基于贝叶斯核慢特征分析的非线性工业过程故障检测方法与流程
本发明属于工业过程故障检测
技术领域:
,涉及非线性工业过程故障检测方法,具体地说,涉及了一种基于贝叶斯核慢特征分析的非线性工业过程故障检测方法。
背景技术:
:由于现代工业系统日益趋于高集成化、大规模化,工业过程的故障诊断已经成为保证现代工业系统安全稳定运行的关键技术。随着现代计算机控制技术的发展,工业过程中采集并存储了丰富的过程运行数据。因此,基于数据驱动的故障检测方法与诊断技术逐渐成为工业过程监控领域的研究热点。研究人员提出了一系列基于数据驱动的故障检测与诊断方法,比如:主元分析(PCA)、独立元分析(ICA)、偏最小二乘(PLS)、慢特征分析(SFA)等。然而大多数的工业生产过程往往是非线性的,上述提到的故障检测与诊断方法在适用场合上具有很大的局限性。因此,针对过程数据的非线性特征,如何从测量数据中提取有用的特征信息以监控工业过程的运行状态是一种具有挑战性的研究课题。为了挖掘工业过程数据中的非线性特征,核函数方法逐渐被引入非线性故障检测与诊断
技术领域:
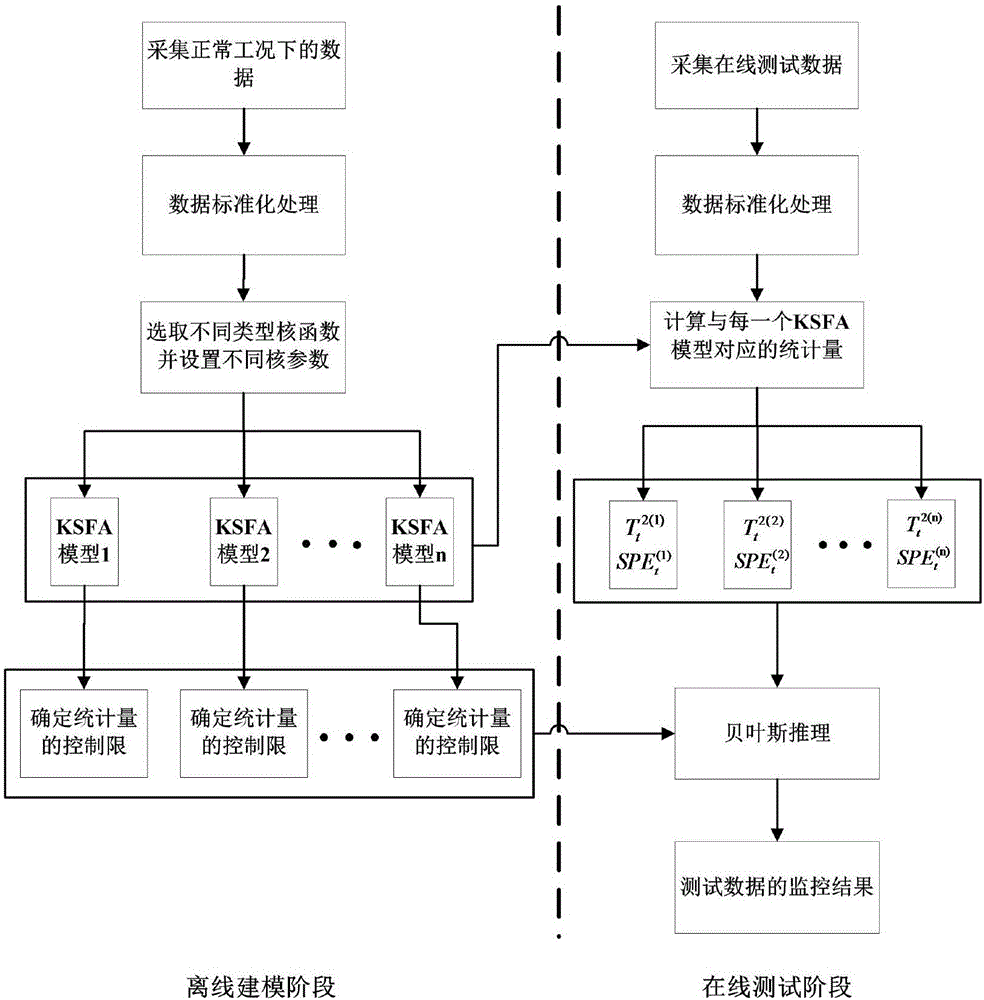
。邓晓刚等人提出了基于核慢特征分析(KernelSFA,KSFA)的工业过程故障检测方法(DengXiaogang,TianXuemin.NonlinearProcessMonitoringUsingDynamicKernelSlowFeatureAnalysisandSupportVectorDataDescription[C].ChineseControlandDecisionConference,2013:4291-4296.)近几年来,KSFA作为一种有效的工业生产过程故障检测方法,引起了国内外研究人员的广泛关注。该方法利用核函数方法将原始数据非线性的映射到高维空间,然后在高维空间中提取变化缓慢的隐含成分作为数据中的不变特征。虽然核慢特征分析方法在非线性工业过程故障检测领域取得一定的应用成果,但是其缺点在于:核函数及相应的核参数难以事先准确选择,单一的核函数和核参数无法准确提取数据中蕴含的非线性特征信息,进而影响故障检测的效果。技术实现要素:本发明针对现有的核慢特征方法在非线性工业过程故障检测中存在核函数及对应核参数难以准确选择,导致无法准确提取数据中蕴含的非线性特征信息的不足,提供一种基于贝叶斯核慢特征分析的非线性工业过程故障检测方法,该方法能够更加精确有效地获取数据中蕴含的非线性特征信息,提高故障检测率,进而改善故障检测结果。为了达到上述目的,本发明提供了一种基于贝叶斯核慢特征分析的非线性工业过程故障检测方法,含有以下步骤:(一)收集历史数据库的正常操作工况数据作为训练数据Xo,并使用均值mean(Xo)和标准差std(Xo)对训练数据Xo进行归一化处理,得到归一化后的训练数据X。(二)选择高斯核G(x,y)和多项式核P(x,y)分别作为KSFA算法的核函数,并且给这两类核函数设置一系列不同的核参数,高斯核参数为ci,i=1,2,…,ng,ng为高斯核参数的个数,多项式核参数为dj,j=1,2,…,np,np为多项式核参数的个数。(三)针对归一化后的训练数据X,建立基于每一种核函数的基本KSFA模型,利用基本KSFA模型从归一化后的训练数据X中提取非线性慢特征。