使用机器学习技术分析纳米孔信号的制作方法
本发明涉及对在聚合物(例如但不限于多核苷酸)相对于纳米孔易位期间从聚合物导出的信号的分析。
背景技术:
用于使用纳米孔估计聚合物中的聚合物单元的靶序列的测量系统是已知的,其中聚合物相对于纳米孔易位。系统的一些性质取决于纳米孔中的聚合物单元,并且进行所述性质的测量。性质取决于相对于纳米孔易位的聚合物单元的身份,并且因此,随时间变化的信号允许估计聚合物单元的序列。与孔的尺寸相比,每个聚合物单元可以非常小,从而允许多个聚合物单元在给定时间段内影响信号。由于聚合物链与纳米孔的相互作用、如缠绕或堆叠等链内性质或聚合物单元与用于控制其易位的任何系统之间的相互作用,也可以存在更长远的影响。信号形成必须被解码以估计潜在的聚合物单元的读段。
这种纳米孔测量系统可以提供表示范围为数百到数十万(并且可能更多)个核苷酸的多核苷酸的连续长读段的信号。使用纳米孔的这种类型的测量系统具有相当大的前景,特别是在对如dna或rna等多核苷酸进行测序的领域中,并且已经成为最近发展的主题。
然而,对聚合物单元的估计的准确度受到极其敏感的测量系统的限制。实际上,具有高准确度的估计需要机器学习技术,并且本发明涉及改善这种分析以增加估计准确度。
早期分析技术使用了隐马尔可夫模型(hiddenmarkovmodel,hmm),所述模型显式地对包括连续聚合物单元组的可能的k聚体进行建模。最近已经开发了使用递归神经网络(rnn)的技术。rnn的使用可以通过将远程信息考虑在内来提高准确度。随着读取速度的提高,rnn尤其有用,结果是像hmm等显式信号建模方法所基于的假设不那么有效。举例来说,teng等人,“手性子:使用深度学习将纳米孔原始信号直接翻译为核苷酸序列(chiron:translatingnanoporerawsignaldirectlyintonucleotidesequenceusingdeeplearning)”,《大数据科学(gigascience)》,2018年5月1日;7(5)[参考1]公开了使用向其输入原始信号的rnn对聚合物核苷酸进行测序的方法。rnn输出一系列后验概率分布,所述一系列后验概率分布包括关于表示四种可能类型的碱基以及空白的标签的后验概率。通过根据后验概率估计最可能的聚合物单元由链结式时间分类解码器对这些后验概率分布进行解码,以导出一系列聚合物单元的估计值。
技术实现要素:
根据本发明的第一方面,提供了一种分析在聚合物相对于纳米孔易位期间从所述聚合物导出的信号的方法,所述聚合物包括属于一组可能类型的聚合物单元的一系列聚合物单元,所述方法包括:使用输出一系列权重分布的机器学习技术来分析所述信号,每个权重分布包括关于一组标签上的标签之间的转换的权重,所述一组标签包含表示所述可能类型的聚合物单元的标签;以及从所述权重分布导出所述一系列聚合物单元的估计值。
所述一组标签可以包含表示空白和/或停留的标签。换句话说,可以说所述组表示可能类型的聚合物单元。
转换可以在一个标签与另一个标签之间。转换可以在连续的标签之间。
因此,所述方法提供的权重是指表示可能类型的聚合物单元,而不是表示包括k个聚合物单元的k聚体的标签。然而,所述方法导出关于标签之间的转换的权重,而不是关于标签本身的权重。此类方法提供了优于比较方法的优点,所述比较方法导出关于一组标签上的标签的一系列权重,所述一组标签包含表示可能类型的聚合物单元的标签。通过提供关于所述一组标签上的标签之间的转换的权重,提供了另外的信息,所述另外的信息允许以更准确的方式估计一系列聚合物单元。这是因为权重提供有关标签可能路径的信息,而关于标签的权重却不提供。
例如,存在以下情况:通过关于标签的权重预测的特定位置的标签不正确,而考虑通过所述位置的标签路径可能会预测出正确的不同标签。以此方式,另外的信息被馈送到估计值中,从而提高了准确度。
举例来说,此技术允许更好地估计重复序列的区域,例如均聚物,包含重复一个或多个聚合物单元的短序列的区域。
优选地,不允许标签之间的至少一个转换并且允许其它转换,所述权重分布各自包括关于被允许的转换的权重。在所述情况下,权重分布可以各自包括关于不被允许的转换的零权重,或者导出一系列聚合物单元的估计值的步骤可以考虑表示是否允许或不允许标签之间的转换的转换矩阵。
在一种类型的表示中,所述一组标签可以包含关于每种类型的聚合物单元的第一标签和第二标签,所述第一标签表示所述类型的聚合物单元的实例的开始,并且所述第二标签表示所述类型的聚合物单元的所述实例中的停留,其中允许任何其它类型的聚合物单元从每个第一标签转换到所述第一标签,允许相同类型的聚合物单元从每个第一标签转换到所述第一标签,允许相同类型的聚合物单元从每个第一标签转换到所述第二标签,不允许任何其它类型的聚合物单元从每个第一标签转换到所述第二标签,允许相同类型的聚合物单元从每个第二标签转换到所述第一标签或允许任何其它类型的聚合物单元从每个第二标签转换到所述第一标签,并且允许相同类型的聚合物单元从每个第二标签转换到所述第二标签,并且不允许任何其它类型的聚合物单元从每个第二标签转换到所述第二标签。
“停留”表示其中所述方法确定标签不发生变化的情况,可以将其视为对应于聚合物单元的相同实例的两个权重分布。
所述一组可能类型的聚合物单元可以包含总是以聚合物单元的已知序列出现的类型的聚合物单元,允许与所述已知序列一致的转换并且不允许与所述已知序列相反的转换。
所述一系列聚合物单元中的相同类型的聚合物单元的标签连续实例可以编码形式表示。
所述标签可以包含关于每种类型的聚合物单元的多个标签,例如两个标签,其中关于每种类型的聚合物单元的所述多个标签表示所述一系列聚合物单元中所述类型的聚合物单元的连续实例。
用于每种类型的聚合物单元的所述多个标签可以具有预先确定的循环顺序,由此通过所述预先确定的循环顺序允许标签之间的一些转换并且通过所述预先确定的循环顺序不允许之间的其它转换,所述权重分布包含关于通过所述预先确定的循环顺序允许的转换的权重。
所述一系列聚合物单元中的相同类型的聚合物单元的连续实例以游程长度编码形式表示。
所述标签可以包含关于每种类型的聚合物单元的不同游程长度的标签。
所述标签可以包含关于每种类型的聚合物单元的标签,并且对于每种类型的聚合物单元,所述权重分布可以包括在相同类型的聚合物单元的连续实例的可能长度上的另外的权重。
对于每种类型的聚合物单元,所述另外的权重可以包括在相同类型的聚合物单元的连续实例的一组可能长度上的权重的分类分布。
对于每种类型的聚合物单元,所述另外的权重可以包括在相同类型的聚合物单元的连续实例的连续实例的可能长度上的参数化分布的参数。
如果可能类型的聚合物单元包含具有未修饰形式和修饰形式的类型的聚合物单元,则所述一组标签可以包含表示具有未修饰形式和经修饰形式的所述类型的聚合物单元的标签,并且每个权重分布可以包括具有未修饰形式和经修饰形式的聚合物单元的所述至少一种类型中的每种的所述未修饰形式和经修饰形式的另外的权重。聚合物单元的未修饰形式可以描述为典型聚合物单元,并且聚合物单元的修饰形式可以描述为非典型聚合物单元。修饰(或非典型)聚合物单元通常影响与对应未修饰(典型)聚合物单元不同的信号。
在一些实施例中,可以制备和随后分析包括一个或多个非典型聚合物单元的聚合物,如在2019年9月4日提交的国际专利申请号pct/gb2019/052456中所详细描述的,对其进行引用并且通过引用并入本文。在一个实例中,可以不确定性的方式,例如通过化学转化或通过酶促转化,将一定比例的典型聚合物单元(例如,氨基酸)转化为对应的非典型聚合物单元(例如,氨基酸)。在所述情况下,当导出一系列聚合物单元的估计值(“调用”)时,可以将非典型碱基估计(“调用”)为对应的典型碱基。以此方式,通过在分析中将非典型聚合物单元识别为典型聚合物单元,初始转换可以提供一种提供具有更多信息的信号的方式,例如,结果是信号分析中出现的任何错误将是非系统性的,从而带来估计准确度的提高。
一组标签可以包含关于每种类型的聚合物单元的至少一个标签和关于一系列聚合物单元中的空白的至少一个标签。
机器学习技术可以是包括至少一个递归层的神经网络,所述递归层可以是双向递归层。
所述神经网络可以相对于通过所述一系列权重分布的所有路径应用所述权重分布的全局归一化。
所述神经网络可以包含多个卷积层,所述多个卷积层布置在所述递归层之前并且执行信号的加窗部分的卷积。
所述权重可以表示后验概率。
从所述权重分布导出所述一系列聚合物单元的估计值的步骤可以使用链结式时间分类执行。
从所述权重分布导出所述一系列聚合物单元的估计值的所述步骤可以包括导出关于每个权重分布的标签和对导出的标签进行游程长度压缩。
从所述权重分布导出所述一系列聚合物单元的估计值的步骤可以包括估计按所述权重分布计通过所述一系列权重分布的最可能标签路径,从被估计为最可能的所述标签路径导出所述一系列聚合物单元的所述估计值。
可替代地,从所述权重分布导出所述一系列聚合物单元的估计值的步骤可以包括估计关于每个权重分布最可能的所述标签、将通过所述一系列权重分布的前向和后向标签路径考虑在内,从被估计为最可能的所述标签导出所述一系列聚合物单元的所述估计值。
根据本发明的第二方面,提供了一种分析在聚合物相对于纳米孔易位期间从所述聚合物导出的信号的方法,所述聚合物包括属于一组可能类型的聚合物单元的一系列聚合物单元,所述方法包括:使用输出一系列权重分布的机器学习技术来分析所述信号,每个权重分布包括关于一组标签上的标签的权重,所述一组标签包含表示所述可能类型的聚合物单元的标签;以及从所述权重分布导出所述一系列聚合物单元的估计值,其中导出所述一系列聚合物单元的估计值的步骤将表示是否允许或不允许标签之间的转换的转换矩阵考虑在内,标签之间的至少一个转换被表示为不允许并且其它转换被表示为允许。
根据本发明的第三方面,提供了一种分析在聚合物相对于纳米孔易位期间从所述聚合物导出的信号的方法,所述聚合物包括属于一组可能类型的聚合物单元的一系列聚合物单元,所述方法包括:使用输出一系列权重分布的机器学习技术来分析所述信号,每个权重分布包括关于一组标签上的标签的权重,所述一组标签包含表示所述可能类型的聚合物单元的标签,其中所述一系列聚合物单元中的相同类型的聚合物单元的连续实例以游程长度编码形式表示;以及从所述权重分布导出所述一系列聚合物单元的估计值。
第一方面的任何特征可以以任何组合应用于本发明的第二方面和第三方面。
进一步地根据本发明,所述方法可以由在计算机设备中执行的计算机程序来实施,或者可以提供一种分析设备,所述分析设备被布置成实施与本发明的方面中的任何方面类似的方法。
更进一步地根据本发明,可以提供一种纳米孔测量和分析系统,其包括与测量系统组合的此类分析设备,所述测量系统被布置成在聚合物相对于纳米孔易位期间从聚合物导出信号。
附图说明
为了更好地理解,现在将参考附图通过非限制性实例的方式描述本发明的实施例,在附图中:
图1是纳米孔测量和分析系统的示意图;
图2是典型信号随时间变化的图;
图3是分析系统中的神经网络的图;
图4是信号的一部分的曲线图,其展示了神经网络的加窗部分的操作;
图5是rnn的递归层的图;
图6是非递归层的图;
图7是单向层的图;
图8是组合了“正向”和“反向”递归层的双向递归层的图;
图9是以交替方式组合了“正向”和“反向”递归层的替代性双向递归层的图;
图10是权重分布表,其中权重关于表示四种类型的多核苷酸的标签之间的转换;
图11是权重分布表,其中权重关于表示四种类型的多核苷酸和空白的标签之间的转换;
图12是权重分布表,其中权重关于表示五种类型的多核苷酸和空白的标签之间的转换,所述五种类型的多核苷酸之一是甲基化-c
图13是权重分布表,其中权重关于标签之间的转换,所述标签包含关于四种类型的多核苷酸中的每种的两个标签;
图14是权重分布表,其中权重使用正位-翻转(flip-flop)表示来表示均聚物;
图15是使用6聚体信号模型和相对于读头和系统其它组件的近似位置的四个碱基的剩余电流的图;
图16是权重分布表,其中权重使用游程长度编码的表示来表示均聚物;
图17是权重分布表,其中权重使用游程长度编码的表示的不同表达方式来表示均聚物;
图18是权重分布的另外的权重的表,所述权重分布表示对于每种可能类型的均聚物的一组可能长度上的分类分布;
图19是权重分布的另外的权重的表,所述权重分布表示对于每种可能类型的均聚物的可能长度上的参数化分布;
图20是由均值和方差参数的不同值表示的两个分布的图;
图21是可以用于表示均聚物的可能分布的表;
图22是权重分布的另外的权重的表,所述权重分布表示对于每种可能的聚合物单元对的一组可能长度上的分类分布;
图23是权重分布的另外的权重的表,所述权重分布表示对于每种可能的聚合物单元三联体的一组可能长度上的分类分布;
图24是权重分布表,其中一组标签被扩展以包含关于修饰聚合物单元的标签;
图25是用于呈因子分解修饰表示的类型的聚合物单元的未修饰形式和经修饰形式的另外的权重的表;
图26是5-碱基表示的信号和从其估计的聚合物单元的图;
图27是由神经网络的解码器执行的方法的流程图;并且
图28到30是不同解码算法的定义;
图31是另外的解码算法的定义;
图32是用于构建用于正位-翻转表示的目标转换矩阵的算法的定义;
图33是在所有路径上用于训练的目标函数的定义;
图34是用于构建用于多停留表示的目标转换矩阵的算法的定义;
图35是用于构建用于游程长度编码的表示的目标转换矩阵的算法的定义;
图36是信号和从其估计的聚合物单元的图,其展示了长均聚物的实例;
图37是对于最佳路径用于训练的目标函数的定义;
图38是函子的表;
图39是信号和从其估计的聚合物单元的图,其展示了使用锐化训练的正位-翻转表示的实例;并且
图40是展示了估计的一系列聚合物单元相对于参考的对准,以用于在没有和有锐化的情况下训练的表示的表。
具体实施方式
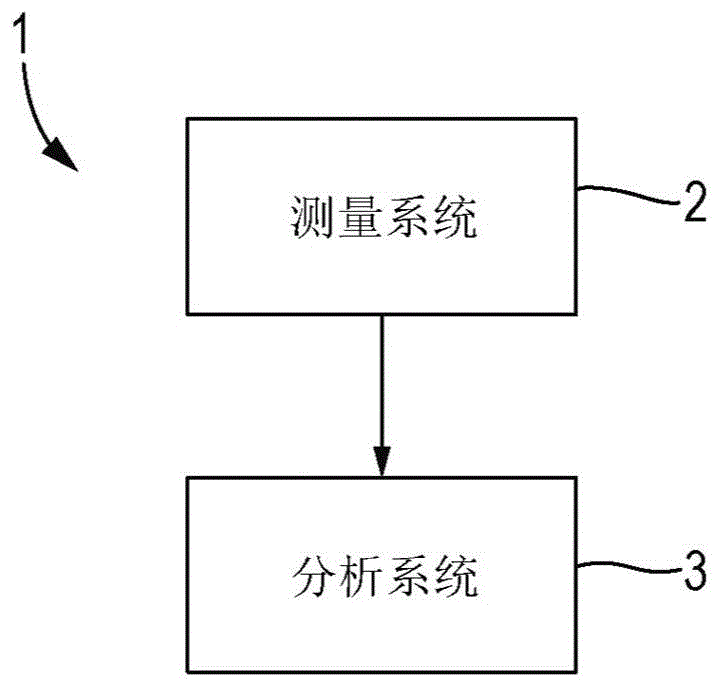
