多维度的用户驾驶行为分析方法与流程
本发明涉及驾驶行为分析领域,具体为一种多维度的用户驾驶行为分析方法。
背景技术:
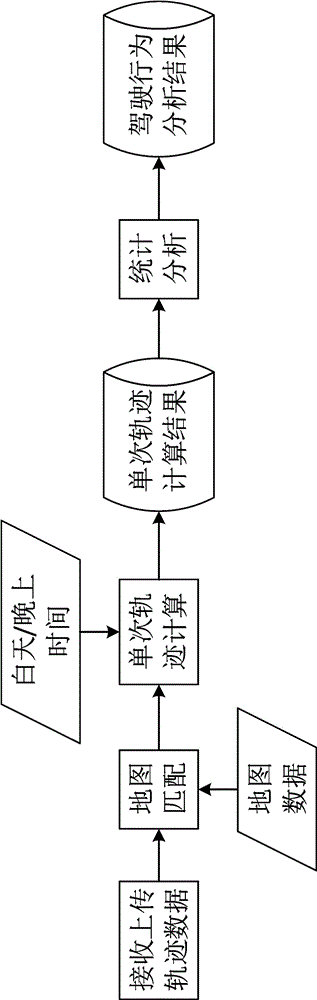
:目前,对驾驶员还没有结合时间段和路网中道路的各种属性信息,统计分析的结果只考虑行驶里程和时间,分析的维度单一,具有片面性,不能全面显示用户的驾驶行为特征。没有对用户的出行数据进行挖掘分析,进一步提炼用户的个性化数据,从而产生商业价值。技术实现要素:为了克服现有技术的缺陷,提供一种分析精确、适配性高的分析方法,本发明公开了一种多维度的用户驾驶行为分析方法。本发明通过如下技术方案达到发明目的:一种多维度的用户驾驶行为分析方法,其特征是:按如下步骤依次实施:接收用户轨迹数据:从数据源接入服务中实时获取用户轨迹数据,转换成程序内部的自定义格式并进行数据攒存,以备后面的处理所用。地图匹配:将用户轨迹的gps点通过地图匹配处理算法,匹配到道路上,还原用户的真实行驶路线,获取用户行驶的每条道路的属性,并且获得用户在每条道路上的进入时间、行驶时间和行驶距离等信息。单次轨迹计算:经过地图匹配后,用户在每条道路上的行驶信息和道路的属性信息就都得到了,同时实时接入每个城市的日出/日落时间,就可以计算出用户在该次行驶轨迹中的里程、时间、市区/郊区/高速/非高速等的行驶里程和行驶时间、早晚高峰/白天/晚上不同时间段的行驶里程和行驶时间等信息。同时将该信息写入数据库,以便后面的查询和统计分析。统计分析:按照天、月、年的时间周期,定时对用户的每次行驶轨迹的数据进行累加,就可以得到不同时间周期的用户驾驶行为统计结果,用于用户驾驶行为特征判断、用户常用行驶路线分析、用户出行地点的分析和保险数据的建模分析等等。车辆的车载终端通过包括gps模块在内的感应装置读取车辆的位置和状态信息,并定时向服务中心的网络层上传至少包括车辆id、驾驶员身份识别码、时间、里程、速度、gps有效性、怠速状态、急刹状态、acc状态、每分钟平均速度等状态信息的行驶数据等,后台的数据处理中心接收终端上传的数据,解析后存储在数据库中,数据库的统计模块根据行驶数据分别统计出最高速度、平均速度、急刹次数、行驶时长、超速次数、超速时长、疲劳驾驶次数、最长连续驾驶时间等用户的驾驶行为分析结果。本发明可通过地图匹配后获取用户行驶道路的路网属性及限速值,同时实时接入各城市的日出/日落时间,从多个维度进行用户出行特征的统计和分析,使得用户驾驶行为特征分析更细化更全面化。本发明可通过用户出行数据的挖掘分析,获取用户常用行驶路线,进而统计分析用户在常用行驶路线/陌生行驶路线下的行驶时间和里程。本发明可通过用户每次出行轨迹的起点、终点和在起点/终点的poi位置的停留时间长短的统计分析,生成用户标签,为用户个性化服务提供数据基础。本发明结合时间段和基础地图数据提供的道路属性,对用户的行驶里程和行驶时间进行分类统计,同时结合用户自己的行驶速度,计算其超速行驶的里程和时间,从而全面地判断用户的驾驶行为特征。同时对用户的海量出行数据进行挖掘分析,进一步提炼用户的个性化数据。综合用户驾驶行为数据和个性化数据,为保险建模分析和用户个性化服务提供数据基础,同时通过生成的用户标签,向用户推送其感兴趣的广告、新品上市等信息,充分挖掘大数据的商用价值。本发明具有如下有益效果:1.由于采用了地图匹配的处理功能,使得用户驾驶行为分析不受终端设备数据采集缺陷的影响,只要有gps位置信息,就可以通过地图匹配,获得车辆的行驶轨迹,从而计算用户的行驶里程、行驶时间和速度、平均速度、最大速度等,从而大大增加了采集用户轨迹数据的来源,同时由于终端采集设备的功能简单,也减少了数据采集终端的硬件成本和软件开发成本,大大增加了设备的普适性。