一种生活垃圾燃烧发电优化系统、方法及存储介质与流程
本发明涉及生活垃圾燃烧发电时的锅炉控制技术领域,具体涉及一种生活垃圾燃烧发电优化系统、方法及存储介质。
背景技术:
在垃圾燃烧发电时,锅炉燃烧过程是一个复杂的物理化学过程。以往针对工业锅炉设备,进行燃烧优化,通常采取项目制的形式,从前期的项目调研、数据采集、poc分析,再到后续的应用开发、算法开发,均需要根据具体的业务需求进行定制化。现阶段由于设备控制的复杂性,垃圾成分复杂性导致的在燃烧过程的较大波动性,需要人工大量介入控制锅炉燃烧过程,而且在异常的情况(如垃圾没有进料)人工通常不能进行及时调整,不利于生产稳定性。
技术实现要素:
鉴于以上技术问题,本发明的目的在于提供一种生活垃圾燃烧发电优化系统、方法及存储介质,解决现有锅炉燃烧过程需要大量人工介入,而且人工通常不能进行及时调整,不利于生产稳定性的问题。
本发明采用技术方案如下:
一种生活垃圾燃烧发电优化方法,包括:
实时获取锅炉设备测点的特征变量数据,所述特征变量数据基于锅炉设备测点数据得到;获取工业预测模型引擎,所述工业预测模型引擎通过多种回归算法建立,所述工业预测模型引擎的特征输入值为某刻特征变量数据,所述工业预测模型引擎的输出为该刻90s后的预测蒸汽量;
获取控制引擎模型,所述控制引擎模型通过pid控制算法以及深度强化学习算法建立,所述控制引擎模型的模型动作变量中的推料时间上下限和控制引擎模型的微分、积分和比例算法参数根据设定时间内蒸汽量的平均值设定;计算所述该刻90s后的预测蒸汽量与该刻实时蒸汽量的偏差,所述偏差为所述控制引擎模型的输入,所述控制引擎模型的输出为推荐进料时间间隔;
根据控制引擎模型推荐进料时间间隔,输出推荐推料时间,在达到推荐推料时间时,发出推料指令。
进一步的,所述设定时间为半个小时,蒸汽量均值是53.4t/h。
进一步的,根据设定时间蒸汽量的平均值,设置控制引擎模型的模型动作变量中的推料时间上下限和控制引擎模型的微分、积分和比例算法参数的步骤具体包括:
当半个小时蒸汽量的平均值小于等于50t/h时,垃圾的可燃性为低,设置控制引擎模型的模型动作变量中的推料时间上限为780s,下限为240s;优化控制模型的比例,积分,微分参数分别设置为-100,-10,-30;
当半个小时的蒸汽量的平均值大于50t/h且小于等于55t/h时,垃圾的可燃性为中,设置控制引擎模型的模型动作变量中的推料时间上限为780s,下限为200s;当前蒸汽量减去预测90s蒸汽量值小于等于3.1t/h时,优化控制模型的比例,积分和微分参数分别是-120,-50,-80;当前蒸汽量减去预测90s蒸汽量值大于等于3.1t/h时,控制引擎模型比例,积分和微分参数分别是-100,-20,-50;
当半个小时的蒸汽量的平均值大于55t/h时,垃圾的可燃性为高,设置控制引擎模型的模型动作变量中的推料时间上限为1200s,下限为200s,优化控制模型的比例,积分和微分参数分别设置为-150,-60,-90。
进一步的,当推料间隔小于200s的时候,控制引擎模型的比例,积分和微分参数分别设置为-80,-10,-30。
进一步的,获取锅炉设备测点的特征变量数据步骤包括:
通过dcs工业数据采集系统通过锅炉传感器采集锅炉设备的全部测点数据,所述dcs工业数据采集系统将所述锅炉设备测点数据发送给现场opc服务器,所述opc服务器配置锅炉的全部测点变量名,选取若干测点数据通过差分方式作特征衍生,将进行特征衍生后的数据作为特征进行训练,得到锅炉设备测点的特征变量数据;所述现场opc服务器将所述特征变量数据发送给中心服务器。
