一种多谱线组合激光诱导击穿光谱谷类作物产地识别方法与流程
本发明属于光谱分析技术领域,具体涉及一种采用激光诱导击穿光谱技术识别谷类作物,尤其是大米的产地的方法,产地也称溯源地。
背景技术:
大米被誉为“五谷之首”,是我国的主要粮食作物之一,约占粮食作物栽培面积的30%,因富含丰富的碳水化合物、维生素和矿物质,而成为补充人体所需各种微量营养元素的基础性食物。然而,大米的营养成分因品种、产地、生长条件的不同,存在很大的差异,加之市场上不断出现“劣质大米冒充优质大米”、“产地冒充”等不良现象,因此需要有效的检测方法对市场流通的大米进行品质和产地鉴别。传统的鉴别方法主要包括感官和化学检测。其中感官检测主观性强且费时费力;化学检测需专业人员对样品进行繁琐的化学预处理,耗时长、无法满足快速、绿色、大批量等处理的要求。因此,急需研究一种快速、环保、准确的检测方法来实现对大米的鉴别。
激光诱导击穿光谱(laser-induced breakdown spectroscopy,简称LIBS)技术是一种新型成分分析方法。该技术可以快速大批量检测样品;采样点尺寸小,破坏性小;并可对多种元素同时进行分析;也可以实现恶劣环境下的检测等特点,已经广泛应用于工业、考古、土壤、水体以及食品检测等领域。
研究论文《气相色谱结合化学计量学区分大米贮藏时间和产地》(分析测试学报,第32卷,10期,2013年10月发表)采用气相色谱法分别分析了不同贮藏时间和不同产地大米样本的挥发性成分,通过主成分分析法(principal components analysis,简称PCA)和偏最小二乘判别分析法(partial least square discriminant analysis,简称PLS-DA)对大米样本进行分类和判别分析,得到不同贮藏时间和不同产地大米样本识别率分别为96%和100%。研究论文《基于无机元素分析对地理标志五常大米鉴别技术的研究》(光谱学与光谱分析,第36卷,21期,2016年3月发表)应用电感耦合等离子体光谱及质谱测定大米中无机元素的含量,结合PCA、Fisher判别、人工神经网络对五常大米和非五常大米进行了鉴别,结果表明采用PCA识别效果较差,Fisher判别、人工神经网络的识准确率分别达到93.5%和96.4%。上述研究方法在大米分类中获得了较高的精度,但需要对大米进行固相微萃取和湿法消解,使得检测复杂。中国专利文献《一种提高激光探针塑料识别精度的方法及其装置》(公告号为CN104730041A,公告日为2015年6月24日)公开了一种基于SVM的LIBS技术进行塑料分类的方法。它通过增加3条非金属特征谱线的权重,增大不同塑料之间的基体差异性而使得识别率得到提高。SVM虽然在塑料识别上取得了不错的结果,但并没有针对农产品(例如大米产地)进行应用。
从以上的研究来看,现有对大米分类检测技术主要使用化学检测手段,复杂、耗时,不能满足工业应用的需求。
技术实现要素:
针对传统的大米产地鉴别检测效率低,检测过程复杂,本发明提出一种激光诱导击穿光谱技术识别谷类作物产地的方法,该方法将激光诱导击穿光谱技术与SVM算法结合起来,以期达到快速准确识别的目的。
本发明提供的一种多谱线组合激光诱导击穿光谱谷类作物产地识别方法,其特征在于,该方法包括建立SVM分类模型和产地识别二个过程,具体如下:
(1)建立SVM分类模型过程:
1.1.样品制备:
取同等质量的粉末样品制成厚度均匀的片状样品,其中,样品为n个不同产地的谷类作物;
1.2.样品的光谱数据采集:
对n个不同产地的谷类作物进行LIBS光谱数据采集,每种产地谷类作物样品采集m个等离子体光谱,共获得N=n×m个等离子体光谱,其中,m为LIBS采集的每种样品的光谱幅数,m=1,2,…,1000;
