一种非线性过程监控方法与流程
本发明涉及一种非线性过程监控方法,适用于工业生产过程监控。
背景技术:
工业生产环境通常处于超高温、超低温、超高压或真空等极端环境,如果因为人为原因操作不当或客观不可抵抗的自然因素所导致的生产故障,轻则生产被迫中断,重则发生火灾、爆炸、泄露毒气等重大生产事故,不仅给企业生产带来了巨大的经济损失,而且严重危害人身安全、社会公共安全。因此,如何使这类工业生产过程安全正常地运行,早已是越来越多的人关注过程监控技术的原因之一。然而,随着生产过程日益复杂化,过程数据呈现“爆炸性”增长,现阶段过程监控面临着如下一系列新问题:
(1)不确定性。现阶段的工业过程普遍存在庞杂的生产机理,从而容易诱发许多干扰,在传统监控技术中大多数干扰无法测量,甚至没办法有效消除。一般来说,不确定的来源可分为两类:不可预知输入和不可预知动态。传统过程监控中所设计的数学模型通常都是被控对象的简单近似,不仅会丢失部分影响生产的关键干扰因素,所会与实际工业生产情况相差较大,较难获得好的监控效果。
(2)多变量性和强耦合性。现阶段工业生产都会产生了数量非常庞大的过程变量,并且这些过程变量之间相互关系、相互影响,如果改变某些过程变量,有可能会导致其它过程变量发生变化,从而使工业生产过程更加复杂化,增加了过程监控的难度。
(3)非线性。现阶段几乎所有的工业过程都存在非线性过程变量。对于存在非线性数据较少的系统,在合理的范围内可以近似于线性系统来对待,而对于非线性数据较多的系统,假如采取线性化的处理方法会容易产生较大误差,导致故障识别和故障诊断失败。
粒子群优化算法是1995年j.kennedy和r.c.eberhart基于鸟群觅食过程中的迁徙和聚集的模拟而提出的一种群体智能性优化算法,它收敛速度快,且只有少量参数需要根据实际情况调整,所以具有较高的可实现性。从一提出至今早已成为智能优化与进化计算领域研究中目标函数优化、神经网络训练、模糊控制系统的一个主要优化工具,已被广泛应用于计算机工程、道路规划工程、运输组合工程等研究方向。
目前,基于粒子群优化算法的工业过程监控并没有相应的发展,pca在非线性情况下并没有很好的解决特征空间内数据的离散度和相关度问题。在现有的核函数优化方法中,大部分都依赖于梯度已知,但是当梯度未知时,粒子群优化算法难以找到全局最优解。
技术实现要素:
本发明基于粒子群优化算法,采用fisher判别函数的思想构建优化核函数参数的目标函数,寻求目标函数最优解,确定核函数最优参数,提取导致过程监控故障的主元,优化减小主元的个数,提高过程监控的效率和准确性。
本发明采用以下技术方案予以实现:
一种非线性过程监控方法,包括以下步骤:
(1)布置探测器获取粒子群样本数据,样本数据通过核函数的内积运算形成一种非线性映射,再通过这一非线性映射将原空间的非线性数据转换成特征空间的线性数据;
(2)计算特征空间的类间平方和以及类内离散度,根据fisher判别准则建立关于核函数参数优化的粒子群优化模型的适应度函数;
(3)初始化粒子群参数,计算适应度函数初始适应值,通过粒子群优化算法迭代求取最优解;
(4)最优解作为核函数的最优核参数,确定特征空间的特征值和特征向量,根据累积贡献率确定导致故障的特征值对应的主元,优化调整原样本空间的主元个数。
作为进一步的改进,步骤(1)中所述的核函数为满足mercer条件的核函数,包括多项式核函数、径向基函数和simoid核函数。
作为进一步的改进,所述的步骤(3)中初始化粒子群参数,计算适应度函数初始适应值,通过粒子群优化算法迭代求取最优解;,其方法为:
在一个m个粒子组成的d维目标搜索空间,初始化粒子群参数,通过目标函数令全部初始粒子都获得一个初始适应值,全部粒子在一个速度向量指引下跟踪到目前为止空间中最优的粒子进行搜索,在搜索过程中,粒子通过速度和位置的迭代更新来求取最优位置下的适应值。
