水稻生长素响应基因的应用的制作方法
本发明属于种子生物技术领域,涉及水稻生长素响应基因的应用。
背景技术:
水稻(oryzasatival.)是世界上最重要的粮食作物之一。近年来,随着经济的发展,农村劳动力日益短缺,直播稻生产变得越来越普遍,高活力水稻品种培育具有重要意义。选育高活力水稻品种,可以提高田间种子发芽能力,促进田间成苗,对保障直播稻产量具有重要意义。生长素是调控植物生长发育的重要因子,有关生长素响应基因调控水稻种子活力的研究未有报道,有关利用生长素响应基因筛选和培育高活力水稻品种的应用未有报道。因此,利用参与水稻种子活力调控的生长素响应基因ossaru33,对筛选和培育高活力水稻品种提供帮助,对直播稻生产具有重要意义。
技术实现要素:
本发明的目的是提供一个控制水稻种子活力的生长素响应基因ossaur33的分离克隆、功能验证和应用。
本发明的目的可通过如下技术方案实现:
本发明的一个来自水稻生长素响应基因ossaur33,其核苷酸序列如seqidno.1所示。
本发明所述的水稻生长素响应基因ossaur33编码的蛋白,其氨基酸序列如seqidno.2所示。
本发明所述的水稻ossaur33基因或蛋白在筛选或培育高活力水稻品种中的应用。
本发明所述的水稻ossaur33基因突变体获得和基因功能验证,包括如下步骤:
(1)获得水稻ossaur33基因的核苷酸序列及氨基酸序列;
(2)设计靶位点引物,以pcbc-mt1t2为模板进行pcr扩增,纯化回收pcr产物,获得mt1t2-pcr;
(3)将步骤(2)得到的带有ossaur33基因的目标片段的mt1t2-pcr胶回收产物构建到phue411载体上,获得phue411+mt1t2-pcr载体;
(4)将步骤(3)得到的带有ossaur33基因目标片段的质粒phue411+mt1t2-pcr转化农杆菌;将带有转化质粒的农杆菌转化水稻;
(5)水稻突变体筛选与鉴定,并在正常条件下鉴定种子活力。
进一步的,在步骤(1)中利用从水稻cdna为模板pcr克隆出该基因的引物序列,所述上游引物序列如seqidno.3所示,所述下游引物序列如seqidno.4所示。
进一步的,在步骤(2)中构建的水稻ossaur33crispr/cas9突变体grna靶序列(ossaur33基因中19bp的目标片段)如seqidno.5、seqidno.6所示;以pcbc-mt1t2为模板进行pcr扩增的引物序列如seqidno.7/seqidno.8、seqidno.9/seqidno.10;以pcbc-mt1t2为模板进行四引物pcr扩增,纯化回收pcr产物,获得mt1t2-pcr片段。
在步骤(3)中,用bsai酶切phue411载体,利用同源重组法获得phue411+mt1t2-pcr载体。
在步骤(5)中,筛选纯合突变体所用上游引物序列如seqidno.11所示,下游引物序列如seqidno.12所示。水稻种子活力鉴定包括正常条件下种子发芽、幼苗生长。
本发明所述的一种检测种子萌发期ossaur33基因表达水平的方法,其特征在于包括如下步骤:
(1)取不同萌发期水稻种子;
(2)用transzolplantkit(transgen,www.transgen.com)试剂盒提取各个样的rna;
(3)用
(4)用荧光定量pcr进行分析,荧光定量pcr检测引物序列,所述上游引物序列如seqidno.13所示,所述下游引物序列如seqidno.14所示。
进一步的,在步骤(1)中水稻种子在10ml蒸馏水培养皿中25℃条件下培养,分别在吸胀0、4、12、36、48、60、72h后取样;种子经液氮冷冻处理后迅速磨成粉末,样品贮存于-80℃,每个时间点取样三份。
在步骤(4)中,采用水稻内参基因osactin引物,所述上游引物的序列如seqidno.15所示,所述下游引物的序列如seqidno.16所示。
有益效果:本发明从水稻中分离克隆了ossaur33基因,并鉴定了该基因在种子活力调控方面的功能,对于高活力水稻品种筛选或育种具有重要意义。
本发明具有如下优点:
(1)本发明从水稻中分离、克隆获得ossaur33基因,通过构建crispr/cas9突变体首次证明了该基因参与水稻种子活力调控。
(2)本发明为筛选高种子活力水稻品种提供了基础,也为改良提高水稻种子活力提供了重要的基因资源,对直播稻生产具有重要意义。
附图说明