(四)根据每个基本KSFA模型的非线性慢特征,计算归一化后的训练数据X对应的监控统计量T2和SPE后,基于给定的置信水平α确定T2和SPE的控制限和(五)采集测试数据xto,利用训练数据Xo的均值mean(Xo)和标准差std(Xo)对测试数据xto进行归一化处理,得到归一化后的测试数据xt。(六)基于已建立的每个基本KSFA模型,提取归一化后的测试数据xt的非线性慢特征。(七)针对每个基本KSFA模型所提取的非线性慢特征,计算归一化后的测试数据xt的监控统计量T2和SPE,并根据贝叶斯推理计算归一化后的测试数据xt是故障数据的概率。(八)根据加权组合计算出最终的监控统计量ET2和ESPE,依据ET2和ESPE是否超出置信水平α判断归一化后的测试数据xt是否是故障数据。进一步的,所述步骤(一)中,利用均值mean(Xo)和标准差std(Xo)通过公式(1)对训练数据Xo进行归一化处理,公式(1)的表达式为:X=(Xo-mean(Xo))/std(Xo)(1)训练数据Xo经上述公式(1)归一化处理后即可获得归一化后的训练数据X。进一步的,所述步骤(二)中,选取的一系列具有不同核参数的高斯核函数和多项式核函数的表达式为:式中,Gi(x,y)为高斯核函数,Pj(x,y)为多项式函数,ng为高斯核参数ci的个数,np为多项式核参数dj的个数。进一步的,步骤(三)中,提取归一化后的训练数据X中非线性慢特征的步骤为:对于归一化后的训练数据X=[x1,x2,…,xn]T,首先计算第i个基本KSFA模型中的核矩阵K(i),核矩阵K(i)中的每个元素的计算公式如下:通过公式(5)归一化核矩阵K(i),公式(5)的表达式如下:式中,为归一化后的核矩阵,IK是n×n维的矩阵,它的每一个元素都为1/n。构造核矩阵的时间变化矩阵式中,是核矩阵中的第k个列向量。开展公式(7)中所示的广义特征值分解,公式(7)表示为:保留与前l(i)个最小特征值相对应的特征向量组成负荷矩阵基于第i个基本的KSFA模型,从归一化后的核矩阵中提取非线性慢特征y(i):式中,是核矩阵K(i)T中的列向量。进一步的,步骤(四)中,利用第i个基本的KSFA模型计算出归一化后的训练数据X的监控统计量T2和SPE,记为:式中,矩阵给定置信水平α,根据核密度估计算法确定T2(i)和SPE(i)的控制限和进一步的,步骤(五)中,利用训练数据Xo的均值mean(Xo)和标准差std(Xo)通过公式(11)对测试数据xto进行归一化处理,公式(11)的表达式如下:xt=(xt-mean(Xo))/std(Xo)(11)测试数据xto经上述公式(11)归一化处理后即可获得归一化后的测试数据xt。进一步的,步骤(六)中,提取归一化后的测试数据xt的非线性慢特征的步骤为:计算归一化后的测试数据xt在第i个基本KSFA模型中对应的测试核向量中的每个元素根据下式计算:归一化测试核向量式中,为归一化后的测试核向量,It=1/n[1,…,1]T∈Rn×1,Rn×1表示n×1维的矩阵。利用第i个基本KSFA模型,从归一化后的测试核向量中提取非线性慢特征进一步的,步骤(七)中,根据公式(9)和(10)分别计算测试数据的监控统计量T2和SPE的值。进而根据贝叶斯推理计算出归一化后的测试数据xt是故障数据的概率:概率和的计算公式为:和的计算公式为:式中,分别表示归一化后的测试数据xt被认为是故障数据的概率,和分别表示在第i个基本的KSFA模型的主元空间和残差空间中过程处于正常工况和故障状态的先验概率。