作为进一步的改进,初始化参数包括权重系数γ,粒子初始位置xid,粒子初始速度vid,种族大小m,加速度常数c1、c2,最大限制速度vmax,最大迭代次数tmax,其中tmax为算法迭代的终止条件,
粒子的迭代更新方法为:
vid(t+1)=γvid(t)+c1r1(pid-xid(t))+c2r2(pgd-xid(t))
xid(t+1)=xid(t)+vid(t+1)
其中,取i=1,2,…,d,加速度常数c1、c2为非负常数;r1、r2服从[0,1]上的均匀分布随机数;xid(t)是第i个粒子的当前位置,pid是第i个粒子在局部至今为止搜索到的最优位置,pgd是第i个粒子在全局至今为止搜索到的最优位置;vid(t)是第i个粒子的当前速度,vid(t)∈[-vmax,vmax],vmax为最大限制速度,vmax≥0。
作为进一步的改进,迭代过程中,若vid(t)>vmax,取vid(t)=vmax;若vid(t)<-vmax,取vid(t)=-vmax。
作为进一步的改进,令粒子群的加速度常数c1、c2随迭代次数t线性化:
其中,r1、r2为初始化时的设置值,tmax为最大迭代次数。
作为进一步的改进,提高搜索初期的空间搜索能力和增强进化迭代中局部搜索能力,避免陷入局部最优解:
r1+r2≤1.5。
作为进一步的改进,步骤(4)中所述确定特征空间的特征值和特征向量,根据累积贡献率确定导致故障的特征值对应的主元,其方法为:根据核函数确定特征值λi和特征向量,特征向量经非线性变化得到非线性主元分量,
选择n使
即提取前n个最大特征值所对应的非线性主元分量构建n维特征子空间;以前n个最大特征值对应的主元表征导致故障的主元。
本发明基于粒子群优化算法提出的过程监控方法,具有以下的改进:
1、优化提取过程监控中导致故障的主元,减少过程监控的数据量,提高监控的准确度和效率。
2、利用粒子群优化算法的数据处理方法,能够快速准确地对大量数据进行处理,同时基于算法的迭代参数随迭代次数线性化,在避免陷入局部最优解的前提下极大地提高了优化速度。
3、采用fisher判别函数的思想构建优化核函数参数的目标函数,克服了必须计算梯度的约束,降低数据处理难度。
4、本发明在大量非线性数据的情况下,能够很好区分出故障类别之间的离散度和各特征值之间的相关度。
附图说明
图1是本发明的粒子群算法流程图;
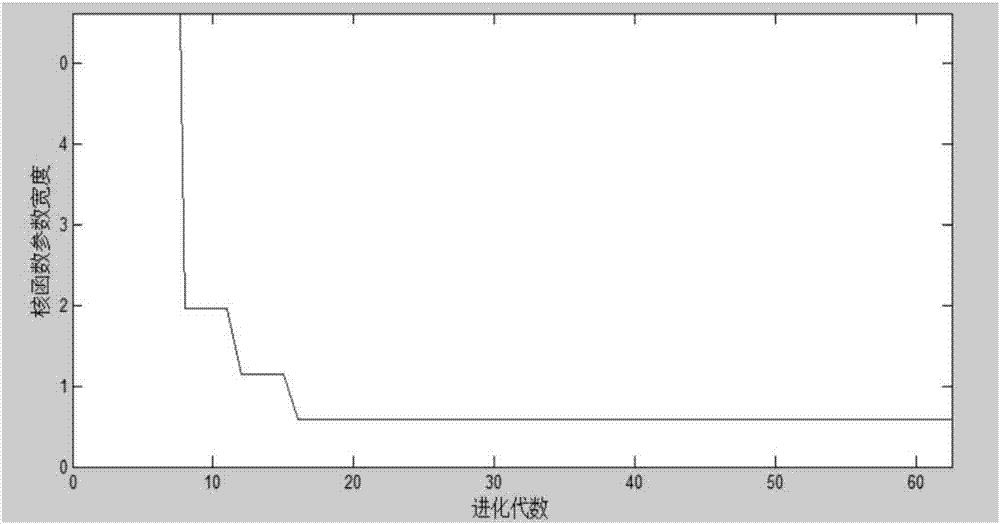
图2为本发明实施例的故障1核参数优化示意图;
图3为本发明实施例的故障2核参数优化示意图;
图4为本发明实施例的故障3核参数优化示意图;
图5-7为本发明实施例特征样本的聚类对比图。
具体实施方式
以下结合附图对本发明的实施例作详细描述。应当理解,此处描述的实施例仅用于解释说明本发明,并非用于限定本发明。
一种非线性过程监控方法,包括以下步骤:
(1)布置探测器获取粒子群样本数据,样本数据通过核函数的内积运算形成一种非线性映射,再通过这一非线性映射将原空间的非线性数据转换成特征空间的线性数据。假设某一粒子群样本空间为x,经过核函数的内积运算非线性映射后为φ(x),再将φ(x)映射到高维空间中,此时的高维特征空间的协方差矩阵为:
(2)计算特征空间的类间平方和以及类内离散度,根据fisher判别准则建立关于核函数参数优化的粒子群优化模型的适应度函数。fisher函数可适用于多种函数参数优化,若是选择含有多个参数的函数则要进行多次参数优化。
若x1(x11,x12,...,x1i),x2(x21,x22,...,x2j)(i=1,2,...,n1;j=1,2,...,n2)是特征空间中的两类特征数据,两类数据在特征空间的均值向量分别为:
类间距离的平方和为:
xk内离散度的平方为:
(3)初始化粒子群参数,计算适应度函数初始适应值,通过粒子群优化算法迭代求取最优解。
在一个m个粒子组成的d维目标搜索空间,初始化粒子群参数,通过目标函数令全部初始粒子都获得一个初始适应值,全部粒子在一个速度向量指引下跟踪到目前为止空间中最优的粒子进行搜索,在搜索过程中,粒子通过速度和位置的迭代更新来求取最优位置下的适应值。
