基于近红外光谱技术的芝麻油品质检测方法与流程
本发明涉及分析化学技术领域,尤其涉及一种基于近红外光谱技术的芝麻油品质检测方法。
背景技术:
十九世纪初赫歇尔在太阳光谱的能量测定中,发现了近红外光谱(Near Infrared Spectroscopy,NIR),这是可见光和红外光从770到2500纳米的波长范围之间的电磁辐射形式,频率范围是13000到4000cm-1。NIR的第一次应用是在20世纪初。直到20世纪60年代,诺里斯博士用NIR提出定量分析技术的多波长线性回归的方法,因此,NIR进入全新的发展时期。但是到了60年代中后期,随着IR技术的活跃,人们忽视了NIR技术的发展。一直到了1980年,NIR与化学计量学方法相结合,运用红外光谱积攒起来的丰富经验,NIR迅速地得到了应用推广。
经过半个多世纪的研究和演变,芝麻油品质分析技术日趋多样化、便捷化、低成本化和快速化。目前研究中的检测技术多达几十种,检测原理遍及各个学科。依据我国的芝麻种植和销售状态,我国芝麻油品质的检测体系主要分为市场和实验室两步检测。不同食用油品质的检测方法适用于不同的步骤。显色法和光谱技术等适用于市场的检测,而条件较好的实验室则常用色谱法、质谱法、核磁共振、电子鼻技术等。
近红外光谱分析方法具有快速、高效、无污染、无需前处理、无损分析、在线检测及多组分同时测定等优点,可以用于食用油的品质快速检测与鉴别中。近红外技术是世纪年代后发展起来的一种新的快速定性定量分析技术,近红外光谱包含有丰富的物质信息,其谱图与物质本身的组成及含量密切相关,通过对光谱特征的分析,可以获得有关物质结构与组成的信息。基于近红外光谱检测技术,可结合不同的化学计量学方法建立的模型对芝麻油品质进行预测。目前,针对芝麻油品质检测,尚缺乏较好的检测模型。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种芝麻油品质的检测方法,对待测样品进行近红外光谱检测,再建立定量模型和定性模型,可准确地定量预测食用油的酸值和过氧化值;并且可以准确的区分纯正芝麻油和掺伪芝麻油样本,适用于定性分析芝麻油掺伪。
本发明提供的技术方案是:
一种芝麻油品质的近红外光谱检测方法,对待测芝麻油样品进行近红外光谱检测,得到待测芝麻油样品的近红外光谱;将得到的近红外光谱进行预处理,得到待测芝麻油样品的预处理数谱图;利用得到的待测芝麻油样品的预处理数谱图建立定量模型,得到芝麻油样品中各组分的含量,实现定量预测芝麻油的酸值和过氧化值;再通过采用预设的定性模型掺伪样本检测,准确区分纯正芝麻油和掺伪芝麻油,提高结果预测性;具体包括以下步骤:
a)对待测芝麻油样品进行近红外光谱扫描检测,得到待测芝麻油样品的近红外光谱;
b)将步骤a)得到的近红外光谱分别进行光谱预处理,得到待测样品的预处理数谱图;
c)预设定量模型真值,预设的定量真值包括芝麻油样本的酸值和过氧化值,采用偏最小二乘法方法建立定量模型,得到样品中各组分的含量;所述建立定量模型包括如下步骤:
第一步,按照式1与式2分解光谱矩阵X和浓度矩阵Y:
X=TP+E (式1)
Y=UQ+F (式2)
