一种基于FPGA的后向投影快速成像架构设计方法与流程
本发明涉及雷达技术领域,特别涉及一种基于fpga的后向投影快速成像架构设计方法。
背景技术:
随着雷达成像技术的不断发展,雷达成像技术在军事和民用领域逐渐得到推广,例如应用在毫米波人体成像安检产品上。目前,雷达成像技术的主要算法分为频域成像算法和时域成像算法,其中,时域成像算法主要包括后向投影算法(backprojection,简称bp)。
由于bp算法的计算量大,为了满足用户对成像速度的需求,实现bp算法的硬件架构由传统的基于cpu的硬件架构逐渐发展成基于cpu+gpu的硬件架构。基于cpu+gpu的硬件架构利用了cpu的串行处理和gpu的并行处理相结合的方式来提高成像速度。然而,随着技术的不断发展,基于cpu+gpu的硬件架构已不能够满足用户对成像速度和运算功耗的要求。为此,需要提出一种成像速度更快、运算功耗更低的后向投影成像架构。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种一种基于fpga的后向投影快速成像架构设计方法,能够提高后向投影成像速度。
第一方面,根据本发明实施例的基于fpga的后向投影快速成像架构设计方法,以流水线的方式执行以下步骤:
获取成像网格信息以及经过距离向脉冲压缩处理的回波数据,并将所述回波数据载入片内缓存;
根据所述成像网格信息生成成像网格的像素点数据;
根据所述像素点数据进行雷达阵元的双基地距离运算,以获得双基地距离数据;
调用所述双基地距离数据和所述回波数据进行后向投影运算的并行处理,以获得成像中间数据;
对所述成像中间数据进行相干累加,以获得成像结果数据。
根据本发明实施例的基于fpga的后向投影快速成像架构设计方法,至少具有如下有益效果:
本发明实施例以流水线的方式执行各个步骤,有利于提高数据处理的效率,基于雷达阵元的双基地距离数据的收发分离特性,进行后向投影运算的并行处理,有利于提高后向投影成像速度。
根据本发明的一些实施例,在所述片内缓存划分出第一缓存区和第二缓存区,所述第一缓存区用于以乒乓存取的方式存取所述回波数据,所述第二缓存区用于以乒乓存取的方式存取所述成像中间数据。
根据本发明的一些实施例,所述第一缓存区按照雷达接收阵元和雷达发射阵元的二维象限进行物理地址编码的方式对所述回波数据进行存取。
根据本发明的一些实施例,所述第二缓存区按照交织地址的方式对所述成像中间数据进行存取。
根据本发明的一些实施例,采用多个级联的后向投影计算内核进行所述后向投影运算,所述后向投影计算内核包括多个并行级联的反投运算基本单元,所述双基地距离数据交叉存储在所述反投运算基本单元的缓存中。
根据本发明的一些实施例,每个所述反投运算基本单元包括第三缓存区和第四缓存区,位于同一列的所述反投运算基本单元的第三缓存区用于存储相同的接收方向单基地距离数据,位于同一行的所述反投运算基本单元的第四缓存区用于存储相同的发射方向单基地距离数据,其中,所述接收方向单基地距离数据用于表征双基地距离数据中雷达接收阵元到相应像素点之间的距离,所述发射方向单基地距离数据用于表征双基地距离数据中雷达发射阵元到相应像素点之间的距离。
根据本发明的一些实施例,每个所述反投运算基本单元还包括第五缓存区,所述第五缓存区用于存储所述后向投影运算所需的所述回波数据。
根据本发明的一些实施例,后向投影计算内核还包括级联输入单元和级联输出单元,所述级联输入单元用于接收并将所述双基地距离数据、所述回波数据和上一级所述后向投影计算内核输出的成像中间数据分别传递给第一级的所述反投运算基本单元,所述级联输出单元用于接收并将来自最后一级的所述反投运算基本单元的所述双基地距离数据、所述回波数据和成像中间数据传递给下一级的后向投影计算内核。