1.3.选取特征谱线
对采集n个不同产地谷类作物的等离子体光谱进行分析,选取每个主量元素中的s个最强特征谱线作为算法分析指标,读取各个特征谱线强度值,选择主量元素中的一个特征谱线强度对其他s-1个主量元素特征光谱强度作归一化处理,其中s-1表示待分析指标个数;
1.4.谱线组合
将所选取主量元素中的s个最强特征谱线附近的同种特征谱线进行组合,最终得到q个组合后的待分析指标;
1.5.SVM分类模型建立
将线性不可分的数据通过构造内核映射函数的方式映射到高维空间中,从而在高维空间得到线性区分,所述内核映射函数采用径向基函数:
将N组谷类作物光谱数据,选择部分组光谱作为训练集,用于建立支持向量机模型,将剩余组光谱作为模型测试集,用于测试所建立支持向量机模型识别精度;
(2)产地识别
首先,按照步骤1.1至1.4的步骤对待识别谷类作物进行样品制备、光谱数据采集、选取特征谱线和进行谱线组合,得到若干组谷类作物光谱数据;
然后,利用步骤1.5中建立的不同产地谷类作物的SVM分类模型,对未知样品的光谱数据进行分类,从而得到相应的产地预测。
本发明采用支持向量机算法,结合LIBS快速物质分析的优点,对不同产地大米进行快速、准确分类,并采用信背比较大的、且彼此相近的同一元素多条特征谱线组合的方式增强不同产地谷类作物(如大米)之间的差异性,从而提高算法的识别精度。具体而言,本发明方法具有以下特点和效果:
(1)本发明方法与传统的大米产地识别方法相比,不需要复杂的化学前处理,本发明仅简单压片制样,通过激光诱导击穿光谱物质成分分析技术对不同产地大米进行光谱信号采集,减少了样品检测时间和复杂的化学分析过程,避免了二次污染,提高了检测的效率。
(2)本发明方法通过信背比较大的、且彼此相近的同一元素特征谱线组合的方法,来增加不同产地大米之间的差异性,但不增加分析变量的数目,从而提高SVM分类器的分类效果。
(3)本发明方法灵活度高,引进的SVM松弛变量的惩罚参数c和映射内核参数g可以有效地提高分类器的泛化能力,并且算法的训练效率高,参数调节迅速。还可以与其他智能算法如遗传算法(Genetic Algorithm,GA)、随机森林(Random Forest,RF)、神经网络(Artificial Neural Network,ANN)等方法相结合,进一步提高分类的准确性。
(4)需要特别指出的是,本发明方法不局限大米产地,可以实现不同产地的不同种类的大米进行识别。同样适用其他谷类作物的产地识别。
本发明与现有方法不同,本发明通过主量元素附近特征谱线组合来提高SVM分类模型的准确性,具有快速,绿色,识别准确度高的优点。
附图说明
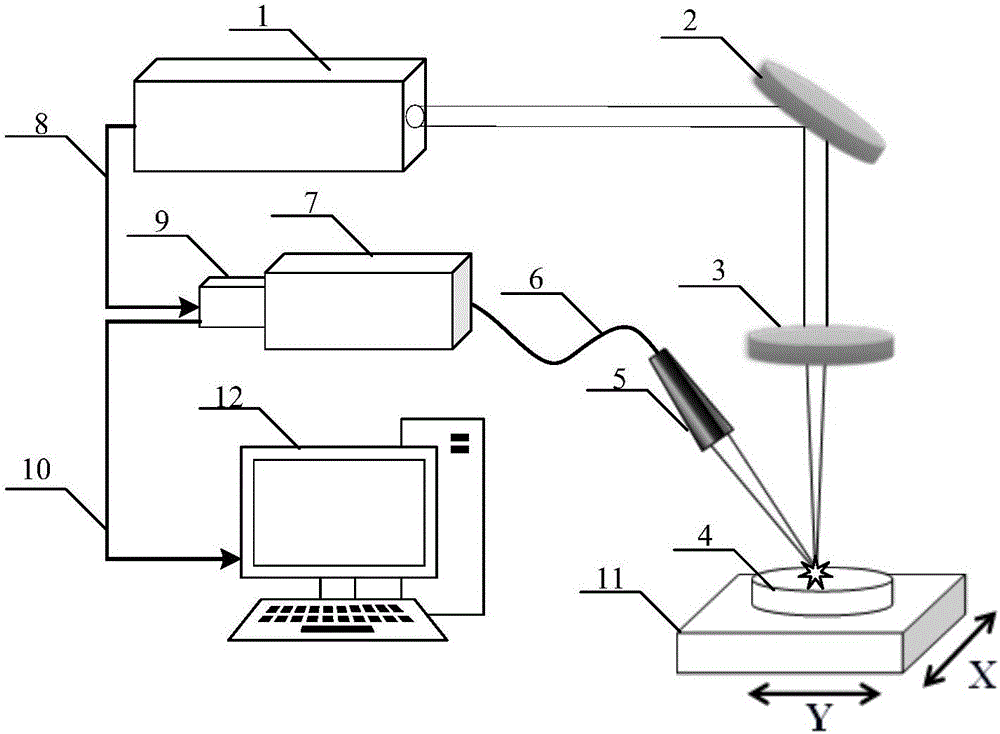
图1为本发明实例提供的激光诱导击穿光谱大米产地识别装置的结构示意图:
其中,1.激光器;2.激光波长反射镜;3.聚焦透镜;4.待测样品;5.信号采集装置;6.光纤;7.光谱仪;8.触发线;9.ICCD;10.数据线;11.位移平台;12.计算机。
图2为广东佛山金豚泰国香米在200~900nm波长范围的LIBS光谱图。
图3为采用单一特征谱线与多条特征谱线组合进行分类的对比。
具体实施方式:
下面结合具体实施例对本发明的具体实施方式进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
由于大米生长环境的不同,直接导致不同产地生长出来的大米之间的成分含量存在差异,因此根据大米中的物质成分来对不同产地大米进行区分是可行的。本发明实例提供的一种多谱线组合支持向量机算法辅助激光诱导击穿光谱技术大米产地识别的方法。