其中,T和U分别为X和Y的得分矩阵;P和Q分别为X和Y的载荷矩阵;E和F分别为X和Y的PLS的拟合残差矩阵;
第二步,按照式3和式4进行T和U矩阵的线性回归:
U=TB (式3)
B=(TTT)-1TTY (式4)
在对预测样本作定量分析时,根据式1中矩阵P求出待测样本的光谱矩阵Y未知的得分矩阵T未知,从而根据公式5得到组分浓度的预测值:
Y未知=T未知BQ (式5)
由此实现定量预测芝麻油的酸值和过氧化值;
d)通过采用预设的定性模型掺伪样本检测来区分纯正芝麻油和掺伪芝麻油;具体包括以下步骤:
d1)将芝麻油中分别掺入大豆油和菜籽油的样品作为待测样品,对待测样品进行近红外光谱的检测,得到待测样品的近红外光谱,进一步得到待测样品的数谱图;
d2)将步骤d1)得到的待测样品的数谱图转为光谱数据表;再通过极限学习机算法分别针对芝麻油掺入大豆油和芝麻油掺入菜籽油建立定性模型;
d3)采用芝麻油掺入大豆油定性模型或芝麻油掺入菜籽油定性模型,对待区分的样品进行区分检测,得到区分结果为是纯正芝麻油或者是掺伪芝麻油。
针对上述检测方法,进一步地,通过极限学习机算法,针对掺伪芝麻油建立定性模型区分芝麻油样品是纯正还是掺伪的过程具体是:
将90个芝麻油掺伪样本和40个纯芝麻油样本的近红外光谱图转为光谱数据表,形成130个实验样本的数据表;设定隐层节点个数为45个;激活函数选择S函数时定性结果最佳;随机分配90个样本作为训练集样本,40个样本作为测试集样本;输出样本为130实验样本的数据表;设置类别1表示纯正芝麻油的类别,类别2表示芝麻油中掺伪的类别;再通过极限学习机算法输出结果。
针对上述检测方法,进一步地,将所述待测样品的数谱图转为光谱数据表,具体将得到的光谱图的格式转换为.CLV格式,通过数据格式的转换将待测样品的数谱图转为光谱数据表。
针对上述检测方法,进一步地,所述极限学习机算法包括如下过程:
给定N个不同的样本(xj,tj)∈Rn×Rm,g(x)代表激活函数,表示隐层节点数量,表示单隐层前馈神经网络的数学模型表达式为式6:
式中,ωi、bi表示随机生成的隐层各节点的参数,βi是连接隐层第i个节点的权重值,j=1,2,…,N;当网络的实际输出跟期望输出相等时表示为式7,简写成式8:
Hβ=T (式8)
其中,隐层输出矩阵矩阵的行表示此行对应的训练样本对隐层全部节点的输出,列表示全部训练样本与对应此列的隐层节点的输出;
采用所述极限学习机算法建立芝麻油掺伪定性模型,再对待区分的样品进行区分检测,得到区分结果为是纯正芝麻油或者是掺伪芝麻油。
针对上述检测方法,进一步地,步骤b)采用一阶导数+减去一条直线的方法和消除常数偏移量方法对光谱进行预处理。
针对上述检测方法,进一步地,步骤a)近红外光谱扫描为点扫描;近红外参数为:光阑为6mm;估计分辨率为8cm-1;样品扫描次数为32次;背景扫描次数为32次;光谱采集范围为12000cm-1-4000cm-1;光栅为400lines/mm;扫描速度为10kHz。
针对上述检测方法,进一步地,优选的,所述步骤a)之后、步骤b)之前还包括对步骤a)光谱范围的选择,光谱选择范围分别为6051.8~4597.7cm-1;9403.7~5446.3cm-1。
