分类与对象检测方法和装置以及图像拍摄和处理设备与流程
本发明涉及图像处理和模式识别领域,尤其涉及训练分类器以进行对象检测的方法和装置。
背景技术:
随着计算机图像处理技术的发展和计算机视觉原理的广泛应用,利用对象检测技术来实时地从图像和视频场景中定位目标越来越普遍。对象检测技术例如在智能终端设备、智能交通系统、智能监控系统甚至军事目标检测等应用中均具有广泛的实用价值。在对象检测领域,广泛地采用根据单类分类方法而训练的分类器。如Moya,M和Hush,D.所著的“Networkconstraintsandmulti-objectiveoptimizationforone-classclassification”(NeuralNetworks,9(3):463-474.doi:10.1016/0893-6080(95)00120-4,1996)中所描述的,在单类分类器中,通过根据仅仅包含一类对象的训练集合进行学习,从而将该类对象与所有其它可能的对象区分开。例如,在照相机中嵌入针对脸部/猫/狗的分类器。然而,这种现有的单类分类器越来越不能满足消费者的要求。以照相机为例,用户可能会定期拍摄某个对象,比如他的宠物。这意味着用户所希望的分类器不再像通常的那样,即仅仅是针对脸部/狗/猫等特定一类对象的分类器,而希望该分类器可以学习用户自己指定的对象(例如他的宠物)的表观特征。例如,用户希望在举起照相机时自动聚焦到他的宠物,或者希望从照相机拍摄的所有照片中找到关于他的宠物的照片。目前,大多数现有的对象检测产品依赖于收集充分多的样本以训练得到良好的分类器,然后再将训练好的分类器设置到产品中以定位目标。然而,在有些实际应用中,可能难以获得充分多的样本来训练分类器。例如,在通过交通监视系统追查特定车辆时,关于该特定车辆的先验样本通常非常少,甚至只有一个。而且,在消费者产品中,不能单纯地依赖于要求用户收集很多的样本,那样会造成较差的用户体验。因此,需要一种对象检测方法,该方法:(1)不依赖于任何先验知识,因为可能的对象类别的数目巨大,并且其分布遵循长尾理论(long-tailtheory),因此几乎不可能准备覆盖可能对象类别的在先学习库;(2)仅使用一个或几个样本就能够进行检测,但同时要求该对象检测方法要能够处理对象表观特征的变化,例如照明、视角、变形、模糊、旋转等;(3)足以将对象与同一类别中的所有其它对象进行区分,例如,要能够区分开用户自己的狗与其他人的狗。现有技术的对象检测方法不能满足上述要求。例如,在V.Ferrari和A.Zisserman所著的“Learningvisualattributes”(InNIPS,2008)中公开了“属性”的概念,但是其要求终端用户识别对象的属性。在L.Fei-Fei、R.Fergus和P.Perona所著的“Abayesianapproachtounsupervisedone-shotlearningofobjectcategories”(InICCV,pages1134-1141,2003)中公开了单次拍摄学习方法。在M.Lew的“Content-basedMultimediaInformationRetrieval:StateoftheArtandChallenges”(ACMTrans.MCCA,2006)以及J.Eakins和M.Graham的“Content-basedImageRetrieval”(UniversityofNorthumbriaatNewcastle)中描述了基于内容的图像检索方法(CBIR)。但是,上述两种方法的精度较低,不足以准确地区分同一类别中的对象。