一种基于自适应阈值PLS的高炉铁水质量监测方法与流程
本发明属于高炉铁水质量监测技术领域,具体是一种基于自适应阈值pls的高炉铁水质量监测方法。
背景技术:
高炉炼铁是现代炼铁的主要方法,这种方法生产的铁占世界铁总量的95%以上,生产的钢铁被广泛应用于机械制造业、交通运输业、医疗器材及军事发展等各行各业上。高炉炼铁是钢铁生产中的重要环节,其生产出的铁水质量水平的高低直接决定着后续转炉炼钢的质量。目前,综合性的铁水质量指标通常采用硅含量([si])、磷含量([p])、硫含量([s])和铁水温度(mit)来衡量。然而,高炉顺行(正常工况)是高炉炼铁过程中各种矛盾因素相对的、暂时的统一。它的基础是正常而稳定的煤气流分布、充沛而合适的炉缸温度。而影响煤气流分布和炉缸温度的因素有原燃料条件、送风制度、装料制度、造渣制度等,它们的任何改变,都会影响高炉内煤气流分布及炉缸温度的变化,从而影响炉况波动和破坏顺行,如不及时纠正,进一步发展就会导致炉况的严重失常,对铁水质量造成重大影响。炉况发生波动都是有先兆的,并不是立即就有较大的波动和异常,而是一个过程。因此,操作者监测高炉生产过程,对炉况进行连续观察分析,通过直观判断与仪表判断相结合发现预兆,对炉况波动做出准确判断,判断高炉炼铁过程是否异常,并及时采取措施处理和纠正,对保证高炉铁水质量尤为重要。
在高炉内,煤气在自下而上的流动中,把自上而下的炉料加热、还原和熔炼成生铁和炉渣,进行着高度复杂的物理和化学过程。高炉炼铁过程炉况波动频繁,在铁水质量监测过程中存在较高误报率和检测不准确的情况,给高炉操作人员判断炉况是否出现异常带来了影响,导致无法及时并准确地确定高炉炼铁过程状况及故障原因。对于高炉炼铁这样一个复杂大型工业过程,很难建立准确的过程机理模型乃至质量监测模型。由于信息采集、存储、传输和处理技术的普遍应用和不断发展,基于数据驱动的质量监测方法得到了广泛应用,使提高高炉炼铁过程的铁水质量监测效果成为可能。
传统pls监测技术通常用平方预测误差(squaredpredictionerror,spe)(也称q统计量)和hotelling’st2绘制控制图,检测高炉炼铁过程是否发生异常,检测指标往往采用的是固定控制限的方法,当统计量值超出控制限时,考虑炼铁过程异常的发生。控制限是基于经验分布定义的,因此,控制限的确定是由给定的置信水平决定的。然而,固定控制限是在权衡误报率与漏报率之间一定程度的关系基础上得来的,因此,质量监测过程中,故障误报率和漏报率是不可避免的,统计量超出控制限的情况可能是故障或者误报的结果。同时,由于这种权衡关系的存在,为了减少误报率,在基于pls的q和t2控制图的质量监测过程中,只有当几个连续的统计值超出控制限时才认定为故障产生,然而,这种规则将产生一定的检测时间延迟,而且极大地降低了故障检测率。因此,基于固定控制限的方法增加了故障误报率和(或)故障漏报率,使这种技术对实际工业过程并不适用,在高炉铁水质量监测过程中,降低了故障检测的可靠性,对于铁水质量会产生很大的影响,造成一定的经济损失甚至事故发生。
技术实现要素:
为了解决以上基于pls(partialleastsquares,偏最小二乘)方法的高炉铁水质量监测中存在的较高误报率及检测效果不理想的问题,本发明基于指数移动加权平均的思想,将固定控制限改进为应用自适应阈值的方法,应用于基于偏最小二乘的高炉铁水质量监测方法中,提高对高炉铁水质量的监测效果。通过pls方法建立模型,采用平方预测误差(squaredpredictionerror,spe)(也称q统计量)和hotelling’st2统计量绘制控制图,不同于传统pls的质量监测采用固定控制限的方法,本发明的检测指标应用自适应阈值这样一个自适应控制限的方法,检测过程是否发生异常,本发明可以在高炉铁水质量监测中保持较高故障检测率,与此同时,降低故障误报率,提高对铁水质量监测性能及高炉炼铁过程运行状况的监测效果。