给定置信水平α后,和的值设定为1-α,而和的值设定为α。进一步的,步骤(八)中,判断归一化后的测试数据xt是否是故障数据的具体步骤如下:根据以下的加权组合计算公式将所有基本KSFA模型中归一化后的测试数据xt被认为是故障数据的概率进行融合:当ET2<α且ESPE<α时,认为过程处于正常工况状态;否则,认为过程中出现了故障。与现有技术相比,本发明的有益效果在于:本发明提供的非线性工业过程故障检测方法,在传统核慢特征分析方法的基础上,采用不同类型的核函数,并且给各个核函数设置不同的核参数,建立一系列基本KSFA模型,并应用这些基本KSFA模型分别监控过程,更加充分的提取数据的非线性特征。本发明提供的非线性工业过程故障检测方法引入贝叶斯推理,将一系列基本KSFA模型对测试数据的监控结果以概率的形式进行加权组合,最终得到多个模型的集成监控结果,进而改善故障检测结果,提高故障检测率。附图说明图1为本发明非线性工业过程故障检测方法的流程图。图2为本发明非线性工业过程故障检测方法的贝叶斯核慢特征分析框图。图3a-d为本发明实施例一所述非线性工业过程故障检测方法对非线性数值系统故障F1的监控结果示意图。图4为本发明实施例二所述连续搅拌反应釜(CSTR)系统的结构图。图5a-d为本发明实施例二所述非线性工业过程故障检测方法对连续搅拌反应釜(CSTR)系统故障F3的监控结果示意图。图6a-d为本发明实施例二所述非线性工业过程故障检测方法对连续搅拌反应釜(CSTR)系统故障F5的监控结果示意图。具体实施方式下面,通过示例性的实施方式对本发明进行具体描述。然而应当理解,在没有进一步叙述的情况下,一个实施方式中的元件、结构和特征也可以有益地结合到其他实施方式中。参见图1、图2,本发明揭示了一种基于贝叶斯核慢特征分析的非线性工业过程故障检测方法,含有以下步骤:(一)收集历史数据库的正常操作工况数据集Xo作为训练数据Xo,并使用均值mean(Xo)和标准差std(Xo)对训练数据Xo进行归一化处理(即标准化处理),得到归一化后的训练数据X。(二)选择高斯核G(x,y)和多项式核P(x,y)分别作为KSFA算法的核函数,并且给这两类核函数设置一系列不同的核参数,高斯核参数为ci,i=1,2,…,ng,ng为高斯核参数的个数,多项式核参数为dj,j=1,2,…,np,np为多项式核参数的个数。(三)针对归一化后的训练数据X,建立基于每一种核函数的基本KSFA模型,利用基本KSFA模型从归一化后的训练数据X中提取非线性慢特征。(四)根据每个基本KSFA模型的非线性慢特征,计算归一化后的训练数据X对应的监控统计量T2和SPE后,基于给定的置信水平α确定T2和SPE的控制限和(五)采集测试数据xto,利用训练数据Xo的均值mean(Xo)和标准差std(Xo)对测试数据xto进行归一化处理(即标准化处理),得到归一化后的测试数据xt。(六)基于已建立的每个基本KSFA模型,提取归一化后的测试数据xt的非线性慢特征。(七)针对每个基本KSFA模型所提取的非线性慢特征,计算归一化后的测试数据xt的监控统计量T2和SPE,并根据贝叶斯推理计算归一化后的测试数据xt是故障数据的概率。(八)根据加权组合计算出最终的监控统计量ET2和ESPE,依据ET2和ESPE是否超出置信水平α判断归一化后的测试数据xt是否是故障数据。