图1展示了包括测量系统2和分析系统3的纳米孔测量和分析系统1。测量系统2在聚合物相对于纳米孔易位期间从所述聚合物导出信号,所述聚合物包括一系列聚合物单元。分析系统3执行分析信号的方法,以导出一系列聚合物单元的估计值。
通常,聚合物可以是任何类型,例如多核苷酸(或核酸)、如蛋白质等多肽或多糖。聚合物可以是天然的或合成的。多核苷酸可以包括均聚物区域。均聚物区域可以包括5到15个核苷酸。
在多核苷酸或核酸的情况下,聚合物单元可以是核苷酸。核酸通常是脱氧核糖核酸(dna)、核糖核酸(rna)、cdna或本领域已知的合成核酸,如肽核酸(pna)、甘油核酸(gna)、苏糖核酸(tna)、锁核酸(lna)或具有核苷酸侧链的其它合成聚合物。pna主链由通过肽键连接的重复n-(2-氨基乙基)-甘氨酸单元构成。gna主链由通过磷酸二酯键连接的重复乙二醇单元构成。tna主链由通过磷酸二酯键连接在一起的重复苏糖构成。lna是由如上文所讨论的具有将核糖部分中的2'氧和4'碳连接的额外桥的核糖核苷酸形成。核酸可以是单链的、双链的或包括单链区域和双链区域两者。核酸可以包括与一条dna链杂交的一条rna链。通常,cdna、rna、gna、tna或lna均是单链的。
聚合物单元可以是任何类型的核苷酸。核苷酸可以是天然存在的或人工的。例如,所述方法可以用于验证制造的寡核苷酸的序列。核苷酸通常含有核碱基、糖和至少一个磷酸基。核碱基和糖形成核苷。核碱基通常是杂环的。合适的核碱基包含嘌呤和嘧啶,以及更具体地,腺嘌呤、鸟嘌呤、胸腺嘧啶、尿嘧啶和胞嘧啶。糖通常是戊糖。合适的糖包含但不限于核糖和脱氧核糖。核苷酸通常是核糖核苷酸或脱氧核糖核苷酸。核苷酸通常含有单磷酸、二磷酸或三磷酸。
核苷酸可以是修饰的碱基,如受损的碱基或表观遗传的碱基。例如,核苷酸可以包括嘧啶二聚体。此类二聚体通常与紫外光引起的损坏相关联并且是皮肤黑色素瘤的主要病因。核苷酸可以被标记或修饰以充当具有不同信号的标记物。这一技术可用于识别碱基的缺失,例如多核苷酸中的脱碱基单元或间隔基。所述方法也可以应用于任何类型的聚合物。
在多肽的情况下,聚合物单元可以是天然存在的或合成的氨基酸。
在多糖的情况下,聚合物单元可以是单糖。
特别是在测量系统2包括纳米孔且聚合物包括多核苷酸的情况下,多核苷酸可以是长的,例如至少5kb(千碱基),即至少5,000个核苷酸;或至少30kb(千碱基),即至少30,000个核苷酸;或至少100kb(千碱基),即至少100,000个核苷酸。
测量系统2的性质和所得信号如下。
测量系统2是包括一个或多个纳米孔的纳米孔系统。在简化类型中,测量系统2仅具有单个纳米孔,但是更实际的测量系统2通常在阵列中采用许多纳米孔,以提供并行的信息收集。
通常通过纳米孔可以在聚合物相对于纳米孔易位期间记录信号。
纳米孔是通常具有纳米级大小的孔,其可以允许聚合物通过其中。
纳米孔可以是蛋白孔或固态孔。孔的尺寸可以使得一次仅有一种聚合物可以使孔易位。
在纳米孔是蛋白孔的情况下,其可以具有以下性质。
生物孔可以是跨膜蛋白孔。用于根据本发明使用的跨膜蛋白孔可以源自β桶孔或α螺旋束孔。β桶孔包括由β链形成的桶或通道。合适的β桶孔包含但不限于:β-毒素,如α-溶血素、炭疽毒素和杀白细胞素;以及细菌的外膜蛋白/孔蛋白,如耻垢分枝杆菌孔蛋白(msp),例如mspa、mspb、mspc或mspd、胞溶素、外膜孔蛋白f(ompf)、外膜孔蛋白g(ompg)、外膜磷脂酶a和奈瑟氏菌属自转运蛋白脂蛋白(nalp)。α螺旋束孔包括由α螺旋形成的桶或通道。合适的α螺旋束孔包含但不限于内膜蛋白和α外膜蛋白,如wza和clya毒素。跨膜孔可以源自msp或来自α-溶血素(α-hl)。跨膜孔可以源自胞溶素。wo2013/153359中公开了源自胞溶素的合适的孔。wo-2012/107778中公开了源自mspa的合适的孔。孔可以源自如wo-2016/034591中所公开的csgg。孔可以是dna折纸孔。
蛋白孔可以是天然存在的孔或可以是突变孔。典型的孔描述于以下中:wo-2010/109197;stoddartd等人,《美国国家科学院院刊(procnatlacadsci)》,12;106(19):7702-7;stoddartd等人,《应用化学国际英文版(angewchemintedengl.)》2010;49(3):556-9;stoddartd等人,《纳米快报(nanolett.)》2010年9月8日;10(9):3633-7;butlertz等人,《美国国家科学院院刊》2008;105(52):20647-52;以及wo-2012/107778。
蛋白孔可以是wo-2015/140535中描述的类型的蛋白孔之一并且可以具有其中所公开的序列。
可以将蛋白孔插入到如生物膜等两亲层例如脂质双层中。两亲层是由具有亲水性和亲脂性两者的如磷脂等两亲分子形成的层。两亲层可以是单层或双层。两亲层可以是gonzalez-perez等人,《朗缪尔(langmuir)》,2009,25,10447-10450或wo2014/064444中所公开的共嵌段聚合物。可替代地,例如,如wo2012/005857中所公开的,可以将蛋白孔插入到固态层中设置的孔中。
wo-2014/064443中公开了用于提供纳米孔阵列的合适的设备。纳米孔可以跨相应的孔提供,其中电极设置在每个相应的孔中,与asic电连接,以便测量流过每个纳米孔的电流。合适的电流测量设备可以包括如wo-2016/181118中所公开的电流感测电路。
纳米孔可以包括形成在固态层中的孔,其可以被称为固态孔。孔可以是固态层中提供的阱、间隙、通道、沟槽或狭缝,分析物可以通过或进入所述固态层。这种固态层不是生物来源的。换言之,固态层不是从生物环境(如生物体或细胞)或合成制造形式的生物学可用结构中产生的,也不是从其中分离出来的。固态层可以由有机材料和无机材料形成,所述材料包含但不限于:微电子材料、如si3n4、a1203和sio等绝缘材料、如聚酰胺等有机聚合物和无机聚合物、如
这种固态孔通常是固态层中的孔。可以通过化学方法或其它方式对孔进行修饰,以增强其作为纳米孔的性质。固态孔可以与提供聚合物的替代性或另外的测量结果的另外的组分结合使用,如隧穿电极(ivanovap等人,《纳米快报》2011年1月12日;11(1):279-85),或场效应晶体管(fet)装置(例如在wo-2005/124888中所公开的)。可以通过已知方法形成固态孔,所述已知方法包含例如wo-00/79257中描述的方法。
纳米孔可以是固态孔与蛋白孔的混合体。
测量系统2进行一系列的性质测量,所述性质取决于相对于孔易位的聚合物单元。一系列测量形成信号。
所述测量的性质可能与聚合物和孔之间的相互作用相关。这种相互作用可以发生在孔的收缩区域。
在一种类型的测量系统2中,所测量的性质可能是流过纳米孔的离子电流。这些或其它电性质可以使用标准单通道记录设备来测量,如下所述:stoddartd等人,《美国国家科学院院刊》,12,106(19):7702-7;liebermankr等人,《美国化学会志(jamchemsoc.)》2010;132(50):17961-72以及wo-2000/28312。可替代地,电性质的测量可以使用例如,如wo-2009/077734、wo-2011/067559或wo-2014/064443中所描述的多通道系统来进行。
可以在膜或固态层的任一侧提供离子溶液,所述离子溶液可以存在于相应的隔室中。可以向膜的一侧添加含有所关注的聚合物分析物的样品并允许其相对于纳米孔移动,例如在电势差或化学梯度下。信号可以在聚合物相对于孔移动期间导出,例如在聚合物通过纳米孔易位期间进行的。聚合物可以部分地使纳米孔易位。
为了在聚合物易位通过纳米孔时进行测量,可以通过聚合物结合部分控制易位速率。通常,所述部分可以使聚合物与施加的场一起或相对于施加的场移动通过纳米孔。所述部分可以是分子马达,在所述部分是酶的情况下,所述分子马达使用例如酶活性或作为分子刹车。在聚合物是多核苷酸的情况下,提出了许多用于控制易位速率的方法,包含使用多核苷酸结合酶。用于控制多核苷酸易位速率的合适的酶包含但不限于聚合酶、解旋酶、外切核酸酶、单链和双链结合蛋白以及拓扑异构酶(如旋转酶)。对于其它聚合物类型,可以使用与所述聚合物类型相互作用的部分。聚合物相互作用部分可以是以下文献中所公开的任何:wo-2010/086603、wo-2012/107778和liebermankr等人,《美国化学会志》2010;132(50):17961-72,并且用于电压门控方案(luanb等人,《物理评论快报(physrevlett.)》2010;104(23):238103)。
可以以多种方式使用聚合物结合部分来控制聚合物运动。所述部分可以使聚合物与施加的场一起或相对于施加的场移动通过纳米孔。所述部分可以用作分子马达,在所述部分是酶的情况下,所述分子马达使用例如酶活性或作为分子刹车。可以通过控制聚合物通过孔的移动的分子制动器来控制聚合物的易位。分子制动器可以是聚合物结合蛋白。对于多核苷酸,多核苷酸结合蛋白优选地是多核苷酸处理酶。多核苷酸处理酶是能够与多核苷酸相互作用并且修饰其的至少一个性质的多肽。酶可以通过切割多核苷酸以形成单独的核苷酸或较短核苷酸链如二核苷酸或三核苷酸来对多核苷酸进行修饰。所述酶可以通过将多核苷酸朝向或使其移动到特定位置来对多核苷酸进行修饰。多核苷酸操作酶并不需要显示酶活性,只要其能够结合靶多核苷酸并且控制其移动通过孔即可。例如,可以对酶进行修饰以移除其酶活性或可以在防止其充当酶的条件下使用。下文更详细地论述了此类条件。
优选的多核苷酸处理酶是聚合酶、外切核酸酶、解旋酶和拓扑异构酶(如旋转酶)。核苷酸处理酶可以是例如wo-2015/140535或wo-2010/086603中描述的一种类型的多核苷酸处理酶。
聚合物通过纳米孔的易位可以按以下方式发生:顺式到反式或反式到顺式,与施加的电势一起或相对于施加的电势。可以在施加的电势下发生易位,所述施加的电势可以控制易位。
在双链dna上逐渐或逐步起作用的外切核酸酶可以在孔的顺式侧使用,以在施加的电势下供给剩余的单链或在反向电势下供给反式侧。同样,使双链dna解旋的解旋酶还可以以类似的方式使用。还存在需要抵抗所施加的电势的链易位的测序应用的可能性,但是dna必须首先在相反或无电势下由酶“捕获”。随着电势随后在结合后转回,链将以顺式到反式的方式穿过孔并且通过电流保持处于延长的构型。单链dna外切核酸酶或单链dna依赖性聚合酶可以充当分子马达,所述分子马达将最近易位的单链以逐步受控方式(反式到顺式,相对于施加的电势)牵拉回孔中。可替代地,单链dna依赖性聚合酶可以充当减慢多核苷酸通过孔的移动的分子刹车。可以使用wo-2012/107778或wo-2012/033524中描述的任何部分、技术或酶来控制聚合物运动。
然而,测量系统2可以是包括一个或多个纳米孔的替代性类型。
类似地,所测量的性质可以是离子电流以外的类型。替代性性质的一些实例包含但不限于:电性质和光学性质。涉及荧光测量的合适的光学方法公开于《美国化学会志》2009,1311652-1653。可能的电性质包含:离子电流、阻抗、隧穿性质,例如隧穿电流(例如,如公开于以下中:ivanovap等人,《纳米快报》2011年1月12日;11(1):279-85)和fet(场效应晶体管)电压(例如,如公开于wo2005/124888中)。可以使用一种或多种光学性质,任选地与电性质组合(sonigv等人,《科学仪器综述(revsciinstrum.)》2010年1月;81(1):014301)。所述性质可以是跨膜电流,如流过纳米孔的离子电流。离子电流通常可以是dc离子电流,但是原则上替代方案使用ac电流(即,在施加ac电压下流动的ac电流的大小)。
在一些类型的测量系统2中,所述信号可以被表征为包括来自一系列事件的测量结果,其中每个事件提供一组测量结果。图2展示了在电流测量的情况下此类信号10的典型实例。来自每个事件的测量结果组具有类似的水平,但是存在一些差异。这可以被认为是噪声步波,其中每个步与事件相对应。事件可以具有生物化学意义,例如由测量系统2的给定状态或相互作用引起。在某些情况下,这可能是由于以制动方式发生的聚合物通过纳米孔的易位引起的。然而,并非所有类型的测量系统都产生这种类型的信号,并且本文所描述的方法不取决于信号的类型。例如,当易位速率接近测量采样速率(例如,以聚合物单元的易位速率的1倍、2倍、5倍或10倍的速率获取测量结果)时,与较慢的测序速度或较快的采样速率相比,事件可能不那么明显或不存在。
另外,在存在事件的情况下,通常不存在组中测量结果的数量的先验知识,所述数量不可预测地变化。这些变化因素和缺乏对测量结果数量的了解可能使得难以区分一些组,例如在组是短的和/或两个连续组的测量结果水平彼此接近的情况下。
与每个事件相对应的测量结果组通常具有在事件的时间尺度上一致的水平,但是对于大多数类型的测量系统2将在短时间尺度上发生变化。这种变化可能由测量噪声引起,例如由电路和信号处理产生,特别是在电生理学的特定情况下来自于放大器。由于测量小幅度的性质,这种测量噪声是不可避免的。这种变化还可能由测量系统2的基础物理或生物系统中的固有变化或扩散引起,例如可能由聚合物的构型变化引起的相互作用的变化。
大多数类型的测量系统2将在更大或更小的程度上经历这种固有的变化。对于任何给定类型的测量系统2,两种变化源都可能有所贡献,或者这些噪声源中的一个可能占主导地位。
随着测序速率(即聚合物单元相对于纳米孔易位的速率)的增加,那么事件可能变得不那么明显,并因此更难鉴定或可能消失。因此,随着测序速率的增加,依赖于检测此类事件检测的分析方法可能变得更低效。
然而,本文所公开的方法不依赖于检测此类事件。下文所描述的方法即使在相对高的测序速率下也是有效的,所述相对高的测序速率包含测序速率,在所述测序速率下,聚合物以每秒至少10个聚合物单元,优选地每秒100个聚合物单元,更优选地每秒500个聚合物单元或更优选地每秒1000个聚合物单元的速率易位。