初始化参数包括权重系数γ,粒子初始位置xid,粒子初始速度vid,种族大小m,加速度常数c1、c2,最大限制速度vmax,最大迭代次数tmax,其中tmax为算法迭代的终止条件,
粒子的迭代更新方法为:
vid(t+1)=γvid(t)+c1r1(pid-xid(t))+c2r2(pgd-xid(t))
xid(t+1)=xid(t)+vid(t+1)
其中,取i=1,2,…,d,加速度常数c1、c2为非负常数;r1、r2服从[0,1]上的均匀分布随机数;xid(t)是第i个粒子的当前位置,pid是第i个粒子在局部至今为止搜索到的最优位置,pgd是第i个粒子在全局至今为止搜索到的最优位置;vid(t)是第i个粒子的当前速度,vid(t)∈[-vmax,vmax],vmax为最大限制速度,vmax≥0。
迭代过程中,若vid(t)>vmax,取vid(t)=vmax;若vid(t)<-vmax,取vid(t)=-vmax。
作为进一步的改进,令粒子群的加速度常数c1、c2随迭代次数t线性化:
其中,r1、r2为初始化时的设置值,tmax为最大迭代次数。
作为进一步的改进,提高搜索初期的空间搜索能力和增强进化迭代中局部搜索能力,避免陷入局部最优解:
r1+r2≤1.5
具体的迭代流程如图所示,首先初始化粒子群参数γ、m、xid、vid、c1、c2、vmax、tmax,计算粒子当前适应度f(ω),根据迭代更新公式对粒子的当前的速度vid(t)和位置进xid(t)行更新;然后进行判别,若当前位置xid(t)下的粒子适应度f(ω)优于局部最优位置pid,则局部最优位置pid替换为当前位置xid(t),反之保持当前位置不变,即取适应度值较小的位置;进一步判别,若当前位置xid(t)下的粒子适应度f(ω)优于全局最优位置pgd,则全局最优位置pgd替换为当前位置xid(t),反之保持当前位置不变,即取适应度值较小的位置;更新迭代直至达到最大迭代次数tmax,最后输出适应度函数极小值对应的极小值点ω。
(4)最优解作为核函数的最优核参数,确定特征空间的特征值和特征向量,根据累积贡献率确定导致故障的特征值对应的主元,优化调整原样本空间的主元个数。
在本实施例中的核函数是指满足mercer条件的核函数,包括多项式核函数、径向基函数和simoid核函数。
核函数形式的选取对于非线性系统的分析具有重要的影响.核函数一般有以下三种形式:
多项式核函数
k(x,y)=<xy>d
径向基函数:
simoid核函数:
k(x,y)=tanh(βo<xy>+β1)
本实施例以径向基核函数为例,寻求适应度函数f(ω)的极小值,所得极小值点ω*为最优核宽度,即最优核参数。
由于k(x1i,x1i)和k(x1j,x1j)的值等于1,所以可以简化为:
主元分析的任务即求出特征值λ与特征向量v,从而选择提取出相关的特征值与特征向量。由λv=cv可得,由λ≠0时,v在φ(xi)(i=1,2,...,m)的空间中,存在αi(i=1,2,...m),满足
在λv=cv两边同时与φ(xk)做内积得
λ<φ(xk),v>=<φ(xk),cv>,k=1,2,...,m
将上两式带入后转化为如下问题:
mλα=kα,k=(k(xi,xj))ij
其中,k是核矩阵,α=(α1,α2,...,αm)′。可得mλ和α是对应于k的特征值和特征向量。令大于0的特征值λ的特征向量v分别为αp,αp+1,...,αm,为了满足<ν′,ν′>=1,取α′使得mλ<α′,α′>=1,则样本φ(x)在ν′上的投影为:
其中,r=p,p+1,...,m。gr(x)为对应于φ(x)的非线性主元分量,将所有投影值形成的向量(g1(x),g2(x),...,gl(x))′作为样本x的新特征。
