基于GPU的视频SAR回波仿真并行实现方法与流程
本发明属于雷达信号处理技术领域,尤其涉及一种基于gpu的视频sar回波仿真并行实现方法,可用于视频合成孔径雷达(videosyntheticapertureradar,videosar)成像算法、运动补偿算法的验证以及视频成像雷达系统性能的评估。
背景技术:
合成孔径雷达具有全天时、全天候、远距离和高分辨率成像等特点。而视频合成孔径雷达可以对分布式场景目标进行连续多帧的不间断观测成像,实现可靠的速度无关运动目标检测,属于雷达研究前沿技术。
在新型视频sar系统付诸实践之前,为对该系统进行验证和评估,一般需要对回波信号进行精确仿真。面对视频sar日益增长的高帧率高分辨宽测绘带需求,需要对分布式场景目标进行高频段回波仿真。但是对场景的每个点目标进行回波模拟的计算量巨大,回波信号生成非常耗时。这使得大场景、高帧率要求的视频sar快速回波仿真成为了研究的热点。
近年来,随着图形处理器(graphicsprocessingunit,gpu)软硬件技术的日趋成熟,gpu强大的浮点运算和并行处理能力使得业界都在致力于挖掘其潜能,让它能够在非图形领域得到广泛应用。基于gpu的通用计算研究逐渐深入。
传统视频sar回波仿真采用基于中央处理器(centralprocessingunit,cpu)的串行处理方式实现。这种做法的缺点是回波模拟计算时间长、效率低,很难满足大场景、高帧率的视频sar回波仿真要求。
技术实现要素:
针对上述现有技术的问题,本发明的目的在于提供一种基于gpu的视频sar回波仿真并行实现方法,用gpu并行实现视频sar回波信号仿真的整个过程,具有高实时性和高效率的特点,特别在大场景、高帧率的视频sar回波仿真方面有显著优势。
本发明的技术思路是:结合改进的同心圆算法与gpu并行处理技术实现高效的视频sar回波仿真。采用统一计算设备架构(computeunifieddevicearchitecture,cuda)的异构编程模式,所述cuda异构编程包括cpu模块和gpu模块。用cpu做数据初始化和逻辑性事务管理,具体包括雷达系统参数设置、内存显存分配、场景数据初始化、cpu-gpu数据传输和gpu线程分配与核函数调用。用gpu做回波仿真算法处理,具体包括点目标参数计算、点目标回波信号模拟生成和附加调频项。
为达到上述目的,本发明采用如下技术方案予以实现。
一种基于gpu的视频sar回波仿真并行实现方法,所述方法基于作为主控制器的cpu和作为设备端的gpu;所述方法包括如下步骤:
步骤1,设置cpu内存为页锁定内存,且采用连续地址访问方式访问gpu显存;
步骤2,在所述cpu中设置雷达系统参数值,并将所述雷达系统参数值存储在cpu的内存中;进而将所述雷达系统参数值从cpu内存复制到gpu的常量存储器中;所述雷达系统参数值至少包含雷达的发射脉冲周期、雷达带宽、雷达斜距采样间隔、雷达方位向波束宽度以及雷达平台的高度以及运行速度;
步骤3,获取一幅sar图像数据作为视频sar回波仿真的原始场景图像数据,所述sar图像为二维灰度图像,且所述二维灰度图像中像素点的灰度值用于表征对应该像素点位置处的点目标的后向散射系数;并将所述原始场景图像数据存储于cpu内存中;进而将cpu内存中的原始场景图像数据经pcie接口传送到gpu显存中;
步骤4,设置第一核函数,并行计算所述原始场景图像数据中每个点目标的空间坐标及每个点目标的后向散射系数;
