一种应用于产地溯源的肉类鉴别方法及装置与流程
本发明涉及肉类鉴别领域,尤其涉及一种肉类掺假鉴别方法及装置。
背景技术:
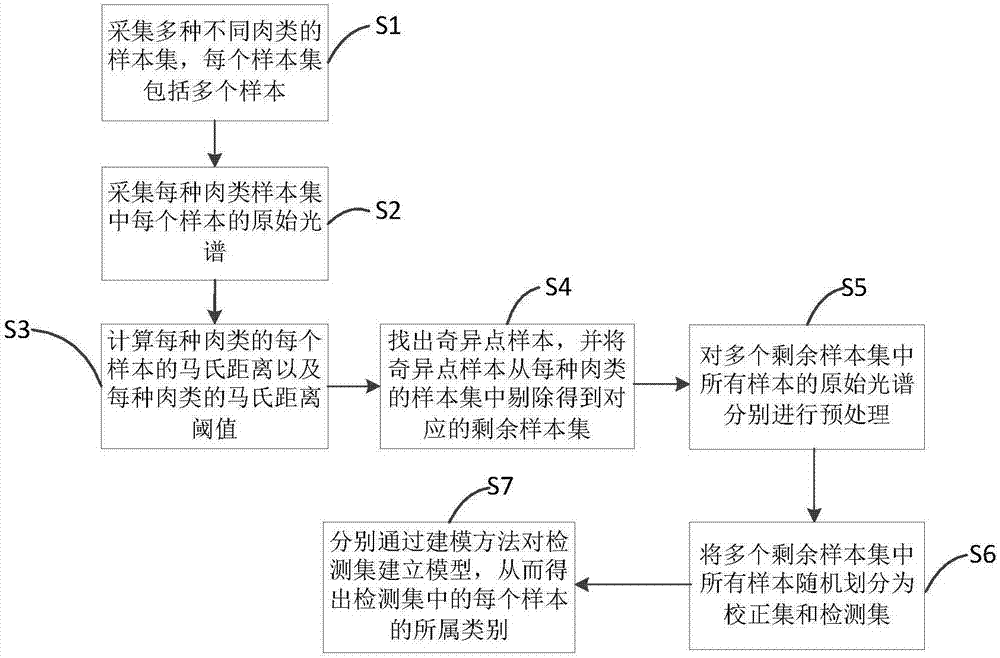
:现实生活中,市场上出现很多肉类掺假事件,使得肉类产品的安全问题处于风口浪尖,备受人们争议和关注。比如在2014至2015年对广东省牛羊肉及其制品中掺杂掺假情况进行调查:50份检验样品中,检出10份掺假肉食品,总掺假率为20.0%。可见国内肉类市场掺假的严重程度。食品造假掺假、以次充好的事件不仅严重危害了消费者的健康和利益,同时也影响了相关企业的发展以及民众对国内食品安全的信任度。比如将猪肉充作为是牛肉、羊肉。因而,快速准确的对肉类产品进行快速鉴别,遏制不良商家的造假行为显得迫在眉睫。传统的肉类鉴别方法包括生物鉴定法和感官评定法,而对于生物鉴定法一般比如采用聚合酶链式反应(pcr)、酶联免疫分析(elisa)等,该类检测方法虽然检测精度很高但存在着工序复杂、成本高、破坏样本、检测时间长等缺点;而对于感官评定法,需要人工丰富的经验,误差较大。技术实现要素:为了克服现有技术的不足,本发明的目的之一在于提供一种应用于产地溯源的肉类掺假鉴别方法,其能够解决现有技术中家畜肉类掺假鉴别的成本高、检测时间长、误差大等问题。为了克服现有技术的不足,本发明的目的之二在于提供一种应用于产地溯源的肉类掺假鉴别装置,其能够解决现有技术中家畜肉类掺假鉴别的成本高、检测时间长、误差大等问题的问题。本发明的目的之一采用以下技术方案实现:一种应用于产地溯源的肉类掺假鉴别方法,包括以下步骤:s1:分别制备多个不同肉类的样本集,每个样本集包括多个检测样本;s2:分别采集s1中每个检测样本的原始光谱;s3:计算每个检测样本的马氏距离以及每种肉类的马氏距离阈值,并根据每个检测样本的马氏距离以及对应肉类的马氏距离阈值得出奇异点样本,然后将奇异点样本从每种肉类的样本集中剔除后得到对应的剩余样本集;s4:对多个剩余样本集中所有检测样本的原始光谱分别进行预处理;s5:将多个剩余样本集中所有检测样本随机划分为校正集和检测集,通过建模方法对检测集建立鉴别模型。进一步地,所述每种肉类样本的马氏距离阈值t为:其中为同一种肉类的所有样本向量的平均光谱、δ为调整参数、σd为马氏距离标准差;所述每个检测样本的马氏距离d(xi)为:其中xi为第i个光谱向量、为光谱向量的平均光谱,s为协方差矩阵;所述每个检测样本的马氏距离为每个检测样本的样本向量xi到平均光谱的马氏距离;所述奇异点样本为马氏距离d(xi)大于对应肉类的马氏距离阈值t的检测样本。进一步地,所述预处理为多元散射校正预处理、标准正则变换预处理、一阶求导预处理、二阶求导预处理、savitzky-golay平滑预处理和归一化预处理中的一种。进一步地,所述建模方法为pls-da建模方法或svm建模方法。进一步地,所述样本集通过以下制备过程得到:在不同肉铺、不同超市采集每种肉类的精瘦肉样本并放置于实验室冰箱进行冷藏,然后对将每个样本切成薄片并放入45度的恒温箱烘干48小时,最后将每个样本研磨成粉末后分别装入干燥保鲜膜中保存。进一步地,每个原始光谱是通过傅里叶变换红外光谱仪对每个检测样本进行连续多次扫描采集,并且每个检测样本扫描采集的次数相同,然后根据每个检测样本多次采集到的数据取平均值得到。进一步地,所述傅里叶变换红外光谱仪的扫描波数范围为4000-450cm-1、分辨率为4cm-1、扫描环境温度为25℃、湿度为30±5%。进一步地,所述s5还包括通过建模方法对校正集建立鉴别模型。进一步地,所述肉类为猪肉或牛肉或羊肉。