用于借助于仿真模块的计算机辅助的设施控制优化的方法与流程
在控制复杂的动态系统(诸如燃气轮机、风力涡轮机或者其它的技术设施或者系统)时,一般来说值得期望的是:关于预先给定的标准来优化系统特性。这样,例如在燃气轮机的情况下,一般来说力求改进效率、效果和/或燃烧动力学,以及降低废气排放、燃烧室噪声和/或磨损。
背景技术:
复杂的动态系统通常具有多个相互作用的控制参数。因此,为了控制该动态系统,影响系统特性的多个可能的控制行动供系统控制装置支配。在此,不同的控制行动可以以非常复杂的方式、尤其是也相反地相互作用。这样,对第一控制标准有积极效果的控制行动可能对第二控制标准有消极作用。此外,相同的控制行动根据系统状态而可能积极地或者消极地起作用。
从现有技术中已知计算机辅助的控制装置或者调节器,所述控制装置或者调节器特定地适用于遵循或者优化预先给定的控制标准。然而,这样的控制标准一般来说根据动态系统的应用情况而有区别。这样,例如可以针对不同的国家中的发电厂规定废气排放的不同的极限值。在第一国家中,低的废气排放相对于其它的控制标准可能优先,而在第二国家中,低的磨损和低的维护成本可能优先。一般来说,多个相互影响的控制标准应以适当的方式来权衡,以便针对当前的情况实现最优的控制。
为了优化预先给定的控制标准,流行的控制通常使用机器学习的技术。这样,例如可以针对如下方面训练神经网络:关于一个或多个预先给定的控制标准来优化对动态系统的控制。然而,对神经网络的训练一般来说是比较耗时的。如果改变控制标准,那么常常持续比较长时间直至进行学习的神经网络适应于经改变的控制标准。因而,对适用于所力求的目的或者新的情况的控制标准进行优化常常是非常耗时的。
技术实现要素:
本发明的任务是提供一种用于对技术系统进行计算机辅助的控制优化的设备和方法,所述设备和方法允许对控制标准进行更灵活的并且更快速的优化。
该任务通过一种具有专利权利要求1的特征的交互式辅助系统、通过一种具有专利权利要求9的特征的方法以及通过具有专利权利要求13的特征的计算机程序产品来解决。
按照本发明,为了对技术系统进行计算机辅助的控制优化,设置一种交互式辅助系统以及一种相对应的方法。该技术系统例如可以是燃气轮机、风力涡轮机、发电厂或者另一技术设施或者另一技术系统。输入终端用于读入说明了该技术系统的第一系统状态的至少一个状态参数,以及用于读入至少一个调整参数,所述至少一个调整参数用于设立适用于训练神经网络的报酬函数(Belohnungsfunktion)。这样的报酬函数常常也被称作Reward-Function。仿真模块用于对在技术系统上执行从第一系统状态出发的行动序列进行仿真,以及用于预测技术系统的从中最终得到的后续状态。此外,还设置有与输入终端和仿真模块耦合的优化模块。该优化模块用于依据调整参数设立报酬函数、用于生成多个针对第一系统状态的行动序列、用于将所述行动序列传送给仿真模块以及用于接收从中最终得到的后续状态。此外,该优化模块还用于借助于所设立的报酬函数来确定对于最终得到的后续状态所要期望的报酬,以及用于确定进行报酬优化的行动序列。为了输出从进行报酬优化的行动序列最终得到的系统状态而设置有输出终端。
