基于变换函数和填充函数的智能控制系统优化算法的制作方法
本发明提出了一种基于变换函数和填充函数的智能控制系统优化算法,其中智能控制系统是多回路反馈控制系统,它使每一个子回路的控制对象为被优化的函数,通过各子回路的反馈和多子回路的分布,实现控制对象优化;变换函数简化目标函数,从而使其全局最小点与其它局部最小值分离;填充函数具有使智能控制系统从一个局部最优点跳到另一个更小的局部最优点的功能,如此反复若干次可以得到更加精确的全局最优点。
背景技术:
反馈控制系统优化算法的基本思路来源于单回路控制系统的反馈思想,具体的框图模型如下图5所示。其中,输入给定值R一般是一个小于目标函数最小值的常数;从图5不难看出,反馈控制系统主要通过输出反馈产生误差,经过控制器控制被控对象(被优化的函数),从而实现寻优,即作为控制对象的被优化函数通过反馈和控制器使其输出越来越小。
在图5中,f(k)是第k次迭代时目标函数值;控制器采用增量式PID控制策略,单回路反馈控制系统优化算法的迭代公式定义为:
x(k+1)=x(k)+kpΔE(k)+kiE(k)+kdΔ2E(k) (1)
上式中的kp,ki和kd分别是PID三个自适应调整参数。
该算法对一些复杂的多极值点的函数,有时达到一定的精度后,就很难再找到更好的极值点,或者无法达到目标要求,为此,某个变换函数被用于简化目标函数(控制对象)使之尽可能地成为简单的凸函数。当目标函数的值远离零时,将其值映射到1或-1,而当目标函数的值接近零时,则将其值尽可能映射到零。另外,由于转换函数在零附近变化非常大,因此,通过函数变换,可以使目标函数的全局最小点与其它靠近零点的局部最小值分离。结合具有被简化的控制对象的智能控制系统,我们可以得到目标函数的更加精确的全局最小点。
如果函数T(x)满足以下两个性质,我们就把它叫做目标函数f(x)的一个函数变换:
1)T(x)(其中x>0)是一个连续、可导的一维函数并且在(0,1)或(-1,0)上是单调的。
2)|(T(±10)-T(0))|/T(∞)≥98%
注1:性质1保证了变换后的函数T(x)和目标函数f(x)有着相同的全局最优点。性质2是给出T(x)的有效区间。
该算法面临两个问题的考验。第一个问题是:如何判断当前的极小值点是全局最优值点;第二个问题是:怎样从当前局部极小点跳出,移向目标函数更小的局部极小值点。
填充函数法是一种能较好的解决陷入局部极小点的方法,通过构造填充函数能有效地跳出局部极小点,找到另一个比它更小的局部极小点。为了更好地理解填充函数,下面给出三个假设。
假设1:函数f(x)的一个包含最小点的连通域B1,在其内部任意一点x出发,用速降法都收敛于但B1外面的部分任意点都不能收敛于则B1叫做f(X)的一个盆域。
假设2:如果是f(x)的最大点,则f(x)包含的谷域是-f(x)的盆域。
假设3:包含局部最小值点的盆域B2是高于包含局部最小值的盆域B1当且仅当
如果一个函数P(x,x*)满足以下四个条件,则它被称为是f(x)在局部最小值点的填充函数:
1)是函数P(x,x*)的一个严格的局部最大点。
2)在任意一个高于盆浴B1的f(x)的盆浴,P(x,x*)没有最小点或者鞍点。
3)如果f(x)有一个在局部最小点比盆域B1小的盆域B2,则存在一点x′使得P(x,x*)最小,且它在和x″的连接线上(它是某一个邻域)。
4)对于属于Ω域的任意x、y,满足和当且仅当P(x)≤(<)P(y)。
技术实现要素:
本发明的目的在于针对已有技术存在的不足,提供一种基于变换函数和填充函数的智能控制系统优化算法,其智能控制系统是多回路反馈控制系统,它使每一个子回路的控制对象为被优化的函数,通过各子回路的反馈和多子回路的分布,实现控制对象优化。因多极值点的优化函数易陷入局部极值点,引入变换函数简化控制对象,使被优化的函数的全局最小点能够与其它靠近零点的局部最小值分离。变换函数是单调一维函数,不影响目标函数的极值点的个数。基于被优化的函数构造的填充函数使控制系统跳出当前局部最小点,并能够在新的位置重新开始寻找比当前最小值更小的局部最小点,从而避免使系统陷入局部最小点。