采样速率是信号中的测量速率。通常,采样速率高于测序速率。例如,采样速率可以在100hz到30khz的范围内,但这不是限制性的。实际上,采样速率可以取决于测量系统2的性质。
在一些情况下,所述方法可以使用多个系列的测量结果,所述多个系列的测量结果是相关的一系列聚合物单元的测量结果。例如,所述多个系列的测量结果可以是具有相关序列的分离的聚合物的一系列测量结果,或者可以是具有相关序列的相同聚合物的不同区域的一系列测量结果。
在多核苷酸的情况下,所述多个系列的聚合物单元可以通过互补而相关,使得一个系列的聚合物单元被称为模板,并且另一系列的与其互补的聚合物单元被称为补体。在这种情况下,可以使用任何合适的技术来测量模板和补体,例如使用多核苷酸结合蛋白或通过多核苷酸样品制备顺序地进行。合适的方法包含wo-2010/086622或wo-2013/014451中描述的那些方法。
例如,通过使用wo-2010/086622或wo-2013/014451中描述的方法,本文所公开的涉及单个系列的聚合物单元的方法中的任何方法可以应用于所述多个系列的测量结果,如模板和补体。
一系列测量结果形成被分析系统3分析的原始信号。原始信号可以在供应给分析系统2之前在测量系统2中进行预处理,或者作为分析系统3中的初始阶段进行预处理,例如经过滤波以减少噪声。在此类情况下,将对预处理的信号执行以下分析。
分析系统3可以与测量系统2物理相关,并且还可以向测量系统2提供控制信号。在所述情况下,可以如wo-2008/102210、wo-2009/07734、wo-2010/122293、wo-2011/067559或wo2014/04443中任一个所公开的布置包括测量系统2和分析系统3的纳米孔测量和分析系统1。
可替代地,可以在单独的设备中实施分析系统3,在这种情况下,通过任何合适的装置(通常是数据网络)将所述一系列测量结果从测量系统2传送到分析系统3。例如,一种方便的基于云的实施方案是将分析系统3作为服务器,通过互联网向其提供输入信号11。
分析系统3可以由执行计算机程序的计算机设备实施,或者可以由专用硬件装置或其任何组合实施。在任一种情况下,所述方法使用的数据储存在分析系统3的存储器中。
在计算机设备执行计算机程序的情况下,计算机设备可以是任何类型的计算机系统,但通常是常规结构。可以用任何合适的编程语言编写计算机程序。计算机程序可以储存在任何类型的计算机可读存储介质上,例如:可插入到计算系统的驱动器中并且可以磁性地、光学地或光磁地储存信息的记录介质;计算机系统的固定记录介质,如硬盘驱动器;或计算机存储器。
在计算机设备由专用硬件装置实施的情况下,可以使用任何合适类型的装置,例如fpga(现场可编程门阵列)或asic(专用集成电路)。在优选的实施例中,可以使用如图形处理单元(gpu)等适于并行化计算的硬件来实施计算机程序的各部分。
如下执行使用纳米孔测量和分析系统1的方法。
首先,使用测量系统2导出信号10。例如,使聚合物相对于孔(例如,通过孔)易位,并且在聚合物易位期间导出信号。可以通过提供允许聚合物易位的条件使聚合物相对于孔易位,因此易位可以自发发生。在易位期间,导出信号10。
其次,分析系统3执行分析信号10的方法,现在将要对其进行描述。
分析系统3使用神经网络20分析信号。神经网络20的参数在下文进一步描述的训练期间取值,并且因此递归神经网络不依赖于具有任何特定形式的测量结果或具有任何特定性质的测量系统2。例如,递归神经网络不依赖于取决于包括k个连续聚合物单元的k-聚体的测量结果。
合适的神经网络20的实例示出在图3中并且包含加窗单元30,cnn(卷积神经网络)40、rnn(递归神经网络)50和解码器80,它们依次对信号进行如下处理。
加窗单元30使信号10加窗,以导出信号10的连续加窗部分31,例如,如图4所展示的。加窗部分11被供应给cnn40。
加窗部分31具有长度32,以及在连续加窗部分31之间的步幅33,这两者都可以在时间上或在信号10的样品数上进行计数。步幅33可以是单个样品或多个样品。如果步幅33是单个样品,则忽略边缘效应,存在与信号10中的样品相同数量的加窗部分31。如果步幅33大于单个样品,则加窗单元30执行下采样并且存在比信号10中的样品少的加窗部分31。通常,步幅33小于长度33,使得加窗部分10在信号10中重叠。
举例来说,长度32可以是4.75毫秒,并且步幅可以是0.5毫秒。
通过另外的实例,长度可以是19个样品,并且步幅可以是2个样品。
cnn40包括至少一个卷积层。至少一个卷积层对每个加窗部分11执行卷积,以导出关于每个加窗部分31的特征向量41。不管信号中是否可能出现任何事件,都可以这样做,并且因此同样适用于此类事件明显或不明显的情况下的信号,或在预处理期间提供事件的情况下的信号。特征向量41被供应给rnn50。
cnn40与rnn50一起训练,如下文所讨论的。
cnn40可以采用任何形式。
在一个实例中,cnn40可以是单个卷积层,由具有权重w和偏差b以及激活函数g的仿射变换定义。在本文中,it-j:t+k表示包括含有t-j到t+k测量结果的原始信号20的测量结果窗口,并且ot是输出特征向量。
yt=ait-j:t+k+b仿射变换
ot=g(yt)激活
双曲正切是合适的激活函数,但是本领域已知更多的替代方案,包含但不限于:整流线性单元(relu)、指数线性单元(elu)、softplus单元和s形单元。也可以使用多个卷积层。
在另一个实例中,cnn40可以采用与参考1中的cnn相同的形式。
如所描述的,直接卷积网络的缺点在于,原始信号中检测到的特征的确切位置存在依赖性,并且这也意味着对特征之间的间隔的依赖性。通过将由第一个卷积产生的特征向量的输出序列用作对输入的阶统计量起作用的第二个“合并”网络中的输入,可以减轻依赖性。
举例来说,在合并网络是单层神经网络的情况下,以下等式描述了输出如何与输入向量相关。将f设置为输入特征的指数,所以af是特征f的权重矩阵,并且将
这种层的一个有用的且计算上有效的实例是返回特征向量,所述特征向量与输入特征的数量相同,其元素是针对每个相应特征获得的最大值。将函子
由于矩阵uf非常稀疏,出于计算效率的原因,可以隐式地执行矩阵乘法:在本文中,σfufxf的作用是将输出特征向量的元素f设置为xf。
可以仅针对每第n个位置(n的步幅)计算它们的输出并且因此对它们的输出进行下采样来执行卷积和/或合并。从计算角度来看,下采样可能是有利的,因为网络的其余部分必须处理更少的块(更快的计算)以实现类似的准确度。
添加卷积层的堆栈解决了上文所描述的许多问题:通过卷积学习的特征检测既可以作为纳米孔特有的特征检测器,也可以作为汇总统计,而无需对系统做任何另外的假设;特征不确定性通过不同特征的相对权重传递到网络的其余部分,并且因此进一步处理可以将这一信息考虑在内,从而导致更精确的预测和对不确定性的量化。
rnn50输出一系列权重分布。rnn50包括至少一个递归层52,所述递归层或每个递归层之后是前馈层53。图5展示了单个递归层52的情况下的rnn,但是通常可以存在任何多数量的递归层52和随后的前馈层53。这提供了单元架构的灵活选择。所述层可以具有不同的参数,可以具有不同的大小,或者甚至可以由不同的单元类型组成。
所述递归层或每个递归层52优选地是双向的,以允许每个输入特征向量的影响在两个方向上通过rnn传播。替代性优选的实施例包括在交替方向上布置的多个单向递归层,例如在反向、正向、反向、正向、反向的连续方向上布置的层。这些双向架构允许rnn50以hmm不可用的方式来累积和传播信息。递归层的另外的优点是,它们不需要精确的信号缩放来建模(反之亦然),例如通过迭代程序。
对于前馈层53中的下采样,将单独的仿射变换应用于每列的前向和后向层的输出向量,然后进行求和;这相当于将仿射变换应用于由输入和输出的串联形成的向量。然后,逐个元素地将激活函数应用于所得矩阵。
递归层52可以使用几种类型的神经网络单元,现在将要对其进行描述。单元类型分为两大类,取决于其是否是“递归的”。虽然非-递归单元独立地处理序列中的每个步,但是递归单元被设计成在序列中使用并且将状态向量从一个步传递到下一个步。
为了示意性地示出非递归单元与递归单元之间的差异,图6示出了非递归单元61的非递归层60并且图7到9示出了相应非递归单元64到66的三个不同层62到64。在图6到9的每个图中,箭头示出了向量通过的连接,被分割的箭头是复制的向量并且被组合的箭头是串联的向量。
在图6的非递归层60中,非递归单元61具有不进行分割或串联的单独的输入和输出。
图7的递归层62是单向递归层,其中递归单元65的输出向量被分割并单向传递到递归层中的下一个递归单元65。
虽然图8和图9的双向递归层63和64本身不是分立单元,但其各自具有分别由更简单的递归单元66和67制成的重复单元状结构。
在图8的双向递归层63中,双向递归层63由递归单元66的两个子层68和69组成,它们是具有与图7的单向递归层62相同的结构的前向子层68和具有与图7的单向递归层62相反的结构的后向子层69,好像时间被反转,从而将状态向量从一个单元66传递到前一单元66。前向子层68和后向子层69二者均接收相同的输入,并且其来自于对应单元66的输出被串联在一起以形成双向递归层63的输出。注意,前向子层68内的任何单元66与后向子层69内的任何单元之间不存在串联。
类似地,图9的替代性双向递归层64由递归单元67的两个子层70和71组成,它们是具有与图7的单向递归层62相同的结构的前向子层68和具有与图7的单向递归层62相反的结构的后向子层69,好像时间被反转。再次,前向子层68和后向子层69接收相同的输入。然而,与图8的双向递归层63相反,前向子层68的输出是后向子层69的输入并且后向子层69的输出形成双向递归层64的输出(前向子层68和后向子层69可以反转)。
图9中所示的双向递归层64的一般化将是由多个“前向”和“后向”递归子层组成的递归层的堆栈,其中每层的输出是下一层的输入。
rnn50的双向递归层52可以采用图8和9的双向递归层63和64中的任一个的形式。通常,图3的双向递归层34可以由非递归层(例如,图6的非递归层60)或由单向递归层(例如,图7的递归层62)代替,但通过使用双向递归层34实现了改善的性能。
现在将描述前馈层53。
前馈层53包括处理相应向量的前馈单元54。前馈单元54是经典神经网络中的标准单元,即,将仿射变换应用于输入向量并且然后逐元素地应用非线性函数。前馈层53均使用非线性函数的双曲正切,但是可以使用许多其它内容,而在网络的总体准确度上几乎没有变化。
如果步t处的输入向量是it,并且仿射变换的权重矩阵和偏差分别为a和b,则输出向量ot为:
yt=ait+b仿射变换
ot=tanh(yt)非线性度
将rnn50的权重分布全局归一化。在下文中更详细地论述这一点。
非递归单元62和递归单元65到67独立地处理每个事件,但是可以由具有现在将描述的形式的长短期记忆单元代替。
长短期记忆(lstm)单元在以下文献中被引入:hochreiter和schmidhuber,《长短期记忆(longshort-termmemory)》,《神经计算(neuralcomputation)》,9(8):1735–1780,1997。lstm单元是递归单元,并且因此将状态向量从序列中的一步传递到下一步。lstm基于单元是存储器单元的符号:将含有存储器内容的隐藏状态从一步传递到下一步,并通过一系列控制存储器更新的门来对所述隐藏状态进行操作。一个门控制是否擦除(遗忘)存储器的每个元素,另一个门控制是否由新值替换,并且最终门测定是否从存储器读取和输出。概念计算机存储器单元的二进制开/关逻辑门由s形函数产生的概念概率代替并且存储器单元的内容代表预期值,这使得存储器单元是可微分的。
首先描述了lstm的标准实施方案,并且然后描述基本方法中实际使用的“窥视孔”修改。
标准lstm如下。
与对lstm单元的不同操作相关联的概率由以下方程组定义。将it设置为步骤t的输入向量,ot为输出向量,并将由x指数化的仿射变换设置为具有偏差bx和分别用于输入和先前输出的权重矩阵wxi和wxo;σ是非线性s形变换。
给定上文定义的更新向量并设置_运算符表示逐元素(hadamard)乘法,则用于更新内部状态st和测定新输出的等式是:
窥视孔修改如下。
“窥视孔”修改(gers和schmidhuber,2000)为lstm架构添加了一些另外的连接,所述架构允许遗忘概率、更新概率和输出概率“窥视”存储器单元的隐藏状态(或由其通知)。网络的更新等式如上所述,但将px设置为长度等于隐藏状态的“窥视”向量,概率向量的三个等式变为:
非递归单元62和递归单元65到67可以可替代地由具有如下形式的门控递归单元代替。
已经发现门控递归单元(gru)运行得更快,但最初发现其产生较差的准确度。gru的架构不像省去隐藏状态与输出之间的分离并且还组合了“遗忘”和“输入门”的lstm那样直观。
虽然存在与事件相同数量的列输出,但假设用网络输入中的单个事件鉴定每列是不正确的,因为由于双向层的存在,每列的内容可能由整个输入事件集通知。输入事件与输出列之间的任何对应关系都是通过用训练集中的符号对其进行标记来实现的。
在另一个实例中,rnn50可以采用与参考1中的rnn相同的形式。
现在将讨论由rnn50输出的一系列权重分布51。
输出关于连续的时间步长的权重分布51,以形成一系列的权重分布。时间步长原则上可以与信号10的样品周期具有相同的长度,但是由于神经网络20中的过采样,所述时间步长通常比信号10的样品周期更长。然而,时间步长是规则的长度,例如对应于加窗单元30的步幅13,这与执行事件调用的系统相反,并且因此连续权重分布51之间的时间步长对应于可变的连续检测到的事件的长度。
通常,权重分布51以比连续的聚合物单元相对于纳米孔易位的速率更高的速率输出,即,权重分布51比聚合物单元多。与所述系列中的每个聚合物单元相对应的多个权重分布51是先验未知的。
