一种基于LKJ列控运行文件数据的多维度异常点识别方法及系统与流程
本发明涉及lkj运行文件数据异常事件检测领域,特别涉及一种基于lkj列控运行文件数据的多维度异常点识别方法及系统。
背景技术:
目前基于lkj运行记录数据文件的车载设备故障分析工作仍然是借助于人工凭借现场经验来判断,或者是采用故障维修中的替换法,对认为可能发生故障的部件进行依次更换来找到故障点。这种方法对分析人员的经验依赖程度高,定位故障原因的时间较长,工作效率低,此外,对于人工分析lkj运行记录数据来讲,由于一次行车所产生的lkj记录数据一般在上千甚至上万条,因而分析人员劳动强度大,分析时容易出错。
技术实现要素:
本发明的主要目的在于提供一种基于lkj列控运行文件数据的多维度异常点识别方法及系统,可以有效解决背景技术中的问题。
为实现上述目的,本发明采取的技术方案为:
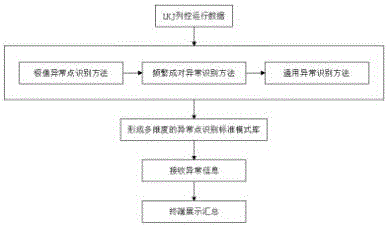
一种基于lkj列控运行文件数据的多维度异常点识别方法及系统,包括多维度的考察lkj运行文件中的异常事件,所述考察步骤包括:
s1:形成多维度的异常点识别方法,方法包括极值异常点识别方法、频繁成对异常识别方法、通用异常识别方法;
s2:将多维度的异常点识别方法应用于一定时间窗口的lkj运行文件数据,形成多维度的异常点识别标准模式库,用于日常lkj运行文件的实时监控;
s3:对于日常lkj运行文件数据,将其与多维度的异常点识别标准模式库进行匹配,输出异常;
s4:连接可视化终端,对异常事件结果进行汇总展示。
优选的,综合多维度的分析方法,全面的捕获lkj列控运行文件异常事件,包括以下步骤:
a1)、极值异常点识别方法,有些事件本身就是一个异常,这些事件发生的次数很少,所以可以简单统计一下所有事件发生的次数,将发生次数较少的事件挑出来,里面可能就包含了故障或异常事件,包括以下步骤:
(1)对所有数据中的事件进行频率统计;
(2)按照频率高低排序;
(3)输出排完序的事件及相对应的频率列表;
(4)频率比较低(确定阈值1%)的事件经专家确认后列入异常模式库;
a2)、频繁成对异常识别方法,有些事件在一段行程中应该是成对或是形成一个组合一起出现,包括以下步骤:
(1)统计各种事件在每个文件中出现的次数;
(2)将每个文件中出现次数相同的事件放入同一集合中;
(3)运行频繁模式挖掘算法(spark的mllib提供了fpgrowth算法,需要设定support参数和confidence参数),输出频繁子集,也就是应该一起发生的事件组合,经专家确认后存入频繁模式库;
a3)、通用异常识别方法,每个运行记录文件都有一些必然要记录的事件,即必然发生的事件,称为通用模式,如果一个运行文件缺失这些事件,则是有异常发生,包括以下步骤:
(1)遍历同一车型所有文件,一个事件如在一个文件中出现,则计数加1;
(2)在大部分文件(如95%)中出现的事件经专家确认后存入通用模式库。
优选的,形成多维度的异常点识别标准模式库,用于日常lkj运行文件的实时监控,包括以下步骤:
b1)、形成极值异常点识别模式库;
b2)、形成频繁成对异常识别模式库;
b3)、形成通用异常识别模式库。
优选的,根据多维度的异常点识别标准模式库,拦截lkj运行文件中的异常事件,包括以下步骤:
c1)、运行文件中如识别到极值异常点识别模式中的事件即作为异常拦截。
c2)、对于频繁成对异常识别模式库中的每一个事件组合,统计运行文件中各个组合所包含的事件出现的次数,如果同个组合中的事件出现次数不相等,则作为异常拦截。
c3)、对于一个新的运行文件,确认其车型,如果没有包含通用异常识别模式库中的事件,则识别为异常。