步骤5,设置第二核函数,并行计算每个方位采样时刻雷达平台的空间坐标以及每个方位采样时刻雷达平台与每个点目标的瞬时斜视角;
步骤6,设置第三核函数,对所有采样时刻的所有点目标进行分块,计算得到多个分块数据,对每个分块数据进行块内点目标的回波信号的叠加,得到每个分块数据内的点目标在所有方位采样时刻的一维距离像数据;
步骤7,设置第四核函数,对所有分块数据的一维距离像数据进行块间叠加,从而得到雷达所有方位时刻的初始回波信号;
步骤8,设置第五核函数,将所述雷达所有方位时刻的初始回波信号变换到频域,并在频域乘以调频因子后,再变换到时域进行线性调频处理,得到最终经过线性调频处理后的回波信号,并将所述最终经过线性调频处理后的回波信号作为视频sar回波信号;
步骤9,将所述视频sar回波信号从gpu显存复制到cpu内存。
本发明技术方案的特点和进一步的改进为:
(1)步骤3中,将cpu内存中的原始场景图像数据分成多个数据流,使一个数据流经pcie接口到gpu显存的传输过程与另一个数据流在gpu中的数据处理同时进行。
(2)在cpu端为第一核函数分配二维线程网格,所述二维线程网格由多个线程块组成,每个线程块由多个线程组成,且每个线程计算一个点目标的空间坐标和后向散射系数;步骤4具体包括如下子步骤:
(4a)获取原始场景图像数据中像素点(m,n),将像素点(m,n)作为原始场景图像中的一个对应点目标,按照所述雷达斜距采样间隔将所述点目标均匀分布在二维坐标平面上,得到该点目标在所述二维坐标平面上的坐标(xm,n,ym,n),进而得到该点目标的空间坐标(xm,n,ym,n,zm,n),其中,xm,n表示像素点(m,n)在x轴方向上的坐标,ym,n表示像素点在y轴方向上的坐标,zm,n表示像素点在z轴方向上的坐标,且zm,n=0;m=1,2,..,m,n=1,2,..,n,m为原始场景图像的长度,n为原始场景图像的宽度;
(4b)以原始场景图像数据中每个像素点(m,n)处的灰度值表征对应点目标的后向散射系数,并附加一个随机相位因子,得到该点目标的后向散射系数
(3)在cpu端为第二核函数分配二维线程网格,采用所述二维线程网格中对应方位采样时刻的线程计算每个方位采样时刻雷达平台的空间坐标,再采用所述二维线程网格中的每个线程计算一个瞬时斜视角;步骤5具体包括如下子步骤:
(5a)雷达平台以速度v沿x轴正方向即方位向做匀速直线运动,对雷达平台在方位向的运动时间以所述发射脉冲周期为间隔进行采样得到各方位采样时刻,并得到每个方位采样时刻雷达平台的空间坐标(xi,yi,zi),其中,下标i表示第i个方位采样时刻,且i大于零;根据第i个方位采样时刻雷达平台的空间坐标(xi,yi,zi)以及原始场景图像数据中第(m,n)个点目标的空间坐标(xm,n,ym,n,zm,n),计算得到第i个方位采样时刻雷达平台与第(m,n)个点目标的瞬时斜视角
(5b)遍历所有方位采样时刻,得到每个方位采样时刻雷达平台的空间坐标,从而计算得到每个方位采样时刻雷达平台与每个点目标的瞬时斜视角。
(4)在cpu端为所述第三核函数分配三维线程网格,步骤6具体包括如下子步骤:
(6a)对所有方位采样时刻的所有点目标进行分块,每个分块数据的大小不超过可用的gpu显存空间;
(6b)三维线程按照分块顺序串行计算每个分块数据内点目标对应的回波信号。
(5)子步骤(6b)具体包括如下子步骤:
每个分块数据内点目标对应的回波信号的计算过程如下,且各方位采样时刻的回波数据的计算是并行进行的:
(6b1)根据第i个方位采样时刻该分块数据中雷达平台与每个点目标的瞬时斜视角,判断该分块数据中每个点目标在第i个方位采样时刻是否在雷达方位向波束宽度范围内,若在第i个方位采样时刻雷达平台与某一点目标的瞬时斜视角小于或者等于所述雷达方位向波束宽度,则该点目标在雷达方位向波束宽度范围内;
(6b2)计算该分块数据中每个位于雷达方位向波束宽度范围内的点目标到雷达平台的斜距
(6b2)从而得到该分块数据中位于雷达方位向波束宽度范围内的每个点目标在第i个方位采样时刻对应的回波信号
其中,k为sinc插值点数,u表示插值点标号,且u=1,...,k,σ(m,n)表示点目标后向散射系数,b表示发射信号带宽,τ(u)表示快时间,c表示光速;
(6b3)将该分块数据中位于雷达方位向波束宽度范围内的所有点目标在第i个方位采样时刻对应的回波信号采用cuda原子加操作进行时域叠加得到该分块数据在第i个方位采样时刻的回波信号
与现有技术相比,本发明的有益效果是:(1)本发明对gpu显存进行合并访存,并通过合理分配线程块大小,增加每个线程拥有的寄存器和共享内存资源,充分发挥了gpu显存和片内高速存储器高传输带宽的优势,不仅实现了数据并行,还实现了指令级并行;(2)本发明利用流处理将数据传输和核函数执行分成多个流进行处理,利用流与流之间的并行执行来隐藏部分数据传输时间,解决了cpu-gpu的io传输瓶颈问题,有效节省了cpu-gpu数据传输时间;(3)本发明为回波模拟生成核函数分配三维线程网格,并行计算各方位时刻的回波信号,与传统各方位时刻回波信号串行计算相比,极大地提高了计算的并行度,有效节省了回波模拟生成的时间;(4)本发明采用线程外推的方法,对所有点目标分块进行回波模拟生成和叠加,分块大小根据显存空间自动调整,克服了因目标回波数据量过大而造成显存溢出的问题,满足了大场景高帧率视频sar回波仿真要求;(5)本发明利用原子加操作进行点目标回波信号的时域叠加,与传统回波信号的并行归约求和相比,减少了对显存空间和计算资源的开销,有效提高了回波信号叠加的实时性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
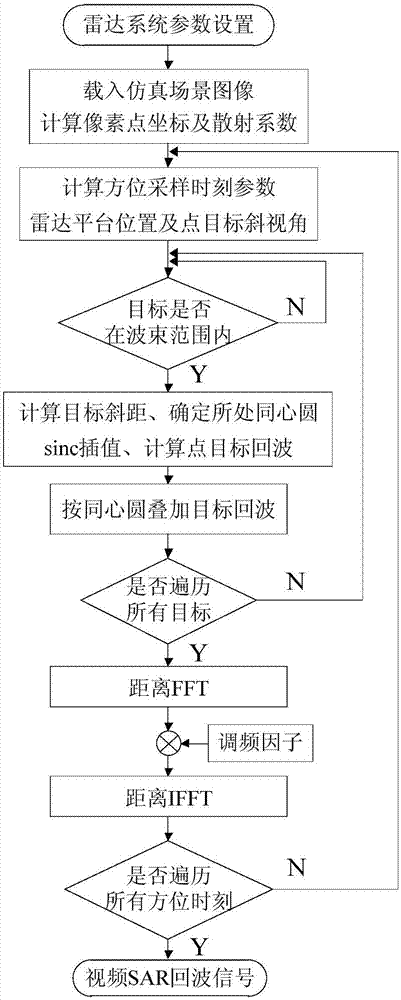
图1为本发明实施例提供的改进同心圆算法的流程示意图;
图2为本发明实施例提供的cuda异构编程的流程示意图;
图3为本发明实施例提供的合并访存与结构体数组替换示意图;
图4为本发明实施例提供的流处理的过程示意图;
图5为本发明实施例提供的雷达回波获取的几何示意图;
图6为本发明实施例提供的三维线程映射示意图;
图7为本发明实施例提供的点目标分块与回波时域叠加示意图;
图8为本发明实施例提供的视频sar回波仿真成像结果图;
图9为本发明实施例提供的视频sar回波仿真运行时间图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供一种基于gpu的视频sar回波仿真并行实现方法,结合改进的同心圆算法与gpu并行技术实现高效的视频sar回波仿真。采用cuda异构编程模式,所述cuda异构编程包括cpu模块和gpu模块。用cpu做数据初始化和逻辑性事务管理,具体包括雷达系统参数设置、内存显存分配、场景数据初始化、cpu-gpu数据传输和gpu线程分配与核函数调用。用gpu做回波仿真算法处理,具体包括点目标参数计算、点目标回波信号模拟生成和附加调频项。