针对上述检测方法,进一步地,优选的,在所述步骤d1)之后、步骤d2)之前,对近红外光谱检测得到的谱图进行特征峰提取。所述特征峰提取的方法包括基线校正、平滑处理和选取特定波段标峰处理方法中的一种或几种。所述特征峰提取选取的波段为6000~4000cm-1。
针对芝麻油检测选取上述光谱范围和特征峰,由于芝麻油在此波段范围,含有的化学信息丰富。再通过剔除无用信息,可提高模型的预测能力。
与现有技术相比,本发明的有益效果是:
本发明提供了一种芝麻油品质的检测方法,对待测样品进行近红外光谱检测,得到待测样品的近红外光谱;将得到的近红外光谱进行预处理,得到待测样品的预处理光谱图;分别将得到的待测样品的预处理数谱图结合预设的定量模型真值,并采用偏最小二乘法方法建立定量模型,得到样品中各组分的含量;对实验室配置好的芝麻油中掺入大豆油和菜籽油的样品进行近红外光谱的检测,得到待测样品的近红外光谱;将得到的待测样品的数谱图,转为光谱数据表。结合极限学习机算法建立芝麻油掺入大豆油和菜籽油建立定性模型。
通过本发明提供的芝麻油品质的检测方法,无需复杂的前处理即可通过对光谱信息的分析提取出物质的特征信息,建立定量和定性模型,可准确地定量预测食用油的酸值和过氧化值,针对芝麻油品质检测的定量模型和定性模型拟合效果好;并且可以准确的区分纯正芝麻油和掺伪芝麻油样本,正确率为90%以上,适用于定性分析芝麻油掺伪;适用于芝麻油品质的快速无损检测;而且,本发明采用预设的定性模型掺伪样本使得结果预测性较高;特别适合用于快速鉴别芝麻油的品质和进行成分检测。
附图说明
图1是本发明提供检测方法的流程框图;
其中,(a)为光谱检测方法实现定量预测的过程框图;(b)为光谱检测方法实现定性分析的过程框图。
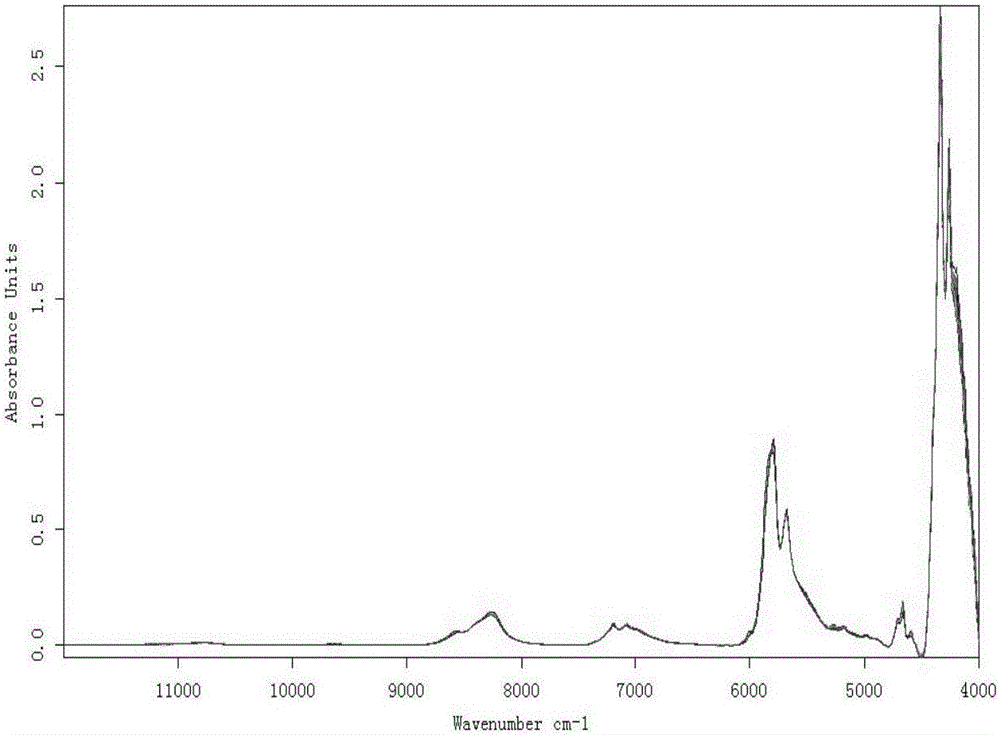
图2是芝麻油的近红外光谱图;
其中,横坐标代表波数范围,单位为cm-1;纵坐标代表吸光度。
图3本发明基于近红外光谱的芝麻油酸值模型结果图;
其中,(a)为酸值校正模型;(b)为酸值预测模型;
经过一阶导数+矢量归一化方法进行预处理后的光谱,采用PLS方法建立食用油酸值指标的定量校正模型;选取的主成分数会使模型的预测能力发生改变,主成分选取得过多会增加噪音含量,容易过分拟合;主成分选取得过少导致有效信息不能被充分利用,会出现欠拟合现象;建立的校正模型结果如图3(a)所示,模型的主成分数为10,决定系数R2为0.9961,交互验证均方差RMSECV为0.0127;预测样本对建立的校正模型进行交叉检验,得到的预测结果如图3(b)所示,模型的主成分数为10,决定系数R2为0.9904,预测均方差RMSEP为0.0187,预测结果较好。
图4是本发明基于近红外光谱的芝麻油过氧化值模型结果图;
其中,(a)为过氧化值校正模型;(b)为过氧化值预测模型;