上述方法中,步骤(一)至(四)为离线建模阶段,步骤(五)至(八)为在线测试阶段。实施例一:以非线性数值系统为例进行说明。仿真一个具有三个监控变量x1,x2,x3的非线性数值系统,其数学描述如下:其中e1,e2,e3∈N(0,0.01)表示三个相互独立的噪声变量,t∈[0,2]是均匀分布的随机变量,系统的输出[x1,x2,x3]作为过程监控变量。在公式(25)所示的正常操作工况下仿真300个样本作为用于建模的训练数据。为了产生故障数据,在仿真过程的第51个时刻对变量x1添加斜坡故障F1,并使故障F1一直持续到第300个时刻仿真结束为止。上述非线性数值系统的故障检测方法,含有以下步骤:(一)收集非线性数值系统的正常操作工况数据作为训练数据Xo,计算训练数据Xo的均值mean(Xo)和标准差std(Xo),对训练数据Xo进行归一化处理,获得归一化的训练数据X。利用均值mean(Xo)和标准差std(Xo)通过公式(1)对训练数据Xo进行归一化处理,公式(1)的表达式如下:X=(Xo-mean(Xo))/std(Xo)(1)训练数据Xo经上述公式(1)归一化处理后即可获得归一化后的训练数据X。(二)选择高斯核G(x,y)和多项式核P(x,y)分别作为KSFA算法的核函数,并且给这两类核函数设置一系列不同的核参数,高斯核参数为ci,i=1,2,…,ng,ng为高斯核参数的个数,多项式核参数为dj,j=1,2,…,np,np为多项式核参数的个数。选取的一系列具有不同核参数的高斯核函数和多项式核函数的表达式如下:式中,Gi(x,y)为高斯核函数,Pj(x,y)为多项式函数,ng为高斯核参数ci的个数,np为多项式核参数dj的个数。(三)针对归一化后的训练数据X,建立与每一种具有不同核参数的核函数相对应的基本KSFA模型,利用每个基本KSFA模型从归一化后的训练数据X中提取非线性慢特征。对于归一化后的训练数据X=[x1,x2,…,xn]T,首先计算第i个基本KSFA模型中的核矩阵K(i),K(i)中的每个元素的计算公式如下:归一化核矩阵K(i):式中,IK是n×n维的矩阵,它的每一个元素都为1/n。构造归一化核矩阵的时间变化矩阵式中,是核矩阵中的第k个列向量。开展式(7)中所示的广义特征值分解,公式(7)表示为:保留与前l(i)个最小特征值相对应的特征向量组成负荷矩阵基于第i个基本的KSFA模型从归一化后的核矩阵中提取非线性慢特征:式中,是核矩阵K(i)T中的列向量。(四)根据每个基本KSFA模型的非线性慢特征,计算归一化后的训练数据X对应的监控统计量T2和SPE后,基于给定的置信水平α确定T2(i)和SPE(i)的控制限和利用第i个基本的KSFA模型计算出归一化后的训练数据X的监控统计量T2和SPE,记为:式中,矩阵给定置信水平α,根据核密度估计算法确定T2(i)和SPE(i)的控制限和(五)采集测试数据xto,利用训练数据Xo的均值mean(Xo)和标准差std(Xo)对测试数据xto进行归一化处理,得到归一化后的测试数据xt。利用训练数据Xo的均值mean(Xo)和标准差std(Xo)通过公式(11)对测试数据xto进行归一化处理,公式(11)的表达式如下:xt=(xt-mean(Xo))/std(Xo)(11)测试数据xto经上述公式(11)归一化处理后即可获得归一化后的测试数据xt。