优选的,所述终端展示汇总分车型、车号、时间等维度对异常事件进行频次统计,或对一段时间内的异常事件频次进行趋势统计、阈值预警等。
与现有技术相比,本发明具有以下有益效果:
本发明中,通过将多角度的异常识别方法与lkj运行文件的事件信号进行结合,实现异常事件的捕获,既可以通过捕获的异常事件定位故障原因,也可以在整体上把握异常事件发生趋势、发生总况,同时也可以结合车型、车号等分类指标,分类查看异常情况,辅助工作人员迅速排查异常,提高异常诊断效率。
附图说明
图1是本发明的系统流程图。
具体实施方式
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
实施例:
如图1所示,一种基于lkj列控运行文件数据的多维度异常点识别方法及系统,将多角度的异常识别方法与lkj运行文件的事件信号进行结合,实现异常事件的捕获,包括以下步骤:
s1:形成多维度的异常点识别方法,方法包括极值异常点识别方法、频繁成对异常识别方法、通用异常识别方法,确定一段历史时间lkj运行文件数据(这里采用半年数据),对于不同的异常识别方法,设计不同的分析步骤。
首先是极值异常点识别方法,有些事件本身就是一个异常,例如“速度骤降”,这些事件发生的次数很少,所以可以简单统计一下所有事件发生的次数,将发生次数较少的事件挑出来,里面可能就包含了故障或异常事件,包括以下步骤:
(1)对所有数据中的事件进行频率统计;
(2)按照频率高低排序;
(3)输出排完序的事件及相对应的频率列表;
(4)频率比较低(确定阈值1%)的事件经专家确认后列入异常模式库。
其次是频繁成对异常识别方法,有些事件在一段行程中应该是成对或是形成一个组合一起出现,包括以下步骤:
(1)统计各种事件在每个文件中出现的次数;
(2)将每个文件中出现次数相同的事件放入同一集合中;
(3)运行频繁模式挖掘算法(spark的mllib提供了fpgrowth算法,需要设定support参数和confidence参数),输出频繁子集,也就是应该一起发生的事件组合,经专家确认后存入频繁模式库。
最后是通用异常识别方法,每个运行记录文件都有一些必然要记录的事件,即必然发生的事件,称为通用模式,如果一个运行文件缺失这些事件,则是有异常发生,包括以下步骤:
(1)遍历同一车型所有文件,一个事件如在一个文件中出现,则计数加1;
(2)在大部分文件(如95%)中出现的事件经专家确认后存入通用模式库。
s2:将多维度的异常点识别方法应用于一定时间窗口的lkj运行文件数据,形成多维度的异常点识别标准模式库,用于日常lkj运行文件的实时监控,实际过程中,将定月重复101过程,实现对多维度异常识别标准模式库的定时更新。
s3:对于日常lkj运行文件数据,将其与多维度的异常点识别标准模式库进行匹配,输出异常,具体识别方法以下:
(1)如识别到极值异常点识别模式中的事件即作为异常拦截;
(2)对于频繁成对异常识别模式库中的每一个事件组合,统计运行文件中各个组合所包含的事件出现的次数,如果同个组合中的事件出现次数不相等,则作为异常拦截;
(3)对于一个新的运行文件,确认其车型,如果没有包含通用异常识别模式库中的事件,则识别为异常;
实际上,可以根据实际需求,逐天、周、月将新的lkj运行文件数据与固定的异常点识别标准模式库进行匹配。
s4:连接可视化终端,对异常事件结果进行汇总展示,如对lkj系统故障/异常事件进行总体统计lkj系统故障/异常事件在不同车型上分布,同一机车lkj系统故障/异常事件分布,lkj系统故障/异常事件趋势分析。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!