一种采用案例推理提取规则的垃圾焚烧炉温度模糊控制方法与流程
本发明涉及城市固体垃圾焚烧炉温度控制技术领域,更具体来说,本发明是一种采用案例推理提取规则的垃圾焚烧炉温度模糊控制方法。
背景技术:
垃圾焚烧过程具有多变量、强耦合、非线性、大惯性及大滞后等特征,传统的控制方法难以实现炉温的稳定、准确控制,可能会使得焚烧后烟气中的二噁英浓度超标,对人和环境造成严重的损害。因此,稳定而准确的炉温控制对减少排放具有重要的实际意义。
模糊控制是一种以模糊控制规则为核心的控制方法,相对于传统的比例-积分-微分(proportional-integral-differential,pid)控制方法来说,它特别适合于无法建立准确机理模型,具有大惯性、强非线性的过程控制领域,比如在工业过程的温度控制中,实践证明模糊控制比单纯的pid控制方法在快速性方面更具优势。而作为模糊控制的核心,模糊控制规则的成功提取是控制系统成功应用的关键。因而,设计一个模糊控制系统之前,必须提取出合理的控制规则。
模糊控制规则的提取过程主要是根据控制过程中产生的样本数据来进行,常见的提取方法有神经网络、专家经验、遗传算法、wang-mendel算法等,已经取得一些实际应用成效。然而,由于这些方法本身固有的一些缺陷又限制了它们的推广应用,比如,神经网络虽然可以根据样本数据间接提取规则,但对训练样本的要求较高,且训练时间较长,不能满足那些对实时性要求较高的过程需求;专家经验提取的规则往往只能适用于比较简单的控制系统设计,当面临多变量系统或模糊集划分过多的情况时,规则的合理性难以得到满足;采用遗传算法提取规则时,需要反复训练导致效率较低,且易于陷入局部最优;wang-mendel算法虽然简单实用,但不具备学习推理能力,在应用时适应性和鲁棒性较差。基于上述,这些方法提取控制规则的过程存在计算量大的缺陷,提取出的规则有合理性差的局限性,难以实现控制要求高的场合,在现实中难以推广应用。因此,如何从样本数据中获取有效的规则以保证被控变量的稳定而准确的控制具有重要的现实意义。
案例推理以认知学为基础,是人工智能领域一种机器学习与推理方法,它以知识获取方便、求解过程易于理解、效率高及学习推理能力强等特点得到了广泛应用。因此,本发明利用案例推理的学习和推理能力强的优势,对城市固体垃圾焚烧炉的炉温控制规则进行提取。
技术实现要素:
针对上述问题,本发明提供一种采用案例推理提取规则的垃圾焚烧炉温度模糊控制方法,可实现炉温的稳定、准确控制。
为达到上述目的,本发明采用如下技术方案:
一种采用案例推理提取规则的垃圾焚烧炉温度模糊控制方法,其特征在于包括以下步骤:(1)对炉温偏差及其变化率、控制器输出的历史数据采用相似度评估法聚类相似数据;(2)依据最大隶属原则生成初始规则库;(3)采用相似度评估法删除冗余规则以约简规则库;(4)计算目标规则与约简规则库中的每一条规则的相似度以检索规则;(5)根据最近邻方法重用规则,从而构成模糊控制规则库;(6)温度控制器对炉温实现稳定、准确控制。