(六)基于已建立的每个基本KSFA模型,提取归一化后的测试数据xt的非线性慢特征。其具体步骤如下:计算归一化后的测试数据xt在第i个基本KSFA模型中对应的测试核向量中的每个元素根据下式计算:归一化测试核向量式中,为归一化后的测试核向量,It=1/n[1,…,1]T∈Rn×1,Rn×1表示n×1维的矩阵。利用第i个基本KSFA模型,从归一化后的测试核向量中提取非线性慢特征(七)针对每个基本KSFA模型所提取的非线性慢特征,计算归一化后的测试数据xt的监控统计量T2和SPE,并根据贝叶斯推理规则计算归一化后的测试数据xt是故障数据的概率。其具体步骤如下:根据公式(9)和(10)分别计算测试数据的监控统计量T2和SPE的值;进而根据贝叶斯推理计算出归一化后的测试数据xt是故障数据的概率:概率和的计算公式为:和的计算公式为:式中,分别表示归一化后的测试数据xt被认为是故障数据的概率,和分别表示在第i个基本的KSFA模型的主元空间和残差空间中过程处于正常工况和故障状态的先验概率。给定置信水平α后,和的值设定为1-α,而和的值设定为α。(八)基于在多个基本KSFA模型中归一化后的测试数据xt被认为是故障数据的概率,根据加权组合计算出最终的监控统计量ET2和ESPE,依据ET2和ESPE是否超出置信水平α判断归一化后的测试数据xt是否是故障数据。其具体步骤如下:根据以下的加权组合计算公式将所有基本KSFA模型中归一化后的测试数据xt被认为是故障数据的概率进行融合:当ET2<α且ESPE<α时,认为过程处于正常工况状态;否则,认为过程中出现了故障。检测到故障发生后,为了评价不同监控方法的故障检测效果,通过故障检测时刻(FDT)和故障检测率(FDR)两个性能指标进行不同方法的故障检测效果对比。故障检测时刻(FDT)定义为第一个被认为是故障数据的样本所在的采样时刻,故障检测率(FDR)定义为被检测出是故障数据的样本数目与实际总的故障样本数目之比。很显然,FDT的数值越小,FDR的数值越大,意味着过程监控方法的故障检测效果越好;反之,过程监控方法的故障检测效果越差。在本实施例的非线性数值系统仿真中,本发明基于贝叶斯核慢特征分析(Bay-KSFA)的方法分别选用高斯核和多项式核作为核函数,设置高斯核的参数为ci=2000+200(i-1),i=1,2,…,5,多项式核的参数为dj=j,j=1,2,3。采用核参数c=2400的基于高斯核的慢特征分析(Gau-KSFA)、采用核参数d=2的基于多项式核的慢特征分析(Poly-KSFA)和线性慢特征分析(SFA)这三种方法与本发明的方法进行对比。置信水平取α=0.01,综合对比上述四种方法,以故障F1为例说明故障识别效果,故障检测时刻(FDT)和故障检测率(FDR)比较参见表1。表1图3(a)-(d)给出了SFA、Poly-KSFA、Gau-SFA和Bay-KSFA对故障F1的监控结果。从图3(a)中可以看出,SFA的T2和SPE统计量分别在第90和87个时刻检测到故障。而Poly-KSFA在图3(b)中给出了更好的故障检测结果,Poly-KSFA的T2和SPE统计量均在第74个时刻检测到故障。图3(c)给出了Gau-KSFA的监控结果,可以看出Gau-KSFA的T2和SPE统计量均在第65个时刻检测到故障。相比于Poly-KSFA,Gau-KSFA的监控效果又有了进一步的提高。