是含于初级转录物内但是在细胞内部经切割而移除并且rna再连接以产生可以翻译成蛋白质的成熟mrna的rna序列。
“调节序列”指位于编码序列上游(5'非编码序列)、内部或下游(3'非编码序列)并影响所结合的编码序列的转录、rna加工或稳定性或翻译的核苷酸序列。调节序列包括增强子、启动子、翻译前导序列序列、内含子和多聚腺苷化信号序列。它们包括天然和合成性序列以及可以作为合成序列和天然序列组合的序列。如上文所示,术语“合适的调节序列”不限于启动子。
调节序列的例子包括启动子(如转录启动子、组成型启动子、诱导型启动子)、操纵基因、或增强子、mrna核糖体结合位点,和控制转录及翻译起始与终止的适宜序列。当调节序列功能地与本发明的cdna序列相关时,核酸序列“可操作地连接”。
每个调节序列可以独立地选自异源和同源调节序列。
“启动子”指核苷酸序列,通常在其编码序列上游(5'),其中所述核苷酸序列通过为正确转录所需的rna聚合酶和其他因子提供识别,控制所述编码序列的表达。“启动子”包括最小启动子,它是由tata框和起到规定转录启动位点的其他序列组成的短dna序列,向其添加调节元件以控制表达。“启动子”也指核苷酸序列,其包括最小启动子外加能够控制编码序列或功能性rna表达的调节元件。这种类型的启动子序列由近端上游元件和更远的上游元件组成,后一类元件经常称作增强子。因此,“增强子”是这样的dna序列,该序列可以刺激启动子活性并且可以是该启动子的固有元件或经插入以增强启动子的水平或组织特异性的异源元件。它能够以两种取向(正常或反转)工作,并且甚至从启动子上游或下游被移动的情况下也能够发挥作用。增强子和其他上游启动子元件均结合介导它们作用的序列特异性dna结合蛋白。启动子可以完全源自天然基因,或由不同的元件组成,源自自然界中存在的不同启动子,或甚至由合成性dna区段组成。启动子也可以含有参与结合蛋白质因子的dna序列,所述蛋白质因子控制响应于生理或发育状况时转录起始的有效性。
如本文所用,术语“核酸”包括对脱氧核糖核苷酸或核糖核苷酸聚合物的称谓,即,处于单链或双链形式的多核苷酸,并且除非另外限制,否则涵盖具有天然核苷酸实质特性的已知类似物,在于它们以类似于天然存在核苷酸的方式与单链核酸杂交(例如,肽核酸)。多核苷酸可以是天然或异源结构基因或调节基因的全长或子序列。除非另外说明,该包括指定序列以及其互补序列。因而,为稳定性或出于其他原因而修饰主链的dna或rna主链修饰是本文如该术语意指的“多核苷酸”。另外,包含稀有碱基(如肌苷)或修饰碱基(如三苯甲基化碱基)的dna或rna(仅提到两个实例)是如该术语在此使用的“多核苷酸”。可以理解已经对dna和rna进行种类多样的修饰,这些修饰起到本领域技术人员已知的许多有用目的。如本文中使用的术语“多核苷酸”包括这类化学、酶促或代谢修饰形式的多核苷酸,以及作为病毒和细胞(包括简单细胞和复杂细胞,这仅为其中之一)之特征的dna和rna的化学形式。
通过参考遗传密码,本文中编码多肽的每个核酸序列也描述了每种可能的核酸沉默变异。术语“保守性修饰的变体”适用于氨基酸序列和核酸序列。就特定核酸序列而言,术语“保守性修饰的变体”指因遗传密码简并性而编码相同变体或保守修饰变体的那些核酸。术语“遗传密码的简并性”指众多功能上相同的核酸编码任一给定蛋白质的事实。例如,密码子gca、gcc、gcg和gcu均编码氨基酸丙氨酸。因而,在其中丙氨酸由某个密码子指定的每个位置,可以将该密码子变成任一个所述的相应密码子,而不改变编码的多肽。这类核酸变异是“沉默性变异”并且代表一个种类的保守性修饰的变异。术语“多肽”、“肽”和“蛋白质”在此互换地使用来指氨基酸残基的聚合物。这些术语适用于其中一个或多个氨基酸残基是相应的天然存在氨基酸的人造化学类似物的氨基酸聚合物,以及适用于天然存在的氨基酸聚合物。天然存在氨基酸的此类类似物的本质特性是当掺入蛋白质中时,该蛋白质与针对同一蛋白质所激发的、但完全由天然存在氨基酸组成的抗体发生特异性反应。术语“多肽”、“肽”和“蛋白质”也包括修饰,包括但不限于糖基化、脂质附着、硫酸盐化、谷氨酸残基的γ羧化、羟基化和adp-核糖基化。
在本申请的语境下,将低聚物(如寡核苷酸,寡肽)视为聚合物群组的一个种类。低聚物具有相对低的单体单位数目,一般2-100个,特别地6-100个。
如本文中所用的“表达盒”意指能够指导特定核苷酸序列在适宜宿主细胞中表达的dna序列,其包含与目的核苷酸序列可操作地连接的启动子,其中所述的目的核苷酸序列与终止信号可操作地连接。该dna序列一般还包含为正确翻译所述核苷酸序列所需的序列。编码区通常编码目的蛋白,但也可以按有义方向或反义方向编码功能性目的rna,例如反义rna或非翻译的rna。包含目的核苷酸序列的表达盒可以是嵌合的,这意指该表达盒的至少一个组分相对于该表达盒的其他组分至少之一是异源的。该表达盒也可以是天然存在的、但已经以可用于异源表达的重组形式获得的表达构建体。该表达盒中的核苷酸序列的表达可以处于组成型启动子或处于仅在宿主细胞暴露于一些特定外部刺激时才启动转录的诱导型启动子的控制下。在多细胞生物的情况下,该启动子也可以是针对特定组织或器官或发育阶段特异的。
如本文所用的术语“载体”指由经设计旨在直接转化所靶向细胞的遗传物质组成的结构。载体含有按位置和顺序取向,即与其他必需元件可操作地连接的多个遗传元件,从而,核酸盒中的核酸可以转录并且当需要时,在转化的细胞中翻译。
具体而言,载体可以选自病毒载体、(细菌)噬菌体、粘粒或质粒。载体也可以酵母人工染色体(yac)、细菌人工染色体(bac)或农杆菌双元载体。载体可以处于双链或单链线性或环状形式,所述形式可以是或可以不是自我传播或移动的,并且可以通过整合至细胞基因组而转化原核或真核宿主或者在染色体外存在(例如带有复制起点的自主复制型质粒)。具体而言,包括穿梭载体,其意指天然能够或通过设计能够在两种不同的宿主生物中复制的dna载体,可以选自放线菌和相关物种、细菌和真核(例如高等植物、哺乳动物、酵母或真菌细胞)。优选地,载体中的核酸处在用于宿主细胞(如微生物细胞例如细菌细胞或植物细胞)中转录的适宜启动子或其他调节元件控制下并可操作地与之连接。载体可以是在多种宿主中发挥作用的双功能表达载体。在基因组dna的情况下,这可以含有其自身的启动子或其他调节元件,并且在cdna的情况下,这种可以处在用于宿主细胞中表达的适宜启动子或其他调节元件控制下。
含有本发明多核酸的载体可以基于本领域本身已知的方法学制备。例如,可以利用与合适调节元件,如转录性或翻译性调节核酸序列可操作地连接的编码本发明多肽的cdna序列。
如本文所用,术语“载体”包括用于标准克隆工作的载体(“克隆载体”)以及更专用类型的载体,如(常染色体)表达载体和用于整合至宿主细胞染色体中的克隆载体(“整合载体”)。
“克隆载体”通常含有一个或少数限制性核酸内切酶识别位点,其中外来dna序列可以在所述识别位点处按可确定方式插入,而载体的基本生物学功能不丧失,以及适于鉴定和选择用克隆载体转化的细胞的标记基因。
术语“表达载体”指线型或环状dna分子,其包含编码目的多肽的区段,所述区段处在引起其转录的额外核酸区段控制下(即与之可操作地连接)。这类额外区段可以包括启动子序列和终止子序列,并且可以任选地包括一个或多个复制起点、一个或多个选择标记、增强子、多聚腺苷化信号等。表达载体通常源自质粒或病毒dna,或可以含有二者的元件。具体而言,表达载体包含一种核苷酸序列,其以5'至3'方向包含以下对象并与之可操作地连接:(a)由宿主生物识别的转录和翻译起始区域,(b)目的多肽的编码序列,和(c)由宿主生物识别的转录及翻译终止区。“质粒”指不整合至微生物的基因组中并且在自然下通常为环状的自主复制型染色体外dna。
“整合载体”指线型或环状的dna分子,所述dna分子可以并入微生物的基因组中并且提供编码目的多肽的基因的稳定遗传。整合载体通常包含一个或多个包含基因序列的区段,所述基因序列编码目的多肽的区段,所述区段处在引起其转录的额外核酸区段控制下(即与之可操作地连接)。这类额外区段可以包括启动子序列和终止子序列,和驱动目的基因(通常借助同源重组过程)并入靶细胞的基因组中的一个或多个区段。通常,整合载体将可以转移入靶细胞中但是具有在该生物中无功能的复制子的一种载体。如果在包含目的基因的区段内部包含适宜的标记,可以选择该区段的整合。
如本文中所用,术语“可操作地连接”或“有效地连接”并列指其中如此所述的组件处在允许它们以其预期方式发挥功能的关系。与另一个控制序列和/或与编码序列“可操作地连接”的控制序列以这样的方式连接,从而在与所述控制序列相容的条件下实现编码序列的转录和/或表达。通常,可操作地连接意指连接的核酸序列是连续的,并且在需要连接两个蛋白质编码区的情况下,是连续并且处于相同的可读框中。
术语“广藿香醇合成酶”在本文用于具有从法尼基二磷酸形成广藿香醇以及优选地还有广藿香醇类萜烯如榄香醇或广藿香奥醇的催化活性的多肽,并且用于包含这种多肽的其他部分。这类其他部分的例子包括所述多肽与一种或多种其他多肽的复合物、融合至肽或蛋白质标签序列的包括广藿香醇合成酶的多肽的融合蛋白、所述多肽的其他复合物(例如金属蛋白复合物)、包含所述多肽和另一个有机部分的大分子化合物,所述多肽与支撑材料结合等。可以在其天然环境中提供,即在已经产生该酶的细胞内部广藿香醇合成酶,或在该酶已经由产生它的细胞分泌的培养基中提供。它也可以与已经产生该多肽的来源无关提供并且可以通过与载体连接、用标记部分标记等进行操作。
本文所用的术语序列的“功能同源物”,或简称为“同源物”,是指包含所述特定序列的多肽,其条件是一个或多个氨基酸被取代、缺失、添加和/或插入,在术语“功能同源物”用于酶的情况下,即具有在从法尼基二磷酸形成广藿香醇中具有催化活性的seqidno:4的序列的同源物的情况下,该多肽具有(定性地)具有用于底物转化的相同的酶功能。在实施例中,描述了适合验证多肽或包含多肽的部分是否是广藿香醇合成酶的测试(“广藿香醇合成酶活性测试”)。此外,本领域技术人员认识到,本发明所涵盖的等同核苷酸序列还可以通过其在低、中和/或严格条件下与本权利要求的字面范围内的核苷酸序列杂交的能力来定义。
根据本发明的seqidno:4的优选同源物具有对广藿香醇形成催化的特异性,表示为广藿香奥醇与广藿香醇的摩尔比在1:4-1:7之间,优选在1:4.5-1:6.5之间,更优选在1:5-1.6之间,最优选为约1:5.6,榄香醇与广藿香醇之比在1:5-1:9之间,优选在1:6-1:8之间,更优选在1:6.5-1:7.5之间,最优选为约1:6.9,和/或榄香醇与广藿香奥醇之比在1:0.7-1:2.25之间,优选在1:0.9-1:1.75之间,更优选在1:1.1-1:1.5之间,最优选为约1:1.3。
序列同一性或相似性在本文中定义为两个或多个多肽序列或两个或多个核酸序列之间的关系,如通过比较这些序列所确定。通常,序列同一性或相似性在序列的整个长度范围内比较,然而,但是也可以仅对彼此对齐的序列部分比较。在本领域,“同一性”或“相似性”也意指多肽序列或核酸序列之间相关性的程度,根据具体情况,如由此类序列之间的匹配所决定。如本文所用的序列同一性是通过emboss配对比对算法“needle”所确定的值,例如其在欧洲生物信息学研究所的服务器上(www.ebi.ac.uk/tools/emboss/align/)。对于氨基酸序列的比对,默认参数是:矩阵=blosum62;开放空位罚分=10.0;空位延伸罚分=0.5。对于核酸序列的比对,默认参数是:基质=全dna;开放空位罚分=10.0;空位延伸罚分=0.5。
在现有的根据seqidno:4的广藿香醇合成酶或根据seqidno:3或seqidno:5的核酸和所述广藿香醇合成酶的功能同源物之间的不一致性可能特别是修饰的结果,其中通过本领域技术人员已知的生物技术如例如分子进化或理性设计或通过使用本领域已知的诱变技术(随机诱变、位点定向诱变、定向进化、基因重组等)进行所示修饰,例如以改善广藿香醇合成酶或多核酸的特性(例如改善的表达)。分别与seqidno:4和seqidno:3或seqidno:5的序列相比,广藿香醇合成酶的氨基酸序列或编码核酸序列可以因一个或多个天然存在的变异而改变。这类天然修饰/变异的例子是糖基化(更广泛地定义为“翻译后修饰”)差异、归因于可变剪接的差异和单核酸多态性(snp)。可以对核酸进行修饰,使得其编码与seqidno:4的多肽相差至少一个氨基酸的多肽,从而其编码与seqidno:4相比包括一种或多种氨基酸取代、缺失和/或插入的多肽,该多肽仍具有与seqidno:4基本相同的广藿香醇合成酶活性。另外,可以利用密码子优化或密码子对优化,例如基于如wo2008/000632中所述的或如商业dna合成公司dna2.0、geneart和genscript所提供的方法。密码子优化序列的一个实例是seqidno:5。
编码不与本发明多肽天然连接的适宜信号肽的一种或多种序列可以并入(表达)载体中。例如,信号肽前导序列的dna序列可以与本发明的核酸序列符合可读框地融合,从而本发明的多肽最初翻译为包含该信号肽的融合蛋白。取决于信号肽的性质,将差异性地导引表达的多肽。在预期宿主细胞中有功能的分泌信号肽例如增强所表达多肽的细胞外分泌。其他信号肽指引表达的多肽至某些细胞器,如叶绿体、线粒体和过氧化物酶体。当转运至预期细胞器或从细胞转运时,信号肽可以从多肽中切除。可以在seqidno:4的多肽或其同源物的氨基端或羧基端提供额外肽序列的融合。
如上所述,本发明还涉及包含本发明载体的宿主细胞。“宿主细胞”意指含有载体并支持该载体复制和/或表达的细胞。
本发明的核酸与本发明的宿主细胞是异源的。宿主细胞可以是原核细胞、真核细胞或来自古细菌成员的细胞。宿主细胞可以来自任何生物,特别地任何非人类生物。具体而言,宿主细胞可以选自细菌细胞、真菌细胞、古细菌、原生生物、植物细胞(包括藻类)、源自动物(尤其从所述动物分离的)的细胞。宿主细胞可以形成除人或该酶从中天然起源的生物之外的多细胞生物的部分(例如在seqidno:4的广藿香醇合成酶的情况下的匙叶甘松(nardostachysjatamansi))。在一个具体实施方案中,本发明的宿主细胞处于源自多细胞生物,然而从中分离的细胞培养物中。
通常而言,宿主细胞是包含表达酶的基因的分离的细胞,所述酶用于催化甲羟戊酸途径或另一条代谢途径(如脱氧木酮糖-5-磷酸(dxp)途径)的反应步骤,所述另一条代谢途径使得产生作为通用类异戊二烯结构单位的c5异戊烯基二磷酸盐类异戊烯基二磷酸(ipp)和二甲基烯丙基二磷酸盐(dmapp)成为可能。迄今已知,除非已经敲除特定基因,否则全部已知的生物均包含这种途径。真核生物通常天然能够经甲羟戊酸途径制备ipp。这种ipp随后因异戊烯基二磷酸异构酶(idi)的作用异构化成dmapp。dxp途径,其以5:1比率供应ipp和dmapp,是原核生物共有的,虽然几种原核生物天然能够经甲羟戊酸途径制备ipp。这些途径是本领域已知的并且已经例如由withers和keasling在appl.microbiol.biotechnol.(2007)73:980-990中描述。这些途径的基因可以各自独立地同源或异源于细胞。
宿主细胞进一步将内源性或从异源来源包含一种或多种表达具有异戊烯基转移酶活性的酶的基因,所述酶催化c5异戊烯基二磷酸盐类的头-对-尾缩合,产生较长的异戊烯基二磷酸盐类。例如,通过这些酶的作用,通用性倍半萜前体法尼基二磷酸(fpp)通过连续头-对-尾添加2分子ipp至1分子dmapp而形成。