进一步具体包括如下步骤:
(1)对炉温偏差及其变化率、控制器输出的历史数据采用相似度评估法聚类相似数据,详细过程如下:
首先,将控制器输入变量(炉温偏差x1及其变化率x2)和控制器输出变量x3的p组历史数据构成案例库c,c中的每一组历史数据称为源案例,每一个源案例可表示为:
其中,
其次,对式(1)中各变量的数据依据下式进行归一化:
归一化后式(1)所表示的每个源案例可表示为
ck:(x1,k,x2,k;x3,k),k=1,2,…,p(3)
再次,设xi(i=1,2,3)的论域xi(i=1,2,3)={-3,-2,-1,0,1,2,3},将xi(i=1,2,3)划分为n个模糊集;
然后,对x1进行聚类,设x1的n个模糊集对应的聚类中心为:
其中,
设定相似度阈值sim1,将sim1,n,k大于sim1的所有源案例进行聚类,形成x1的n个聚类簇;
最后,在上述形成的n个聚类簇的基础上对x2进行聚类,设x2的n个模糊集对应的聚类中心为:
其中,
其中
(2)依据最大隶属原则生成初始规则库;设xi(i=1,2,3)的语言变量分别为e、ec、u,相应的语言值分别为{负大(nb),负小(ns),零(z),正小(ps),正大(pb)};取xi(i=1,2,3)的值域到相应论域xi(i=1,2,3)的比例因子分别为k1、k2、k3;采用三角型隶属函数,依据比例因子ki(i=1,2,3)与上述生成的q个聚类簇中的p'个源案例,并利用三角隶属函数公式计算出这些源案例中xi(i=1,2,3)的隶属度,并依据最大隶属原则生成p'条初始规则;
(3)采用相似度评估法删除冗余规则以约简规则库;对上述的p'条初始规则,依据式(5)的相似度评估方法计算这些规则之间的相似度,并删除相似度为1的重复规则,获得最简规则库
其中,m为规则总数;
(4)计算目标规则与约简规则库中的每一条规则的相似度以检索规则;根据xi(i=1,2)的语言变量e和ec及其相应的语言值,采用笛卡尔积创建以x1和x2的规则归一化值为输入条件的目标规则集
其中,
根据最近邻方法,对每一条目标规则
(5)根据最近邻方法重用规则,从而构成模糊控制规则库;对上述检索出的规则,重用其结论,得到式(8)中待求解的
(6)基于上述的模糊控制规则库,设计模糊控制器,进而对炉温实现稳定、准确控制;
本发明与现有技术相比,具有以下优点:1、本发明利用垃圾焚烧炉温控制的历史数据,采用案例推理方法建立了模糊控制规则库,所需时间较短,有利于实时应用;2、避免了专家经验制定模糊控制规则的主观性;3、采用案例推理方法提取的规则能够保证其有效性,使得炉温的控制稳定而准确,对于减少污染排放有重要意义。
附图说明
图1是案例推理提取模糊控制规则的原理图;
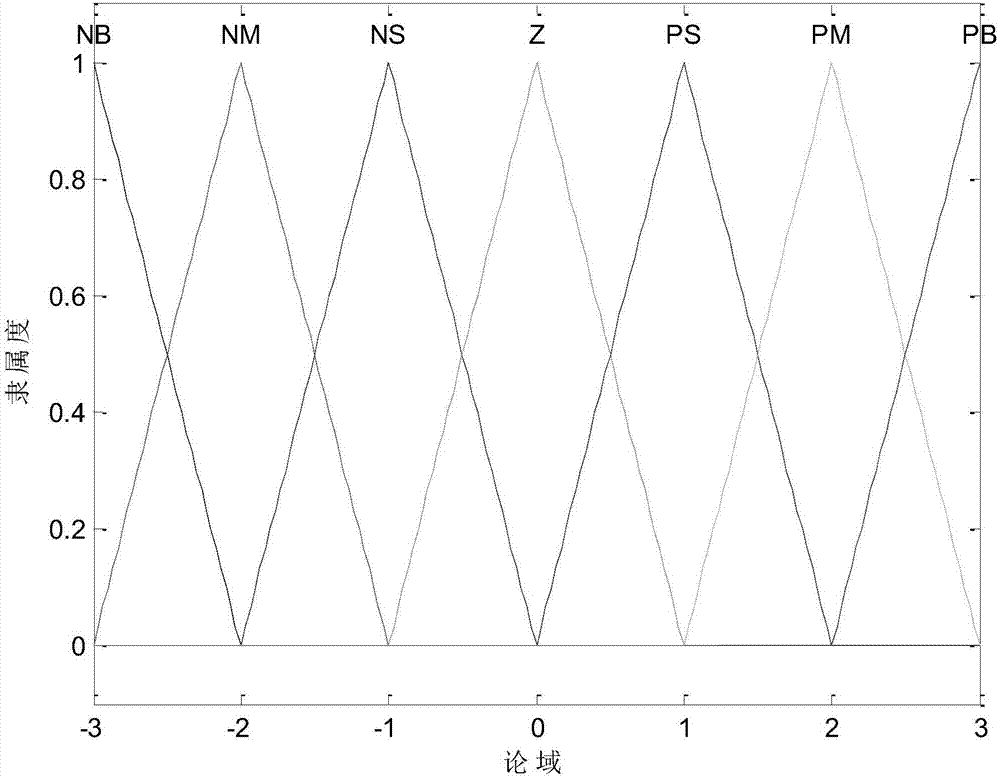
图2是炉温偏差及其变化率、控制器输出的隶属函数。
具体实施方式