在图3(d)中,Bay-KSFA的T2和SPE统计量均在第54个时刻检测到故障发生,因此Bay-KSFA对故障F1最为敏感。表1给出了上述四种方法对故障F1的故障检测时间(FDT)和故障检测率(FDR)。可以清楚的看出,Bay-KSFA的ET2和ESPE统计量在四种方法中获得了最高的故障检测率,均为98.79%。因此,从非线性数值系统的故障检测结果可以看出,本发明Bay-KSFA方法在故障检测时间和故障检测率方面优于SFA、Poly-KSFA和Gau-KSFA方法。实施例二:以连续搅拌反应釜(CSTR)系统为例,参见图4,在CSTR系统中,物料A进入反应器,发生一阶不可逆化学方应,生成物料B,放出热量,通过外面的夹套冷却剂对反应器降温,为保证过程正常运行,采用串级控制系统控制反应器的液位和温度。根据过程机理,建立CSTR系统的动态机理模型如下:式中,A是反应器截面积,cA是反应器内物料A的浓度,cAF是物料A在进料中的浓度,Cp是反应物比热,CpC是冷却剂比热,E是活化能,h是反应器液位,k0是反应因子,QF进料流量,QC是冷却剂流量,R是气体常数,T是反应器内温度,TC是冷却剂出口温度,TCF是冷却剂入口温度,TF是反应器进料温度,U是换热系数,AC是总的换热面积,ΔH是反应热,ρ是反应物密度,ρC是冷却剂密度。根据动态机理模型,对CSTR系统进行仿真。在仿真过程中,采集反应器进料流量、反应器进料温度、进料中物料A浓度、反应器内温度、反应器液位、反应器出料流量、反应器出料中物料A浓度、冷却剂入口温度、冷却剂出口温度和冷却剂流量10个测量变量。在CSTR系统的仿真过程中加入服从高斯分布的测量噪声,采集900个正常工况下的样本最为训练数据集。另外模拟了6类故障的发生,每一类故障数据分别采集900个样本点,在第201个采样时刻添加故障,6类故障的类型见表2。表2故障类型故障描述F1热传递系数斜坡下降F2反应器温度测量存在偏差F3冷却水调节阀出现粘滞故障F4进料流量出现阶跃变化F5进料温度出现斜坡上升或下降F6冷却水进入温度斜坡上升或下降上述CSTR系统的多变量工业过程故障识别方法,含有以下步骤:(一)收集CSTR系统的正常操作工况数据作为训练数据Xo,计算训练数据Xo的均值mean(Xo)和标准差std(Xo),对训练数据Xo进行归一化处理,获得归一化的训练数据X。利用均值mean(Xo)和标准差std(Xo)通过公式(1)对训练数据Xo进行归一化处理,公式(1)的表达式如下:X=(Xo-mean(Xo))/std(Xo)(1)训练数据Xo经上述公式(1)归一化处理后即可获得归一化后的训练数据X。(二)选择高斯核G(x,y)和多项式核P(x,y)分别作为KSFA算法的核函数,并且给这两类核函数设置一系列不同的核参数,高斯核参数为ci,i=1,2,…,ng,ng为高斯核参数的个数,多项式核参数为dj,j=1,2,…,np,np为多项式核参数的个数。选取的一系列具有不同核参数的高斯核函数和多项式核函数的表达式如下:式中,Gi(x,y)为高斯核函数,Pj(x,y)为多项式函数,ng为高斯核参数ci的个数,np为多项式核参数dj的个数。(三)针对归一化后的训练数据X,建立与每一种具有不同核参数的核函数相对应的基本KSFA模型,利用每个基本KSFA模型从归一化后的训练数据X中提取非线性慢特征。