本发明的目的之二采用以下技术方案实现:一种应用于产地溯源的肉类掺假鉴别装置,包括:样本采集模块,用于分别制备多个不同肉类的样本集,每个样本集包括多个检测样本;光谱采集模块,用于分别采集s1中每个检测样本的原始光谱;奇异样本剔除模块,用于计算每个检测样本的马氏距离以及每种肉类的马氏距离阈值,并根据每个检测样本的马氏距离以及对应肉类的马氏距离阈值得出奇异点样本,然后将奇异点样本从每种肉类的样本集中剔除后得到对应的剩余样本集;预处理模块,用于对多个剩余样本集中所有检测样本分别进行预处理;鉴别模块,用于将多个剩余样本集中所有检测样本随机划分为校正集和检测集,通过建模方法对检测集建立鉴别模型。相比现有技术,本发明的有益效果在于:本发明通过红外光谱技术结合相应的建模方法对不同种类的肉类进行鉴别判断,解决了现有技术中肉类掺假鉴别时的成本高、检测试剂、误差大等问题。附图说明图1为本发明提供的鉴别方法的流程图;图2为本发明提供的所有样本的原始光谱图;图3为本发明提供的三种肉类的样本平均光谱图;图4为本发明提供的牛肉样本集中所有样本的马氏距离分布图;图5为本发明提供的猪肉样本集中所有样本的马氏距离分布图;图6为本发明提供的羊肉样本集中所有样本的马氏距离分布图;图7为本发明提供的pls-da建模方法中检测集中每种肉类的每个样本的预测值与参考值的分布图;图8为本发明提供的pls-da建模方法中校正集中每种肉类的每个样本的预测值与参考值的分布图;图9为本发明提供的svm建模方法中检测集中每种肉类的每个样本的预测值与参考值的分布图;图10为本发明提供的装置模块图。具体实施方式下面,结合附图以及具体实施方式,对本发明做进一步描述:实施例红外线光谱技术是依据物体内部原子、分子等特定结构对电磁波有不同吸收特性的原理,对物体特定成分进行定性、定量的分析技术。其具有快速、无损、简单等优点,在农业产品检测中应用非常广泛,目前在茶叶、蜂蜜、葡糖酒、稻米、橄榄油以及肉制品等方面都具有广泛的应用。本发明主要是将该红外光谱技术与建立模型的方法进行结合,从而能够对家畜肉类,比如猪肉、牛肉、羊肉等的掺假情况进行检测、鉴别。一种应用于产地溯源的家畜肉类掺假鉴别方法,如图1所示,包括以下步骤:s1:分别制备多个不同肉类的样本集,每个样本集包括多个样本;s2:分别采集s1中每个样本的原始光谱;s3:计算每种肉类样本集中的每个样本的马氏距离以及每种肉类的马氏距离阈值;s4:根据每个样本的马氏距离与对应肉类的马氏距离阈值找出奇异点样本,然后剔除每种肉类样本集中的奇异点样本得到对应的剩余样本集。当样本的马氏距离大于对应的马氏距离阈值时,该样本为奇异点样本。s5:对多个剩余样本集中所有样本的原始光谱分别进行预处理;s6:将多个剩余样本集中所有样本随机划分为校正集和检测集;s7:通过建模方法对检测集建立鉴别模型,从而根据鉴别模型得出检测集中每个样本的所属类别。优选地,所述s7还包括通过建模方法对校正集建立鉴别模型,从而根据鉴别模型对建模方法进行评价。作为优选,本发明所采用的肉类为猪肉、牛肉和羊肉三种肉类,每种肉类的样本均采用60个。本发明所采用的样本均为不同肉铺、不同超市采集到的精瘦肉,并且采集后立即放到实验室冰箱进行冷藏,然后将每个样本切成薄片并放入45度恒温箱烘干48小时,研磨成粉末后装入干燥保鲜膜中保存。本发明可以应用于肉类的产地溯源中的肉类的掺假鉴别,从而可杜绝肉类掺假在市场上的流通。在建立模型之前,首先需要对每个样本进行光谱处理。本发明使用红外光谱仪对每个样本进行透射光谱采集。优选地,本发明中采用的光谱采集仪器为傅里叶变换红外光谱仪,通过该红外光谱仪对制作的样本进行透射光谱采集。其光谱仪所采集扫描的波数范围为4000-450cm-1、分辨率为4cm-1、扫描环境温度为25℃、湿度为30±5%。