食用油过氧化值定量模型的建立方法与酸值定量模型建立方法相同;在建立过氧化值定量分析模型时选择最小—最大归一化的光谱预处理方法,光谱范围选择9403.7~7498.3cm-1和5450.1~4597.7cm-1,采用PLS算法建立食用油酸值指标的定量校正模型;建立的酸值模型如图4所示,校正模型的主成分数为9,决定系数R2为0.9794,交互验证均方差RMSECV为0.114;测试样本交叉检验得到的预测结果模型的主成分数为9,决定系数R2为0.9637,预测均方差RMSEP为0.142。
图5是本发明实施例中芝麻油掺入大豆油的近红外光谱图;
对配制好的芝麻油掺伪样本采集其近红外光谱图,样本无需任何化学试剂处理,直接采用德国Bruker公司VERTEX 70傅里叶红外光谱仪进行光谱采集,采集到的芝麻油掺入大豆油的近红外光谱图。
图6是本发明实施例中芝麻油掺入菜籽油的近红外光谱图;
对配制好的芝麻油掺伪样本采集其近红外光谱图,样本无需任何化学试剂处理,直接采用德国Bruker公司VERTEX 70傅里叶红外光谱仪进行光谱采集,采集到的芝麻油掺入菜籽油的近红外光谱图。
图7是本发明实施例中基于近红外光谱的芝麻油掺入大豆油和纯芝麻油的预测分类结果图。
图8是本发明实施例中基于近红外光谱的芝麻油掺入菜籽油和纯芝麻油谱图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
为保证芝麻油质量,国家标准《GB 8233-2008芝麻油》和《GB/T 5539-2008粮油检验油脂定性试验》规定了芝麻油的理化性质和识别方法,本发明主要针对芝麻油中的酸值和过氧化值基于近红外光谱技术对芝麻油品质进行检测。
近红外光谱仪采集到的食用油近红外谱图如图2所示。图中横坐标代表波数范围,单位为cm-1,纵坐标代表吸光度。从光谱图可知食用油的近红外光谱主要在9000~4000cm-1范围内产生较大的吸收峰,因此在这个波数范围内有较为丰富的信息。
本发明提供的检测方法可以对芝麻油的品质进行快速、无污染的检测,无需复杂的样品制备。本发明采用近红外光谱结合极限学习机算法在芝麻油中掺杂大豆油和菜籽油以及掺假芝麻油定性分析模型。
图1是本发明提供检测方法的流程框图;本发明提供了一种芝麻油品质的检测方法,包括以下步骤:
a)对待测样品进行近红外光谱检测,得到待测样品的近红外光谱;
本发明实施例具体针对芝麻油品质进行检测。
b)将所述步骤a)得到的近红外光谱分别进行一阶导数+减去一条直线的方法和消除常数偏移量方法的光谱预处理,得到待测样品的光谱预处理图(数谱图);
c)分别将所述步骤b)得到的待测样品的光谱预处理图结合预设的定量模型真值(即预设的定量真值:芝麻油样本的酸值和过氧化值),并采用偏最小二乘法方法建立定量模型,得到样品中各组分的含量。
本发明采用偏最小二乘法方法建立定量模型,其中,第一步是按照公式1与2进行分解光谱矩阵X跟浓度矩阵Y。
X=TP+E (式1)
Y=UQ+F (式2)
其中,T和U分别为X和Y的得分矩阵;P和Q分别为X和Y的载荷矩阵;E和F分别为X和Y的PLS的拟合残差矩阵。
第二步是按照公式3和4进行T和U矩阵的线性回归。
U=TB (式3)
B=(TTT)-1TTY (式4)
在对预测样本作定量分析时,根据公式1中矩阵P求出待测样本的光谱矩阵Y未知的得分矩阵T未知,从而根据公式5得到组分浓度的预测值。