本发明方法包括建立SVM分类模型和产地识别二个过程,具体包括下述步骤:
(1)建立SVM分类模型过程:
1.1.样品制备
首先利用粉碎机对已知产地大米分别进行粉碎,制备成均匀的粉末样品,然后称取同等质量的粉末样品采用压片机制成厚度均匀的片状样品。
1.2.样品的光谱数据采集
为了获得光谱强度和信噪比高的LIBS信号,选取n个不同产地大米中的一个产地的大米进行光谱信号的采集延迟时间、激光能量和离焦量实验参数进行优化。以大米中主量元素C、N、H等光谱强度稳定性和信噪比为评判指标,光谱检测稳定性指标通过计算相对标准偏差(Relative Standard Deviation,简称RSD)来确定,具体的RSD=(标准偏差/计算结果的算术平均值)*100%,RSD值越小越好;信噪比具体的计算是通过采集的光谱强度值减去背景信号强度值除以噪声值,选择信噪比最大的。通过优化主量元素的光谱稳定度和最大信噪比,综合确定最佳实验条件。在最佳的实验条件下,对n个不同产地的大米进行LIBS光谱数据采集,每种产地大米样品采集m个等离子体光谱,共获得N=n×m个等离子体光谱,其中,n为采集的大米产地个数;m为LIBS采集光谱幅数,m=1,2,…,1000。
1.3.选取特征谱线
对采集n个不同产地大米的等离子体光谱进行分析,选取s个主量元素的最强特征谱线作为算法待分析指标,用光谱数据处理软件读取各个特征谱线强度值,选择s个主量元素中的一个特征谱线强度对其他s-1个主量元素特征光谱强度作归一化处理,作为样本数据,其中s表示分析指标个数,s=5,6,…,100,最终得到s-1个未组合谱线待分析指标。
1.4.谱线组合
将所选取得s个主量元素的最强特征谱线附近p个同种特征谱线进行组合,组合后的s个主量元素中的选择未组合的一个特征谱线强度对其他s-1个主量元素特征光谱强度作归一化处理,得到q个组合后的待分析指标(组合后的待分析指标q个数与未组合的分析指标s-1个数相同)。p值是由物质成分和其物理特性所决定的,一般而言,p=1,2,…,100。
1.5.SVM分类模型建立
训练SVM分类模型的数学过程如下:设训练集中每个实例为(Xi,yi),i=1,…,n,Xi,yi分别表示第i个样本数据和其对应的标签值,其中Xi(xi1,xi2,…,xir)∈Rr,Rr表示训练样本数据集,r表示属性值的数目;yi∈{1,2,3,…},1,2,3,…为每组属性值的标签值。算法重要的特点是将线性不可分的数据通过构造核函数的方式映射到高维空间中,从而在高维空间得到线性区分。本发明选择径向基函数(RadialBasis Function,RBF)作为内核映射函数:
由此得到的非线性SVM分类器方程为:
约束条件:
其中,表示预测集的样本数据;表示预测集样本的映射函数;表示二范数距离;l表示训练集的数目;αi为拉格朗日乘子;b为方程中的偏置因子;c为惩罚参数,g为映射内核参数。
由方程可看出c,g参数对模型建立有重要影响。一般设置c、g的选择范围:c=2e,g=2w,e、w∈{-10,-9,…,9,10}。
本发明实例采用支持向量机软件进行数据处理,将N组大米光谱数据选择其中部分组光谱作为训练集,用于建立支持向量机模型,剩余组光谱作为模型测试集,用于测试所建立支持向量机模型识别精度。
支持向量机软件可以选用如林智仁等人开发的支持向量机软件工具箱(A Library for Support Vector Machines—LIBSVM)。
(2)产地识别