每个权重分布51包括多个权重。所述权重表示后验概率。权重可以是实际的后验概率,或更通常地,可以是不是实际概率但仍然表示后验概率的权重。通常,在权重不是实际概率的情况下,原则上可以根据权重的归一化确定后验概率。
rnn50输出关于一组标签上的标签之间的转换的权重,所述一组标签包含表示可能类型的聚合物单元的标签。因此,关于转换的权重表示那些转换的后验概率。因为权重分布51比聚合物单元多,所以要理解,在一些表示中,允许从标签到相同标签的转换,并且因此权重分布51包含关于这种转换的权重,即单词“转换”既不意味着必须更改标签,也不意味着必须发出另外的聚合物单元。
下文给出由rnn50输出的权重分布51的各个实例。这些实例中的每个是指聚合物单元是多核苷酸并且聚合物单元的类型是四个碱基a,c,g和t的情况。如上文所讨论的,本发明方法同样适用于更多类型的多核苷酸和/或非核苷酸的聚合物单元,因此可以相应地概括这些实例。在所述实例的每个中,权重分布51包含表示标签之间的转换的权重。因此,权重被标记为wij,其中i是从其进行转换的标签的指数,并且j是转换进行到的标签的指数。因此权重wij是从标签i到标签j转换的权重。在附图中的每个中,行对应于从其发生转换的标签i,并且列对应于转换到其的标签j。
这种配置的一个实例是在其输出(最终)层中配置有等于要产生的权重分布中的权重数的数量的前馈元素的rnn。图7-9还提供了示出了来自rnn单元的许多输出的实例;应当理解,在rnn内可以存在这些配置中的任何一个或多个,使得输出的数量等于要产生的权重分布中的权重的数量。
图10和11示出了可以由rnn50输出的权重分布51的两个实例。
在图10的实例中,关于示出为a、c、g和t的四个碱基,存在单个标签。允许所有转换,因此关于从标签中的每个到标签中的每个的16个转换总共存在十六个权重wij。
图10的实例没有提供均聚物的良好表示,所述均聚物是一系列聚合物单元内的相同类型的多个聚合物单元的连续。这是因为从标签到相同标签的转换不能区分给定类型的聚合物单元的相同实例和给定类型的聚合物单元的另外的实例。结果,从标签到相同标签的一系列转换表示一系列任何数量(一个或多个)的聚合物单元(即,具有任何长度的单个聚合物单元和相同类型的聚合物单元的均聚物两者)的实例。
然而,图11是通过扩展图10的表示改善均聚物的表示的实例,使得所述一组标签包含(i)单个标签,每个标签表示四个碱基中的一个不同碱基,以及(ii)表示一系列聚合物单元中空白的标签。在图11的实例中示出了所有允许的转换,因此关于从标签中的每个到标签中的每个的25个转换,总共有25个权重wij。在此表示中,空白标签表示所述系列中的碱基(聚合物单元)的两个实例之间的分隔,即使所述实例是相同类型。
换句话说,在聚合物单元的序列中,可能的情况是分析了数据测量的窗口,但在所述数据窗口中不存在聚合物单元之间的转换。在此情况下,转换可以表示为从先前标签到“空白”标签的转换,这表示没有新的聚合物单元的实例转换到窗口中。
在一些实施例中,可以将空白视为强制性的,因为在确定的聚合物单元序列中必须存在空白,以便将空白任一侧上的聚合物单元视为单独的聚合物单元。例如,在以下生成的标签序列的情况中,空白用“-”表示:aaa--a,这将解析为聚合物单元的实际序列=aa。“a”标签的前三个实例中的每个被视为相同的实际聚合物单元“a”的实例,而最后一个“a”标签被视为不同的,因为它与前三个“a”之间用两个空白标签隔开。
在一些实施例中,空白可以被视为任选的,因为空白表示聚合物单元与标签的重复之间的间隔子。例如,在以下生成的标签序列的情况中,空白用“-”表示:aaa--a,这将解析为聚合物单元的实际序列=aaaa。“a”标签的前三个实例中的每个被视为不同的聚合物单元,并且空白标签充当这些单元与最终“a”标签之间的间隔子。
在rnn50输出中使用关于标签之间的转换的权重的此表示与参考1形成对比,其中rnn输出关于一组标签上的标签的后验概率(权重的特定实例),所述一组标签由表示四种类型的多核苷酸(即碱基c、g、a和t)中的每一种的四个标签和表示空白的标签组成。使用关于标签之间的转换的权重的表示优于使用关于标签的权重的表示,因为提供了另外的信息,所述信息提高了估计一系列聚合物单元的准确度。这是因为配重提供了关于通过一系列聚合物单元的可能路径的信息,而出于进一步分析的目的,关于标签本身的权重会丢失关于与其它标签的关系的信息。因此,将另外的信息提供给估计聚合物单元的步骤,这提高了解码的准确度。
另外,所述表示允许表示允许和不允许的转换。即,标签可以不允许标签之间的转换中的一个或多个转换并且允许其它转换的方式表示可能类型的聚合物单元。在所述情况下,权重分布51包括关于被允许的转换的权重。所述权重分布51可以包括关于不被允许的转换的零权重。
零权重可以是在由rnn50输出的权重分布51中不存在权重。在附图所示出的实例中,通过不存在权重来展示零权重,但是可以替代地应用下文的替代方案。
可替代地,零权重可以是存在于由rnn50输出的权重分布51中的权重,以易于实施rnn50,但是具有标称值。此类标称值可以是具有零值或无关紧要大小的值,使得所述标称值确实影响由解码器80执行的估计,如下文所描述的。可替代地,此类标称值可以是存在于由rnn输出的权重分布51中但被解码器80忽略的值,例如通过使用如下文所描述的转换矩阵。
这一点的一些实例如下。
发生允许的转换和不允许的转换的第一实例是一组可能类型的聚合物单元包含总是以聚合物单元的已知序列出现的类型的聚合物单元。在此情况下,允许与已知序列相一致的转换,并且不允许与已知序列相反的转换。对于多核苷酸,这样的实例是,脊椎动物中的5-甲基胞嘧啶仅出现在鸟嘌呤之前的胞嘧啶(“cpg”)上,并且这可以用于进一步限制可能的转换,并且因此,需要来自rnn50的较少权重。即,cpg甲基化导致甲基化c(其在本文中将表示为cm)始终在g之前,因此cm始终以已知序列cmg出现。图12是用于表示这一点的权重分布51的实例。权重分布51改编自图11的权重分布,以将表示甲基化c的标签添加到表示四种类型的多核苷酸(即,碱基c、g、a和t)的四个标签和表示空白的标签。在此情况下,不允许从cm到a、c或t的转换,因此,对于这些转换,存在零权重,即权重分布中的权重w61、w62和w64为零。这使rnn提供有关甲基化c碱基的更好信息,从而提高了对甲基化c碱基的估计的准确度。
任选地,从cm到cm的转换的权重可以为零。这可以是在停留的情况下。这是因为尽管可以在测量期间将其鉴定出来,但由于cpg甲基化导致甲基化c总是在g之前,即序列cmg,所述转换不形成序列的一部分。这一点的另外的实例是下文所描述的正位-翻转表示,其中允许从经修饰正位或经修饰翻转到鸟嘌呤或经修饰翻转标签的转换,从而将rnn50所需的权重数从60减少到52(参考:所有可能的转换需要100个权重)。除了减少所需的网络输出量之外,将转换限制到可能的转换防止所述方法在不可能的背景中产生带有修饰的类型的聚合物单元的估计值,这既是估计值中的误差,又是错误的肯定修饰调用。
第二实例是其中所述一组标签被修饰的表示,使得每种类型的聚合物由多个标签而不是单个标签表示。例如,所述一组标签可以包含关于每种类型的聚合物单元的第一标签和第二标签,其中所述第一标签表示所述类型的聚合物单元的实例的开始,并且所述第二标签表示所述类型的聚合物单元的所述实例中的停留。如上文所提及的,“停留”表示其中所述方法确定与连续权重分布相关的标签不发生变化的情况,可以将其视为对应于聚合物单元的相同实例的两个权重分布。在本文中,此实例将被称为“多停留”。由于停留由不同的标签表示,因此这改善了表示。这改善了聚合物单元的估计准确度。
这种多停留表示的结果是允许一些转换,并且一些转换是不允许的。例如,关于相同类型的聚合物单元,仅允许第一标签例如仅允许“a”转换为第二标签,例如关于相同类型的聚合物单元的as,或转换为不同类型的聚合物单元的第一标签。更具体地,以下转换是允许的和不允许的:
a)允许任何其它类型的聚合物单元从每个第一标签转换到第一标签并且允许相同类型的聚合物单元从每个第一标签转换到第一标签;
b)允许相同类型的聚合物单元从每个第一标签转换到所述第二标签;
c)不允许任何其它类型的聚合物单元从每个第一标签转换到所述第二标签;
d)允许相同类型的聚合物单元从每个第二标签转换到所述第一标签或允许任何其它类型的聚合物单元从每个第二标签转换到所述第一标签;
e)允许相同类型的聚合物单元从每个第二标签转换到所述第二标签;并且
f)不允许任何其它类型的聚合物单元从每个第二标签转换到所述第二标签。
可以与图11的方案类似的方式,将上文说明性的多停留表示方案视为“强制性”方案,其中如上文所描述的,空白可以被认为是强制性的或任选的。这样,应当理解,对于多停留表示,可以设想与上文类似的方案,其中允许第一标签转换为相同的第一标签。此类方案可以被认为是“任选的”多停留表示方案。
图13展示了权重分布51的实例,所述权重分布改编自图10的权重分布以实施这种类型的表示。因此,在图13中,所述一组标签包含关于示出为a、c、g和t的四种类型的碱基的四个第一标签,以及关于示出为as、cs、gs和ts的四种类型的碱基的四个第二标签。在本文中,上标s(用于“停留”)用于区分关于相同类型的碱基的第二标签和第一标签,并表示停留。如图13所示,鉴于允许和不允许的转换,以下权重存在或为零:
a)允许任何其它类型的聚合物单元(例如,c、g和t)从每个第一标签(例如,a)转换到第一标签并且允许相同类型的聚合物单元从每个第一标签(例如,a)转换到第一标签(例如,a),因此左上象限中的所有权重都存在;
b)允许相同类型的聚合物单元标签(例如,as)从每个第一标签(例如,a)转换到第二标签,因此右上象限中的w15、w26、w37和w48都存在;
c)不允许任何其它类型的聚合物单元从每个第一标签(例如,a)转换到第二标签(例如,cs、gs和ts),因此右上象限中除了w15、w26、w37和w48的权重都为零;
d)允许相同类型的聚合物单元从每个第二标签(例如,as)转换到第一标签(例如,a)或允许任何其它类型的聚合物单元(例如,c、g和t)从每个第二标签转换到第一标签,因此左下象限中的所有权重都存在;
e)允许相同类型的聚合物单元从每个第二标签(例如,as)转换到第二标签(例如,as),因此右下象限中的w55、w66、w77和w88都存在;并且
f)不允许任何其它类型的聚合物单元从每个第二标签(例如,as)转换到第二标签(例如,cs、gs和ts),因此右下象限中除了w55、w66、w77和w88的权重都为零。
可以将多停留表示与上文所阐述的甲基化c的表示组合,或者实际上与总是以聚合物单元的已知序列出现的一种类型的聚合物单元的任何类似表示组合。
现在将考虑均聚物的表示。均聚物是一系列聚合物单元中的相同类型的聚合物单元的连续实例的序列。
均聚物通过上文所讨论的多停留表示适当地表示,因为对于相同类型的聚合物单元(例如,a),从第二标签(例如,as)到第一标签的转换表示相同类型的聚合物单元的第二实例。例如,一系列标签aasasaasaasasaasasasas表示长度为四个聚合物单元的均聚物,连续标签a或as的数量是任意的并且在实践中变化。然而,可以通过调整表示来提高估计的准确度,使得标签表示呈编码形式的均聚物,例如如下。
呈编码形式的均聚物的第一表示将被称为“正位-翻转”表示并且如下。
使分析方法的输出为重叠的固定长度片段的好处之一是,可以使用重叠量来确定是否发生了聚合物单元的易位以及发生了多少易位。依赖重叠的分析方法在聚合物(如均聚物)的低复杂度区域中失败,其中重叠可以是不明确的(例如,aaa->aaa可以为a同聚物的零个、一个、两个或更多个易位),并且不同的表示是期望的。在正位-翻转表示中,对于每种类型的聚合物单元通过包含多个标签,标签表示均聚物,其中用于每种类型的聚合物单元的所述多个标签表示所述一系列聚合物单元中所述类型的聚合物单元的连续实例。通常,每种类型的聚合物单元有两个标签,为便于参考,可以将所述标签称为“正位”和“翻转”。
因此,与解码到固定长度片段相反,解码的正位-翻转方法将聚合物单元的序列表示为“正位”和“翻转”标签的序列,所述标签具有以下限制:均聚物必须以“正位”标签开始,并且然后在“正位”和“翻转”标签之间交替,直到它们终止。正位-翻转表示确保没有标签与其相邻标签相同,因此一个单元与均聚物的易位(从正位到翻转的改变,反之亦然)总是有区别于没有易位的(正位到正位或翻转到翻转)。举例来说,所述一系列的聚合物单元caatacctttaaaaaaaagaaacttttagctc被表示为caaftaccfttftaafaafaafaafgaafacttfttfagctc,其中聚合物单元x的正位标签由x表示并且对应的翻转标签由xf表示。在正位-翻转编码下,始终可以将一个易位与没有易位区分开来;大量聚合物单元的易位可能仍然是不明确的。因此,就由连续权重分布51表示的标签而言,如果碱基a的两个标签是a(正位)和af(翻转),则一系列标签aaaaaaafafafafaaa表示长度为三个聚合物单元的均聚物,连续的标签a或af的数量是任意的并且在实践中变化。对于每种类型的聚合物单元,原则上可以有两个以上的标签,但是两个标签是足够的。
每种类型的聚合物单元的多个标签可以具有预先确定的循环顺序。在每种类型的聚合物单元的两个标签(正位和翻转)的实例中,预先确定的循环顺序可以是第一聚合物单元总是正位,然后正位和翻转交替。因此,预先确定的循环顺序允许标签之间的一些转换,并且预先确定的循环顺序不允许标签之间的其它转换。在权重分布中,存在通过预先确定的循环顺序不允许的转换的零权重,而当然,存在通过预先确定的循环顺序允许的转换的权重。