Y未知=T未知BQ (式5)
d)将实验室配置好的芝麻油中掺入大豆油和菜籽油的样品作为待测样品,对待测样品进行近红外光谱的检测,得到待测样品的近红外光谱;
e)将所述步骤d)得到的待测样品的数谱图,转为光谱数据表。结合极限学习机算法建立芝麻油掺入大豆油和菜籽油建立定性模型;
具体将得到的光谱图的格式转换为.CLV格式,通过数据格式的转换将待测样品的数谱图转为光谱数据表。
本发明实施例采用结合极限学习机算法,对芝麻油掺入大豆油和菜籽油建立定性模型:
(1)芝麻油掺入大豆油建立定性模型:
输入样本:将90个芝麻油掺入大豆油的掺伪样本和40个纯芝麻油样本的近红外光谱图转为光谱数据表,形成130个实验样本的数据表;具体地,设定隐层节点个数为45个;激活函数选择S函数时定性结果最佳;随机分配90个样本作为训练集样本,40个样本作为测试集样本;输出样本为130实验样本的数据表;设置类别1表示纯正芝麻油的类别,类别2表示芝麻油中掺入大豆油的类别。
(2)芝麻油掺入菜籽油建立定性模型:
输入样本:将90个芝麻油掺入菜籽油的掺伪样本和和40个纯芝麻油样本的近红外光谱图转为光谱数据表,形成130个实验样本的数据表;具体地,设定隐层节点个数为45个;激活函数选择正弦函数时定性结果最佳;随机分配90个样本作为训练集样本,40个样本作为测试集样本;输出样本为130实验样本的数据表;类别1表示纯正芝麻油的类别,类别2表示芝麻油中掺入菜籽油的类别。
极限学习机算法包括如下过程:
给定N个不同的样本(xj,tj)∈Rn×Rm,g(x)代表激活函数,N~表示隐层节点数量,数学模型表达式(式6)表示单隐层前馈神经网络:
式中ωi、bi表示随机生成的隐层各节点的参数,βi是连接隐层第i个节点的权重值,j=1,2,…,N。当网络的实际输出跟期望输出相等时则有式7,简写成式8。
Hβ=T (式8)
其中,隐层输出矩阵矩阵的行表示此行对应的训练样本对隐层全部节点的输出,列表示全部训练样本与对应此列的隐层节点的输出;
通过本发明提供的芝麻油品质的检测方法建立了定量和定性模型,可准确地定量预测食用油的酸值和过氧化值。并且可以准确的区分纯正芝麻油和掺伪芝麻油样本,正确率为90%以上。
优选的,所述步骤a)近红外光谱扫描为点扫描。
优选的,所述步骤a)近红外参数为:光阑6mm,估计分辨率8cm-1,样品扫描次数32次,背景扫描次数32次,光谱采集范围12000cm-1-4000cm-1,光栅400lines/mm,扫描速度10kHz。
优选的,所述步骤a)之后、步骤b)之前还包括对步骤a)光谱范围的选择,光谱选择范围分别为6051.8~4597.7cm-1;9403.7~5446.3cm-1。
优选的,所述步骤d)之后、步骤e)之前近红外光谱检测得到的谱图进行提取特征峰。
优选的,所述提取特征峰的方法选自基线校正、平滑处理和选取特定波段标峰处理中的一种或几种。
优选的,所述建立定性选取特征峰的波段为6000~4000cm-1。
为了进一步说明本发明,以下结合实施例对本发明提供的芝麻油品质的检测方法进行详细描述。
实施例1