样本数据来自某垃圾焚烧处理厂炉温控制过程中产生的1000组数据。控制器输入变量(炉温偏差x1及其变化率x2)和控制器输出变量x3的值域分别为:x1∈[-1.5,0.3]、x2∈[-1.8,2.6]、x3∈[-1.6,7.7]。下面结合附图对本发明的具体实施方式做进一步说明。
一种采用案例推理提取规则的垃圾焚烧炉温度模糊控制方法,其特征在于包括以下步骤:
(1)聚类相似数据;对控制器输入变量(炉温偏差x1及其变化率x2)和控制器输出变量x3的1000组历史数据采用相似度评估法进行聚类,详细过程如下:
首先,将上述1000组历史数据构成案例库c,c中的每一组历史数据称为源案例,每一个源案例可表示为:
其中,
其次,对式(1)中各变量的数据依据下式进行归一化:
归一化后式(1)所表示的每个源案例可表示为
ck:(x1,k,x2,k;x3,k),k=1,2,…,1000(3)
再次,设xi(i=1,2,3)的论域xi(i=1,2,3)={-3,-2,-1,0,1,2,3},将xi(i=1,2,3)划分为5个模糊集,其中,x1的5个模糊集分别为[0,0.734]、[0.667,0.8004]、[0.734,0.8674]、[0.8004,0.9338]、[0.8674,1],x2的5个模糊集分别为[0,0.2002]、[0.182,0.2184]、[0.2002,0.2366]、[0.2184,0.2548]、[0.2366,1];
然后,对x1进行聚类,设x1的5个模糊集对应的聚类中心为:
其中,
设定相似度阈值sim1=0.7,将sim1,n,k大于0.7的所有源案例进行聚类,形成x1的5个聚类簇,各簇中的源案例总数分别为110、16、824、50、20个;
最后,在上述形成的5个聚类簇的基础上对x2进行聚类,设x2的5个模糊集对应的聚类中心为:
其中,
(2)生成初始规则库;设xi(i=1,2,3)的语言变量分别为e、ec、u,相应的语言值分别为{负大(nb),负小(ns),零(z),正小(ps),正大(pb)};取xi(i=1,2,3)的值域到相应论域xi(i=1,2,3)的比例因子分别k1=25,k2=1.7,k3=1;采用图2所示的三角型隶属函数,依据比例因子ki(i=1,2,3)与上述生成的19个聚类簇中的1036个源案例,并利用三角隶属函数公式计算出这些源案例中xi(i=1,2,3)的隶属度,并依据最大隶属原则生成1036条初始规则;
(3)约简规则库;对上述的1036条初始规则,依据式(5)的相似度评估方法计算这些规则之间的相似度,并删除相似度为1的重复规则,获得最简规则库
其中,
(4)检索规则;根据xi(i=1,2)的语言变量e和ec及其相应的语言值,采用笛卡尔积创建以x1和x2的规则归一化值为输入条件的目标规则集
其中,
根据最近邻方法,对每一条目标规则
(5)重用规则并构成模糊控制规则库;对上述检索出的规则,重用其结论,得到式(8)中待求解的
(6)温度控制器对炉温实现稳定、准确控制;基于上述的模糊控制规则库,采用模糊控制算法设计温度控制器并应用实际,从而实现炉温的稳定、准确控制。
- 还没有人留言评论。精彩留言会获得点赞!