在一个实施方案中,宿主细胞是细菌。细菌可以是革兰氏阳性或革兰氏阴性的。革兰氏阳性细菌可以选自芽孢杆菌属(bacillus)、乳杆菌属(lactobacillus)、和棒状杆菌属(corynebacteriumspp),特别地选自以下物种:枯草芽孢杆菌(bacillussubtilis)、干酪乳杆菌(lactobacilluscasei)、和谷氨酸棒状杆菌(cornynebacteriumglutamicum)。
在一个优选实施方案中,细菌是选自革兰氏阴性细菌,特别地来自红细菌属(rhodobacter)、副球菌属(paracoccus)和埃希氏菌属(escherichia)的组,更具体地来自荚膜红细菌(rhodobactercapsulatus)、类球红细菌(rhodobactersphaeroides)、产类胡萝卜素副球菌(paracoccuscarotinifaciens)、产玉米黄素副球菌(paracoccuszeaxanthinifaciens)和大肠杆菌(escherichiacoli)。类球红细菌是天然含有表达催化dxp途径中各种反应步骤的酶所需要的全部基因的生物的例子,这使得胞内产生ipp和dmapp成为可能,因此是特别优选的。
在一个优选的实施方案中,宿主细胞是真菌细胞,特别是选自选自以下属的真菌细胞:曲霉属(aspergillus)、布拉霉属(blakeslea)、青霉属(penicillium)、法夫酵母属(红法夫酵母)(phaffia(xanthophyllomyces))、毕赤酵母属(pichia)、糖酵母属(saccharomyces)和耶罗维亚酵母属(yarrowia),更特别地选自构巢曲霉(aspergillusnidulans)、黑曲霉(aspergillusniger)、米曲霉(aspergillusoryzae)、三孢布拉霉(blakesleatrispora)、产黄青霉(penicilliumchrysogenum)、红法夫酵母(phaffiarhodozyma)(红法夫酵母(xanthophyllomycesdendrorhous))、巴斯德毕赤酵母(pichiapastoris)、酿酒酵母(saccharomycescerevisiae)和解脂耶罗维亚酵母(yarrowialipolytica)。
也可能在源自高等真核生物的细胞如植物细胞和动物细胞如昆虫细胞或来自小鼠、大鼠或人的细胞中表达本发明的核酸。所述细胞可以在细胞或组织培养物中维持并用于广藿香醇合成酶的体外产生。
包含本发明宿主细胞的多细胞生物可以特别地选自多细胞植物和蘑菇(担子菌纲(basidiomycetes))。
因而,在一个具体实施方案中,本发明涉及转基因植物或包含转基因植物细胞的植物细胞或组织培养物,所述植物或培养物包含本发明的植物宿主细胞。转基因植物细胞的转基因植物或培养物可以特别地选自烟草属物种(nicotianaspp.),茄属物种(solanumspp.),菊苣(cichorumintybus),莴苣(lactucasativa),薄荷属物种(menthaspp.),黄花蒿(artemisiaannua),块茎形成植物,如菊芋(helianthustuberosus)、木薯和甜菜(betavulgaris),油料作物,如芸苔属物种(brassicaspp.)、油棕属物种(elaeisspp.)(油棕榈树)、向日葵(helianthusannuus)、大豆(glycinemax)和落花生(arachishypogaea)、水培植物如浮萍属物种(lemnaspp.)、烟草by2细胞和展叶剑叶藓(physcomitrellapatens)、树如松树和杨树,分别地,任何所述植物的细胞培养物或组织培养物。在一个具体实施方案中,组织培养物是须根培养物。
因而,在又一个具体的实施方案中,本发明涉及转基因蘑菇或包含转基因蘑菇细胞的培养物。转基因蘑菇或包含转基因宿主细胞的培养物可以特别地分别选自裂褶菌属(schizophyllum)、伞菌属(agaricus)和侧耳属(pleurotus),更特别地选自裂褶菌(schizophyllumcommune)、普通蘑菇(双孢蘑菇(agaricusbisporus))、平菇(糙皮侧耳(pleurotusostreotus)和美味侧耳(pleurotussapidus)),分别包含任何所述蘑菇的细胞的培养物。
本发明的宿主细胞可以基于本领域通常已知的标准遗传学和分子生物学技术产生,例如,如sambrook,j.和russell,d.w."molecularcloning:alaboratorymanual"第3版,coldspringharborlaboratorypress,coldspringharbor,ny,(2001);和f.m.ausubel等编著,"currentprotocolsinmolecularbiology",johnwileyandsons,inc.,newyork(1987)以及最近补充中所述。
转化担子菌的方法是例如从alves等(appl.environ.microbiol.(2004)70:6379-6384)、godio等(curr.genet.(2004)46:287-294)、schuurs等(genetics(1997)147:589-596)和wo06/096050中已知的。为实现在担子菌中表达合适的广藿香醇合成酶基因,通常地将其完整可读框克隆适于转化担子菌的表达载体中。该表达载体优选地也包含调节转录启动和终止的核酸序列。还优选并入至少一个选择标记基因以允许选择转化体。可以使用担子菌启动子,例如组成型启动子或诱导型启动子实现广藿香醇合成酶的表达。一种强组成型启动子的例子是甘油醛-3-磷酸脱氢酶(gpda)启动子。当重组dna物质在担子菌宿主中表达时,这种启动子优选用于组成型表达。其他例子是担子菌的磷酸甘油酸激酶(pgk)启动子、丙酮酸激酶(pki)启动子、tpi磷酸丙糖异构酶(tpi)启动子、apc合成酶亚基g(olic)启动、sc3启动子和乙酰胺酶(amds)启动子(wo96/41882)。
如果需要,可以将广藿香醇合成酶基因的主要核苷酸序列改变以适应于担子菌宿主的密码子使用。
另外,表达可以尤其指向(单核)菌丝体或指向(二核)子实体。在后一种情况下,侧耳属fbh1启动子是特别有用的(penas,m.m.等,mycologia(2004)96:75-82)。
本领域中描述了构建植物转化构建体的方法学。可以通过插入所选择基因的一个或多于一个额外副本实现过量表达。不知道最初用核苷酸序列的一个或多于一个额外副本所转化的植物或其子代是否显示出过量表达。
在适宜的植物组织中获得足够水平的转基因表达是产生基因修饰作物的重要方面。异源dna序列在植物宿主中的表达取决于存在可操作地连接的在植物宿主内有功能的启动子。启动子序列的选择将决定异源dna序列在生物内部何时和何处表达。虽然来自双子叶植物的许多启动子已经显示在单子叶植物中可运作并且反之亦然,但是理想地选择双子叶启动子用于双子叶植物中的表达,并选择单子叶启动子用于单子叶植物中的表达。然而,对所选择的启动子的出处不存在限制;足够的是它们有效驱动核苷酸序列在所需的细胞或组织中表达。在一些情况下,需要多种组织中的表达,并且在这种情况下看,可以使用组成型启动子如35s启动子系列。然而,在本发明的一些实施方案中,在转基因植物中的表达优选地是叶特异性的,更优选地,基因表达叶质体中发生。来自银白杨(populusalba)的异戊二烯合酶基因启动子(paisps)(sasaki等,febsletters(2005)579:2514-2518)似乎驱动质体特异性表达。因此,这种启动子是非常适合用于本发明表达载体中的启动子。
其他适合的叶特异性启动子是rbcs(核酮糖二磷酸羧化酶-加氧酶)启动子(例如来自咖啡,见wo02/092822);来自芸苔属(brassica),见us7,115,733;来自大豆,见dhanker,o.等,naturebiotechnol.(2002)20:1140-1145)、cy-fbpase启动子(见us6,229,067)、来自油棕的集光性叶绿素a/b结合蛋白的启动子序列(见us2006/0288409)、来自拟南芥(arabidopsisthaliana)的stp3启动子(见büttner,m.等,plantcell&environ.(2001)23:175-184)、菜豆pal2基因的启动子(见sablowski,r.w.等,proc.natl.acad.sci.usa(1995)92:6901-6905)、马铃薯st-ls1启动子的增强子序列(见stockhaus,j.等,proc.natl.acad.sci.usa(1985)84:7943-7947)、小麦cab1启动子(见gotor,c.等,plantj.(1993)3:509-518)、来自马铃薯的adp葡萄糖磷酸化酶基因的气孔特异性启动子(见us5,538,879)、来自稻p(d540)基因的lpse1元件(见cn2007/10051443)和来自拟南芥的气孔特异性启动子pgc1(atlg22690)(见yang,y.等,plantmethods(2008)4:6)。
可以例如通过dna介导的植物细胞原生质体转化法并且随后根据本领域熟知的方法从转化的原生质体再生出植物来转化植物物种。
转化植物细胞的方法的其他例子包括微量注射法(crossway等,mol.gen.genet.(1986)202:179-185)、电穿孔法(riggs,c.d.和bates,g.w.,proc.natl.acad.sci.usa(1986),83:5602-5606)、农杆菌介导转化法(hinchee等,bio/technol.(1988)6:915-922)、直接基因转移法(paszkowski,j.等,emboj.(1984)3:2717-2722)和使用从agracetus,inc.、madison,wisconsin和biorad,hercules,california可获得的装置的射弹粒子加速法(见,例如,sanford等,美国专利号4,945,050以及欧洲专利申请ep0332581)。
也可以采用用于玉米的原生质体转化法(欧洲专利申请ep0292435,美国专利号5,350,689)。
特别优选使用农杆菌ti和ri质粒的双元型载体。ti衍生的载体转化类型广泛的高等植物,包括单子叶和双子叶植物,如大豆、棉花、油菜、烟草和稻(pacciotti等,bio/technol.(1985)3:241;byrnem.c.等,plantcelltissueandorganculture(1987)8:3-15;sukhapinda,k.等,plantmol.biol.(1987)8:209-217;hiei,y.等,theplantj.(1994)6:271-282)。t-dna转化植物细胞的用途已经得到广泛研究并且大量描述(例如ep-a120516)。为了引入植物中,可以将本发明的嵌合基因插入如实施例中所述的双元载体中。
本领域技术人员可获得其他转化方法,如直接摄入外来dna构建体(见ep-a295959)、电穿孔技术(fromm,m.e.等,nature(1986),319:791-793)或采用核酸构建体包覆的金属粒子的高速射弹轰击法(例如us4,945,050)。一旦转化,可以通过本领域技术人员再生细胞。特别有意义的是将外来基因转化至商业重要的作物中的方法,如油菜(deblock,m.等,plantphysiol.(1989)91:694-701)、向日葵(everett,n.p.等,bio/technology(1987)5:1201-1204)、大豆(ep-a301749)、稻(hiei,y.等,theplantj.(1994)6:271-282)和玉米(fromm等,1990,bio/technology8:833-839)。
本领域技术人员将理解方法的选择可能取决于植物的类型,即单子叶植物或双子叶植物。
在另一个实施方案中,可以将如本文所述的载体直接转化至质体基因组中。质体转化技术广泛地例如在us5,451,513、us5,545,817、us5,545,818和wo95/16783中描述。用于叶绿体转化的基本技术涉及将分布于选择标记侧翼的克隆的质体dna的区域连同目的基因一起导入合适的靶组织,如使用生物弹射击法或原生质体转化(如氯化钙或peg介导的转化)。
含有本发明载体的根癌农杆菌(agrobacteriumtumefaciens)细胞可用于产生转化植物的方法中,其中载体包含ti质粒。用如上文所述的根癌农杆菌感染植物细胞以产生转化的植物细胞,并且随后从转化的植物细胞再生出植物。已知可用于实施本发明的许多农杆菌载体系统。这些载体统一般携带至少一个t-dna边界序列并且包括载体如pbinl9(bevan,nucl.acidsres.(1984)12:8711-8720)。
通常但不必然地随选择标记采取使用一种形式的直接基因转移或农杆菌介导转移的方法,其中所述选择标记可以提供针对抗生素(例如卡那霉素、潮霉素或甲氨蝶呤)或除草剂(例如膦丝菌素)的抗性。然而,选择用于植物转化的选择标记对本发明并非至关重要。
培养植物组织的一般方法例如由maki,k.y.等,plantphysiol.(1993)15:473-497,和phillips,r.i.等在spraguegf,dudleyjw编著.cornandcornimprovement.第3版.madison(1988)345-387中提供。
在转化后,将转基因植物细胞置于选择转基因细胞的适宜选择培养基中,其中随后将所述转基因细胞培育成愈伤组织。从愈伤组织培育出苗并且通过在生根培养基中生长,从苗产生小植物。所用的特定标签将允许与缺少已经引入的dna的细胞相比,选择转化的细胞。
为证实转基因在转基因细胞和植物中的存在,可以进行多种测定法。此类测定法例如包括本领域技术人员熟知的“分子生物学”测定法,如dna印迹和rna印迹法,原位杂交和基于核酸的扩增方法如pcr或rt-pcr和“生物化学”测定法,如检测蛋白质产物的存在,例如,通过免疫手段(elisa和蛋白质印迹法)或通过酶功能。可以通过化学分析植物的挥发性产物(广藿香醇)建立确立有酶活性的广藿香醇合成酶的存在。
根据本发明的广藿香醇合成酶可以用于广藿香醇的工业生产,该广藿香醇本身可以用作香料或香精,例如在食品中使用,或用作香味料(fragrance),例如用于家用产物中,或用作生产另一种类异戊二烯(例如檀香醇)的中间体。
根据本发明的生产广藿香醇的方法包括在广藿香醇合成酶存在下制备广藿香醇。原则上,这种方法可以基于在制备目的化合物中使用酶的任何技术。
该方法可以是其中向包含广藿香醇合成酶的细胞输送fpp或其任何前体(如法尼醇、ipp、异戊烯基磷酸酯、3-甲基丁-3-烯-1-醇和甚至甲羟戊酸)作为底物的方法。可选地,该方法也可以其中利用活生物的方法,所述活生物包含能够从适合的碳源形成fpp的酶系统,因此建立通向广藿香醇的完整发酵途径。应当指出术语“发酵”在本文中以广义用于其中利用生物的培养物从适合的原料(糖、氨基酸源、脂肪酸源)中合成化合物的过程。因而,如本文中所意指的发酵过程不限于无氧条件,并且扩展至需氧条件下的过程。合适的原料通常是对于具体(微)生物物种已知的。