根据本发明的一些实施例,采用动态门控时钟的方式对所述后向投影计算内核进行功耗控制。
第二方面,根据本发明实施例的fpga架构,包括:高带宽存储单元;总线控制单元,用于获取成像网格信息以及经过距离向脉冲压缩的回波数据;内存管理单元,用于接收所述回波数据并将所述回波数据存储至所述高带宽存储单元;像素网格生成控制单元,用于接收所述成像网格信息,并根据所述成像网格信息生成像素点数据;双基地距离计算单元,用于根据所述像素点数据进行雷达阵元的双基地距离运算,以获得双基地距离数据;后向投影计算内核,用于调用所述双基地距离数据和所述回波数据进行后向投影运算的并行处理,以获得成像中间数据;所述内存管理单元还用于对所述成像中间数据进行相干累加,以获得成像结果数据。
根据本发明实施例的fpga架构,至少具有如下有益效果:
基于fpga的硬件架构的流水线设计更加灵活,而且fpga模块内部可以根据不同的功能需求配置相应的逻辑架构,在不同的fpga模块上实现相应的功能,功能专注,而且可以充分利用fpga模块灵活重构的特性分别对第一fpga模块和第二fpga模块的功能和架构进行维护和管理,两者相互配合工作且能够独立设计,有利于降低设计难度。
根据本发明的一些实施例,所述后向投影计算内核的数量为多个,多个所述后向投影计算内核级联连接,所述后向投影计算内核包括多个并行级联的反投运算基本单元,所述双基地距离数据交叉存储在所述反投运算基本单元的缓存中。
根据本发明的一些实施例,每个所述反投运算基本单元包括第三缓存区和第四缓存区,位于同一列的所述反投运算基本单元的第三缓存区用于存储相同的接收方向单基地距离数据,位于同一行的所述反投运算基本单元的第四缓存区用于存储相同的发射方向单基地距离数据,其中,所述接收方向单基地距离数据用于表征双基地距离数据中雷达接收阵元到相应像素点之间的距离,所述发射方向单基地距离数据用于表征双基地距离数据中雷达发射阵元到相应像素点之间的距离。
根据本发明的一些实施例,每个所述反投运算基本单元还包括第五缓存区,所述第五缓存区用于存储所述后向投影运算所需的所述回波数据。
根据本发明的一些实施例,后向投影计算内核还包括级联输入单元和级联输出单元,所述级联输入单元用于接收并将所述双基地距离数据、所述回波数据和上一级所述后向投影计算内核输出的成像中间数据分别传递给第一级的所述反投运算基本单元,所述级联输出单元用于接收并将来自最后一级的所述反投运算基本单元的所述双基地距离数据、所述回波数据和成像中间数据传递给下一级的后向投影计算内核。
第三方面,根据本发明实施例的后向投影成像架构,包括:第一fpga模块,用于获取外部输入的回波采样数据,并对所述回波采样数据进行距离向脉冲压缩处理,以获得回波数据,以及用于从所述回波数据中提取成像网格信息;第二fpga模块,通过芯片间互连总线与所述第一fpga模块连接,所述第二fpga模块用于接收所述回波数据和所述成像网格信息,并根据所述回波数据和所述成像网格信息进行后向投影成像处理,以获得成像结果数据,以及用于将所述成像数据返回至所述第一fpga模块,用以进行所述成像结果数据的对外输出。
根据本发明的一些实施例,所述第二fpga模块配置有上述的fpga架构。
第四方面,根据本发明实施例的设备,包括上述的后向投影成像架构。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
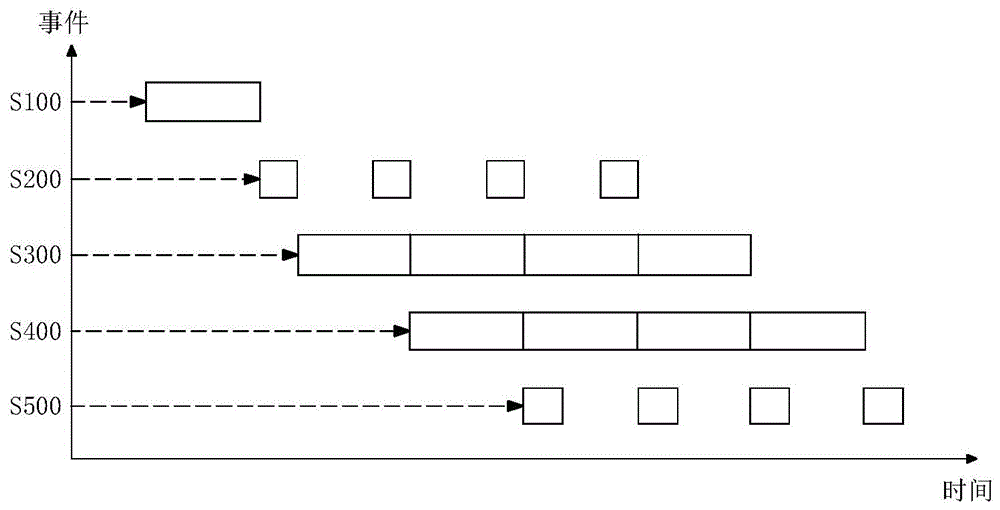
图1为本发明实施例的基于fpga的后向投影快速成像架构设计方法的流程图;
图2为本发明实施例的基于fpga的后向投影快速成像架构设计方法中的像素网格与收发距离的逻辑结构示意图;
