基于局部加权贝叶斯网络的自适应软测量预测方法与流程
本发明属于工业过程控制领域,尤其涉及一种基于局部加权贝叶斯网络的自适应软测量预测方法。
背景技术:
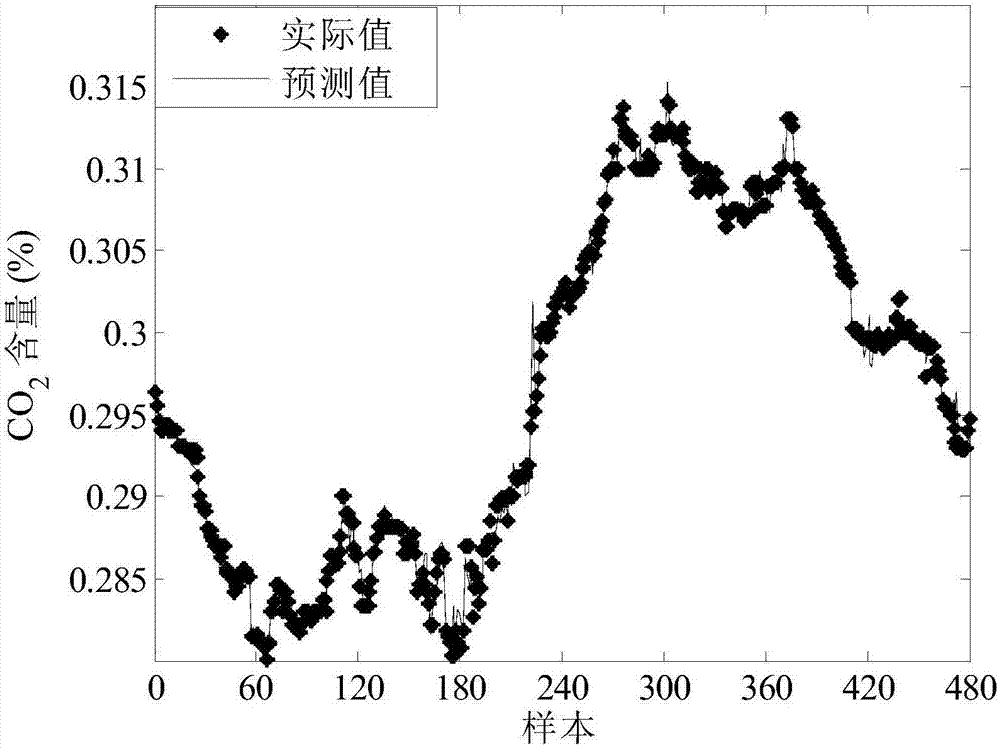
:软测量的目标是建立适当的模型,使用易于测量的过程变量预测难以测量或者测量存在大时延的质量变量。实时准确的预测出质量变量有利于控制产品质量,提高生产效率。软测量模型一般分为机理模型和数据驱动的模型。随着计算机技术的发展,数据驱动的建模方法受到了越来越多的关注。常见的数据驱动建模方法有很多,目前使用最广泛的是主成分分析和偏最小二乘方法,这两种都是线性模型;考虑到过程的不确定性,将概率形式加入到这两种方法中,就得到了概率的主成分分析和基于概率的偏最小二乘方法;如果工业过程呈现出多个模态,高斯混合模型可以很好地处理这一难题;将支持向量回归的思想用于软测量领域也可取得较高的预测精度;还有神经网络的方法也可用于质量预测。但在实际工业过程中,由于过程的漂移、催化剂的失效等会引起模型的退化,简单地说就是原来建立的模型不再适用于现有的运行状态。为了解决这一问题,出现了不少自适应的方法。即时学习是众多自适应软测量方法中的一种,而局部加权的方法又是即时学习中最重要的一种。贝叶斯网络是一种概率图论模型,它在处理不确定性问题中有很大的优势。技术实现要素:针对现有技术中的不足,本发明提出一种基于局部加权贝叶斯网络的自适应软测量预测方法,其能在工业过程存在漂移的情况下,也能较准确地给出质量预报,即使在训练数据和测试数据均存在不同程度缺失的情况下,也能获得较高的预测精度。具体技术方案如下:一种基于局部加权贝叶斯网络的自适应软测量预测方法,包括以下步骤:步骤一:收集工业过程中的历史数据集:将易于测量的过程变量作为输入,即x=[x1;x2;…;xn]∈rn×m,其中x的每一列代表一个过程变量,每一行代表一个样本;将不容易实时测量的质量变量作为输出,即y=[y1;y2;…yn]∈rn×1;步骤二:从历史数据集中选择建立贝叶斯网络模型的样本,具体如下:(a)新来一个输入样本xq,选择与该样本最相近的k个样本,即计算历史数据中的第n个输入样本xn与xq的欧式距离dn,并对计算出的欧式距离进行排序,选出欧式距离最小的k个样本,其中欧式距离的计算公式如下:(b)计算(a)中挑选出的k个样本的权重,计算公式如下:其中,表示位置参数,通常在0-1之间取值;σd表示公式(1)中求得欧式距离的标准差。(c)获得训练数据:将(a)中选出的k个样本分别乘以公式(2)计算得到的各自的权重,作为局部加权处理后的训练数据,公式如下:(d)计算(c)中处理后训练数据输入、输出的均值按如下方式计算:步骤三:用选出的k个样本建立贝叶斯网络,得到预测结果,具体如下:(a)对数据进行标准化处理:用步骤二得到的输入输出均值分别对步骤二中得到的作标准化化处理;(b)根据专家知识,将所有输入变量作为贝叶斯网络的父节点,待预测的输出变量作为子节点,各父节点与子节点间用一根带箭头的线连接,箭头指向子节点,各父节点间没有线直接相连,从而得到贝叶斯网络的结构;(c)当各节点服从高斯分布时,将所有父节点设置为可观测节点,唯一的子节点设置为隐含节点,将(a)中的标准化后数据放入贝叶斯网络中进行参数学习,如果此时的建模样本中存在数据缺失现象,将缺失值置为空后,直接进行后面的参数学习;所述的参数学习过程采用em算法,通过不断迭代给出各个节点参数的最大似然估计;当数据中存在缺失现象时,参数学习的过程大致如下:随机给定缺失数据的初值,根据给定初值估计模型参数;根据估计的模型参数重新计算缺失值,如此反复迭代直至待估计参数收敛;(d)根据上步参数学习的结果,获得步骤(b)中各节点的先验概率分布,包括各节点的均值和方差,此时得到一个完整的贝叶斯网络;(e)将待预测的输入样本xq去中心化处理后,作为证据添加进(d)中建立的完整的贝叶斯网络中,通过联合树推理引擎获得待预测节点的后验概率分布,包括输出的均值和方差;将均值作为预测值,并计算实际测量真值y与预测值yq的误差;步骤四:一旦完成预测后,当前模型被丢弃,当下一个新样本x′q到来时,重复步骤二和三,建立新的贝叶斯网络模型,得到y′q的预测值和预测误差。