为了分别预先给定的情况和/或为了分别力求的目的,本发明允许快速地交互式地优化或改进针对技术系统的控制标准。通过适当地设立适用于神经网络的训练的报酬函数,所述控制标准可以以灵活的方式由用户在输入终端上来修改。这些修改的作用可以通过用户在输出终端上直接检测。据此,用户接着可以进行报酬函数或控制标准的其它适配,而且这样可以连续地(sukzessiv)交互式地优化所述报酬函数或所述控制标准。将报酬函数用于优化控制标准是有利的,因为报酬函数根据其交互式优化而可以直接被用于训练技术系统的基于神经网络的控制。
仿真模块的应用允许时间有利地并且成本有利地确定技术系统的由行动序列造成的后续状态。这尤其是也适用于如下这种行动序列,所述行动序列在真正的技术系统上只能用高的耗费来执行。此外,在足够的计算能力的前提下,仿真模块常常可以比真正的技术系统更快地提供后续状态,而且这样可以缩短优化过程。
本发明的有利的实施方式和扩展方案在从属权利要求中被说明。
根据本发明的一种有利的实施方式,所述仿真模块可以被设立用于优化包括连续的调节参量的行动序列。这种连续的调节参量(诸如在燃气轮机中的气体输送)在很多技术系统中都是可控制的。
此外,在优化模块中可以实施随机的和/或非凸的优化方法来确定进行报酬优化的行动序列。随机的优化方法也可以成功地被应用到高维的和/或非线性的优化问题上。如果不同的优化参数彼此相关,那么非凸的优化方法是有利的。
优选地,作为优化方法可以实施粒子群优化、遗传优化方法、模拟退火方法(Simulated-Annealing-Verfahren)和/或随机梯度方法。
此外,该仿真模块还可以被设立用于处理技术系统的传感器数据。以这种方式被设立的仿真模块也可以在真正的技术系统上用真正的传感器数据来运行而且关于该仿真模块的仿真忠实度(Simulationstreue)来优化。
此外,在仿真模块中可以实施神经网络、支持向量机(Support-Vector-Machine)、高斯过程模型和/或物理模型来仿真该技术系统。
根据一种有利的实施方式,神经网络可以被实施为递归神经网络。这种递归神经网络允许以高效的方式识别与时间相关的模式。
此外,该神经网络已经可以针对该技术系统来预先训练。
根据另一种实施方式,进行报酬优化的行动序列可以在输出终端上输出。
优选地,最终得到的系统状态的、进行报酬优化的行动序列的和/或报酬函数的返回值的时间变化过程可以被输出在输出终端上。这允许由用户来迅速地判断优化结果。尤其是,用户可以直接比较关于当前被调整的控制标准最优的系统特性在何种程度上对应于用户所期望的系统特性。
此外,还可以通过输出终端来输出报酬函数和/或状态参数的其它的变体来在输入终端上进行在用户侧的选择。尤其是可以输出根据预先给定的标准来实现的从可能的报酬函数和/或状态参数中的预先选择。
附图说明
随后依据附图来进一步解释本发明的一个实施例。
附图以示意图示出按照本发明的交互式辅助系统。
具体实施方式
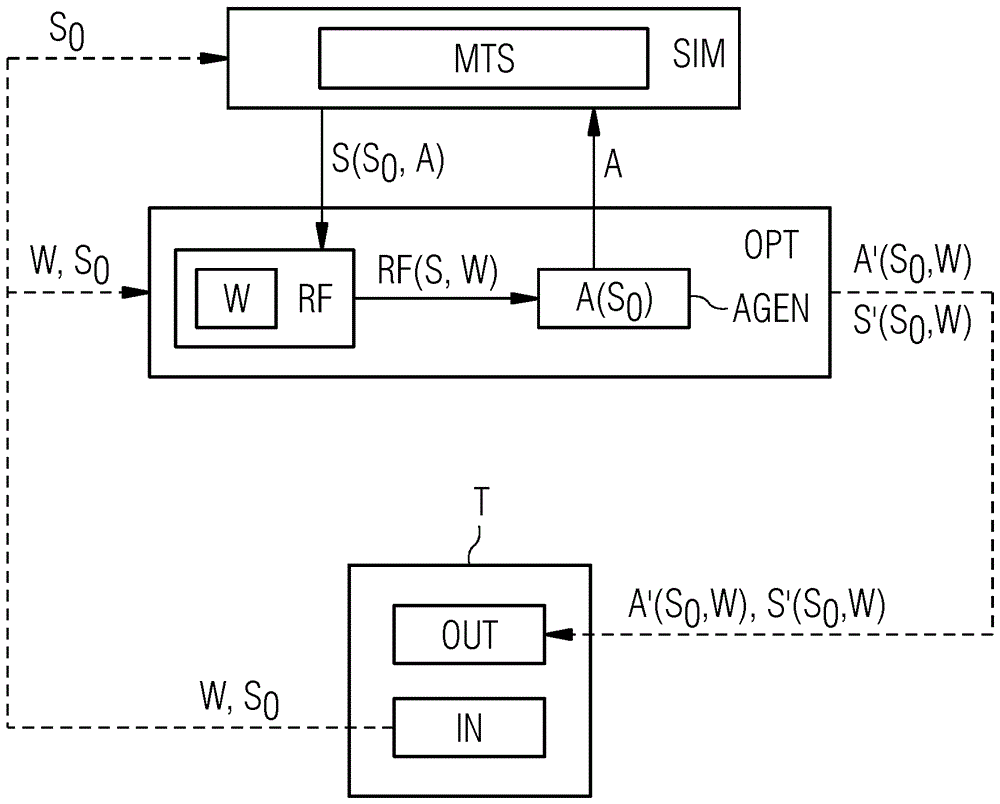
在该附图中,示意性地示出了用于对于动态技术系统进行计算机辅助的控制优化的交互式辅助系统。该技术系统例如可以是燃气轮机、风力涡轮机、发电厂、生产设施或者另一技术设施或者另一动态系统。
该交互式辅助系统包括具有输入终端IN(例如键盘)的以及具有输出终端OUT(例如显示屏)的终端T。