图3为本发明实施例的基于fpga的后向投影快速成像架构设计方法中片内缓存的逻辑结构示意图;
图4a、图4b分别为本发明实施例的基于fpga的后向投影快速成像架构设计方法的回波数据的数据结构和成像中间结果的数据结构;
图5为本发明实施例的基于fpga的后向投影快速成像架构设计方法的后向投影计算内核的逻辑结构示意图;
图6为图5中后向投影计算内核的反投运算基本单元的逻辑结构示意图;
图7为本发明实施例的基于fpga的后向投影快速成像架构设计方法中动态门控时钟的逻辑关系图;
图8为本发明实施例的后向投影成像架构的逻辑结构示意图;
图9为本发明实施例的fpga架构的逻辑结构示意图;
图10为本发明实施例的成像中间数据累加输出的逻辑关系图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
实施例1
本实施例公开了一种基于fpga的后向投影快速成像架构设计方法,该方法主要基于fpga模块的流水线处理技术以及雷达阵元的双基地距离数据的收发分离特性。其中,本实施例以mimo雷达(多输入多输出雷达)为例进行说明。mimo雷达通常包括多个发射阵元和多个接收阵元,当然,雷达阵元也可以收发共用。mimo雷达允许在每个雷达阵元上同时传输不同的波形,各发射阵元发射不同的信号波形,各个波形的发射信号经过目标对象反射后被多个接收阵元采样接收,从而得到回波采样数据。而后向投影算法的基本原理是将雷达的回波采样数据反向投影到成像区域的每个像素点,像素点的值可通过计算雷达回波在雷达阵元和像素点之间距离的延时累加来确定。后向投影算法的主要流程包括距离向处理和方位向处理,而距离向处理主要是对回波采样数据进行基于傅里叶变换和傅里叶逆变换的距离向脉冲压缩处理,以获得回波数据。对于本领域技术人员来说,该步骤的处理方法是较为公知的,本实施例不再累述。为了提高数据处理效率,该步骤可以在预处理单元(preprocessunit,ppu)中进行预处理。需要说明的是,后续的方位向处理需要用到提取自回波数据的成像网格信息,其中,成像网格信息包括成像区域的网格尺寸、网格间距和网格坐标等。为了提高数据处理效率,从回波数据中提取成像网格信息这一步骤可以在预处理单元中完成。
请参照图1,本实施例公开了一种基于fpga的后向投影快速成像架构设计方法,以流水线的方式执行以下步骤s100、步骤s200、步骤s300、步骤s400和步骤s500。需要说明的是,在本发明实施例的描述中,对方法步骤的连续标号是为了方便审查和理解,结合本发明的整体技术方案以及各个步骤之间的逻辑关系,调整步骤之间的实施顺序并不会影响本发明技术方案所达到的技术效果。下面对步骤s100、步骤s200、步骤s300、步骤s400和步骤s500进行详细阐述。
s100、获取成像网格信息以及经过距离向脉冲压缩处理的回波数据,并将回波数据载入片内缓存。
本实施例的基于fpga的后向投影快速成像架构设计方法在后向投影处理单元(backprojectionunit,bpu)中完成,通过不同单元的分工合作,可以使单元的功能更加集中。在本实施例中,预处理单元和后向投影处理单元均采用fpga模块实现。fpga模块由逻辑单元、ram、乘法器等硬件资源组成,通过将这些硬件资源合理组织,可实现用于进行数据存储的片内缓存。相比于不同fpga模块之间的数据传输效率,同一fpga模块内不同单元之间的数据传输效率更高,因此,将回波数据载入片内缓存,可以便于后续的数据处理中调用相应的回波数据,有利于提高运算速度。
s200、根据成像网格信息生成成像网格的像素点数据。
请参照图2,在进行三维成像时,通过雷达阵面构造一个空间三维像素网格,其中,像素网格以雷达阵面作为z维度的起始,以雷达阵面的物理中心点作为x、y维度的坐标中心点,像素网格与雷达阵面在全局统一坐标系下进行构建并进行后续的雷达回波的双基地距离运算。
