一种RNA文库的构建方法及试剂盒与流程
本申请属于基因测序技术领域,更具体地说,它涉及一种rna文库的构建方法及试剂盒。
背景技术:
转录组测序技术,rna-seq是研究生物基因表达的重要工具,该技术广泛应用于不同物种的基因表达图谱分析中。近年来出现的rna-seq建库试剂盒主要侧重于rna链特异性研究,文库建库过程需要提取总rna,富集mrna,通过逆转录合成第一链cdna,使用dutp合成第二链cdna,随后进行双链cdna的末端补平、加腺嘌呤a碱基再进行接头连接,消化含尿嘧啶u碱基的cdna后通过pcr扩增完成建库。
其具体的建库过程如下:
(1)片段化rna,添加dutp合成双链cdna,通过尿嘧啶u碱基区分链特异性;
(2)对cdna进行末端补平修复及对cdna的3’端加腺嘌呤a碱基,保证cdna双链的3’端含有a碱基悬挂进而配合接头的3’端胸腺嘧啶t碱基实现ta连接完成建库;
(3)需要设计两条单链接头并退火形成双链,且含有硫代硫酸酯键修饰,保证接头t碱基不会脱落,才能进行有效接头连接;
(4)最后,在进行pcr之前还需对含有尿嘧啶u碱基的cdna第二链进行消化才能实现链特异性建库。
由于现有的流程需要先进行rna打断至小片段,再生成双链cdna后,最后进行双链的补平,加a,连接接头、扩增建库等步骤,所以流程较长,通常需要7~9个小时才能完成试验,建库效率低。
技术实现要素:
为了提高建库效率,本申请提供一种rna文库的构建方法,该方法能够简化建库的路程,通过两轮带有接头序列的cdna的合成,同步完成模板的逆转录和双端接头序列的引入,并完成模板的富集,实现了快速高效的建库。
本申请是通过以下方案实现的:
本申请提供了一种rna文库的构建方法,包括如下步骤:
采用第一引物逆转录总rna,得到第一链cdna,所述第一引物包括第一接头序列和随机序列;
纯化所述第一链cdna;
采用第二引物扩增所述第一链cdna,生成二链dna,所述第二引物包括第二接头序列和随机序列;
采用第三引物扩增所述二链dna得到rna文库。
本申请通过对完整的cdna模板进行逆转录,由于第一引物中的随机序列可以和模板进行多点的结合,获得了高于原始模板产量的cdna,且由于引物结合位点的随机性,每一条产物都具有不同的序列。
本申请中,通过纯化第一链cdna去掉残留的接头序列,以减少后续非特异性扩增,减少二聚体的产生。
在本申请的一个具体实施方式中,所述第二引物扩增所述第一链cdna时采用具有链置换功能的dna聚合酶。
本申请中,合成二链dna时,由于dna聚合酶具有高效的链置换活性,因此,一条cdna链可以合成多条不同长度的二链dna,且产物带有双端接头序列,无需再进行接头连接。
在本申请的一个具体实施方式中,所述dna聚合酶为phi29酶。
本申请中,由于随机序列的结合效率和模板长度呈正相关性,因此,不打断的rna可以产生更多的目的片段。
本申请中,通过第三引物扩增,对模板进行富集,同时,利用dna扩增的短片段扩增效率远高于长片段扩增效率的特点,对dna进行扩增,扩增产物以插入的小片段dna为主。产生的文库片段长度更适合用于ngs测序。
在本申请的一个具体实施方式中,所述第一引物的序列为acgctcttccgatct+nnnnnn,其中acgctcttccgatct为第一接头序列;n为a、t、c、g四种碱基的兼并碱基。本申请中,对第一接头序列不作限定,其可以根据测序平台自行设计。
在本申请的一个具体实施方式中,所述第二引物的序列为cgtatgccgtcttctgcttg+nnnnnn,其中cgtatgccgtcttctgcttg为第二接头序列;n为a、t、c、g四种碱基的兼并碱基。本申请中,对第二接头序列不作限定,其可以根据测序平台自行设计。
在本申请的一个具体实施方式中,所述第三引物包括上游引物和下游引物,所述上游引物从5’端至3’端依次包括:上游测序平台序列、第一文库标签序列以及上游测序引物序列,所述下游引物从5’端至3’端依次包括:下游测序平台序列、第二文库标签序列以及下游测序引物序列,其中,所述下游测序引物序列与所述第一引物的5’端的至少部分序列相同或互补,所述上游测序引物序列与所述第二引物的5’端的至少部分序列互补或相同。