为实现上述目的,本发明采用如下技术方案:
一种基于自适应阈值pls的高炉铁水质量监测方法,包括:
步骤1、采集相同时刻的高炉炼铁历史数据中的高炉运行参数和铁水质量变量,将高炉运行参数作为数据矩阵x,铁水质量变量作为数据矩阵y;
步骤2、对输入数据矩阵x和输出数据矩阵y做预处理,从中选择高炉炼铁正常过程的数据作为训练集,计算输入数据矩阵x和输出数据矩阵y中各变量的均值和标准差,并标准化处理成零均值和单位标准差的数据;
步骤3、采用非线性最小二乘迭代算法构建偏最小二乘模型(即pls模型)来描述输入数据矩阵x和输出数据矩阵y;
步骤4、获取高炉炼铁过程新的高炉运行参数样本数据,并进行标准化处理,即减去步骤2中计算出的均值再除以步骤2中计算出的标准差,得到测试集;
步骤5、针对测试集,对pls模型采用q统计量和hotelling’st2统计量来检验高炉炼铁过程是否发生异常,计算测试集样本的q统计量和t2统计量值,并计算q统计量和t2统计量的固定控制限;
步骤6、采用指数加权移动平均技术,实时计算当前时刻每个样本统计量的指数加权移动平均值,进而确定当前时刻的t2统计量自适应阈值和q统计量自适应阈值,完成测试集的故障检测:若当前时刻t2统计量的值、当前时刻q统计量的值至少有一个超过相应的自适应阈值,则高炉炼铁过程发生了故障。
所述高炉运行参数,包括冷风流量、送风比、热风压力、顶压、压差、顶压风量比、透气性、阻力系数、热风温度、富氧流量、富氧率、设定喷煤量、鼓风湿度、理论燃烧温度、标准风速、实际风速、鼓风动能、炉腹煤气量、炉腹煤气指数、顶温东北、顶温西南、顶温西北、顶温东南、软水温度;上述高炉运行参数作为输入数据矩阵x中的过程变量;
所述铁水质量变量,包括硅含量([si])、磷含量([p])、硫含量([s])和铁水温度(mit),作为输出数据矩阵y的质量变量。
所述t2统计量自适应阈值计算公式如下:
其中,
q统计量自适应阈值计算公式如下:
其中,qada[i]为q统计量自适应阈值,qα表示置信水平为α的q统计量的固定控制限,qi-h+j表示i-h+j时刻的q统计量。
本发明的有益效果:
本发明提出的一种基于自适应阈值pls的高炉铁水质量监测方法,与传统应用基于固定控制限pls的高炉铁水质量监测方法进行对比,从所得出的故障误报率和检测率表中,同样可以发现,本发明所用方法能明显降低故障误报率,同时保证了故障检测效果的准确性和灵敏性。良好的监测效果及可靠的报警信息,能够方便操作人员监测高炉生产过程,对炉况波动做出准确判断,判断高炉炼铁过程是否异常,并及时采取措施处理和纠正,进而保证高炉的稳定、高效、安全顺行,对保证铁水质量尤为重要。
附图说明
图1为本发明的一种基于自适应阈值pls的高炉铁水质量监测方法的流程图;
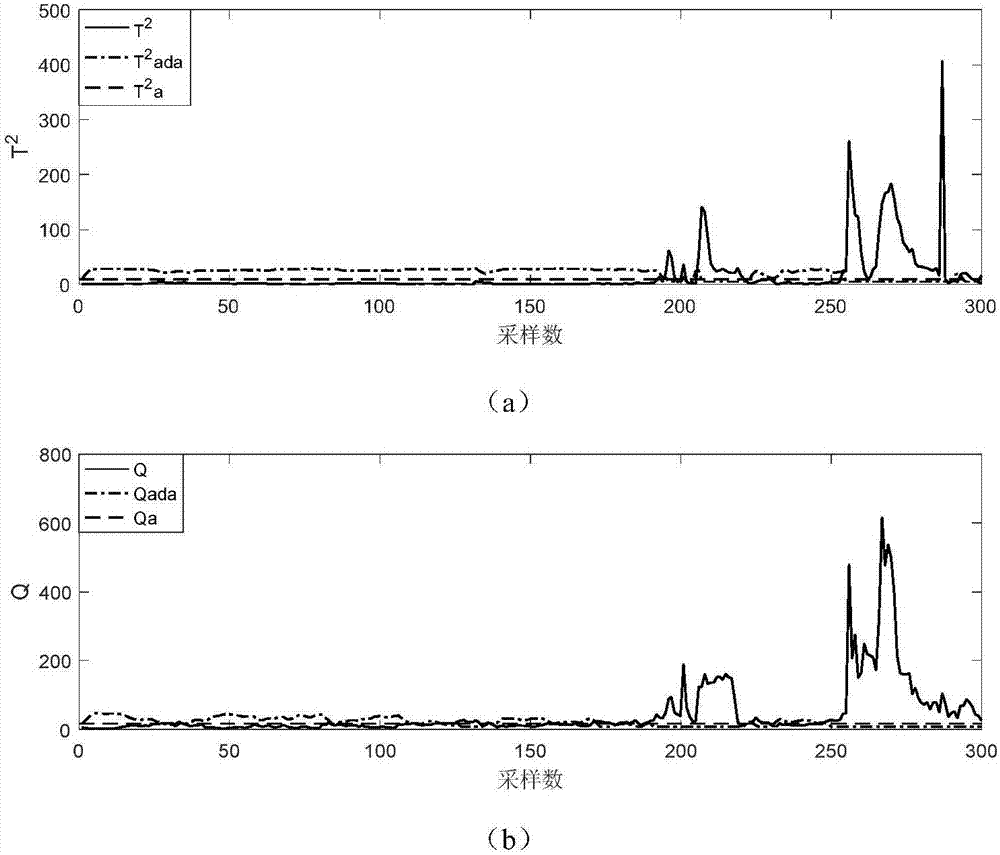
图2为对测试集1进行的基于自适应阈值和传统固定控制限的pls高炉铁水质量监测效果对比图,其中(a)为基于自适应阈值和传统固定控制限的pls高炉铁水质量监测对于t2统计量的监测效果,(b)为基于自适应阈值和传统固定控制限的pls高炉铁水质量监测对于q统计量的监测效果;
图3为对测试集2进行的基于自适应阈值和传统固定控制限的pls高炉铁水质量监测效果对比图,其中(a)为基于自适应阈值和传统固定控制限的pls高炉铁水质量监测对于t2统计量的监测效果,(b)为基于自适应阈值和传统固定控制限的pls高炉铁水质量监测对于q统计量的监测效果;