进一步地,所述的方差采用均方根误差rmse衡量预测结果的准确性,其计算公式如下:公式中n表示测试样本的个数,yreal代表测量的真实值,ypred代表由贝叶斯网络得到的预测值。本发明的有益效果是:本发明提出的基于局部加权贝叶斯网络的方法,每新来一个待预测样本,从历史数据中选择与它最相近的样本建立贝叶斯网络,完成预测后,该局部模型立即被丢弃。本发明的优势在于,在工业过程存在漂移的情况下,也能较准确地给出质量预报,即使在训练数据和测试数据均存在不同程度缺失的情况下,也能获得较高的预测精度。附图说明图1为本发明方法预测co2剩余含量的结果示意图;图2为局部加权的偏最小二乘方法预测co2剩余含量的结果示意图;图3为本发明方法在训练数据约有15%缺失的情况下的结果示意图。具体实施方式本发明针对工业过程中的软测量问题,该方法首先从历史数据集中选出与待预测样本最接近的数据作训练样本,运用贝叶斯网络的方法建立模型,并将待预测样本的输入作为证据添加进网络中,经推理得出预测值。一旦完成预测后,该模型立即被丢弃,当下一个待预测样本到来时,重新建立局部模型。下面结合具体的实施例对本发明的基于局部加权贝叶斯网络的自适应软测量预测方法作进一步的说明。一种基于局部加权贝叶斯网络的自适应软测量预测方法,包括以下步骤:步骤一:收集工业过程中的历史数据集:将易于测量的过程变量作为输入,即x=[x1;x2;…;xn]∈rn×m,其中x的每一列代表一个过程变量,每一行代表一个样本;将不容易实时测量的质量变量作为输出,即y=[y1;y2;…yn]∈rn×1;步骤二:从历史数据集中选择建立贝叶斯网络模型的样本,具体如下:(a)新来一个输入样本xq,选择与该样本最相近的k个样本,即计算历史数据中的第n个输入样本xn与xq的欧式距离dn,并对计算出的欧式距离进行排序,选出欧式距离最小的k个样本,其中欧式距离的计算公式如下:(b)计算(a)中挑选出的k个样本的权重,计算公式如下:其中,表示位置参数,通常在0-1之间取值;σd表示公式(1)中求得欧式距离的标准差。(c)获得训练数据:将(a)中选出的k个样本分别乘以公式(2)计算得到的各自的权重,作为局部加权处理后的训练数据,公式如下:(d)计算(c)中处理后训练数据输入、输出的均值,按如下方式计算:步骤三:用选出的k个样本建立贝叶斯网络,得到预测结果,具体如下:(a)对数据进行标准化处理:用步骤二得到的输入输出均值分别对步骤二中得到的作标准化处理;(b)根据专家知识,将所有输入变量作为贝叶斯网络的父节点,待预测的输出变量作为子节点,各父节点与子节点间用一根带箭头的线连接,箭头指向子节点,各父节点间没有线直接相连,从而得到贝叶斯网络的结构;(c)当各节点服从高斯分布时,将所有父节点设置为可观测节点,唯一的子节点设置为隐含节点,将(a)中的标准化后数据放入贝叶斯网络中进行参数学习,如果此时的建模样本中存在数据缺失现象,将缺失值置为空后,直接进行后面的参数学习;所述的参数学习过程采用em算法,通过不断迭代给出各个节点参数的最大似然估计;当数据中存在缺失现象时,参数学习的过程大致如下:随机给定缺失数据的初值,根据给定初值估计模型参数;根据估计的模型参数重新计算缺失值,如此反复迭代直至待估计参数收敛;(d)根据