具体的,所述改进同心圆算法的流程图如图1所示。
所述改进的同心圆算法是一种适用于分布式场景目标的快速时域回波仿真方法。在分布式场景目标中,斜距间隔小于斜距采样间隔的相邻点目标将落到同一距离单元上,形成许多以雷达相位中心为原点的同心圆,位于相同圆上的所有点目标的回波信号被累加到同一个距离单元上。当按每个同心圆累加点目标回波信号时,得到分布式场景目标的一维距离像。
所述cuda异构编程模型是将cpu作为主控制器(host),负责进行逻辑性强的事务管理和串行计算相关的工作;将gpu作为设备端(device),专注于执行高度线程化的并行处理任务,两者协调一致完成工作。所述cuda异构编程的流程图如图2所示,包括:
(1)所述雷达系统参数设置即先在cpu端设置雷达系统参数值,如发射脉冲周期、带宽、斜距采样间隔、方位向波束宽度及雷达平台速度与高度等。先将参数值存入内存,再将参数值传送给gpu端的常量存储器(constantmemory),以供gpu模拟回波信号时使用。
具体的,先在cpu端初始化雷达系统参数值,再利用cuda的常量复制函数将cpu内存的雷达系统参数值通过pci-e接口传送给gpu的常量存储器。由于雷达系统参数值在回波模拟计算中频繁使用,将系统参数值存储在常量存储器中,不仅可以保护参数值不被非法修改,而且常量存储器的访问速度快于显存,可以节省数据读取时间。
(2)所述内存显存分配即在cpu端使用页锁定内存,在gpu端对显存采用合并访存方式。
(2.1)页锁定内存分配:
在cuda中,cpu端的内存分为两种:可分页内存和页锁定内存。可分页内存即通过操作系统api分配的存储空间,内存中的数据可能被存入低速的虚拟内存中。页锁定内存始终不会分配低速的虚拟内存,能够保证数据存放在快速的物理内存中,并且能够通过dma加速与gpu的通信。
具体的,通过cuda的页锁定内存分配函数和释放函数为cpu端的数据分配页锁定内存,并在使用完成后释放页锁定内存。
(2.2)显存合并访问:
所述显存合并访问即连续地址的显存访问,且速度快于非连续地址的显存访问。合并访存一般用于对显存中数组的存取,对于简单数组,cuda显存分配函数已经确保数组在显存中连续对齐存放,对于结构体数组经常发生非连续访问,造成访存事件增加,访存时延增大。
具体的,合并访存与结构体数组替换如图3所示,通过将结构体数组替换为数组的结构体,或拆分为多个简单数组,以实现显存合并访问,进而节省数据存取时间,有效利用显存带宽。
(3)所述场景数据初始化即以一幅原始sar图像作为回波仿真的分布式场景目标,将场景图像数据由cpu内存传送到gpu显存,以供gpu模拟回波信号时使用。
改进的同心圆法以一幅原始sar图像作为分布式场景目标进行回波仿真,所述原始sar图像为二维灰度图像,以图像像素点的灰度值表征对应位置点目标的后向散射系数幅度值。
具体的,先在cpu端将读取的sar图像灰度矩阵存入页锁定内存,再利用cuda的数组复制函数将cpu内存的场景图像数据通过pci-e接口传送给gpu显存。
(4)所述cpu-gpu数据传输即通过cpu与gpu之间的pci-e接口将上述的雷达系统参数及场景图像数据由cpu端传送给gpu端进行运算,再将最终的视频sar回波数据由gpu端传回cpu端。为了减少cpu-gpu数据传输时延,采用流处理。
具体的,利用cuda的数组复制函数将cpu端页锁定内存的场景图像数据通过pci-e接口传送给gpu显存,最终将生成的视频sar回波数据以同样方式由gpu端传回到cpu端。