在采集的过程中,对每个样本连续扫描三次,然后对三次所得到的光谱数据求平均值得到每个样本的原始光谱数据,如图2所示。每次扫描时,要保证每个样本的扫描环境一致。由于样本制备过程中被污染或光谱采集过程中受设备、环境等因素的影响,可能存在个别样本成为奇异点样本,其对建模的稳健性、精度都有较大的影响,因此本发明采用马氏距离首先将奇异点样本从该肉类的样本集中剔除,以免影响后建模,影响鉴别结果。本发明中采用马氏距离(英文名:mahalanobisdistance)进行排除奇异点样本只要是通过首先计算出每种肉类的马氏距离阈值,以及每个样本的马氏距离,然后将马氏距离大于对应的马氏距离阈值的样本被认为是奇异点样本,将其从样本集中剔除。具体地,对于同一种肉采集到的60个样本的原始光谱数据应该是相近的,也即是每个样本的马氏距离应该在一个允许的范围内,若出现一个样本的马氏距离与其他的马氏距离相差较大时,则认为该样本为奇异点样本。本发明中将一个样本经过光谱处理后得到一个光谱曲线看作为一光谱向量,该光谱向量包括波数和透射率信息,该向量用x表示。对于同一种肉类的60个样本,每个样本的光谱向量可表示为xi,其中i为[1,60]。假设一种肉类的马氏距离阈值t为:其中为同一种肉类的所有样本向量的平均光谱,如图3所示;δ为调整参数、σd为马氏距离标准差。而对于每个样本的样本向量xi到平均光谱的马氏距离d(xi)为:其中xi为第i个光谱向量、为光谱向量的平均光谱、s为协方差矩阵。当一个样本的d(xi)大于对应肉类的马氏距离阈值t时,认为该样本为奇异点样本。另外,本发明中采用的δ=3,其是按统计学经验和相关资料确定的值。如图4、5、6所示,对于本发明提供的-猪肉、牛肉、羊肉三种肉类样本,分别通过公式(1)、(2)计算得到每种肉类的每个样本的马氏距离以及对应的马氏距离阈值。如图4为牛肉的每个样本的马氏距离与牛肉样本的马氏距离阈值的分布图、图5为猪肉的每个样本的马氏距离与猪肉样本的马氏距离阈值的分布图、图6为羊肉的每个样本的马氏距离与羊肉样本的马氏距离阈值的分布图。从图4中可知:对于牛肉的样本集,第53个样本的马氏距离为18.55,其远超过牛肉的马氏距离阈值8.74,因此,在之后进行建模处理时,将该第53个样本从牛肉的样本集中剔除,在后期建模时不做考虑。同理,对于猪肉的样本集中将第1个样本和第53个样本剔除、对于羊肉的样本集中的第20个样本剔除。本发明还进行了检测对比,对于在剔除奇异点样本与不剔除奇异点样本,这两种情况对于鉴别的结果性能影响,如图表1所示。样本选取r2calrmsecr2valrmsecv剔除奇异点样本前0.960.170.930.21剔除奇异点样本后0.980.090.990.11表1根据表1可以看出校正集决定系数r2cal、检测集决定系数r2val、校正集均方根误差rmsec和检测集均方根误差rmsecv均有所提高,说明奇异点样本对建模模型有较大影响,排除奇异点样本后进行建模模型鉴别时,其性能更好。另外,为了排除原始光谱采集过程中受设备、环境、样本制作的因素的影响,本文对原始光谱进行预处理。预处理方法可采用多元散射校正预处理、标准正则变换预处理、一阶求导预处理、二阶求导预处理、sacitzky-golay平滑预处理以及归一化预处理六种预处理方法。本发明还对上述六种预处理的方法进行分析后得到每种预处理的方法对于鉴别结果的影响性能,如表2所示。表2从表2中可以看出,一阶求导预处理方法和二阶求导预处理方法不仅放大了特征吸收波段,同时也放大了噪声,导致模型性能和准确率反而下降,而归一化处理由于能够排除不同样本之间厚度、透过率的影响,因此更能有效消除同种肉类样本间的差异,效果最好。其中,r2cal为校正集决定系数、r2val为检测集决定系数、rmsec为校正集均方根误差、rmsecv为预测集均方根误差。