基于集成变量选择型偏最小二乘回归的软测量方法与流程
本发明涉及一种工业过程软测量方法,尤其是涉及一种基于集成变量选择型偏最小二乘回归的软测量方法。
背景技术:
在现代流程工业过程中,实时测量与监控产品的质量指标或其他某些能间接反映产品质量的指标是保证产品质量稳定性的最直接最简单的途径。相比于温度、流量、压力等容易测量的数据信息而言,这些能直接或间接反映产品质量信息的关键变量通常不是那么容易获取的。以液体产品的浓度为例,获取浓度信息可通过在线分析仪实时测量,也可通过人工采集液体样本进行离线分析,两种手段各有优劣。在线分析仪虽能保证实时测量到的质量信息,但设备价格高昂,而且后期维护成本较高。离线分析手段所需设备价格低廉,但会造成严重的滞后,无法及时反映当前质量状况。在这种背景下,软测量技术应运而生,其基本思想在于:先利用生产过程历史数据建立回归模型,后在线利用与之相关的其他容易测量的变量(如温度、压力、流量等),估计出该难以测量变量的数值以便实时监控产品的质量信息。
查阅已有的文献与专利,可以发现实施软测量的方法主要有:统计回归法、神经网络、支持向量回归等。通常来讲,在数据量非常充分以及非线性特性很强的条件下,利用神经网络或支持向量回归建立相应的软测量模型,通常能取得较好的软测量效果,但是这类方法在模型更新时会受限于训练耗时大的问题。相比之下,统计回归法所需的数据量较小,而且训练时间很短,可较好的适应于模型更新,已越来越多地被应用在软测量建模领域。偏最小二乘回归(partialleastsquareregression,plsr)是最常用的统计回归算法,各种改进举措层出不穷。plsr算法旨在最大化输入数据与输出数据间的协方差,这里的输入数据通常是历史数据库中容易测量的数据(如温度、压力、流量等),而输出数据一般是直接或间接反映产品质量信息的测量数据(如浓度、成分比等)。然而,若是输入数据中包含了很多与输出不怎么相关的干扰变量的测量数据,plsr模型的回归拟合精度会受到很大影响。由于软测量方法通常针对的都是数据,直接通过数据剔除与输出不相关的测量变量是非常困难的。若是依赖生产机理或操作人员经验,那么相应的plsr模型建立方法不具备通用性,而且对机理知识或经验的正确性要求也非常高。
为此,科研文献中出现了很多关于输入数据变量选择的方法以改进plsr模型的回归精度,较常见的有回归系数plsr法(β-plsr)、变量重要性plsr法(vip-plsr)、无益变量剔除plsr法(uve-plsr)等。不同的选择方法揭示训练数据不同的潜在特征,但直至目前为止,还没有文献或专利直接证明哪种变量选择方法无论针对何种工业对象的采样数据始终是最佳的。针对某一个工业过程对象,确定哪种方法最合适实际上只有通过数据验证才能知晓。考虑到现代流程工业的时变特性,环境以及设备状态在不断变化,相应采样数据的特征同样是在变化的。可能某一段时间类采样数据适合于某种变量选择法,而另一时间段的采样数据却适合于使用另外一种变量选择方法。因此,工业过程的时变特性给变量选择型plsr方法的适用性提出了新的挑战。因此,丞待设计出一种能应对这种数据变化特性的变量选择型plsr软测量方法。
技术实现要素:
本发明所要解决的主要技术问题是:在实际应用中,很难确定哪种变量选择型plsr方法最适合于为当前数据建立软测量模型。为此,本发明提供一种基于集成变量选择型偏最小二乘回归的软测量方法。该方法首先同时使用多种变量选择方法建立一个集成变量选择型plsr模型。其次,在线实施软测量时,利用该集成变量选择型plsr模型计算得到多个输出估计值。最后,通过加权计算得到最终的输出估计值。
本发明解决上述技术问题所采用的技术方案为:一种基于集成变量选择型偏最小二乘回归的软测量方法,包括以下步骤:
(1)利用集散控制系统收集工业生产过程中容易测量的数据组成软测量模型的输入训练数据矩阵x∈rn×m,并对其进行标准化处理使各个过程变量的均值为0,标准差为1,得到新数据矩阵
(2)采用离线分析手段获取与输入训练数据x相对应的产品质量数据组成输出训练数据y∈rn×1,计算向量y的均值μ与标准差ε,并对其进行标准化处理得到新数据向量
(3)利用plsr算法建立输入数据
(4)分别实施β-plsr、vip-plsr、和uve-plsr方法,建立相应的软测量模型。
(5)利用β-plsr、vip-plsr、和uve-plsr模型计算对应于输出
(6)再次利用plsr算法建立新输入z与输出
(7)收集新的容易测量的数据xt∈rm×l,并对其进行与x相同的标准化处理得到
(8)分别利用β-plsr、vip-plsr、和uve-plsr模型计算得到t时刻的输出估计值
(9)通过加权法计算t时刻的输出估计值
与现有技术方法相比,本发明方法的主要优势在于:同时建立了三个不同的变量加权型plsr软测量模型,并通过加权的方式集成得到最终的输出估计值,在线实施软测量值时不再拘泥于单个的变量加权型plsr模型,而是采用多个软测量模型集成的方式,巧妙地避免了确定哪种变量选择型plsr方法最适合于为当前数据建立软测量模型这一难题。此外,本发明方法通过plsr算法计算出来的回归系数向量来对各模型输出估计值进行适当加权,不仅不需要反复验证某个变量选择方法的适用性,而且还可以进一步地提高软测量模型的精度。可以说,本发明方法是在已有工作的基础上,利用集成建模思路有效地提升变量选择型plsr方法用于软测量建模的适用性。
附图说明
图1为本发明方法的实施流程图。
图2为plsr算法迭代求取回归模型的流程示意图。
具体实施方式
下面结合附图对本发明方法进行详细的说明。
如图1所示,本发明涉及了一种基于集成变量选择型偏最小二乘回归的软测量方法,该方法的具体实施步骤如下所示:
步骤1:利用集散控制系统收集工业生产过程中容易测量的数据组成软测量模型的输入训练数据矩阵x∈rn×m,并对其进行标准化处理使各个过程变量的均值为0,标准差为1,得到新数据矩阵
步骤2:采用离线分析手段获取与输入训练数据x相对应的产品质量数据组成输出训练数据y∈rn×l,计算向量y的均值μ与标准差ε,并对其进行标准化处理得到新向量
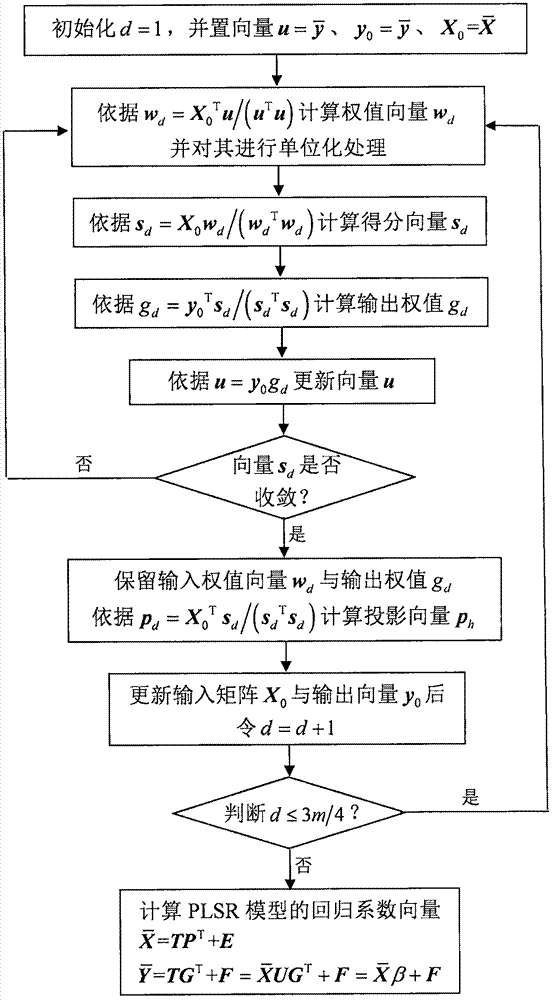
步骤3:利用plsr算法建立输入数据
其中,
①初始化d=1,并设置向量
②依据公式wd=x0tu/(utu)计算输入权值向量wd,并用公式wd=wd/||wd||单位化向量wd;