另外,可以利用从已经产生广藿香醇合成酶的细胞分离的广藿香醇合成酶,例如在其中使底物(fpp)和广藿香醇合成酶在合适条件下(ph、溶剂、温度)接触的反应体系中利用,所述条件可以基于在此和本公开提到的现有技术,任选地与一些例行检验组合。广藿香醇合成酶可以例如溶解于其中也存在fpp的含水介质中,或广藿香醇合成酶可以按本领域已知的方式固定在支撑材料上并且随后与包含fpp的液体接触。由于该酶具有催化fpp至广藿香醇的高度活性和/或选择性,所以本发明也有利于这种体外方法,不仅在酸性条件下,还在ph为约中性或碱性的情况下。适合的条件可以基于用于已知广藿香醇合成酶的已知(例如在文献中提到、在本文中提到的)方法学、本文中公开的信息、公知常识和任选地一些常规实验。
在本发明的一个特别有利的方法中,广藿香醇以发酵方式(即,通过在培养基中培育表达广藿香醇合成酶的细胞)制备。由广藿香醇合成酶催化的实际反应可以在胞内发生或-如果合成酶排出至培养基中-可以在培养基中胞外发生。
在制备本发明的广藿香醇的方法中使用的细胞可以特别地是本发明的宿主细胞。如果需要,可以将这些宿主细胞工程化以便将fpp以增加的量供应给广藿香醇合成酶。这可以例如通过增强通向fpp的碳通量实现,后者本身可以按不同方式实现。在具有内源dxp途径的宿主细胞(如大肠杆菌和类球红细菌),这些途径酶的表达的脱调节可以对类异戊二烯形成具有清晰的积极影响。过量表达编码1-脱氧-d-木酮糖-5-磷酸合酶(dxp合酶)(dxp途径的第一酶)的dxs和因此代谢工程的主要靶之一已经导致几种类异戊二烯的生物合成增加(例如,matthews和wurtzel,appl.microbiol.biotechnol.(2000)53:396-400;huang等,bioorg.med.chem.(2001)9:2237-2242;harker和bramley,febslett(1999)448:115-119;jones等,metab.eng.(2000)2:328-338;和yuan等,metab.eng.(2006)8:79-90)。另外,编码dxp异构还原酶(也称作1-脱氧-d-木酮糖-5-磷酸还原异构酶)(催化dxp途径中第二和关键步骤的酶)的dxr的过量表达可以导致增加的类异戊二烯产生(albrecht等,biotechnol.lett.(1999)21:791-795),这种作用可以通过同时共过量表达dxs而进一步增加(kim和keasling,biotechnolbioeng(2001)72:408-415)。通过过量表达异戊烯基二磷酸异构酶(ipp异构酶,idi)(催化ipp与二甲基烯丙基二磷酸酯dmapp互变的酶)(例如,kajiwara等,biochem.j.(1997)324:421-426);misawa和shimada,j.biotech.(1998)59:169-181;以及yuan等,metab.eng.(2006)8:79-90)和在大肠杆菌中作为一个操纵子ispdf转录的mep胞苷酰基转移酶(也称作4-二磷酸胞苷酰-2-c-甲基-d-赤藓糖醇合酶,ispd)和2c-甲基-d-赤藓糖醇2,4-环二磷酸酯合酶(ispf)(yuan等,metab.eng.(2006)8:79-90),进一步获得对类异戊二烯生物合成的积极影响。
一种用内源dxp途径使菌株工程化以高水平产生类异戊二烯的替代性和更有效方法是引入异源甲羟戊酸途径。当重组大肠杆菌菌株在lb+丙三醇培养基中培育时,大肠杆菌中共表达酿酒酵母甲羟戊酸途径连同合成性紫穗槐-4,11-二烯合酶基因导致滴度超过110mg/l的倍半萜紫穗槐二烯形成(martin等,nat.biotechnol.(2003)21:796-802)。随后通过引入额外拷贝的编码酵母酶3-羟基-3-甲基-戊二酰-辅酶a(hmg-coa)还原酶c端催化性结构域的基因thmg1改进这种大肠杆菌菌株。通过增加这种酶的形成并因此增加其活性,毒性甲羟戊酸途径中间体hmg-coa的胞内水平降低,因而克服生长抑制并且导致甲羟戊酸的产生增加(pitera等,metab.eng.(2007)9:193–207)。通过异源甲羟戊酸途径的前三个基因的密码子优化进一步改善经过该途径的通量,其中所述密码子优化与野生型lac启动子替换为两倍更强的lacuv5启动子组合(anthony等,met.eng.(2009)11:13-19)。甚至可以通过将酵母hmg-coa合酶和hmg-coa还原酶基因替换为来自革兰氏阳性细菌金黄色葡萄球菌(staphylococcusaureus)的等同基因更多地增加紫穗槐二烯的产生。与优化的发酵方案组合,这种工程化的新大肠杆菌菌株的培育产生27.4g/l的紫穗槐二烯滴度(tsuruta等,plosone(2009)4(2):e4489.doi:10.1371/journal.pone.0004489)。类似地,采用与根癌农杆菌癸异戊烯基二磷酸合酶(ddsa)基因组合的肺炎链球菌(streptococcuspneumoniae)甲羟戊酸途径工程化的大肠杆菌菌株产生多于2400μg/g细胞干重的辅酶q10(coq10)(zahiri等,met.eng.(2006)8:406-416)。通过用天然形式(wo2005/005650)或突变形式(wo2006/018211)的来自产玉米黄素副球菌的甲羟戊酸途径工程化类球红细菌菌株,也获得增加的coq10产量。
另外,具有内源mev途径的宿主细胞(如酿酒酵母)已经成为多种工程化研究的主题以获得类异戊二烯高产菌株。向酿酒酵母中引入与编码柑橘广藿香醇合成酶的基因组合的大肠杆菌源异源dxp途径产生了与仅表达广藿香醇合成酶的菌株相比,积累大约10倍更多广藿香醇的菌株(wo2007/093962)。然而,在工业上重要的酵母产朊假丝酵母(candidautilis)和酿酒酵母中的最大改善是同源mev途径工程化的核心。尤其,过量表达全长或截短形式的据信作为dxp途径种主要调节酶的hmg-coa还原酶似乎是增加类异戊二烯产生的高效方法。过量表达n端截短的hmg-coa还原酶的这种刺激作用例如已经在产朊假丝酵母中产生番茄红素时(shimada等,appl.env.microbiol.(1998)64:2676-2680)和在酿酒酵母中产生表-雪松醇时(jackson等,org.lett.(2003)5:1629-1632)观察到。在后一种情况下,可以通过引入upc2-1(刺激指向固醇生物合成的代谢通量增加的等位基因)进一步增强这种倍半萜的产生。增加经mev途径的通量的另一种方法是利用对fpp和其他类异戊二烯前体的反馈抑制较不敏感的甲羟戊酸激酶变体。例如,wo2006/063752显示产玉米黄素副球菌r114(具有内源mev途径的细菌)在引入酿酒酵母甲羟戊酸激酶突变体n66k/i152m和来自产玉米黄素副球菌atcc21588的ddsa基因后产生比表达野生型酿酒酵母甲羟戊酸激酶的相应产玉米黄素副球菌菌株显著更多的辅酶q10。也已经用产玉米黄素副球菌甲羟戊酸激酶的反馈抗性变体k93e获得对采用产玉米黄素副球菌r114产生辅酶q10的相似积极影响(wo2004/111214)。
增加fpp量的第二种方法基于减少或消除对fpp的酶促副活性。在酵母中,基因erg9编码法尼基二磷酸法尼基转移酶(鲨烯合酶),其催化两个法尼基二磷酸部分缩合以形成鲨烯。因为这是醇生物合成中fpp之后的第一步骤并因而调节异戊二烯单位进入固醇途径的通量,所以erg9是酵母代谢工程中用于增加倍半萜和类胡萝卜素产生的常见的靶。在酵母产朊假丝酵母中破坏erg9联合thmg-coa还原酶的过量表达增加番茄红素的产生(shimada等,appl.env.microbiol.(1998)64:2676-2680)。与仅表达紫穗槐二烯合酶基因的酵母菌株相比,过量表达thmg-coa还原酶和使用甲硫氨酸可阻遏启动子下调erg9的相似组合增加了酵母中倍半萜紫穗槐二烯的产生约10倍(ro等,nature(2006)440:940-943;lenihan等,biotechnol.prog.(2008)24:1026-1032)。由于麦角甾醇对酵母生长不可或缺并且酵母细胞不能在有氧生长期间同化外部输入的麦角甾醇,因此erg9的下调/敲除经常与使酵母菌株能够从培养基有效有氧摄入麦角甾醇的突变组合。例子是sue等位基因(takahishi等,biotechnol.bioeng.(2007)97:170-181)和upc2-1等位基因(jackson等,org.lett.(2003)5:1629-1632)。takahashi等(biotechnol.bioeng.(2007)97:170-181)也研究通过敲除酵母中的磷酸酶基因dpp1限制内源磷酸酶活性的影响。虽然这种敲除明显限制fpp的去磷酸化,由法尼醇积累少得多反映,但是它未改善倍半萜产生,除非在所用生长条件下联合erg9/sue突变之外。
可以根据所用宿主细胞物种(例如荚膜红细菌、类球红细菌、产玉米黄素副球菌、大肠杆菌、构巢曲霉、黑曲霉、米曲霉、酿酒酵母、产黄青霉、红法夫酵母和巴斯德毕赤酵母的已知条件、本文中公开的信息、公知常识和任选地一些例行实验,选择以发酵方式制备广藿香醇的反应条件。
原则上,可以选择本发明方法中所用的反应培养基(培养基)的ph处于宽限制范围内,只要广藿香醇合成酶(在宿主细胞中)有活性并且在该ph条件下显示想要的特异性。在该方法包括使用细胞表达广藿香醇合成酶的情况下,如此选择ph,从而细胞能够执行其预期功能或多项功能。可以特别地选择ph处于中性ph以下4个ph单位和中性ph以上两个ph单位的范围内,即在25℃在基本上水质的系统中在ph3和ph9之间。良好结果例如已经在具有6.8至7.5范围内的ph的含水反应培养基中实现。
如果水是唯一溶剂或优势溶剂(基于总液体>50wt.%、特别地>90wt.%),则认为该系统是水质的,其中例如少量醇或另一种溶剂可以以这样的浓度(基于总液体<50wt.%、特别地<10wt.%)(例如在完整发酵方法的情况下,作为碳源)溶解,从而存在的微生物仍有活性。
具体而言,在使用酵母和/或真菌的情况下,可以优选酸性条件,特别地,基于在25℃基本上水质的系统,ph可以处于ph3至ph8的范围内。如果需要,ph可以使用酸和/或碱调节或用酸和碱的合适组合缓冲。
无氧条件在本文中定义为没有任何氧或其中培养的细胞(特别地微生物)基本上不消耗氧的条件,并且通常对应于小于5mmol/l.h的氧消耗,优选地对应于小于2.5mmol/l.h或更优选地小于1mmol/l.h的氧消耗。有氧条件是这样的条件,其中不限制生长的足够氧水平溶解于培养基中,能够支持至少10mmol/l.h、更优选地多于20mmol/l.h、甚至更优选地多于50mmol/l.h并且最优选地多于100mmol/l.h的氧消耗速率。
限氧条件定义为其中氧消耗受氧从气体转移至液体限制的条件。限氧条件的下限由无氧条件的上限决定,即通常是至少1mmol/l.h,并且特别地是至少2.5mmol/l.h,或至少是5mmol/l.h。限氧条件的上限由有氧条件的下限决定,即即小于100mmol/l.h,小于50mmol/l.h,小于20mmol/l.h,或小于至10mmol/l.h。
条件是否为有氧、无氧或限氧取决于实施方法的条件,特别地取决于进入气流的量和组成、所用设备的实际混合/传质特性、所用微生物的类型和微生物密度。
原则上,所用的温度不是关键的,只要广藿香醇合成酶(在细胞中)显示大部分活性。通常,温度可以是至少0℃,特别地是至少15℃,更特别地是至少20℃。在其中利用细胞表达广藿香醇合成酶的方法的情况下,所需的最高温度取决于广藿香醇合成酶和细胞。温度是70℃或更低,优选地是50℃或更低,更优选地是40℃或更低,特别地是35℃或更低。
在发酵过程的情况下,可以选择温育条件处于宽限值内部,只要细胞显示出足够的活性和/或生长。这包括有氧、限氧和无氧条件。
具体而言,如果在宿主细胞外部实施借以形成广藿香醇的催化反应,则包含有机溶剂的反应培养基可以在高浓度使用(例如基于总液体,高于50%或高于90wt.%),此时,所用的广藿香醇合成酶在这种培养基中保留足够的活性和特异性。
如果需要,根据本发明方法中所产生的广藿香醇、广藿香奥醇、和榄香醇从已经产生它的反应培养基回收。适合方法是采用与反应培养基不可溶混的提取液的液体-液体提取法。
具体而言,适合用液态有机溶剂,如液态烃提取(从含水反应培养基提取)。来自初步结果中,显而易见这种方法也适合从包含用于产生广藿香醇和榄香醇、以及优选地还有广藿香奥醇的本发明的细胞的反应培养基中提取广藿香醇和榄香醇、以及优选地还有广藿香奥醇,而不需要裂解细胞来回收广藿香醇(或其他产物)。特别地,有机溶剂可以选自液态链烷、液态长链醇(具有至少12个碳原子的醇)和长链脂肪酸的液态酯(具有至少12个碳原子的酸)。合适的液态链烷特别地包括c6-c16链烷,如己烷、辛烷、癸烷、十二烷、异十二烷和十六烷。合适的长链脂族醇特别地包括c12-c18脂族醇,如油醇和棕榈醇。长链脂肪酸的合适酯特别地包括c12-c18脂肪酸的c1-c4醇酯,如肉豆蔻酸异丙酯和油酸乙酯。
在一个有利的实施方案中,广藿香醇和榄香醇、以及优选地还有广藿香奥醇在反应器中产生,所述反应器包含第一液相(反应相),所述第一液相含有本发明的细胞,在所述细胞中产生广藿香醇(或其他产物),和第二液相(当接触时与第一相保持基本上相分离的有机相),所述第二液相是形成的产物对其具有更高亲和力的提取相。这种方法是有利的,在于它允许原位回收产物。另外,它有助于防止或至少减少广藿香醇和榄香醇、以及优选地还有广藿香奥醇对细胞的潜在毒性效应,原因是由于存在第二相,反应相中的广藿香醇和榄香醇、以及优选地还有广藿香奥醇的浓度可以在整个过程期间保持相对低。最后,存在提取相有助于从反应相中提取出广藿香醇、广藿香奥醇、以及榄香醇的强烈迹象。
在本发明的优选方法中,提取相在反应相的顶部形成一层或与反应相混合以形成反应相在提取相中的分散体或提取相在反应相中的分散体。因此,提取相不仅从反应相提取产物,还有助于减少或完全避免形成的产物从反应器经排气损失,其中如果广藿香醇在(水质)反应相中产生或分泌入(水质)反应相中,则所述损失可能发生。广藿香醇在水中溶解不良并且因此容易从水中挥发出来。构思了至少基本上防止在有机相中溶剂化的广藿香醇(作为层或分散体)挥发。
用作提取相的合适液体兼有比反应相更低的密度连同良好生物相容性(不干扰活细胞的生存力)、低挥发性及与水质反应相的几乎绝对不互溶性。适合这种应用的液体的例子是液态链烷,如癸烷、十二烷、异十二烷、十四烷和十六烷或长链脂族醇如油醇和棕榈醇、或长链脂肪酸的酯如肉豆蔻酸异丙酯和油酸乙酯(见例如asadollahi等,(biotechnol.bioeng.(2008)99:666-677),newman等,(biotechnol.bioeng.(2006)95:684-691)以及wo2009/042070)。
根据本发明生产的广香酚可以作为例如香料或香精或驱虫剂使用,或可用作另一种化合物、特别是另一种香料或香精的原料。
此外,本公开内容涉及一种制备广藿香醇、广藿香奥醇和榄香醇的方法,该方法包括在酶存在下将聚异戊二烯基二磷酸底物转化为广藿香醇、广藿香奥醇和榄香醇,所述酶包含第一片段和第二片段,所述第一片段包含标签肽,所述第二片段包含根据本发明的广藿香醇合成酶。包含所述第一和所述第二片段的酶在本文中可以被称为“标签酶”。
对于广藿香醇、广藿香奥醇和榄香醇的制备,特别可以使用本文所述的方法、氨基酸序列、核酸序列或宿主细胞。例如,檀香醇可以通过本身已知的方式由广藿香醇的氧合/氧化来制备。
