一种基于软测量技术的催化剂活性检测方法与流程
本发明涉及化剂活性检测技术领域,尤其是一种基于软测量技术的催化剂活性检测方法。
背景技术:
石油化工是是国民经济的重要支柱产业之一,石油化工产品提供了90%以上的交通运输燃料、润滑剂和有机化工原料。合理优化控制生产过程是石油化工企业提高生产效率、节能减排、实现智能转型发展的必由之路。随着现代石化企业对优化控制的要求不断提高,各种非常规、高难度的测量要求也日益增多。一方面,需要测量与生产过程优化控制密切相关的各类变量信息,包括产品质量、工艺参数等;另一方面,测量的精度、稳定性和实时性要求越来越高,测量从静态向动态发展。其中,催化剂活性的测量分析是当前亟待解决的重要问题。
在现代炼油过程中,随着工艺复杂性不断提高,包括催化裂化、加氢裂化、催化重整等80%以上的炼油过程都是催化过程。此外,重油深度转化、清洁燃料生产等炼油重大业务的发展均离不开相关催化剂研发和应用核心技术的支撑。炼油技术进步主要体现在催化剂的技术进步。在石化生产过程中,催化剂的活性不仅受到生产过程中高温、高压等苛刻操作环境的影响,还与进料量、进料速率等操作工艺相关,催化剂容易因结焦、中毒、结构变化等原因造成失活。因此,对催化剂活性的分析可以用于指导生产环境和操作工艺,从而提高生产效率和催化剂利用率。
催化剂活性的实时检测对于保证产品质量、生产装置连续平稳操作以及充分发挥装置的生产能力都有举足轻重的作用。然而,石化生产过程涉及物理、化学反应包含复杂的物质转化和能量转换过程,催化剂活性难以直接用传感器进行测量。
针对上诉问题,本发明人设计了一种基于软测量技术的催化剂活性检测方法。
技术实现要素:
本发明的目的在于提供一种基于软测量技术的催化剂活性检测方法,通过容易测量的过程变量与难以直接测量的催化剂活性之间的数学关系,间接测量催化剂活性,并通过在线的模型结构和参数自适应调整,实现对催化剂活性高效、准确地预测。
为了实现上述目的,本发明采用如下技术方案:
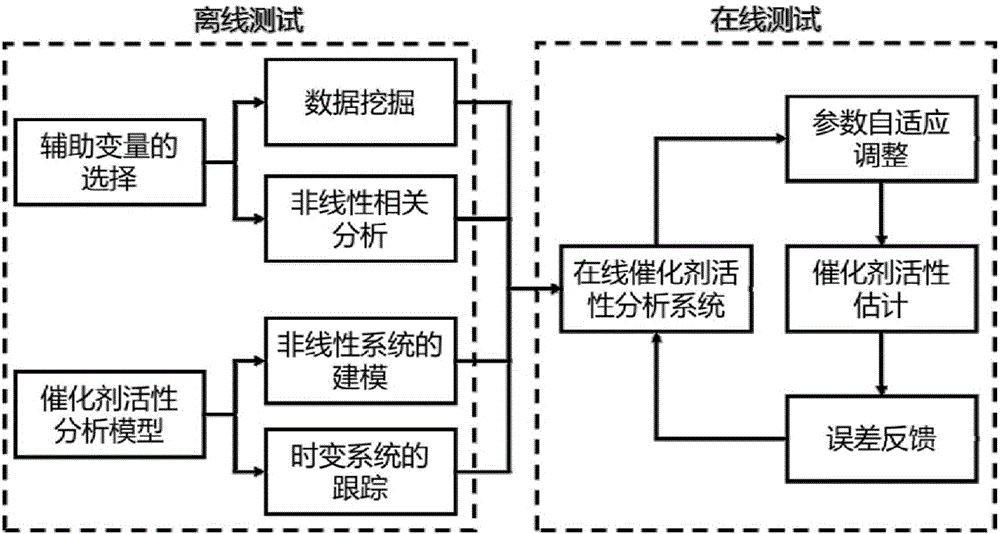
一种基于软测量技术的催化剂活性检测方法,包括离线测试和在线测试两部分,其具体包括以下步骤:
一、系统建模:建立催化剂活性与辅助变量之间的数学模型,该模型的基本结构采用单隐层的径向基神经网络,模型无限逼近任何非线性系统,并采用模型结构自适应的方式来确定合适的隐层中心数和中心位置,而宽度参数采用交叉验证法来确定,模型训练过程中模拟实时数据输入和相关异常扰动,使模型能跟踪复杂的时变系统;
二、辅助变量选取:基于工艺理解的方式定位与催化剂活性相关的过程变量,过程变量包括反应过程中的温度、压强、反应物和产物浓度,再采用基于核回归的非相关性分析法从过程变量中选出可以作为后续分析的辅助变量;
三、数据采集:利用传感器从实际生产过程中实时地采集步骤二所述辅助变量的数据;
四、数据预处理:针对步骤三采集到的数据进行预处理,预处理流程依次包括数据清理、数据融合、数据变换和数据归约;
五、离线测试:根据步骤四预处理之后的数据对模型进行训练,完成模型结构选择和参数确定,并初步验证催化剂活性估计是否有效;
六、在线检测:将实时采集的数据带入训练后的模型来分析催化剂活性,给出催化剂活性估计结果,此过程中采用误差反馈的方式来实时调整模型结构和参数。
优选的,步骤一种,模型采用单隐层的径向基神经网络模型,模型包括输入层、隐层和输出层,模型输入为选定的辅助变量,输出为生产过程的反应速率,t时刻模型的输出f(Xt)用函数方程可表示为:
f(Xt)=PtTθt-1 (1)
其中,Xt=[xt(1),xt(2),……,xt(Nx)]T,
θt-1=[ωt-1(1),ωt-1(2),……,ωt-1(M)]T,
P(Xt)=[g1(Xt),g2(Xt),……,gM(Xt)]T,
这里Xt是t时刻的输入样本,维度为Nx,Wt-1是隐层到输出层的参数,g(Xt)是隐层径向基函数,选用高斯核函数:
其中Cp=[cp(1),cp(2),……,cp(Nx)]T是第p个中心的位置,σ是宽度参数,决定高斯函数的形状(扁平或窄高),宽度取值与隐层中心之间的最大距离dmax和中心数M有关,由式(3)确定,c是可调节的正实数;
在离线测试中对模型进行训练,包括:用大量历史样本中选择中心位置,用小二乘法确定参数θ,完成RBF-NN模型的初始化;
在线测试时将实时采集的数据带入训练后的模型来分析催化剂活性,包括:对于t时刻的模型结构和参数采用t-1之前的时刻的进行确定,时刻间隔步长λ,实时模型预测效果由λ个输出值与真实值对比决定,并进而计算各个隐层中心的贡献度;
第p个中心Cp的贡献度由包含Cp的模型和不包含Cp的模型分别测试的预测误差变化大小来作为判断依据,如果不包含Cp时模型预测误差增大很多,则说明Cp的贡献度大,反之则贡献度小,每次选择一个中心作为t时刻的待弃中心;
而对于λ个相近时刻的样本,依次作为中心引入模型,采用类似的办法,评判其贡献度,将贡献度最大的中心最为考察中心,如果考察中心的贡献度大于待弃中心,则剔除待弃中心,引入考察中心,此时模型的参数也随之调整。
进一步的,具体的建模步骤包括:
1-1、模型结构初始化,从历史样本集中选择合适大小样本作为隐层中心;
1-2、参数初始化,用最小二乘法来确定初始模型参数;
1-3、t时刻,模型结构和参数自适应调整;
1-3-1、选择待弃中心:选择t时刻之前的时间间隔步长为λ的数据,分别计算包含中心Cp(p=1,2,3,……,M)和不包含中心Cp的模型预测均方误差增大量Δerrp,从而计算出各个中心的贡献度Dp:
比较各个中心的贡献度,将贡献度最小的中心作为待弃中心;
1-3-2、选择考察中心:用λ个相近时刻样本作为中心Cj(j=1,2,3,……,λ),分别替代待弃中心引入模型,用(3.1)的方法计算贡献度Dj(j=1,2,3,……,λ),选出其中贡献度最大的Dj,max所对应的中心作为考察中心;
1-3-3、比较Dp和Dj,max,若Dp≥Dj,max,模型结构不变,若Dp<Dj,max,则用考察中心替代待弃中心,模型结构发生变化;
1-3-4、调整模型参数;
重复步骤1-3,直至测试结束。
优选的,所述步骤二中,再采用基于核回归的非相关性分析法从过程变量中选出可以作为后续分析的辅助变量,包括:
构造非线性函数,拟合变量之间的关系,双变量之间的关系为x1=ax2+b;
采用基于核方法的典型相关性分析法,分别将变量x1和x2的数据映射到高维,然后进行相关性计算;
用K(ab)=φ(a)φ(b)构建了一个非线性映射到高维特征空间(4),如下:
然后得到矩阵再由奇异值分解,得到矩阵K最大特征值对应的两个特征向量α1和α2,从而计算和之间的相关系数,即为x1和x2之间的相关性;
根据分析出的相关性结果从过程变量中选出可以作为后续分析的辅助变量。
优选的,所述步骤四中:
数据的清理具体是对异常数据的过滤和缺失数据的插补,过滤方法采用“3σ准则”,去除在数据样本均值3倍样本方差之外的数据;缺失数据的插补方法则采用均值插补、线性插补和/或函数插补;
数据的变换包括数据平滑和当量化处理,数据平滑采用均值滤波等方式来处理;
数据归约是针对大规模、多维度的数据进行有效特征提取和数据压缩,数据归约采用主成分分析法。
采用上述方案后,本发明有益效果是,本发明通过容易测量的过程变量(辅助变量)与难以直接测量的催化剂活性之间的数学关系,从而间接测量催化剂活性,并通过在线的模型结构和参数自适应调整,实现高效、准确预测。
下面结合附图对本发明做进一步的说明。
附图说明
图1是本发明提出的基于软测量技术的催化剂活性检测的流程图。
图2是单隐层的径向基神经网络的模型结构示意图。
具体实施方式
如图1所示本实施例揭示的一种基于软测量技术的催化剂活性检测方法,具体包括以下步骤:
一、系统建模:建立催化剂活性与辅助变量之间的数学模型,该模型的基本结构采用单隐层的径向基神经网络,模型无限逼近任何非线性系统,并采用模型结构自适应的方式来确定合适的隐层中心数和中心位置,而宽度参数采用交叉验证法来确定,模型训练过程中模拟实时数据输入和相关异常扰动,使模型能跟踪复杂的时变系统;
二、辅助变量选取:基于工艺理解的方式定位与催化剂活性相关的过程变量,过程变量包括反应过程中的温度、压强、反应物和产物浓度,再采用基于核回归的非相关性分析法从过程变量中选出可以作为后续分析的辅助变量;
三、数据采集:利用传感器从实际生产过程中实时地采集步骤二所述辅助变量的数据;
四、数据预处理:针对步骤三采集到的数据进行预处理,预处理流程依次包括数据清理、数据融合、数据变换和数据归约;
五、离线测试:根据步骤四预处理之后的数据对模型进行训练,完成模型结构选择和参数确定,并初步验证催化剂活性估计是否有效;
六、在线检测:将实时采集的数据带入训练后的模型来分析催化剂活性,给出催化剂活性估计结果,此过程中采用误差反馈的方式来实时调整模型结构和参数。
优选的,步骤一中,模型采用单隐层的径向基神经网络模型(Radial Basis Function Neural Network,RBF-NN),参见图2,模型包括输入层、隐层和输出层,模型输入为选定的辅助变量,输出为生产过程的反应速率,t时刻模型的输出f(Xt)用函数方程可表示为:
f(Xt)=PtTθt-1 (1)
其中,Xt=[xt(1),xt(2),……,xt(Nx)]T,
θt-1=[ωt-1(1),ωt-1(2),……,ωt-1(M)]T,
P(Xt)=[g1(Xt),g2(Xt),……,gM(Xt)]T,
这里Xt是t时刻的输入样本,维度为Nx,Wt-1是隐层到输出层的参数,g(Xt)是隐层径向基函数,选用高斯核函数:
其中Cp=[cp(1),cp(2),……,cp(Nx)]T是第p个中心的位置,σ是宽度参数,决定高斯函数的形状(扁平或窄高),宽度取值与隐层中心之间的最大距离dmax和中心数M有关,由式(3)确定,c是可调节的正实数;