2.由于从多个维度(空间、时间等)对用户的出行特征进行统计分析,使得用户驾驶行为特征分析更细化更全面化,为用户保险建模分析和用户个性化服务提供了坚实的数据基础,从而带来了更大的商用价值和应用。3.通过用户每次出行轨迹的起点、终点和在起点/终点的poi位置的停留时间长短的统计分析,进而可以分析出用户是什么类型的人群,生成用户标签。根据用户标签类型,就可以向用户推送其感兴趣的广告、新品上市等信息,从而带来巨大的商用价值。附图说明图1是本发明的流程示意图,图2是本发明运行时用户保险和驾驶行为分析数据的计算模型图。具体实施方式以下通过具体实施例进一步说明本发明。实施例1一种多维度的用户驾驶行为分析方法,主要是通过用户行驶轨迹数据接收、地图匹配、轨迹结算和统计分析,从多个维度进行全面分析,获取用户的驾驶行为和出行行为特征,为保险建模分析、用户分类进行个性化服务推送提供数据基础。如图1所示:1.接收用户轨迹数据:用户驾驶行为分析主程序从数据源接入服务中实时获取自己需要的用户轨迹数据,转换成内部高效计算的数据格式并积攒数据。通过对用户一次行驶轨迹的开始和结束判断标准,将用户该次行驶轨迹的所有数据打包进行后续处理。用户一次行驶轨迹的开始和结束判断标准如下:(1)如有明确的点火和熄火标志,就将点火时间和熄火时间之间的所有gps点作为用户的一次行驶轨迹。(2)用户导航开始和导航结束间的所有gps点作为用户的一次行驶轨迹。(3)如果没有1和2的判断标志,就以轨迹中连续两gps点时间间隔大于n分钟(比如15分钟)进行判断,如超过该设定阈值,就将前面的所有gps点作为用户的一次行驶轨迹。2.地图匹配:由于用户行驶时会出现跨城市,所以需要进行全国地图的道路匹配,考虑到用户轨迹数据量会越来越大和全国地图需要占用大量内存,需要将地图匹配做成服务的方式,方便用计算机集群进行分布式的地图匹配。这样可以减少主程序的内存和计算压力,也可以减少不同功能之间的耦合度,方便维护和扩展。主程序将积攒的用户每一次行驶轨迹的所有gps点传输给地图匹配服务进行处理。首先对gps点序列按照时间的先后顺序进行排序,并对gps点进行异常数据处理,比如时间重复gps点过滤、堆积点变成一个gps点进行处理等。然后进行单点地图匹配,获取每个gps点的多条候选道路,根据gps点方向与行驶道路的夹角和gps点距离候选道路的距离进行权重计算,获取每条候选道路的选中权重。再经过两两gps点的路径推测,其中需要考虑道路的连通性和匹配绕路错误。推测完后进行路径回溯,获取用户行驶的所有道路。同时计算用户行驶的每条道路的进入时间、行驶时间和行驶距离,还有每条道路的道路等级、长度、市区/郊区标识、高速/非高速标识、每条道路的限速值、用户每次行驶轨迹的起始点和终止点分别对应的poi信息等内容。地图匹配的处理流程具体如下:(1)gps点预处理:将车辆轨迹数据按gps时间进行排序,对异常gps点进行过滤,同时对堆积点和来回跳点进行处理,同时对gps方向进行修正,保证后续处理的轨迹是正常的。(2)gps点抓路获取候选link:先进行单点匹配,获取gps点的多条候选link,同时计算每条候选link的可信度,可信度计算方法有两种,具体如下:i.