输入终端IN用于读入状态参数,该状态参数描述了技术系统的第一系统状态S0。第一系统状态S0能够交互式地由终端T的用户来预先给定,而且描述如下初始状态,对技术系统的仿真从该初始状态出发。第一系统状态S0通过技术系统的状态参数的向量、即所谓的状态向量S0=((S0)1...(S0)N)来示出,其中N说明了技术系统的状态参数的数目。状态参数描述技术系统的在仿真开始时存在的状态。尤其是,状态参数可以是物理参量(如温度、压力或者电压)或者例如在燃气轮机的情况下描述燃烧室噪声或者氮氧化物的排放。用户可以在交互式输入终端IN上明确地输入不同的状态参数,或者也可以从在输出终端OUT上所建议的状态参数或者系统状态中选择。
描述第一系统状态的状态向量S0从输入终端IN被传送到用于仿真技术系统的动态特性的仿真模块SIM。仿真模块SIM从第一系统状态S0出发仿真通过技术系统的动态特性从S0得出的状态序列S、也就是说从S0最终得到的后续状态。状态序列S=(S1,...,ST)=: (Si)是技术系统的在时间上连续的系统状态Si的序列,其中i=1,...,T表示不同的连续的时间步骤,而T是所考虑的时间步骤的数目。系统状态Si分别通过技术系统的状态向量、也就是说通过状态参数的向量S0=((S0)1...(S0)N)来示出,该向量描述了技术系统在第i个时间步骤的状态。概括来说,因此通过状态向量S=(Si)n,i=1,...,T,n=1,...,N的序列来示出状态序列S。
此外,输入终端IN还用于交互式地读入用于报酬函数RF的调整参数W。在本实施例中,用于技术系统的N个不同的状态参数的具有权重Wi的长度N的向量W=(W1,...,WN)作为调整参数W被读入。由用户交互式地预先给定的调整参数W从输入终端IN被传送到优化模块OPT。该优化模块OPT实施报酬函数RF并且通过调整参数W将该报酬函数RF参数化。这样的与优化问题相关联地被使用的报酬函数常常也被称作Reward Function。这种报酬函数(Reward Function)RF尤其是也可以被用于训练神经网络。按照由调整参数W所调整的优化标准,报酬函数RF将所要期望的报酬分配给技术系统的相应的状态向量Si或者状态向量S的序列。通过该报酬函数RF来映射针对该技术系统的特定的优化标准或者优化目标。因此,优化模块OPT的优化目标是最大化优选地通过多个时间步骤所累加的并且借助于报酬函数RF所确定的报酬。通过交互式地修改调整参数W,用户可以改变报酬函数RF、优化目标或控制标准,而且可以交互式地观察和评价所述改变的作用。以这种方式,用户可以快速地将优化目标与新的情况或者与特定的目的进行适配。这允许对经情况适应的控制标准的快速的和灵活的优化。
在本实施例中,通过用于技术系统的不同的状态参数的具有权重的向量来示出调整参数W。借此,报酬函数RF例如可以被实施为RF=RF(Si,W)=W1·(Si)1+...+WN·(Si)N。这是在第i个时间步骤中的报酬。在这种情况下,(Si)1例如可以是描述燃烧室噪声的状态参数,而(Si)2例如可以是描述氮氧化物的排放的状态参数。替代地或者附加地,报酬函数RF也可以将不同的时间步骤的状态参数进行关联或者将整个状态序列进行关联。替代计算被加权的状态参数的线性总和或者除了计算被加权的状态参数的线性总和之外,报酬函数RF也可以非线性地通过特定的调整参数W来参数化。