s300、根据像素点数据进行雷达阵元的双基地距离运算,以获得双基地距离数据。
对于成像空间中某一像素点而言,雷达波行驶的距离之和即为雷达收、发阵元与该像素点之间的距离之和,该距离之和满足公式:
rb=rt+rr(1)
式中,rt为双基地距离数据中雷达发射阵元到相应像素点之间的距离,rr为双基地距离数据中雷达接收阵元到相应像素点之间的距离,x、y、z分别为像素点在x、y、z维度的坐标值,xt、yt分别为雷达发射阵元在x、y维度的坐标值,xr、yr分别为雷达接收阵元在x、y维度的坐标值。
s400、调用双基地距离数据和回波数据进行后向投影运算的并行处理,以获得成像中间数据。
对于三维成像而言,在(x,y,z)域等间隔划分三维像素网格,将这些像素网格的极坐标分别记为{xp|p=1,2,...,p}、{yq|q=1,2,...,q}和{zu|u=1,2,...,u}。将补偿完阵元位置误差和通道间延时误差后的mimo雷达一维距离压缩后回波信号在方位时域-距离频域的表达式记为sc=(fr,m,n),则后向投影算法的基本原理在频域可以表示为:
式中,fr为距离向频率,m为雷达发射阵元的数量,n为雷达接收阵元的数量。考虑到实际操作时成像场景和距离向频率轴都会被离散化,上式可以退化为三级求和的形式,则后向投影处理得到的三维复图像为:
进一步的,记
其中,
式(7)为典型反傅里叶级数的定义式,考虑到其频谱恰好为有限基带谱,该部分的计算可利用ifft近似计算,则公式(6)可以写成如下形式:
其中,η表示插值倍数,sbase(h,m,n),h=0,1,...,η·k表示sc(fk,m,n)序列在k这一维度的ifft结果,该结果包含在步骤s100的回波数据中。
在公式(5)至(8)中,雷达波行驶的距离之和rb(m,n,xp,yq,zu)的计算方式可参照公式(1)至(3)。对于某一像素点(xp,yq,zu)而言,i0(p,q,u)可简单理解为以m,n为变量的求和
表1
表1中,m为雷达发射阵元的数量,n为雷达接收阵元的数量。从表1可知,当n取不同的值时,表示对第n个雷达接收阵元对应的数据,例如双基地距离数据和回波数据进行累加。对于m=1的一列而言,
s500、对成像中间数据进行相干累加,以获得成像结果数据。
从表1可知,每一列计算得到的成像中间数据是以雷达接收阵元的数据为变量的求和,而要获得成像结果数据,还需要对成像中间数据进行相干累加。
本发明实施例以流水线的方式执行步骤s100至s500,可以在时间上实现准并行运作,有利于提高数据处理的效率。从步骤s300和s400的原理可知,本发明实施例基于雷达阵元的双基地距离数据的收发分离特性,进行后向投影运算的并行处理,有利于提高后向投影成像速度。与现有的cpu+gpu的串行+并行的处理方式相比,本发明实施例采用流水线并行的方式可以更好地提高后向投影的成像速度。
请参照图3,为了提升片内缓存的使用效率,在片内缓存划分出第一缓存区和第二缓存区,第一缓存区用于以乒乓存取的方式存取回波数据,第二缓存区用于以乒乓存取的方式存取成像中间数据。乒乓存取是在数据存取过程中按节拍进行存储和读取数据的配合切换,将经过缓冲的数据流不停地送到目标处理模块中进行处理。在数据存取过程中,数据流均是连续不断的,因此,乒乓存取数据的方式在流水线式操作过程中,可以实现数据的无缝缓冲处理。而且本实施例为回波数据和成像中间数据单独划分相应的缓存区,可以在物理空间上实现不同数据存取的相互独立,以及在时间维度上实现不同数据存取的并行处理,极大地提升了片内缓存的使用效率。