上步参数学习的结果,获得步骤(b)中各节点的先验概率分布,包括各节点的均值和方差,此时得到一个完整的贝叶斯网络;(e)将待预测的输入样本xq去中心化处理后,作为证据添加进(d)中建立的完整的贝叶斯网络中,通过联合树推理引擎获得待预测节点的后验概率分布,包括输出的均值和方差;将均值作为预测值,并计算实际测量真值y与预测值yq的误差;所述的方差采用均方根误差rmse衡量预测结果的准确性,其计算公式如下:公式中n表示测试样本的个数,yreal代表测量的真实值,ypred代表由贝叶斯网络得到的预测值。显然,均方根误差rmse越小,表示贝叶斯网络预测的精度越高。用该指标可以定量比较各种模型的预测能力。步骤四:一旦完成预测后,当前模型被丢弃,当下一个新样本x′q到来时,重复步骤二和三,建立新的贝叶斯网络模型,得到y′q的预测值和预测误差。以下结合一个具体的工业过程的例子来说明本发明的有效性。co2吸收塔是实际化工合成氨过程中的一个子单元。整个工艺过程可大致描述为:来自前一单元的工艺气经过初步降温后,在工艺冷凝分离罐再次降温,进入吸收塔。经过吸收塔后的工艺气,送入到除雾分离罐中,残余co2由仪表记录。罐中吸收co2后,吸收液由贫液,半贫液变成富液。富液从罐底部经富液闪蒸槽送入再生塔中,进行溶液的再生操作,再生的溶液被抽回吸收塔。co2吸收塔中发生的主要化学反应是co2+k2co3+h2o←→2khco3+q。为了最大限度地利用co2,最后工艺气中残余的co2含量应尽可能的少。吸收塔中共有12个变量如下表1给出。前11个变量较易测量得到,第12个变量工艺气中残余co2含量较难测量,因此对这12个变量建立贝叶斯网络,用前11个变量预测co2剩余含量。接下来结合该具体过程对本发明的实施步骤进行详细地阐述:表1co2吸收塔工艺中的变量变量编号变量描述1工艺气压力12液位13出口贫液温度4贫液流量5半贫液流量6出口工艺气温度7工艺气进出口压差8出口富液温度9液位210高液位报警值11工艺气压力212工艺气中残余co2含量采集co2吸收塔正常运行过程中的数据,对于待预测的输入样本xq,在历史数据中选择与它最相近的k个样本,对挑选出的样本作加权处理后用于后续建立贝叶斯网络。根据专家知识,确定贝叶斯网络的结构:共有12个节点,前11个为可观测的父节点,第12个节点为隐含的子节点,共有12条有向边,均为从父节点出发指向同一个子节点。当这12个节点均服从高斯分布时,用步骤1加权处理后的k个样本进行参数学习,获得这12个节点的先验概率分布。将新来样本的输入xq作为证据添加进已建好的贝叶斯网络中,由联合树推理引擎求得唯一子节点的后验概率分布,即子节点的均值和方差。将求得的均值作为预测值,方差反映了预测值的波动大小,可作为预测值精度的衡量指标。预测完成后,该局部模型立即被丢弃,当下一个新样本x′q到来时,重新建立新的贝叶斯网络。一旦获得待预测量的真值后,计算预测误差。采用本发明方法预测co2剩余含量的结果如图1所示,局部加权的偏最小二乘方法预测co2剩余含量的结果如图2所示,两种方法的预测精度对比如表2所示,从表2可以看出,本发明的基于局部加权的贝叶斯网络的预测方法比局部加权的偏最小二乘方法的预测精度高。表2本发明方法和局部加权的偏最小二乘方法的预测精度对比表建模方法预测的均方根误差预测最大误差的绝对值局部加权的贝叶斯网络0.00060720.002356局部加权的偏最小二乘0.00097350.007976本发明方法在数据约有15%缺失的情况下的预测结果如图3所示,从图3中可以看出,即使在数据存在一定缺失率的情况下,本发明仍然有较高的预测精度。上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1