标签肽优选选自由氮利用蛋白(nusa)、硫氧还蛋白(trx)、麦芽糖结合蛋白(mbp)、谷胱甘肽s-转移酶(gst)、小泛素样修饰剂(sumo)或钙结合蛋白(fh8)所组成的组及其功能同源物。如本文所用,标签肽的功能同源物是与非标签酶相比对标签酶的溶解度具有至少大致相同的作用的标签肽。通常,同源物的不同之处在于已从其为同源物的肽中插入、取代、缺失或延伸一个或多个氨基酸。同源物可以特别地包含一个或多个亲水性氨基酸被另一个亲水性氨基酸取代或疏水性氨基酸被另一个疏水性氨基酸取代。所述同源物可以特别地与nusa、trx、mbp、gst、sumo或fh8的序列具有至少50%、优选至少55%、更优选至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少98%或至少99%的序列同一性。
特别合适的是来自大肠杆菌的麦芽糖结合蛋白或其功能同源物。
根据本发明的带标签的酶的使用是特别有利的,因为它可以有助于增加类萜或萜烯例如广藿香醇、广藿香奥醇和榄香醇的产量,特别是增加细胞的产量。
为了提高带标签的酶的溶解度(与没有标签的酶相比),酶的第一片段优选在其c末端结合至第二片段的n末端。备选地,带标签的酶的第一片段在其n末端结合至第二片段的c末端。
此外,本公开内容涉及包含编码多肽的核苷酸序列的核酸,该多肽包含第一片段和第二片段,所述第一片段包含标签肽,所述标签肽优选为mbp、nusa、trx、gst、sumo或fh8标签或这些中的任何一个的功能同源物,所述第二片段包含广藿香醇合成酶。第二片段可以例如包含如seqidno:3所示的氨基酸序列或其功能类似物。
此外,本公开涉及包含编码所述带标签的广藿香醇合成酶的所述核酸的宿主细胞。根据本发明的编码带标签的酶的特定核酸显示在seqidno:10、seqidno:14、seqidno:18、seqidno:22、seqidno:26、和seqidno:30。宿主细胞可以特别地包括含有这些序列中的任一个或其功能类似物的基因。
此外,本公开涉及一种酶,其包含第一片段和第二片段,所述第一片段包含标签肽,所述第二片段包含具有将多聚戊二烯酸二磷酸酯转化为萜烯的酶活性的多肽、特别是广藿香醇合成酶,所述标签肽优选从mbp、nusa、trx或set中选择。包含根据本发明的带标签的酶的特定酶在seqidno:11、seqidno:15、seqidno:19、seqidno:23、seqidno:27、和seqidno:31中显示。
现在将通过以下实施例说明本发明。
附图说明
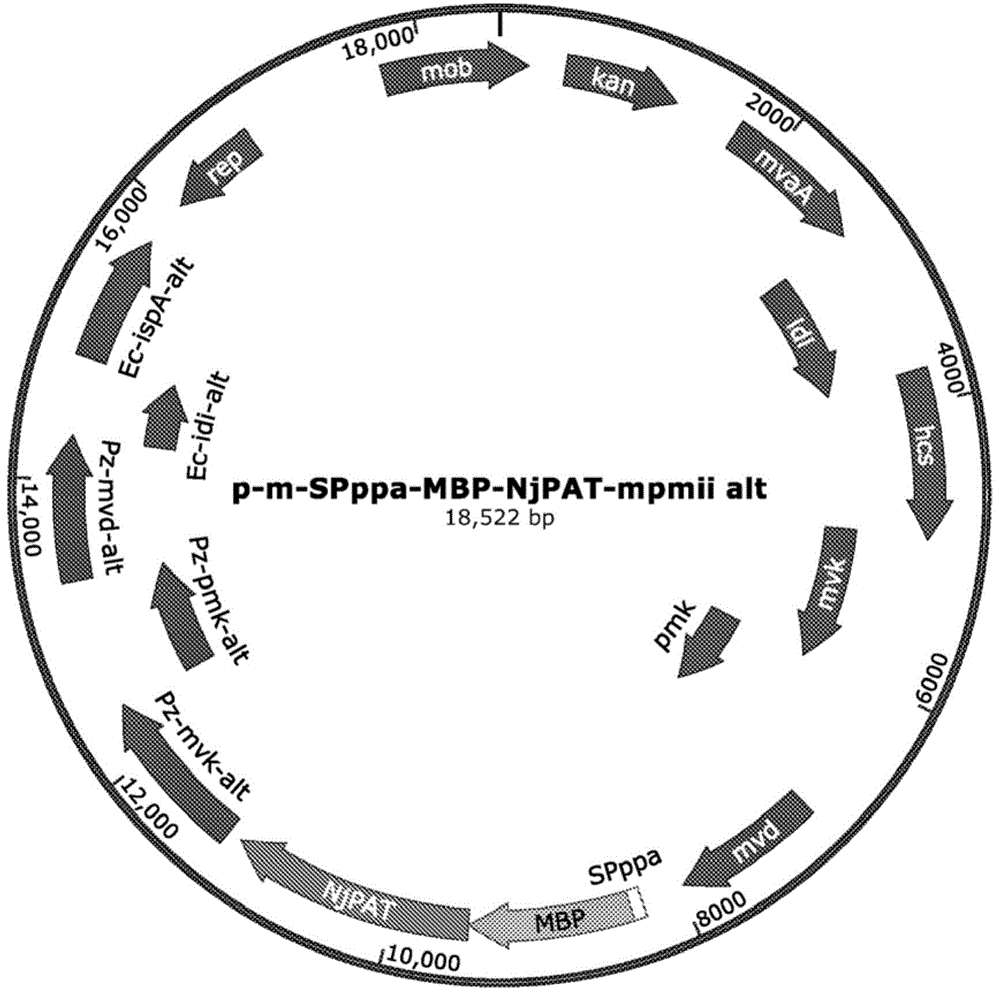
图1:显示质粒p-m-spppa-mbp-njpat-mpmiialt的特征的遗传图谱,其中njpat基因与mbp标签融合并受启动子spppa调控。
图2:显示质粒p-m-spppa-fh8-njpat-mpmiialt的特征的遗传图谱,其中njpat基因与fh8标签融合并受启动子spppa调控。
图3:显示质粒p-m-spppa-sumo-njpat-mpmiialt的特征的遗传图谱,其中njpat基因与sumo标签融合并受启动子spppa调控。
图4:显示质粒p-m-spppa-nusa-njpat-mpmiialt的特征的遗传图谱,其中njpat基因与nusa标签融合并受启动子spppa调节。
图5:显示质粒p-m-spppa-rstrx-njpat-mpmiialt的特征的遗传图谱,其中njpat基因与rstrx标签融合并受启动子spppa调控。
图6:显示质粒p-m-spppa-gst-njpat-mpmiialt的特征的遗传图谱,其中njpat基因与gst标签融合并受启动子spppa调控。
图7:njpat萜烯醇提取物的gc-fid色谱图。a:榄香醇;b:广藿香奥醇;c:广藿香醇。
图8:njpat提取物的gc-qtof色谱图。a:愈创木-11-二烯;b:β-广藿香烯;c:双环大牛儿烯;d:西车烯;e:α-广藿香烯;f:δ-广藿香烯;g:δ-愈创木烯;h:γ-广藿香烯;i:榄香醇;j:广藿香奥醇;k:乙酸异长叶酯;l:绿花白千层醇/喇机茶醇;m:广藿香醇。
具体实施方式
实施例:
实施例1:
匙叶甘松(nardostachysjatamansi)的gc-ms分析
约20厘米高的匙叶甘松植物购自苏格兰ross&cromarty的dingwalliv78lx(位于blackisle的poyntzfieldherbnursery)。将植物切成叶材料和根材料。在预冷的玻璃管中称取0.5g的植物材料,并加入2ml的二氯甲烷。将悬浮液涡旋1分钟,在超声浴中超声5分钟,并在室温下以1500g离心5分钟。收集上清液,并在1g硫酸钠柱上过滤。如cankar等(2015)描述的细节,通过gc/ms使用气相色谱对约2微升进行分析。通过与广藿香油5(sigma-aldrich)的保留时间和质谱进行比较,鉴定了广藿香醇。
结果:
匙叶甘松的根显示出含有与广藿香醇(保留时间16.4分钟)及α广藿香烯(保留时间13.9分钟)相对应的化合物。因此,该组织被进一步用于提取rna。
实施例2:
rna提取和分析
如下分离匙叶甘松根材料的rna:约15ml20提取缓冲液(2%十六烷基三甲基溴化铵、2%聚乙烯吡咯烷酮k30、100mmtris-hcl(ph8.0)、25mmedta、2.0mnacl、0.5g/l亚精胺和2%β-巯基乙醇)加热至65℃,然后加入3g地面组织并混合。混合物用等体积的氯仿:异戊醇(1:24)萃取两次,然后将四分之一体积的10mlicl加入到上清液中并混合。rna在4℃下沉淀过夜,并通过在10000g下离心20分钟收获。将沉淀溶解于500微升sste[1.0mnacl,0.5%sds,10mmtris-hcl(ph8.0),1mmedta(ph8.0)]中,并用等体积的氯仿:异戊醇萃取一次。将两体积的乙醇添加到上清液中,在-20℃下孵育至少2h,以13000g离心并除去上清液。将沉淀风干并重悬于水中。将总rna(60vg)送至vertisbiotechnologyag(freising,德国)。分离polya+rna,使用随机n6衔接子引物和m-mlvh-逆转录酶合成随机引发的cdna。剪切并分级分离cdna,将5个片段和500bp大小的片段用于进一步分析。cdna带有连接到其的5’和3’末端的如illumina所指定的接头序列a和b。
随后在illuminamiseq测序设备上分析该材料。miseq总共读取了28,331,910个序列,总序列长度为11,064,059,151个碱基对。trimmomatic-0.32用于修饰illumina测序接头的序列,seqprep用于重叠配对的末端序列,bowtie2(2.2.1版)用于去除phix污染(phixdna作为掺入对照,通常以<1%存在)。在trinity程序集(trinityrnaseq-2.0.2)中使用配对的末端读数和单读数。trinity总共组装了160871个重叠群。为了鉴定倍半萜烯合成酶,使用了匙叶甘松重叠群来创建cdna序列数据库。在该数据库中,部署了tblastn程序来鉴定编码与倍半萜烯合成酶的蛋白质序列具有同一性的蛋白质的cdna序列,所述倍半萜烯合成酶包括来自广藿香的广藿香醇合成酶、来自缬草的广藿香醇合成酶。在匙叶甘松cdna数据库中总共鉴定出77个重叠群,它们与倍半萜合成酶具有显著同源性。通过使用blastx程序对其进行分析以使其与uniprot数据库中存在的蛋白质序列(2015年8月28日下载)进行比对,进一步鉴定了这77个重叠群,根据它们与uniprot中存在的萜烯合成酶序列的同源性,其中24个被鉴定为假定的倍半萜合成酶序列,另外11个被鉴定为公认的单萜合成酶。基于blastx分析提供的比对,筛选重叠群以寻找编码全长萜烯合成酶蛋白的开放阅读框。鉴定了两个编码全长倍半萜烯合成酶的rna序列,其中之一是重叠群27692。
实施例3:匙叶甘松的广藿香醇合成酶(njpat)的克隆
从匙叶甘松的cdna中扩增出全长开放阅读框。设计表1所示的正向和反向引物,并以如下方式扩增总的开放阅读框:将阅读框与质粒pcdf-duet-1(novagen公司)中his-6标签的c末端融合。总共克隆了5种不同的萜烯合成酶orf。使用引物27692-fw(seqidno:1)和27692-re(seqidno:2),克隆了两个不同的密切相关的cdna。相对于由上述重叠群27692编码的蛋白质,这些蛋白质之一(pts11-1)编码的蛋白质缺乏70个氨基酸。另一个克隆(pts11-2)包括编码蛋白seqidno:4的cdna序列(seqidno:3)。
通过对ts插入片段进行测序来分析克隆的变体。通过热激转化将不同的变体引入具有化学活性的大肠杆菌bl21-ril(stratagene)中,并在含有1%葡萄糖、50ug/ml大观霉素和50ug/ml氯霉素的lb琼脂上进行选择。将转化子转移到含有1%葡萄糖50ug/ml大观霉素和50ug/ml氯霉素的5mllb液体培养基中,并在37℃和250rpm下生长过夜。
将200毫升的这些微升培养物转移到100ml锥形瓶中的20ml具有适当抗生素的5lb培养基中,并在37℃、250rpm下孵育直至a600为0.4至0.6。随后,加入1mmiptg,将培养物在18℃和250rpm下孵育过夜。第二天,通过离心(10min,8000xg)收集细胞,除去培养基,并将细胞重悬于1ml重悬缓冲液(50mmtris-hct,ph=7.5,1.4mmβ-巯基乙醇;4℃)中。通过在fastprep机器中以6.5的速度用0.2g锆砂摇动2次10秒钟来破坏细胞。随后通过离心(10min,13,000xg,4℃)除去不溶性颗粒。可溶性蛋白立即用于酶分析。
实施例4:体外酶测定
为了进行酶分析,在玻璃管中由800μlmopso缓冲液(15mmmopso(3-[n-吗啉代]-2-羟基丙烷磺酸)ph=7.0、12.5%甘油、1mmmgcl2、0.1吐温20%、1mm抗坏血酸、1mm二硫苏糖醇)、100微升纯化酶溶液和5μl法尼基二磷酸酯或香叶基二磷酸酯(10mm,sigmafpp干燥蒸发并溶于50%乙醇)和20μlna-原钒酸盐250mm。将该混合物在30℃温和搅拌下孵育2小时。随后,将水相用2ml乙酸乙酯萃取。收集乙酸乙酯相,以1200xg离心,在硫酸钠柱上干燥并通过gc-ms分析。
gc-ms分析在agilenttechnologies系统上进行,该系统包括7980agc系统、597c惰性msd检测器(70ev)、7683自动进样器和注射器以及30m长x0.25mm内径和0.25μm固定相的phenomenexzebronzb-5ms色谱柱,其带有guardian预柱(5m)。在该系统中,进样了1微升样品。进样室温度为250℃,进样不分流,zb5色谱柱在45℃保持2分钟,然后开始以每分钟10℃的梯度升至300℃。在总离子计数的色谱图中检测到峰。通过化合物的保留指数、质谱以及质谱与文库(nist8和内部)的比较来识别化合物。
在该体外测定中,发现克隆ts11-2产生了广藿香醇,因此编码广藿香醇合成酶,被称为njpat。密切相关的克隆ts11-1在体外测定中不产生任何倍半萜。
实施例5:克隆njpat以在具有溶解性标签的类球红细菌中表达。
为了在启动子spppa的调控下与不同的溶解性标签结合表达njpat基因,构建体spppa-mbp、spppa-fh8、spppa-sumo、spppa-nusa、spppa-rstrx和spppa-gst和njpat基因由genscriptusainc.(美国新泽西州piscataway)合成。对njpat基因(seqidno:5)和所有编码溶解性标签的序列均进行密码子优化以用于球形球菌中的表达。
质粒p-m-spppa-mbp-njpat-mpmiialt(图1)是根据标准
质粒p-m-spppa-fh8-njpat-mpmiialt(图2)的获得方法与质粒p-m-spppa-mbp-njpat-mpmiialt相似:使用引物pppa-fw(seqidno:6)-和fh8_njpat_rv(seqidno:12)扩增构建体spppa-fh8,并且用引物fh8_njpat_fw(seqidno:13)njpat_rv(seqidno:9)扩增njpat基因。进一步的克隆过程与质粒spppa-mbp-njpat-mpmiialt相同。构建体spppa-fh8-njpat的核苷酸序列在seqidno:14中给出;该蛋白质序列表示为seqidno:15。
对于其他构建体,遵循相同的克隆程序。
使用引物pppa-fw(seqidno:6)-和sumo_njpat_rv(seqidno:16)扩增构建体spppa-sumo,并用引物sumo_njpat_fw(seqidno:17)njpat_rv(seqidno:9)扩增njpat基因。seqidno:18给出了构建体spppa-sumo-njpat的核苷酸序列;该蛋白质序列表示为seqidno:19。最终质粒p-m-spppa-sumo-njpat-mpmiialt的图谱如图3所示。
使用引物pppa-fw(seqidno:6)-和nusa_njpat_rv(seqidno:20)扩增构建体spppa-nusa,并用引物nusa_njpat_fw(seqidno:21)njpat_rv(seqidno:9)扩增njpat基因。seqidno:22给出了构建体物spppa-nusa-njpat的核苷酸序列;该蛋白质序列表示为seqidno:23。最终质粒p-m-spppa-nusa-njpat-mpmiialt的图谱如图4所示。
使用引物pppa-fw(seqidno:6)-和rstrx_njpat_rv(seqidno:24)扩增构建体spppa-rstrx,并用引物rstrx_njpat_fw(seqidno:25)njpat_rv(seqidno:9)扩增njpat基因。seqidno:26给出了构建体spppa-rstrx-njpat的核苷酸序列。该蛋白质序列表示为seqidno:27。最终质粒p-m-spppa-rstrx-njpat-mpmiialt的图谱如图5所示。
使用引物pppa-fw(seqidno:6)-和gst_njpat_rv(seqidno:28)扩增构建体spppa-gst,并用引物gst_njpat_fw(seqidno:29)njpat_rv(seqidno:9)扩增njpat基因。seqidno:30给出了构建体spppa-gst-njpat的核苷酸序列。该蛋白质序列表示为seqidno:31。最终质粒p-m-spppa-gst-njpat-mpmiialt的图谱如图6所示。
使用标准方法(专利us9260709b2)通过缀合将质粒从s17-1转移至类球红细菌rs265-9c。
实施例6:生长条件摇瓶实验。
种子培养是在不带挡板的100ml摇瓶中进行的,其中装有20ml具有100mg/l新霉素和一定量甘油储备液的rs102培养基(专利us9260709b2)。将烧瓶在摇动培养箱中在30℃下培养72小时,该培养箱的轨道为50mm,转速为110rpm。
在72小时结束时,评估培养物的od600,以便计算出要转移到较大烧瓶中的培养物的确切体积。
摇瓶实验在带有2个底部挡板的300ml摇瓶中进行。将20ml的rs102培养基和新霉素(终浓度为100mg/l)与2ml的无菌正十二烷一起添加到烧瓶中。调节接种物的体积以在20ml培养基中获得最终的od600值为0.05。
将烧瓶在振动培养箱中于30℃保持72小时,该培养箱的轨道为50mm,转速为110rpm。
