一种基于大数据分析的性能自动调优方法及装置与流程
本发明涉及数据处理领域,具体涉及一种基于大数据分析的性能自动调优方法及装置。
背景技术:
城市轨道交通信号控制系统,是铁路运输的基础设备之一,它担负着路网上行车设备的运行状况、列车运行的实时状态、运输调度的指令控制等信息的传递与监控任务,在控制列车运行,保证列车安全,保证高效运营组织方面发挥着核心作用。
维护支持系统(Maintenance Support System,简称MSS),是轨道交通信号系统中的一个子系统,是管理轨道交通信号系统大量设备和维持信号系统设备高完好率的重要组成部分。是整个信号系统设备状态监测和维护的辅助工具。
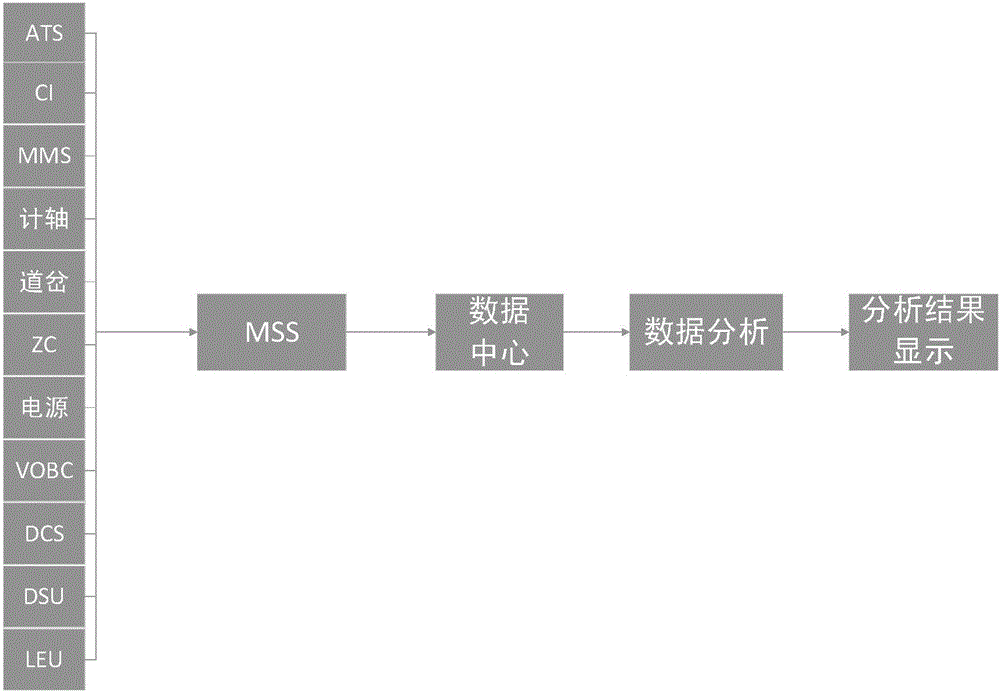
大数据平台(Basic Data Management Stage,简称BDMS),是轨道交通信号维护系统的核心,其主要功能是对各信号系统进行软硬件故障分析处理以及维护工单的下发等。大数据分析功能中,使用转辙机举例说明。如图1所示,MSS采集转辙机数据发送到大数据中心,大数据中心根据采集到的实时数据(油压曲线、模拟量等)结合资产数据(资产号、设备号、使用年限、开始使用日期)和历史数据(历史故障次数、故障原因码、历史油压、历史电流、历史转辙机模拟量等)进行状态预故障分析即数据分析,根据分析结论,给出需要对故障进行的补救和应急措施,如:购买设备、更换设备的某元器件、上油等。
通过历史数据可以分析出设备的性能,包括最快转辙速度、转辙反应时间等,根据历史故障和使用年限等数据,可分析出设备的老化程度,包括设备的磨损率、剩余使用年限等。传统的分析处理过程为人工制作某项功能的处理函数,此功能的处理方法永久维持不变,系统分析速度会随着数据量的增大而减小。
目前信号系统的维护方式存在以下缺陷:
大数据平台系统负责分析各子系统的状态数据和设备信息,由于数据量庞大,数据结构复杂,在根据实时数据信息进行分析时,无法在规定时间(如3S)内计算出分析结论。
在大数据分析过程中,在分析数据时可能需要对某类数据进行查找,现已大家熟知的查找算法举例说明,不同厂商可能采用不同的算法来对数据进行搜索,例如,厂商A可能采用二分查找法,厂商B可能采用顺序查找法,厂商C可能采用分块查找法。但是,缺陷在于,一旦采用了某类算法,就不再改变,由于数据量增减带来的影响,导致分析速度时快时慢,不能保证系统始终保持最快分析速度,给软件性能带来严重影响。
技术实现要素:
鉴于上述问题,本发明提出了克服上述问题或者至少部分地解决上述问题的一种基于大数据分析的性能自动调优方法及装置。
为此目的,第一方面,本发明提出一种基于大数据分析的性能自动调优方法,包括:
接收用户输入的设备类型、状态数据类型、包括分析方式和设备标识的执行条件;
根据所述设备类型、状态数据类型、执行条件,从数据中心筛选出预设时间段内待分析的数据量;
根据数据量、状态数据类型、执行条件,确定算法动态库中每一算法的性能值;
选取最高性能值对应的算法,依据执行条件对待分析的数据量进行分析,获取分析结果。
可选地,所述方法还包括:
在人机交互界面显示所述分析结果。
可选地,根据数据量、状态数据类型、执行条件,确定算法动态库中每一算法的性能值的步骤之前,所述方法还包括:
建立所述算法动态库,
所述算法动态库包括至少一个算法;
或者,所述算法动态库包括至少一个算法及该算法对应的影响该算法性能值的各项的权重系数。
可选地,所述算法动态库包括下述的一项或多项算法:
二分查找法、哈希表查找法、分块查找法、顺序查找法、堆排序算法。
可选地,所述方法还包括:
将所述状态数据类型、数据量信息、最高性能值对应的算法作为配置组合进行存储。
可选地,所述方法还包括:
在维护系统处于空闲状态时,采用不同状态数据类型的数据量、模拟执行条件,对算法动态库中的各算法的性能值进行评估,获取各算法对应的执行条件、数据量、状态数据类型的权重系数。
可选地,根据数据量、状态数据类型、执行条件,确定算法动态库中每一算法的性能值的步骤,包括:
根据每一算法对应的执行条件、数据量、状态数据类型的权重系数,确定算法动态库中每一算法的性能值。
可选地,所述分析方式包括:
状态预故障分析方式、状态预处理分析方式、设备性能分析方式、设备老化程度分析方式、和/或设备最大可用期限分析方式。
另一方面,本发明还提供一种基于大数据分析的性能自动调优装置,包括:
接收单元,用于接收用户输入的设备类型、状态数据类型、包括分析方式和设备标识的执行条件;
数据筛选单元,用于根据所述设备类型、状态数据类型、执行条件,从数据中心筛选出预设时间段内待分析的数据量;
性能值确定单元,用于根据数据量、状态数据类型、执行条件,确定算法动态库中每一算法的性能值;
选取单元,用于选取最高性能值对应的算法;
分析处理单元,用于采用选取的算法依据执行条件对待分析的数据量进行分析,获取分析结果。
可选地,所述装置还包括:
算法动态库建立单元,用于建立算法动态库;
所述算法动态库包括至少一个算法;
或者,所述算法动态库包括至少一个算法及该算法对应的影响该算法性能值的各项的权重系数。
由上述技术方案可知,本发明提出的基于大数据分析的性能自动调优方法及装置,通过获取数据量及数据结构,进而选择最优性能值的算法,采用选择的算法获取分析结果,能够提升系统处理事件的效率,减少人工等待分析时间,进一步地,优化执行速度,在相同数据量情况下,减少事件和空间复杂度,进而能够处理更大量的数据,使得系统性能达到最佳状态,系统以更加稳定的状态高速运行。
附图说明
图1为现有技术中的数据分析的过程示意图;
图2为本发明一实施例提供的基于大数据分析的性能自动调优方法的流程示意图;
图3为本发明一实施例提供的数据分析的过程示意图;
图4为本发明一实施例提供的基于大数据分析的性能自动调优装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
图2示出了本发明一实施例提供的基于大数据分析的性能自动调优方法的流程示意图,如图2所示,本实施例的方法包括如下步骤:
201、接收用户输入的设备类型、状态数据类型、包括分析方式和设备标识的执行条件。
本实施例中的设备类型为识别某类设备的标识。例如:转辙机、信号机等;状态数据类型是识别某类数据类别的标识。例如:电流值、油压值等;执行条件是检索和分析所有数据的条件,将负责此条件的数据抽取出来。例如:设备编号=001,将查找所有设备编号为001的数据。
本实施例中的设备类型、状态数据类型可由数据中心统一编号实现。
举例来说,状态预故障分析方式、状态预处理分析方式、设备性能分析方式、设备老化程度分析方式、和/或设备最大可用期限分析方式等。
202、根据所述设备类型、状态数据类型、执行条件,从数据中心筛选出预设时间段内待分析的数据量;
203、根据数据量、状态数据类型、执行条件,确定算法动态库中每一算法的性能值。
本步骤的目的在于预先比较哪些数据类型和多少数据量更适应于哪些分析算法,针对不同的状态数据类型和数据量的多少,选择不同的算法,使得分析速度能够更快。