首先,按照步骤1.1至1.4的步骤对待识别大米进行样品制备、光谱数据采集、选取特征谱线和进行谱线组合,得到若干组大米光谱数据;
然后,利用步骤1.5中建立的不同产地大米的SVM分类模型,对未知样品的光谱数据进行分类,从而得到相应的产地预测。
实例:
实施例1
1.样品制备。
本实施案例选取10种不同产地的大米样本(表1所示),样本具体名称和产地如下:金豚泰国香米(广东佛山)、湖北观庙山特产有机大米(湖北枝江)、广西巴马正宗糯米(广西巴马)、盘府丰锦大米(辽宁盘锦)、五常稻花香大米(黑龙江五常)、东北糙米(吉林四平双辽)、渡民御贡(安徽安庆)、湘池大米(湖南桃源)、万年贡米(江西上饶)和崇明岛大米(江苏泰州)。采用本发明方法对它们进行产地分类。为了简化分析过程,对不同产地大米进行分别编号,标签值依次为:1,2,3,4,5,6,7,8,9,10;对应的产地以地名简称广东(GD),湖北(HB),广西(GX),辽宁(LN),黑龙江(HLJ),吉林(JL),安徽(AH),湖南(HN),江西(JX),江苏(JS)。考虑到样本的物理特性,如样品的不规则会在一定程度影响光谱信号,在LIBS采集信号前对样品进行预处理,利用粉碎机对不同产地大米分别进行粉碎,制备成均匀的粉末样品,然后称取15g左右的粉末样品采用压片机以25MPa压力制成厚度均匀的片状样品用于LIBS光谱检测。
2.大米样品的光谱数据采集。
光谱采集在空气环境下进行,实验装置如图1所示。采用调Q开关Nd:YAG脉冲激光器1(Quantel Brilliant B,波长532nm,脉冲宽度8ns,最大重复频率10Hz)作为激发光源,激发出的等离子体辐射光由采集头5收集并传输至光谱仪7(Andor Technology,Mechelle5000,波长范围200~975nm,分辨率λ/△λ=5000)进行分光,ICCD9(Andor Technology,iStar DH-334T,1024×1024像素)对光谱仪传过来的光谱信号进行光电转换。光谱采集过程中使用电动位移平台11控制样品表面沿X方向和Y方向做“弓”形运动。为防止空气击穿,激光聚焦透镜3(焦距15cm)焦点位于样品表面以下1.27mm处。为获得最佳的光谱强度和光谱信背比,激光脉冲能量设为40mJ,ICCD延时和门宽分别设为1.5μs和3μs。在以上工艺参数下,采集10种大米的等离子体的光谱,每种样品采集100个光谱,因此10种大米共采集1000个光谱。例如,图2为广东佛山金豚泰国香米在200~900nm波长范围的LIBS光谱图。
3.选取特征谱线。
由于大米中含有丰富的碳水化合物和矿物质元素,因此选择主量元素的13个特征谱线C-N(0,0)388.34nm,C I 247.86nm,N I 746.83nm,O I 777.19nm,H I 656.29nm,C-C(0,0)516.52nm,Mg II 279.55nm,Mn I 403.08nm,Ca I 422.67nm,Si I 288.16nm,Al I 394.40nm,Na I 588.95nm、和K I 766.49nm,具体的特征谱线如表2所示。将每组数据中特征谱线强度值除以Ca I 422.67nm谱线强度值作归一化,最终得到1000组光谱数据,每组光谱数据包含12个分析变量。
4.特征谱线组合