③依据公式sd=x0wd/(wdtwd)计算得分向量sd;
④依据公式gd=y0tsd/(sdtsd)计算输出权值gd;
⑤依据公式u=y0gd更新向量u;
⑥重复②~⑤直至sd收敛(即向量sd中各元素不再变化);
⑦保留输入权值向量wd与输出权值gd,并依据公式pd=x0tsd/(sdtsd)计算投影向量ph;
⑧依据如下两式更新输入矩阵x0与输出向量y0:
x0=x0-sdpdt(2)
y0=y0-sdgd(3)
⑨令d=d+1后,若d≤3m/4,重复②~⑧求解下一个wd、gd、和pd;若d>3m/4,则执行⑩;
⑩将得到的所有输入权值向量组成矩阵w=[w1,w2,…,wd]、所有输出权值向量组成行向量g=[g1,g2,…,gd]、以及所有投影向量组成矩阵p=[p1,p2,…,pd],那么plsr模型中的投影变换矩阵为u=w(ptw)-1,d个得分向量组成的矩阵为
步骤4:分别实施β-plsr、vip-plsr、和uve-plsr方法,建立相应的软测量模型,具体的操作步骤如下所示:
实施β-plsr方法的具体步骤为:
①对回归系数向量β中各元素求取绝对值得到新向量b,并计算向量b的均值,记为α;
②找出向量b中大于α的元素,并将相应的位置标号存放于位置标号集θ1中;
③根据记录的位置标号θ1,从输入数据矩阵
④利用plsr算法建立输入x1与输出
实施vip-plsr方法的具体步骤为:
①初始化h=1;
②根据如下所示公式计算输入数据矩阵
其中,wj,h表示向量wj中的第h个元素,符号||||表示计算向量的长度。
③判断h<m?若是,置h=h+1后,若返回②计算下一个变量的重要性;若否,执行下一步骤④;
④找出向量v=[v1,v2,…,vm]中大于1的元素,并将相应的位置标号存放于位置标号集θ2中;
⑤根据记录的位置标号θ2,从输入数据矩阵
⑥利用plsr算法建立输入x2与输出
实施uve-plsr方法的具体步骤为:
①随机产生一个n×m的数据矩阵n,矩阵n中各元素都是在区间[0,1]上均匀分布的随机数;
②对矩阵n中各列进行标准化处理得到
③利用plsr算法建立输入
④将向量
⑤找出向量b1中绝对值大于δ的元素,并将相应的位置标号存放于位置标号集θ3中;
⑥根据记录的位置标号θ3,从输入数据矩阵
⑦利用plsr算法建立输入x3与输出
步骤5:按照如下所示公式,分别利用β-plsr、vip-plsr、和uve-plsr模型中的回归系数向量β1,β2,β3计算对应于输出
yk=xkβk(5)
上式中,下标号k=1,2,3。并将其组成新的输入矩阵z=[y1,y2,y3]∈rn×3。
步骤6:再次利用plsr算法建立新输入z与输出
步骤7:收集新的容易测量的数据xt∈rm×l,并对其进行与x相同的标准化处理得到
步骤8:依据位置标号集θ1,θ2,θ3分别从向量
步骤9:根据如下所示公式,利用β-plsr、vip-plsr、和uve-plsr模型中的回归系数向量分别计算得到t时刻的输出估计值
步骤10:通过加权法计算t时刻的输出估计值
上述实施例只用来解释本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!