在本申请的一个具体实施方式中,所述第三引物序列为:
上游引物:
gatcggaagagcacacgtctgaactccagtcacxxxxxxxxatctcgtatgccgtcttctgcttg;
下游引物:
aatgatacggcgaccaccgagatctacacxxxxxxxxacactctttccctacacgacgctcttccgatc,
其中xxxxxxxx为index序列。
在本申请的一个具体实施方式中,所述纯化为磁珠纯化。
在本申请的一个具体实施方式中,所述rna为总rna、mrna、lncrna或去除核糖体的rna。
本申请另一方面提供一种试剂盒,其包括上述所述的第一引物、第二引物和第三引物。
在本申请的一个具体实施方式中,所述试剂盒还包括逆转录酶和dna聚合酶。
在本申请的一个具体实施方式中,所述dna聚合酶为具有链置换功能的dna聚合酶。优选地,所述dna聚合酶为phi29酶。
本申请提供的rna文库的构建方法至少具有以下有益效果之一:
本申请提供的rna文库的构建方法,以完整的rna链为模板进行逆转录,无需将rna进行片段化,引物上直接连接有接头序列,无需后期再进行双端接头连接,而且该方法仅需要带有双端接头的单链,因此无论是扩增效率还是建库速度都大幅提升。
附图说明
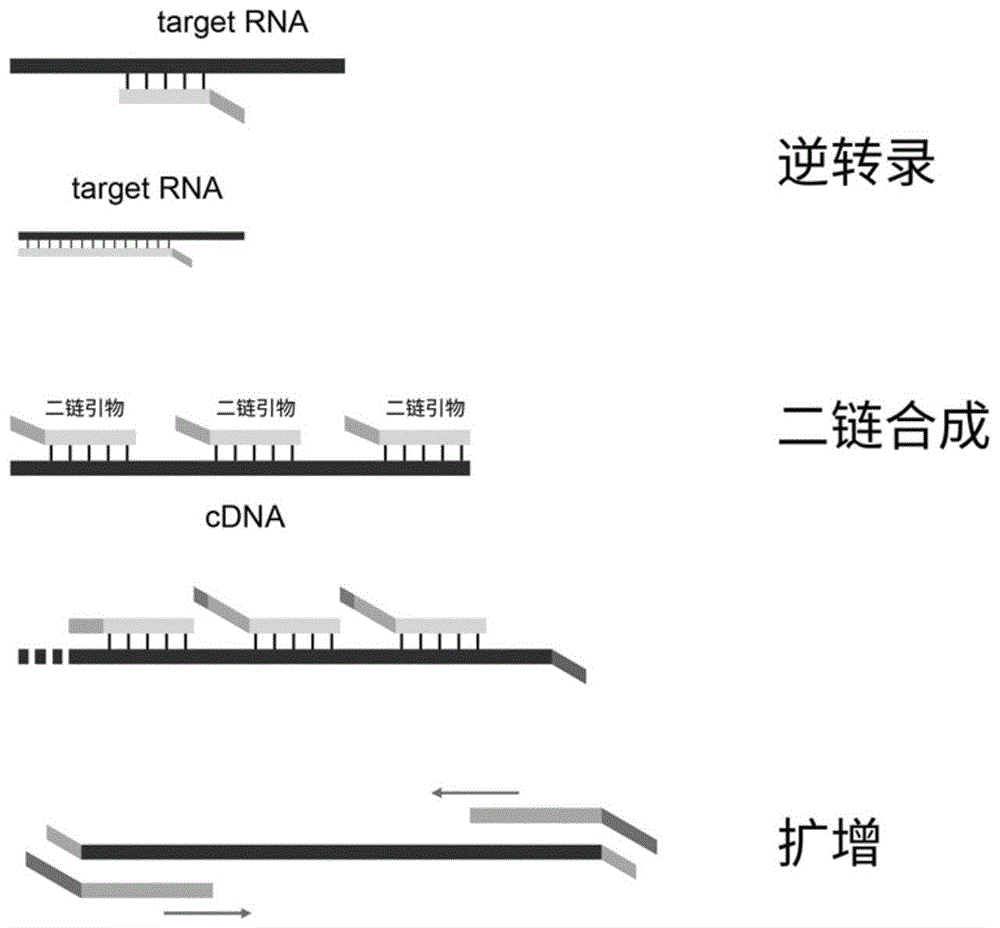
图1为本申请实施例中提供的构建rna文库的流程示意图。
图2为本申请实施例中提供的rna文库凝胶电泳图。
图3为本申请实施例中提供的rna第一链cdna产物和富集后的双链产物的对比结果图。
具体实施方式
除非另有定义,本申请中使用的所有技术和科学术语具有与本申请所述技术领域的普通技术人员通常理解的相同含义。
下面将结合本申请实施例,对本申请的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。实施例中未注明具体条件者,按照常规条件或制造商建议的条件进行。所用试剂或仪器未注明生产厂商者,均为可以通过市售购买获得的常规产品。
本申请中的rna文库的构建方法可以适用于总rna、mrna、lncrna或去除核糖体的rna。以下实施例中以总rna为例进行说明。
实施例1rna文库的构建
rna文库的构建示意图见图1所示。rna文库构建的步骤如下:如图1所示,通过带有第一接头序列的随机引物进行逆转录合成第一cdna链,然后加入带有第二接头序列的随机引物合成二链,再经过pcr扩增富集得到rna文库。具体过程如下:
1.逆转录:采用逆转录试剂盒(superscriptiv逆转录酶invitrogen,货号:18090200)逆转录总rna样本。
1.1按照下表1配制逆转录mix。
表1逆转录mix
第一引物的序列为acgctcttccgatct+nnnnnn,其中,acgctcttccgatct为第一接头序列,n为a、t、c、g四种碱基的兼并碱基。
1.2将逆转录mix置于pcr仪上,按照如下表2中的程序进行逆转录得到逆转录产物即第一链cdna。
表2逆转录反应程序
1.3采用vahtsdnacleanbeads(vahtsdna磁珠)试剂盒(诺唯赞,货号:n411)纯化逆转录产物。
在逆转录产物中加入30ulnuclearfree(简写nf)水,再加入1倍体积vahtsdna磁珠50ul,吸打混匀后静置5min,置于磁力架上至澄清,弃去上清。
使用200ul新鲜的80%乙醇清洗磁珠,清洗两次后,使用22ulnf水洗脱磁珠得到纯化后的逆转录产物;吸取20ul逆转录产物,加入20ul磁珠,吸打混匀后静置5min,置于磁力架上至澄清,弃去上清。再使用200ul新鲜的80%乙醇清洗磁珠,清洗两次后,使用12ulnf水洗脱磁珠得到纯化后的逆转录产物,吸取10ul逆转录产物进入后续试验。
2.二链合成
按照表3配制二链合成mix
表3二链合成mix
第二引物的序列为cgtatgccgtcttctgcttg+nnnnnn,其中cgtatgccgtcttctgcttg为第二接头序列,n为a、t、c、g四种碱基的兼并碱基。