在步骤s400的后向投影运算的过程中,需要调用相应的雷达接收阵元和雷达发射阵元的回波数据。从表1的格式可知,数据的运算格式是以m,n为变量的二维矩阵。因此,请参照图4a,为了便于对回波数据进行调用和管理,第一缓存区按照雷达接收阵元和雷达发射阵元的二维象限进行物理地址编码的方式对回波数据进行存取。当进行回波数据调用时,可以根据内存首地址、雷达发射阵元的编号、地址偏移量和雷达接收阵元编号,对相应雷达阵元的回波数据进行内存地址计算和数据调用。
同理,请参照图4b,第二缓存区按照交织地址的方式对成像中间数据进行存取,图4b中示出了在z0、z1、...、zn平面内,不同像素点对应的成像中间数据以交织地址的方式进行存储,便于对成像中间数据进行存储、调用和管理。
请参照图5,在上述步骤s400中,为了进一步提高后向投影成像效率,采用多个级联的后向投影计算内核(kernel)进行后向投影运算,后向投影计算内核包括多个并行级联的反投运算基本单元(bpcore),双基地距离数据交叉存储在反投运算基本单元的缓存中。请参照图5,反投运算基本单元是后向投影计算内核的基本运算单元,请参照图5和表1,多个并行级联的反投运算基本单元用于对同一像素点的雷达发射阵元和雷达接收阵元的数据进行级联累加的并行处理,减少了数据重复累加的冗余操作,达到了数据级联进位累加的流水并行操作目标。通过多个级联的后向投影计算内核对不同像素点的数据进行级联进位流水处理,简化了数据之间的进位累加冗余操作,有利于提高数据处理效率,从而提升后向投影成像速度。后向投影计算内核的数量可根据实际需求和相应的硬件条件来进行扩展或删减,实现后向投影计算内核的灵活裁剪,有利于提高应用的灵活性。
请参照图5和图6,在一个具体的实施例中,每个反投运算基本单元包括第三缓存区和第四缓存区,位于同一列的反投运算基本单元的第三缓存区用于存储相同的接收方向单基地距离数据,位于同一行的反投运算基本单元的第四缓存区用于存储相同的发射方向单基地距离数据,其中,接收方向单基地距离数据用于表征双基地距离数据中雷达接收阵元到相应像素点之间的距离,发射方向单基地距离数据用于表征双基地距离数据中雷达发射阵元到相应像素点之间的距离。通过将双基地距离数据交叉存储在反投运算基本单元中,可以实现双基地距离数据的交叉复用。此外,在步骤s300的双基地距离运算中,每计算一次像素点对应的雷达阵元的双基地距离数据时,只需计算每个反投运算基本单元所需的接收方向单基地距离数据和发射方向单基地距离数据,而无需重复计算,简化了步骤s300的双基地距离运算操作,有利于提高数据处理效率,从而提升后向投影成像速度。
请继续参照图6,每个反投运算基本单元还包括第五缓存区,第五缓存区用于存储后向投影运算所需的回波数据,例如在表1中,当n的取值不同时,从片内缓存中读取相应雷达接收阵元的回波数据,并存储在对应的反投运算基本单元的第五缓存区内。在进行运算时,每个反投运算基本单元内的反投运算单元从第五缓存区内调用数据,用以对像素点的雷达发射阵元和雷达接收阵元的数据进行累加处理,而无需反复从片内缓存中读取数据,有利于提高数据调用的效率。
请参照图5,后向投影计算内核还包括级联输入单元和级联输出单元,级联输入单元用于接收并将双基地距离数据、回波数据和上一级后向投影计算内核输出的成像中间数据分别传递给第一级的反投运算基本单元,级联输出单元用于接收并将来自最后一级的反投运算基本单元的双基地距离数据、回波数据和成像中间数据传递给下一级的后向投影计算内核,反投运算基本单元之间的数据通过广播形式级联传输,例如,每个数据携带有广播目的id,根据广播目的id将数据传输到相应的反投运算基本单元。需要说明的是,第一级的后向投影计算内核从片内缓存中读取相应的回波数据,最后一级的后向投影计算内核将运算得到的成像中间数据进行累加后存储至片内缓存中。