为达到上述目的,本发明的构思是:智能控制系统采用多回路反馈控制系统,每一个子回路的控制对象为被优化的函数,利用变换函数对控制对象进行T变换,使被优化函数的全局最小点(接近零点的最小值)能够与其它靠近零点的局部最小值分离,用自适应PID控制器寻找被优化函数的最优值。当被判断为陷入局部最小值时(即相邻两次迭代后的被优化函数值之差很小时),此时进入填充函数迭代,直到跳出局部最小值并找到一个更小的最小点,在此基础上继续用自适应PID控制器寻找系统最优值。
根据上述发明构思,本发明采用下述技术方案:
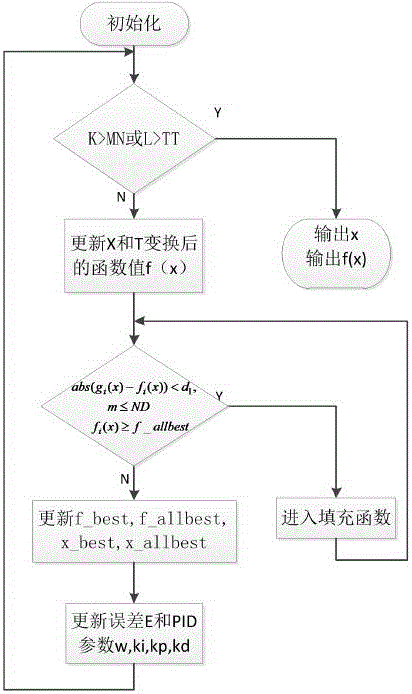
第一步:对各个参数进行初始化:在可行域内利用随机分布确定初始点Xn×d的初值,其中n为并行控制系统个数,d为实际自变量的维数,给各个参数局部最小点x_best,全局最小点x_allbest,局部最小值f_best,全局最小值f_allbest,惯性因子w,PID算法的参数ki,kp,kd,[0,2]之间的常数c1,c2,随机数r1,r2区间的初值,并确定算法总循环次数MN,进入填充函数子程序的最大次数TT以及填充函数内迭代的最大次数ND,令k=1,L=1.m=1;
第二步:判断是否结束算法流程:k>MN或L>TT,若是,则输出目标函数的全局最优值f_allbest,程序结束;否则,k=k+1,gi(x)=fi(x),i=1,2,3...n;根据下列的式(3)更新自变量Xn×d和T变换后的目标函数n个子系统的值f(X)=[f1,f2...fn]并判断向量x是否超出可行域;
第三步:判断是否进入填充函数:abs(gi(x)-fi(x))<d1且m≤ND且fi(x)≥f_allbest,若是,则x(i,k)=x(i,k)+d2×(rand(1,1)-0.5)×exp(d3(k-1)/ND)
x(i,k)=x(i,k)+d4×rand(1,1)×exp(d5(k-1)/ND)×(x(i,k)-x_allbest)/||x(i,k)-x_allbest||进入填充函数,更新f(x),T变换后的目标函数n个子系统的值f(X)=[f1,f2...fn],gi(x)=fi(x),i=1,2,3...n,然后转回第三步;否则,跳转至第四步;
第四步:更新x_best,x_allbest,f_best,f_allbest;
第五步:根据式(4)更新相关误差量E,ΔE,Δ2E。根据式(5)调整惯性因子w,PID算法的参数ki,kp,kd,然后跳转至第二步。
上述第二步中,对目标函数f(x)进行T变换的具体方法:目标函数f(x)的T变换为这里T变换函数为更新自变量Xn×d的迭代方程式为:
其中x(i,k)表示第i个子系统的第k次迭代向量,ki,kp,kd是PID算法的参数向量,w是惯性因子。r1,r2是初值设定区间的随机数。c1,c2是常数,一般取值范围是[0,2]。x_best(i)是第i个子系统在迭代过程中的最好位置向量,x_allbest是所有系统在迭代过程的最好位置向量。判断向量x是否超出可行域:x<s1或x>s2,若是,则超出可行域,x(i,k+1)=x_allbest(k),更新f(X)=[f1,f2...fn];否则,没有超出可行域,以此次迭代结果x(i,k+1)更新f(X)=[f1,f2...fn],其中k用来累计算法循环次数,g(x)用来保存该次f(x)的值,MN为算法循环次数的最大值;L用来累计进入填充函数子程序的次数,TT允许进入填充函数子程序的最大次数;s1,s2为自变量x有效区间的边界。
上述第三步中,判断是否进入填充函数,其判断条件为:abs(gi(x)-fi(x))<d1且m≤ND且fi(x)≥f_allbest,m用来累计在填充函数内迭代的次数,ND为在填充函数内迭代的最大次数,d1为设定进入填充函数子程序时的相邻两次f(x)之差的绝对值的最大值。
2.上述第四步中,更新x_best,x_allbest,f_best,f_allbest:若f(i,k+1)<f_best(i),则x_best(i)=x(i,k+1),f_best(i)=f(i,k+1);若f_allbest(k)>f_best(i,k+1),则x_allbest(k)=x_best(i,k+1),f_allbest(k)=f_best(i,k+1)否则跳转至步骤5)。