模型的结构和参数θ的自适应需要由离线测试和在线测试两个环节来进行。在离线测试中需要用大量历史样本,选择适当的模型结构,并从样本中选择中心位置,用小二乘法确定参数θ,从而完成RBF-NN模型的初始化。在线测试时,对于t时刻的模型结构和参数采用t-1之前的时刻的进行确定,时刻间隔步长λ(λ为正实数),实时模型预测效果由λ个输出值与真实值对比决定,并进而计算各个隐层中心的贡献度,第p个中心Cp的贡献度由包含Cp的模型和不包含Cp的模型分别测试的预测误差变化大小来作为判断依据,如果不包含Cp时模型预测误差增大很多,则说明Cp的贡献度大,反之则贡献度小,每次选择一个中心作为t时刻的待弃中心,而对于λ个相近时刻的样本,依次作为中心引入模型,采用类似的办法,评判其贡献度,将贡献度最大的中心最为考察中心,如果考察中心的贡献度大于待弃中心,则剔除待弃中心,引入考察中心,此时模型的参数也随之调整。
进一步的,本实施例采用的建模方式不好看步骤:
1-1、模型结构初始化,从历史样本集中选择合适大小样本作为隐层中心;
1-2、参数初始化,用最小二乘法来确定初始模型参数;
1-3、t时刻,模型结构和参数自适应调整;
1-3-1、选择待弃中心:选择t时刻之前的时间间隔步长为λ的数据,分别计算包含中心Cp(p=1,2,3,……,M)和不包含中心Cp的模型预测均方误差增大量Δerrp,从而计算出各个中心的贡献度Dp:
比较各个中心的贡献度,将贡献度最小的中心作为待弃中心;
1-3-2、选择考察中心:用λ个相近时刻样本作为中心Cj(j=1,2,3,……,λ),分别替代待弃中心引入模型,用(3.1)的方法计算贡献度Dj(j=1,2,3,……,λ),选出其中贡献度最大的Dj,max所对应的中心作为考察中心;
1-3-3、比较Dp和Dj,max,若Dp≥Dj,max,模型结构不变,若Dp<Dj,max,则用考察中心替代待弃中心,模型结构发生变化;
1-3-4、调整模型参数;
重复步骤1-3,直至测试结束。
步骤二中,本发明采用的相关性分析法是非线性的相关性分析法,有别于传统的线性相关性分析,线性相关性分析通常是构造线性函数,双变量之间的关系为x1=ax2+b,而实际生产中过程变量由于自身具有非线性特征,变量之间的相关性则呈现更为复杂的线性相关性。
因此步骤二中,再采用基于核回归的非相关性分析法从过程变量中选出可以作为后续分析的辅助变量,包括:
构造非线性函数,拟合变量之间的关系,双变量之间的关系为x1=ax2+b;
采用基于核方法的典型相关性分析法,分别将变量x1和x2的数据映射到高维,然后进行相关性计算;由于非线性函数种类繁多,基于核方法的典型相关性分析法可提高效率,该方法具体如下:
用K(ab)=φ(a)φ(b)构建了一个非线性映射到高维特征空间(4),如下:
然后得到矩阵再由奇异值分解,得到矩阵K最大特征值对应的两个特征向量α1和α2,从而计算和之间的相关系数,即为x1和x2之间的相关性;
根据分析出的相关性结果从过程变量中选出可以作为后续分析的辅助变量。
优选的,所述步骤四中:
原始数据要的预处理包括数据清理、数据融合、数据变换和数据归约四个流程,数据的清理主要是对异常数据的过滤和缺失数据的插补,过滤方法可采用“3σ准则”,去除在数据样本均值3倍样本方差之外的数据;缺失数据的插补方法则有均值插补、线性插补和函数插补,应结合数据的缺失情况和数据的变化趋势来选取合适的方法。
数据的变换包括数据平滑和当量化处理,数据平滑可采用均值滤波等方式来处理,减少数据的异常波动,当量化处理可减少不同变量数据的数量级差别对后续建模的影响。
数据归约是针对大规模、多维度的数据进行有效特征提取和数据压缩,从而减少异常干扰和模型的计算量,常用的方法有主成分分析法等。上述说明示出并描述了本发明的优选实施例,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!