根据距离和方向进行计算:根据gps方向和gps点到候选link的距离计算权重,如(a)式所示:(a)式中,wd+wθ=1;当候选道路过多时,wd=0.4,wθ=0.6,否则wd=0.6,wθ=0.4;di、θi分别为gps点到候选link的距离及gps点方向与候选link方向的夹角;dmax、θmax分别为设定的最大距离和最大角度阈值;λi越小,表示该候选link的选中权重越高,反之越低。ii.只根据距离计算:基于gps坐标点和投影点之间的距离计算匹配的概率,一般来说该距离满足正态分布n(μ,σ2),如(b)式所示:(b)式中,μ=0,σ=30m~60m,综合考虑gps精度和道路宽度;i指第i个gps点,j指第j个候选link。上述两种方法需要根据实际情况使用。当速度偏高时,用第二种方法计算的概率可信度更高,同时结合第一种方法计算的概率,主要是参考gps方向的影响。(3)路径推测:由于gps点的频率较高,两gps点间的行驶距离较短,几乎是直线。所以用两gps点间的直线距离和两gps点间在候选link上的投影距离进行比较,误差在10%(参数可调)内的,认为该link就是当前gps点的匹配link,投影点坐标即为该gps点在行驶link上的位置。另外,两个gps点间隔1秒,大部分是在同一条link上,即使是跨link的话,基本上都是相连的后续link。根据link的拓扑关系和下一个gps点的候选link是否相同,从而确定车辆转弯时的用户行驶路径。根据多个连续gps点的候选link的相同性,确定这些gps点的共同候选link就是用户的行驶link。对于平行路,可能存在两条link,这个需要通过后续gps点的行驶link和该link的拓扑关系进行判断,加上速度和道路等级的判断,选取概率较高的行驶路径作为用户的最终路径。地图匹配的正确率对驾驶行为分析的准确性至关重要,用不同城市的不同轨迹数据进行了测试,该算法的匹配准确率如下:城市轨迹数量(条)正确率p(%)北京41394.29%上海40894.78%广州25992.51%深圳27893.79%。3.单次轨迹计算:经过地图匹配后,用户在每条道路上的行驶信息和道路的属性信息就都得到了,同时实时接入每个城市的日出/日落时间,就可以计算出用户在该次行驶轨迹中的里程、时间、市区/郊区/高速/非高速等的行驶里程和行驶时间、早晚高峰/白天/晚上不同时间段的行驶里程和行驶时间等信息,同时将该信息写入数据库,以便后面的查询和统计分析。主要的内容包含:行驶里程、行驶时间、平均速度、最大速度、市区/郊区的行驶里程和时间、高速/非高速的行驶里程和时间、早晚高峰/白天/晚上不同时间段的行驶里程和行驶时间、用户超限速值行驶的次数及里程和时间等。(1)用户在每条道路上的行驶距离之和即为用户该次轨迹的行驶里程,行驶时间计算方法相同。由于用户行驶的每条道路都有属性,比如市区/郊区标识、高速/非高速标识、限速值等,那么该用户在所有市区标识道路上的行驶距离之和即为用户该次行驶轨迹中的市区行驶里程,行驶时间之和即为用户该次行驶轨迹中的市区行驶时间,郊区的行驶里程和时间、高速/非高速的行驶里程和时间的计算方法相同。(2)系统中实时接入各城市每天的日出/日落时间,同时根据用户出行轨迹的大数据挖掘定义每个城市的早晚高峰时间段,从而将用户的出行时间分为早晚高峰、白天、晚上三个时间段。根据用户每次行驶轨迹中相邻两gps点涉及道路或部分道路的进入时间为基准,和早晚高峰、白天、晚上三个时间段进行判断,将所属时间段上用户的行驶时间和里程分别相加,就可以得到用户在一次行驶轨迹中在不同时间段的行驶时间和里程。(3)超速行驶是指用户自己驾车行驶时在每条道路上的平均速度超过该道路的限速值,具体判断标准如下:一般超速:1.2v限速<v车<=1.5v限速,严重超速:v车>1.5v限速。