流处理将数据传入gpu、核函数执行和数据传出gpu的整个过程分成多个流进行处理,每个流顺序执行一系列操作,流与流之间异步并行执行。这样,一个流的cpu-gpu数据传输和另一个流的核函数执行可以同时进行,以隐藏部分cpu-gpu数据传输时间。从而解决了cpu-gpu的io传输瓶颈问题,有效地节省了数据传输时间。所述流处理的过程示意图如图4所示。
(5)所述gpu线程分配与核函数调用即根据gpu端核函数(kernel)所处理的数据模型,分配相适宜的gpu线程网格(grid),线程网格划分为一定数量的线程块(block),每个线程块又由一定数量的线程(thread)组成。调用核函数将线程网格中的各线程映射到数据模型中的各数据元素,使每个线程计算对应的一个数据元素。
在线程块中分配较少的线程。本实施例为每个线程块分配128个线程,在低设备占有率的情况下,增加了每个线程拥有的寄存器和共享内存资源,利用尽可能多的高速存储器来提高数据存取速度。
(5.1)kernel1函数实现:
该核函数用于并行计算分布式场景目标中各点目标的空间坐标及其后向散射系数。
将原始sar图像即二维灰度图像中各像素点(m,n)按所述雷达系统参数中的斜距采样间隔均匀分布在二维坐标平面上,计算得到各像素点的坐标即为分布式场景目标中各点目标的空间坐标(xm,n,ym,n,zm,n)。所述点目标的空间坐标不考虑起伏高度,即zm,n=0。
以原始sar图像即二维灰度图像中(m,n)处的像素点灰度值表征对应点目标的后向散射系数幅度值,并附加一个随机相位因子,得到该点目标的后向散射系数为
具体的,由于场景目标数据是二维结构体数组,可以在cpu端为kernel1函数分配二维线程网格,线程网格由一定数量的线程块组成,每个线程块又由一定数量的线程组成。调用kernel1函数将二维线程网格映射到场景二维结构体数组,使每个线程计算一个点目标的空间坐标和后向散射系数即场景二维结构体数组中的一个数据元素。
(5.2)kernel2函数实现:
该核函数用于并行计算各方位采样时刻雷达平台的空间坐标及雷达与各点目标的瞬时斜视角。
本发明实施例假设雷达工作在条带模式,雷达回波获取的几何关系如图5所示。雷达平台飞行高度为h,并以速度v沿x轴正方向即方位向做匀速直线运动,对雷达平台在方位向的运动时间以所述雷达系统参数中的发射脉冲周期为间隔进行采样得到各方位采样时刻i。计算雷达平台在各方位采样时刻的空间坐标(xi,yi,zi)。由各方位采样时刻雷达平台的空间坐标(xi,yi,zi)及分布式场景中各点目标的空间坐标(xm,n,ym,n,zm,n)可计算求得各方位采样时刻雷达平台与各点目标的瞬时斜视角
具体的,由于分布式场景中各点目标在各方位时刻的瞬时斜视角数据构成二维数组,其中一维表示方位时刻,另一维表示点目标数。可以在cpu端为kernel2函数分配二维线程网格,调用kernel2函数将二维线程网格映射到瞬时斜视角二维数组,先用其中一维对应方位采样时刻的线程计算各方位采样时刻雷达平台的空间坐标(xi,yi,zi)。再使二维线程网格中每个线程计算一个瞬时斜视角。
(5.3)kernel3和kernel4函数实现:
该核函数用于点目标回波模拟生成计算,具体包括判断点目标是否在方位向波束宽度范围内、计算雷达到点目标的斜距、点目标回波幅度sinc插值和点目标回波信号分块叠加。