实施例7:用于分析有机相中类异戊二烯含量的样品制备。
接种72小时后,在预先称重的50mlpp管中收集培养物,然后将其以4500xg离心20分钟。将正十二烷层转移到微量离心管中,供以后进行gc分析。
在10ml玻璃小瓶中称量10微升的月桂酸乙酯,向其中添加800μl分离的十二烷溶液并称重。随后,将8ml丙酮添加到该样品瓶中,以稀释十二烷的浓度,以进行更准确的gc分析。将大约1.5ml含萜烯的十二烷在丙酮中的溶液转移到色谱瓶中。
实施例8:气相色谱火焰电离检测器(gc-fid)
气相色谱法在配备有restekrtx-5silms毛细管柱的shimadzugc2010plus上进行(30mx0.25mm,0.5μm)。进样器温度和fid检测器温度分别设置为280℃和300℃。通过柱的气流设置为40ml/min。烘箱的初始温度为160℃,以2℃/分钟的速率升高至180℃,进一步以50℃/分钟的速率升高至300℃,并在该温度下保持3分钟。进样量为1μl,分流比为1:50,氮气补充流量为30ml/分钟。
实施例9:njpat生产的萜烯的气相色谱定量飞行时间(gc-qtof)分析
来自类球红细菌培养物的十二烷提取物的储备溶液在己烷中制备为1mg/ml,然后在甲醇中稀释至20μg/ml。
将2μl的稀释液转移至tenax管中,并以200ml/分钟的氦气流干清洗2h,以去除溶剂。使用markes热脱附器(unitytd100)在240℃下5分钟将tenax管脱附到具有多床填料(0℃)的冷阱中。通过以40ml/s的速度加热到260℃,分流为9ml/分钟,柱流为1.2ml/分钟的氦气,注入捕获的材料。在agilent7890bgc中,在db5ms色谱柱(agilent,30m,0.25mm内径,1μmdf)上分析注入的材料。
温度程序如下:在40℃下2分钟,然后以10℃/分钟的速度升至280℃。使用质量范围为50-350amu的agilent7200qtofms检测化合物。
为了进行数据分析,使用了masshunter(agilent,版本b.07.00)。去卷积光谱与nist库(nist版本2.22014)进行比较。
实施例10:由类球红细菌菌株生产萜烯的分析
带有质粒p-m-spppa-mbp-njpat-mpmiialt的红杆菌菌株显示出最高的萜烯种类产量,其中广藿香醇、广藿香奥醇和出人意料的榄香醇(图7)。广藿香醇和榄香醇之间的比例为6.9:1,广藿香醇和广藿香奥醇之间的比例为5.6:1,最后广藿香奥醇与榄香醇之间的比例为1.3:1。fh8标签与njpat的融合使该酶完全失活,该酶只能产生法尼醇(fpp的去磷酸化产物)。用具有溶解性标签sumo的表达njpat的菌株获得的滴度是用mbp菌株获得的滴度的74%,并且非常类似于来自nusa-njpat菌株的73%的滴度。当njpat与gst或rstrx组合使用时,获得的滴度较低(与mbp-njpat滴度相比,分别为43%和7%)。
序列表
seqidno:1
27692-fw核苷酸序列
atatgagctcaatgtcaattattattgcaacaaacagtactgagcatcc
seqidno:2
27692-re核苷酸序列
atatgcggccgcttatatggatacgggatctacgaacaacgatatgatgtg
seqidno:3
njpat核苷酸序列
atgtcaattattattgcaacaaacagtactgagcatccaatttttcgtccattagcaaattttccaccaagtttatggggcaatcttttcacttcattctccatggataatcaggctagggaaatatatgctaaagaacatgaaggtttaaaagaaaaagtgagaatgatgtttttagatacaacaaattacaaaatttcagagaaaatcaatttcataaacacagtggaaagattaggtgtatcatatcattttgagaaagagattgaagaactacttcatcaaatgtttgatgctcattctaaacacctagatgatattcaagaatttgatttgttcactttgggaatttacttcaggattctaaggcaacatggttataaaatctcttgtgatgttttcaataagttgaaagatagcaatggcgaattcaaggacgaacttaaagatgatgtgaatggtatgctaagtttctatgaagcaacacatgtaagaacacatggagaaaatattttagatgaagctctcatttatacaaaagctcaacttgaatccatggccgctgcaagtttaagcccatttctcgcgaaccaagttaagcatgctttgatgcaagctctccacaaagggatcccaagaatcgaagcacgtaactatatctctgtttacgaagaagatcctaacaaaaatgatttgttattgaggttctcaaagatagatttcaatctagtacaaatgattcacaagcaagaattgtgcgatacctttaggtggtggaaagatttggagttcgaatcgaaactatcttttgcaaggaatagagtggtggaagcctacttatggactcttagcgcgtactacgaaccaaaatactcttccgctcggattatattagtcaaactaatggttataatatctgttacggatgacacatatgatgcatatggtacattagatgaacttcaactttttacagatgcaatacaaaggttggatatgagttctatcaatcaacttccagattacatgaagaccatctataaagctctcctagatctttttgacgaaatagaagatcgattatcgaagcatgaaactgatcattcttaccgcgttgcttatgcgaaatatgtgtataaagagatcgttaggtgctacgatatggagtacaaatggttcaacaaaaattacgtgccggcatttgaagaatatatgcagaaagcgttagtcacatcaggtaaccgtttgctcataacgttttcctttctgggaatggacgaagtcgcaactattcaagcgttcgagtgggtaaaaagtaatgccaaaatgatagtctcttccaataaagtattacgacttattgatgacataatgagtcacgaggaagaggatgaaaggggacatgttgcaacagggattgaatgctttgtaaaagaacatggactaactagggaagaggttatcgttgaatttcataagaggattgatgatgcttggaaggatataaatgaggaatttataacgccaaataatttaccgattgagatacttacgcgtgttctaaaccttacaagaattggagatgttgtttacaagtatgatgacgggtatactcatccggagaaagcgttgaaagatcacatcatatcgttgttcgtagatcccgtatccatataa
seqidno:4
njpat氨基酸序列
msiiiatnstehpifrplanfppslwgnlftsfsmdnqareiyakeheglkekvrmmfldttnykisekinfintverlgvsyhfekeieellhqmfdahskhlddiqefdlftlgiyfrilrqhgykiscdvfnklkdsngefkdelkddvngmlsfyeathvrthgenildealiytkaqlesmaaaslspflanqvkhalmqalhkgipriearnyisvyeedpnkndlllrfskidfnlvqmihkqelcdtfrwwkdlefesklsfarnrvveaylwtlsayyepkyssariilvklmviisvtddtydaygtldelqlftdaiqrldmssinqlpdymktiykalldlfdeiedrlskhetdhsyrvayakyvykeivrcydmeykwfnknyvpafeeymqkalvtsgnrllitfsflgmdevatiqafewvksnakmivssnkvlrliddimsheeederghvatgiecfvkehgltreevivefhkriddawkdineefitpnnlpieiltrvlnltrigdvvykyddgythpekalkdhiislfvdpvsi
seqidno:5
njpat密码子优化的核苷酸序列
atgtcgatcatcatcgccaccaacagcaccgagcatcccatcttccgcccgctcgccaacttcccgccgtcgctctggggcaacctgttcacctcgttcagcatggacaaccaggcgcgcgagatctacgccaaggagcacgagggcctcaaggagaaggtccggatgatgttcctggacaccacgaactacaagatctcggagaagatcaacttcatcaacaccgtcgagcgcctgggcgtgagctatcacttcgagaaggagatcgaggagctgctccatcagatgttcgacgcccactcgaagcatctggacgacatccaggagttcgacctcttcacgctgggcatctacttccgcatcctgcggcagcatggctataagatctcgtgcgacgtcttcaacaagctgaaggacagcaacggcgagttcaaggacgagctcaaggacgacgtcaacggcatgctgtcgttctatgaggccacccatgtgcgcacccatggcgagaacatcctcgacgaggcgctgatctacacgaaggcccagctggagtcgatggcggccgcctcgctcagcccgttcctggccaaccaggtgaagcacgcgctcatgcaggccctgcataagggcatcccgcgcatcgaggcgcggaactacatctcggtctatgaggaagacccgaacaagaacgacctgctcctgcgcttcagcaagatcgacttcaacctggtgcagatgatccacaagcaggagctgtgcgacaccttccggtggtggaaggacctggagttcgagtcgaagctgtcgttcgcccgcaaccgggtggtggaggcctacctctggacgctgtcggcgtactatgagccgaagtattcgagcgcccgcatcatcctcgtgaagctgatggtcatcatctcggtgaccgacgacacgtacgacgcctatggcaccctggacgagctccagctgttcacggacgcgatccagcgcctcgacatgtcgagcatcaaccagctgcccgactacatgaagaccatctataaggcgctcctggacctcttcgacgagatcgaggaccgcctgtcgaagcacgagacggaccatagctaccgggtggcgtatgccaagtacgtctataaggagatcgtgcgctgctacgacatggagtataagtggttcaacaagaactacgtccccgccttcgaggagtatatgcagaaggccctggtgacctcgggcaaccggctcctgatcacgttcagcttcctgggcatggacgaggtcgcgaccatccaggccttcgagtgggtgaagtcgaacgccaagatgatcgtgtcgtcgaacaaggtgctccgcctgatcgacgacatcatgtcgcacgaggaagaggacgagcgcggccatgtggccacgggcatcgagtgcttcgtgaaggagcacggcctgacccgcgaggaagtgatcgtcgagttccataagcggatcgacgacgcgtggaaggacatcaacgaggagttcatcaccccgaacaacctgccgatcgagatcctgacccgcgtgctcaacctgacccggatcggcgacgtggtctacaagtatgacgacggctacacgcaccccgagaaggccctcaaggaccatatcatcagcctgttcgtggaccccgtcagcatctga
seqidno:6
pppa_fw核苷酸序列
actggcctcagaattcaaatttatttgctttgtgagcggataac
seqidno:7
mbp_njpat_rv核苷酸序列
ggcgatgatgatcgacatgatcttg
seqidno:8
mbp_njpat_fw核苷酸序列
caagatcatgtcgatcatcatcgc
seqidno:9
njpat_rv核苷酸序列
tttatgatttggatcctcagatgctgacggggt
seqidno:10
spppa-mbp-njpat核苷酸序列