本研究所用仪器是为Bruker VERTEX 70傅里叶红外光谱仪。它具有高灵敏度与信噪比,高稳定性,可扩展性,高度智能化,可实现远程操作、远程控制、远程诊断、资源共享等功能的网络化设计,对主机的所有硬件、工作状态、性能指标,测量附件的识别、工作状态、测量参数的设定可进行实时在线监控等特点。
从古船油厂采集到的实验样本在采集光谱时不需要任何前处理,可以直接采集食用油的近红外光谱数据,近红外光谱图,如图2所示。
常见的食用油:多为植物油脂,包括粟米油、花生油、火麻油、玉米油、橄榄油、山茶油、棕榈油、芥花子油、葵花子油、大豆油、芝麻油、亚麻籽油(胡麻油)、葡萄籽油、核桃油、牡丹籽油。
实验参数设置方法如下:光阑6mm,估计分辨率8cm-1,样品扫描次数32次,背景扫描次数32次,光谱采集范围12000cm-1-4000cm-1,光栅400lines/mm,扫描速度10kHz。
实施例2
对实施例1采集到的近红外光谱图,结合偏最小二乘的方法建立芝麻油的酸值定量分析模型,预处理方法为一阶导数+减去一条直线的方法,光谱范围选择6051.8~4597.7cm-1。建模结果如图2所示,校正模型的主成分数为8,决定系数R2为0.9873,交互验证均方差RMSECV为0.0302;预测模型结果是主成分数为8,决定系数R2为0.9502,预测均方差RMSEP为0.0497。
实施例3
结合偏最小二乘的方法建立芝麻油的过氧化值定量分析模型,预处理方法为消除常数偏移量的方法,光谱范围选择9403.7~5446.3cm-1。建模结果如图3所示,校正模型的主成分数为6,相关系数R2为0.9687,交互验证均方差RMSECV为0.0994;预测模型结果是主成分数为6,相关系数R2为0.9314,预测均方差RMSEP为0.128。
实施例4
为模拟掺伪芝麻油,本实验的样本均为实验室配制的样本,各种类的食用油均采购自北京市各大超市,均为正品保质的食用油。通过前期的分析调研结果表明参与芝麻油掺伪的食用油多为价格相对廉价的大豆油和菜籽油,因此选购了不同品牌不同批次的芝麻油3种(分别为金龙鱼100%纯芝麻油(一级压榨)400ml、古币100%纯芝麻香油(一级压榨)245ml、鲁花芝麻香油(一级压榨)350ml)、大豆油3种(金龙鱼精纯一级大豆油1.8L、福临门一级豆油1.8L、九三非转基因大豆油1.8L)、菜籽油3种(金龙鱼外婆乡小榨菜籽油900ml、盈成双低菜籽油1.8L、鲁花压榨特香菜籽油2L)进行芝麻油的掺伪样本配制。
掺伪样本按每50ml芝麻油中掺入体积比为50%、45%、40%、35%、30%、25%、20%、15%、10%、5%的10个梯度进行配制,共计3×3×2×10=180个掺伪样本,其中90个为芝麻油掺入大豆油的掺伪样本,另外90个为芝麻油掺入菜籽油的掺伪样本。配制好的的芝麻油掺伪样本与纯芝麻油样本40个共计220个样本进行定性建模分析。采集到的光谱图见图4和图5。
实施例5