在预先确定的循环顺序是第一聚合物单元始终是正位,然后正位和翻转交替的上述实例中,不允许从任何给定类型的聚合物单元的正位到任何其它类型的聚合物的翻转的转换,并且类似地,不允许从任何给定类型的聚合物单元的翻转到任何其它类型的聚合物的翻转的转换。
图14展示了用于这种类型的正位-翻转表示的权重分布51的实例。因此,在图14中,所述一组标签包含关于示出为a、c、g和t的四种类型的碱基的四个第一标签(正位),以及关于示出为af、cf、gf和tf的四种类型的碱基的四个第二标签(翻转)。如图14所示,鉴于允许和不允许的转换,以下权重存在或为零:
a)允许所有类型的聚合物单元从每个第一标签(正位,例如,a)到第一标签(例如,a、c、g和t)(正位)的转换,因此左上象限中的所有权重都存在;
b)允许相同类型的聚合物单元(翻转,例如,af)从每个第一标签(正位,例如,a)到第二标签的转换,因此右上象限中的w15、w26、w37和w48都存在;
c)不允许任何其它类型的聚合物单元从每个第一标签(正位,例如,a)到第二标签(例如,cf、gf和tf)的转换,因此右上象限中除了w15、w26、w37和w48的权重都为零;
d)允许所有类型的聚合物单元从每个第二标签(翻转,例如,af)到第一标签(正位,例如,a、c、g和t)的转换,因此左下象限中的所有权重都存在;
e)允许相同类型的聚合物单元从每个第二标签(翻转,例如,af)到第二标签(翻转,例如,af)的转换,因此右下象限中的w55、w66、w77和w88都存在;并且
f)不允许任何其它类型的聚合物单元从每个第二标签(翻转,例如,af)到第二标签(翻转,例如,cf、gf和tf)的转换,因此右下象限中除了w55、w66、w77和w88的权重都为零。
根据相对于聚合物单元的易位速度进行测量的速率,当聚合物在测量之间易位多次时,可以观察到一个以上单元的明显易位。在可能发生的情况下,可以添加每个聚合物单元的另外的多余标签(“flap”、“flup”、“flep”等),使得可以表示存在另外的单元,例如,从正位到flap的序列意味着中间翻转标签的存在。
呈编码形式的均聚物的第二表示将被称为游程长度编码的表示并且如下。
正位-翻转表示可以通过长均聚物进行调用,但必须作为交替标签的路径并进行多次连接调用。对于较长的均聚物,所观察到的信号变平可能意指不再存在清晰的时间,因为聚合物相对于纳米孔易位时,信号发生变化,并且标签中每个变化的位置变得更加任意。图15示出了示例区域的这种特异性丧失的实例,在所述示例区域中,权重在t-正位或t-翻转之间分配,尽管两者的累积证据都很高。
因此,与将均聚物表示为交替标签的序列相反,替代地整个均聚物可以由关于聚合物单元的类型的标签表示。因此,与训练rnn50来调用典型序列或其正位-翻转编码相反,训练rnn50来调用一系列聚合物单元的游程长度编码。例如,典型序列taattcaaactttttttctgataagctggt的游程长度编码为ta2t2ca3ct7ctgata2gctg2t,其中游程长度遵循碱基,并且一个的长度是隐含的。始终采用尽可能长的游程,因此没有游程与具有相同碱基的游程相邻。
在游程长度编码表示的第一表达方式中,标签包含每种类型的聚合物单元的不同游程长度的标签。图16展示了此类权重分布的实例。在此实例中,关于示出为a,c,g和t的四个碱基以及关于示出为a2、a3等的每个碱基的均聚物存在单个标签。这是难处理的,因为存在大量标签以适应所有可能的均聚物长度,并且允许所有转换,除了从关于一种类型的碱基均聚物的标签转换到相同类型的碱基但长度不同的均聚物之外,因此,关于标签之间的大多数转换的权重wij的数量几乎等于标签数量的平方(其它可能的转换方案可以可替代地实施)。
大基因组中的长均聚物发生的频率比偶然预期的要高,因此表示常规测序期间可能遇到的所有均聚物长度所需的标签数量非常高。由于网络输出的权重明确地参数化了均聚物标签之间的转换,因此训练数据成为问题,这既是因为需要训练的参数数量众多,又是因为它们耦接较弱。将标签的标签混排(例如,a6→a3、t2→t7、g8→g1)会产生等效模型,可以对所述等效模型进行训练以达到相同的性能,因此训练长度为4和6的均聚物的实例不会告知所述模型长度为5的那些均聚物。
游程长度编码的替代性和优选表达方式是将权重分布51因子分解为若干个相关分布。因此,标签包含关于每种类型的聚合物单元的标签,并且权重分布51除了关于转换的权重之外,包括对于每种类型的聚合物单元的游程长度压缩的均聚物的可能长度上的另外的权重。rnn50发出转换权重,以描述游程长度压缩序列的分布,即所有长度下降的游程长度编码序列,以及在给定聚合物单元的情况下针对游程长度的一组单独的条件分布。
在游程长度编码的此优选表达方式中,由rnn输出的权重分布51可以包含呈图10所示出形式的权重,以表示不同类型的聚合物单元之间的转换。如上文所讨论的,在此情况下,从标签到相同标签的一系列转换表示一系列任何数量的聚合物单元(即具有任何长度的单个聚合物单元或相同类型的聚合物单元的均聚物)的实例。
作为对此(游程长度编码的此优选表达方式)的替代方案,可以在一组标签上定义rnn输出的权重分布51,其中每种类型的聚合物由第一标签和第二标签而不是单个标签表示,例如关于第一类型的聚合物单元的标签a和ah。因此,上标h用于关于相同类型的聚合物单元区分第二标签与第一标签并且有效地表示“保持(hold)”。
除了以下之外,这类似于图13中所示出的多停留表示。如上文所描述的,在多停留表示中,允许从第二类型的标签到第一类型的标签的转换(例如,从as到a),并且表示出现了相同类型的聚合物单元的另外的实例。结果,均聚物由一系列标签表示,其中所述第一类型的所述标签被重复,如在上文实例中aasasaasaasasaasasasas表示长度为三个聚合物单元的均聚物。与之相反,在当前表示中,允许的转换不同,使得不允许从第二类型的标签到第一类型的标签(例如,从ah到a)的转换。结果,一种类型的聚合物单元的单个实例和相同类型的聚合物单元的任何长度的均聚物全部由一系列标签表示,所述一系列标签包括第一类型的标签和任意数量的所述第二类型的标签。例如,aahahahahahahahahahah可以表示单个碱基a或碱基a的均聚物。具体地,这通过以下方式实现:
a)允许任何其它类型的聚合物单元从每个第一标签转换到第一标签,但不允许相同类型的聚合物单元从每个第一标签转换到第一标签;
b)允许相同类型的聚合物单元从每个第一标签转换到所述第二标签,
c)不允许任何其它类型的聚合物单元从每个第一标签转换到所述第二标签;
d)不允许相同类型的聚合物单元从每个第二标签转换到所述第一标签;
e)允许任何其它类型的聚合物单元从每个第二标签转换到所述第一标签;
f)允许相同类型的聚合物单元从每个第二标签转换到所述第二标签;并且
g)不允许任何其它类型的聚合物单元从每个第二标签转换到所述第二标签。
图17展示了此类权重分布51的实例,所述权重分布改编自图10的权重分布以实施这种类型的表示。因此,在图17中,所述一组标签包含关于示出为a、c、g和t的四种类型的碱基的四个第一标签以及关于示出为ah、ch、gh和th的四种类型的碱基的四个第二标签。如图17所示,鉴于允许和不允许的转换,以下权重存在或为零:
a)允许任何其它类型的聚合物单元从每个第一标签(例如,a)转换到第一标签(例如,c、g和t),但不允许相同类型的聚合物单元从每个第一标签(例如,a)转换到第一标签(例如,a),因此除了为零的w11、w22、w33和w44之外,两个左象限中的权重都存在;
b)允许相同类型的聚合物单元从每个第一标签(例如,a)转换到第二标签(例如,ah),因此右上象限中的权重w15、w26、w37和w48存在;
c)不允许任何其它类型的聚合物单元从每个第一标签(例如,a)转换到第二标签(例如,ch、gh、th),因此,右上象限中除了w15、w26、w37和w48之外的权重都为零;
d)不允许相同类型的聚合物单元从每个第二标签(例如,ah)转换到第一标签(例如,a),因此,左下象限中的权重w51、w62、w73和w84为零;
e)允许任何其它类型的聚合物单元从每个第二标签(例如,ah)转换到第一标签(例如,c、g和t),因此,左下象限中除了w51、w62、w73和w84之外的权重都存在;
f)允许相同类型的聚合物单元从每个第二标签(例如,ah)转换到第二标签(例如,ah),因此,右下象限中的权重w55、w66、w77和w88存在;并且
g)不允许任何其它类型的聚合物单元从每个第二标签(例如,ah)转换到第二标签(例如,ch、gh、th),因此,右下象限中除了w55、w66、w77和w88之外的权重都为零。
因此,给定类型的聚合物单元的一系列标签总是以第一标签的单个实例,然后以第二标签的一个或多个实例开始。例如,一系列标签a、aah、aahah等(具有任意数量的标签ah)中的任何一种表示一系列任何数量的聚合物单元实例(即,具有任何长度的单个聚合物单元或相同类型的聚合物单元的均聚物)。
如上文所提及的,图10的实例不提供均聚物的良好表示,并且图17的实例也是如此。然而,均聚物由在游程长度压缩的均聚物的可能长度上的另外的权重表示。现在将描述此类另外的权重的若干种概率,所述另外的权重中的每个都可以与呈图10的形式或图17的形式的权重组合应用。
另外的权重的第一概率是,对于每种可能类型的聚合物单元,它们包括在一组均聚物的可能长度上的权重的分类分布。可能长度是一个类别并且rnn50输出为每个类别分配权重。通常,每个类别可以表示单个均聚物长度,或者类别的一些或全部可以表示一定范围的均聚物长度。类别可以包含表示大于给定长度的所有均聚物的类别。类别不必均匀间隔。
图18示出了根据此第一概率的此类另外的权重的实例。在此实例中,对于四个碱基a、c、g、t的每一个的每个可能的长度,存在权重lij,碱基由指数i指数化,并且长度由指数j指数化。在此实例中,每个类别对应于单个长度,但是可替代地,每个类别可以对应于一定范围的长度以减少类别的数量。图18中所示出的另外的权重连同用于标签之间的转换的权重一起形成权重分布51的一部分,其可以采用如上文所描述的形式,例如,如图10到13中的任何一个所示出的。
与完全指定所有均聚物标签之间的转换相比,分类分布需要更少的参数,并且允许估计潜在的游程长度压缩的基因组,但仍然存在弱耦接的问题,所述问题会导致训练数据使用率低,并且使长均聚物难以训练。
另外的权重的第二概率是,对于每种可能类型的聚合物单元,它们包括在均聚物的可能长度上的参数化分布的参数。此类参数可以用于计算给定聚合物单元的均聚物为任何给定长度的概率。
图19示出了根据此第二概率的此类另外的权重的实例。在此实例中,对于四种类型的碱基中的每种(示出为a、c、g、t并且由指数i指数化)存在权重pij。权重指示分布的j个参数p1、p2、…、pj,这些参数由指数j指数化。参数可以是表示分布的任何参数。通常,根据分布,j可以具有任何复数值。图19中所示出的另外的权重连同用于标签之间的转换的权重一起形成权重分布51的一部分,其可以采用如上文所描述的形式,例如,如图10到13中的任何一个所示出的。
举例来说,图20给出了分别由两个参数(均值和方差)的不同值表示的均聚物长度的两种不同分布的实例。
在均聚物长度上使用参数化分布的优势在于,分布可以解释为均聚物长度的后验分布,从而将置信度置于估计的长度中。例如,在图20中,两个分布都给出了均聚物长度的相同后验平均估计值,但是却给出了不同的置信度,方差较大(左)的分布的置信度比方差较小(右)的分布的置信度低。
由于对不同均聚物长度的预测都是通过同一组网络输出进行的,因此它们比以前更加紧密地耦接在一起,并且允许网络将一种均聚物的实例推广到具有类似长度的那些。
许多不同的概率分布可以与网络的输出结合使用。选择能够表示可能出现的任何均聚物长度的分布是有利的,因此所述分布应该支持较大或甚至半无限的潜在长度集。还期望存在表示给定均聚物长度中高置信度(低方差)和低置信度(高方差)的参数值。可以使用负二项式或几何分布,并且无法区分高置信度情况和低置信度情况。
几何分布的方差是均值的函数,负二项式具有另外的自由度,并且其方差必须始终大于均值。满足这些标准的分布可以通过离散化支持[0,∞]的连续分布来找到。离散化的一种方式是将长度为l的均聚物的概率设置为从l到l+1,可替代地l-0.5到l+0.5的密度函数的积分,其中适当的处理为l=0。
优选地,离散的分布具有显式的累积密度函数。此类密度的实例是但不限于威布尔分布(weibulldistribution)、对数逻辑分布、对数正态分布、γ分布。如果存在使用的参数分布或其离散对应项的均值、众数和方差的明确表达式,则是有利的,但不是必需的。
图21展示了用于表示均聚物长度的一些合适的离散分布,所有都支持
在第一概率和第二概率中的每一个中,对于聚合物单元的每种可能类型,即可能类型的均聚物的聚合物单元,定义另外的权重。尽管这是有效的,但是可以通过修饰来提供进一步的改进,其中(a)对于给定聚合物单元的类型和先前聚合物单元的类型的可能对、(b)对于给定聚合物单元的类型和后续聚合物单元的类型的可能对或(c)对于给定聚合物单元的类型、先前聚合物单元的类型和后续聚合物单元的类型的可能三联体的另外的权重。
通过此修饰,权重采用相同的形式,例如,根据第一概率,在一组均聚物的可能长度上的权重的绝对分布,或者根据第二概率,在均聚物的可能长度上的参数化分布的参数,但是增加了权重数量。对于情况(a)和(b),权重数量增加了三倍,以便为每个可能对而不是聚合物单元的每种可能类型定义分布,例如对于12对碱基{(a,c)、(a,g)、(a,t)、(c,a)、(c,t)、(c,g)、(g,a)、(g,c)、(g,t)、(t,a)、(t,c)、(t,g)}而不是4种类型的碱基{a,c,g,t}。举例来说,图22示出了此类另外的权重的实例,所述另外的权重包括对于每对类型的聚合物单元定义的均聚物的可能长度上的参数化分布的参数。这对应于情况(a)和(b),在情况(a)下,所述对是给定聚合物单元和先前聚合物单元的类型,并且在情况(b)下,所述对是给定聚合物单元的类型和后续聚合物单元的类型。参数本身的形式与图19相同,并且可以相同的方式用于计算给定聚合物单元的均聚物为任何给定长度的概率。