对于归一化后的训练数据X=[x1,x2,…,xn]T,首先计算第i个基本KSFA模型中的核矩阵K(i),K(i)中的每个元素的计算公式如下:归一化核矩阵K(i):式中,IK是n×n维的矩阵,它的每一个元素都为1/n。构造归一化核矩阵的时间变化矩阵式中,是核矩阵中的第k个列向量。开展式(7)中所示的广义特征值分解,公式(7)表示为:保留与前l(i)个最小特征值相对应的特征向量组成负荷矩阵基于第i个基本的KSFA模型从归一化后的核矩阵中提取非线性慢特征:式中,是核矩阵K(i)T中的列向量。(四)根据每个基本KSFA模型的非线性慢特征,计算归一化后的训练数据X对应的监控统计量T2和SPE后,基于给定的置信水平α确定T2(i)和SPE(i)的控制限和利用第i个基本的KSFA模型计算出归一化后的训练数据X的监控统计量T2和SPE,记为:式中,矩阵给定置信水平α,根据核密度估计算法确定T2(i)和SPE(i)的控制限和(五)采集测试数据xto,利用训练数据Xo的均值mean(Xo)和标准差std(Xo)对测试数据xto进行归一化处理,得到归一化后的测试数据xt。利用训练数据Xo的均值mean(Xo)和标准差std(Xo)通过公式(11)对测试数据xto进行归一化处理,公式(11)的表达式如下:xt=(xt-mean(Xo))/std(Xo)(11)测试数据xto经上述公式(11)归一化处理后即可获得归一化后的测试数据xt。(六)基于已建立的每个基本KSFA模型,提取归一化后的测试数据xt的非线性慢特征。其具体步骤如下:计算归一化后的测试数据xt在第i个基本KSFA模型中对应的测试核向量中的每个元素根据下式计算:归一化测试核向量式中,为归一化后的测试核向量,It=1/n[1,…,1]T∈Rn×1,Rn×1表示n×1维的矩阵。利用第i个基本KSFA模型,从归一化后的测试核向量中提取非线性慢特征(七)针对每个基本KSFA模型所提取的非线性慢特征,计算归一化后的测试数据xt的监控统计量T2和SPE,并根据贝叶斯推理规则计算归一化后的测试数据xt是故障数据的概率。其具体步骤如下:根据公式(9)和(10)分别计算测试数据的监控统计量T2和SPE的值;进而根据贝叶斯推理计算出归一化后的测试数据xt是故障数据的概率:概率和的计算公式为:和的计算公式为:式中,分别表示归一化后的测试数据xt被认为是故障数据的概率,和分别表示在第i个基本的KSFA模型的主元空间和残差空间中过程处于正常工况和故障状态的先验概率。给定置信水平α后,和的值设定为1-α,而和的值设定为α。(八)基于在多个基本KSFA模型中归一化后的测试数据xt被认为是故障数据的概率,根据加权组合计算出最终的监控统计量ET2和ESPE,依据ET2和ESPE是否超出置信水平α判断归一化后的测试数据xt是否是故障数据。其具体步骤如下:根据以下的加权组合计算公式将所有基本KSFA模型中归一化后的测试数据xt被认为是故障数据的概率进行融合:当ET2<α且ESPE<α时,认为过程处于正常工况状态;否则,认为过程中出现了故障。检测到故障发生后,为了评价不同监控方法的故障检测效果,通过故障检测时刻(FDT)和故障检测率(FDR)两个性能指标进行不同方法的故障检测效果对比。故障检测时刻(FDT)定义为第一个被认为是故障数据的样本所在的采样时刻,故障检测率(FDR)定义为被检测出是故障数据的样本数目与实际总的故障样本数目之比。