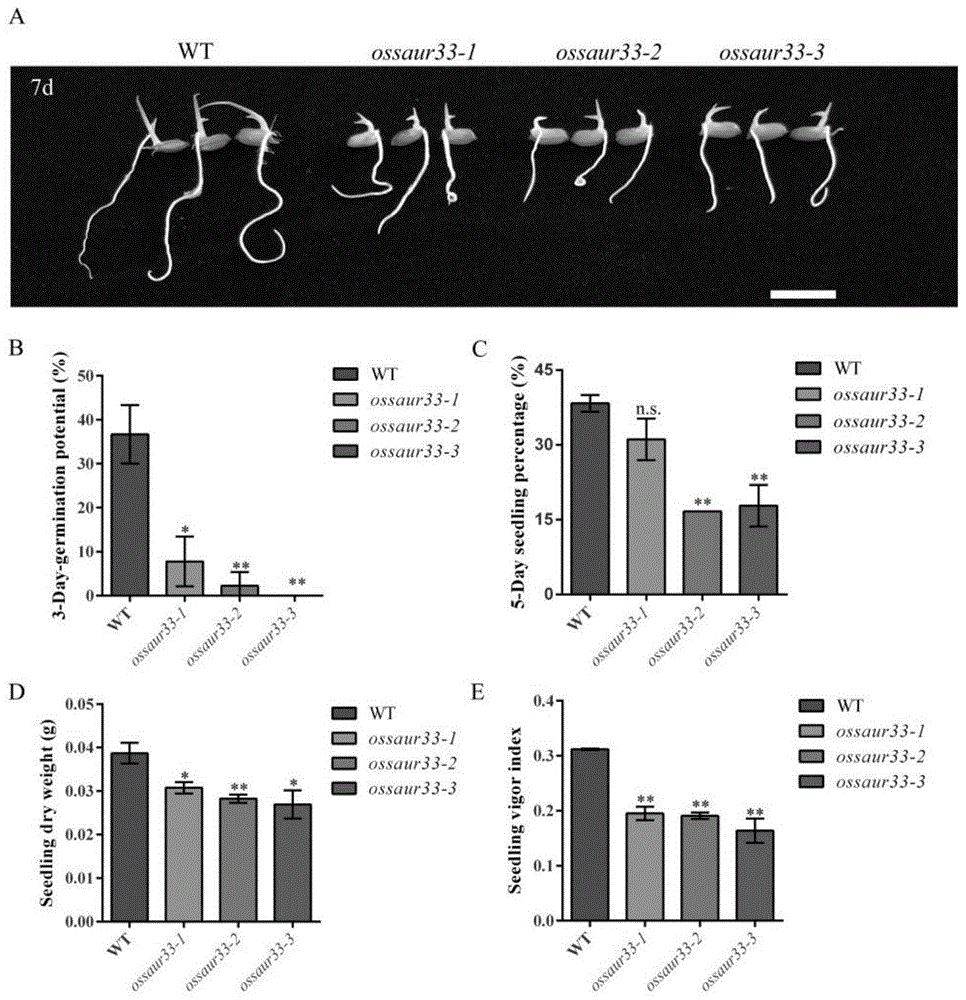
图1:水稻ossaur33突变体在正常条件下的种子活力表现
图2:水稻ossaur33基因在种子萌发过程中的表达情况
具体实施方式
本发明结合附图和具体实施例作进一步说明,实施例中所用方法无特别说明均为常规方法,所用引物、测序由广州天一辉远基因科技有限公司完成;实验中用到的各种限制性内切酶、连接酶、dnamarker、tagdna聚合酶、dntps等购自广州硕恒生物科技有限公司;反转录试剂盒购于诺唯赞生物科技有限公司;质粒提取试剂盒、胶回收试剂盒以及基因组提取试剂盒购于美基生物科技有限公司,方法均参照说明书进行。
实施例1:基因克隆
利用粳稻品种日本晴cdna为模板pcr克隆出ossaur33基因的序列,所述上游引物序列如seqidno.3所示,所述下游引物序列如seqidno.4所示。获得水稻ossaur33基因的核苷酸序列及氨基酸序列,其核苷酸序列如seqidno.1所示,其氨基酸序列如seqidno.2所示。
实施例2:突变体构建
登录到网站http://www.genome.arizona.edu/crispr/crisprsearch.html,筛选靶点。靶点序列如seqidno.5、seqidno.6所示,以靶点序列设计引物,引物结构如seqidno.7/seqidno.8,seqidno.9/seqidno.10所示。以pcbc-mt1t2为模板进行四引物pcr扩增,纯化回收pcr产物,获得mt1t2-pcr载体。用bsai酶切phue411载体,利用同源重组法获得phue411+mt1t2-pcr载体。
得到的含有phue411+mt1t2-pcr载体转化农杆菌;将带有转化质粒的农杆菌转化野生型的粳稻品种日本晴;利用pcr扩增产物测序,与野生型比对,筛选纯合突变体,所用上游引物序列如序列表seqidno.11所示,下游引物序列如seqidno.12所示。
实施例3:基因突变体表型分析
利用构建的ossaur33crispr/cas9突变体ossaur33-1、ossaur33-2、ossaur33-3种子,以及野生型日本晴(wt)水稻品种,进行种子发芽试验。具体方法如下:每次重复挑选健康饱满的种子50粒,用0.1%的氯化汞溶液表面消毒5min,蒸馏水冲洗3次,将种子表面擦干,置于垫有两层滤纸的培养皿(直径9cm)中,加入10ml蒸馏水,放置25℃条件下光照/黑暗各12h培养7d后,最后统计成苗率。试验重复3次。结果表明,与对照种子比较,突变体种子发芽速度变慢,幼苗生长显著变弱(图1)。可见,该基因对提高种子发芽速度及幼苗生长具有重要作用。
实施例4:种子萌发期基因表达分析
利用粳稻品种日本晴,每次重复挑选健康饱满的种子50粒,用0.1%的氯化汞溶液表面消毒5min,蒸馏水冲洗3次,将种子表面擦干,置于垫有两层滤纸的培养皿(直径9cm)中,加入10ml蒸馏水,放置30℃黑暗培养箱中分别吸胀0、4、12、36、48、60、72h后,分别取样。种子经液氮冷冻处理后迅速磨成粉末,样品贮存于-80℃。试验重复3次。
用transzolplantkit(transgen,www.transgen.com)试剂盒提取各个样的rna;用
序列表
<110>华南农业大学
<120>水稻生长素响应基因的应用
<160>16
<170>siposequencelisting1.0
<210>1
<211>402
<212>dna
<213>水稻(oryzasativa)
<400>1
atggggaagggaggcgggctgagcaagctgaggtgcatgatcaggaggtggcactcgtcg60
agccgcatcgcgcgggcgccgccgtcggcgggggagctggaggagggctctgcggcggcg120
gcggggagggcggcgtcgttccacggcgcggacgaggtgcccaaggggctccacccggtg180
tacgtcggcaagtcgcggcggcggtacctcatcgccgaggagctcgtcggccacccgctg240
ttccagaacctcgtcgaccgcaccggcggcggcggcggcggcggcgccgcgaccgtcgtc300
ggctgcgaggtcgtgctgttcgagcacctgctctggatgctggagaacgccgacccgcag360
