作为生物标志物的游离组蛋白的制作方法
本发明涉及用于检测游离组蛋白的测定法,并涉及在游离组蛋白检测的基础上诊断疾病或医学病症(condition)例如系统性炎症。
背景技术:
核心组蛋白h2a、h2b、h3和h4(各两个)形成八聚体,其被165个碱基对的dna缠绕,形成染色质的基本子单元核小体。每个核小体与其相邻的核小体相连,通过连接组蛋白h1和h5而稳定(felsenfeldg.,groudinem.,nature2003;421(6921):p.448-53)。
所有组蛋白具有共同的紧凑的中心结构:中央为螺旋,侧翼带有螺旋-转角-螺旋基序。尽管组蛋白带有高度正电荷,但它们的结构使其能够与邻近成员发生特异性疏水相互作用以形成紧凑的八聚体。上述中心结构外部的区域是松散的,并含有对核小体形成来说重要的核酸相互作用面。这些区域也是各种不同的翻译后修饰(ptm),通常为n-端乙酰化、瓜氨酸化、甲基化和磷酸化以及c-端遍在蛋白化的对象。ptm对于解开核小体结构来说是必需的,因此在各种细胞过程例如基因转录、dna损伤修复、凋亡以及细胞周期调控中发挥重要作用(kouzaridest.,cell2007;128(4):p.693-705)。
在多种病理生理过程中,也在核的外部检测到组蛋白(wo2009/061918)。在遭受涉及炎性过程的不同病因例如关节炎、严重创伤、胰腺炎和脓毒症的患者的血液中,已描述了细胞外组蛋白的存在。组蛋白从活化的免疫细胞的释放可以由细胞外诱捕网(extracellulartrap)介导。作为控制和清除感染的最终机制,活化的嗜中性粒细胞可以释放出细胞外纤维,即所谓的嗜中性粒细胞细胞外诱捕网(net)(brinkmannv.等,science2004;303(5663):p.1532-5)。可以将组蛋白释放到患者血流中的其他机制包括细胞的凋亡、坏死、焦亡或坏死性凋亡。
一旦组蛋白被释放到细胞外空间中并进入循环之后,它们激发出它们的促炎性和毒性潜力(xuj.等,natmed2009;15:1318-1321;abramsst.等,jimmunol2013;191(5):2495-502)。各种研究揭示,循环组蛋白不仅具有抗微生物性质,而且在炎性和传染性疾病、与创伤相关的损伤、以无菌性炎症为特征的病症、器官损伤、自体免疫疾病、癌症和视网膜脱落中发挥病理作用(wo2009/062948;us8,716,218;millerb.f.等,science1942;96(2497):p.428-430.;hirsch,j.g.jexpmed1958;108(6):p.925-44.;allamr.等,jmolmed2014;92:465-472.;xuj.等,natmed2009;15:1318-1321;abramsst.等,jimmunol2013;191(5):2495-502;huangh.等,hepatology2011;54:999–1008.;kangr.等,gastroenterology2014;146:1097–1107.;wenz.等,jcellbiochem2013;114:2384–2391.;xuj.等,jimmunol2011;187:2626–2631.;demeyersf.等,arteriosclerthrombvascbiol2012;32:1884–1891.;barreroca.等,amjrespircritcaremed2013;188:673–683;allamr.等,jamsocnephrol2012;23:1375–1388;bosmannm.等,fasebj2013;27:5010–5021;allamr.等,eurjimmunol2013;43:3336–3342;kawanoh.等,labinvest2014;94:569–585;monachpa.等,procnatlacadsciusa2009;106:15867–15872;hakkima.等,procnatlacadsciusa2010;107:9813–9818;kessenbrockk.等,natmed2009;15:623–625;holdenrieders.等,intjcancer2001;95:114–120)。
组蛋白可以充当生物标志物用于早期疾病识别和/或恶化以及潜在的治疗靶点(chenr.等,celldeathanddisease2014;5:e1370;xuj.等,natmed2009;15:1318-1321)。
缺少自由循环组蛋白的可用且可靠的定量工具,阻碍了对这些潜在生物标志物的临床用途的评估。血液来源的患者样品中的循环组蛋白,仅仅通过使用western印迹分析或通过使用酶联免疫测定法测定核小体(与dna结合的组蛋白八聚体——蛋白质dna复合物)水平来间接测量(zeerleders.等,critcaremed2003;31(7):p.1947-51;kutcherm.e.等,jtraumaacutecaresurg2012;73(6):p.1389-94;zeerleders.,critcare2006;10(3):p.142;wo2009061918)。由于高成本、复杂的技术要求和获得结果的时间长,western印迹分析在临床常规中的使用非常有问题。此外,它需要多个步骤,因此易于产生主观结果。也已在病理过程中检测了核小体水平。尽管组蛋白反映出核小体的基本部分,但完整的核小体是无毒的(abramsst.等,amjrespcritcaremed2013;187:160-169)。核小体测定法检测与dna复合的组蛋白。因此,核小体检测不给出关于自由循环的组蛋白或其片段的量的信息。
翻译后修饰的组蛋白可以通过质谱测量技术来检测(sidolis.等,jproteomics2012;75(12):3419-3433;villar-gareaa.等,currprotocproteinsci2008;chapter14:unit1410)。对于来自于体外培养的组织培养物的高度纯化的样品来说,也已显示了通过使用质谱(ms)技术(buschows.i.等,immunolcellbiol2010;88(8):p.851-6)或通过以前的凝胶电泳(xuj.等,natmed2009;15:1318-1321)检测外泌体中的组蛋白。
使用ms在本源的患者血浆样品中定量测量组蛋白据报道是不成功的,这是由于高丰度的血浆蛋白干扰了组蛋白的检测。此外,即使剥离了主要的丰富蛋白质也没有提高患者血浆样品中的组蛋白可检测性(ekaneym.等,critcare2014;18(5):p.543)。
对于质谱测量来说,在分析和定量靶蛋白之前通常进行化学衍生(yuanz.f.等,annurevanalchem(paloaltocalif)2014;7:113-128;garciab.a.等,natprotoc2007;2(4):933-938.;wo2013/148178)。然而,尚未描述在没有任何化学修饰或标记的生物流体中的定量方法。
在现有技术中,已描述了几种用于区分sirs与脓毒症的生物标志物(wo2009/062948)。
发明概述
本发明涉及用于生物样品例如血液来源的样品中的细胞外组蛋白的定量测量的灵敏的检测方法。本文中描述的检测方法可以靶向不是大分子复合物例如核小体或嗜中性粒细胞细胞外诱捕网(net)的一部分的游离的循环组蛋白。所述方法不需对所述样品中蛋白质混合物的复杂度进行任何降低,例如通过免疫沉淀进行初始组蛋白捕获或通过凝胶电泳进行分离。通过分析“本源”样品,本发明的方法避免了结合到非靶蛋白例如白蛋白的组蛋白或组蛋白来源的肽的非故意移除。因此,所描述的方法能够通过检测血清和血浆蛋白质组的复杂本源混合物中的组蛋白来源的肽,进行组蛋白的精确和标准化的定量。此外,所述方法可以应用于(危重)患者的临床评估。本发明涉及一种检测游离组蛋白的方法。这种方法检测例如当组蛋白组装在核小体中时不可接近的组蛋白的表位或肽片段。此外或可选地,所述组蛋白的待检测表位或肽片段可能具有或可能不具有翻译后修饰,优选地,所述组蛋白的待检测表位或肽片段不具有翻译后修饰。
本发明的方法可用于疾病或医学病症的诊断、预后、风险评估、危险分层和/或疗法控制。在随附的实施例中,证实了本发明的基于免疫测定法和质谱法的测定法检测患有疾病或医学病症的受试者的样品中的游离组蛋白;参见说明图1、2和8。
所述游离组蛋白或其片段的检测可以使用任何适合的方法例如基于免疫测定法或质谱法(ms)的方法来进行。
具体来说,本发明提供了一种利用本发明的方法检测游离组蛋白的免疫测定方法,所述方法包括下述步骤:a)将所述样品与特异性针对所述游离组蛋白的表位的第一抗体或其抗原结合片段或衍生物和特异性针对所述游离组蛋白的表位的第二抗体或其抗原结合片段或衍生物相接触,以及b)检测所述两种抗体或其抗原结合片段或衍生物与所述游离组蛋白的结合。
本发明还涉及用于检测游离组蛋白的基于质谱法(ms)的方法。
本发明还涉及抗体和试剂盒及其在本发明的方法中的应用。
附图说明
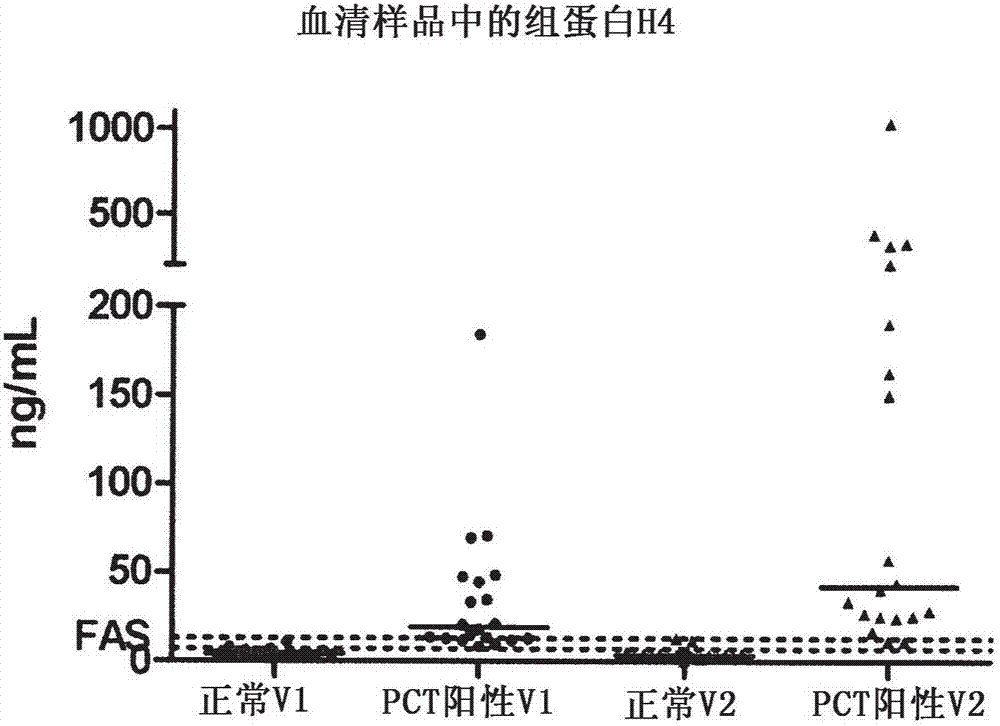
图1:使用免疫测定法确定来自于健康志愿者的血清样品和来自于被测试为pct阳性的患者的样品中的组蛋白h4浓度的典型结果。
图2:检测样品中的组蛋白h4的免疫测定法h4-li-9-ab31830(v1)与h4-rr-13-ab31830(v2)的比较。
图3:检测样品中的组蛋白h4的免疫测定法h4-li-9-ab31830(v1)与h4-rr-13-ab31830(v2)的关联性。
图4:在零血清中检测组蛋白h4的免疫测定法h4-li-9-ab31830(v1)与h4-rr-13-ab31830(v2)的剂量响应曲线的比较。
图5:srm与免疫测定法之间的关联性。
图6:使用与图1中相同的样品,使用rochecelldeathdetectionelisa(#11544675001)测定的核小体浓度。
图7:本发明的夹心免疫测定法和srm测定法与可商购的rochecelldeathdetectionelisa(#11544675001)之间的比较,显示出检测到的是游离组蛋白而不是核小体。
图8:通过肽vflenvir(seqidno:4)的srm测量,在来自于健康志愿者的血清样品和来自于患有脓毒症的患者的样品中确定的组蛋白h4浓度的结果。
图9:来自于患有脓毒症的患者的血清样品中组蛋白h4肽vflenvir(seqidno:4)的srm曲线(skyline软件)。顶部的图表示内源肽的4个跃迁。底部的图表示重掺杂肽的相应的4个跃迁。
图10:来自于组蛋白h4的肽vflenvir(seqidno:4)的校准曲线。将恒定量的从重组h4消化获得的轻肽与变化量的相应的重肽掺混,以产生一套浓度标准品。
发明详述
本发明涉及一种用于在受试者的生物样品中检测游离组蛋白的方法。所述方法是基于所述组蛋白的表位或肽片段的检测。
本发明还涉及一种用于疾病或医学病症的诊断、预后、风险评估、危险分层和/或疗法控制的方法,所述方法包括检测受试者的生物样品中的游离组蛋白或其肽片段,其中所述游离组蛋白或其片段的存在指示所述疾病或医学病症。
当在本文中使用时,术语“多肽”、“肽”和“蛋白质”可互换使用,是指氨基酸残基的聚合物。
术语“氨基酸”是指天然存在的氨基酸。天然存在的氨基酸是由遗传密码编码的氨基酸,以及在晚些时候被修饰的氨基酸例如羟脯氨酸、γ-羧基谷氨酸和o-磷酸丝氨酸。在本文中,氨基酸可以用它们通常已知的三字母符号或由iupac-iub生物化学命名委员会(iupac-iubbiochemicalnomenclaturecommission)推荐的单字母符号来指称。
在本发明的任一方法中待检测的组蛋白涵盖了标准的组蛋白及其同工型/变体。优选地,待检测的游离组蛋白或其肽片段选自h1、h2a、h2b、h3、h4及其同工型,更优选为h2a或h4。甚至更优选地,检测跨越符合seqidno:23的组蛋白h2a的20至55位或70至118位氨基酸残基的序列中的表位或肽片段,或跨越符合seqidno:1的游离组蛋白h4的22至102位、更优选地46至102位氨基酸残基的序列中的表位或肽片段。
当在本文中使用时,组蛋白变体是组蛋白的标准或常规变体。具有一个或几个(最多2、4、6或8个)氨基酸交换的非标准(非等位基因)组蛋白,与它们的常规对应物相比以非常低的水平表达。组蛋白变体具有特定的表达、定位和种分布情况,并为核小体提供新的结构和功能性质,影响染色质重塑和组蛋白翻译后修饰。在核心组蛋白中,h2a具有最大的变体数目,包括h2a.z、macroh2a、h2a-bbd、h2avd和h2a.x,而组蛋白h4是进化最慢的蛋白质之一,并且组蛋白h4似乎不存在已知的序列变体。
在本发明的情形中,“游离组蛋白”涵盖了未组装在大分子复合体例如核小体或嗜中性粒细胞细胞外诱捕网(net)中的组蛋白。因此,在本发明的情形中,游离组蛋白以所述组蛋白的区域可以利用本发明的方法来检测为特征,所述区域在组装的化学计量的大分子复合体例如单核小体或八聚体中是不可接近的。在这种情形中,“化学计量的”涉及完整的复合体,例如单核小体或八聚体。“net”是嗜中性粒细胞细胞外诱捕网(brinkmannv.等,science303(5663):p.1532-5,2004)。net的骨架由从自杀的嗜中性粒细胞释放的染色质构造而成,并采取基于dna的线缆的形式。除了dna之外,一些蛋白质例如组蛋白在这些net中形成球形结构域。微生物被受到刺激产生net的嗜中性粒细胞培养物杀死。“游离组蛋白”还包含未被染色质结合的组蛋白。即“游离组蛋白”还可以包含net中缠结的单个组蛋白或非八聚体组蛋白复合体。游离组蛋白被称为单体、异二聚体或四聚体组蛋白,其未组装在由结合到核酸的组蛋白八聚体构成的(“化学计量的”)核小体复合体中。因此,游离组蛋白被定义为仅仅以单体和/或同二聚体和异二聚体和/或同四聚体和异四聚体的形式存在的单独的组蛋白,而结合的组蛋白被定义为并入到由通过疏水相互作用发生相互作用的各两个分子的h2a、h2b、h3和h4构成的核小体的八聚体核心中的组蛋白。在后一种情况下,组蛋白的中心区域被覆盖并且在空间上不可接近,因为这些区域参与各个组蛋白分子之间的分子内相互作用。
游离组蛋白可能被短暂地结合到单个组蛋白,例如组蛋白可能形成同二聚体,或者h3与h4或h2a与h2b可能形成异二聚体。符合本发明的游离组蛋白也可能形成同四聚体或异四聚体。同四聚体或异四聚体由4个分子的组蛋白例如h2a、h2b、h3和/或h4构成。典型的异四聚体由两个异二聚体形成,其中每个异二聚体由h3和h4构成。在本文中还应该理解,异四聚体可能由h2a和h2b形成。在本文中还设想了异四聚体可能由一个由h3和h4构成的异二聚体和一个由h2a和h2b构成的异二聚体形成。在本文中应该理解,所述游离组蛋白可以是组蛋白变体,或者可以被发现与组蛋白变体相结合。在本发明的某些情况下,游离组蛋白例如组蛋白的单体、二聚体或四聚体,与核酸例如dna结合。因此,本发明的抗体和方法可以检测独立于结合的核酸的游离组蛋白。
正如上面提到的,在本文中应该理解,游离组蛋白不是与核小体相关的八聚体的一部分。所述八聚体是由两个h2a和h2b的二聚体和一个h3和h4的四聚体构成的核小体的蛋白质核心粒子。实施例4证实了基于免疫测定法的方法及其利用的抗体不检测作为核小体的八聚体核心的一部分时的组蛋白,例如h4。同样地,通过符合本发明的基于质谱法的方法检测的肽例如seqidno:3和4,源自于游离组蛋白。这些检测的肽是当组蛋白作为八聚体的一部分时将被埋藏并因此不可被例如蛋白酶接近的组蛋白部分;参见例如实施例3和7。
游离组蛋白也可以短暂地与高丰度血浆蛋白包括白蛋白、血清淀粉样肽a、inter-α抑制蛋白、toll样受体、正五聚蛋白例如血清淀粉样肽p和c-反应蛋白发生相互作用,其通过主要在组蛋白的n-端处的带正电荷的残基的离子相互作用驱动。因此,当结合到血浆蛋白时,游离组蛋白仍然可以被针对中央区域和c端的抗体接近。