本实施例中,性能值是反映算法执行效率的值,执行速度越快,性能值越高,使用性能值作为评估算法的依据。
举例来说,本实施例的算法动态库包括至少一个算法;例如,二分查找法、哈希表查找法、分块查找法、顺序查找法、堆排序算法等等,本实施例不对其进行限定。
204、选取最高性能值对应的算法,依据执行条件对待分析的数据量进行分析,获取分析结果。
需要说明的是,现有技术中每一厂商固定使用一种算法,若采用上述图2所示的方法比厂商固定使用算法效率高,可替换该厂商使用算法,实现对厂商算法的自动调优。
本实施例的方法,将传统的分析方法自适应调整化,优先选取算法效率最高的方式,可使分析性能达到最大化,有效提升分析效率。
在实际应用中,上述图2所示的方法还可包括下属的图中未示出的步骤205:
205、在人机交互界面显示所述分析结果。
通常,人机交互界面可为维护系统用的人机交互界面。相应地,前述的步骤201中的接收用户输入的设备类型、状态数据类型、包括分析方式和设备标识的执行条件等信息可具体为:
用户在人机交互界面操作,如选择设备类型、状态数据类型等信息,进而输入/选择分析方式、设备标识等信息。
另外,前述的步骤203之前,上述图2所示的方法还可包括下述的图中未示出的步骤A01:
A01、建立所述算法动态库,。
该处可以是人工预先将各种设备的算法/函数增加到算法动态库中,也可以是软件自动查找当前各厂商使用的各种算法/函数进行处理并合并。
例如,人工可以输入与转辙机相关的常用算法/函数。
本实施例中,算法动态库可包括至少一个算法,如二分查找法、哈希表查找法、分块查找法、顺序查找法、堆排序算法等等。
举例来说,算法动态库中的二分查找法的特点是:查找速度最快,但是数据量较大时才会体现效果。通常,二分查找法适合数据量庞大,且无序存储。如转辙机电流数据,由于系统设计问题和采集周期较长,导致数据无序存储。每天数据量大约800万条。
顺序查找法的特点是:查找速度一般,数据量较小时,速度快。通常,顺序查找法适合数据量在1万以下,最好有顺序存储的数据,如信号机的状态数据,全部按照时间顺序存储。每天数据量大约8千条。
分块查找法的特点是:查找速度介于二分法和顺序法之间。通常,分块查找法适合数据量较大,且无序存储。如区段状态信息。数据量较大。每天数据量在230万条。
另外,在一种优选的实现方式中,上述步骤A01中的算法动态库可包括至少一个算法及该算法对应的影响该算法性能值的各项的权重系数。
此时,前述步骤203可具体为:根据每一算法对应的执行条件、数据量、状态数据类型的权重系数,确定算法动态库中每一算法的性能值。
通常,在维护系统处于空闲状态时,该系统可采用不同状态数据类型的数据量、模拟执行条件,对算法动态库中的各算法的性能值进行评估,获取各算法对应的执行条件、数据量、状态数据类型的权重系数。进而将获取的权重系数等存储在算法动态库中。
可选地,在前述步骤204或步骤205之后,上述图2所示的方法还可包括图中未示出的步骤206:
206:将状态数据类型、数据量信息、最高性能值对应的算法作为配置组合进行存储。
上述方法针对数据分析过程中的算法进行优化配置,达到加快分析速度,优化分析结果,减少人工等待时间的效果。
以北京地铁7号线平均每天的数据为例说明如下。
以下以转辙机为例进行举例说明,如上所述,道岔转辙机的数据使用二分查找算法进行分析最合适,为了体现出本发明实施例中可自动调整算法的目的,因此将分析道岔转辙机的电流数据的算法默认设置成分块查找法。