进一步的,还包括:当蒸汽量小于51t/h时,限定推料时间间隔的最小间隔时间;
当风室风压大于2.3kpa,延迟30秒进料;若预测蒸汽量大于等于56t/h时,延迟20s进料。
进一步的,当蒸汽量大于58t/h,氧气浓度小于4%,一次风出口压力为2.5kpa时,
当垃圾可燃性为高时,推荐一次风温为130℃;
当垃圾可燃性为中时,推荐一次风温为150℃;
当垃圾可燃性为低时,推荐一次风温为175℃。
进一步的,通过et工业大脑获取工业预测模型引擎和控制引擎模型。
一种生活垃圾燃烧发电优化系统,包括dcs工业数据采集系统、现场opc服务器、中心服务器和et工业大脑;
所述dcs工业数据采集系统用于通过锅炉传感器采集锅炉设备的全部测点数据,所述dcs工业数据采集系统将所述锅炉设备测点数据发送给现场opc服务器;
所述opc服务器配置锅炉的全部测点变量名,所述现场opc服务器用于将所述锅炉设备测点数据发送给中心服务器;
所述et工业大脑包括工业预测模型引擎和控制引擎模型,所述工业预测模型引擎通过多种回归算法建立,所述工业预测模型引擎的特征输入值为所述特征变量数据,所述工业预测模型引擎的输出为某刻90s后的预测蒸汽量;所述控制引擎模型通过pid控制算法以及深度强化学习算法建立,所述控制引擎模型的模型动作变量中的推料时间上下限和控制引擎模型的微分、积分和比例算法参数根据设定时间内蒸汽量的平均值设定;所述控制引擎模型的输入为所述某刻90s后的预测蒸汽量与该刻实时蒸汽量的偏差,所述控制引擎模型的输出为推荐进料时间间隔;
所述中心服务器用于选取若干测点数据通过差分方式作特征衍生,将进行特征衍生后的数据作为特征进行训练,得到锅炉设备测点的特征变量数据,并将所述特征变量数据发送给et工业大脑,并根据控制引擎模型推荐进料时间间隔,输出推荐推料时间,并在达到推荐推料时间时,发出推料指令。
一种计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现所述的生活垃圾燃烧发电优化方法。
相比现有技术,本发明的有益效果在于:
本发明获取锅炉设备测点的特征变量数据,并建立对应的燃烧优化控制算法,根据工业预测模型引擎和控制引擎模型燃烧推荐进料时间间隔,输出推荐推料时间,能实现稳定锅炉燃烧和控制自动化。进一步的,通过调整工业预测模型引擎和控制引擎模型的参数得出最合适的模型,大大减少了人工干预操作,提高了生产的稳定性。
附图说明
图1为本发明一种生活垃圾燃烧发电优化方法流程示意图;
图2为本发明一种生活垃圾燃烧发电优化系统的结构示意图;
图3为本发明的一种生活垃圾燃烧发电优化系统的原理示意图;
图4为本发明一种生活垃圾燃烧发电优化系统应用实施例的结构示意图;
图5为本发明实施例中测点数据通过差分方式进行特征衍生的流程示意图;
图6为本发明一种生活垃圾燃烧发电优化系统工作时的系统界面图;
图7为本发明实施例中通过阿里云销售网站获取et工业大脑平台的示意图;
图8为本发明实施例中采用et工业大脑时输出试验数据的流程示意图;
图9为本发明实施例中采用控制引擎模型控制的界面示意图;
图10为本发明实施例中蒸汽量的时序图和月蒸汽量分布图;
图11为本发明实施例中蒸汽量的数据分布图;
图12为本发明实施例蒸汽量、氧量和推料时间的相关性示意图;
图13为本发明实施例中控制引擎模型功能框图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
实施例:
请参考图1-12所示,一种生活垃圾燃烧发电优化方法,如图1所示,包括:
步骤s10:实时获取锅炉设备测点的特征变量数据,所述特征变量数据基于锅炉设备测点数据得到;获取工业预测模型引擎,所述工业预测模型引擎通过多种回归算法建立,所述工业预测模型引擎的特征输入值为某刻特征变量数据,所述工业预测模型引擎的输出为该刻90s后的预测蒸汽量;
步骤s20:获取控制引擎模型,所述控制引擎模型通过pid控制算法以及深度强化学习算法建立,所述控制引擎模型的模型动作变量中的推料时间上下限和控制引擎模型的微分、积分和比例算法参数根据设定时间内蒸汽量的平均值设定;计算所述该刻90s后的预测蒸汽量与该刻实时蒸汽量的偏差,所述偏差为所述控制引擎模型的输入,所述控制引擎模型的输出为推荐进料时间间隔;
步骤s30:根据控制引擎模型推荐进料时间间隔,输出推荐推料时间,在达到推荐推料时间时,发出推料指令。
本发明的一种生活垃圾燃烧发电优化系统,如图2所示,生活垃圾燃烧发电优化系统,包括dcs工业数据采集系统、现场opc服务器、中心服务器和et工业大脑;本发明的一种生活垃圾燃烧发电优化系统的原理示意图如图3所示,收集的数据通过机器学习算法预测,并输出优化控制参数。
具体的,所述dcs工业数据采集系统用于通过锅炉传感器采集锅炉设备的全部测点数据,所述dcs工业数据采集系统将所述锅炉设备测点数据发送给现场opc服务器;
所述opc服务器配置锅炉的全部测点变量名,所述现场opc服务器用于将所述锅炉设备测点数据发送给中心服务器;
所述et工业大脑包括工业预测模型引擎和控制引擎模型,所述工业预测模型引擎通过多种回归算法建立,所述工业预测模型引擎的特征输入值为所述特征变量数据,所述工业预测模型引擎的输出为某刻90s后的预测蒸汽量;所述控制引擎模型通过pid控制算法以及深度强化学习算法建立,所述控制引擎模型的模型动作变量中的推料时间上下限和控制引擎模型的微分、积分和比例算法参数根据设定时间内蒸汽量的平均值设定;所述控制引擎模型的输入为所述某刻90后的预测蒸汽量与该刻实时蒸汽量的偏差,所述控制引擎模型的输出为推荐进料时间间隔;
所述中心服务器用于选取若干测点数据通过差分方式作特征衍生,将进行特征衍生后的数据作为特征进行训练,得到锅炉设备测点的特征变量数据;并根据控制引擎模型推荐进料时间间隔,输出推荐推料时间,并在达到推荐推料时间时,发出推料指令。
具体的,本发明的系统应用实例如下:
如图4,通过锅炉传感器上传数据到dcs工业数据采集系统,然后在电厂现场站布置一台opcserver服务器,该服务器安装部署了wincc过程监视系统的opc服务器,并配置了所需的全部锅炉的测点变量名。
在该服务器上同时部署famedataserver软件,根据所配置测点变量名,通过opc驱动获取wincc过程监视系统所配置的变量点的数据。至此,数据已经由wincc过程监视系统采集至famedataserver软件,现场站opc服务器上的数据需要通过famedataserver软件的adsl线路服务来传输至电厂中心机房服务器,在adsl线路服务中设置连接的中心服务器的ip地址以及端口号,会每2秒将数据包传输到中心服务器,中心服务器接收到现场站上传的数据,进行汇总成具体变量内容。最终通过运行阿里云提供的脚本文件,把中心服务器数据上传至阿里云datahub数据处理平台和阿里云工业大脑,同时,通过阿里云dataconnector数据同步工具,测点数据备份至阿里云maxcompute大数据服务平台,实现长期存储。
数据上云后,选取若干测点数据通过差分方式作特征衍生,将进行特征衍生后的数据作为特征进行训练,得到锅炉设备测点的特征变量数据的步骤具体如下:
首先要,从锅炉设备所涉及的三百多个变量中,根据实际生产中有较明显的呈现正负相关的一些测点数据,挖掘数据中的重要特征和相互关系,主要方法有:(1)通过业务人员的焚烧经验,(2)绘制各个测点之间的相关性图像,如绘制蒸汽量的时序图和月蒸汽量分布图如图10所示,蒸汽量的数据分布图如图11所示,通过图11可查看蒸汽量的均值,标准差和分布图像,(3)绘制多个变量测点之间的图像来查看相关性,如图12所示,图12是比较蒸汽量、氧量和推料时间的相关性,通过图12可知道氧气和蒸汽量有一定的负相关性(4)通过特征衍生等方法找出一些特征。如建模方法:差分建模。生产人员总结出哪些测点数据对模型影响较大的点位数据做差分,如图5所示,通过差分的形式进行特征衍生,分别用10s前数据和当前数据得到差值1,用20s前数据和10s前数据得到差值2…等等,生产人员总结出的如一次风出口压力,一次风室压力,省煤器氧量,推料器正在前进信号等68个特征,将这些特征对应的测点数据作为特征进行训练,如一次风出口压力,一次风室压力,省煤器氧量,推料器正在前进信号等68个特征变量数据。
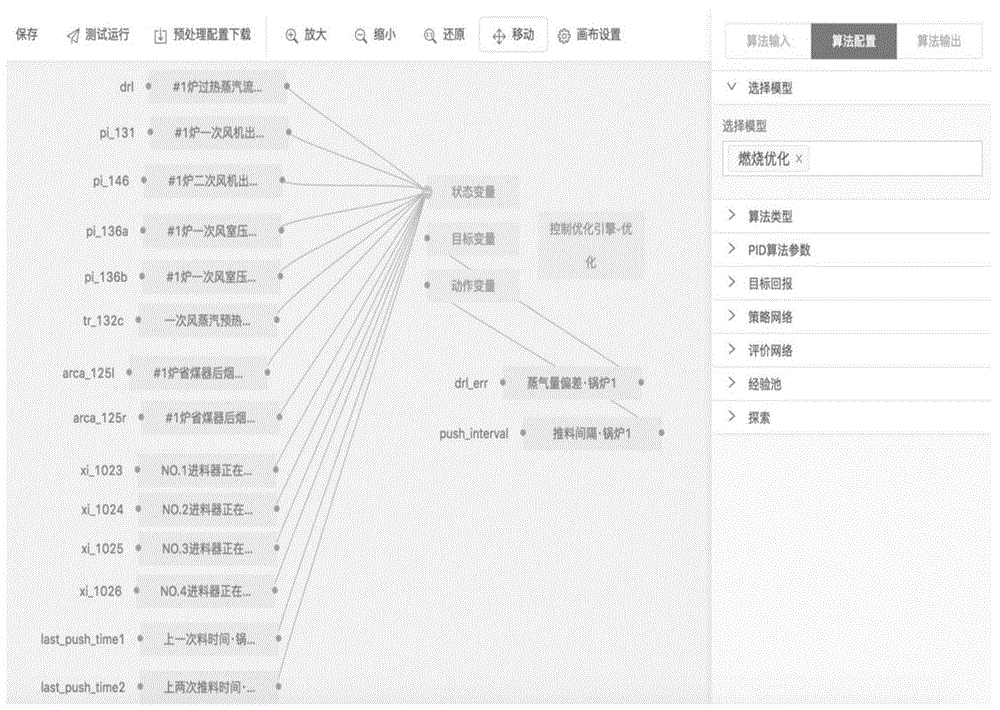
数据上传到阿里云et工业大脑之后,如图8所示,利用阿里云et工业大脑已经封装好的工业预测模型引擎和控制引擎模型,先搭建控制在线预测服务,再搭建在线仿真模型和服务,然后调用控制在线预测服务和在线仿真服务,输出试验数据。具体的,通过读取实时上传的设备测点,使用特征变量如一次风出口压力,一次风室压力,省煤器氧量,推料器正在前进信号等68个特征变量数据,作为阿里云et工业大脑的工业预测模型引擎的特征输入值,阿里云et工业大脑的工业预测模型引擎整合使用线性回归、逻辑回归、非线性回归、svr、集成学习等多种回归算法进行建模,预测90s后的蒸汽量的数值作为输出值。然后使用当前蒸汽量值与预测90s后的蒸汽量的数值的偏差,作为阿里云et工业大脑中控制引擎的目标输入,如图9所示,在使用控制引擎模型控制过程时,该内置的封装的垃圾焚烧优化算法模板选用了数据上云的实时测点数据进行垃圾焚烧稳定性优化的过程控制,分别用于控制状态变量、目标变量和动作变量。
控制引擎模型是阿里云工业大脑平台通用的算法模型,该算法主要利用pid以及深度强化学习算法,在线实时进行学习和融合,最后输出推荐进料时间,控制引擎模型主要是通过调节模型微分、积分和比例三个算法参数,以及算法运行数据如蒸汽量偏差、推料间隔,以及变量参数的动作变量推荐进料时间间隔,pid算法的执行流程即利用反馈来检测偏差信号,并通过偏差信号来控制被控量。控制引擎模型功能框图如图13所示,本身就是pid控制器,pid控制器为比例、积分、微分三个环节的加和。
pid控制器的作用是在没有其他特殊工艺情况下准确推测出进料时间,防止过早推料和过晚推料,pid控制器的准确性与工业大脑的90s后蒸汽流量预测值的准确性相关,预测值越准确,pid控制器推测的时间就越准确,pid控制器使用预测蒸汽流量与当前蒸汽流量的偏差,比例kp,积分ki和微分kd作为偏差的系数,使用kp与偏差相乘加上ki与偏差相乘的累加值加上微分kd与当前偏差与上一次偏差的差相乘的值,具体计算公式如u(t)=kp(e(t)+1/tie(t)dt+td*de(t)/dt)式中积分的上下限分别是0和t因此传递函数为:g(s)=u(s)/e(s)=kp(1+1/(ti*s)+td*s)其中kp为比例系数;ti为积分时间常数;td为微分时间常数最终得出一个推料时间间隔,设置pid的参数的大小影响到下一波推料的时间的准确度。