图2和图3中所用的标记符号如下:
t2统计量——t2
t2统计量的自适应阈值指标——t2ada
t2统计量的固定控制限指标——t2a
q统计量——q
q统计量的自适应阈值指标——qada
q统计量的固定控制限指标——qa。
具体实施方式
下面结合附图对本发明的具体实施方式做详细说明。
本实施方式提供一种基于自适应阈值pls的高炉铁水质量监测方法,如图1所示,包括:
步骤1、采集相同时刻的高炉炼铁历史数据中的高炉运行参数和铁水质量变量,将高炉运行参数作为数据矩阵x,铁水质量变量作为数据矩阵y:
所述高炉运行参数,包括冷风流量、送风比、热风压力、顶压、压差、顶压风量比、透气性、阻力系数、热风温度、富氧流量、富氧率、设定喷煤量、鼓风湿度、理论燃烧温度、标准风速、实际风速、鼓风动能、炉腹煤气量、炉腹煤气指数、顶温东北、顶温西南、顶温西北、顶温东南、软水温度;上述高炉运行参数作为输入数据矩阵x中的过程变量;
所述铁水质量变量,包括硅含量([si])、磷含量([p])、硫含量([s])和铁水温度(mit),作为输出数据矩阵y的质量变量;
步骤2、对输入数据矩阵x和输出数据矩阵y做预处理,从中选择高炉炼铁正常过程的数据作为训练集x0∈r600×24,y0∈r600×4,计算输入数据矩阵x和输出数据矩阵y中各变量的均值和标准差,并标准化处理成零均值和单位标准差的数据。
步骤3、采用非线性最小二乘迭代算法构建偏最小二乘模型(即pls模型)来描述输入数据矩阵x和输出数据矩阵y:
设输入数据矩阵x∈rn×m,由n个样本组成,每个样本有m个高炉运行参数,输出数据矩阵y∈rn×p同样由n个样本构成,每个样本由p个铁水质量变量构成。将数据矩阵(x,y)投影到一个由少量得分向量t1,…,ta构成的低维空间中,构建的pls模型如下:
其中,t=[t1,…,ta]是得分矩阵,p=[p1,…,pa]和q=[q1,…,qa]分别是针对输入数据矩阵x和输出数据矩阵y的载荷矩阵,p′表示载荷矩阵p的转置,q′表示载荷矩阵q的转置。e和f分别是输入数据矩阵x的建模误差和输出数据矩阵y的建模误差。输入数据矩阵x和输出数据矩阵y是经过数据预处理,化为零均值与单位方差的;a为pls模型主元个数,本实施方式通过交叉验证的方法选取主元个数为4,即a=4。
通过pls模型将数据矩阵空间分解为两个正交且互补的子空间,其中由载荷矩阵p或q的所有列张成的子空间tp′或tq′称为主元子空间(pcs),pcs的正交补e或f称为残差子空间(rs)。任意一个样本向量均可以被分解为在主元子空间和残差子空间上的投影。
采用如下非线性最小二乘迭代算法建立pls模型:
(1)开始:令u为输出数据矩阵y的任一列;
(2)输入数据矩阵x中的各列在u上进行回归得到负载向量,w′=u′x/u′u;
(3)将w归一化;
(4)计算得分向量:t=xw/w′w;
(5)输出数据矩阵y中的各列在得分向量t上进行回归:q′=t′y/t′t;
(6)计算输出数据矩阵y的新得分向量:u=yq/q′q;
(7)判断u是否收敛:如果是,跳到第8步,如果不是,跳到第2步;
(8)计算输入数据矩阵x的负载矩阵:p′=t′x/t′t;
(9)计算残差矩阵:e=x-tp′,f=y-tq′;
(10)用e、f分别代替输入数据矩阵x、输出数据矩阵y,计算下一个得分向量,重复上述过程直到a个得分向量均被提取。
其中,w、q分别是权重向量,用以计算输入数据矩阵x的得分向量t和输出数据矩阵y的得分向量u。记w=[w1,…wa],由于得分矩阵t无法由w直接从输入数据矩阵x中计算得到,令