上述第五步中,相关误差量E,ΔE,Δ2E的更新公式和参数ω、kp、ki和kd的自适应修正公式如下:
η是一个非常小的正数,R是系统输入,f(i,k)表示第i个子系统的第k次系统输出f(x)的值。ΔE(i,k)表示第i个子系统的第k次系统误差E(i,k)与第k-1次系统误差E(i,k-1)的差值,Δ2E(i,k)表示第i个子系统的第k次系统误差E(i,k)和第k-1次系统误差E(i,k-1)的差值与第i个子系统的第k-1次系统误差E(i,k-1)和第k-2次系统误差E(i,k-2)的差值的差值。
本发明中用到的变换函数:从图7中可清晰看出函数T(x)在原点附近的值变化很大而定义域内远离原点的区域变化很平缓,这说明通过变换得到的新目标函数在远离原点的局部最小值被削减,而在原点附近处的全局最小值被放大了,这样就减小了系统陷入局部最小点的可能性。为了验证这一点,取一个例子F1,变换函数T(x)处理前后的曲线如图8~9所示。
本发明提出了一种不带参数的填充函数并给出证明:
定理1:如果x1是f(x)的一个已知的局部最小点,则x1是P(x,x1)的一个严格的局部最大点。证明:设B1是f(x)在局部最小点x1的一个s型盆域,即对任意x∈B1有f(x)≥f(X1),则
这表明x1是P(x,x1)的一个严格的局部最大点。
定理2:令x1是f(x)的一个已知的局部最小点,如果x∈S1={x|f(x)≥f(X1),x≠X1},则P(x,x1)在S1域内无固定点或者最小点。
证明:因为x∈S1,则当f(x)>f(X1)和x≠X1,有如果d(x)=(x-x1)和x≠X1,则因此d(x)是对于任意x∈S1,P(x,x1)的一个速降方向。当f(y)=f(X1),有则对于满足||x-x1||>||y-x1||和||x2-x1||<||y-x1||的任意x,x2∈S1,有因此,P(x,x1)在S1域内无固定点或者最小点。
定理3:令x1是f(x)的一个已知的局部最小点,对于任意x2∈Ω,x2≠x1,如果f(x2)≥f(x1),则x2是P(x,x1)的一个连续点,或者x2是P(x,x1)的一个下半连续点。
证明:因为x1是f(x)的B1盆域内的一个局部最小点,所以对于任意x∈B1,有f(x)≥f(x1),则因此,P(x,x1)在x1点是连续的。如果f(x2)≠f(x1)且x2≠x1,即f(x2)<f(x1)或f(x2)>f(x1),则或这样存在一个邻域N(x2,δ),δ>0使对于任意x∈N(x2,δ),即P(x,x1)在x2点是连续的。如果f(x2)=f(x1)且x2≠x1,则因此x2是P(x,x1)的一个下半连续点。
定理4:令x1是f(x)的一个已知的局部最小点,x2是满足f(x2)<f(x1)的另一个与x1邻近的局部最小点,则存在一点x'∈S2={x,f(x)<f(X1),x∈Ω}使得P(x,x*)最小,且它在和x″的连接线上(它是某一个邻域)。
证明:因为x1是f(x)的一个已知的局部最小点,则存在一个s型盆域B1,对于任意x∈B1,使f(x)≥f(x1),由此得到
类似地,关于局部最小点x2,存在s型盆域B2,对于某些x3∈B2,有f(x2)≤f(x3)<f(x1),则对于x3∈B2,有
因此P(x',x1)<P(x3,x1),另外P(x1,x1)=0,则当x远离x1时,有P(x,x1)<0。因此,当f(x)≥f(x1)时,P(x,x1)减小,否则P(x,x1)增加。由定理4,则存在一点x'∈S2={x,f(x)<f(X1),x∈Ω}使得P(x,x*)最小,且它在和x″的连接线上(它是某一个邻域)。
定理5:令x1是f(x)的一个已知的局部最小点,以及d是满足dT(x-X1)>0的一个方向,如果f(x)>f(X1),则d是P(x,x1)在x1点的一个速降方向。
证明:因为f(x)>f(X1)和dT(x-X1)>0,则
因此d是P(x,x1)在x1点的一个速降方向。
定理6:令x1是f(x)的一个已知的局部最小点,对于任意x,y∈Ω满足