目前,信号机、区段、转辙机、应答器、电源、通信板等六个设备分别具有设备类型编号0x01~0x06。当接收到设备类型编号为0x03的数据时,认为是接收到了道岔转辙机的数据。
由于是道岔转辙机的数据,现有技术中会自动地调用分块查找算法对道岔转辙机的数据进行分析。大数据平台(即图3中的数据中心)中转辙机的数据结构如下:此数据结构编号为”S1”,如下表一:
表一
在该数据结构中,转辙机ID为数据中心对此转辙机的唯一编号,对该转辙机的电流值的一天的数据进行分析,其中,每隔10秒对道岔收集一次信息,道岔由于收集信息时间较长,电流的采集间隔10毫秒采集一次,导致收集一次道岔信息的电流曲线内部数据量较大,经计算,一个道岔,10秒采集1000个电流值,每天将采集864万个电流值。
假如现在需要分析某个转辙机的故障率,那么分析故障率就是通过对某转辙机一天的动作电流曲线进行检索,如果电流超过35A,那么就认为出现一次电流过大,现需要在864万个电流值中扫描所有超过35A的电流值,此过程由于数据量较大,对算法要求较高,可见选择一个合理的算法的重要性。
本实施例中通过性能值确定使用二分查找算法进行检索分析,可以在1秒内完成。而采用现有技术中的某种固定在硬件内部的算法(分块查找法),如果该算法不适合于分析转辙机的数据,那么将大大延长处理的时间,甚至是无法处理道岔转辙机的所有数据,而无法实现分析目的。
另外,结合图3对本发明的方法使用过程进行举例说明。
上述图2所示的方法可在图3的虚线框的范围内实现。在实际应用中,为更好的使用上述图2所示的方法,本实施例中使用方法库、算法库等进行配置。
第一步:算法库配置
(1)预先将大数据分析方式(状态预故障分析、状态预处理分析、设备性能分析、设备老化程度分析、设备最大可用期限分析等)写入分析方法动态库。
此时,调整该分析方法动态库开放分析功能接口。即用户可以通过界面选择相应的分析方式;
接口参数包括:设备信息、状态数据类型、需要分析的功能编号(1、预故障2、使用年限3、老化程度)等。
(2)预先将常用的算法(二分查找法、哈希表查找、分块查找法、顺序查找法、堆排序算法等)写入算法动态库。
另外,由于现有的哈希表和泛型算法的数据结构比较特殊,故可预先将哈希表和泛型等数据结构用法存入方法库,用户在选择哈希表或泛型算法时直接调用开放的分析功能接口确定数据结构。
第二步:状态数据类型识别
根据分析功能对所有状态数据类型进行分类。
状态数据类型:1:转辙机位置,2:转辙机油压,3:转辙机电流,4:转辙机故障状态。
状态值:转辙机位置信息值(定位0xaa、反位0xbb等),油压值(转辙机油压曲线),电流值(转辙机动作电流曲线),转辙机故障状态值(正常0x66、故障状态0x55)。
第三步:算法性能评估
在进行数据分析前,自动获取之前使用的算法,对之前数据量和当前数据量进行对比,根据评比结果计算数据对本算法的性能值,性能值为执行数据所消耗的时间(毫秒),时间越短,性能值越高。
例如:对转辙机动作电流进行分析,此前使用顺序查找算法,之前数据量为100万,当前数据量为864万,在算法库中查找配置好的分块查找法、二分法和顺序查找法,分别在后台运行以上三种算法,根据后台对864万数据量运行使用时间的记录,二分法数据执行速度为230毫秒,分块查找法执行速度为300毫秒,顺序查找法执行速度为10000毫秒;因此,在分析电流值时,应该利用二分法。通过模拟真实计算分别计算出性能值。
在系统空闲状态下,分别对各类数据自动进行不同数据量的模拟,将模拟出的数据注入到算法中,利用与分析转辙机动作电流相同的分析方式自动对所有算法的性能值进行定期评估。