aaatttatttgctttgtgagcggataacaattattagattcaccggcgagccagcaggaatttcactctagatgacaggagggacatatgaagatcgaggaaggcaagctcgtgatctggatcaacggcgacaagggctacaacggcctggccgaggtgggcaagaagttcgagaaggacaccggcatcaaggtgacggtggagcacccggacaagctcgaggagaagttcccgcaggtggcggccacgggcgacggcccggacatcatcttctgggcccatgaccgcttcggcggctacgcccagtcgggcctgctggccgagatcaccccggacaaggcgttccaggacaagctctatcccttcacgtgggacgccgtgcgctacaacggcaagctgatcgcgtatcccatcgcggtggaggccctgtcgctcatctataacaaggacctgctcccgaacccgcccaagacctgggaggagatccccgccctcgacaaggagctgaaggccaagggcaagtcggcgctcatgttcaacctgcaggagccgtacttcacctggcccctgatcgcggccgacggcggctacgcgttcaagtatgagaacggcaagtatgacatcaaggacgtgggcgtggacaacgcgggcgccaaggccggcctgaccttcctcgtggacctgatcaagaacaagcacatgaacgccgacacggactactcgatcgcggaggccgcgttcaacaagggcgagaccgccatgacgatcaacggcccgtgggcgtggtcgaacatcgacacctcgaaggtgaactatggcgtgaccgtgctccccacgttcaagggccagccctcgaagcccttcgtgggcgtgctgtcggcgggcatcaacgccgcgtcgccgaacaaggagctcgcgaaggagttcctggagaactacctgctcaccgacgagggcctggaggccgtgaacaaggacaagcccctgggcgccgtggccctgaagtcgtatgaggaagagctggtgaaggacccgcgcatcgcggccaccatggagaacgcgcagaagggcgagatcatgccgaacatcccccagatgtcggccttctggtatgcggtgcgcaccgccgtgatcaacgcggcctcgggccgccagaccgtggacgaggccctcaaggacgcccagaccggcgacgacgacgacaagatcatgtcgatcatcatcgccaccaacagcaccgagcatcccatcttccgcccgctcgccaacttcccgccgtcgctctggggcaacctgttcacctcgttcagcatggacaaccaggcgcgcgagatctacgccaaggagcacgagggcctcaaggagaaggtccggatgatgttcctggacaccacgaactacaagatctcggagaagatcaacttcatcaacaccgtcgagcgcctgggcgtgagctatcacttcgagaaggagatcgaggagctgctccatcagatgttcgacgcccactcgaagcatctggacgacatccaggagttcgacctcttcacgctgggcatctacttccgcatcctgcggcagcatggctataagatctcgtgcgacgtcttcaacaagctgaaggacagcaacggcgagttcaaggacgagctcaaggacgacgtcaacggcatgctgtcgttctatgaggccacccatgtgcgcacccatggcgagaacatcctcgacgaggcgctgatctacacgaaggcccagctggagtcgatggcggccgcctcgctcagcccgttcctggccaaccaggtgaagcacgcgctcatgcaggccctgcataagggcatcccgcgcatcgaggcgcggaactacatctcggtctatgaggaagacccgaacaagaacgacctgctcctgcgcttcagcaagatcgacttcaacctggtgcagatgatccacaagcaggagctgtgcgacaccttccggtggtggaaggacctggagttcgagtcgaagctgtcgttcgcccgcaaccgggtggtggaggcctacctctggacgctgtcggcgtactatgagccgaagtattcgagcgcccgcatcatcctcgtgaagctgatggtcatcatctcggtgaccgacgacacgtacgacgcctatggcaccctggacgagctccagctgttcacggacgcgatccagcgcctcgacatgtcgagcatcaaccagctgcccgactacatgaagaccatctataaggcgctcctggacctcttcgacgagatcgaggaccgcctgtcgaagcacgagacggaccatagctaccgggtggcgtatgccaagtacgtctataaggagatcgtgcgctgctacgacatggagtataagtggttcaacaagaactacgtccccgccttcgaggagtatatgcagaaggccctggtgacctcgggcaaccggctcctgatcacgttcagcttcctgggcatggacgaggtcgcgaccatccaggccttcgagtgggtgaagtcgaacgccaagatgatcgtgtcgtcgaacaaggtgctccgcctgatcgacgacatcatgtcgcacgaggaagaggacgagcgcggccatgtggccacgggcatcgagtgcttcgtgaaggagcacggcctgacccgcgaggaagtgatcgtcgagttccataagcggatcgacgacgcgtggaaggacatcaacgaggagttcatcaccccgaacaacctgccgatcgagatcctgacccgcgtgctcaacctgacccggatcggcgacgtggtctacaagtatgacgacggctacacgcaccccgagaaggccctcaaggaccatatcatcagcctgttcgtggaccccgtcagcatctga
斜体序列是spppa启动子;带下划线的序列是密码子优化的mbp,普通字体的序列是密码子优化的njpat。
seqidno:11
mbp-njpat氨基酸序列
mkieegklviwingdkgynglaevgkkfekdtgikvtvehpdkleekfpqvaatgdgpdiifwahdrfggyaqsgllaeitpdkafqdklypftwdavryngkliaypiavealsliynkdllpnppktweeipaldkelkakgksalmfnlqepyftwpliaadggyafkyengkydikdvgvdnagakagltflvdliknkhmnadtdysiaeaafnkgetamtingpwawsnidtskvnygvtvlptfkgqpskpfvgvlsaginaaspnkelakeflenylltdegleavnkdkplgavalksyeeelvkdpriaatmenaqkgeimpnipqmsafwyavrtavinaasgrqtvdealkdaqtgddddkimsiiiatnstehpifrplanfppslwgnlftsfsmdnqareiyakeheglkekvrmmfldttnykisekinfintverlgvsyhfekeieellhqmfdahskhlddiqefdlftlgiyfrilrqhgykiscdvfnklkdsngefkdelkddvngmlsfyeathvrthgenildealiytkaqlesmaaaslspflanqvkhalmqalhkgipriearnyisvyeedpnkndlllrfskidfnlvqmihkqelcdtfrwwkdlefesklsfarnrvveaylwtlsayyepkyssariilvklmviisvtddtydaygtldelqlftdaiqrldmssinqlpdymktiykalldlfdeiedrlskhetdhsyrvayakyvykeivrcydmeykwfnknyvpafeeymqkalvtsgnrllitfsflgmdevatiqafewvksnakmivssnkvlrliddimsheeederghvatgiecfvkehgltreevivefhkriddawkdineefitpnnlpieiltrvlnltrigdvvykyddgythpekalkdhiislfvdpvsi
带下划线的序列为mbp标签
seqidno:12
fh8_njpat_rv核苷酸序列
gatcgacatcgacgagaggatcgag
seqidno:13
fh8_njpat_fw核苷酸序列
ctcgtcgatgtcgatcatcatcgcc
seqidno:14
spppa-fh8-njpat核苷酸序列
aaatttatttgctttgtgagcggataacaattattagattcaccggcgagccagcaggaatttcactctagatgacaggagggacatatgccctcggtgcaagaggtggagaagctgctgcatgtgctggaccggaacggcgacggcaaggtgtcggcggaggagctgaaggcgttcgccgacgactcgaagtgcccgctggactcgaacaagatcaaggcgttcatcaaggagcatgacaagaacaaggacggcaagctggacctcaaggagctggtctcgatcctctcgtcgatgtcgatcatcatcgccaccaacagcaccgagcatcccatcttccgcccgctcgccaacttcccgccgtcgctctggggcaacctgttcacctcgttcagcatggacaaccaggcgcgcgagatctacgccaaggagcacgagggcctcaaggagaaggtccggatgatgttcctggacaccacgaactacaagatctcggagaagatcaacttcatcaacaccgtcgagcgcctgggcgtgagctatcacttcgagaaggagatcgaggagctgctccatcagatgttcgacgcccactcgaagcatctggacgacatccaggagttcgacctcttcacgctgggcatctacttccgcatcctgcggcagcatggctataagatctcgtgcgacgtcttcaacaagctgaaggacagcaacggcgagttcaaggacgagctcaaggacgacgtcaacggcatgctgtcgttctatgaggccacccatgtgcgcacccatggcgagaacatcctcgacgaggcgctgatctacacgaaggcccagctggagtcgatggcggccgcctcgctcagcccgttcctggccaaccaggtgaagcacgcgctcatgcaggccctgcataagggcatcccgcgcatcgaggcgcggaactacatctcggtctatgaggaagacccgaacaagaacgacctgctcctgcgcttcagcaagatcgacttcaacctggtgcagatgatccacaagcaggagctgtgcgacaccttccggtggtggaaggacctggagttcgagtcgaagctgtcgttcgcccgcaaccgggtggtggaggcctacctctggacgctgtcggcgtactatgagccgaagtattcgagcgcccgcatcatcctcgtgaagctgatggtcatcatctcggtgaccgacgacacgtacgacgcctatggcaccctggacgagctccagctgttcacggacgcgatccagcgcctcgacatgtcgagcatcaaccagctgcccgactacatgaagaccatctataaggcgctcctggacctcttcgacgagatcgaggaccgcctgtcgaagcacgagacggaccatagctaccgggtggcgtatgccaagtacgtctataaggagatcgtgcgctgctacgacatggagtataagtggttcaacaagaactacgtccccgccttcgaggagtatatgcagaaggccctggtgacctcgggcaaccggctcctgatcacgttcagcttcctgggcatggacgaggtcgcgaccatccaggccttcgagtgggtgaagtcgaacgccaagatgatcgtgtcgtcgaacaaggtgctccgcctgatcgacgacatcatgtcgcacgaggaagaggacgagcgcggccatgtggccacgggcatcgagtgcttcgtgaaggagcacggcctgacccgcgaggaagtgatcgtcgagttccataagcggatcgacgacgcgtggaaggacatcaacgaggagttcatcaccccgaacaacctgccgatcgagatcctgacccgcgtgctcaacctgacccggatcggcgacgtggtctacaagtatgacgacggctacacgcaccccgagaaggccctcaaggaccatatcatcagcctgttcgtggaccccgtcagcatctga
斜体序列是spppa启动子;带下划线的序列是密码子优化的fh8,普通字体的序列是密码子优化的njpat。
seqidno:15
fh8-njpat氨基酸序列
mpsvqevekllhvldrngdgkvsaeelkafaddskcpldsnkikafikehdknkdgkldlkelvsilssmsiiiatnstehpifrplanfppslwgnlftsfsmdnqareiyakeheglkekvrmmfldttnykisekinfintverlgvsyhfekeieellhqmfdahskhlddiqefdlftlgiyfrilrqhgykiscdvfnklkdsngefkdelkddvngmlsfyeathvrthgenildealiytkaqlesmaaaslspflanqvkhalmqalhkgipriearnyisvyeedpnkndlllrfskidfnlvqmihkqelcdtfrwwkdlefesklsfarnrvveaylwtlsayyepkyssariilvklmviisvtddtydaygtldelqlftdaiqrldmssinqlpdymktiykalldlfdeiedrlskhetdhsyrvayakyvykeivrcydmeykwfnknyvpafeeymqkalvtsgnrllitfsflgmdevatiqafewvksnakmivssnkvlrliddimsheeederghvatgiecfvkehgltreevivefhkriddawkdineefitpnnlpieiltrvlnltrigdvvykyddgythpekalkdhiislfvdpvsi
带下划线的序列为fh8标签
seqidno:16
sumo_njpat_rv核苷酸序列
gatcgacatgccgatctgctcgcg
seqidno:17
sumo_njpat_fw核苷酸序列
gatcggcatgtcgatcatcatcgcc
seqidno:18
spppa-sumo-njpat核苷酸序列