将所选取每种元素最强的特征谱线且彼此相近的同一元素强度归一化后多条特征谱线(C-N(0,0)388.34nm+C-N(1,1)387.14nm+C-N(2,2)386.19nm+C-N(3,3)385.47nm+C-N(4,4)385.09nm,N I 746.83nm+N I 744.23nm+N I 742.36nm,O I 777.19nm+O I 777.42nm,Mg II 279.55nm+Mg II 280.27nm+Mg I 285.21nm,Mn I 403.08nm+Mn I 403.31nm+Mn I 403.45nm,Al I394.40nm+Al I 396.15nm,Na I588.95nm+Na I589.59nm和K I 766.49nm+K I 769.90nm)组合,增加不同产地大米之间的差异性,同样得到1000组光谱数据,每组光谱数据包含12个分析变量。由图3可知,7、8、9不同产地谱线归一化强度比在C-N(0,0)388.34nm特征谱线处区分度很小,通过C-N(0,0)388.34nm、C-N(1,1)387.14nm、C-N(2,2)386.19nm、C-N(3,3)385.47nm和C-N(4,4)385.09nm特征谱线组合有效的增加了产地之间的差异性。不同产地大米具体差异值如表3所示,表中Δ12指的是产地1与产地2特征谱线强度归一化后的差值。
5.SVM分类模型建立。
在Matlab2010b版的软件环境下使用LIBSVM工具箱来进行数学建模,采用的内核函数为径向基函数,适合非线性数据的分类,有较高稳定性。内核径向基函数中的g参数和对松弛变量的惩罚因子c参数是影响SVM算法性能的主要因素,算法的核心原理也是找出最佳的映射内核参数g与惩罚因子c。为了训练结果更具说服力,防止建模过学习,采用交互验证法来优化影响因子。单一特征谱线的c、g参数分别为222.8609和0.125;组合特征谱线的c、g参数分别为588.1336和0.047366。最终运用SVM训练模型得到单一特征谱线的训练集识别率为91.2%,预测集识别率为90.8%,多谱线组合的训练集识别率为94.2%,预测集识别率为94.6%,获得了较高的识别率,具体的不同产地识别结果以及与谱线组合的SVM识别结果对比如表4所示,其中湖北枝江大米的识别率由64%提高到88%。因此通过多特征谱线组合能够提高激光诱导击穿光谱大米产地识别的准确度。
6.其他权重值调节方法对比
对比谱线组合方法与中国专利文献《一种提高激光探针塑料识别精度的方法及其装置》(公告号为CN104730041A,公告日为2015年6月24日)公开了一种谱线权重调整结合SVM的LIBS技术,通过增加非金属主量元素C、N、H权重值,结果如表4所示,采用谱线组合方式对大米的识别率94.6%高于谱线权重调整的识别率90.8%。
实施例2
1.样品制备。
本实施案例选取同一省份6种不同产地的大米样本(如表5),样本具体产品名称和产地如下:七河源(黑龙江绥化)、五常稻花香大米(黑龙江五常)、宝宝辅食(黑龙江宁安莲花村)、萃林糯米(黑龙江齐齐哈尔)、东北响水大米(黑龙江宁安响水村)和素食猫泰来大米(黑龙江齐齐哈尔)。采用本发明方法对它们进行产地分类。为了简化分析过程,对不同产地大米进行分别编号,标签值依次为:1,2,3,4,5,6;对应的产地以地名简称绥化(SH),五常(WC),莲花(LH),齐齐哈尔1(QQHE1),响水(XS),齐齐哈尔2(QQHE2)。同样利用粉碎机对不同产地大米分别进行粉碎,制备成均匀的粉末样品,然后称取15g左右的粉末样品采用压片机以25MPa压力制成厚度均匀的片状样品用于LIBS光谱检测。
2.大米样品的光谱数据采集。
在相同的实验条件下,采集6种大米的等离子体的光谱,每种样品采集100个光谱,因此6种大米共采集600个光谱。
3.选取特征谱线。