请参照图7,图7中示出了时钟源(clkroot)、门控时钟单元(clkgating)、后向投影计算内核(kernel)和待机控制单元(standbyctrl)的逻辑关系。当没有回波采样数据输入至预处理单元时,待机控制单元向门控时钟单元提供停止信号,以截断时钟源与后向投影计算内核之间的时钟信号,后向投影计算内核停止工作,可以降低功耗;当预处理单元接收到回波采样数据或后向投影处理单元接收到回波数据时,待机控制单元向门控时钟单元提供使能信号,以控制门控时钟单元动作,从而使时钟源向后向投影计算内核提供时钟信号,后向投影计算内核根据时钟信号进行工作。本实施例采用动态门控时钟的方式对后向投影计算内核进行功耗控制,有利于降低功耗。
实施例2
请参照图8,基于实施例1的基于fpga的后向投影快速成像架构设计方法,本实施例提供一种后向投影成像架构,包括第一fpga模块和第二fpga模块,第一fpga模块用于获取外部输入的回波采样数据,并对回波采样数据进行距离向脉冲压缩处理,以获得回波数据,以及用于从回波数据中提取成像网格信息,第二fpga模块通过芯片间互连总线(serialrapidio,srio)与第一fpga模块连接,第二fpga模块用于接收回波数据和成像网格信息,并根据回波数据和成像网格信息进行后向投影成像处理,以获得成像结果数据,以及用于将成像数据返回至第一fpga模块,用以进行成像结果数据的对外输出。与cpu+gpu的硬件架构相比,基于fpga模块的硬件架构的流水线设计更加灵活,而且fpga模块内部可以根据不同的功能需求配置相应的逻辑架构,其中,第一fpga模块对外部输入的回波采样数据进行预处理,第二fpga模块对回波数据进行后向投影成像处理,在不同的fpga模块上实现相应的功能,功能专注,而且可以充分利用fpga模块灵活重构的特性分别对第一fpga模块和第二fpga模块的功能和架构进行设计、维护和管理,两者相互配合工作且能够独立设计,有利于降低设计难度。
请参照图9,为了提高第二fpga模块的数据处理效率,第二fpga模块可配置一种fpga架构,该fpga架构包括总线控制器(sriox4controller)、内存管理单元(mmu)、高带宽存储单元(hbm)、像素网格生成控制单元(voxel_grid_gen)、双基地距离计算单元(range_gen)和后向投影计算内核(kernel)。
本实施例中,总线控制器、内存管理单元、高带宽存储单元、像素网格生成控制单元、双基地距离计算单元和后向投影计算内核采用流水线方式进行数据运算,数据运算的过程可参照实施例1。其中,总线控制单元通过芯片间互连总线与第一fpga模块进行数据交互,总线控制单元用于获取成像网格信息以及经过距离向脉冲压缩的回波数据;内存管理单元用于接收回波数据并将回波数据存储至高带宽存储单元;像素网格生成控制单元用于接收成像网格信息,并根据成像网格信息生成像素点数据;双基地距离计算单元用于根据像素点数据进行雷达阵元的双基地距离运算,以获得双基地距离数据;后向投影计算内核用于调用双基地距离数据和回波数据进行后向投影运算的并行处理,以获得成像中间数据;内存管理单元还用于对成像中间数据进行相干累加,以获得成像结果数据;总线控制单元还用于将成像结果数据发送给第一fpga模块。
请参照图2,像素网格生成控制单元设置有用于缓存成像网格信息的内存区。像素网格生成控制单元在进行三维成像时,通过雷达阵面构造一个空间三维像素网格,其中,像素网格以雷达阵面作为z维度的起始,以阵面物理中心点作为x、y维度的坐标中心点,像素网格与雷达阵面在全局统一坐标系下进行构建并进行后续的雷达回波的双基地距离运算,像素网格生成控制单元生成相应的像素点数据,并将像素点数据传递给双基地距离计算单元。双基地距离计算单元根据像素点数据进行雷达阵元的双基地距离运算,而双基地距离的计算方法可参照实施例1,本实施例不再累述。