且r=[r1,…,ra]。那么得分矩阵t可以由原始的输入数据矩阵x计算得到
t=xr(5)
至此,求得pls模型中的得分矩阵t,得到最终的pls模型。
步骤4、获取高炉炼铁过程新的高炉运行参数样本数据,并进行标准化处理,即减去步骤2中计算出的均值再除以步骤2中计算出的标准差,得到测试集。
步骤5、针对测试集,对pls模型采用平方预测误差(squaredpredictionerror,spe)(也称q统计量)和hotelling’st2统计量来检验高炉炼铁过程是否发生异常,计算测试集样本的q统计量和t2统计量值,并计算q统计量和t2统计量的固定控制限。
当获得一个新的样本向量xnew时,pls模型的得分和残差由式(4)计算,即
t2统计量衡量样本向量xnew在主元子空间中的变化:
其中,
其中,fa,n-a;α是带有a和n-a个自由度、置信水平为α的f分布临界值。
q统计量用于衡量样本向量xnew在残差子空间投影的变化:
其中,qα表示置信水平为α时q统计量的控制限。当q统计量位于该控制限内时,高炉炼铁过程是正常的。控制限计算如下:
其中,s是训练样本的q统计量的方差,μ是训练样本q统计量的均值,
步骤6、采用指数加权移动平均技术,实时计算当前时刻每个样本统计量的指数加权移动平均值,进而确定当前时刻的t2统计量自适应阈值和q统计量自适应阈值,完成测试集的故障检测:若当前时刻t2统计量的值、当前时刻q统计量的值至少有一个超过相应的自适应阈值,则高炉炼铁过程发生了故障;
t2统计量自适应阈值
其中,i表示当前时刻,参数λ是加权因子,λ>1,它决定了旧数据进入指数加权移动平均值的计算速率。λ越小,对旧数据的加权越小,h是滤波窗口的长度,表示参与计算每个样本指数加权移动平均值的样本数,ti-h+j表示i-h+j时刻的t2统计量。
在基于自适应阈值pls的高炉铁水质量监测中,如果t2统计量的值超过上述自适应阈值,即:
q统计量自适应阈值qada[i]计算公式如下:
其中,qi-h+j表示i-h+j时刻的q统计量,qα表示置信水平为α时q统计量的固定控制限。
在基于pls的故障检测中,如果统计指标q的值超过上述自适应阈值,即:qi>qada[i],则考虑与铁水质量无关的故障发生。
大多数情况下,传统pls质量监测技术检测指标采用的是固定控制限的方法,控制限的确定是由给定的置信水平决定的,同时权衡了故障误报率与漏报率之间一定程度的关系,在高炉铁水质量监测过程中,假设从新的样本数据应用pls模型得到一系列t2统计量值t2=[t1t2…ti],当t2统计量值超出控制限时,即ti超出固定控制限
指数加权移动平均(exponentiallyweightedmovingaverage,ewma)是一种理想的最大似然估计技术,也可以看作一个低通滤波器,其思想是以指数式递减加权的移动平均。各数值的加权随时间而指数式递减,对越近期的数据给予更大的权重。基于这种思想,采用相同数量的样本以及每个样本统计量的幅值,并对最新的数据给予更大的权重,计算每个样本的指数加权移动平均值:
其中,参数λ是加权因子,λ>1,它决定了旧数据进入
将不等式(10)右边的部分作为i时刻t2统计量检测指标的自适应阈值,这种自适应阈值包含两部分,一部分是定义在一定置信水平上的固定控制限成不同比例的总和,另一部分是由之前的h-1个样本按一定权重构造而成的值。因此,这个自适应阈值不仅包含了t2统计量相对于控制限
在基于自适应阈值pls的高炉铁水质量监测过程中,如果统计指标t2的值超过上述自适应阈值,即:
将同样的方法应用于q统计量上,q=[q1q2…qi]。可以得到:
在基于自适应阈值pls的高炉铁水质量监测过程中,如果统计指标q的值超过上述自适应阈值,即:qi>qada[i],则考虑故障的发生。
在选择加权因子λ时,要保证指数加权移动平均中最近的统计值对应于健康样本,如果λ太小接近于1,将会导致自适应的方案为求取一定样本量的平均值,这虽然能够达到降低误报的要求,却会增加检测延迟时间。如果λ过大,能够增加对最近样本的权重,增加了对最近数据的依赖性,达到快速检测的目的,但不能较好地降低误报率。窗口长度h代表用于计算每个时刻的动态自适应阈值的统计量数目,会影响计算时间,由于随着时间的推移,越靠后的数据权重系数越小,甚至可以忽略不计,所以h不能太大。在本发明提出的一种基于自适应阈值pls的高炉铁水质量监测方法中,选择参数λ=1.2,h=4。
在铁水质量监测过程中出现报警样本时,可能会导致自适应阈值计算出的值显著降低,当高炉炼铁过程恢复正常时,正常样本的统计量值较低,可能会将正常样本错误检测为异常状况。因此,需要将自适应阈值强制高于某一参考值。然而,如果将自适应阈值被强制高于传统pls方法采用的固定控制限的值,便会降低故障检测率;如果阈值非常小,便会增加故障误报率。本实施方式中选择动态自适应阈值强制高于固定控制限的一半。
本发明进行了两次测试集的试验,x1∈r300×24,x2∈r890×24。分别对测试集1和测试集2中的输入数据矩阵x1和x2计算基于所构造的pls模型的q统计量和t2统计量的值,q=[q1q2…qi]和t2=[t1t2…ti]并根据式(12)和式(11)计算自适应阈值qada[i]和
图2(a)~(b)和图3(a)~(b)给出了对于两个测试集x1和x2,基于自适应阈值和传统固定控制限的pls高炉铁水质量监测对于q和t2统计量的监测效果。从监测图中可以发现,正常情况的样本对应的统计值较低,应用自适应阈值将高于固定控制限,显著降低了故障误报率。在过程存在异常的情况下,对应的统计值较高,应用自适应阈值将降至固定控制限的一半,保证了故障检测率。因此,本发明提出的一种基于自适应阈值pls的高炉铁水质量监测方法相比于传统基于固定控制限的pls监测方法,提高了故障检测的准确度与灵敏性。
测试基于自适应阈值pls的高炉铁水质量监测的故障检测性能。评价过程的检测性能最常用的指标是:漏报率(mdr),故障检测率(fdr),故障检测时间延迟和误报率(far)。一个可靠的监测方案的目标是实现较高的fdr,降低far和故障检测时间延迟。
其中,nf,f表示故障样本中被检测为故障的样本个数,nf表示故障样本个数,nn,f表示正常样本中被检测为故障的样本个数,nn表示正常样本个数。
表1和表2列出了基于自适应阈值pls的高炉铁水质量监测过程中,对两个测试集分别根据式(13)计算得到的故障误报率和故障检测率,并与传统基于固定控制限pls方法进行比较。可以看出,本发明方法相较于传统固定控制限的pls方法,能够有效的降低故障误报率和提高故障检测率,同时,能够保持良好的检测性能,提高了故障检测的可靠度。
表1测试集1的误报率与检测率
表2测试集2的误报率与检测率
本发明提出的一种基于自适应阈值pls的高炉铁水质量监测方法,与传统应用基于固定控制限pls的高炉铁水质量监测方法进行对比,从所得出监测图与故障误报率和检测率表中,可以发现,本发明所用方法能降低故障误报率,同时保证了故障检测效果的准确性和灵敏性。良好的监测效果及可靠的报警信息,能够方便操作人员监测高炉生产过程,对炉况波动做出准确判断,判断高炉炼铁过程是否异常,并及时采取措施处理和纠正,进而保证高炉的稳定、高效、安全顺行,对保证铁水质量尤为重要。
- 还没有人留言评论。精彩留言会获得点赞!