正如在随附的实施例中证实的,本文中提供了检测游离组蛋白的测定法、试剂盒和抗体。例如,游离组蛋白通过组蛋白例如h2a和h4的在化学计量的大分子复合体例如八聚体中基本上不可接近的区域来检测;参见例如实施例3和4。在本文中应该理解,组蛋白的区域是在游离组蛋白中可接近,但在组蛋白处于大分子复合体例如八聚体中的情况下基本上不可接近的多肽区段。在随附的实施例中,证实了方法例如免疫测定法以及基于质谱法的测定法适用于检测游离组蛋白。具体来说,在本文中示出了在所述基于免疫测定法的方法中使用的示例性抗体特异性针对游离组蛋白。因此,与存在于例如八聚体或核小体中的结合的组蛋白相比,本发明的抗体对游离组蛋白具有更高的结合亲和性。在随附的实施例中显示,所述示例性抗体结合到组蛋白的仅仅在游离组蛋白中可接近的区域。具体来说,在实施例4中证明了符合本发明的基于免疫测定法的方法和其中使用的抗体检测游离组蛋白例如h4,但是当所述组蛋白是八聚体核心的一部分时不检测所述组蛋白。
游离组蛋白也可以利用质谱测量法来检测。正如对基于免疫测定法的方法所显示的,可以通过质谱法检测作为游离组蛋白的切割产物的肽;参见例如说明性实施例4。换句话说,这些肽从游离组蛋白产生。不希望受到理论限制,可以在本发明的某些情况中用于产生蛋白水解消化物以准备用于质谱测量分析的蛋白酶,当组蛋白处于大分子复合体例如八聚体中时不能接近中央区域的肽。换句话说,所述蛋白酶由于空间位阻不能渗透到这些切割位点。因此,这种方法检测代表游离组蛋白的肽,例如中央区域的肽。
在随附的实施例中证实,本发明的测定法、试剂盒和抗体检测在游离组蛋白中可接近的游离组蛋白的肽或表位。这些氨基酸区段在本文中也被称为组蛋白的中央区域或部分。在下文中,描述了可用于利用本文中提供的方法检测游离组蛋白的肽或表位。可用于通过本文中提供的方法检测游离组蛋白的示例性的肽或表位是在跨越符合seqidno:1的组蛋白h4的22至102位氨基酸残基或符合seqidno:23的组蛋白h2a的20至118位氨基酸残基的序列中的表位或肽片段。此外,可用于通过本文中提供的方法检测游离组蛋白的示例性的肽或表位可以是在跨越符合seqidno:36的组蛋白h3的27至62位氨基酸残基或符合seqidno:31的组蛋白h2b的41至69位氨基酸残基的序列中的表位或肽片段。更优选地,游离组蛋白h4通过选自跨越seqidno:1的22至30位残基、seqidno:1的67至78位残基、seqidno:1的92至102位残基、seqidno:1的22至34位残基、seqidno:1的46至102位残基、seqidno:1的46至55位残基、seqidno:1的60至67位残基、seqidno:1的80至91位残基、seqidno:1的24至35位残基和seqidno:1的68至77位残基的氨基酸序列的肽或表位来检测。
游离组蛋白h2a优选地通过选自跨越seqidno:23的21至53位残基、seqidno:23的21至29位残基、seqidno:23的30至53位残基、seqidno:23的120至129位残基、seqidno:23的21至29位残基、seqidno:23的82至88位残基、seqidno:23的89至95位残基和seqidno:23的100至118位残基的氨基酸序列的肽或表位来检测。
游离组蛋白h2b优选地通过跨越seqidno:31的41至69位残基的肽或表位来检测。
游离组蛋白h3优选地通过跨越seqidno:36的27至37位残基和/或跨越seqidno:36的52至62位残基的肽或表位来检测。
当在本文中使用时,术语“染色质”是指包含细胞基因组的核蛋白结构。细胞染色质包含核酸、主要是dna,以及蛋白质,包括组蛋白和非组蛋白染色体蛋白质。大多数真核细胞染色质以核小体的形式存在,其中核小体核心包含约150个碱基对的dna,其与包含组蛋白h2a、h2b、h3和h4各两个的八聚体相结合;并且在核小体核心之间延伸有连接dna(取决于生物体具有可变的长度)。组蛋白h1的分子一般与连接dna相结合。“染色体”是包含细胞的全部或一部分基因组的染色质复合体。
在本文中,术语“核小体”或“核小体复合物”意味着染色质的基本单位,其由周围被约150个碱基对的dna缠绕的四种核心组蛋白h3、h4、h2a和h2b的八聚体构成。
所检测的表位优选地可以是当组蛋白组装在核小体中时不可接近的表位。如上所述,在本发明的情形中,“不可接近”意味着当组蛋白是核小体复合物的一部分时,所述表位不能被配体、特别是被抗体特异性结合。还涵盖了当组蛋白是核小体复合物的一部分时由于空间位阻而在结构上不可接近的表位。
在本发明的情形中,术语“片段”是指可源自于较大蛋白质或肽的较小蛋白质或肽,因此其包含所述较大蛋白质或肽的部分序列。所述片段可以从较大的蛋白质或肽,通过其一个或多个肽键的水解来衍生。所述片段优选地具有至少6、9、10或12个残基。
在本文中,术语“样品”是生物样品。当在本文中使用时,“样品”可以例如是指出于目标受试者例如患者的诊断、预后或评估的目的而获得的体液或组织的样品。
优选地,在本文中,样品是受试者的体液或组织的样品。体液样品是优选的。优选的试验样品包括血液、血清、血浆、脑脊液、尿液、唾液、痰液和胸腔积液。此外,本领域技术人员将会认识到,某些试验样品在分级或纯化程序例如将全血分离成血清或血浆组分后,将更容易分析。
因此,优选地,在本发明中使用的样品选自血液样品、血清样品、血浆样品、脑脊液样品、唾液样品、尿液样品、组织样品或任何上述样品的提取物。
优选地,所述样品是血液样品,更优选为血清样品或血浆样品。在本发明的情形中,血清样品是最优选的样品。
在适合的情况下,在本发明中使用之前,所述样品可以被均化或用溶剂萃取,以便获得液体样品。在本文中,液体样品可以是溶液或悬液。液体样品在用于本发明之前,可以进行一种或多种预处理。这些预处理包括但不限于稀释、过滤、离心、浓缩、沉降、沉淀或透析。预处理还可以包括向所述溶液添加化学或生物化学物质,例如酸、碱、缓冲剂、盐、溶剂、反应性染料、去污剂、乳化剂、螯合剂。
在本发明的情形中,“血浆”是在离心后获得的含有抗凝剂的血液的事实上无细胞的上清液。示例性的抗凝剂包括钙离子结合性化合物例如edta或柠檬酸盐和凝血酶抑制剂例如肝素盐或水蛭素。无细胞血浆可以通过抗凝化血液(例如柠檬酸化、edta或肝素化血液)的离心,例如在2000至3000g离心至少15分钟来获得。
在本发明的情形中,“血清”是在允许血液凝结后收集的全血的液体级分。当将凝结的血液(凝血)离心时,血清可以作为上清液获得。
术语“患者”、“个体”和“受试者”在整个本发明中可以互换使用。出于本发明的目的,“患者”、“个体”或“受试者”包括人类和其他动物、特别是哺乳动物,以及其他生物体。因此,所述方法适用于人类诊断和兽医应用两者。在优选实施方式中,所述患者是哺乳动物,并且在最优选实施方式中,所述患者或受试者是人类。当在本文中使用时,术语“患者”是指未接受医疗护理或正接受医疗护理或由于疾病或医学病症、特别是系统性炎症而应该接受医疗护理的活的人类或非人类生物体。这包括正被调查疾病征兆的没有确定患病的人。因此,本文中描述的方法和测定法适用于人类和兽医疾病两者。
本文中使用的术语“表位”,也被称为抗原决定簇,是指抗原的被抗体、b细胞或t细胞识别的部分。因此,“表位”意味着分子的抗体与其结合的部分,例如多肽区段。术语“表位”涵盖了构象表位和线性表位两者。
在本发明的情形中,在本发明的方法中检测的游离组蛋白或其肽片段可以被看作生物标志物,术语“生物标志物”是指可测量且可定量的生物学参数(例如特定酶的浓度、特定激素的浓度、特定基因表型在群体中的分布、生物物质的存在),其充当指数用于与健康和生理相关的评估,例如疾病风险、精神障碍、环境暴露及其影响、疾病诊断、代谢过程、物质滥用、妊娠、细胞系发育、流行病学研究等。此外,生物标志物被定义为作为正常生物学过程、病理过程或对治疗性干预的药理响应的指示物而被客观测量和评估的特征。生物标志物可以在生物样品上测量(作为血液、尿液或组织化验),并且它可以是从人获得的记录(血压、ecg或holter)。生物标志物可以指示各种不同的健康或疾病特征,包括暴露于环境因素的水平或类型、遗传易感性、对暴露的遗传响应、亚临床或临床疾病的生物标志物或对疗法的响应的指示物。因此,考虑生物标志物的简化方式是作为疾病性状(风险因子或风险生物标志物)、疾病状态(临床前或临床)或疾病速率(进展)的指示物。因此,生物标志物可以被分类为先行生物标志物(鉴定发生疾病的风险)、筛查生物标志物(亚临床疾病的筛查)、诊断生物标志物(识别外显疾病)、分期生物标志物(对疾病的严重性分类)或预后生物标志物(预测将来的疾病过程,包括复发和对疗法的响应,以及监测疗法的效能)。生物标志物也可充当替代终点。替代终点是在临床试验中可用作结果以代替真正的目标结果的测量来评估疗法的安全性和有效性的终点。隐含的原理是替代终点的变化密切追踪目标结果的变化。替代终点与诸如发病率和死亡率这些需要大型临床试验来评估的终点相比,具有可以在较短的时间框中并以较少的成本来收集的优点。替代终点的其他价值包括它们与更远的临床事件相比,更接近目标暴露/干预并且可以更容易进行因果关联的事实。替代终点的一个重要缺点在于如果目标临床结果受到大量因素(除了替代终点之外)影响,则残留的迷惑性可能降低替代终点的有效性。已建议,如果替代终点可以解释至少50%的暴露或干预对目标结果的影响,则它的有效性更大。例如,生物标志物可以是蛋白质、肽或核酸分子。在本发明的情形中,游离组蛋白可以与其他生物标志物一起使用,即游离组蛋白可以是生物标志物组的一部分。
在本发明的情形中,“诊断”是指受试者中的疾病或临床病症的识别和(早期)检测,并且也可以包括差异诊断。在某些实施方式中,疾病或临床病症的严重性的评估,也可以被术语“诊断”所涵盖。
“预后”是指患有特定疾病或临床病症的受试者的结果或特定风险的预测。这可以包括所述受试者的恢复机会或不利结果的机会的估算。
本发明的方法也可用于监测。“监测”是指保持追踪已经诊断的疾病、障碍、并发症或风险,以例如分析所述疾病的进展或特定治疗对疾病或障碍的进展的影响。
在本发明的情形中,术语“疗法控制”是指所述患者的治疗性治疗的监测和/或调整。
在本发明中,术语“风险评估”和“危险分层”是指按照受试者的进一步预后将它们分成不同的风险组。风险评估还涉及为应用预防性和/或治疗性措施而分层。
此外或可选地,在本发明的方法中,所述待检测的游离组蛋白的表位或肽片段没有翻译后修饰。
在本发明的情形中,术语“翻译后修饰”或“ptm”是指在蛋白质被核糖体的翻译完成后,通过酶的催化在其上发生的修饰。翻译后修饰通常是指将官能团共价添加到蛋白质。优选地,在本发明的情形中,组蛋白的“翻译后修饰”是例如通过乙酰基转移酶、赖氨酸甲基转移酶和赖氨酸去甲基化酶引入的修饰。优选地,在本发明的情形中,翻译后修饰选自乙酰化、瓜氨酸化、脱乙酰化、甲基化、去甲基化、脱亚胺化、异构化、磷酸化和遍在蛋白化。
在本发明的诊断、预后和风险评估方法的情形中,可以另外分析至少一种临床参数,其中所述临床参数选自体温、血压、心率、白细胞数。
在本发明的诊断、预后和风险评估方法的情形中,可以另外分析至少一种生物标志物,其中所述生物标志物选自降钙素、肾上腺髓质素(adm/proadm)、内皮素-1(et-1)、精氨酸加压素(avp)、心房利钠肽(anp)、嗜中性粒细胞明胶酶相关性脂质运载蛋白(ngal)、肌钙蛋白、脑利钠肽(bnp)、c-反应性蛋白(crp)、胰石蛋白(psp)、髓样细胞上表达的触发性受体1(trem1)、白介素-6(il-6)、白介素-20(il-20)、白介素-22(il-22)、白介素-24(il-24)、其他il、presepsin、脂多糖结合蛋白(lbp)、α-1-抗胰蛋白酶、基质金属蛋白酶2(mmp2)、基质金属蛋白酶9(mmp9)和肿瘤坏死因子α(tnfα)。优选地,至少一种生物标志物选自降钙素原(pct)、肾上腺髓质素(adm/proadm)、presepsin(scd14-st)和c反应性蛋白(crp)。
本发明的任一方法的疾病或医学病症可以选自涉及个体的系统性炎性响应(sirs)的疾病或医学病症,所述炎性响应涉及感染性和非感染性病因例如由微生物刺激物即细菌、病毒、真菌或寄生虫引起的脓毒症、重症脓毒症和脓毒性休克,创伤性损伤和/或出血,缺血再灌注损伤,烧伤,急性胰腺炎,以及介入治疗例如心肺转流术、化疗和放疗,其中个体处于发生内皮组织损伤、血栓栓塞和急性播散性血管内凝血(dic)的风险,在疾病的过程中造成单一或多个器官机能障碍和衰竭(特别是急性肾损伤、急性肺损伤和肝损伤)。
在本发明的情形中,“系统性炎症”优选地是指以促炎性细胞因子的释放和可以由生物因子、化学因子或遗传因子引起的先天免疫系统的激活为特征的病症。严重的“系统性炎症”可以引起器官衰竭和死亡。
在本发明的情形中,“sirs”是没有感染迹象的系统性炎性响应综合征。它包括但不限于超过一种下述临床表象:(1)体温高于38℃或低于36℃;(2)心率高于每分钟90次;(3)呼吸急促,表现为呼吸率超过每分钟20次呼吸,或换气过度,由低于32mmhg的paco2所指示;以及(4)白细胞计数的变化,例如计数超过12,000/mm3,计数低于4,000/mm3,或存在超过10%的未成熟的嗜中性粒细胞(bone等,chest101(6):1644-55,1992)。
在本发明的情形中,“脓毒症”意味着对感染的系统性响应。或者,脓毒症可以被看作sirs与已确认的感染过程的组合。脓毒症可以被表征为由感染和系统性炎性响应两者的存在所定义的临床综合征(levymm等,2001sccm/esicm/accp/ats/sisinternationalsepsisdefinitionsconference.critcaremed.2003apr;31(4):1250-6)。本文中使用的术语“脓毒症”包括但不限于脓毒症、重症脓毒症、脓毒性休克。在这种情形中,重症脓毒症意味着伴有器官机能障碍、低灌注异常或脓毒症诱导的低血压的脓毒症。低灌注异常包括乳酸血症、少尿和精神状态的急性变化。脓毒症诱导的低血压由在不存在低血压的其他原因(例如心源性休克)的情况下出现收缩压低于90mmhg或从基线降低40mmhg或以上所定义。脓毒性休克被定义为尽管使用足够的液体复苏但脓毒症诱导的低血压仍持续,并伴随着低灌注异常或器官机能障碍的出现的重症脓毒症(bone等,chest101(6):1644-55,1992)。本文中使用的术语“脓毒症”涉及脓毒症发展中的所有可能阶段。
在本发明的范围内,上述“感染”意味着由病原性或潜在病原性微生物侵入正常情况下无菌的组织或流体而引起的病理过程,并涉及由细菌、真菌、寄生虫和/或病毒引起的感染。
在本发明的情形中,“胰腺炎”可以被看作胰腺的炎症,其发展从急性(突然发作;持续时间<6个月)到复发性急性(>1次急性胰腺炎发作期)到慢性(持续时间>6个月)。在本发明的范围内包括但不限于家族性胰腺炎、遗传性胰腺炎和特应性偶发胰腺炎。
在本发明的情形中,术语“多发伤”涵盖在身体的至少两个区域中具有两个或更多个严重损伤的病症,或具有多个损伤、即在一个身体区域中的两个或更多个严重损伤的病症。多发伤可能伴有创伤性休克和/或出血性低血压和一种或多种生命机能的严重危险。两个或更多个损伤中的至少一个或所有损伤的总和危及具有多发伤的受伤受试者的生命(kroupaj.,actachirorthoptraumatolcech.1990jul;57(4):347-60)。在本发明的情形中,所述疾病或病症优选为系统性炎症,更优选为脓毒症或sirs。
正如上面提到的,游离组蛋白可以使用任何适合的方法来检测。在本发明的情形中,基于免疫测定法的方法和基于质谱法的方法是特别优选的,并且将在下文中更详细描述:
基于免疫测定法的方法
本发明还涉及利用本发明的任何方法的免疫测定法。具体来说,所述免疫测定法包括下述步骤:a)将所述样品与特异性针对所述游离组蛋白靶的第一表位的第一抗体或其抗原结合片段或衍生物和特异性针对所述游离组蛋白靶的第二表位的第二抗体或其抗原结合片段或衍生物相接触,以及b)检测所述两种抗体或其抗原结合片段或衍生物与所述游离组蛋白的结合。这种测定法的一个实例是夹心elisa测定法。
在本文中,除非另有指明,否则术语“抗体”也包含抗原结合片段或衍生物。