另外,从表1中的数据还可以看出,归一化预处理方法的校正集决定系数r2cal、检测集决定系数r2val均为0.99、校正集均方根误差rmsec为0.06、预测集均方根误差rmsecv为0.08、检测集预测准确率为100%,由此可以看出归一化预处理应用于建模时使得预测准确率最高。因此,归一化预处理为最为优选地预处理方法。另外,上述六种预处理方法均为现有比较成熟的技术手段,其方法本身并不是本发明的发明点。对所有的样本进行预处理后,对样本集进行建模,首先对三种肉类的所有样本进行随机划分,将样本划分为两部分,一部分为校正集而一部分为检测集,然后通过对校正集、检测集分别进行建立鉴别模型。每种肉类的样本集中剔除奇异点样本后,猪肉的样本集中剩余58个样本、牛肉的样本集中剩余59个样本、羊肉的样本集中剩余59个样本,分别随机将上述所有的样本进行拆分。比如随机选取猪肉的38个样本、牛肉的39个样本、羊肉的39个样本作为校正集,而对应剩下的猪肉20个样本、牛肉20个样本、羊肉20个样本作为检测集。本发明所采用的建模方法之一为pls-da建模方法(也称为偏最小二乘法建模方法),是通过最小化均方根误差找到一组数据的最佳函数匹配;用最简单的方法求得一些绝对不可知的真值,而令均方根误差之和为最小。pls-da建模方法的具体建模过程如下(以下建模的计算过程只是较简单的介绍,该建模方法的具体计算过程是本领域技术人员所熟知的):设x为猪肉或牛肉或羊肉校正集样本光谱矩阵,y为本方案假设的包含{-1,0,1}的向量,其中-1、0、1分别对应牛肉样本、猪肉样本和羊肉样本的参考值。a、对x和y进行中心化,得到x0和y0;并从y0中选择一列作为u1。一般来说,选择方差较大的一列作为u1。b、迭代求解x的变换权重w1、因子t1,y的变换权重c1、因子u1,直到收敛。该迭代求解的过程为:b1、利用y的信息u1,求x的变换权重w1及因子t1,从而将x0的信息用t1来近似表达;迭代公式如下:w1=x0tu1/(u1tu1),w1=w1/||w1||,t1=x0w1。b2、利用x的信息t1求y的变换权重c1,并将因子u1更新为μ1,从而将y0的信息用t1来近似表达;迭代公式如下:c1=y0tt1/(t1tt1),c1=c1/||c1||,μ1*=y0c1。b3、根据δu判断是否已经找到合理解,若是则执行s3;若否则继续进行迭代求解,直到找到合理解;其中δu为δu=uδtuδ=(u1*-u1)t(u1*-u1),其中uδ=u1*-u1;当δu<阈值,找到合理解,则执行s3;否则,取u1=u1*,返回s21。该阈值可以是10-6。c、求x与y的残差矩阵。首先,x的载荷为p1:p1=x0tt1/(t1tt1)。则p1的推导公式如下:根据t1来表达x0,建立回归模型:对转置得两边右乘t1有从而有求得x0的残差x1为:其中,p1代表因子t1在x上的载荷(loadings),它反映了原始变量x与第一个因子向量t1间的关系,而残差x1表达了u1所不能反映的x0中的信息。建立x因子t1与y因子u1间的回归模型u1=b1t1,用t1预测u1的信息,得到b1=u1tt1/(t1tt1),则残差y1为其中残差y1表达了x因子t1所不能预测的y0中的信息。d、然后利用x1与y1重复上面步骤,求解下一个主成分pls参数,最终求出一定主成分的pls-da模型;其中pls参数包括因子、转换权重、载荷、回归系数等。通过pls-da建模方法对检测集建立对应的鉴别模型,得出检测集中每个样本的预测值,然后将预测值通过图示的方式进行显示,如图7所示。本文中采用参考值上下浮动±0.5,作为参考值的参考范围,也即是得到的预测值若是在参考值上下浮动±0.5以内,均认为是正常的。