选取芝麻油掺入大豆油的定性建模分析,选取芝麻油掺入大豆油的90个掺伪样本与从古船采样获得的40个纯芝麻油样本进行近红外的定性建模分析。90个芝麻油掺入大豆油的掺伪样本和40个纯芝麻油样本的近红外光谱图转为光谱数据表,每张光谱有2074个数据点,形成130个实验样本的数据表。通过MATLAB软件实现极限学习机(ELM)分类算法,建立鉴别芝麻油掺入大豆油与纯芝麻油的定性分析模型,经过多次计算比较,设定隐层节点个数为45个,激活函数选择S函数时定性结果最佳。随机分配90个样本作为训练集样本,40个样本作为测试集样本,设置类别1表示纯正芝麻油的类别,类别2表示芝麻油中掺入大豆油的类别。
建模分析结果训练集分类正确率为98.89%(89/90),测试集预测分类正确率为97.5%(39/40)。测试集预测结果见图7,其中圆圈符号表示样本的真实类别,星星符号表示通过ELM算法进行预测的分类。结果表明有一个掺伪的芝麻油样本分类有误,预测准确率为97.5%。
实施例6
选取芝麻油掺入菜籽油的90个掺伪样本与从古船采样获得的40个纯芝麻油样本进行近红外的定性建模分析。将90个芝麻油掺入菜籽油的掺伪样本和40个纯芝麻油样本的近红外光谱图转为光谱数据表,每张光谱图有2074个数据点,形成130个实验样本的数据表。通过MATLAB软件实现极限学习机(ELM)分类算法,建立芝麻油掺入菜籽油的定性分析模型,经过多次计算比较,设定隐层节点个数为40个,激活函数选择正弦函数。随机分配90个训练集样本和40个测试集样本,类别1表示纯正芝麻油的类别,类别2表示芝麻油中掺入菜籽油的类别。
建模分析结果表明训练集分类正确率为98.89%(89/90),测试集预测分类正确率为90%(36/40)。测试集预测结果见图8,其中圆圈符号表示样本的真实类别,星星符号表示通过ELM算法进行预测的分类。结果表明可以看到纯正的芝麻油样本分类全部正确,有3个纯芝麻油样本和1个掺伪的芝麻油样本分类有误,预测准确率为90%。
图5是芝麻油掺入大豆油的近红外光谱图。对配制好的芝麻油掺伪样本采集其近红外光谱,样本无需任何化学试剂处理,直接采用德国Bruker公司VERTEX 70傅里叶红外光谱仪进行光谱采集。
图6是芝麻油掺入菜籽油的近红外光谱图。对配制好的芝麻油掺伪样本采集其近红外光谱,样本无需任何化学试剂处理,直接采用德国Bruker公司VERTEX 70傅里叶红外光谱仪进行光谱采集
图7是基于近红外光谱的芝麻油掺入大豆油和纯芝麻油的预测分类结果;建模分析结果训练集分类正确率为98.89%(89/90),测试集预测分类正确率为97.5%(39/40)。测试集预测结果见图7,其中圆圈符号表示样本的真实类别,星星符号表示通过ELM算法进行预测的分类。结果表明有一个掺伪的芝麻油样本分类有误,预测准确率为97.5%。
图8是基于近红外光谱的芝麻油掺入菜籽油和纯芝麻油谱图;建模分析结果表明训练集分类正确率为98.89%(89/90),测试集预测分类正确率为90%(36/40)。测试集预测结果见图8,其中圆圈符号表示样本的真实类别,星星符号表示通过ELM算法进行预测的分类。结果表明可以看到纯正的芝麻油样本分类全部正确,有3个纯芝麻油样本和1个掺伪的芝麻油样本分类有误,预测准确率为90%。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!