或者,代替抗体,本发明的范围可以涵盖特异性和/或选择性识别组蛋白序列、组蛋白表位和组蛋白的结构构象的其他捕获分子或分子支架。
在本文中,术语“捕获分子”或“分子支架”包含可用于从样品结合靶分子或目标分子、即被分析物(在本发明的情形中,即游离组蛋白)的分子。因此,捕获分子必须在空间上和表面特点例如表面电荷、疏水性、亲水性、路易斯供体和受体的存在或不存在两方面充分塑造,以特异性结合所述靶分子或目标分子。在这里,所述结合可以例如由所述捕获分子或分子支架与靶分子或目标分子之间的离子、范德华、π-π、σ-π、疏水或氢键相互作用或两种或更多种上述相互作用的组合或共价相互作用介导。在本发明的情形中,捕获分子或分子支架可以例如选自核酸分子、糖类分子、pna分子、蛋白质、肽和糖蛋白。捕获分子或分子支架包括例如适体、darpin(设计的锚蛋白重复蛋白)、affimer等。
术语“抗体”通常包含单克隆抗体、遗传工程改造的单克隆抗体和多克隆抗体及其结合片段,特别是fc-片段以及所谓的“单链抗体”(birdr.e.等,(1988)science242:423-6),嵌合的、人源化的、特别是cdr嫁接的抗体,以及双体或四体抗体(holligerp.等,(1993)proc.natl.acad.sci.u.s.a.90:6444-8)。抗体可以是天然存在的和非天然存在的。此外,抗体包括全合成抗体、单链抗体及其片段。抗体可以是人类或非人类的。非人类抗体可以通过重组方法人源化,以降低它们在人类中的免疫原性。抗体片段包括但不限于fab和fc片段。“抗体的fc部分”可以是通过免疫球蛋白的木瓜蛋白酶消化获得的可结晶片段,其由通过二硫键连接的两条重链的c-端半条链构成,并被称为免疫球蛋白的“效应区”。“抗体的fc部分”也可以意味着重链的所有或基本上所有的c-端半条链。还包含通过包括例如噬菌体展示的技术选择的特异性结合到样品中包含的目标分子的免疫球蛋白样蛋白质。在这种情形中,术语“特异的”和“特异性结合”指称针对目标分子或其片段产生的抗体。如果抗体对目标分子(在这里是游离组蛋白)或其提到的片段的亲和性比对含有目标分子的样品中包含的其他分子的亲和性高至少50倍、优选地高100倍、最优选地高至少1000倍,则所述抗体被认为是特异的。如何开发和选择具有给定特异性的抗体,在本领域中是公知的。在本发明的情形中,单克隆抗体是优选的。
正如将在下文中更详细讨论的,本发明的(第一和/或第二)抗体或其抗原结合片段或衍生物可以例如是多克隆抗体、单克隆抗体或遗传工程改造的单克隆抗体。
所述抗体与游离组蛋白(或其片段)的结合发生在适合的条件下(即允许免疫反应,即所述抗体与游离组蛋白的结合并形成免疫复合体的条件下)。这些条件对于专业技术人员来说是已知的,并且可以使用例如如下所述的免疫测定法的标准格式。这些条件优选是在生理温度、ph和离子强度下,并且可以在介质例如磷酸盐缓冲盐水(pbs)中发生。
在说明性实施例1至4中,描述了用于检测游离组蛋白的抗体和基于免疫测定法的方法。在随附的实施例中证实,检测游离组蛋白的表位可以是存在于跨越符合seqidno:1的组蛋白h4的22至102位氨基酸残基或符合seqidno:23的组蛋白h2a的20至118位氨基酸残基的序列中的表位。此外,检测游离组蛋白的表位可以是存在于跨越符合seqidno:36的组蛋白h3的27至62位氨基酸残基或符合seqidno:31的组蛋白h2b的41至69位氨基酸残基的序列中的表位。
此外,本发明的免疫测定法可以优选地利用特异性针对游离组蛋白h4的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物,其中所述第一表位和/或第二表位是存在于跨越seqidno:1的22至102位氨基酸残基的序列中的组蛋白h4的表位。
此外,本发明的免疫测定法可以利用特异性针对游离组蛋白h2a的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物,其中所述第一表位和/或第二表位是存在于跨越seqidno:23的21至53、20至118或120至129位氨基酸残基的序列中的组蛋白h2a的表位。
此外,本发明的免疫测定法可以利用特异性针对游离组蛋白h3的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物,其中所述第一表位和/或第二表位是存在于跨越seqidno:36的27至63位氨基酸残基的序列中的组蛋白h3的表位。
更优选地,本发明的免疫测定法利用特异性针对游离组蛋白h4的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物,其中所述表位选自跨越seqidno:1的22至30位残基、seqidno:1的67至78位残基、seqidno:1的92至102位残基、seqidno:1的22至34位残基和seqidno:1的46至102位残基的氨基酸序列。
此外,本发明的免疫测定法优选地利用特异性针对游离组蛋白h2a的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物,其中所述表位选自跨越seqidno:23的21至53位残基、seqidno:23的21至29位残基、seqidno:23的30至53位残基和seqidno:23的120至129位残基的氨基酸序列。
此外,本发明的免疫测定法可以利用特异性针对跨越seqidno:31的41至69位残基的游离组蛋白h2b的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物。
此外,本发明的免疫测定法可以利用特异性针对跨越seqidno:36的27至37位残基和/或跨越seqidno:36的52至62位残基的游离组蛋白h3的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物。
此外,本发明的免疫测定法优选地利用特异性针对游离组蛋白h2a的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物,所述表位存在于跨越由seqidno:23表示的组蛋白h2a序列的21至53位和/或120至129位残基的序列中。换句话说,本发明的免疫测定法优选地可以利用特异性针对存在于跨越由seqidno:23表示的组蛋白h2a序列的21至53位和/或120至129位氨基酸残基的序列中的组蛋白h2a的表位的第一抗体和/或第二抗体或其抗原结合片段或衍生物。
此外,本发明的免疫测定法可以利用特异性针对存在于跨越seqidno:1的22至102位氨基酸残基的序列中的组蛋白h4的表位的第一抗体、其抗原结合片段或衍生物,以及特异性针对游离组蛋白h2a、h2b或优选地h3的表位的第二抗体、其抗原结合片段或衍生物。
此外,本发明的免疫测定法可以利用特异性针对存在于跨越seqidno:23的21至53位、120至129位或20至118位氨基酸残基的序列中的组蛋白h2a的表位的第一抗体、其抗原结合片段或衍生物,以及特异性针对游离组蛋白h3、h4或优选地h2b的表位的第二抗体、其抗原结合片段或衍生物。
此外,本发明的免疫测定法可以利用特异性针对存在于跨越seqidno:36的27至62位氨基酸残基的序列中的组蛋白h3的表位的第一抗体、其抗原结合片段或衍生物,以及特异性针对游离组蛋白h4或优选地h2a或h2b的表位的第二抗体、其抗原结合片段或衍生物。
在本文中理解,在本文中提供的免疫测定法的情形中,与“第一”和“第二”抗体、其抗原结合片段或衍生物相关的接触步骤的顺序可以改变。因此,在本文中理解,可以首先将所述“第二”抗体、其抗原结合片段或衍生物与所述样品相接触,随后可以将所述“第一”抗体、其抗原结合片段或衍生物与所述样品相接触。在本文中还理解,可以将所述两种抗体、其抗原结合片段或衍生物同时与所述样品相接触。
本发明的免疫测定法可以利用特异性针对存在于跨越seqidno:23的21至29位氨基酸残基的序列中的组蛋白h2a的表位的第一抗体或其抗原结合片段或衍生物,和/或特异性针对存在于跨越seqidno:23的30至53位氨基酸残基的序列中的组蛋白h2a的表位的第二抗体或其抗原结合片段或衍生物。
本发明的免疫测定法优选地也可以利用特异性针对存在于跨越seqidno:1的22至30位氨基酸残基(对应于肽h4-li-9,seqidno:10)或seqidno:1的46至102位残基(对应于seqidno:2)或seqidno:1的22至34位残基的序列中存在的组蛋白h4的表位的第一抗体或其抗原结合片段或衍生物,以及特异性针对跨越组蛋白h4(seqidno:1)的46至102位氨基酸残基的序列中的表位的第二抗体或其抗原结合片段或衍生物。
本发明的免疫测定法可以利用特异性针对存在于跨越seqidno:1的20至30位氨基酸残基或seqidno:1的67至78位残基或seqidno:1的92至102位残基或seqidno:1的22至34位残基、优选为seqidno:1的67至78位残基的序列中的组蛋白h4的表位的第一抗体或其抗原结合片段或衍生物,和/或特异性针对存在于跨越seqidno:1的46至102位氨基酸残基的序列中的组蛋白h4的表位的第二抗体或其抗原结合片段或衍生物。
优选的检测方法包括采取各种不同格式的免疫测定法,例如放射免疫测定法(ria)、化学发光和荧光免疫测定法、酶免疫测定法(eia)、酶联免疫测定法(elisa)、基于发光的珠子阵列、基于磁珠的测定法、蛋白质微阵列测定法、快速测试格式例如免疫层析试条测试。
本发明的测定法可以是均相或非均相测定法、竞争和非竞争测定法。在特别优选的实施方式中,所述测定法采取夹心测定法的形式,这是一种非竞争免疫测定法,其中待检测和/或定量的分子被结合到第一抗体并结合到第二抗体。所述第一抗体可以被结合到固相例如珠子、孔或其他容器的表面、芯片或试条,并且所述第二抗体是例如用染料、放射性同位素或反应性或催化活性组成部分标记的抗体,或反之亦然。然后通过适合的方法测量结合到被分析物的标记抗体的量。涉及“夹心测定法”的一般性组成和程序是已确立的,并且为专业技术人员所知(《免疫测定法手册》(theimmunoassayhandbook),ed.davidwild,elsevierltd,oxford;第三版(may2005),isbn-13:978-0080445267;hultschigc等,curropinchembiol.2006feb;10(1):4-10.pmid:16376134,通过参考并入本文)。
在本发明的情形中,所述测定法可以包含两种捕获分子、优选为抗体,其两者都作为在液体反应混合物中的分散系存在,其中第一标记组分被附连到第一捕获分子,其中所述第一标记组分是基于荧光或化学发光-淬灭或扩增的标记系统的一部分,并且所述标记系统的第二标记组分被附连到第二捕获分子,使得在两种捕获分子结合到所述被分析物后,产生可测量的信号,其允许在包含所述样品的溶液中检测形成的夹心复合物。
优选地,所述标记系统包含稀土穴状化合物或稀土螯合物与荧光染料或化学发光染料、特别是花青素类型的染料的组合。
在本发明的情形中,基于荧光的测定法可以包括使用染料,其可以例如选自fam(5-或6-羧基荧光素)、vic、ned、荧光素、荧光素异硫氰酸酯(fitc)、ird-700/800、花青染料例如cy3、cy5、cy3.5、cy5.5、cy7、占吨、6-羧基-2’,4’,7’,4,7-六氯荧光素(hex)、tet、6-羧基-4’,5’-二氯-2’,7’-二甲氧基荧光素(joe)、n,n,n’,n’-四甲基-6-羧基罗丹明(tamra)、6-羧基-x-罗丹明(rox)、5-羧基罗丹明-6g(r6g5)、6-羧基罗丹明-6g(rg6)、罗丹明、罗丹明绿、罗丹明红、罗丹明110、bodipy染料例如bodipytmr、俄勒冈绿、香豆素类例如伞形酮、苯甲亚胺类例如hoechst33258、菲啶类例如德克萨斯红、yakima黄、alexafluor、pet、溴乙菲啶、吖啶染料、咔唑染料、吩噁嗪染料、卟啉燃料、聚甲炔染料等。
在本发明的情形中,基于化学发光的测定法包括使用基于在下述文献中为化学发光材料所描述的物理原理的染料:kirk-othmer,《化学技术百科全书》(encyclopediaofchemicaltechnology),第四版,执行主编j.i.kroschwitz,主编m.howe-grant,johnwiley&sons,1993,vol.15,p.518-562,通过参考并入本文,包括在第551-562页上的引用文献。优选的化学发光染料是吖啶酯。游离组蛋白可以例如在b.r.a.h.m.skryptor紧凑型plus仪器(thermoscientificb.r.a.h.m.sgmbh,hennigsdorf/berlin,germany)上,使用全自动夹心免疫测定法系统来检测。这种随机存取分析仪利用基于两种荧光团之间的非放射活性转移的灵敏的时间分辨扩增穴状化合物发射(trace)技术。
本发明还涉及一种方法,其中所述抗体之一(例如第一抗体)被标记,并且另一种抗体(例如第二抗体)被结合到固相或者可以被选择性结合到固相。然而,正如上面提到的,在本发明的方法的情形中,优选地所述第一和第二抗体分散地存在于液体反应混合物中,并且其中作为基于荧光或化学发光消光或扩增的标记系统的一部分的第一标记组分被结合到所述第一抗体,并且所述标记系统的第二标记组分被结合到所述第二抗体,使得在两种抗体结合到组蛋白(或其片段)之后,产生可测量的信号,其允许检测在测量溶液中得到的夹心复合物。
正如本文中提到的,“测定法”或“诊断测定法”可以是在诊断学领域中使用的任何类型。这种测定法可以基于待检测的被分析物与具有一定亲和性的一种或多种捕获探针的结合。对于抗体与靶分子或目标分子之间的相互作用来说,亲和常数优选地高于108m-1。
本发明还涉及特异性针对上面已经详细描述的游离组蛋白或其片段的表位的如上所述的抗体或其抗原结合片段或衍生物。
随附的实施例记录了成功地用于检测符合本发明的游离组蛋白的示例性抗体。因此,本发明涉及特异性针对游离组蛋白h4、h2a、h2b和/或h3的表位的抗体、其抗原结合片段或衍生物。此外,本发明涉及特异性针对游离组蛋白h4的表位的抗体、其抗原结合片段或衍生物,所述表位包含在跨越符合seqidno:1的组蛋白h4的22至102位氨基酸残基的序列中。
此外,本发明涉及特异性针对游离组蛋白h4的表位的抗体、其抗原结合片段或衍生物,所述表位包含在跨越符合seqidno:1的组蛋白h4的46至102位氨基酸残基的序列中。
更优选地,本发明涉及特异性针对游离组蛋白h4的表位的抗体、其抗原结合片段或衍生物,所述表位包含在选自跨越seqidno:1的22至30位残基、seqidno:1的67至78位残基、seqidno:1的92至102位残基、seqidno:1的22至34位残基、seqidno:1的46至102位残基、seqidno:1的46至55位残基、seqidno:1的60至67位残基、seqidno:1的80至91位残基、seqidno:1的24至35位残基和seqidno:1的68至77位残基的氨基酸序列的序列中。
此外,本发明涉及特异性针对游离组蛋白h2a的表位的抗体、其抗原结合片段或衍生物,所述表位包含在跨越符合seqidno:23的组蛋白h2a的20至118位氨基酸残基的序列中。
更优选地,本发明涉及特异性针对游离组蛋白h2a的表位的抗体、其抗原结合片段或衍生物,所述表位包含在选自跨越seqidno:23的21至53位残基、seqidno:23的21至29位残基、seqidno:23的30至53位残基、seqidno:23的120至129位残基、seqidno:23的21至29位残基、seqidno:23的82至88位残基、seqidno:23的89至95位残基和seqidno:23的100至118位残基的氨基酸序列的序列中。
此外,本发明涉及特异性针对游离组蛋白h3的表位的抗体、其抗原结合片段或衍生物,所述表位包含在跨越符合seqidno:36的组蛋白h3的27至62位氨基酸残基的序列中。