仿真模块SIM包括递归神经网络,所述递归神经网络具有该技术系统的预先训练的神经模块MTS。该神经模块MTS适用于处理该技术系统的传感器数据,而且这样可以由现有的技术系统采用或者被进一步用于所述现有的技术系统。尤其是,描述第一系统状态S0的状态参数作为传感器数据被传送给仿真模块SIM。替代递归神经网络地或者除了递归神经网络之外,在仿真模块SIM中也可以实施支持向量机、高斯过程模型和/或物理模型来仿真该技术系统。
通过仿真模块SIM来仿真对用于技术系统的从第一状态S0出发的行动序列A的执行。行动序列A包括在时间上连续的行动向量Ai, i=1,...,T、也就是说A=(A1,...,AT)的序列,其中T(如上)说明了所考虑的时间步骤的数目。行动向量Ai描述了在第i个时间步骤中在技术系统上进行的控制行动。对用于动态技术系统的调节参量的特定的调整被称作控制行动、或者简称行动。例如对于燃气轮机来说,气体输送、压缩、冷却或者其它的尤其是连续的物理调节参量被称作针对这种调节参量的示例。
控制行动Ai使该技术系统从状态Si-1变为状态Si。控制行动Ai通过具有M个分量的向量来示出,其中M说明了该技术系统的调节参量的数目。因此,总体上,行动序列A通过A=(Ai)m, i=1,...,T,m=1,...,M来示出。
仿真模块SIM借助于神经模块MTS来仿真该技术系统在行动序列A的影响下从第一系统状态S0出发的动态特性。在这种情况下,预测、也就是说预告该技术系统的从A最终得到的后续状态S(S0,A)=(S1,...,ST)。在这种情况下,仿真模块SIM的递归神经网络优选地只被用于仿真该技术系统的动态特性而且在仿真期间没有被训练。要执行的行动序列A作为输入参量尤其被输送给通过仿真模块SIM引起的递归神经仿真,使得该仿真本身可以基本上与控制标准或与报酬函数RF无关地来实现。不同于神经仿真,在训练神经控制时应该通过该神经控制本身来确定进行报酬优化的行动序列。因此,神经控制必须明确地考虑控制标准或报酬函数RF,而神经仿真仅仅预测行动序列对系统特性的作用。因为对神经网络的训练是相对耗时的,所以神经控制只能缓慢地对报酬函数RF的改变做出反应。不同于此,通过仿真模块SIM来实现的神经仿真本身基本上与报酬函数RF无关,而且因此已经可以例如依据真正的技术系统来预先训练。
优化模块OPT与仿真模块SIM耦合以及与终端T耦合。依据由终端T接收到的调整参数W,优化模块OPT将报酬函数RF按照RF=RF(S,W)设立为状态序列S的函数。
优化模块OPT拥有行动生成器AGEN。该行动生成器AGEN在用于使累加的报酬最大化的优化方法的范围内生成多个从第一系统状态S0出发的行动序列A(S0),所述累加的报酬借助于所设立的报酬函数RF来确定。随机的优化方法和/或尤其是无梯度的优化启发方法(诸如粒子群优化、遗传优化方法、模拟退火方法和/或随机梯度方法)可以作为优化方法被用于非凸的优化问题。所生成的行动序列A(S0)中的每个都被传送到仿真模块SIM。在那里,从中分别最终得到的后续状态S(S0,A)被预测而且被传送到优化模块OPT。针对相应的后续状态S,按照当前所调整的优化标准所要期望的报酬RF(S,W)被确定而且被传送到行动生成器AGEN。按照所实施的优化方法,根据所要期望的报酬来生成新的行动序列A(S0),所述新的行动序列A(S0)可期望更高的报酬。这些新的行动序列A(S0)重新被传送到仿真模块SIM,以便根据仿真结果重新确定为此所要期望的报酬。以这种方式,优化模块OPT基于仿真模块SIM的仿真而优化长度为T的从第一系统状态S0出发的行动序列A。在这种情况下,相应的被生成的行动序列代表如下提议:在接下来的T个时间步骤中控制该技术系统。一般来说,针对复杂的技术系统(诸如燃气轮机),具有多个时间步骤的行动序列是必要的,以便也映射长期的动态效应。这一般来说导致高维的优化问题,尤其是上面所提到的随机方法特别适用于所述高维的优化问题。