很显然,FDT的数值越小,FDR的数值越大,意味着过程监控方法的故障检测效果越好;反之,过程监控方法的故障检测效果越差。在本实施例CSTR仿真中,本发明基于贝叶斯核慢特征分析(Bay-KSFA)的方法分别选用高斯核和多项式核作为核函数,设置高斯核的参数为ci=25000+5000(i-1),i=1,2,…,5,多项式核的参数为dj=j,j=1,2,3。采用核参数c=35000的基于高斯核的慢特征分析(Gau-KSFA)、采用核参数d=2的基于多项式核的慢特征分析(Poly-KSFA)和线性慢特征分析(SFA)这三种方法与本发明的方法进行对比。置信水平取α=0.01,综合对比上述四种方法,以故障F3和F5为例说明故障识别效果。故障F3为冷却水调节阀出现粘滞故障,SFA、Poly-KSFA、Gau-KSFA和Bay-KSFA的故障检测效果见图5(a)-(d)。从图5(a)中可以看出SFA的SPE统计量一直在控制限以下,在故障发生后,不能给出报警。在图5(b)和图5(c)中,虽然Poly-KSFA和Gau-KSFA的SPE监控图在故障发生后能够给出一定的报警,故障检测效果相对于SFA有了改善。但是SPE统计量在各自的控制限上下波动,仍然不能有效的检测出故障。图5(d)给出了Bay-KSFA的故障检测结果,可以看出Bay-KSFA的ET2和ESPE统计量均在第201个时刻发现故障,并且ET2和ESPE的故障检测率均为100%。因此Bay-KSFA对于故障F3具有最好的故障检测效果。故障F5为进料温度斜坡上升,图6(a)显示SFA的T2统计量在第290个采样点检测出故障,SFA的SPE统计量在第266个采样点检测出故障。图6(b)显示Poly-KSFA的T2统计量同样在第290个采样点检测出故障而Poly-KSFA的SPE统计量在第293个采样点检测出故障。单从故障检测时刻上看,SFA的监控效果似乎比Poly-KSFA的监控效果好,但SFA的T2和SPE统计量的故障漏报率明显大于Poly-KSFA。因此从总体而言,Poly-KSFA的监控效果实际上还是优于SFA的监控效果。Gau-KSFA的监控效果有了进一步提高,在图6(c)中,Gau-KSFA的T2统计量在第239个采样点检测出故障,SPE统计量在第244个采样点检测出故障。与上述三种方法相比,Bay-KSFA具有最好的监控效果,从图6(d)中可以看出,它的ET2统计量在第210个采样点检测出故障,ESPE统计量在第214个采样点检测出故障。表3和表4分别给出了SFA、Poly-KSFA、Gau-KSFA、Bay-KSFA这四种方法对于6种故障的故障检测时间和故障检测率。表3表4从表3和表4可以看出,对于阶跃故障F2和F4,这四种方法均能在第201个时刻检测到故障方法,故障检测率均为100%。但是对于阶跃故障F3和斜坡故障F1、F6和F7,Bay-KSFA方法都具有最短的故障检测时间和最高的故障检测率。综合以上分析,本发明的Bay-KSFA方法的故障检测效果明显优于其它三种方法。以上所举实施例仅用为方便举例说明本发明,并非对本发明保护范围的限制,在本发明所述技术方案范畴,所属
技术领域:
的技术人员所作各种简单变形与修饰,均应包含在以上申请专利范围中。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1