根据用户在每条道路上行驶的速度和该道路的限速值进行比较,将不同超速程度下每条道路上行驶的里程和时间进行累加,就可以得到用户该次行驶轨迹在不同超速程度下的超速行驶的次数、里程和时间。同时结合道路的市区/郊区、高速/非高速的路网属性,可以计算出用户在市区/郊区、高速/非高速等不同道路属性上的超速次数、行驶里程和时间。4.统计分析:按天统计的数据一般放在凌晨进行,通过数据源id、用户id作为关键key,将相同key的同一天数据进行累加即可以得到每个用户一天的驾驶行为统计结果。按月、年时间周期的统计项和按天统计的数据一样,在更新天表的时候同时更新月表、年表。5.数据挖掘分析:基于用户长时间的出行统计数据进行数据挖掘,可以获取用户的熟悉路线及在熟悉路线上行驶的时间和里程;根据用户每次出行轨迹的起始点所对应的poi信息计算用户在不同位置的停留时间,从而分析出用户是什么类型的人群,生成用户标签。(1)用户在两点(出行起点和终点)之间(家庭和公司之间、家庭和购物场所之间等)出行的行驶路径一般不多,只有固定的几条路线。根据用户每次的行驶轨迹起点、终点坐标及对应的poi信息和中间经过的道路,统计分析出其几个固定地点及这些地点之间的行驶路线,比如家、公司、购物场所、娱乐场所、餐饮餐所、汽车4s店等,通过这些信息就可以将熟悉路线提炼出来。有了这个判断标准,就可以统计分析出用户每次行驶轨迹中的道路是属于熟悉路线还是陌生路线,从而计算出各自条件下的行驶时间和里程以及各自所占比例。具体示例如下:路线时间(hour)时间比例里程(km)里程比例熟悉路线7077.8%170063.0%陌生路线2022.2%100037.0%。(2)一般情况下,用户在家庭停留时间在晚间,在公司停留时间在周一~周五的白天,在餐饮场所停留时间在中餐或晚餐时间,在娱乐场所停留时间在周末或者周一~周五的晚间,购物场所停留时间在周末。根据上述基本规律,通过用户停车时间长短(在上述场所车辆会熄火,时间较长)及地图poi信息(写字楼、居民小区、购物场所、餐饮场所、娱乐场所等)的大数据分析,可以挖掘出用户在上述地点的停留时间、次数及比例,进而可以分析出用户是什么类型的人群,生成用户标签。根据用户标签类型,就可以向用户推送其感兴趣的广告、新品上市等信息。比如:经常去汽车4s店就表示该用户有买车的意向;经常去售楼处就表示该用户有买房的意向。下面是一个用户1个月(30天)在不同场所停留时间、次数及驾驶时间的分布示例:位置时间(hour)时间比例次数次数比例家庭27037.5%6027.0%公司20027.8%4219.0%购物场所405.5%209.0%娱乐场所304.2%209.0%餐饮场所506.9%4018.0%汽车4s店202.8%209.0%售楼处202.8%209.0%…………………………驾驶出行9012.5%111100%每次行驶轨迹的起点和终点各算1次,比如家->公司->4s店->家,那么家、公司和4s店就各为2次。经过用户出行数据的统计分析和数据挖掘分析,就可以进行用户驾驶行为特征判断、用户保险数据的建模分析、用户个性化服务推送等等。其中,用户保险和驾驶行为分析数据的计算模型如图2所示。用户个性化服务推送就是根据大量数据进行驾驶行为分析后得到的用户标签(比如:上班族、汽车发烧友、购物达人等),通过第三方软件(比如app)进行消息发布,推送给相关用户群体。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1