aaatttatttgctttgtgagcggataacaattattagattcaccggcgagccagcaggaatttcactctagatgacaggagggacatatgtcggacagcgaggtgaaccaggaagccaagcccgaggtgaagcccgaggtgaagccggagacccacatcaacctgaaggtgtcggacggctcgtcggagatcttcttcaagatcaagaagaccacgcccctgcgccgcctcatggaggccttcgccaagcgccagggcaaggagatggactcgctgcgcttcctctacgacggcatccgcatccaggcggaccagacgccggaggacctcgacatggaggacaacgacatcatcgaggcgcatcgcgagcagatcggcatgtcgatcatcatcgccaccaacagcaccgagcatcccatcttccgcccgctcgccaacttcccgccgtcgctctggggcaacctgttcacctcgttcagcatggacaaccaggcgcgcgagatctacgccaaggagcacgagggcctcaaggagaaggtccggatgatgttcctggacaccacgaactacaagatctcggagaagatcaacttcatcaacaccgtcgagcgcctgggcgtgagctatcacttcgagaaggagatcgaggagctgctccatcagatgttcgacgcccactcgaagcatctggacgacatccaggagttcgacctcttcacgctgggcatctacttccgcatcctgcggcagcatggctataagatctcgtgcgacgtcttcaacaagctgaaggacagcaacggcgagttcaaggacgagctcaaggacgacgtcaacggcatgctgtcgttctatgaggccacccatgtgcgcacccatggcgagaacatcctcgacgaggcgctgatctacacgaaggcccagctggagtcgatggcggccgcctcgctcagcccgttcctggccaaccaggtgaagcacgcgctcatgcaggccctgcataagggcatcccgcgcatcgaggcgcggaactacatctcggtctatgaggaagacccgaacaagaacgacctgctcctgcgcttcagcaagatcgacttcaacctggtgcagatgatccacaagcaggagctgtgcgacaccttccggtggtggaaggacctggagttcgagtcgaagctgtcgttcgcccgcaaccgggtggtggaggcctacctctggacgctgtcggcgtactatgagccgaagtattcgagcgcccgcatcatcctcgtgaagctgatggtcatcatctcggtgaccgacgacacgtacgacgcctatggcaccctggacgagctccagctgttcacggacgcgatccagcgcctcgacatgtcgagcatcaaccagctgcccgactacatgaagaccatctataaggcgctcctggacctcttcgacgagatcgaggaccgcctgtcgaagcacgagacggaccatagctaccgggtggcgtatgccaagtacgtctataaggagatcgtgcgctgctacgacatggagtataagtggttcaacaagaactacgtccccgccttcgaggagtatatgcagaaggccctggtgacctcgggcaaccggctcctgatcacgttcagcttcctgggcatggacgaggtcgcgaccatccaggccttcgagtgggtgaagtcgaacgccaagatgatcgtgtcgtcgaacaaggtgctccgcctgatcgacgacatcatgtcgcacgaggaagaggacgagcgcggccatgtggccacgggcatcgagtgcttcgtgaaggagcacggcctgacccgcgaggaagtgatcgtcgagttccataagcggatcgacgacgcgtggaaggacatcaacgaggagttcatcaccccgaacaacctgccgatcgagatcctgacccgcgtgctcaacctgacccggatcggcgacgtggtctacaagtatgacgacggctacacgcaccccgagaaggccctcaaggaccatatcatcagcctgttcgtggaccccgtcagcatctga
斜体序列是spppa启动子;带下划线的序列是密码子优化的sumo,正常字体的序列是密码子优化的njpat。
seqidno:19
sumo-njpat氨基酸序列
msdsevnqeakpevkpevkpethinlkvsdgsseiffkikkttplrrlmeafakrqgkemdslrflydgiriqadqtpedldmedndiieahreqigmsiiiatnstehpifrplanfppslwgnlftsfsmdnqareiyakeheglkekvrmmfldttnykisekinfintverlgvsyhfekeieellhqmfdahskhlddiqefdlftlgiyfrilrqhgykiscdvfnklkdsngefkdelkddvngmlsfyeathvrthgenildealiytkaqlesmaaaslspflanqvkhalmqalhkgipriearnyisvyeedpnkndlllrfskidfnlvqmihkqelcdtfrwwkdlefesklsfarnrvveaylwtlsayyepkyssariilvklmviisvtddtydaygtldelqlftdaiqrldmssinqlpdymktiykalldlfdeiedrlskhetdhsyrvayakyvykeivrcydmeykwfnknyvpafeeymqkalvtsgnrllitfsflgmdevatiqafewvksnakmivssnkvlrliddimsheeederghvatgiecfvkehgltreevivefhkriddawkdineefitpnnlpieiltrvlnltrigdvvykyddgythpekalkdhiislfvdpvsi
带下划线的序列为sumo标签
seqidno:20
nusa_njpat_rv核苷酸序列
tgatcgacatcgcctcgtcgccgaac
seqidno:21
nusa_njpat_fw核苷酸序列
cgaggcgatgtcgatcatcatcgcc
seqidno:22
spppa-nusa-njpat核苷酸序列
aaatttatttgctttgtgagcggataacaattattagattcaccggcgagccagcaggaatttcactctagatgacaggagggacatatgaacaaggagatcctcgcggtggtggaggcggtgtcgaacgagaaggcgctgccccgcgagaagatcttcgaggccctggagtcggccctggccaccgcgaccaagaagaagtacgagcaggagatcgacgtgcgcgtgcagatcgaccgcaagtcgggcgacttcgacacgttccgccgctggctcgtggtggacgaggtgacccagcccacgaaggagatcaccctggaggcggcccgctatgaggacgagtcgctgaacctcggcgactatgtggaggaccagatcgagtcggtgaccttcgaccgcatcaccacgcagacggcgaagcaggtgatcgtgcagaaggtgcgcgaggccgagcgcgccatggtggtggaccagttccgcgagcacgagggcgagatcatcaccggcgtggtgaagaaggtgaaccgcgacaacatctcgctggacctgggcaacaacgcggaggccgtgatcctgcgcgaggacatgctcccgcgcgagaacttccgcccgggcgaccgcgtgcgcggcgtgctctattcggtgcgccccgaggcccgtggcgcccagctgttcgtgacccgctcgaagccggagatgctgatcgagctcttccgcatcgaggtgcccgagatcggcgaggaagtgatcgagatcaaggcggccgcccgcgacccgggctcgcgcgcgaagatcgccgtgaagaccaacgacaagcgcatcgaccccgtgggcgcctgcgtgggcatgcgtggcgcccgcgtgcaggccgtgtcgaccgagctcggcggcgagcgcatcgacatcgtgctgtgggacgacaacccggcgcagttcgtgatcaacgccatggccccggcggacgtggcctcgatcgtggtggacgaggacaagcataccatggacatcgccgtggaggcgggcaacctggcccaggccatcggccgcaacggccagaacgtgcgcctggcctcgcagctctcgggctgggagctgaacgtgatgacggtggacgacctgcaggccaagcatcaggccgaggcccatgccgccatcgacaccttcacgaagtacctcgacatcgacgaggacttcgcgaccgtgctcgtggaggaaggcttctcgacgctggaggagctcgcctatgtgccgatgaaggagctgctcgagatcgagggcctggacgagccgacggtggaggcgctccgcgagcgcgccaagaacgccctggccaccatcgcccaggcccaggaagagtcgctgggcgacaacaagccggccgacgacctgctcaacctggagggcgtggaccgcgacctggccttcaagctcgccgcccgcggcgtgtgcacgctcgaggacctggccgagcagggcatcgacgacctggccgacatcgagggcctcaccgacgagaaggccggcgccctgatcatggccgcccgcaacatctgctggttcggcgacgaggcgatgtcgatcatcatcgccaccaacagcaccgagcatcccatcttccgcccgctcgccaacttcccgccgtcgctctggggcaacctgttcacctcgttcagcatggacaaccaggcgcgcgagatctacgccaaggagcacgagggcctcaaggagaaggtccggatgatgttcctggacaccacgaactacaagatctcggagaagatcaacttcatcaacaccgtcgagcgcctgggcgtgagctatcacttcgagaaggagatcgaggagctgctccatcagatgttcgacgcccactcgaagcatctggacgacatccaggagttcgacctcttcacgctgggcatctacttccgcatcctgcggcagcatggctataagatctcgtgcgacgtcttcaacaagctgaaggacagcaacggcgagttcaaggacgagctcaaggacgacgtcaacggcatgctgtcgttctatgaggccacccatgtgcgcacccatggcgagaacatcctcgacgaggcgctgatctacacgaaggcccagctggagtcgatggcggccgcctcgctcagcccgttcctggccaaccaggtgaagcacgcgctcatgcaggccctgcataagggcatcccgcgcatcgaggcgcggaactacatctcggtctatgaggaagacccgaacaagaacgacctgctcctgcgcttcagcaagatcgacttcaacctggtgcagatgatccacaagcaggagctgtgcgacaccttccggtggtggaaggacctggagttcgagtcgaagctgtcgttcgcccgcaaccgggtggtggaggcctacctctggacgctgtcggcgtactatgagccgaagtattcgagcgcccgcatcatcctcgtgaagctgatggtcatcatctcggtgaccgacgacacgtacgacgcctatggcaccctggacgagctccagctgttcacggacgcgatccagcgcctcgacatgtcgagcatcaaccagctgcccgactacatgaagaccatctataaggcgctcctggacctcttcgacgagatcgaggaccgcctgtcgaagcacgagacggaccatagctaccgggtggcgtatgccaagtacgtctataaggagatcgtgcgctgctacgacatggagtataagtggttcaacaagaactacgtccccgccttcgaggagtatatgcagaaggccctggtgacctcgggcaaccggctcctgatcacgttcagcttcctgggcatggacgaggtcgcgaccatccaggccttcgagtgggtgaagtcgaacgccaagatgatcgtgtcgtcgaacaaggtgctccgcctgatcgacgacatcatgtcgcacgaggaagaggacgagcgcggccatgtggccacgggcatcgagtgcttcgtgaaggagcacggcctgacccgcgaggaagtgatcgtcgagttccataagcggatcgacgacgcgtggaaggacatcaacgaggagttcatcaccccgaacaacctgccgatcgagatcctgacccgcgtgctcaacctgacccggatcggcgacgtggtctacaagtatgacgacggctacacgcaccccgagaaggccctcaaggaccatatcatcagcctgttcgtggaccccgtcagcatctga
斜体序列是spppa启动子;带下划线的序列是密码子优化的nusa,正常字体的序列是密码子优化的njpat。
seqidno:23
nusa-njpat氨基酸序列
mnkeilavveavsnekalprekifealesalatatkkkyeqeidvrvqidrksgdfdtfrrwlvvdevtqptkeitleaaryedeslnlgdyvedqiesvtfdrittqtakqvivqkvreaeramvvdqfrehegeiitgvvkkvnrdnisldlgnnaeavilredmlprenfrpgdrvrgvlysvrpeargaqlfvtrskpemlielfrievpeigeevieikaaardpgsrakiavktndkridpvgacvgmrgarvqavstelggeridivlwddnpaqfvinamapadvasivvdedkhtmdiaveagnlaqaigrngqnvrlasqlsgwelnvmtvddlqakhqaeahaaidtftkyldidedfatvlveegfstleelayvpmkelleiegldeptvealreraknalatiaqaqeeslgdnkpaddllnlegvdrdlafklaargvctledlaeqgiddladiegltdekagalimaarnicwfgdeamsiiiatnstehpifrplanfppslwgnlftsfsmdnqareiyakeheglkekvrmmfldttnykisekinfintverlgvsyhfekeieellhqmfdahskhlddiqefdlftlgiyfrilrqhgykiscdvfnklkdsngefkdelkddvngmlsfyeathvrthgenildealiytkaqlesmaaaslspflanqvkhalmqalhkgipriearnyisvyeedpnkndlllrfskidfnlvqmihkqelcdtfrwwkdlefesklsfarnrvveaylwtlsayyepkyssariilvklmviisvtddtydaygtldelqlftdaiqrldmssinqlpdymktiykalldlfdeiedrlskhetdhsyrvayakyvykeivrcydmeykwfnknyvpafeeymqkalvtsgnrllitfsflgmdevatiqafewvksnakmivssnkvlrliddimsheeederghvatgiecfvkehgltreevivefhkriddawkdineefitpnnlpieiltrvlnltrigdvvykyddgythpekalkdhiislfvdpvsi