更优选地,本发明涉及特异性针对游离组蛋白h3的表位的抗体、其抗原结合片段或衍生物,所述表位包含在跨越seqidno:36的27至37位残基和/或seqidno:36的52至62位残基的序列中。
此外,本发明涉及特异性针对游离组蛋白h2b的表位的抗体、其抗原结合片段或衍生物,所述表位包含在跨越符合seqidno:31的组蛋白h2b的41至69位氨基酸残基的序列中。
在本发明的情形中,特别优选的是特异性针对跨越符合seqidno:23的游离组蛋白h2a的22至55位或70至118位氨基酸残基的序列中的组蛋白h2a的表位的抗体或其抗原结合片段或衍生物,或特异性针对存在于跨越seqidno:1的46至102位氨基酸残基的序列中的组蛋白h4的表位的抗体或其抗原结合片段或衍生物。换句话说,在本发明的优选情况下,所述抗体或其抗原结合片段或衍生物特异性针对seqidno:2中给出的表位。
本发明还涉及表达本发明的抗体或其抗原结合片段或衍生物的宿主细胞。
在本发明的情形中,术语“宿主细胞”是指表达本发明的抗体或其抗原结合片段或衍生物的任何细胞。因此,原核以及真核细胞在本发明的范围内。
本发明还涉及包含本发明的抗体或其抗原结合片段或衍生物的试剂盒。上面提到的本发明的抗体可用于本发明的试剂盒中。
本发明还涵盖了本发明的抗体或其抗原结合片段或衍生物的用途或本发明的试剂盒的用途,其用于疾病或医学病症的诊断、预后、风险评估和/或疗法控制的方法中,所述疾病或医学病症选自涉及个体的系统性炎性响应(sirs)的疾病或医学病症,所述炎性响应涉及感染性和非感染性病因例如由微生物刺激物即细菌、病毒、真菌和/或寄生虫引起的脓毒症、重症脓毒症和脓毒性休克,创伤性损伤和/或出血,缺血再灌注损伤,烧伤,急性胰腺炎,以及介入治疗例如心肺转流术、化疗和放疗,其中个体处于发生内皮组织损伤、血栓栓塞和急性播散性血管内凝血(dic)的风险,在疾病的过程中造成单一或多个器官机能障碍和衰竭(特别是急性肾损伤、急性肺损伤和肝损伤)。
基于质谱法的方法
根据本发明,所述游离组蛋白分子可以使用质谱法(ms)方法来检测。因此,本发明还提供了一种用于上面定义的疾病或医学病症的诊断、预后、风险评估、危险分层和/或疗法控制的方法,所述方法包括通过质谱法(ms)检测样品中的至少一种游离组蛋白或其肽片段。因此,本发明涉及将ms用于患者中的上面提到的障碍或医学病症的诊断、预后、风险评估、筛查和疗法监测。
本发明还涉及一种用于测量生物样品中游离组蛋白的量的方法,所述方法包括检测所述生物样品或来自于所述样品的蛋白质消化物(例如胰蛋白酶消化物)中一种或多种修饰或未修饰的组蛋白片段肽的存在或量,以及任选地使用层析方法分离所述样品,并对所述制备并任选地分离的样品进行ms分析。例如,在ms分析中可以使用选择反应监测(srm)、多反应监测(mrm)或平行反应监测(prm)质谱法,以特别是确定至少一种组蛋白肽的量。
在本发明的ms分析方法的一种情况下,在蛋白水解消化之前不需预先分离所述样品中的蛋白质。游离组蛋白及其肽的可靠检测,可以在不使用包含脱脂、层析、离心或剥离丰富蛋白质的亲和基质的分离方法的情况下实现。
在本文中,术语“质谱法”或“ms”是指通过质量鉴定化合物的一种分析技术。ms是指基于离子的质荷比或“m/z”来过滤、检测和测量离子的方法。“ms”技术的特征在于:(1)将化合物电离以产生带电荷的化合物,以及(2)检测所述带电荷化合物的质荷比。所述化合物通常通过电离器电离并通过离子检测器检测。电离器和离子检测器被并入到质谱仪中。一般来说,将一个或多个目标分子电离,随后将离子引入到质谱仪中,在其中离子按照它们的m/z分离。这种分离可以在离子在电场(或电场与磁场的组合)中的m/z依赖性行为或具有m/z依赖性动力学能量的离子在无场区域中的飞行时间可变性的基础上进行。参见例如题为“来自于表面的质谱法”(massspectrometryfromsurfaces)的美国专利号6,204,500;题为“用于串联质谱法的方法和装置”(methodsandapparatusfortandemmassspectrometry)的美国专利号6,107,623;题为“基于质谱法的dna诊断”(dnadiagnosticsbasedonmassspectrometry)的美国专利号6,268,144;题为“用于被分析物的解吸和检测的表面增强的光不稳定性附连和释放”(surface-enhancedphotolabileattachmentandreleasefordesorptionanddetectionofanalytes)的美国专利号6,124,137;wright等,prostatecancerandprostaticdiseases2:264-76(1999);以及merchant和weinberger,electrophoresis21:1164-67(2000)。
一般来说,取决于分析的目的,ms检测和分析可以以不同方式进行。自上而下的蛋白质组学涉及完整分析,其维持蛋白质完整性用于降解产物、序列变体和翻译后修饰的组合的检测。自下而上的肽分析涉及纯化的蛋白质样品的还原、烷基化和消化,以接近并分析肽片段。
为了增强质谱法的质量分辨和质量确定能力,可以在ms分析之前对样品进行加工。因此,本发明涉及ms检测方法,其可以与免疫富集技术、与样品制备相关的方法和/或层析方法相组合,优选地与液相色谱(lc)、更优选地与高效液相色谱(hplc)或超高效液相色谱(uhplc)相结合。样品制备方法包括用于将样品裂解、分级、消化成肽、剥离、富集、透析、脱盐、烷基化和/或肽还原的技术。然而,这些步骤是任选的。在本发明的一种情况下,为了测量片段例如seqidno:2,不需蛋白水解(例如胰蛋白酶)消化。在ms分析之前可以对样品进行免疫富集。质谱免疫测定法技术例如thermofishermsiatm技术可以在消化之前使用,或者可以在消化后使用
单维度或多维度hplc可用于分离蛋白质或肽。可以将蛋白质或肽混合物通过一系列层析固定相或维度,其提供更高的分辨力。hplc可适应于许多实验方法,并且可以对各种不同的固定相和流动性进行选择,以获得它们在分辨特定目标蛋白质或肽类别中的适合性和彼此之间以及与下游质谱测量检测和鉴定方法的相容性。hplc可用于分离已被或未被产生相应酶产物、即肽混合物的蛋白水解酶消化的临床样品。可以将所述相应的肽混合物通过一系列层析固定相或维度,其提供更高的分辨力。肽和蛋白质的分离是基于肽序列、肽序列的官能团以及物理性质。
因此,质谱检测可以与在质谱检测之前进行的液相色谱(lc)的应用相结合。更优选地,在质谱检测之前进行高效液相色谱(hplc)。
在本发明的优选情况下,所述基于ms的方法不依赖于蛋白水解消化之前的预备性蛋白纯化。此外,在蛋白水解消化之前,可能不需除去生物化学化合物例如脂类、蛋白质或dna。在优选情况下,在蛋白水解消化之前,可能不需按照物理性质分离蛋白质的纯化步骤,即层析或离心。此外,在蛋白水解消化之前,可能不需剥离丰富或中等丰富的蛋白质。丰富蛋白可以通过诸如ig-y12柱的基质来去除。在本发明的情形中,这些预先分离步骤被称为蛋白水解消化之前的预分离。因此,在生物样品例如血清或血浆中的游离组蛋白可以在蛋白水解消化之前不进行任何预处理或预分离的情况下检测。
在某些情况下,可以在没有预先分离程序的情况下对生物样品进行ms分析,在所述预先分离程序中可以进行免疫富集技术和预处理程序。在这种实施方式中,样品优选地通过使用静态电喷雾原理的直接输注、流动注入分析或带有样品富集的流动注入来分析。
当在本文中使用时,术语样品分子的“电离”或“离子化”是指产生具有等于一个或多个电子单位的净电荷的被分析物离子的不同技术。所述技术可以是化学电离(ci)、电子电离(ei)、快原子轰击(fab)、基质辅助激光解吸电离(maldi)、电喷雾电离(esi)、表面增强激光解吸电离(seldi)、大气压化学电离(apci)、大气压光致电离(appi)、电感耦合等离子体(icp)、场解吸(fd)、热喷雾、硅上的解吸/电离(dios)、二次离子质谱法(sims)、火花放电电离、热电离或离子附着电离。
被分析物离子的选择性检测可以使用串联质谱法(ms/ms)进行。串联质谱法的特征在于质量选择步骤(当在本文中使用时,术语“质量选择”是指具有特定m/z或狭窄的m/z范围的离子的分离),随后进行所选离子的片段化和得到的产物(片段)离子的质量分析。
所述前体被分析物离子可以使用不同技术片段化,所述技术可以选自碰撞诱导的解离(cid)、多阶段激活(msa)、脉冲式q解离(pqd)、电子转移解离(etd)、热毛细管解离(htd)、电子捕获解离(ecd)或红外多光子解离(irmpd)、高能c-阱解离(hcd)。
当在本文中使用时,串联质谱法优选地通过使用三级串联四极杆质谱仪来进行。串联质谱仪的特征在于第一和第三四极杆是质量过滤器,即能够选择性传送所需m/z或狭窄m/z范围的离子。第二四极杆被用于碰撞诱导的解离。前体被分析物离子在第一四极杆中被选择,并在第二四极杆中通过与中性气体的碰撞而发生解离。第三四极杆过滤电离的片段,其通过任选地包括电子倍增器的检测系统进一步检测(hoffmanne.,journalofmassspectrometry,vol.31,1996,129-137)。
正如本文中概括的,三级串联四极杆质谱仪可用于进行选择反应监测(srm),也被称为多反应监测(mrm),以及定量选择反应监测(qsrm)。
或者,测定法可以利用平行反应监测(prm)来检测和定量靶被分析物。与下文中所描述的通过在特征性跃迁之间切换来连续检测和定量不同产物离子的mrm相反,prm同时检测并定量由共同前体离子的片段化产生的两种或更多种产物。一般来说,prm需要不同产物离子物质的积累和随后的质量分析。在一个非限制性实例中,prm可以在可以从thermofisherscientific(bremen,germany)获得的qexactive质谱仪上进行。在qexactive质谱仪中,特定m/z的前体离子被四极杆质量过滤器选择性传送到碰撞室,在其中它们以相对高的能量与中性气体的分子或原子碰撞,因此经历碰撞诱导的解离以形成产物离子。收集到的包括具有各种不同的m/z的不同离子物质的产物离子,随后被递送到轨道静电阱(orbitrap)质量分析仪,其对产物离子进行质量分析,以产生代表多种产物离子物质中每一种的个体丰度(强度)的质谱图。
所述检测方法可以包含采取例如选择/多反应监测(srm/mrm)格式的测定法。
在这种情形中,优选地使用三级串联四极杆质谱仪来进行srm/mrm。srm或定量选择反应监测(qsrm)是用于精确分析和定量复杂生物样品中的化合物(蛋白质)的技术,产生高水平的选择性和灵敏度。当在本文中使用时,“qsrm”是指如下所述的选择反应监测,其中通过使用同位素标记的参比肽或全长蛋白质来定量所选的肽。
当在本文中使用时,术语“srm”定义了一种技术,在其中在质谱仪中选择并分离特定前体被分析物(作为待检测的靶蛋白、在这里是游离组蛋白的替代物的肽)。将所述电离的前体被分析物片段化,并在质荷比的基础上监测所述电离的片段,用于检测和定量。与所述前体和片段离子相关的特定的一对m/z值,被称为“跃迁”。
所述“跃迁”是指第一和第三四极杆被调制到的一对特定的前体/片段离子m/z值。所述“跃迁”对于作为复杂的蛋白质消化物中的目标蛋白的替代物的特定肽的鉴定和定量来说是必不可少的。平均来说,在qsrm测定法中测量替代物与合成的同位素标记的参比肽的2-4个跃迁。为了使用srm/qsrm测量值,建议为每个肽使用至少两个跃迁以确保特异性并且不错误鉴定靶物质。
一般来说,srm/mrm测定法的建立始于在目标蛋白被消化后选择一个或多个肽。适合的肽(前体被分析物)显示出明显高的质谱信号响应。其次,选择对所述前体被分析物特异的肽片段。对于每个前体被分析物-片段来说,可以进行特定ms参数包括碰撞能量、离子光学设置和停留时间的优化。随后的跃迁验证确认了生物样品(例如血浆/血清)中的可检测性并评估背景。通过添加同位素标记的标准肽,可以对前体被分析物定量,对于肽和片段的选择来说,可以使用预测工具(例如具有算法预测、数据库的软件程序)来帮助选择最适的跃迁。
正如上面概述的,本发明在一种情况下涉及生物样品中游离组蛋白的检测和/或定量,其中使用包括应用液相色谱和srm和/或qsrm测定法的方法,所述测定法特异性检测作为游离组蛋白的替代肽的组蛋白肽。
在某些实施方案中,利用高分辨/准确质量(hram)质量分析仪来检测和测量从游离组蛋白或由其衍生的肽形成的前体和/或产物离子,可能是有益的。hram质量分析仪是能够以通常超过15k的分辨力和通常小于5百万分数(ppm)的质量准确度获取质谱图的质量分析仪。hram质量分析仪的实例包括傅里叶变换/离子回旋共振(ft-icr)分析仪、orbitrap轨道静电阱分析仪和某些多反射或长路径飞行时间(tof)分析仪。合并有hram质谱仪的质谱仪器包括可以从thermofisherscientific(bremen,germany)获得的exactive和qexactive产品系列。一般来说,hram质量分析仪能够在质谱图中将靶被分析物与具有紧密相近的m/z的干扰性离子物质区分开,从而促进靶被分析物(例如从游离组蛋白或其替代肽形成的离子)的可信的鉴定和定量。通过这种方式,可以在复杂的生物基质例如血浆中以高选择性检测和测量靶被分析物。hram质量分析仪的使用可以允许忽略或简化样品制备和分离技术,所述技术旨在将所述靶被分析物与样品中存在的可以混淆通过质谱法进行的靶被分析物测量的干扰性组分分离开。在某些应用中,hram分析仪的使用可以允许使用前体离子丰度(例如基于在完整ms谱图中出现的强度)可信地检测和定量靶被分析物,消除了对片段化步骤的需求。
相对定量“rsrm”可以通过下述方法实现:
1.通过将在生物样品中检测到的来自于给定组蛋白肽的srm特征峰面积与至少第二、第三、第四或更多生物样品中相同组蛋白片段肽的同一srm特征峰面积进行比较,确定游离组蛋白存在的增加或减少。
2.通过将在生物样品中检测到的来自于给定组蛋白肽的srm特征峰面积与源自于不同且分开的生物来源的其他样品中从来自于其他蛋白的片段肽产生的srm特征峰面积进行比较,确定游离组蛋白存在的增加或减少,其中所述两种样品的肽片段之间的srm特征峰面积的比较被归一化至例如在每个样品中分析的蛋白质的量。
3.通过将同一生物样品中给定组蛋白肽的srm特征峰面积与源自于不同蛋白质的其他片段肽的srm特征峰面积进行比较,以便将组蛋白的变化水平归一化到在各种不同的细胞条件下不改变其表达水平的其他蛋白质的水平,来确定组蛋白存在的增加或减少。
4.这些测定法可以应用于所述组蛋白的未修饰的片段肽和修饰的片段肽两者,其中所述修饰包括但不限于磷酸化和/或糖基化、乙酰化、甲基化(单、二、三)、瓜氨酸化、遍在蛋白化,并且其中修饰肽的相对水平以与确定未修饰肽的相对量相同的方式来确定。
给定肽的绝对定量可以通过下述方法实现:
1.将个体生物样品中来自于组蛋白的给定片段肽的srm/mrm特征峰面积与掺杂在来自于所述生物样品的蛋白质裂解物中的内部片段肽标准品的srm/mrm特征峰面积进行比较。
所述内部标准品可以是来自于正在被质询的组蛋白的片段肽的标记的合成版本或标记的重组蛋白。这种标准品在消化之前(对于重组蛋白来说强制性的)或之后以已知的量掺入到样品中,并且可以分开地确定生物样品中内部片段肽标准品和本源片段肽两者的srm/mrm特征峰面积,然后将两个峰面积进行比较。这可以应用于未修饰的片段肽和修饰的片段肽,其中所述修饰包括但不限于磷酸化和/或糖基化、乙酰化、甲基化(单、二、三)、瓜氨酸化、遍在蛋白化,并且其中修饰肽的绝对水平可以以与确定未修饰肽的绝对水平相同的方式来确定。
2.肽也可以使用外部校准曲线来定量。正常曲线法使用恒定量的作为内部标准品的重肽和可变量的掺入到样品中的轻的合成肽。需要使用与测试样品的基质相似的代表性基质来构建标准曲线,以解释基质效应。此外,反向曲线法克服了基质中的内源被分析物的问题,其中将恒定量的轻肽掺入到内源被分析物顶上以产生内部标准品,并掺入可变量的重肽以产生一组浓度标准品。将要与正常或反向曲线比较的测试样品掺有与掺入到基质中用于产生校准曲线的内部标准品相同量的标准肽。