请参照图3,高带宽存储单元设置有第一缓存区和第二缓存区,第一缓存区用于以乒乓存取的方式存取回波数据,第二缓存区用于以乒乓存取的方式存取成像中间数据。乒乓存取是在数据存取过程中按节拍进行存储和读取数据的配合切换,将经过缓冲的数据流不停地送到目标处理模块中进行处理。在数据存取过程中,数据流均是连续不断的,因此,乒乓存取数据的方式在流水线式操作过程中,可以实现数据的无缝缓冲处理。而且高带宽存储单元为回波数据和成像中间数据单独设置相应的缓存区,可以在物理空间上实现不同数据存取的相互独立,以及在时间维度上实现不同数据存取的并行处理,极大地提升了高带宽存储单元的使用效率。
请参照图4a,第一缓存区按照雷达接收阵元和雷达发射阵元的二维象限进行物理地址编码的方式对回波数据进行存取。当进行回波数据调用时,内存管理单元可以根据内存首地址、雷达发射阵元的编号、地址偏移量和雷达接收阵元编号,对相应雷达阵元的回波数据进行内存地址计算和数据调用。
同理,请参照图4b,第二缓存区按照交织地址的方式对成像中间数据进行存取,图4b中示出了在z0、z1、...、zn平面内,不同像素点对应的成像中间数据以交织地址的方式进行存储,便于对成像中间数据进行存储、调用和管理。基于第一缓存区和第二缓存区的设计,内存管理单元对回波数据的调用以及对成像中间数据的存储可以实现物理空间和时间维度上的并行。
请参照图5,在本实施例中,后向投影计算内核的数量为多个,多个后向投影计算内核级联连接,每个后向投影计算内核包括多个并行级联的反投运算基本单元(bpcore),来自双基地距离计算单元的双基地距离数据交叉存储在反投运算基本单元的缓存中。请参照图5,反投运算基本单元是后向投影计算内核的基本运算单元,参照图5和表1,多个并行级联的反投运算基本单元用于对同一像素点的雷达发射阵元和雷达接收阵元的数据进行级联累加的并行处理,减少了数据重复累加的冗余操作,达到了数据级联进位累加的流水并行操作目标。多个级联的后向投影计算内核对不同像素点的数据进行级联进位流水处理,简化了数据之间的进位累加冗余操作,有利于提高数据处理效率,从而提升后向投影成像速度。后向投影计算内核的数量可根据实际需求和相应的硬件条件来进行扩展或删减,实现后向投影计算内核的灵活裁剪,有利于提高应用的灵活性。
请参照图5和图6,在本实施例中,每个反投运算基本单元包括第三缓存区和第四缓存区,位于同一列的反投运算基本单元的第三缓存区用于存储相同的接收方向单基地距离数据,位于同一行的反投运算基本单元的第四缓存区用于存储相同的发射方向单基地距离数据,其中,接收方向单基地距离数据用于表征双基地距离数据中雷达接收阵元到相应像素点之间的距离,发射方向单基地距离数据用于表征双基地距离数据中雷达发射阵元到相应像素点之间的距离。通过将双基地距离数据交叉存储在反投运算基本单元中,可以实现双基地距离数据的交叉复用。此外,双基地距离运算中,每计算一次像素点对应的雷达阵元的双基地距离数据时,只需计算每个反投运算基本单元所需的接收方向单基地距离数据和发射方向单基地距离数据,而无需重复计算,简化了双基地距离运算操作,有利于提高数据处理效率,从而提升后向投影成像速度。
请继续参照图6,每个反投运算基本单元还包括第五缓存区,第五缓存区用于存储后向投影运算所需的回波数据,例如在表1中,当n的取值不同时,从高带宽存储单元中读取相应雷达接收阵元的回波数据,并存储在对应的反投运算基本单元的第五缓存区内。在进行运算时,每个反投运算基本单元内的反投运算单元从第五缓存区内调用数据,用以对像素点的雷达发射阵元和雷达接收阵元的数据进行累加处理,而无需反复从高带宽存储单元中读取数据,有利于提高数据调用的效率。