通过电厂运行人员与阿里云算法工程师多次配合与实验,调整出合适准确的参数模型,同时根据人工操作的经验对模型进行逻辑限定,如图6所示,可以根据不同情况输出准确的推料时间,并返回至系统界面,输出推荐推料时间。
在垃圾焚烧发电中,蒸汽量是主要关注的指标,是垃圾焚烧过程中产生的蒸汽来进行发电,所以蒸汽量的稳定性在生产环境中也是至关重要的测点,该算法模型设定的蒸汽量均值是53.4t/h。
现在垃圾的可燃性分析是先根据垃圾的可燃性,计算半个小时的蒸汽量,当蒸汽量的平均值小于等于50t/h的时候,垃圾的可燃性低,根据业务人员焚烧的经验,设置优化控制模型的模型动作变量中的推料时间上限为780s,下限为240s,在垃圾可燃性低时,按照运行人员的经验和统计,超过780s之后还未进行推料会导致垃圾焚烧的负荷过低,下限时间为240s,是在垃圾热值低的时候,让垃圾投放到锅炉炉排上等待燃烧,让垃圾着火焚烧,防止小于240s时垃圾还未着火的情况下继续推料,导致负荷越来越低。优化控制模型的比例,积分和微分参数分别设置为-100,-10,-30。积分和微分参数具体的计算过程如下:
控制引擎模型就会在这个时间的区间内,预测出推料时间,在到达推荐推料时间时,系统发出推料指令,在系统调试优化的过程中,初始pid参数的比例kp,积分ki,微分kd分别为-50,-50,-50,在实际的场景中,刚进行一次推料操作后,假设当前推料时间间隔为500秒,当前的蒸汽流量是52.38t/h,预测90后的蒸汽流量为51.3t/h,含氧量为9.12%,右侧含氧量为7.68%,下一秒的目标蒸汽流量为53.4t/h。目标蒸汽流量和预测蒸汽流量的差为53.4t/h-51.3t/h=2.1t/h,kp*2.1t/h=-47.9s,这个结果是根据当前实时的预测蒸汽流量进行计算,所以是瞬时值,ki的计算是累加值,如当前偏差是2.1t/h,下一秒预测蒸汽流量是50.3t/h,偏差为目标蒸汽流量和预测蒸汽流量的差为53.4t/h-50.3t/h=3.1t/h,ki的累加计算为(-50*2.1t/h)+(-50*3.1t/h+....),kd计算为上两次偏差的差与微分kd相乘,如kd*(3,1t/h-2.1t/h)=-50s,通过这样的计算方式,把pid参数从-50,-50,-50调整为-100,-10,-30,得到准确的推料时间。在可燃性为中和高的时候,同理进行计算。
当半个小时的蒸汽量的平均值大于50t/h且小于等于55t/h的时候,垃圾的可燃性为中,根据业务人员焚烧的经验,设置控制引擎模型的模型动作变量中的推料时间上限为780s,下限为200s,在垃圾可燃性为中的基础上,当前蒸汽量减去预测90s蒸汽量值小于等于3.1t/h时,优化控制模型的微分,积分和比例参数分别是-120,-50,-80,当前蒸汽量减去预测90s蒸汽量值大于等于3.1t/h时,根据积分和微分参数具体的计算过程,对pid参数进行计算,得到模型比例,积分和微分参数分别是-100,-20,-50,当推料间隔小于200s的时候,说明上一斗垃圾的热值较高,燃料快速烧烬,要使用较小的pid参数控制引擎模型的比例,积分和微分参数分别设置为-80,-10,-30。控制引擎模型就会在这个时间的区间内,预测出推料时间,在到达推荐推料时间时,系统发出推料指令。