将二链合成mix置于pcr仪上,42℃条件下进行孵育20分钟,65℃10分钟失活得到二链dna。
向二链dna中加入20ul磁珠,吸打混匀后静置5min,置于磁力架上至澄清,弃去上清;再使用200ul新鲜的80%乙醇清洗磁珠,清洗两次后,使用12ulnf水洗脱磁珠得到纯化后的二链产物,吸取10ul二链产物进入后续试验。
3.pcr扩增
向二链产物中加入1uludi引物(swiftuniquedualindexingudikit,cat.no.x9096)和4ulnf水,25ul高保真pcrmastermix(含有dna聚合酶)(kapahifipcrkit,kk2101),吸打混匀,按照表4程序进行pcr扩增得到扩增产物。
表4pcr扩增运行程序
udi引物中:
上游引物:
gatcggaagagcacacgtctgaactccagtcaccaacacagatctcgtatgccgtcttctgcttg
下游引物:
aatgatacggcgaccaccgagatctacacatgtgaagacactctttccctacacgacgctcttccgatc
其中带有下划线的部分为index序列。
向扩增产物中加入40ul磁珠,吸打混匀后静置5min,置于磁力架上至澄清,弃去上清。
使用200ul新鲜的80%乙醇清洗磁珠,清洗两次后,使用22ulnf水洗脱磁珠得到纯化后的rna文库。
对纯化的产物进行电泳,其结果如图2所示。从图2中可以看出,通过磁珠纯化,可以较好的将小片段进行去除,主要的文库长度集中在200~400bp区域,大片段由于扩增效率原因,产生的文库较少。
由上可见,本实施例中提供的rna文库的构建方法,全流程仅需3步扩增反应即可,操作简单,整体实验时间为4~4.5小时,整个建库所需时间缩短一半,而所构建的rna文库有利于后期的推广应用。
实施例2应用
使用两个人源rna(标记为1和2),利用其18s进行检测,分别对第一链cdna产物和富集后的双链产物进行扩增,结果如下表5和图3所示。
表5扩增结果对比
从表5和图3中可以看出,同样的模板,经过二链合成后,其产物经过扩增会有几倍的提升。
综上,本申请通过带有接头的随机引物进行扩增,放弃了传统的先合成双链,再进行双端接头连接方案,避免受到双链cdna产物每个环节产量呈数量级下降的缺点,进而影响建库的效率;而且通过带有接头的随机引物进行二链合成,并结合phi29酶的链置换特性,可以一次性在cdna模板上生成多个二链产物。
本具体实施例仅仅是对本申请的解释,其并不是对本申请的限制,本领域技术人员在阅读完本说明书后可以根据需要对本实施例做出没有创造性贡献的修改,但只要在本申请的权利要求范围内都受到专利法的保护。
序列表
<110>探因医学科技(浙江)有限公司
<120>一种rna文库的构建方法及试剂盒
<160>4
<170>siposequencelisting1.0
<210>1
<211>15
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>第一接头序列
<400>1
acgctcttccgatct15
<210>2
<211>20
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>第二接头序列
<400>2
cgtatgccgtcttctgcttg20
<210>3
<211>65
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>上游引物
<400>3
gatcggaagagcacacgtctgaactccagtcaccaacacagatctcgtatgccgtcttct60
gcttg65
<210>4
<211>69
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>下游引物
<400>4
aatgatacggcgaccaccgagatctacacatgtgaagacactctttccctacacgacgct60
cttccgatc69
- 还没有人留言评论。精彩留言会获得点赞!