类似地,对于情况(c),权重数量增加了九倍,以便为每个可能的三联体定义分布,例如为36个三联体的碱基而不是4种类型的碱基。举例来说,图23示出了此类另外的权重的实例,所述另外的权重包括对于每个三联体类型的聚合物单元定义的均聚物的可能长度上的参数化分布的参数。这对应于情况(c),三联体是给定聚合物单元、先前聚合物单元的类型和后续聚合物单元的类型。参数本身的形式与图19相同,并且可以相同的方式用于计算给定聚合物单元的均聚物为任何给定长度的概率。
基于区分长均聚物的边缘的能力可以根据先前和/或后续聚合物单元而变化的认识,此修饰提高了准确度。例如,从碱t到碱a的均聚物的转换比从碱c到碱a的均聚物的转换更容易区分。因此,提供表示各种对或三联体的分布的不同的另外的权重会提供可以更准确地估计聚合物单元的表示。
将权重分布51类似地因子分解为若干个相关分布可以用于表示聚合物的其它性质。一个实例是具有未修饰形式和经修饰形式的一种类型的聚合物单元的表示,例如可以包含一种类型的碱基和同一碱基的修饰类型的多核苷酸。
dna的天然链含有修饰的碱基,例如5-甲基胞嘧啶或6-甲基腺嘌呤,并且可使用一系列纳米孔测量来检测它们的存在和位置。正位-翻转和其它表示很容易概括为能够通过从碱基a、c、g和t扩展一组标签以包含表示修饰的碱基的另外的标签(例如,cm表示修饰c)来调用修饰。
图24示出权重分布的实例,其中一组标签被扩展以另外包含关于修饰的碱基的标签cm。类似地,可以将另外的标签cm添加到图10、12到14或16所示出的权重分布51中的任何权重分布中的一组标签。
标签的字母的这种扩展还可以与本领域中描述的先前方法一起使用,所述方法假定在特定时间的信号可以由固定长度的碱基片段表示,但是由于网络必须针对固定长度的碱基之间的每个可能的转换具有输出,因此随着所考虑的修饰数量的增加,这些标签缩放较差。例如,对于长度为5的片段,存在1024(45)个可能组合,其由四个典型碱基组成,如果允许另外的修饰的碱基,则为3125(=55),并且如果允许两个修饰,则为7776(=65)。rna中已知有一百多种修饰,因此基于片段的模型需要快速增加的处理量。
聚合物单元的未修饰形式可以描述为典型聚合物单元,并且聚合物单元的修饰形式可以描述为非典型聚合物单元。修饰(或非典型)聚合物单元通常影响与对应未修饰(典型)聚合物单元不同的信号。
通过引用并入本文的2019年9月4日提交的国际专利申请号pct/gb2019/052456含有与可以应用于本文所公开的本发明方法中的任何一个的典型和非典型碱基有关的教导。
国际专利申请号pct/gb2019/052456公开了可以应用于本发明方法中的任何一个的非典型碱的实例。
国际专利申请号pct/gb2019/052456还公开了制备和分析包括一种或多种非典型聚合物单元的聚合物的方法,其可以与本发明方法中的任何一个组合使用。
通过非限制性实例,国际专利申请号pct/gb2019/052456中公开的可以与本发明本发明方法中的任何一个组合的一种方法以不确定性的方式,例如通过化学转化或通过酶促转化,将一定比例的典型聚合物单元(例如,氨基酸)转化为对应的非典型聚合物单元(例如,氨基酸)。在所述情况下,当导出一系列聚合物单元的估计值(“调用”)时,可以将非典型碱基估计(“调用”)为对应的典型碱基。这包含参考以下的图18b-18k所描述的方法:国际专利申请号pct/gb2019/052456。
由于非确定性地将典型和非典型聚合物单元并入靶聚合物中,因此聚合物单元的基础序列是未知的,并且将在链到链的基础上变化。即使每个链含有替代性聚合物单元,但是仍然存在相关的典型序列,并且所关注的是直接调用这而不是尝试推断任何替代方案的类型和位置。换言之,尽管在靶聚合物中存在另外的聚合物单元,但分析仅将典型值归属于信号,使得所测定的序列由来自a、c、g和t的组的碱基组成。以此方式,通过在分析中将非典型聚合物单元识别为典型聚合物单元,初始转换可以提供一种提供具有更多信息的信号的方式,例如,结果是信号分析中出现的任何错误将是非系统性的,从而带来估计准确度的提高。
正位-翻转和类似的表示更易于处理,因为在每个时间点从rnn50输出的权重数量需要使用修饰数量而不是等于片段长度的幂对转换权重标度进行二次参数化(对于4个典型碱基40个输出,对于一个另外的修饰碱基60个输出,对于两个碱基84个输出等)。
当神经网络10使用正位-翻转表示时,执行训练以使正确序列的概率最大化,对于每次读取,其产生条件随机场,必须对所述条件随机场进行进一步解码以产生估计序列。所使用的解码方法可能会在最终调用中引入不必要的偏差,所述偏差会以大量量度显示自身,例如称为其组成的读段或汇总统计信息的碱基总数。当将来自具有相同序列或含有共同子序列的链的读段的估计序列综合考虑时,另外的偏差可能明显。
为了减少这个问题,可以将惩罚项并入到训练的神经网络10中,调整其输出以提高所关注的量度的性能:例如,从对应于不发射新的聚合物单元(相同碱基中的正位-正位或翻转-翻转转换)的所有权重中减去常数将增加调用的聚合物单元的数量,而通过将常数添加到结束发射具有所述标识的新的聚合物单元的所有转换,可以增加特定聚合物单元的比例。
可以通过针对网格值上的一组代表性读段计算所关注的量度来调整使用的惩罚项的值,可替代地可以使用更正式的优化方法(例如,单纯形法或本领域已知的许多其它方法)。惩罚项可以是关于读段的先验信息的函数,而不是固定的常数。
可以在任何层将惩罚项并入到神经网络10中,但是优选的是在可能的情况下将它们并入到最终层中,直接影响所发射的转换权重,因为这样做的优点是可以直观地影响最终的估计序列,从而指导惩罚的形式。
为了保持将神经网络10的输出解释为概率模型,期望但并非必须的是,在执行“全局归一化”之前并入惩罚。
通常,准确地确定典型碱基的序列和任何修饰的存在都是所关注的,并且不期望尝试估计修饰对基础典型序列的估计产生不利影响。这如何发生的一个实例是典型胞嘧啶与5-甲基胞嘧啶之间的权重分割,因此另一种碱成为最可能的估计。
为了防止权重分割行为,可以将rnn输出的权重分布51因子分解成两个相关分布。在此情况下,第一分布是权重分布51,所述权重分布采用上文所描述的形式中的任何一种,表示具有未修饰形式和经修饰形式的类型的聚合物单元的单个标签,并且第二分布是条件分布,所述条件分布包括未修饰形式和修饰形式的另外的权重。对于任何数量的修饰形式和可能类型的聚合物单元中的任何一种的修饰形式可以扩展此表示。
图25示出了用于表示碱基c的未修饰形式和相同碱基cm的修饰形式的另外的权重的实例。在此情况下,另外的权重是关于碱基c的未修改形式的权重m1和针对碱基cm的修饰形式的权重m2。这可以代替图24所示出的类型的权重分布51而被应用。另外的权重连同用于标签之间的转换的权重一起形成权重分布51的一部分,其可以采用如上文所描述的形式,例如,如图10到14或16中的任何一个所示出的。
这种因子分解式表示意指可以确定典型序列,就好像不存在修饰一样,然后可以确定任何修饰的位置。修饰的条件分布本身可能是因子分解的,可能反映了先前的生物学期望。例如,一种分布可以表示胞嘧啶是否被修饰,并且另一种分布可以表示在存在修饰的情况下,所述修饰是5-甲基胞嘧啶还是5-羟甲基胞嘧啶。
作为实例,图26示出了当采用已经以此方式扩展的四个碱基的正位-翻转表示来检测修饰的碱基5mc时,由rnn50的输出预测的碱基。在此实例中,在与外部预测一致的位置处的三个位置处估计了修饰的碱基5mc。
如上文所提及的,将rnn50的权重分布全局归一化。此类全局归一化可以通过一系列权重分布在标签的所有路径上,使得所有可能路径上的总和是一。全局归一化可以在输出空间上,使得权重可以被认为是后验概率。
全局归一化严格意义上比局部归一化更具表达性,并且避免了本领域中称为“标签偏差问题”的问题。
使用全局归一化优于局部归一化的优点类似于条件随机场(lafferty等人,《条件随机场:分段和标记序列数据的概率模型(conditionalrandomfields:probabilisticmodelsforsegmentingandlabellingsequencedata)》,《国际机器学习会议论文集(proceedingsoftheinternationalconferenceonmachinelearning)》,2001年6月)具有优于最大熵马尔可夫模型(mccallum等人,《用于信息提取和分割的最大熵马尔可夫模型(maximumentropymarkovmodelsforinformationextractionandsegmentation)》,《icml会议论文集(proceedingsoficml)》,2000,591-598。斯坦福,加利福尼亚州,2000)的优点。标签偏差问题影响标签之间允许稀疏的转换矩阵的模型,如聚合物序列的扩展。
全局归一化通过在整个序列上进行归一化来缓解这个问题,从而允许不同时间处的转换相互交换。全局归一化对于避免均聚物和其它低复杂性序列的偏差估计特别有利,因为与其它序列相比,这些序列可具有不同数量的允许的转换(取决于模型,其可以更多或更少)。
现在将考虑解码器80。
解码器80从所述权重分布51中导出所述一系列聚合物单元的估计值。这可以通过使用链结式时间分类来完成,例如在以下中公开的:graves等人,“用递归神经网络标记未分割的序列数据的链结式时间分类(connectionisttemporalclassificationlabellingunsegmentedsequencedatawithrecurrentneuralnetworks)”,《第23届国际机器学习会议论文集(proceedingsofthe23rdinternationalconferenceonmachinelearning)》中,369–376(acm,2006)。
解码器80如下执行如图27所示出的三个步骤。
在步骤s1中,导出关于相应权重分布51的标签的估计值。此估计在下文中进一步讨论。
在步骤s2中,对在步骤s1中导出的标签进行游程长度压缩,以导出一系列聚合物单元的估计值(也可以被称为解码)。这是需要的,因为权重分布51比聚合物单元多。游程长度压缩产生聚合物单元的估计值,因为如上文所描述的,在rnn50固有的聚合物表示中,相同标签的连续序列表示相同聚合物单元。
步骤s2还考虑了其中多个标签用于表示给定类型的聚合物单元的表示。例如,在上文所描述的多停留表示中,第二标签被压缩成关于相同类型的聚合物单元的第一标签。类似地,在上文所描述的正位-翻转表示中,第一标签(正位)的连续实例被压缩成单个聚合物单元,并且第一标签(翻转)的连续实例被压缩成另一个单个聚合物单元,依此类推,从而提供均聚物的估计值。
例如,在图11的方案中,可以在步骤s2中执行解码空白以区分相同聚合物单元的实例。如上文所讨论的,对于空白可以考虑“任选”和“强制”方案,因此,步骤s2可以根据以下两个方案中的哪一个将标签序列:aaa--a解码为aaaa或aa。
在正位-翻转方案的情况下,步骤s2可以包括将相同标签的多个游程折叠到单个对应的聚合物单元上。例如,可以在步骤s2中将标签序列caaftaccfttf解码为一系列聚合物单元caatacctt。
关于多停留方案,步骤s2可以包括通过将相同标签的连续序列识别为相同类型的不同聚合物单元来进行解码。例如,可以在步骤s2中将标签序列aasasttscaasas解码为一系列聚合物单元atca。
关于游程长度编码方案,步骤s2可以包括通过折叠相同标签的游程来进行解码(并且如果在所述方案中必要则丢弃空白)。例如,在步骤s2中标签序列ta2t2ca3可以表示一系列聚合物单元taattcaaa。
在权重分布51被因子分解为相关分布的情况下执行步骤s3,否则省略。在此情况下,使用关于转换的权重执行步骤s1和s2,并且在步骤s3中,使用另外的权重来估计由此表示的聚合物单元的质量。例如,在上文所描述的游程长度编码的表示中,另外的权重用于估计均聚物的长度。类似地,在上文所描述的修饰形式的因子分解式表示中,另外的权重用于估计聚合物单元是未修饰形式还是修饰形式。
现在将讨论步骤s1中的标签估计。由于权重表示相应转换的后验概率,因此权重可以用于通过权重分布51导出标签的任何给定路径的后验概率,即对于对应于所讨论的路径的一系列转换,通过组合由权重表示的后验概率。这意指权重允许考虑不同路径的可能性,从而提高了估计的准确度。因此,步骤s1应用了一种技术,所述技术基于对通过权重分布51关于标签路径的转换的组合权重的考虑。
在不允许一个或多个转换的情况下(如上文所讨论的),解码器在步骤s1中执行的估计可以考虑表示标签之间的转换是否被允许或不允许的转换矩阵。
两种不同的方法是可能的,所述方法将被称为“最佳路径”和“最佳标签”。
在最佳路径方法中,基于权重分布51通过一系列权重分布51的最可能标签路径。在此情况下,在步骤s1中导出的关于相应权重分布51的标签是所述最可能路径的标签。
由于权重分布51是转换上的权重,因此解码以估计序列的一种方法是找到具有最大权重之和的路径。此类路径可以有效的方式从转换权重中找到,例如使用动态程序算法。可以使用维特比算法(viterbialgorithm)。
例如,图28展示了最佳路径算法,其中在框i处,rnn50将权重wijk输出到从标签j到标签k的转换。向量ti存储了回溯信息,所述回溯信息是来自给定当前标签的最佳标签,并且用于确定评分s和最佳路径p。