改进的同心圆法在常规同心圆法基础上还对点目标回波信号的幅度进行sinc插值处理即得到插值点数个子回波信号,用所有子回波信号的幅度模拟点目标回波信号的脉冲波形,即所有子回波信号构成了一个点目标回波信号。
下面详细叙述视频sar回波模拟生成并行实现的整个过程:
由于视频sar回波数据是三维数据模型(sinc插值点数、点目标数和方位向点数),可以在cpu端为kernel3函数分配三维线程网格,调用kernel3函数将三维线程网格映射到回波三维数据模型,使每个线程计算三维数据中的一个元素即一个子回波数据。每个线程依次进行如下操作:根据点目标的瞬时斜视角是否满足θi,m,n≤θbw,判断点目标是否在方位向波束宽度范围内,其中θbw为所述雷达系统参数的方位向波束宽度;对位于方位向波束宽度范围内的点目标计算其到雷达的斜距
为防止gpu显存因点目标回波模拟计算时数据量过大而溢出,采用线程外推的方法,使有限线程可以遍历所有点目标,即对所有点目标按一定数量进行分块处理,分块确保数据大小不超过可用显存空间。由三维线程按分块顺序串行计算各分块的回波信号,并进行块内点目标回波信号叠加及块间回波信号叠加,最终得到所有方位时刻的回波信号。点目标分块与回波时域叠加如图7所示。
块内点目标回波信号叠加具体采用cuda原子加操作实现。如图7右下图所示,首先为块内各点目标分配插值点数大小的显存空间用于存储点目标的子回波信号,再用cuda原子加操作将点目标回波信号(子回波信号构成的数组)叠加到对应的距离采样点(距离单元)处,其中距离采样点数远大于sinc插值点数。各方位采样时刻都进行上述操作,从而实现各分块点目标回波信号的并行叠加。采用cuda原子加操作实现点目标回波信号叠加减少了显存空间占用和非必要计算开销,节省了点目标回波信号叠加的时间。调用kernel4函数,对上述各分块数据即点目标回波信号叠加后的二维矩阵(距离采样点数,方位采样点数)进行块间数据叠加,得到各方位采样时刻的回波信号(距离采样点数,方位采样点数)即初始回波信号。
(5.4)kernel5函数实现:
该核函数用于将(5.3)计算得到的初始回波信号由时域变换到频域,乘以调频因子再变换到时域,做线性调频处理,得到最终的经线性调频的回波信号即视频sar回波信号。
具体的,调用cuda的cufft函数即可将模拟生成的初始回波信号由时域快速变换到频域,乘以调频因子后再快速变换到时域,以得到最终的线性调频回波信号即视频sar回波信号。
(6)为上述各kernel函数所分配的线程网格由一定数量的线程块组织而成,每个线程块又由一定数量的线程组成。本实施例对各kernel函数的线程网格进行优化分配,即在线程块中分配较少的线程,本实施例为每个线程块分配128个线程,实现在低设备占有率的情况下,增加每个线程拥有的寄存器和共享内存资源,利用尽可能多的高速存储器来提高数据存取速度。高速存储器中共享内存带宽是显存的7.6倍,寄存器带宽是共享内存的6倍。
本发明的结果可由实测数据处理结果进一步说明:
图8为本发明实施例提供的由上述模拟生成的视频sar回波信号经成像算法处理后截取的视频sar单帧图像,所成图像质量良好。图9为本发明实施例提供的视频sar回波仿真的运行时间图,从回波仿真运行时间上看,基于gpu的视频sar回波仿真比基于cpu的视频sar回波仿真具有明显的速度提升,极大地缩短了仿真运行时间,验证了并行实现方案设计的可行性及有效性。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!