f(x)≥f(X1),f(y)≥f(X1)及||x-x1||≥||y-x1||当且仅当P(x,x1)≤P(y,x1)。
证明:因为对于任意x,y∈Ω满足f(x)≥f(X1),f(y)≥f(X1),则
因为单调递增的函数,则对于||x-x1||>(≥)||y-x1||,有P(x,x1)<(≤)P(y,x1)或者对于P(x,x1)<(≤)P(y,x1),有||x-x1||>(≥)||y-x1||。
注释1:从定理1—6,很容易看出P(x,x1)是一个填充函数,因为它满足了填充函数所有的定义,当f(x)≥f(x1),P(x,x1)减少;当f(x)<f(x1),P(x,x1)增加,如果d是在点满足dT(x-X1)>0的P(x,x1)速降方向,那么通过d可以找到满足f(x)<f(x1)的搜索方向。
令是当前局部极小点,是当前迭代点,λ和μ是两个给定的常数且0<λ<μ,是在的搜索方向,使
定理7:令和如果满足则
这里,Ω是x的可行域。
证明:如果则
注释2:从定理3,很容易看到,如果是一个满足的搜索方向,那么当迭代次数达到足够大时,搜索将达到Ω的边界或者找到满足f(x)<f(X1)的点。为了实现
和我们选择也就是
说,因此这里,η>0。当边界Ω非常大的时候,η可以选为一个较大的正数,否则η可以选为一个较小的正数。另外,为了避免搜索达到边界,有必要采用分布性的学习步长,因此η可以选为一个随机的正数。
从填充函数的定义出发得到基于填充函数算法的思路,首先使用一种局部优化算法得到目标函数f(X)的一个局部极小点然后在处构造一个填充函数F(x),在处搜索一点x1,以x1为出发点用局部优化算法极小化填充函数F(x),得到一点x2,有填充函数的性质可知,点x2一定在比B1低的盆域内,再从现已取得的极小点x2为初始点用局部最优化方法极小化目标函数f(X),得到f(X)的另一个更优的局部极小点交替进行上述过程就会得到目标函数f(X)的局部极小点列利···x*,满足从而得到目标函数的全局极小值点。
本发明的基于变换函数和填充函数的智能控制系统优化算法与现有技术相比较具有如下显而易见的突出实质性特点和显著优点:
1)智能控制系统是多回路反馈控制系统,它使每一个子回路的控制对象为被优化的函数,通过各子回路的反馈和多子回路的分布,实现控制对象优化。
2)通过函数变换简化了被优化函数,使其在远离远点的局部最小值被削减而在原点附近的局部最小值被放大了,从而减小了陷入局部最小点的可能性,很大程度上增大了找到全局最小值的可能性,提高了寻优的精度和速度。
3)当系统陷入了局部最优点时,进入填充函数迭代,使智能控制系统从一个局部最优点跳到另一个更小的局部最优点,如此反复若干次可以得到更加精确的全局最优点。
4)多回路系统并行计算的智能控制系统与函数变换以及填充函数法的结合,既保留了智能控制系统的多系统分布并行计算的优点,又在一定程度上克服了智能控制系统算法容易陷入局部最优点的不足。
附图说明
图1算法主流程图;
图2算法子流程图;
图3算法子流程图;
图4算法子流程图;
图5单回路反馈控制系统优化算法的模型
图6基于变换函数和填充函数的多回路系统框图;
图7是变换函数T(x)的曲线;
图8是F1(x)的曲线,定义域(-6<x<6);
图9 T变换后的F1(x)即T(F1(x))的曲线,定义域(-6<x<6);
图10对F1基准函数5个算法的仿真曲线;
图11对F2基准函数5个算法的仿真曲线;
图12对F3基准函数5个算法的仿真曲线;
图13对F4基准函数5个算法的仿真曲线;
图14对F5基准函数5个算法的仿真曲线;
具体实施方式
本发明的优选实施例结合附图详述如下:
实施例一:
基准函数:
搜索范围:-5.12≤xi≤5.12(本文实验采用30维)。全局最优值:min(F1)=F1(0,...,0)=0。参见图1~图9,本基于变换函数和填充函数的智能控制系统优化算法,其特征在于操作步骤如下:
1)对各个参数进行初始化:在可行域内利用随机分布确定初始点X5×30=10.24×(rand(5,30,1)-0.5),其中5为并行控制系统个数,30为实际自变量的维数,局部最小点x_best=10.24×(rand(5,30,1)-0.5),全局最小点x_allbest=0×rand(1,30,1),局部最小值f_best=2×108×rand(5,1,1),全局最小值f_allbest=2×107,惯性因子w=0.01×rand(5,30,1),PID算法的参数ki=kd=1×10-8×rand(5,30,1),kp=5×10-8×rand(5,30,1),c1=c2=1.5,r1=r2=1.0×(rand(1,1)-0.5),算法总循环次数MN=40,进入填充函数子程序的最大次数TT=80,以及填充函数内迭代的最大次数ND=300,d1=1×10-15,d1=1×10-7,d3=5,d4=1,d5=3,k=1,L=1,m=1;
2)判断是否结束算法流程:k>40或L>80,若是,则输出目标函数的全局最优值f_allbest,程序结束;否则,k=k+1,gi(x)=fi(x),i=1,2,3,4,5;更新自变量X5×30和T变换后的目标函数5个子系统的值f(X)=[f1,f2...f5]并判断向量x是否超出可行域;
3)判断是否进入填充函数:abs(gi(x)-fi(x))<1×10-15且m≤300且fi(x)≥f_allbest,若是,则x(i,k)=x(i,k)+1×10-7×(rand(1,1)-0.5)×exp(5×(k-1)/300)
x(i,k)=x(i,k)+1×rand(1,1)×exp(3×(k-1)/300)×(x(i,k)-x_allbest)/||x(i,k)-x_allbest||进入填充函数,更新f(x),T变换后的目标函数5个子系统的值f(X)=[f1,f2...f5],gi(x)=fi(x),i=1,2,3,4,5,然后转回步骤3);否则,跳转至步骤4);
4)更新x_best,x_allbest,f_best,f_allbest;
5)更新相关误差量E,ΔE,Δ2E;调整惯性因子w,PID算法的参数ki,kp,kd,然后跳转至步骤2)。
实施例二:
本实施例与实施例一基本相同,特别之处在于如下:
所述操作步骤2)中,对目标函数f(x)进行T变换的具体方法:目标函数f(x)的T变换为这里T变换函数为更新自变量Xn×d的迭代方程式为:
其中x(i,k)表示第i个子系统的第k次迭代向量,x_best(i)是第i个子系统在迭代过程中的最好位置向量,x_allbest是所有系统在迭代过程的最好位置向量;判断x(i,k+1)是否超出可行域:x<-5.12或x>5.12,若是,则超出可行域,x(i,k+1)=x_allbest(k),更新f(X)=[f1,f2...f5];否则,没有超出可行域,以此次迭代结果x(i,k+1)更新f(X)=[f1,f2...f5]。
所述操作步骤3)判断是否进入填充函数:判断条件为abs(gi(x)-fi(x))<1×10-15且m≤300且fi(x)≥f_allbest,若是,则x(i,k)=x(i,k)+1×10-7×(rand(1,1)-0.5)×exp(5×(k-1)/300)
x(i,k)=x(i,k)+1×rand(1,1)×exp(3×(k-1)/300)×(x(i,k)-x_allbest)/||x(i,k)-x_allbest||进入填充函数,判断是否超出可行域,然后更新f(X)=[f1,f2...f5],对f(x)进行T变换。
所述操作步骤4)更新x_best,x_allbest,f_best,f_allbest:若f(i,k+1)<f_best(i),则x_best(i)=x(i,k+1),f_best(i)=f(i,k+1);若f_allbest(k)>f_best(i,k+1),则x_allbest(k)=x_best(i,k+1),f_allbest(k)=f_best(i,k+1)否则跳转至步骤5)。
所述操作步骤5),相关误差量E,ΔE,Δ2E的更新公式和参数ω、kp、ki和kd的自适应修正公式如下:
这里η=1×10-11,系统输入R=-20,初始化f(X)=0×rand(5,1,1)。
实施例三:
图1为算法主流程图,首先按图1对F1进行初始化,然后判断是否结束算法,若不结束算法按图2更新自变量X,判断X是否超出可行域,更新f(x);然后按图3判断是否进入填充函数,判断X是否超出可行域,更新f(x),对f(x)进行T变换;然后按图4更新x_best,x_allbest,f_best,f_allbest;然后按图1更新相关误差量E,ΔE,Δ2E的更新公式和参数ω、kp、ki和kd,循环多次上述步骤。以图5所示经典单回路反馈控制系统为基础,本发明采用图6所示基于填充函数的多回路反馈控制系统。图7为算法中用到的变换函数的图形。图8为的图形,从图可以看出,F1有很多局部极小点,不便于寻找函数的全局最小点。图9为对F1变换后的图形,经变换后全局最优解非常突出,而边缘的局部极小点被弱化,使全局寻优变得更容易,更精准。
图10至图14是以F1~F5为基准函数做出的仿真结果。图中曲线1为APID算法(参数自适应PID反馈控制系统优化算法),曲线2为MAPID算法(参数自适应多回路PID反馈控制系统优化算法),曲线3为TAPID算法(基于变换函数的参数自适应PID反馈控制系统优化算法),曲线4为TMAPID算法(基于变换函数的参数自适应多回路PID反馈控制系统优化算法),曲线5为FTMAPID算法(基于变换函数和填充函数的参数自适应多回路PID反馈控制系统优化算法,即本发明论述的算法)。横坐标为算法迭代次数,纵坐标为f(x)的函数值。从图10至图14能看出其中基于变换函数和填充函数的控制系统优化算法收敛的精度能进一步得到提高,收敛的速度也变的更好。
这里对每个测试函数重复实验30次,统计30次中的最大值(MAX)、最小值(MIN)、成功收敛的平均值(AVG)、置信区间(Confidence Interval,按照95%置信水平)、收敛次数N以及CPU时间(CPU-TIME)。最后为了更直观地说明问题,在同一幅图中给出了四个算法的仿真曲线以方便进行性能比较。实验中允许误差为SA,即在设定迭代步数内仿真结果与实际最优值之间的误差小于SA则认为是成功收敛,否则不收敛(用“/”表示)。
表1 F1Generalized Griewanks函数的实验结果
表2 F2Goldstein-Price函数的实验结果
表3 F3Shubert函数的实验结果
表4 F4Shekel’s Family函数的实验结果
表5 F5weierstrassy函数的实验结果
从表1至表5的数据可以看出,基于变换函数和填充函数的控制系统优化算法相对于前面四种控制算法,减少了算法陷入最优值的可能,完成了成功收敛且收敛精度都很好。
多系统并行计算的智能控制系统与填充函数法结合的基于变换函数和填充函数的控制系统优化算法,一方面,既保留了智能控制系统的多系统并行计算和群体学习的优点,又在一定程度上克服了智能控制系统算法容易陷入局部最优点的不足。另一方面,智能控制系统算法具有较强的局部搜索能力,而填充函数法则保证了智能控制系统算法的全局搜索,从而大大提高了智能控制系统算法的寻优精度。
下面给出对应于图10至图14,作为被优化函数的5个基准测试函数:
1.Generalized Rastrigin函数
函数表达式:
搜索范围:-5.12≤xi≤5.12(本文实验采用30维)。
全局最优值:min(F1)=F1(0,...,0)=0。
2.Kowalik函数
函数表达式:
搜索范围:-2≤xi≤2(自变量4维)。
全局最优值:min(F2)≈F2(-0.1928,0.1908,0.1231,0.1358)≈3.0749e-4
3.Shubert函数
函数表达式:
搜索范围:-10≤xi≤10(自变量2维)。全局最优值:min(F3)=-186.7309。
4.Shekel’s Family
函数表达式:
c=[0.1 0.2 0.2 0.4 0.4 0.6 0.3 0.7 0.5 0.5]
搜索范围:0≤xi≤10(自变量4维)。全局最优值:min(F4)=F4(4,4,4,4)=-10.5364。
5.Weierstrass函数
函数表达式:
a=0.5,b=3,kmax=20
搜索范围:-5.12≤xi≤5.12(本文实验采用10维)。全局最优值:min(F5)=F5(0,...0)=0。
- 还没有人留言评论。精彩留言会获得点赞!