正如上面解释的,生物样品中游离组蛋白的量可以通过检测来自于所述生物样品的蛋白质消化物中一种或多种修饰或未修饰的组蛋白片段肽的量,任选地使用层析方法分离所述样品,并对所述制备且任选分离的样品进行选择反应监测(srm)串联质谱法以确定至少一种组蛋白肽的量,来测量。
本发明还涉及一种用于测量样品中游离组蛋白的量的方法,所述方法包括检测来自于所述生物样品的蛋白质消化物中一种或多种修饰或未修饰的组蛋白片段肽的量,任选地使用层析方法分离所述样品,并对所述制备且任选分离的样品进行选择反应监测(srm)串联质谱法以确定至少一种组蛋白肽的量。所述组蛋白片段肽的定量可以是通过rsrm的相对定量或绝对定量。
本发明还提供了一种用于测量样品中的游离组蛋白的量的方法,所述方法包括在蛋白水解消化之前不对所述样品进行预先分离的情况下检测来自于所述生物样品的蛋白质消化物中一种或多种组蛋白片段肽的量,并对分离的肽进行选择反应监测(srm)串联质谱法以确定至少一种组蛋白肽的量。
本发明还涉及一种用于测量样品中的游离组蛋白的量的方法,所述方法包括在蛋白水解消化之前不对所述样品进行预先分离的情况下检测来自于所述生物样品的蛋白质消化物中一种或多种修饰或未修饰的组蛋白片段肽的量,并对分离的肽进行选择反应监测(srm)串联质谱法以确定至少一种组蛋白肽的量。
此外,本发明涉及一种用于测量样品中的游离组蛋白的量的方法,所述方法包括在蛋白水解消化之前不对所述样品进行预先分离的情况下检测来自于所述生物样品的蛋白质消化物中一种或多种未修饰的组蛋白片段肽的量,并对分离的肽进行选择反应监测(srm)串联质谱法以确定至少一种组蛋白肽的量。
此外,本发明涉及一种用于测量样品中的游离组蛋白的量的方法,所述方法包括检测来自于所述生物样品的没有进行蛋白水解消化但在所述样品的预分离之前进行了预处理程序或免疫富集程序的一种或多种未修饰的组蛋白片段肽的量,并对分离的肽进行选择反应监测(srm)串联质谱法以确定至少一种游离组蛋白肽的量。
因此,本发明还涉及一种用于测量尚未进行蛋白水解(例如胰蛋白酶)消化的样品中游离组蛋白的量的方法,所述方法包括通过选择反应监测(srm)串联质谱法检测一种或多种组蛋白片段肽的量以确定至少一种游离组蛋白肽的量,其中所述样品在检测之前已经历预处理程序或免疫富集程序。
下面的说明性和示例性测定法也可用于本发明的情形中,然而,其他测定法也可以同样地使用。将所述样品蛋白水解消化,优选地通过添加蛋白酶(例如胰蛋白酶),这产生含有对组蛋白特异的组蛋白肽(替代肽)的样品。对于替代肽的精确定量来说,以确定的量向样品添加内部标准品。因此,同位素标记的合成肽被添加并代表替代肽的对应物。所述内部标准品也可以在蛋白水解消化之前添加。含有替代肽和相应的内部标准品的消化的样品现在使用适合的lc/hplc方案(hplc柱、梯度、洗脱时间)进行层析分离。当在本文中使用时,所述层析分离在线进行,其中将柱洗脱液直接转移到质谱仪的第一电离装置。或者,可以首先收集不同的洗脱液并随后分析。除了液相层析之外,可以使用用于样品分离的不同技术,例如在前一段中描述的技术。在分离步骤后,将使用质谱仪、优选地使用串联质谱仪来确定所选替代肽和相应片段的质量。所述含有组蛋白肽的样品在质谱仪中被电离,并将得到的离子递送到第一质量过滤器。正如以前描述的,仅仅具有所需质荷比(m/z)的电离肽被选择性地引入到碰撞单元中,在其中所述前体肽由于与碰撞气体的碰撞而经历片段化。所选的肽片段离子被进一步传送到第二质量过滤器。在检测后产生信号,其代表了传送的组蛋白肽片段离子的量。
在本发明的免疫测定法的背景中描述的抗体或其抗原结合片段或衍生物,也可用于在ms分析之前对游离组蛋白进行免疫沉淀/免疫纯化,其中可以使用或不使用蛋白酶消化。
因此,本发明涉及一种测量生物样品中游离组蛋白的存在或量的方法,其中所述方法包括使用特异性针对包含在组蛋白中的表位的抗体或其抗原结合片段或衍生物对游离组蛋白进行免疫纯化,使用层析方法分离所述样品,检测来自于所述生物样品的一种或多种修饰或未修饰的组蛋白片段肽的量,并对制备的样品进行ms分析。
正如上文中概述的,在本发明的基于ms的方法中,可以在ms分析之前对所述样品进行蛋白酶消化,优选为胰蛋白酶消化。然而,在本发明的其他情况下,在ms分析之前不对所述样品进行蛋白酶消化,优选为胰蛋白酶消化。
根据上述解释,本发明的基于ms的方法可以任选地包括一个或多个下述步骤:
(i)对所述样品进行预处理例如添加化学或生物化学物质;
(ii)对所述样品进行还原和/或烷基化反应;
(iii)在ms分析之前和胰蛋白酶消化之后使用层析方法分离所述样品;
(iv)使用免疫亲和装置(例如thermoscientificmsiatm技术)富集所述样品或使用剥离柱剥离不想要的组分;
(v)添加至少一种内部参比标准品,其中所述参比标准品是待检测的肽或蛋白质的同位素标记的版本。
在本发明的基于ms的方法中,所述游离组蛋白可以是组蛋白h2a,并且至少其选自seqidno:24、28、29和30的肽片段、优选地选自seqidno:24和28的肽片段被检测并任选地被定量。
在本发明的基于ms的方法中,所述游离组蛋白也可以是组蛋白h4,并且至少其选自seqidno:2、3、4、5、6和7的肽片段、优选地选自seqidno:3和4的肽片段被检测并任选地被定量。
优选地,在本发明的情形中的肽片段和跃迁被列于表4和5中。
本文中引用的所有参考文献包括科学文献和专利文献,通过参考并入本文。
序列
seqidno:1(人类组蛋白h4的氨基酸序列,uniprotidp62805.2,未包括起始甲硫氨酸)
1sgrgkggkglgkggakrhrkvlrdniqgitkpairrlarrggvkrisgli
51yeetrgvlkvflenvirdavtytehakrktvtamdvvyalkrqgrtlygf
101gg
seqidno:2(seqidno:1的46-102位残基的氨基酸序列)
1isgliyeetrgvlkvflenvirdavtytehakrktvtamdvvyalkrqgr
51tlygfgg
seqidno:3(seqidno:1的46-55位残基的氨基酸序列)
1isgliyeetr
seqidno:4(seqidno:1的60-67位残基的氨基酸序列)
1vflenvir
seqidno:5(seqidno:1的80-91位残基的氨基酸序列,具有乙酰化的k91)
1tvtamdvvyalk
seqidno:6(seqidno:1的24-35位残基的氨基酸序列)
1dniqgitkpair
seqidno:7(seqidno:1的68-77位残基的氨基酸序列)
1davtytehak
seqidno:8(h4-gr-17的氨基酸序列,seqidno:1的2-17位)
1grgkggkglgkggakr
seqidno:9(h4-gh-18的氨基酸序列,seqidno:1的2-18位)
1grgkggkglgkggakrh
seqidno:10(h4-li-9的氨基酸序列,seqidno:1的22-30位)
1lrdniqgit
seqidno:11(h4-lr-15的氨基酸序列,seqidno:1的22-35位)
1lrdniqgitkpair
seqidno:12(h4-ll-17的氨基酸序列,seqidno:1的22-37微)
1lrdniqgitkpairrl
seqidno:13(h4-pr-15的氨基酸序列,seqidno:1的32-45位)
1pairrlarrggvkr
seqidno:14(h4-ps-17的氨基酸序列,seqidno:1的32-47位)
1pairrlarrggvkris
seqidno:15(h4-ee-13的氨基酸序列,seqidno:1的52-63位)
1eetrgvlkvfle
seqidno:16(h4-en-14的氨基酸序列,seqidno:1的52-64位)
1eetrgvlkvflen
seqidno:17(h4-rr-13的氨基酸序列,seqidno:1的67-78位)
1rdavtytehakr
seqidno:18(h4-rk-14的氨基酸序列,seqidno:1的67-79位)
1rdavtytehakrk
seqidno:19(h4-tk-13的氨基酸序列,seqidno:1的80-91位)
1tvtamdvvyalk
seqidno:20(h4-tr-14的氨基酸序列,seqidno:1的80-92位)
1tvtamdvvyalkr
seqidno:21(h4-rg-9的氨基酸序列,seqidno:1的92-99位)
2rqgrtlyg
seqidno:22(h4-rg-12的氨基酸序列,seqidno:1的92-102位)
3rqgrtlygfgg
seqidno:23(1型人类组蛋白h2a的氨基酸序列,uniprotidq96qv6,未包括起始甲硫氨酸)
1sgrgkqggkaraksksrssraglqfpvgrihrllrkgnyaerigagapvy
51laavleyltaeilelagnasrdnkktriiprhlqlairndeelnkllggv
101tiaqggvlpniqavllpkkteshhhkaqsk
seqidno:24(ha-ar-10的氨基酸序列,seqidno:23的21-29位)
1aglqfpvgr
seqidno:25(ha-ah-12的氨基酸序列,seqidno:23的21-31位)
1aglqfpvgrih
seqidno:26(ha-il-23的氨基酸序列,seqidno:23的30-51位)
1ihrllrkgnyaerigagapvyl
seqidno:27(ha-ia-25的氨基酸序列,seqidno:23的30-53位)
1ihrllrkgnyaerigagapvylaa
seqidno:28(seqidno:23的82-88位残基的氨基酸序列)
1hlqlair
seqidno:29(seqidno:23的89-95位残基的氨基酸序列)
1ndeelnk
seqidno:30(seqidno:23的100-118位残基的氨基酸序列)
1vtiaqggvlpniqavllpk
seqidno:31(人类组蛋白h2b的氨基酸序列,uniprotidp62807)
1mpepaksapapkkgskkavtkaqkkdgkkrkrsrkesysvyvykvlkqvh
51pdtgisskamgimnsfvndiferiageasrlahynkrstitsreiqtavr
101lllpgelakhavsegtkavtkytssk
seqidno:32(seqidno:31的94-100位残基的氨基酸序列)
1eiqtavr
seqidno:33(seqidno:31的101-109位残基的氨基酸序列)
1lllpgelak
seqidno:34(人类组蛋白h2b的氨基酸序列,uniprotidq6dn03.3,未包括起始甲硫氨酸)
seqidno:35(seqidno:34的181-193位残基的氨基酸序列)
1lvnfrrahntkhr
seqidno:36(人类组蛋白h3.1的氨基酸序列,uniprotidp68431.2,未包括起始甲硫氨酸)
1artkqtarkstggkaprkqlatkaarksapatggvkkphryrpgtvalre
51irryqkstellirklpfqrlvreiaqdfktdlrfqssavmalqeaceayl
101vglfedtnlcaihakrvtimpkdiqlarrirgera
seqidno:37(seqidno:36的57-63位残基的氨基酸序列)
1stellir
seqidno:38(seqidno:36的117-122位残基的氨基酸序列)
1vtimpk
seqidno:39(seqidno:36的41-49位残基的氨基酸序列)
1yrpgtvalr
seqidno:40(3型人类组蛋白h2a的氨基酸序列,uniprotidq7l7l0.3,未包括起始甲硫氨酸),sigma重组h2asrp0406
1sgrgkqggkarakaksrssraglqfpvgrvhrllrkgnyservgagapvy
51laavleyltaeilelagnaardnkktriiprhlqlairndeelnkllgrv
101tiaqggvlpniqavllpkkteshhkakgk
seqidno:41(人类组蛋白h1的氨基酸序列,uniprotidp07305,未包括起始甲硫氨酸)
实施例
下面的实施例和图被用于本发明的更详细解释,但是不将本发明限制到所述实施例和图。
实施例1:抗体的产生
a.肽
与组蛋白h4的氨基酸序列相关的肽由thermofisherscientificgmbh,ulm,germany、newenglandpeptideinc,gardner,ma,usa或jptpeptidetechnologiesgmbh化学合成并纯化(>90%)。免疫接种肽使用磺基-mbs(间马来酰亚胺基苯甲酰基-n-羟基琥珀酰亚胺酯)偶联到牛血清白蛋白(bsa,sigmaaldrich)或通过附加的n-端半胱氨酸偶联到钥孔戚血蓝蛋白(klh,thermofisherscientific)。用于抗体的亲和纯化的肽与用于免疫接种的肽相比含有一个或两个附加的c-端氨基酸和用于固定化到sulfolink偶联树脂的附加的n-端半胱氨酸。
b.多克隆抗体的生成
按照标准程序(参见ep1488209a1、ep1738178a1)产生针对h4-li-9(组蛋白h4的22-30位氨基酸,seqidno:10)、h4-ee-13(组蛋白h4的52-63位氨基酸,seqidno:15)、h4-rr-13(组蛋白h4的67-78位氨基酸,seqidno:17)和h4-rg-9(组蛋白h4的92-99位氨基酸,seqidno:21)的绵羊多克隆抗体。简单来说,通过额外的n-端半胱氨酸,使用mbs将肽偶联到载体蛋白klh。按照下述流程将偶联物用于免疫接种绵羊:将绵羊首先用100μg偶联物免疫接种(质量是指所述偶联物的肽组成部分),随后以4周的间隔用50μg加强。在初次免疫接种后4个月,从所述绵羊获得300ml抗血清。
按照标准程序产生针对的ha-ar-10(1型组蛋白h2a的21-29位氨基酸,seqidno:24)和ha-il-23(1型组蛋白h2a的30-51位氨基酸,seqidno:26)的兔多克隆抗体。简单来说,通过额外的n-端半胱氨酸,使用mbs将肽偶联到klh。按照下述流程将偶联物用于免疫接种:将兔首先用800μg偶联物免疫接种(质量是指所述偶联物的肽组成部分),并在第4周开始随后以一周的间隔用500μg加强3次。在初次免疫接种后2个月,从所述兔获得各20ml抗血清。
抗原特异性抗体如下所述从相应的抗血清纯化:将5mg纯化肽(参见下面的表1)偶联到5mlsulfolink凝胶(pierce,rockford,il,usa)。将50ml抗血清逐批与所述凝胶在室温下温育4小时。将悬液转移到柱(空的nap25柱,gehealthcarelifesciences)中。在将穿流液舍弃并将柱用100ml清洗缓冲液(100mmkpi,0.1%tween-20,ph6.8)清洗后,用ph2.7的50mm柠檬酸洗脱特异性结合的抗体。将洗脱液针对50mmnapi,100mmnacl,ph8.0透析。
表1.用于组蛋白h4和组蛋白h2a多克隆抗体产生的肽
c.单克隆抗体的产生