对于游程长度编码,找到的最佳路径是针对游程长度压缩序列的,并且需要根据由rnn50输出的适当的条件分布来确定每个游程的长度。在最佳路径示出出现了新的聚合物单元的情况下,可以根据对应于所述聚合物单元的条件分布来估计游程长度。进行此估计的适当方法包含:找到条件分布的均值(四舍五入)、众数或中值;在合适的先验条件下,还可以使用具有最大贝叶斯因子(bayesfactor)的长度。在网络输出表示可能存在的可能的碱基修饰的条件分布的情况下,以它们的存在来标记最佳路径的过程以类似地进行,尽管后验均值和中值不是合理的估计量,因为修饰是分类的,而不是有序的。
对于游程长度编码,可以应用游程长度偏差校正。由于所述模型是根据实际读段训练的,因此存在学习并且并入模型的权重中的游程长度的一些先前分布。对于从随机链或实际(例如,基因组)链导出的读段,训练数据将含有的不同长度的游程的比例存在显著的偏差,例如,长游程极为罕见。这影响了所述方法调用长游程的能力。游程的长度存在歧义,通常调用短游程比调用长游程更正确,并且因此单读段准确度的最大化趋于导致调用短游程。这样,对相对较短的游程长度应用偏差校正是有益的。
找到最可能的路径后,必须导出一系列典型碱基。对于正位-翻转表示,合并标签的相邻重复,因为它们在其它ctc类模型中起与空白标签相同的间隔作用,然后去除每个标签的正位或翻转标识以保留典型碱基。对于游程长度编码,删除空白标签,并且将每个游程扩展为适当数量的碱基。
现在将讨论最佳标签方法,注意到在正确的标签不在最可能的路径上的情况下,最佳路径方法可能会错误地估计一些特定的标签。来自rnn50的权重分布51有效地定义了标签的所有可能路径上的概率分布,为位置分配标签的一致方法,并且每个路径对应于一系列标签,因此对应于聚合物单元,尽管这种对应关系不是唯一的(可能存在给出相同序列的许多路径)。最佳标签方法通过估计最可能的一系列标签(以及因此聚合物单元)来改进最佳路径方法。也就是说,通过对满足此条件的所有路径求和,而不是找到最佳路径,可以得出在时间步长i之后路径在标签j中的后验概率。这可以考虑通过一系列权重分布51的标签的前向和后向路径。在此情况下,在步骤s1中导出的关于相应的权重分布51的标签是由此最有可能导出的标签。
动态的时间前向和后向编程允许使用类似于最佳路径的递归的递归以有效的方式执行此计算;在最佳路径算法可以看作是维特比解码的形式的情况下,后验概率的计算可以看作是前向和后向算法的形式。类似地,可以通过对满足此转换的所有路径求和来计算在时间步长i处标签发生变化的后验概率;此计算还可以以有效的方式执行。
尽管后验概率提供了有关每个位置处可能的标签的信息,但通过选择最可能的标签进行解码可能会导致路径不一致,从而导致序列不一致。通过定义从一个标签到另一个标签的转换矩阵t(根据是否允许转换,所述标签的条目为一或零),可以将最佳路径解码算法应用于这些后验概率,以从所有一致的路径中找到最大化其标签的后验概率之和的路径。
作为此的实例,图29展示了应用于在位置i处在标签k中的后验概率pik的算法。向量ti存储了回溯信息,所述回溯信息是来自给定当前标签的最佳标签,并且用于确定评分s和最佳路径p。
可替代地,可以将最佳路径算法应用于后验概率的对数,以找到在所有一致路径上最大化其标签的对数后验概率之和的路径。这等同于找到在所有一致路径上最大化其标签的后验概率乘积的路径。
作为此的实例,图30展示了应用于在位置i处在标签k中的对数后验概率pik的最佳路径算法。向量ti存储了回溯信息,所述回溯信息是来自给定当前标签的最佳标签,并且用于确定评分s和最佳路径p。
可替代地,由于权重分布51是在转换上定义的,因此前向和后向算法可以用于计算位置之间转换的后验概率,而不是每个位置处的标签。
作为此的实例,图31展示了计算在所有路径上求和的后验概率。由于这些权重是在转换上的,因此所述权重具有与转换矩阵相同的形状,并且它们的对数可以馈送到图28中定义的方程中而不是转换权重以找到一致路径。
从覆盖基因组相同区域的许多信号中产生共有序列的更成功的方法之一被称为“抛光(polishing)”,并且已经在一些出版物中进行了描述。抛光共有序列是迭代过程,其中根据所有读段与候选变化的匹配程度,对草案共有序列的候选更改进行评分,并且保持较高的评分更改,允许由一种读段引起的错误由其它读段来校正;重复此程序,直到找不到更高的评分更改为止。
不明显的是,抛光还可以有益地应用于单个读段。先前小节中所描述的所有估计聚合物单元的方法都旨在通过网络输出找到好的路径,可以从中提取出碱基序列,但是无配准培训目标针对给定序列的所有路径求和,而不是将单个路径标识为好。为了与训练标准一致,理想地,应该通过找到最可能的序列,对导致相同序列的所有路径而不是最可能的路径求和,来对来自rnn50的输出进行解码。给定序列的所有路径的总和是抛光用来评估候选变化是否良好的标准,因此可以将抛光视为迭代启发法(贪婪爬山的变体),以找到最可能的序列。
在分析作为相关的一系列聚合物单元的测量的多个测量系列的情况下,所述方法基本上是相同的,但是来自多个测量系列的测量被视为布置为多个相应的尺寸。这增加了维度,但是神经网络10的形式在其它方面与上文所描述的相同。在此情况下适用的一些另外的考虑如下。
当使用惩罚项时,作为不发射的惩罚针对所有转换不变的替代方案,惩罚可以根据转换取不同的值或完全不存在。例如,一些转换不会导致状态发生变化,并且可以是自由的,或具有小的惩罚,因为所述转换并不意味着其它读段中丢失的状态。
对于每个读段,所使用的一种或多种惩罚不必相同,并且对于两个读段可能具有不同的特性可能有好的生物物理原因。例如,一个读段可能来自在马达上方的双链的分子,而另一个则是单链的;可替代地,两个读段可以是具有不同马达的链;一个读段可以是dna,而另一个可以是rna;可替代地,两个读段可以是同一正向-反向-互补链的第一部分和第二部分,并且在测序期间两者之间的杂交改变了动力学。
所使用的一种或多种惩罚可以与时间有关。所使用的一种或多种惩罚可以取决于读段的本地统计信息。这样的实例包含:速度、失速的存在或噪音。所使用的一种或多种惩罚可以取决于使用其它模型或技术的读段分析的输出,例如,预测滑动的可能性(缺失碱基)。
正位-翻转表示和rle表示的状态转换模型都具有时间顺序,并且颠倒状态的顺序可移不是有效的状态序列。也就是说,在rle表示中,必须在停留之前发射碱基,并且正位-翻转表示要求任何重复的第一碱基必须是“正位”。这样的结果是,在读段之一来自链(或链的一部分)的情况下,所述链是另一条链的反向补体或反向链,在分析之前反转读段之一并应用与两个正向读段相同的程序是不够的。
虽然可以使用更复杂的程序组合两个不同方向上的读段,从而跟踪作为一对的两个读段的状态,但是有利的是在一个读段上使用标准模型并且在另一个读段上使用已被“后向”训练的模型——在训练期间,来自读段的信号和靶序列是相反的(并且可能是补充的)。使用此类一对模型确保正向和反向读段以相同的顺序通过模型的状态,因此可以将所述读段组合起来,就好像它们都是正向读段一样。
可以使用常规技术来训练神经网络10,例如如下。
神经网络10输出表示权重的分布,所述权重表示在标签的路径上的概率(用标签对度量的一致标记),然后将其解码为聚合物单元序列的估计值。用旨在确保此估计值具有低比例的误差的标准来训练神经网络10。
使用转换权重定义路径上的概率分布的重要方面是,必须对权重进行归一化使得所有路径上的总和为1。给定一组转换权重,可以使用动态编程通过应用如上文所讨论的后验概率计算中使用的前向算法(或后向算法)来计算归一化因子。由于所有可能路径的总和,而不是在每个时间点将网络的输出归一化为1,因此此技术被称为全局归一化,并且确保每个路径的评分具有概率(其对数的)的解释。具有一致标签的每条路径对应于概率,并且这些概率形成了所有路径上的分布。
与全局归一化相反,归一化神经网络10使得每个时间点的输出总和为1被称为局部归一化。可以计算每条路径的评分并且其具有概率的形式,但是由于总的概率质量小于1,因此它们不形成分布。局部归一化将概率分配给所有标签序列,无论它们是否形成一致路径。
序列标记的训练需要训练实例,即输入信号对及其对应的标签序列,以及用于优化训练实例的目标函数。由于纳米孔测量结果与聚合物单元序列之间的真正配准是未知的,因此,无配准的训练方法如graves等人所描述(2006)是优选的。如果配准培训方法需要对测量序列的每个元素进行标记,则免配准的方法仅需要知道聚合物单元的真实序列。可以通过在纳米孔装置中测量已知序列的聚合物,或将读段与参考序列或具有已知序列的一组测量结果进行比较,来确定用于读段的聚合物单元的真实序列。
测量已知序列的实例可以包含小的基因组,其中有可能在单个读段(如λ噬菌体(50千碱基))中对完整的基因组进行测序。也可以使用限制性酶切,并且通过其长度鉴定片段。另一个实例涉及将已知片段按顺序添加到游程中,因此可以通过片段出现在数据中的时间来识别它们。显而易见的是,可以使用可以将序列分配给信号读段的任何方法。
在训练神经网络10时,在各种背景下以及在各种实验中进行跨每个聚合物单元的测量是有益的,因此所网络已暴露于正常运行状况下将遇到的整个变化范围的大部分。理想地,神经网络10使用完整的读段来训练,即纳米孔读取的覆盖全长聚合物的信号和序列对。然而,出于实际考虑(计算时间、内存),通常在较小的信号和序列块上进行操作。
递归、卷积和注意力神经网络单元具有时间顺序的概念,并且训练中呈现的测量窗口的大小限制了可以从中学习的背景。由于每个聚合物单元可能具有很大的影响范围,因此为神经网络10呈现较大的测量窗口以进行训练是有益的。所使用的窗口的大小是呈现足够大的一系列测量结果之间的平衡,以使神经网络10可以在孔隙、聚合物链和其它系统组件之间的相互作用以及可用的计算能力的数量上创建足够的内部表示。理想地,将使用每个读段的全部内容,但在实践中,固定大小的度量块呈现良好的折衷方案。足够的块的大小取决于纳米孔以及链的易位速率,但是已证明,对应于约200到约300个碱基的块大小是足够的。例如,已证明这对于csgg纳米孔是足够的。
示例训练集大小可以包括~1百万组~300个信号和序列的碱基块。仅几千个块的较小训练集可能就足够了,并且>1百万个块的较大训练集可以为训练提供更多多样性。
训练神经网络的许多技术或其它机器学习方法是本领域已知的,并且可以在此应用。由于所述方法概述不同的实验运行和聚合物序列的能力得益于大量的训练数据,因此寻求最大化目标函数方向通常是不切实际的,因为优选的是在内存受限的图形处理单元(gpu)或其它专用硬件上执行计算。与直接在整个数据集上最大化目标函数相反,优选的是使用随机梯度下降法(sgd)或相关技术,以迭代方式使用整个训练集的子集(“小批量”)来近似地最大化目标函数。优选的小批量大小取决于所使用的计算装置上的可用内存以及小批量的每个元素中的度量数量。
随机梯度下降(sgd)的许多变体是本领域已知的,例如:sgd、具有动量的sgd、具有nesterov动量的sgd、rmsprop、adamax、adam。adam的修饰“adamski”,其中迭代n的动量以从0到最大值μ的动量斜坡因子r增加:其中μn=μ(1-e-rn),是优选的。adamski具有学习速率、两个平滑参数(在本领域中通常称为衰减1和衰减2)和动量斜坡速率。这些参数的许多选择都是有益的。优选的参数化具有初始学习速率10-3、平滑参数0.9和0.999以及动量斜坡因子0.005。平滑参数0.95和0.99也已被证明对于完善已经训练的模型有效,因为初始学习速率已降至10-4。
sgd和相关技术以迭代方式进行,每次迭代由以下步骤组成:
1.选择完整训练数据的子集。
2.计算此子集的目标函数
3.使用反向传播计算所有网络参数的梯度
4.使用sgd或变体更新网络参数
5.转到1(下一个迭代的开始)
步骤4中更新的大小按称为学习速率的因子进行缩放。高学习速率意指参数可以快速变化,因此最大化可以更快地进行,但是每个小批量的影响可能较大,这意指模型接近收敛时,更新可以由小批量到小批量可变性来控制。优选的是缓慢降低迭代到迭代的学习速率;这种降低可以是动态的,根据目标函数在批量到批量之间的变化和可变性,或者根据某些预先确定的时间表来调整学习速率。优选地,使用双曲线衰减,其中对于某个初始学习速率r和小批量的数量k,第n个小批量的学习速率为r/(1+(n/k))。
虽然已经使用求和来将小批量的每个成员的评分组合到小批量的评分中,但是其它组合方法也是可能的。求和得出的小批量评分与其组成元素的评分的均值成比例,对应于其它集中趋势度量的组合也具有良好的性质。如中值、修剪均值或加权均值等组合器或拟合m估计器的组合器可以用于更改物镜对具有异常值的小批量元素的敏感性。
小批量的每个元素对总评分的作用是在所有一致路径上求和的真实序列的后验概率(的对数)。对于正位-翻转表示,正位到正位或翻转到翻转的转换表示停留在序列的相同位置,而所有其它转换涉及位置的移动。给定表示在每个时间点从rnn50输出的标签之间的转换的权重,可以将这些权重转换为已知序列位置之间的转换权重。
图32示出了对于标签s1、s2、…、sn的正位-翻转编码序列,如何构建每个时间点i的目标转换矩阵mi的元素。图33中所描述的目标函数使用此目标转换矩阵来计算小批量的每个元素的评分。
由于目标函数的转换矩阵非常稀疏,对角线(停留)和超对角线(在位置上移动)上仅具有非零元素,因此从真实序列的长度(从二次到线性)的角度,此计算的优选实施例仅忽略了零元素并且降低每个步骤的表观复杂性。
多停留表示的目标函数在结构上与正位-翻转目标类似,但表示停留在相同位置的状态不同。从停留或非停留状态到任何非停留状态的转换意味着位置的改变;停留状态的任何转换不意味着位置的改变。对于多停留表示,表示停留在新位置(碱基到停留转换)和停留在旧位置(停留到停留转换)的转换是有区别的,并且目标函数的有效计算需要使用一组重复的真实序列的“剩余”位置:s1、r1、s2、r2、…、sn、rn。
图34示出了对于此实例如何构建目标转换矩阵的元素。出于形成目标转换矩阵的目的,原始位置被列举为1…n,而对应的重复位置被列举为n+1…2n。