当半个小时的蒸汽量的平均值大于55t/h的时候,垃圾的可燃性为高,根据业务人员焚烧的经验,设置控制引擎模型的模型动作变量中的推料时间上限为1200s,下限为200s,根据积分和微分参数具体的计算过程,对pid参数进行计算,得到优化控制模型的微分,积分和比例参数分别设置为-150,-60,-90。控制引擎模型就会在这个时间的区间内,预测出推料时间,在到达推荐推料时间时,系统发出推料指令。
同时根据人工经验和锅炉生产的实际情况,在试验的过程中摸索推迟进料时间在算法中添加的具体条件逻辑,如下:
当蒸汽量小于51t/h的时候,限定推料的最小间隔时间,以免在垃圾未烧起来前再进料;
计算最近推料间隔时间,如果过小,延迟进料;
如果风室风压大于2.3kpa,延迟30秒进料;
预测蒸汽量大于等于56t/h,延迟进料推送20s;
当蒸汽量大于58t/h,氧气浓度小于4%,一次风出口压力为2.5kpa时,根据可燃性程度推荐一次风温,具体的:
当可燃性为低时候,炉膛温度不高,一次风温的温度高低会影响到垃圾燃烧的剧烈程度,当可燃性低的时候,一次风温温度高,有助于助燃,根据多次反复试验垃圾燃烧效果,推荐一次风温为170℃-175℃;
当可燃性为中时候,炉膛温度不高,一次风温的温度高低会影响到垃圾燃烧的剧烈程度,当可燃性中的时候,一次风温中等,可以平稳燃烧,根据多次反复试验垃圾燃烧效果,推荐一次风温为150℃-155℃;
当可燃性为高时候,炉膛温度不高,一次风温的温度高低会影响到垃圾燃烧的剧烈程度,当可燃性高的时候,一次风温温度低,防止燃烧过猛,根据多次反复试验垃圾燃烧效果,推荐一次风温为120℃-130℃;
在上面模型的基础上,根据实际生产中产生的不同情况,如判断是否压低了一次风压,当判断风压偏低的时候,延时进料。
作为具体实施例,本发明通过et工业大脑获取工业预测模型引擎和控制引擎模型。阿里云et工业大脑是阿里云基于燃烧机理与实际运行数据,寻找最优的锅炉操作参数,提升锅炉燃烧效率,最终实现降低能耗的系统,如图7所示,该发明可通过阿里云销售网站上的阿里云et工业大脑平台获取et工业大脑,et工业大脑已装载锅炉焚烧优化算法,该算法模型封装了工业预测模型引擎和控制引擎燃烧模型,对阿里云销售网站上获取的et工业大脑,作为现有技术,本申请这里不作详细介绍。
本发明从锅炉设备所涉及的三百多个变量中,挖掘各参数间的逻辑关系,建立了锅炉设备行业数据模型,并建立对应的燃烧优化控制算法。本发明通过使用已有的阿里云et工业大脑算法模型为工具,结合电厂实际生产状况和电厂业务人员的垃圾焚烧经验,调整工业预测模型引擎和控制引擎模型燃烧的参数,进行多次试验得出最合适的模型,能实现稳定锅炉燃烧和控制自动化,大大减少了人工干预操作。
在垃圾燃烧发电过程中,由于垃圾成分的变化,蒸汽量波动较大。本发明先通过算法建立一套仿真系统,再通过参考进料的时间,人工根据提示进料;同时结合人工经验针对一些异常的情况(垃圾爆燃,垃圾没有进料)进行及时调整,能提高生产稳定性。
本发明还提供一种计算机存储介质,其上存储有计算机程序,本发明的方法如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在该计算机存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机存储介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机存储介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机存储介质不包括电载波信号和电信信号。
对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!