同样选择主量元素的13个特征谱线C-N(0,0)388.34nm,C I 247.86nm,N I 746.83nm,O I 777.19nm,H I 656.29nm,C-C(0,0)516.52nm,Mg II 279.55nm,Mn I 403.08nm,Ca I 422.67nm,Si I 288.16nm,Al I 394.40nm,Na I 588.95nm和K I 766.49nm。将每组数据中特征谱线强度值除以Ca I 422.67nm谱线强度值作归一化,最终得到600组光谱数据,每组光谱数据包含12个分析变量。
4.特征谱线组合
同样将所选取每种元素最强的特征谱线且彼此相近的同一元素强度归一化后多条特征谱线(C-N(0,0)388.34nm+C-N(1,1)387.14nm+C-N(2,2)386.19nm+C-N(3,3)385.47nm+C-N(4,4)385.09nm,N I 746.83nm+N I 744.23nm+N I 742.36nm,O I 777.19nm+O I 777.42nm,Mg II 279.55nm+Mg II 280.27nm+Mg I 285.21nm,Mn I 403.08nm+Mn I 403.31nm+Mn I 403.45nm,Al I394.40nm+Al I 396.15nm,Na I588.95nm+Na I589.59nm和KI766.49nm+KI 769.90nm)组合,增加不同产地大米之间的差异性,同样得到600组光谱数据,每组光谱数据包含12个分析变量。
5.SVM分类模型建立。
在Matlab2010b版的软件环境下使用LIBSVM工具箱来进行数学建模。单一特征谱线的c、g参数分别为12.1257和2.2974;组合特征谱线的c、g参数分别为64和0.43528。最终运用SVM训练模型得到单一特征谱线的训练集识别率为93.67%,预测集识别率为88.67%,多谱线组合的训练集识别率为94.33%,预测集识别率为93%,获得了较高的识别率,具体的不同产地识别结果以及与谱线组合的SVM识别结果对比如表6所示。因此通过多特征谱线组合能够提高激光诱导击穿光谱大米产地识别的准确度。
6.其他权重值调节方法对比
对比谱线组合方法与谱线权重调整结合SVM的LIBS技术结果如表4所示,采用谱线组合方式对大米的识别率93%高于谱线权重调整的识别率92.33%。
实施例3
1.样品制备。
本实施案例选取10个不同省份20种不同产地的大米样本(如表7),样本具体产品名称和产地如下:金豚泰国香米(广东佛山)、湖北观庙山特产有机大米(湖北枝江)、七河源(黑龙江绥化)、靓虾王香软米(广东东莞)、天地粮人(辽宁朝阳)、广西巴马正宗糯米(广西巴马)、盘府丰锦大米(辽宁盘锦)、五谷杂粮小西米(广东广州)、五常稻花香大米(黑龙江五常)、宝宝辅食(黑龙江宁安莲花村)、萃林糯米(黑龙江齐齐哈尔)、东北糙米(吉林四平双辽)、渡民御贡(安徽安庆)、东北响水大米(黑龙江宁安响水村)湘池大米(湖南桃源)、万年贡米(江西上饶)、崇明岛大米(江苏泰州)、一江秋富硒大米(江西吉安)、竹溪贡米(湖北十堰竹溪)和素食猫泰来大米(黑龙江齐齐哈尔)。采用本发明方法对它们进行产地分类。为了简化分析过程,对不同产地大米进行分别编号,标签值依次为:1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20;对应的产地以地名简称佛山(FS)、枝江(ZJ)、绥化(SH)、东莞(DG)、朝阳(CY)、河池(HC)、盘锦(PJ)、广州(GZ)、五常(WC)、莲花村(LHC)、齐齐哈尔(QQHE)、双辽(SL)、安庆(AQ)、响水村(XSC)、桃源(TY)、上饶(SR)、泰州(TZ)、吉安(JA)、竹溪(ZX)和黑龙江(HLJ)。同样利用粉碎机对不同产地大米分别进行粉碎,制备成均匀的粉末样品,然后称取15g左右的粉末样品采用压片机以25MPa压力制成厚度均匀的片状样品用于LIBS光谱检测。