在多次连续的优化回合之后,在当前所调整的报酬函数RF的意义上进行报酬优化的行动序列A'被确定。所述进行报酬优化的行动序列A'包括(如其它的优化序列A那样)调节参量的向量的序列,也就是说A'=(A'i)m, i=1,...,T, m=1,...,M。所述进行报酬优化的行动序列A'可以被理解为第一系统状态S0与调整参数W的函数A'(S0,W)。因此,对第一系统状态S0与调整参数W的不同的选择允许通过优化模块OPT对进行报酬优化的行动序列A'进行彼此无关的优化。
从第一系统状态S0出发,通过仿真模块SIM确定从所述进行报酬优化的行动序列A'最终得到的状态序列S'=(S'i)n, i=1,...,T且n=1,...,N。,最终得到的状态序列S'对应于由仿真模块SIM预告的在所述进行报酬优化的行动序列A'的作用下的系统特性。所述进行报酬优化的行动序列A'(S0,W)以及所述从中最终得到的状态序列S'(S0,W)紧接着从优化模块OPT被传输到终端T。优选地,也可以将报酬函数的返回值RF(S'i,W), i=1,...,T或者其它从A'和/或S'推导出的参量传输到终端T。接着,通过输出终端OUT可以以时间上的变化过程i=1,...,T来示出进行报酬优化的行动向量A'i,最终得到的状态向量S'i,和/或所属的报酬值RF(S'i,W)。这允许由用户来迅速地判断优化结果。据此,用户接着可以交互式地在终端T上进行对报酬函数RF或控制标准以及初始状态S0的进一步匹配。
由优化模块OPT使用的优化方法一般来说比对神经网络的训练显著更快地收敛。如上面已经提及的那样,优化模块SIM的递归神经网络基本上与报酬函数RF无关,而且不必在该报酬函数RF改变时被重新训练。为了仿真该技术系统,仅仅分析所述递归神经网络。这种分析常常也被称作再呼叫(Recall)并且是很高效的和高性能的。因此,借助于递归神经网络来实施的仿真与基于快速的随机的优化方法的优化的逻辑分离,允许特别高性能地和高效地确定针对被仿真的技术系统的进行报酬优化的行动序列A'。
因此,对于用户来说,在输入新的第一系统状态S0并且调整新的报酬函数RF之后,所述新的第一系统状态S0和所述新的报酬函数RF的作用在短时间之后就可以被识别,使得可以由用户交互式地在终端T上通过权衡不同的优化目标来匹配或者优化该报酬函数。以这种方式,交互式辅助系统允许关于所期望的系统特性快速地对报酬函数或控制标准进行交互式的优化。
在此,该交互式辅助系统尤其是可以支持用户以高效的方式在该技术系统的高维的行动空间内找到最优的工作点。在此,该用户可以在短时间内测试和比较不同的控制标准,而且这样可以创建如下报酬函数,该报酬函数在预先给定的情况下对于技术系统是最优的。此外,该交互式辅助系统还可以被用于评估针对该技术系统的其它的控制,其方式是针对其它的控制的性能来提供一种参考。
- 还没有人留言评论。精彩留言会获得点赞!