通过标准程序(lane,r.d.jimmunolmethods,1985,81(2):223-228)产生针对h4-gr-17(组蛋白h4的2-17位氨基酸,seqidno:8)、h4-li-9(组蛋白h4的22-30位氨基酸,seqidno:10)、h4-ee-13(组蛋白h4的52-63位氨基酸,seqidno:15)、h4-rr-13(组蛋白h4的67-78位氨基酸,seqidno:17)、h4-tk-13(组蛋白h4的80-91位氨基酸,seqidno:19)、h4-rg-12(组蛋白h4的92-102位氨基酸,seqidno:22)和全长组蛋白h3(sigmaaldrichsrp0177,seqidno:36)的单克隆抗体。在本研究中,评估淋巴细胞-骨髓瘤细胞混合物向促融剂的暴露时长对总的杂交瘤集落和分泌单克隆抗体的集落的得率的影响。将sp2/0和fox-ny骨髓瘤细胞与用绵羊红细胞免疫的鼠脾淋巴细胞融合不同的时长。最适的融合时长由在37℃下在45s的时长内向细胞混合物添加促融剂(5.0mlkodak1450peg,0.5ml二甲亚砜和4.5ml磷酸盐缓冲盐水,ph7.0)构成。所述融合过程通过将所述混合物在50mlrpmi-1640中逐渐稀释来停止。10min后,将细胞离心,重悬浮在含有饲养巨噬细胞的选择培养基中并培养。与常用的更长的融合技术相比,这种程序导致当使用sp2/0细胞时产生的杂交瘤数目约5倍的提高,并且当使用fox-ny细胞作为融合配偶体时产生的杂交瘤数目30倍的提高。在两种情况下,事实上所有的孔都含有分泌单克隆抗体的杂交瘤集落。这种高效率融合技术可以最有利地用于产生针对弱免疫原的单克隆抗体或减少用较强免疫原免疫接种所需的时间。
简单来说,在这里,使用磺基-mbs(间马来酰亚胺基苯甲酰基-n-羟基琥珀酰亚胺酯)将肽偶联到bsa。使用这些偶联物和组蛋白h3对balb/c小鼠进行免疫接种和加强,并将脾细胞与sp2/0骨髓瘤细胞融合,以产生杂交瘤细胞系。筛选细胞系分泌结合于包被在聚苯乙烯固相上的筛选肽(参见表2)和重组全长组蛋白的抗体的能力。产生了分泌单克隆抗体ak654/f3和654/h10(针对h4-gr-17)、ak602/f11和602/g3(针对h4-li-9)以及ak660/d2、ak660/g9、ak660/f6、ak660/e9、ak660/g3和ak660/f7(针对组蛋白h3)的细胞系。
此外,针对组蛋白h4的50-102位残基内的区域的小鼠单克隆抗体购自abcam(#ab31830)。
表2.用于组蛋白h4和组蛋白h3单克隆抗体产生的肽
d.抗体的标记
抗体按照标准程序(ep1488209a1、ep1738178a1)进行标记:将相应的纯化的抗体的浓度调整到1g/l,并将所述抗体通过与化学发光标记物macn-吖啶-nhs-酯(1g/l;inventgmbh,hennigsdorf,germany)以1:5的摩尔比在室温下温育20min来标记。通过添加1/10体积的50mm甘氨酸在室温下10min,将反应停止。在nap-5柱(gehealthcarelifesciences)和
实施例2:游离组蛋白免疫测定法的开发
a.抗体的包被
抗体按照标准程序(ep1488209a1、ep1738178a1)进行包被:将聚苯乙烯管(greiner)用纯化的抗体在22℃下包被(每管2μg抗体,在300μl10mmtris,100mmnacl,ph7.8中)过夜。然后将管用含有30g/lkarionfp(merck)、5g/l无蛋白酶bsa(sigmaaldrich)的10mmnapi(ph6.5)阻断并冷冻干燥。
b.使用多克隆和单克隆和可商购的单克隆抗体进行的参比组蛋白h4测定法
组蛋白h4:使用上面描述的多克隆和单克隆组分并使用重组人类全长组蛋白h4(sigmaaldrich#srp0178,seqidno:1)设置了几种夹心组蛋白免疫测定法。在血清和edta血浆样品中,使用包被在管中的抗h4-li-9抗体(变体v1)和抗h4-rr-13抗体(变体v2)和abcam的针对组蛋白h4的50-102位氨基酸内的残基的抗组蛋白h4ab31830的组合,观察到最佳信号。在来自于健康志愿者的样品中没有看到信号(信号低于功能测定法灵敏度),然而,来自于降钙素原水平提高、表明严重细菌感染或脓毒症的患者的样品,都高于功能测定法灵敏度(fas)(图1)。两种测定法组合相关联,但是当使用组合h4-li-9时测量到更低的水平,可能是由于被分析物(seqidno:1)在h4-li-9区域(seqidno:10)与h4-rr-13区域(seqidno:17)之间的蛋白水解,引起较长的组蛋白h4片段与较小的c-端片段相比浓度较低(图2和3)。
将50μl标准品(重组人类全长组蛋白h4,来自于sigmaaldrich#srp0178,seqidno:1)或来自于患者的样品和200μl含有macn标记的抗体的缓冲液在包被的管中混合(300mmkpi,ph7.0,50mmnacl,10mmedta,0.09%nan3,0.1%bsa,0.1%非特异性牛igg,0.1%非特异性igg,0.01%非特异性小鼠igg),并且每200μl含有0.5x106个相对光单位(rlu)的macn标记的抗体。将所述管在室温下温育18-24小时。然后,将管用1mlb.r.a.h.m.s50x通用清洗溶液(tris400mm,nacl3m,tween201%,硅酮消泡剂0.001%)(thermofisherscientific,b.r.a.h.m.sgmbh,hennigsdorf,germany)清洗4次,并使用lb925t照度计(berthold)对每个管的结合的化学发光进行1s的测量。使用软件multicalc(样条拟合)计算样品的浓度。
c.剂量响应曲线
在上述两种免疫测定法中,通过使用重组组蛋白h4(sigmaaldrich#srp0178,seqidno:1)作为标准材料来产生剂量响应曲线。典型的剂量响应曲线示出在图4中。
实施例3:srm与免疫测定法之间的相关性
使用在下文中描述的本发明的srm测定法,评估了在本发明的免疫测定法中试验的同样的样品。
图5示出了本发明的组蛋白h4lia和srm测定法相关性非常好,皮尔森相关系数为0.95,表明两种测定法测量同一被分析物。出于与当组蛋白复合成八聚体时特异性针对位于组蛋白h4的中央部分中的残基的抗体不能结合相同的原因,胰蛋白酶不能到达该区域中的潜在切割位点。因此,只有游离组蛋白可以在所述中央部分处被切开,并且源自于该区域的可检测的肽例如seqidno:3和4只能从游离组蛋白产生。
实施例4:本发明的夹心免疫测定法和srm测定法与来自于roche的针对核小体的可商购elisa之间的比较
在来自于roche的可商购elisa系统中试验了用于产生图4中所示的标准曲线的重组全长组蛋白h4:尽管roche细胞死亡检测elisa(#11544675001)被设计用于特异性确定细胞裂解物的细胞质级分中的单核小体和寡核小体这一事实,但我们试验了它在血清和edta血浆样品中的性能,这是因为组蛋白h2a、h2b、h3和h4形成核小体的八聚体核心。所述测定法含有用针对哺乳动物组蛋白h2a、h2b、h3和h4的抗体包被的微量滴定板和针对dna的检测抗体。由于所述试剂盒不包括标准材料,因此我们使用本源核小体(bpsbioscience#52015)来估算基质浓度。使用与图1中所示用于组蛋白h4浓度试验的相同的样品,在降钙素原水平提高的患者中核小体水平升高或不可检测(图6)。因此,可以得出结论,在核小体与游离组蛋白h4水平之间没有相关性(图7)。此外,我们试验了掺入到零血清中的可商购的被分析物:重组人类组蛋白h2a(sigmaaldrich#srp0406,seqidno:23),重组人类组蛋白h3(sigmaaldrich#srp0177,seqidno:36)和组蛋白h4(sigmaaldrich#srp0178,seqidno:1),以及本源人类核小体(bpsbioscience#52015)。表3列出了可以通过brahms组蛋白h4lia或roche细胞死亡检测elisa来检测的被分析物。所述组蛋白h4lia特异性针对人类组蛋白h4,不检测组蛋白h2a和h3,并且重要的是不检测本源核小体。这表明被在本发明中描述的免疫测定法中使用的抗体识别的组蛋白h4的表位,当组蛋白h4作为核小体的八聚体核心的一部分时不可接近。然而,当组蛋白h4在溶液中游离时,组蛋白h4lia能够检测基质包括血清和edta血浆中的组蛋白h4水平。相反,roche细胞死亡检测elisa检测核小体,但不检测任一种组蛋白。
表3:通过brahms组蛋白h4免疫测定法和roche细胞死亡试剂盒进行的被分析物检测的比较。
实施例5:基于质谱法的选择反应监测(srm)
srm是一种基于ms的技术,用于可以在高度复杂背景例如血液来源的血清或血浆中检测的具有确定片段化性质的先前选择的蛋白水解肽的定向检测和定量。
通过lc-ms/ms技术(tsqvantage质谱仪(ms);thermofisherscientific)检测被称为h4和h2a的源自于组蛋白h4和组蛋白h2a的特定肽。发现的结果通过srm分析得以证实,显示h4来源的肽随着演变的血流感染过程而变。发现对于每种肽来说,鉴定到的肽序列及其片段化离子、即所谓的跃迁,是用于监测血液样品中h4和h2a蛋白水平的有用替代物。
开发了下文中描述的定量srm测定法来测量通过血浆或血清蛋白的胰蛋白酶消化产生的未修饰的组蛋白来源的肽的相对定量水平。
对从sigma购买的重组蛋白进行了优化。对所有可能的胰蛋白酶消化的肽进行筛选,并选择在信噪比方面最好的肽(参见表4和5)。对至少4个最佳跃迁,设立最适保留时间、停留时间和碰撞能。
肽的实例vflenvir(seqidno:4)被示出在图9中。
实施例6:用于组蛋白的srm/mrm测定法的设立
在三级串联四极杆质谱仪上用于单个片段肽的srm/mrm测定法
srm是一种基于ms的技术,用于可以在高度复杂背景例如血液来源的血清或血浆中检测的具有确定片段化性质的先前选择的蛋白水解肽的定向检测和定量。
开发了下文中描述的定量srm测定法来测量通过血浆或血清蛋白的胰蛋白酶消化产生的未修饰的组蛋白来源的肽的定量水平。
通过lc-ms/ms技术(tsqvantage和tsqquantiva质谱仪(ms);thermofisherscientific)检测被称为h4和h2a的源自于组蛋白h4和组蛋白h2a的特定肽。发现对于每种肽来说,鉴定到的肽序列及其片段化离子、即所谓的跃迁,是用于监测血液样品中h4和h2a蛋白水平的有用替代物。
对从sigma购买的重组蛋白进行了优化。对所有可能的胰蛋白酶消化的肽进行筛选,并选择在信噪比方面最好的肽(参见表4和5)。对至少4个最佳跃迁,设立最适保留时间、停留时间和碰撞能。
可以对临床样品进行相对定量和/或绝对定量,并使用正常曲线或反向曲线评估测定法的性能。
实施例7:ms定量/肽和跃迁的选择的演示
a.样品制备
将血浆样品(12μl)在冰上融化,并与50μl的8m尿素/2.5%正丙醇/200mmtris-hcl/10mmdttph8.5混合。将样品在37℃温育1小时。然后将样品用5μl溶解在1m碳酸氢铵中的500mm碘乙酸烷基化,并在室温下在暗处温育1小时。然后将残留的烷基化试剂与3.3μl500mmdtt反应。然后将样品用260μlph8的50mmtris-hcl、5mmcacl2缓冲液稀释。然后向每个样品添加150μl胰蛋白酶(pierce,20μg,在25mm乙酸中),提供1:50的胰蛋白酶:蛋白质比例。允许样品在37℃消化18小时。对于发现运行来说,在质谱分析之前将300ng样品载样到50mm×1mm1.9μmhypersilgold柱(thermofisherscientific)上。
在vantage三级四极杆质谱仪、surveyorms泵、ctcpal自动进样器和装备有高流速金属针的ionmax源(thermofisherscientific)上,或者在与hplcultimate3000偶联的三级四极杆质谱仪tsqquantiva(thermofisherscientific)上,开发srm测定法。反相分离在从5%至40%b的20min线性梯度中进行,总运行时间为40min(溶剂a:水,0.2%fa(甲酸);溶剂b:acn(乙腈),0.2%fa)。在线性梯度期间的流速被设定到240μl/min。对于曲线上的所有样品和点来说,总进样体积为160μl。accucore2.6μmaq150x2.1mm柱(thermofisherscientific)在50℃的温度下运行。
将5μl每种临床血浆样品添加到20μl8m尿素/2.5%正丙醇/300mmtris-hcl/10mmdttph8.5,并在37℃温育1小时。向每个样品孔添加在1m碳酸氢铵中制备的500mm碘乙酸,并在室温下在暗处温育1小时。向每个孔添加113μl50mmtris-hcl/5mmcacl2ph8.0。将胰蛋白酶(pierce,thermofisherscientific)用150μl25mm乙酸重新水合,以1:10的比例(总蛋白含量:蛋白酶)添加,并在37℃下温育20小时。最后通过添加2μl甲酸来淬灭所述消化。然后在进样之前添加胰高血糖素(1ng/μl)和标准的重肽。
同位素标记的肽c-端赖氨酸或精氨酸由thermofisherscientificgmbh,ulm,germany或newenglandpeptideinc,gardner,ma,usa化学合成并纯化(>95%肽纯度,>99%同位素纯度)。
将从发现ms实验获得的保留时间信息输入到pinpoint(thermofisherscientific)中,以建立初步安排的srm方法用于优化。为每个跃迁自动试验各个仪器参数例如碰撞能、镜筒透镜、停留时间和预测的保留时间。在多次迭代后,最终确定肽和跃迁的优化的(即强度信号最高并且与其他跃迁重叠最少的)名单,并选择每个蛋白至少两个蛋白水解肽和每个肽至少四个片段跃迁。
表4和5列出了为人类h4和h2a蛋白分析的所有肽。为组蛋白h4筛选的总共6个肽,并且为组蛋白h2a筛选了总共6个肽。
对于组蛋白h4来说,对5个肽进行了详细的跃迁分析。将符合seqidno:3和4的肽作为重标记的肽进行分析,并且为每个肽监测4至5个跃迁。
对于组蛋白h2a来说,对4个肽进行了详细的跃迁分析。将符合seqidno:24和28的肽作为重标记的肽进行分析,并且为每个肽监测4至5个跃迁。
通过在色谱分离中共同洗脱轻和重标记的跃迁来鉴定肽。将pinpoint软件(thermofisherscientific)或skyline软件(开源)用于时间配准、跃迁的相对定量和定向蛋白质定量。
表4.为h4监测的示例性肽和跃迁。
表5.为h2a监测的示例性肽和跃迁。
b.ms分析
进行srm/mrm分析,使得作为来自于srm/mrm质谱分析的独特的srm/mrm特征峰面积的函数的被检测的组蛋白片段肽的量,指示了特定样品中蛋白质的相对和绝对量两者。
实施例8:用于评估灵敏度的校准曲线的产生
将恒定量的轻肽掺入到内源被分析物顶上以产生内部标准品,并掺入可变量的重肽以产生一组浓度标准品。由于用于产生曲线的变化的重肽信号对于内源被分析物的未知量没有贡献,因此可以确定定量极限(loq)值,这是指测量值在定量上变得有意义的点。在该loq处被分析物的响应是可识别的、离散的且可重复的,精确度为20%,准确度为80-120%。
反向校准曲线使用血浆样品合并物作为背景基质来产生。校准曲线上的每个点(以及被分析的每个样品)包含100fmol的重标记的肽。柱上背景基质的量,对于校准曲线上的每个点以及在所有被分析的样品中是20μg。标准重肽(c-端赖氨酸或精氨酸同位素标记的肽,由thermofisherscientificgmbh,ulm,germany或newenglandpeptideinc,gardner,ma,usa化学合成并纯化,>95%肽纯度,>99%同位素纯度)在消化后掺入。此外,将所有样品溶解在1μg/ml胰高血糖素水溶液/0.2%fa中,以最小化与塑料表面的结合。
图10示出了来自于组蛋白h4的肽vflenvir(seqidno:4)的校准曲线。掺入恒定量的从重组h4消化获得的轻肽和可变量的相应的重肽,以产生一组浓度标准品。
实施例9:在人类数据集上rsrm的相对定量
进行srm/mrm分析,使得作为来自于srm/mrm质谱分析的独特的srm/mrm特征峰面积的函数的被检测的组蛋白片段肽的量,指示了特定蛋白质裂解物中蛋白质的相对和绝对量两者。
相对定量rsrm可以通过下述方法实现:
1.通过将在生物样品中检测到的来自于给定组蛋白肽的srm特征峰面积与至少第二、第三、第四或更多生物样品中相同组蛋白片段肽的同一srm特征峰面积进行比较,确定组蛋白存在的增加或减少。
2.通过将在生物样品中检测到的来自于给定组蛋白肽的srm特征峰面积与源自于不同且分开的生物来源的其他样品中从来自于其他蛋白的片段肽产生的srm特征峰面积进行比较,确定组蛋白存在的增加或减少,其中所述肽片段的两种样品之间的srm特征峰面积的比较被归一化至例如在每个样品中分析的蛋白质的量。
3.通过将同一生物样品中给定组蛋白肽的srm特征峰面积与源自于不同蛋白质的其他片段肽的srm特征峰面积进行比较,以便将组蛋白的变化水平归一化到在各种不同的细胞条件下不改变其表达水平的其他蛋白质的水平,来确定组蛋白存在的增加或减少。
4.这些测定法可以应用于所述组蛋白的未修饰的片段肽和修饰的片段肽两者,其中所述修饰包括但不限于磷酸化和/或糖基化、乙酰化、甲基化(单、二、三)、瓜氨酸化、遍在蛋白化和苏素化,并且其中修饰肽的相对水平以与确定未修饰肽的相对量相同的方式来确定。
通过将在生物样品中检测到的来自于给定组蛋白肽的srm特征峰面积与至少第二、第三、第四或更多生物样品中相同组蛋白片段肽的同一srm特征峰面积进行比较,确定组蛋白存在的增加或减少来实现相对定量rsrm;参见图9。
给定肽的绝对定量可以通过下述方法来实现:
将个体生物样品中来自于组蛋白的给定片段肽的srm/mrm特征峰面积与掺杂在来自于所述生物样品的蛋白质裂解物中的内部片段肽标准品的srm/mrm特征峰面积进行比较。
所述内部标准品可以是来自于正在质询的组蛋白的片段肽的标记的合成版本或标记的重组蛋白。这种标准品在消化之前(对于重组蛋白来说强制性的)或之后以已知的量掺入到样品中,并且可以分开地确定生物样品中内部片段肽标准品和本源片段肽两者的srm/mrm特征峰面积,然后将两个峰面积进行比较。
这可以应用于未修饰的片段肽和修饰的片段肽,其中所述修饰包括但不限于磷酸化和/或糖基化、乙酰化、甲基化(单、二、三)、瓜氨酸化、遍在蛋白化,并且其中修饰肽的绝对水平可以以与确定未修饰肽的绝对水平相同的方式来确定。
图8示出了在来自于20位健康志愿者的血清样品和来自于患有脓毒症的患者的29个样品中,通过肽vflenvir(seqidno:4)的srm测量确定的组蛋白h4浓度的结果。
本发明的某些条目
下文中列出了本发明的某些条目:
1.一种用于检测受试者的生物样品中游离组蛋白的方法,其中检测所述组蛋白的表位或肽片段。
2.一种用于疾病或医学病症的诊断、预后、风险评估、危险分层和/或疗法控制的方法,
所述方法包括检测受试者的生物样品中的游离组蛋白或其肽片段,
其中所述游离组蛋白或其片段的存在指示所述疾病或医学病症。
3.条目1或2任一项的方法,其中当所述组蛋白组装在核小体中时,待检测的表位不可接近。
4.条目1至3任一项的方法,其中所述表位不具有翻译后修饰。
5.符合前述条目任一项的方法,其中所述疾病或医学病症选自涉及炎性响应的疾病和医学病症,所述炎性响应与感染性和非感染性病因例如非感染性sirs、细菌、病毒、真菌脓毒症、重症脓毒症、脓毒性休克、腹膜炎、与创伤相关的损伤包括出血和/或组织损伤、烧伤、急性胰腺炎、缺血再灌注损伤、心肌梗塞、心源性休克、中风、急性中毒、血栓栓塞以及介入治疗例如心肺转流术和肿瘤疗法相关。
6.符合前述条目任一项的方法,其中所述生物样品是体液或组织样品。
7.条目6的方法,其中所述体液选自血液、血清、血浆、脑脊液、尿液和唾液,优选为血浆或血清。
8.符合前述条目任一项的方法,其中所述游离组蛋白或其肽片段源自于典型组蛋白或其同工型。
9.符合条目8的方法,其中所述游离组蛋白或其肽片段选自h1、h2a、h2b、h3、h4及其同工型,优选为组蛋白h2a或组蛋白h4。
10.条目9的方法,其中检测跨越符合seqidno:23的游离组蛋白h2a的20至118位氨基酸残基的序列中的表位或肽片段。
11.符合条目9的方法,其中检测跨越符合seqidno:1的游离组蛋白h4的22至102位氨基酸残基的序列中的表位或肽片段。
12.符合前述条目任一项的方法,其中所述方法是免疫测定法,其包括下述步骤:
a)将所述样品与下述物质相接触:
(i)特异性针对所述游离组蛋白的第一表位的第一抗体或其抗原结合片段或衍生物,以及
(ii)特异性针对所述游离组蛋白的第二表位的第二抗体或其抗原结合片段或衍生物,
b)检测所述两种抗体或其抗原结合片段或衍生物与所述游离组蛋白的结合。
13.符合条目12的方法,其中所述第一表位和/或第二表位是存在于跨越seqidno:23的21至53位氨基酸残基的序列中的组蛋白h2a的表位。
14.符合条目13的方法,其中所述第一表位存在于跨越seqidno:23的21至29位氨基酸残基的序列中,和/或所述第二表位存在于跨越seqidno:23的30至53位氨基酸残基的序列中。
15.符合条目12的方法,其中所述第一表位和/或第二表位是存在于跨越seqidno:1的22至102位氨基酸残基的序列中的组蛋白h4的表位。
16.符合条目12的方法,其中所述第一表位存在于跨越seqidno:1的22至30位氨基酸残基或seqidno:1的67至78位残基或seqidno:1的92至102位残基的序列中,和/或所述第二表位存在于跨越seqidno:1的46至102位氨基酸残基的序列中。
17.符合条目12至16任一项的方法,其中所述方法选自线性免疫测定法(lia)、放射免疫测定法(ria)、化学发光和荧光免疫测定法、酶免疫测定法(eia)、酶联免疫测定法(elisa)、基于发光的珠子阵列、基于磁珠的阵列、蛋白质微阵列测定法、快速测试格式和稀土穴状物测定法。
18.符合条目17的方法,其中所述测定法在均相或非均相中进行。
19.符合条目18的方法,其中所述抗体之一被标记,并且另一个抗体被结合到固相或能够被选择性地结合到固相。
20.符合条目19的方法,其中所述第一抗体和第二抗体分散存在于液体反应混合物中,其中作为基于荧光或化学发光消光或扩增的标记系统的一部分的第一标记组分被结合到所述第一抗体,并且所述标记系统的第二标记组分被结合到所述第二抗体,使得在两种抗体结合到待检测的游离组蛋白或其片段之后,产生可测量的信号,其允许检测在测量溶液中得到的夹心复合物。
21.符合条目20的方法,其中所述标记系统包含稀土穴状物或螯合物与荧光或化学发光染料、特别是花青类型的染料的组合。
22.符合条目1至11任一项的方法,其中所述游离组蛋白或其肽片段通过质谱法(ms)检测。
23.符合条目12的方法,其中所述ms分析方法是反应监测(srm)、多反应监测(mrm)或平行反应监测(prm)。
24.符合条目22或23的方法,所述方法包括下述步骤:
a)对所述样品进行胰蛋白酶消化;以及
b)在所述ms分析之前和胰蛋白酶消化之后,使用层析方法分离所述样品。
25.符合条目22至24任一项的方法,其包括使用免疫亲和装置富集所述样品或使用剥离柱剥离不想要的组分的步骤。
26.符合条目22至25任一项的方法,其包括添加至少一种内部参比标准品的步骤,其中所述参比标准品是待检测的肽或蛋白质的同位素标记的版本。
27.符合条目22至26的方法,其中所述方法不包括所述样品的预处理步骤和/或蛋白水解消化。
28.符合条目22至27任一项的方法,其中所述游离组蛋白是组蛋白h2a,并且至少对其选自seqidno:24、28、29和30的肽片段进行检测和定量。
29.符合条目22至27任一项的方法,其中所述游离组蛋白是组蛋白h4,并且至少对其选自seqidno:2、3、4、5、6和7的肽片段进行检测和定量。
30.一种抗体或其抗原结合片段或衍生物,其特异性针对包含在跨越符合seqidno:23的20至55位或70至118位氨基酸残基的序列中的组蛋白h2a的表位。
31.一种抗体或其抗原结合片段或衍生物,其特异性针对存在于符合seqidno:2的、跨越seqidno:1的46至102位氨基酸残基的序列中的组蛋白h4的表位。
32.一种宿主细胞,其表达符合条目30或31任一项的抗体或其抗原结合片段或衍生物。
33.一种试剂盒,其包含符合条目30或31任一项的抗体或其抗原结合片段或衍生物。
34.符合条目30或31任一项的抗体或符合条目33的试剂盒的用途,其用于疾病或医学病症的诊断、预后、风险评估和/或疗法控制的方法中,所述疾病或医学病症选自涉及炎性响应的疾病和医学病症,所述炎性响应与感染性和非感染性病因例如非感染性sirs、细菌、病毒、真菌脓毒症、重症脓毒症、脓毒性休克、腹膜炎、与创伤相关的损伤包括出血和/或组织损伤、烧伤、急性胰腺炎、缺血再灌注损伤、心肌梗塞、心源性休克、中风、急性中毒、血栓栓塞以及介入治疗例如心肺转流术和肿瘤疗法相关。
序列表
<110>b.r.a.h.m.s有限公司
<120>作为生物标志物的游离组蛋白
<130>x3493pctbln
<150>ep15155599.2
<151>2015-02-18
<150>us62/114,300
<151>2015-02-10
<160>41
<170>bissap1.3
<210>1
<211>102
<212>prt
<213>homosapiens
<220>
<223>aminoacidsequenceofhumanhistoneh4,uniprotidp62805.2,
initialmethioninenotincluded
<400>1
serglyargglylysglyglylysglyleuglylysglyglyalalys
151015
arghisarglysvalleuargaspasnileglnglyilethrlyspro
202530
alaileargargleualaargargglyglyvallysargilesergly
354045
leuiletyrglugluthrargglyvalleulysvalpheleugluasn
505560
valileargaspalavalthrtyrthrgluhisalalysarglysthr
65707580
valthralametaspvalvaltyralaleulysargglnglyargthr
859095
leutyrglypheglygly
100
<210>2
<211>57
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceof46-102ofseqidno:1
<400>2
ileserglyleuiletyrglugluthrargglyvalleulysvalphe
151015
leugluasnvalileargaspalavalthrtyrthrgluhisalalys
202530
arglysthrvalthralametaspvalvaltyralaleulysarggln
354045
glyargthrleutyrglypheglygly
5055
<210>3
<211>10
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence46-55ofseqidno:1
<400>3
ileserglyleuiletyrglugluthrarg
1510
<210>4
<211>8
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence60-67ofseqidno:1
<400>4
valpheleugluasnvalilearg
15
<210>5
<211>12
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence80-91withacetylatedk90ofseqidno:1
<220>
<221>mod_res
<222>12
<223>acetylation
<400>5
thrvalthralametaspvalvaltyralaleulys
1510
<210>6
<211>12
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence24-35ofseqidno:1
<400>6
aspasnileglnglyilethrlysproalailearg
1510
<210>7
<211>10
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence68-77ofseqidno:1
<400>7
aspalavalthrtyrthrgluhisalalys
1510
<210>8
<211>16
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-gr-17,position2-17ofseqidno:1
<400>8
glyargglylysglyglylysglyleuglylysglyglyalalysarg
151015
<210>9
<211>17
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-gh-18,position2-18ofseqidno:1
<400>9
glyargglylysglyglylysglyleuglylysglyglyalalysarg
151015
his
<210>10
<211>9
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-li-9,position22-30ofseqidno:1
<400>10
leuargaspasnileglnglyilethr
15
<210>11
<211>14
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-lr-15,position22-35ofseqidno:1
<400>11
leuargaspasnileglnglyilethrlysproalailearg
1510
<210>12
<211>16
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-ll-17,position22-37ofseqidno:1
<400>12
leuargaspasnileglnglyilethrlysproalaileargargleu
151015
<210>13
<211>14
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-pr-15,position32-45ofseqidno:1
<400>13
proalaileargargleualaargargglyglyvallysarg
1510
<210>14
<211>16
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-ps-17,position32-47ofseqidno:1
<400>14
proalaileargargleualaargargglyglyvallysargileser
151015
<210>15
<211>12
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-ee-13,position52-63ofseqidno:1
<400>15
glugluthrargglyvalleulysvalpheleuglu
1510
<210>16
<211>13
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-en-14,position52-64ofseqidno:1
<400>16
glugluthrargglyvalleulysvalpheleugluasn
1510
<210>17
<211>12
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-rr-13,position67-78ofseqidno:1