如图7为检测集中每种肉类的每个样本的预测值与参考值的分布图,牛肉的每个样本的预测值位于[-1.09,-0.92]而牛肉的样本的参考值范围为[-1.5,-0.5]、猪肉的每个样本的预测值位于[-0.05,0.18]而猪肉的样本的参考值范围为[-0.5,0.5]、羊肉的每个样本的预测值位于[0.70,1.08]而羊肉的样本的参考值范围为[0.5,1.5]。由此可见,检测集的每种肉类的每个样本的预测值都在相应参考值允许的范围内,建模方法所建立的鉴别模型其预测准确率为100%,pls-da建模方法具有良好的判断性能。另外,本发明还对校正集建立鉴别模型,如图8所示为校正集中每种肉类的每个样本的预测值与对应参考值的分布图,本文可根据校正集的每个样本的预测值与对应参考值的分布图来对pls-da建模方法进行的评价。本发明还提供了另外一种建模方法,即是svm建模方法(又称为支持向量机建模方法,该建模的具体计算过程也是本领域技术人员所熟知的),通过svm建模方法同样的将剔除奇异点样本的剩余样本集中的所有样本随机划分为校正集与检测集,然后对检测集通过svm建模方法进行建模,从而得到如9所示检测集中每种肉类的每个样本的预测值与参考值的分布图。由图9得知,检测集中的每个样本的预测值均在相应的参考值可允许的范围内,也即是该svm建模方法所建立的鉴别模型其预测准确率达到100%。同样的,还通过svm建模方法对校正集建立鉴别模型,从而得到校正集中每种肉类的每个样本的预测值与参考值的关系,可用来对svm建模方法的计算过程进行评价。本发明通过pls-da建模方法和svm建模方法分别对校正集与检测集建立鉴别模型,其预测准确率均达到了100%。优选地,本发明还包括s6:通过计算上述两种建模方法所建立的鉴别模型的决定系数、均方根误差以及交叉验证均方根误差来验证两种建模方法的性能优劣。建模方法r2calrmsecr2valrmsecvrmsep检测集预测准确率/%pls-da0.990.060.990.080.08100svm0.970.150.960.170.24100表3从表3中可以看出,pls-da建模方法和svm建模方法对检测集的预测准确率都达到了100%,同时两种建模方法的校正集决定系数r2cal、检测集决定系数r2val都在0.96以上,校正集均方根误差rmsec、检测集均方根误差rmsecv都在0.25以下,因此两种建模方法都具有较好的性能,都能准确的对三种肉类进行鉴别。但在比较两种建模方法的优劣时可以看出,pls-da建模方法的校正集决定系数r2cal和检测集决定系数r2val都达到了0.99,均高于svm建模方法的;同时pls-da建模方法的校正集均方根误差rmsec、检测集均方根误差rmsecv以及交叉验证均方根误差rmsep都在0.08以下,均小于svm建模方法的。因此pls-da建模方法比svm建模方法具有更好的判别性能。如图10所示,本发明还提供了一种应用于产地溯源的肉类掺假鉴别装置,包括:样本采集模块,用于分别制备多个不同肉类的样本集,每个样本集包括多个检测样本;光谱采集模块,用于分别采集s1中每个检测样本的原始光谱;奇异样本剔除模块,用于计算每个检测样本的马氏距离以及每种肉类的马氏距离阈值,并根据每个检测样本的马氏距离以及对应肉类的马氏距离阈值得出奇异点样本,然后将奇异点样本从每种肉类的样本集中剔除后得到对应的剩余样本集;预处理模块,用于对多个剩余样本集中所有检测样本分别进行预处理;鉴别模块,用于将多个剩余样本集中所有检测样本随机划分为校正集和检测集,通过建模方法对检测集建立鉴别模型。对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1