2.大米样品的光谱数据采集。
在相同的实验条件下,采集20种大米的等离子体的光谱,每种样品采集100个光谱,因此20种大米共采集2000个光谱。
3.选取特征谱线。
同样选择主量元素的13个特征谱线C-N(0,0)388.34nm,C I 247.86nm,N I 746.83nm,O I 777.19nm,H I 656.29nm,C-C(0,0)516.52nm,Mg II 279.55nm,Mn I 403.08nm,Ca I 422.67nm,Si I 288.16nm,Al I 394.40nm,Na I 588.95nm和K I 766.49nm。将每组数据中特征谱线强度值除以Ca I 422.67nm谱线强度值作归一化,最终得到2000组光谱数据,每组光谱数据包含12个分析变量。
4.特征谱线组合
同样将所选取每种元素最强的特征谱线且彼此相近的同一元素强度归一化后多条特征谱线(C-N(0,0)388.34nm+C-N(1,1)387.14nm+C-N(2,2)386.19nm+C-N(3,3)385.47nm+C-N(4,4)385.09nm,N I 746.83nm+N I 744.23nm+N I 742.36nm,O I 777.19nm+O I 777.42nm,Mg II 279.55nm+Mg II 280.27nm+Mg I 285.21nm,Mn I 403.08nm+Mn I 403.31nm+Mn I 403.45nm,Al I394.40nm+Al I 396.15nm,Na I588.95nm+Na I589.59nm和K I 766.49nm+K I 769.90nm)组合,增加不同产地大米之间的差异性,同样得到2000组光谱数据,每组光谱数据包含12个分析变量。
5.SVM分类模型建立。
在Matlab2010b版的软件环境下使用LIBSVM工具箱来进行数学建模。单一特征谱线的c、g参数分别为222.8609和0.37893;组合特征谱线的c、g参数分别为388.0234和0.071794。最终运用SVM训练模型得到单一特征谱线的训练集识别率为86.7%,预测集识别率为86.2%,多谱线组合的训练集识别率为90.1%,预测集识别率为89.4%,获得了较高的识别率,具体的不同产地识别结果以及与谱线组合的SVM识别结果对比如表8所示。因此通过多特征谱线组合能够提高激光诱导击穿光谱大米产地识别的准确度。6.其他权重值调节方法对比
对比谱线组合方法与谱线权重调整结合SVM的LIBS技术结果如表4所示,采用谱线组合方式对大米的识别率89.4%高于谱线权重调整的识别率84.8%。
以上显示和描述了本发明的基本原理和主要特征以及本发明的优点。本行业的科研人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
表1为不同产地大米清单
表2为所采用的的单一特征谱线与多条特征谱线的组合
表3为采用单一特征谱线与多条特征谱线组合方式下不同产地大米特征谱线强度归一化后具体差异值
表4为不同产地大米SVM分类的结果
表5为同一省份不同产地大米清单
表6为同一身份不同产地大米SVM分类的结果
表7为不同省份不同产地大米清单
表8为不同省份不同产地大米SVM分类的结果
- 还没有人留言评论。精彩留言会获得点赞!