<400>17
argaspalavalthrtyrthrgluhisalalysarg
1510
<210>18
<211>13
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-rk-14,position67-79ofseqidno:1
<400>18
argaspalavalthrtyrthrgluhisalalysarglys
1510
<210>19
<211>12
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-tk-13,position80-91ofseqidno:1
<400>19
thrvalthralametaspvalvaltyralaleulys
1510
<210>20
<211>13
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-tr-14,position80-92ofseqidno:1
<400>20
thrvalthralametaspvalvaltyralaleulysarg
1510
<210>21
<211>8
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-rg-9,position92-99ofseqidno:1
<400>21
argglnglyargthrleutyrgly
15
<210>22
<211>11
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofh4-rg-12,position92-102ofseqidno:1
<400>22
argglnglyargthrleutyrglypheglygly
1510
<210>23
<211>130
<212>prt
<213>homosapiens
<220>
<223>aminoacidsequenceofhumanhistoneh2atype1,uniprotid
q96qv6,initialmethioninenotincluded
<400>23
serglyargglylysglnglyglylysalaargalalysserlysser
151015
argserserargalaglyleuglnpheprovalglyargilehisarg
202530
leuleuarglysglyasntyralagluargileglyalaglyalapro
354045
valtyrleualaalavalleuglutyrleuthralagluileleuglu
505560
leualaglyasnalaserargaspasnlyslysthrargileilepro
65707580
arghisleuglnleualaileargasnaspglugluleuasnlysleu
859095
leuglyglyvalthrilealaglnglyglyvalleuproasnilegln
100105110
alavalleuleuprolyslysthrgluserhishishislysalagln
115120125
serlys
130
<210>24
<211>9
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofha-ar-10,position21-29ofseqidno:23
<400>24
alaglyleuglnpheprovalglyarg
15
<210>25
<211>11
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofha-ah-12,position21-31ofseqidno:23
<400>25
alaglyleuglnpheprovalglyargilehis
1510
<210>26
<211>22
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofha-il-23,position30-51ofseqidno:23
<400>26
ilehisargleuleuarglysglyasntyralagluargileglyala
151015
glyalaprovaltyrleu
20
<210>27
<211>24
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequenceofha-ia-25,position30-53ofseqidno:23
<400>27
ilehisargleuleuarglysglyasntyralagluargileglyala
151015
glyalaprovaltyrleualaala
20
<210>28
<211>7
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence82-88ofseqidno:23
<400>28
hisleuglnleualailearg
15
<210>29
<211>7
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence89-95ofseqidno:23
<400>29
asnaspglugluleuasnlys
15
<210>30
<211>19
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence100-118ofseqidno:23
<400>30
valthrilealaglnglyglyvalleuproasnileglnalavalleu
151015
leuprolys
<210>31
<211>126
<212>prt
<213>homosapiens
<220>
<223>acidsequenceofhumanhistoneh2b,uniprotidp62807
<400>31
metprogluproalalysseralaproalaprolyslysglyserlys
151015
lysalavalthrlysalaglnlyslysaspglylyslysarglysarg
202530
serarglysglusertyrservaltyrvaltyrlysvalleulysgln
354045
valhisproaspthrglyileserserlysalametglyilemetasn
505560
serphevalasnaspilephegluargilealaglyglualaserarg
65707580
leualahistyrasnlysargserthrilethrserarggluilegln
859095
thralavalargleuleuleuproglygluleualalyshisalaval
100105110
sergluglythrlysalavalthrlystyrthrserserlys
115120125
<210>32
<211>7
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence94-100ofseqidno:31
<400>32
gluileglnthralavalarg
15
<210>33
<211>9
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence101-109ofseqidno:31
<400>33
leuleuleuproglygluleualalys
15
<210>34
<211>193
<212>prt
<213>homosapiens
<220>
<223>aminoacidsequenceofhumanhistoneh2b,uniprotidq6dn03.3,
initialmethioninenotincluded
<400>34
metprogluproalalysphealaproalaprolyslysglyserlys
151015
lysalavalthrlysalaglnlyslysaspglylyslysarglysarg
202530
serarglysglusertyrseriletyrvaltyrlysvalleulysarg
354045
valhisproaspthrglyiletrpcyslysalametglyilemetasn
505560
serpheleuasnaspilephegluargilealaglyglualaserarg
65707580
leualahistyrasnlysargserthrilethrserargargserarg
859095
argprocysalacyscyscysproalasertrpproserthrprocys
100105110
proargalaproargargserproserthrproalaprosergluser
115120125
leuproglyproglyalaargserleuproproserleuproproarg
130135140
valalaglycysphevalserlysglyserpheglnglyhisleuthr
145150155160
thrservallysgluserpheleucyscysglnserglnleumetphe
165170175
leualaserargleuvalasnpheargargalahisasnthrlyshis
180185190
arg
<210>35
<211>13
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence181-193ofseqidno:34
<400>35
leuvalasnpheargargalahisasnthrlyshisarg
1510
<210>36
<211>135
<212>prt
<213>homosapiens
<220>
<223>aminoacidsequenceofhumanhistoneh3.1,uniprotidp68431.2,
initialmethioninenotincluded
<400>36
alaargthrlysglnthralaarglysserthrglyglylysalapro
151015
arglysglnleualathrlysalaalaarglysseralaproalathr
202530
glyglyvallyslysprohisargtyrargproglythrvalalaleu
354045
arggluileargargtyrglnlysserthrgluleuleuilearglys
505560
leupropheglnargleuvalarggluilealaglnaspphelysthr
65707580
aspleuargpheglnserseralavalmetalaleuglnglualacys
859095
glualatyrleuvalglyleuphegluaspthrasnleucysalaile
100105110
hisalalysargvalthrilemetprolysaspileglnleualaarg
115120125
argileargglygluargala
130135
<210>37
<211>7
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence57-63ofseqidno:36
<400>37
serthrgluleuleuilearg
15
<210>38
<211>6
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence117-122ofseqidno:36
<400>38
valthrilemetprolys
15
<210>39
<211>9
<212>prt
<213>artificialsequence
<220>
<223>aminoacidsequence41-49ofseqidno:36
<400>39
tyrargproglythrvalalaleuarg
15
<210>40
<211>129
<212>prt
<213>homosapiens
<220>
<223>aminoacidsequenceofhumanhistoneh2atype3,uniprotid
q7l7l0.3,initialmethioninenotincluded),sigmarecombinanth2a
srp0406
<400>40
serglyargglylysglnglyglylysalaargalalysalalysser
151015
argserserargalaglyleuglnpheprovalglyargvalhisarg
202530
leuleuarglysglyasntyrsergluargvalglyalaglyalapro
354045
valtyrleualaalavalleuglutyrleuthralagluileleuglu
505560
leualaglyasnalaalaargaspasnlyslysthrargileilepro
65707580
arghisleuglnleualaileargasnaspglugluleuasnlysleu
859095
leuglyargvalthrilealaglnglyglyvalleuproasnilegln
100105110
alavalleuleuprolyslysthrgluserhishislysalalysgly
115120125
lys
<210>41
<211>193
<212>prt
<213>homosapiens
<220>
<223>aminoacidsequenceofhumanhistoneh1,uniprotidp07305,
initialmethioninenotincluded
<400>41
thrgluasnserthrseralaproalaalalysprolysargalalys
151015
alaserlyslysserthrasphisprolystyrseraspmetileval
202530
alaalaileglnalaglulysasnargalaglyserserargglnser
354045
ileglnlystyrilelysserhistyrlysvalglygluasnalaasp
505560
serglnilelysleuserilelysargleuvalthrthrglyvalleu
65707580
lysglnthrlysglyvalglyalaserglyserpheargleualalys
859095
seraspgluprolyslysservalalaphelyslysthrlyslysglu
100105110
ilelyslysvalalathrprolyslysalaserlysprolyslysala
115120125
alaserlysalaprothrlyslysprolysalathrprovallyslys
130135140
alalyslyslysleualaalathrprolyslysalalyslysprolys
145150155160
thrvallysalalysprovallysalaserlysprolyslysalalys
165170175
provallysprolysalalysserseralalysargalaglylyslys
180185190
lys
- 还没有人留言评论。精彩留言会获得点赞!