需要说明的是,由于部分算法可能对应特殊的数据结构,为此,在使用该算法时,预先将待分析的所有数据按照特定数据结构存储,进而对存储的对应该算法的数据结构使用相应算法进行计算。
第四步:算法自动调整
所有方法和算法根据配置进行存储,预先根据配置和性能来评估出最佳配置组合,重新增加或者修改配置。
也就是说,对算法进行性能评估后,识别最快速的算法,将影响此算法的信息保存,以便进行计算时调用;
保存内容包括:数据结构编号(即状态数据类型)、数据总量范围、执行条件。
例如:
数据结构编号:“S1”转辙机电流曲线数据结构
数据总量范围:(864w)
执行条件:(设备类型=0x03,设备编号=001)。
本实施例的方法,通过获取数据量及数据结构,进而选择最优性能值的算法,采用选择的算法获取分析结果,能够提升系统处理事件的效率,减少人工等待分析时间,进一步地,优化执行速度,在相同数据量情况下,减少事件和空间复杂度,进而能够处理更大量的数据,使得系统性能达到最佳状态,系统以更加稳定的状态高速运行。
另外,本发明实施例还提供一种基于大数据分析的性能自动调优装置,如图4所示,本实施例的性能自动调优装置包括:接收单元41、数据筛选单元42、性能值确定单元43、选取单元44、分析处理单元45;
其中,接收单元41用于接收用户输入的设备类型、状态数据类型、包括分析方式和设备标识的执行条件;
数据筛选单元42用于根据所述设备类型、状态数据类型、执行条件,从数据中心筛选出预设时间段内待分析的数据量;
性能值确定单元43用于根据数据量、状态数据类型、执行条件,确定算法动态库中每一算法的性能值;
选取单元44用于选取最高性能值对应的算法;
分析处理单元45用于采用选取的算法依据执行条件对待分析的数据量进行分析,获取分析结果。
可选地,图4所示的装置还包括图中未示出的算法动态库建立单元46,该算法动态库建立单元46用于建立算法动态库;
所述算法动态库包括至少一个算法;
或者,所述算法动态库包括至少一个算法及该算法对应的影响该算法性能值的各项的权重系数。
当然,在实际应用中,上述的图4所示的装置还包括图中未示出的存储单元,该存储单元用于存储前述的配置组合,即所述数据结构类型、数据量信息、最高性能值对应的算法组成的配置组合。
本实施例的装置可执行前述任意方法实施例的内容,详见上述记载,该处不再详述。
本实施例的装置,位于维护系统中且连接维护系统的数据中心,使用本实施例的装置能够提升维护系统处理事件的效率,减少人工等待分析时间,进一步地,优化执行速度,在相同数据量情况下,减少事件和空间复杂度,进而能够处理更大量的数据,使得系统性能达到最佳状态,系统以更加稳定的状态高速运行。
本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。
本领域技术人员可以理解,实施例中的各步骤可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(DSP)来实现根据本发明实施例的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。
虽然结合附图描述了本发明的实施方式,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下做出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!