带下划线的序列为nusa标签
seqidno:24
rstrx_njpat_rv核苷酸序列
tgatcgacatgagcgccgaggcgatc
seqidno:25
rstrx_njpat_fw核苷酸序列
ggcgctcatgtcgatcatcatcgcc
seqidno:26
spppa-rstrx-njpat核苷酸序列
aaatttatttgctttgtgagcggataacaattattagattcaccggcgagccagcaggaatttcactctagatgacaggagggacatatgtccaccgttcccgtgacggacgccaccttcgacaccgaggtgcgcaagtccgacgtgcccgtcgtcgtcgatttctgggccgaatggtgcggcccctgccggcagatcggcccggcgctcgaggagctctcgaaggaatatgccggcaaggtgaagatcgtgaaggtcaatgtcgacgagaaccccgagagcccggcgatgctgggcgttcgcggcatcccggcgctgttcctgttcaagaacggtcaggtcgtgtcgaacaaggtcggcgctgcgccgaaggccgcgctggccacctggatcgcctcggcgctcatgtcgatcatcatcgccaccaacagcaccgagcatcccatcttccgcccgctcgccaacttcccgccgtcgctctggggcaacctgttcacctcgttcagcatggacaaccaggcgcgcgagatctacgccaaggagcacgagggcctcaaggagaaggtccggatgatgttcctggacaccacgaactacaagatctcggagaagatcaacttcatcaacaccgtcgagcgcctgggcgtgagctatcacttcgagaaggagatcgaggagctgctccatcagatgttcgacgcccactcgaagcatctggacgacatccaggagttcgacctcttcacgctgggcatctacttccgcatcctgcggcagcatggctataagatctcgtgcgacgtcttcaacaagctgaaggacagcaacggcgagttcaaggacgagctcaaggacgacgtcaacggcatgctgtcgttctatgaggccacccatgtgcgcacccatggcgagaacatcctcgacgaggcgctgatctacacgaaggcccagctggagtcgatggcggccgcctcgctcagcccgttcctggccaaccaggtgaagcacgcgctcatgcaggccctgcataagggcatcccgcgcatcgaggcgcggaactacatctcggtctatgaggaagacccgaacaagaacgacctgctcctgcgcttcagcaagatcgacttcaacctggtgcagatgatccacaagcaggagctgtgcgacaccttccggtggtggaaggacctggagttcgagtcgaagctgtcgttcgcccgcaaccgggtggtggaggcctacctctggacgctgtcggcgtactatgagccgaagtattcgagcgcccgcatcatcctcgtgaagctgatggtcatcatctcggtgaccgacgacacgtacgacgcctatggcaccctggacgagctccagctgttcacggacgcgatccagcgcctcgacatgtcgagcatcaaccagctgcccgactacatgaagaccatctataaggcgctcctggacctcttcgacgagatcgaggaccgcctgtcgaagcacgagacggaccatagctaccgggtggcgtatgccaagtacgtctataaggagatcgtgcgctgctacgacatggagtataagtggttcaacaagaactacgtccccgccttcgaggagtatatgcagaaggccctggtgacctcgggcaaccggctcctgatcacgttcagcttcctgggcatggacgaggtcgcgaccatccaggccttcgagtgggtgaagtcgaacgccaagatgatcgtgtcgtcgaacaaggtgctccgcctgatcgacgacatcatgtcgcacgaggaagaggacgagcgcggccatgtggccacgggcatcgagtgcttcgtgaaggagcacggcctgacccgcgaggaagtgatcgtcgagttccataagcggatcgacgacgcgtggaaggacatcaacgaggagttcatcaccccgaacaacctgccgatcgagatcctgacccgcgtgctcaacctgacccggatcggcgacgtggtctacaagtatgacgacggctacacgcaccccgagaaggccctcaaggaccatatcatcagcctgttcgtggaccccgtcagcatctga
斜体序列是spppa启动子;带下划线的序列是密码子优化的rstrx,普通字体的序列是密码子优化的njpat。
seqidno:27
rstrx-njpat氨基酸序列
mstvpvtdatfdtevrksdvpvvvdfwaewcgpcrqigpaleelskeyagkvkivkvnvdenpespamlgvrgipalflfkngqvvsnkvgaapkaalatwiasalmsiiiatnstehpifrplanfppslwgnlftsfsmdnqareiyakeheglkekvrmmfldttnykisekinfintverlgvsyhfekeieellhqmfdahskhlddiqefdlftlgiyfrilrqhgykiscdvfnklkdsngefkdelkddvngmlsfyeathvrthgenildealiytkaqlesmaaaslspflanqvkhalmqalhkgipriearnyisvyeedpnkndlllrfskidfnlvqmihkqelcdtfrwwkdlefesklsfarnrvveaylwtlsayyepkyssariilvklmviisvtddtydaygtldelqlftdaiqrldmssinqlpdymktiykalldlfdeiedrlskhetdhsyrvayakyvykeivrcydmeykwfnknyvpafeeymqkalvtsgnrllitfsflgmdevatiqafewvksnakmivssnkvlrliddimsheeederghvatgiecfvkehgltreevivefhkriddawkdineefitpnnlpieiltrvlnltrigdvvykyddgythpekalkdhiislfvdpvsi
带下划线的序列为rstrx标签
seqidno:28
gst_njpat_rv核苷酸序列
atcgacatcttgggcggatgg
seqidno:29
gst_njpat_fw核苷酸序列
gcccaagatgtcgatcatcatcgcc
seqidno:30
spppa-gst-njpat核苷酸序列
aaatttatttgctttgtgagcggataacaattattagattcaccggcgagccagcaggaatttcactctagatgacaggagggacatatgtcgccgatcctgggctattggaagatcaagggcctcgtgcagcccacccgcctgctcctggagtacctggaggagaagtatgaggagcacctctacgagcgcgacgagggcgacaagtggcgcaacaagaagttcgagctcggcctggagttcccgaacctgccctactatatcgacggcgacgtgaagctcacgcagtcgatggccatcatccgctacatcgcggacaagcataacatgctgggcggctgccccaaggagcgcgcggagatctcgatgctggagggcgcggtgctcgacatccgctatggcgtgtcgcgcatcgcctactcgaaggacttcgagaccctgaaggtggacttcctctcgaagctgccggagatgctcaagatgttcgaggaccgcctgtgccacaagacctatctcaacggcgaccacgtgacgcatcccgacttcatgctctatgacgcgctggacgtggtgctctacatggacccgatgtgcctggacgccttccccaagctcgtgtgcttcaagaagcgcatcgaggcgatcccgcagatcgacaagtatctgaagtcgtcgaagtacatcgcctggcccctccagggctggcaggcgacgttcggcggcggcgaccatccgcccaagatgtcgatcatcatcgccaccaacagcaccgagcatcccatcttccgcccgctcgccaacttcccgccgtcgctctggggcaacctgttcacctcgttcagcatggacaaccaggcgcgcgagatctacgccaaggagcacgagggcctcaaggagaaggtccggatgatgttcctggacaccacgaactacaagatctcggagaagatcaacttcatcaacaccgtcgagcgcctgggcgtgagctatcacttcgagaaggagatcgaggagctgctccatcagatgttcgacgcccactcgaagcatctggacgacatccaggagttcgacctcttcacgctgggcatctacttccgcatcctgcggcagcatggctataagatctcgtgcgacgtcttcaacaagctgaaggacagcaacggcgagttcaaggacgagctcaaggacgacgtcaacggcatgctgtcgttctatgaggccacccatgtgcgcacccatggcgagaacatcctcgacgaggcgctgatctacacgaaggcccagctggagtcgatggcggccgcctcgctcagcccgttcctggccaaccaggtgaagcacgcgctcatgcaggccctgcataagggcatcccgcgcatcgaggcgcggaactacatctcggtctatgaggaagacccgaacaagaacgacctgctcctgcgcttcagcaagatcgacttcaacctggtgcagatgatccacaagcaggagctgtgcgacaccttccggtggtggaaggacctggagttcgagtcgaagctgtcgttcgcccgcaaccgggtggtggaggcctacctctggacgctgtcggcgtactatgagccgaagtattcgagcgcccgcatcatcctcgtgaagctgatggtcatcatctcggtgaccgacgacacgtacgacgcctatggcaccctggacgagctccagctgttcacggacgcgatccagcgcctcgacatgtcgagcatcaaccagctgcccgactacatgaagaccatctataaggcgctcctggacctcttcgacgagatcgaggaccgcctgtcgaagcacgagacggaccatagctaccgggtggcgtatgccaagtacgtctataaggagatcgtgcgctgctacgacatggagtataagtggttcaacaagaactacgtccccgccttcgaggagtatatgcagaaggccctggtgacctcgggcaaccggctcctgatcacgttcagcttcctgggcatggacgaggtcgcgaccatccaggccttcgagtgggtgaagtcgaacgccaagatgatcgtgtcgtcgaacaaggtgctccgcctgatcgacgacatcatgtcgcacgaggaagaggacgagcgcggccatgtggccacgggcatcgagtgcttcgtgaaggagcacggcctgacccgcgaggaagtgatcgtcgagttccataagcggatcgacgacgcgtggaaggacatcaacgaggagttcatcaccccgaacaacctgccgatcgagatcctgacccgcgtgctcaacctgacccggatcggcgacgtggtctacaagtatgacgacggctacacgcaccccgagaaggccctcaaggaccatatcatcagcctgttcgtggaccccgtcagcatctga
斜体序列是spppa启动子;带下划线的序列是密码子优化的gst,普通字体的序列是密码子优化的njpat。
seqidno:31
gst-njpat氨基酸序列
mspilgywkikglvqptrllleyleekyeehlyerdegdkwrnkkfelglefpnlpyyidgdvkltqsmaiiryiadkhnmlggcpkeraeismlegavldirygvsriayskdfetlkvdflsklpemlkmfedrlchktylngdhvthpdfmlydaldvvlymdpmcldafpklvcfkkrieaipqidkylksskyiawplqgwqatfgggdhppkmsiiiatnstehpifrplanfppslwgnlftsfsmdnqareiyakeheglkekvrmmfldttnykisekinfintverlgvsyhfekeieellhqmfdahskhlddiqefdlftlgiyfrilrqhgykiscdvfnklkdsngefkdelkddvngmlsfyeathvrthgenildealiytkaqlesmaaaslspflanqvkhalmqalhkgipriearnyisvyeedpnkndlllrfskidfnlvqmihkqelcdtfrwwkdlefesklsfarnrvveaylwtlsayyepkyssariilvklmviisvtddtydaygtldelqlftdaiqrldmssinqlpdymktiykalldlfdeiedrlskhetdhsyrvayakyvykeivrcydmeykwfnknyvpafeeymqkalvtsgnrllitfsflgmdevatiqafewvksnakmivssnkvlrliddimsheeederghvatgiecfvkehgltreevivefhkriddawkdineefitpnnlpieiltrvlnltrigdvvykyddgythpekalkdhiislfvdpvsi
带下划线的序列为gst标签。
- 还没有人留言评论。精彩留言会获得点赞!