在特征提取过程中,非线性主元分量个数的确定至关重要,若保留的个数太多,则失去了特征选择的意义;若提取的个数少了,特征属性则不能完整地描述出原始数据含有的故障信息。因此,利用非线性主元分量贡献比值
选择n使
即提取前n个最大特征值所对应的非线性主元分量构建n维特征子空间;以前n个最大特征值对应的主元表征导致故障的主元。降低了过程监控中变量维度,提高了过程监控的效率和准确度。
在本发明的一个具体应用实施例中,采用青霉素发酵仿真平台pensim2.0对青霉素生产过程进行模拟,利用本发明的过程监控方法进行优化监控。
模拟输入参数如表1:
表1
选取4个批次数据:
(1)正常工况运行300小时,采样时间为0.5小时。
(2)故障1:空气流量故障,阶跃+10%,运行300小时,故障从100小时加入,采样时间为0.5小时。
(3)故障2:搅拌功率故障,斜坡+10%,运行300小时,故障从100小时加入,采样时间为0.5小时。
(4)故障3:底物流加速度故障,阶跃+10%,运行300小时,故障从100小时加入,采样时间为0.5小时。
任意选取4个批次的30个采样点,以正常工况和不同故障采样点进行优化,本实施例采用径向基函数作为核函数,取核函数参数宽度ω为粒子,初始参数如表2。
表2
由上图2-4可知,当迭代次数在50以内时,三种故障的核函数宽度都能稳定到一个最优值:图2中故障1的核函数宽度优化结果为0.6176,图3中故障2的核函数宽度优化结果为0.5254,图4中故障3的核函数宽度优化结果为0.3261。
如图5-7所示,以正常工况的30个采样点为原始特征集作为训练集,用3个故障的30个采用的作为样本特征进行测试,比较分析pca与kpca所得到的结果并分别提取第一至第二主元投影图。pca的第一主元、第二主元投影图上的主元特征混合在一起,根本无法看出正常工况的聚类中心和区分其中各类故障,而从kpca在第一主元、第二主元投影图的三个主元特征区分清晰可见,可以区分正常工况和其他两个故障的类别,由此可见kpca比pca在非线性分析上具有较大的优势。
累积贡献率是指非线性主元分量所含有的原始特征向量的多少,累积贡献率越大说明其对原始特征信息的描述效果越好,对原始特征信息的描述效果也越好,反之则越差。表3是本发明kpca和pca对上述采样点的贡献度分析对比结果:
表3
如表3,由于青霉素菌的底物消耗、代谢、合成等都是非线性行为,擅长处理线性行为的pca不再适用,导致其前5个主元特征向量的累积贡献度小于kpca,而本发明kpca的贡献率排行前5的特征向量的累积贡献度已然超过了规定的85%,因此,将前5个特征值所相对的特征向量重构为新的特征子空间,即可用这5个特征属性取代原有的11个特征属性,变量维度也就下降了6个。
表4是不同故障时各输出参数作为特征值第一主元的投影值,以正常工况下的第一主元为标准值,以3种故障模式与正常工况下的第一主元作差的绝对值大小为评判标准,绝对值越大说明该指标偏离正常工况越严重,对故障的敏感度越高。
表4
按从大到小的顺序将绝对值较大的前5个特征值排列如表5所示,从表中可以看出,有的特征值对不同的故障模式都有不同的敏感度,有的特征值对多个故障模式都存在敏感度,有的则一个都没有,因此,将存在敏感度的特征值用√标示,如表6,故障模式所含√越多,则表明该特征值的敏感度越强。从表5可知,对3种故障都存在敏感度的参数有co2,对两种故障都存在敏感度的参数有菌丝浓度、青霉素浓度、产生热量、底物浓度,只对一种故障存在敏感度的参数有发酵罐体积、ph值。
表5
表6
因此,通过本发明可以区分出故障类别之间的离散度和各特征值之间的相关度,可以用敏感度从高到低的前5个特征值(co2、菌丝浓度、青霉素浓度、产生热量、底物浓度)来取代原有的11个特征值,而且这5个特征值中保留了原有11个特征值的85%以上特征信息,能够更进一步地提高过程监控的效率和精确度。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!