ccggagtccctcgacgagctcgtcgagtactacgcctgctga402
<210>2
<211>133
<212>prt
<213>水稻(oryzasativa)
<400>2
metglylysglyglyglyleuserlysleuargcysmetileargarg
151015
trphisserserserargilealaargalaproproseralaglyglu
202530
leuglugluglyseralaalaalaalaglyargalaalaserphehis
354045
glyalaaspgluvalprolysglyleuhisprovaltyrvalglylys
505560
serargargargtyrleuilealaglugluleuvalglyhisproleu
65707580
pheglnasnleuvalaspargthrglyglyglyglyglyglyglyala
859095
alathrvalvalglycysgluvalvalleuphegluhisleuleutrp
100105110
metleugluasnalaaspproglnprogluserleuaspgluleuval
115120125
glutyrtyralacys
130
<210>3
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>3
atggggaagggaggcgg17
<210>4
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>4
tcagcaggcgtagtactcg19
<210>5
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>5
agctgaggtgcatgatcag19
<210>6
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>6
ggagggcggcgtcgttcca19
<210>7
<211>36
<212>dna
<213>人工序列(artificialsequence)
<400>7
aataatggtctcaggcgagctgaggtgcatgatcag36
<210>8
<211>40
<212>dna
<213>人工序列(artificialsequence)
<400>8
gagctgaggtgcatgatcaggttttagagctagaaatagc40
<210>9
<211>33
<212>dna
<213>人工序列(artificialsequence)
<400>9
tggaacgacgccgccctcccgcttcttggtgcc33
<210>10
<211>36
<212>dna
<213>人工序列(artificialsequence)
<400>10
attattggtctctaaactggaacgacgccgccctcc36
<210>11
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>11
tagcgagccagccttcctct20
<210>12
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>12
gtcggcgttctccagcatc19
<210>13
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>13
cgggtaatatctccgtcctttgcc24
<210>14
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>14
tggcatatcagcaccgaaacagg23
<210>15
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>15
aggaaggctggaagaggacc20
<210>16
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>16
cgggaaattgtgagggacat20
- 还没有人留言评论。精彩留言会获得点赞!