图33中所描述的目标函数使用此目标转换矩阵来计算小批量的每个元素的评分。目标转换矩阵是稀疏的,并且目标计算的优选实施例利用了这种稀疏性。
每个评分可以乘以权重,然后用于目标函数,并且此权重可以表示对应于训练过程的小批量的元素的值。例如,对于具有异常序列组成的元素或已知与碱基调用误差有关的元素,权重可能更大,这可以在先前训练的网络的测试期间发现。确定小批量的元素的权重的一种方法是将其设置为等于其最稀有的均聚物的频率的倒数,所述频率是根据整个训练数据集或根据其它外部参考确定的。
每当转换了新的序列位置以表示通过网络输出的对应条件分布对游程长度的预测程度如何,游程长度编码的目标的定义类似于多停留模型的目标除了并入的另外的因子。游程长度压缩序列上的目标转换矩阵的形式与许多停留目标的形式相同,在位置之间允许的转换中,没有碱基可以遵循隐含的相同碱基的限制,但是在给定其组成的每个位置处,网络分配给均聚物长度的对数概率的另外组成。
当已知训练数据的均聚物含量存在偏差时,在许多应用中网络学习此偏差可能是不期望的,因为网络可能无法表示其它数据集。代替直接在训练目标中在给定其组成的每个位置处使用网络分配给均聚物长度的对数概率,它可以首先与另一个分布合并;可以通过从训练数据中列出均聚物的频率来获得这种其它分布(“训练先验分布”)。通过以此方式进行训练,网络必须学习分配克服对训练先验分布的期望的对数概率。
出于碱基调用的目的,可以使用标准方法如贝叶斯定理(bayestheorem)将训练数据的先验分布或均聚物长度的任何其它期望与网络分配的对数概率组合,以产生通过有关均聚物长度的外部信息得出新的对数概率;可替代地,可以将来自网络的对数概率直接用于无偏调用。
图35示出了对于此实例如何构建目标转换矩阵的元素。将网络在测量的时间步长i处分配给长度为lj的游程长度的概率的对数为risj:lj,游程具有序列位置j的组成sj。图33中所描述的目标函数使用此目标转换矩阵来计算小批量的每个元素的评分。
尽管以免配准的方式训练碱基调用模型的优点众多,但在呈现的大多数解码算法与使用的训练目标之间存在断开。用于模型训练的目标函数最大化真实碱基序列的概率,对可以表示其的所有各个路径的概率求和,而除如上文所描述的抛光外的所有解码例程都在寻找具有高评分的路径。图36示出了此断开连接所引起的问题之一。具体地,对于正位-翻转表示的实例,图36示出了在时间上处于特定标签中的信号(顶部)和后部概率(底部),在时间2410与2600之间的长均聚物区域的情况下,即大约模型停留在t翻转状态(红色虚线)而不是与t正位状态(红色实线)交替的情况。输入了长均聚物后,围绕所述区域的开始和结束进行了估计,但正位状态和翻转状态很快变得不那么明显,并且后验概率均匀。存在穿过所述区域的多条路径,其中正位和翻转碱基的配准略有不同,并且后验概率反映了此集合的平均值。
一种可能的替代方案是使用最佳路径的评分作为训练目标,而不是对所有路径求和,并且这仍然是免配准的方法,因为没有明确定义配准,并且与标记不同,最佳配准可能会随着模型而改变。虽然训练最佳路径似乎很直观,但是从头开始训练模型时,这种方法却大为失败,因为最初的不良模型具有不良的最佳路径,并且训练过程对此有所强化。
锐化是将训练集中朝向单个路径的方法,而不必事先指定配准,同时仍要考虑所有其它可能性。首先,考虑用于计算所有路径(图33)和最佳路径(图37)的总和评分的算法。这些都应用了函子,log∑jexp和maxj分别将转换权重和先前的前向向量组合在一起。锐化的目标是用仍然对所有可能路径求和但对评分较高的那些向上加权的函子代替此函子。
图38示出了一些函子,所述函子可以是用于将前向向量和转换或映射权重组合在一起的函数。优选在图38中被称为“锐化的所有路径”的函子,但是可以使用许多其它函子,并且实际上,可以将它们组合在一起以创建新的函子。
与从一开始就启用锐化进行训练相反,已发现使用所有路径目标函数开始训练,然后一旦找到了良好的模型,将锐化因子(a)从1增加到更高的值是有利的,其中可能会以更高的锐化值重复。此多阶段过程还使模型可以使用最佳路径目标进行训练。首先对所有路径目标进行训练找到良好的模型,使得最佳路径是良好的,然后通过进一步的训练来强化此路径。
图39示出了在如图36所示出的相同示例区域上锐化正位-翻转表示的作用。图39示出了对于此实例随时间处于特定状态但使用锐化训练的信号(顶部)和后验概率(底部)。在时间2400与2620之间大约有一个长的区域,在所述区域中发生均聚物,并且模型在t翻转状态与t正位状态之间交替,以调用碱基序列。各个调用更不同,并且可以看出在整个均聚物区域中,t正位和t翻转之间交替。
对此模型进行解码产生比未锐化模型更好的聚合物单元的估计。这在图40所示出的实例中进行了说明,其中将来自未锐化和锐化模型的聚合物单元(碱基调用)的估计值与参考序列进行了比较。尽管未锐化的调用仅调用8个t碱基,锐化的调用同意在参考中找到的27个t碱基。
尽管使用最佳路径或锐化代替了训练异议,但它们也可以用来增强它并且训练网络远离测试期间已发现的不期望行为。一种此类不期望行为可能是向下调用均聚物长度的趋势,这可能会在训练数据严重偏向短均聚物时发生,并且可以通过对训练异议添加惩罚来校正。可以通过使用最佳路径找到调用均聚物的位置并且将其真实长度与基于网络在所述位置分配的对数概率的估计值进行比较,来找到一种此类惩罚;可以使用绝对差之和进行比较;可以使用平方差之和进行比较;许多其它比较方法是本领域已知的。可以将惩罚添加到训练目标中;惩罚可以另外通过预先确定的因子加权,以改变其相对于训练目标的重要性。
代替预先确定的,对惩罚项进行加权的因子可以被视为拉格朗日乘数(lagrangemultiplier)。在寻找拉格朗日乘数的固定点的同时,通过优化训练目标进行训练。在这些点处或附近,惩罚近似为零,并且网络已经受惩罚条件保持下的训练;对于惩罚是真实长度与估计长度之间的绝对差之和的实例,平均而言,网络调用将是正确的长度。
可以使用多个惩罚项来增强训练目标,例如,每个均聚物长度一个惩罚项;每个惩罚可以通过预先确定的因子加权或被视为拉格朗日乘数。
上文的描述考虑了权重分布51表示一组标签之间的转换的情况。作为替代方案,本文所描述的方法可以适用于权重分布51表示一组标签内的标签的情况。
在权重分布51表示一组标签内的标签的情况下,解码器80可以使用转换矩阵来表示是否允许或不允许标签之间的转换。转换矩阵可以具有与权重分布51中的权重矩阵类似的形式,但是二进制元素指示允许或不允许的转换。转换矩阵可以将至少一个转换表示为不允许,并且将其它转换表示为允许。考虑到根据转换矩阵通过允许的标签的不同路径的可能性,解码器80可以使用此转换矩阵从表示标签的权重分布51导出一系列聚合物单元的估计值。
同样在这种权重分布51表示一组标签中标签的情况下,可以以如上文所描述的编码形式来表示一系列聚合物单元中的相同类型的聚合物单元的连续实例,例如,使用正位-翻转-表示或游程长度编码表示。
尽管上文的描述涉及包含rnn50的神经网络10,但是具有上文所描述的形式和解码的权重分布可以等同地应用于任何其它形式的机器学习技术,例如hmm。
根据本发明的第二方面,提供了一种如以下条款中所定义的方法。
条款1.一种分析在聚合物相对于纳米孔易位期间从所述聚合物导出的信号的方法,所述聚合物包括属于一组可能类型的聚合物单元的一系列聚合物单元,所述方法包括:使用输出一系列权重分布的机器学习技术来分析所述信号,每个权重分布包括关于一组标签上的标签的权重,所述一组标签包含表示所述可能类型的聚合物单元的标签;以及从所述权重分布导出所述一系列聚合物单元的估计值,其中导出所述一系列聚合物单元的估计值的步骤将表示是否允许或不允许标签之间的转换的转换矩阵考虑在内,标签之间的至少一个转换被表示为不允许并且其它转换被表示为允许。
条款2.根据条款1所述的方法,其中不允许标签之间的至少一个转换并且允许其它转换,所述权重分布各自包括关于被允许的标签的权重。
条款3.根据条款2所述的方法,其中所述权重分布各自包括关于不被允许的标签的零权重。
条款4.根据条款2或3所述的方法,其中导出所述一系列聚合物单元的估计值的步骤将表示是否允许或不允许标签之间的转换的转换矩阵考虑在内。
条款5.根据条款2到4中任一项所述的方法,其中所述一组标签包含关于每种类型的聚合物单元的第一标签和第二标签,所述第一标签表示所述类型的聚合物单元的实例的开始,并且所述第二标签表示所述类型的聚合物单元的所述实例中的停留,其中允许任何其它类型的聚合物单元从每个第一标签转换到所述第一标签,允许相同类型的聚合物单元从每个第一标签转换到所述第一标签,允许相同类型的聚合物单元从每个第一标签转换到所述第二标签,不允许任何其它类型的聚合物单元从每个第一标签转换到所述第二标签,允许相同类型的聚合物单元从每个第二标签转换到所述第一标签或允许任何其它类型的聚合物单元从每个第二标签转换到所述第一标签,并且允许相同类型的聚合物单元从每个第二标签转换到所述第二标签,并且不允许任何其它类型的聚合物单元从每个第二标签转换到所述第二标签。
条款6.根据条款2到5中任一项所述的方法,其中所述一组可能类型的聚合物单元包含总是以聚合物单元的已知序列出现的类型的聚合物单元,允许与所述已知序列一致的转换并且不允许与所述已知序列相反的转换。
条款7.根据条款2到6中任一项所述的方法,其中所述一系列聚合物单元中的相同类型的聚合物单元的连续实例以编码形式表示。
条款8.根据条款7所述的方法,其中所述标签包含关于每种类型的聚合物单元的多个标签,其中关于每种类型的聚合物单元的所述多个标签表示所述一系列聚合物单元中所述类型的聚合物单元的连续实例。
条款9.根据条款8所述的方法,其中用于每种类型的聚合物单元的所述多个标签具有预先确定的循环顺序,由此通过所述预先确定的循环顺序允许标签之间的一些转换并且通过所述预先确定的循环顺序不允许之间的其它转换,所述权重分布各自包含关于通过所述预先确定的循环顺序允许的标签的权重。
条款10.根据条款8或9所述的方法,其中用于每种类型的聚合物单元的所述多个标签是用于每种类型的聚合物单元的两个标签。
条款11.根据条款7所述的方法,其中所述一系列聚合物单元中的相同类型的聚合物单元的连续实例以游程长度编码形式表示。
条款12.根据条款11所述的方法,其中所述标签包含关于每种类型的聚合物单元的不同游程长度的多个标签。
条款13.根据条款11所述的方法,其中所述标签包含关于每种类型的聚合物单元的标签,并且对于每种类型的聚合物单元,所述权重分布包括在相同类型的聚合物单元的连续实例的可能长度上的另外的权重。
条款14.根据条款3所述的方法,其中对于每种类型的聚合物单元,所述另外的权重包括在相同类型的聚合物单元的连续实例的一组可能长度上的权重的分类分布。
条款15.根据条款13所述的方法,其中对于每种类型的聚合物单元,所述另外的权重包括在相同类型的聚合物单元的连续实例的连续实例的可能长度上的参数化分布的参数。
条款16.根据条款2到15中任一项所述的方法,其中所述可能类型的聚合物单元包含具有未修饰形式和经修饰形式的类型的聚合物单元。
条款17.根据条款16所述的方法,其中所述一组标签包含关于具有未修饰形式和经修饰形式的所述类型的聚合物单元的标签。
条款18.根据条款17所述的方法,其中对于具有所述未修饰形式和所述经修饰形式的所述类型的聚合物单元中的每个聚合物单元的所述未修饰形式和所述经修饰形式,每个权重分布包括另外的权重。
条款19.根据条款2到18中任一项所述的方法,其中所述一组标签包含至少一个表示每种类型的聚合物单元的标签。
条款20.根据前述条款中任一项所述的方法,其中所述一组标签进一步包含至少一个表示所述一系列聚合物单元中的空白和/或停留的标签。
条款21.根据前述条款中任一项所述的方法,其中所述机器学习技术是包括至少一个递归层的神经网络。
条款22.根据条款21所述的方法,其中所述至少一个递归层是双向递归层。
条款23.根据条款21或22所述的方法,其中所述神经网络相对于通过所述一系列权重分布的所有标签路径应用所述权重分布的全局归一化。
条款24.根据条款21到23中任一项所述的方法,其中所述神经网络包含至少一个卷积层,所述至少一个卷积层布置在所述至少一个递归层之前并且执行所述信号的加窗部分的卷积。
条款25.根据前述条款中任一项所述的方法,其中所述权重表示后验概率。
条款26.根据前述条款中任一项所述的方法,其中从所述权重分布导出所述一系列聚合物单元的估计值的步骤使用链结式时间分类执行。
条款27.根据前述条款中任一项所述的方法,其中从所述权重分布导出聚合物单元的估计值的步骤包括导出关于相应的权重分布的标签和对导出的标签进行游程长度压缩。
条款28.根据前述条款中任一项所述的方法,其中从所述权重分布导出所述一系列聚合物单元的估计值的步骤包括估计按所述权重分布计通过所述一系列权重分布的最可能标签路径并且从被估计为最可能的所述标签路径导出所述一系列聚合物单元的所述估计值。
条款29.根据前述条款中任一项所述的方法,其中从所述权重分布导出所述一系列聚合物单元的估计值的步骤包括估计关于每个权重分布最可能的所述标签、将通过所述一系列权重分布的前向和后向标签路径考虑在内并且从被估计为最可能的所述标签导出所述一系列聚合物单元的所述估计值。
条款30.根据前述条款中任一项所述的方法,其中所述纳米孔是蛋白孔。
条款31.根据前述条款中任一项所述的方法,其中所述聚合物是多核苷酸,并且所述聚合物单元是核苷酸。
条款32.根据前述条款中任一项所述的方法,其中所述信号从以下性质中的一个或多个的测量结果导出:离子电流、阻抗、隧穿性质、场效应晶体管电压和光学性质。
条款33.根据前述条款中任一项所述的方法,所述方法在计算机设备中执行。
条款34.根据前述条款中任一项所述的方法,其进一步包括在所述聚合物相对于纳米孔易位期间从所述聚合物导出所述信号。
- 还没有人留言评论。精彩留言会获得点赞!