请参照图5,后向投影计算内核还包括级联输入单元和级联输出单元,级联输入单元用于接收并将双基地距离数据、回波数据和上一级后向投影计算内核输出的成像中间数据分别传递给第一级的反投运算基本单元,级联输出单元用于接收并将来自最后一级的反投运算基本单元的双基地距离数据、回波数据和成像中间数据传递给下一级的后向投影计算内核,反投运算基本单元之间的数据通过广播形式级联传输,例如,每个数据携带有广播目的id,根据广播目的id将数据传输到相应的反投运算基本单元。需要说明的是,第一级的后向投影计算内核从高带宽存储单元中读取相应的回波数据,最后一级的后向投影计算内核将运算得到的成像中间数据输出至内存管理单元,经过内存管理单元的累加处理后存储至高带宽存储单元中。
请参照图7,后向投影计算内核设置有时钟信号输入端,后向投影计算内核的时钟信号输入端依次连接有门控时钟单元和时钟源,门控时钟单元的使能端连接有待机控制单元。当没有回波采样数据输入至第一fpga模块时,待机控制单元向门控时钟单元提供停止信号,以截断时钟源与后向投影计算内核之间的时钟信号,后向投影计算内核停止工作,可以降低功耗;当第一fpga模块接收到回波采样数据或第二fpga模块接收到回波数据时,待机控制单元向门控时钟单元提供使能信号,以控制门控时钟单元动作,从而使时钟源向后向投影计算内核提供时钟信号,后向投影计算内核根据时钟信号进行工作。本实施例采用动态门控时钟的方式对后向投影计算内核进行功耗控制,有利于降低功耗。
在本实施例中,内存管理单元还用于对成像中间数据进行相干累加。请参照图10,图10中示出了相干累加的功能模块的逻辑关系,其中,累加器的具体计算方法可参照实施例1,本实施例不再累述,从图10中可知,本实施例通过内存管理单元对成像中间数据的传输和累加进行并行处理,可以提高数据处理效率,从而提升后向投影成像速度。
实施例3
本实施例以xilinx(赛灵思)的ultrascaleplus系列fpga产品为例对实施例2的后向投影成像架构进行验证。其中,第一fpga模块和第二fpga模块均采用型号vu37p的fpga芯片。该型号的fpga芯片内部集成了16个后向投影计算内核(kernel),等价1536个高并发反投运算基本单元(bpcore),该型号的fpga芯片的工作主频为420mhz,拥有2800万个逻辑单元,配置有8gb的高带宽存储单元。
在本实施例中,后向投影成像的计算时间通过公式(9)得到,其中公式(9)中的变量含义参照表3。
表3
在本实施例中,算力评估可根据公式(10)进行计算,公式(10)中的变量说明参见表4。
tops=(kernel_num·kernel_pe·complex_mult_ops+accmulate_ops)·fmax(10)
表4
本实施例对第二fpga模块在不同工作模式下的功耗进行统计,详见表5。
表5
在本实施例的fpga硬件架构下,第二fpga模块的后向投影成像的计算时间为630ms,算力达到int16tops10.3,在待机状态下的功耗降至30w,可以达到快速成像和低功耗的效果。
实施例4
本实施例公开一种设备,包括实施例2的后向投影成像架构。基于fpga模块的硬件架构的流水线设计更加灵活,而且fpga模块内部可以根据不同的功能需求配置相应的逻辑架构,在不同的fpga模块上实现相应的功能,功能专注,而且可以充分利用fpga模块灵活重构的特性分别对第一fpga模块和第二fpga模块的功能和架构进行维护和管理,两者相互配合工作且能够独立设计,有利于降低设计难度。
上面结合附图对本发明实施例作了详细说明,但是本发明不限于上述实施例,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!