在HaeJongSeo和PeymanMilanfar的“Training-FreeGenericObjectDetectionUsingLocallyAdaptiveRegressionKernels”(IEEETrans.PAMI,vol.32,no.9,pp.1688-1704,2010)中公开了基于无训练LARK的检测方法,但这种方法不具有旋转不变性,在类内区分方面效果很差。Lowe,DavidG所著的“Objectrecognitionfromlocalscale-invariantfeatures”(ICCV.pp.1150-1157,1999)以及H.Bay、A.Ess、T.Tuytelaars和L.V.Gool所著的“SURF:SpeededUpRobustFeatures”(CVIU,pp.346-359,2008)公开了基于SIFT/SURF的局部点匹配方法。在E.Nowak,F.Jurie和B.Triggs的“SamplingStrategiesforBag-of-FeaturesImageClassification”(ECCV,2006)中公开了基于BOW/Part的模型。这几种方法不能很好地处理非常小的目标以及非刚性对象变形。如上所述的各现有技术方法均不能在较少样本的情况下提供满意的检测性能。因此,需要仅利用少量样本就能够实现高鲁棒性和高辨别力的对象检测的方法和装置。
技术实现要素:
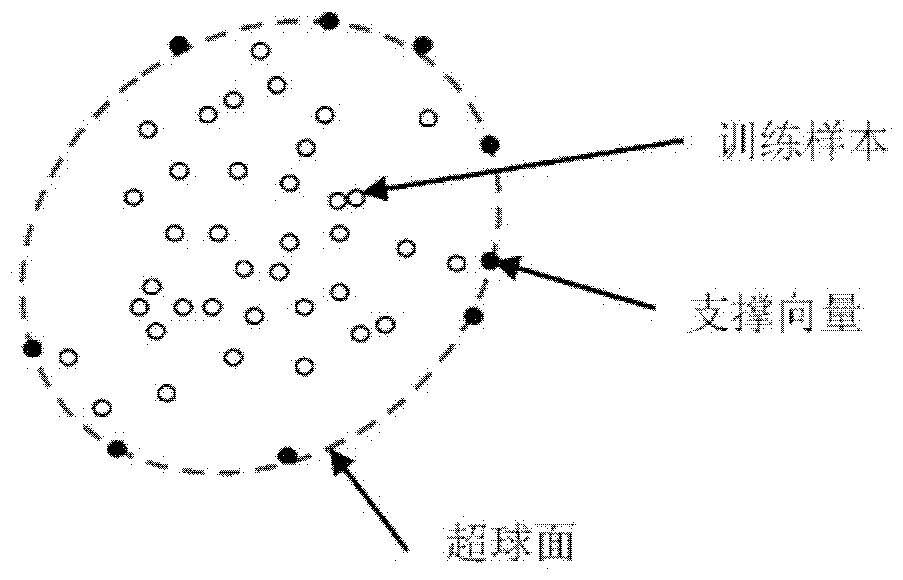
仅仅使用一个或几个样本训练有效的分类器的瓶颈在于,如何在样本数量少的情况下控制分类器的性能,即鲁棒性和辨别力。换言之,分类器既要保证能够覆盖目标对象的所有表观特征变化,又要能够足够准确地将目标对象与同一类别的其他对象区分开。而在样本数量少的情况下,样本的分散性有限,难以覆盖关于目标对象的所有可能表观特征变化,如图1所示,例如照明、视角、变形、模糊、旋转等。这也是现有技术的分类器需要足够多的样本进行训练的一个原因。为了解决上述技术问题,本发明提出了一种全新的分类学习方法和装置,该分类学习方法和装置基于支撑向量估计一个判决超球面作为分类的阈值,其中该判决超球面基本上不随样本本身或数量而变化,即任何正样本落在判决超球面内的概率基本上固定。根据本发明的第一方面,提供了一种在特征空间中的分类方法,所述特征空间包括一个或多个特征向量,所述一个或多个特征向量中的一些或全部被识别为支撑向量,所述分类方法包括:最大超球面生成步骤,用于根据所述支撑向量在所述特征空间中生成可能的最大超球面;超球面中心计算步骤,用于根据所述支撑向量计算所生成的最大超球面的中心;判决超球面生成步骤,用于利用所计算的中心和所生成的最大超球面,生成判决超球面;以及分类步骤,用于将所述判决超球面内的特征向量归类为正特征向量。根据一些实施例,所述判决超球面被生成为使得任何正特征向量落在所生成的判决超球面内的概率固定。根据一些实施例,所述超球面中心计算步骤包括:根据所述支撑向量,在所述特征空间中生成可能的最小超球面;判断在所述最小超球面内是否只有一个特征向量;如果在所述最小超球面内只有一个特征向量,则将该特征向量确定为所述最大超球面的中心;以及如果在所述最小超球面内有超过一个的特征向量,则估计所述最小超球面的中心,作为所述最大超球面的中心。根据一些实施例,所述判决超球面生成步骤包括:计算所述最大超球面的表面积;以及确定判决超球面,使得该判决超球面的中心即为所计算的最大超球面的中心,且该判决超球面与所述最大超球面的表面积之比是预定值。根据本发明的第二方面,提供了一种在特征空间中的分类装置,所述特征空间包括一个或多个特征向量,所述一个或多个特征向量中的一些或全部被识别为支撑向量,所述分类装置包括:最大超球面生成单元,配置成根据所述支撑向量在所述特征空间中生成可能的最大超球面;超球面中心计算单元,配置成根据所述支撑向量,计算由所述最大超球面生成单元生成的所述最大超球面的中心;判决超球面生成单元,配置成利用由所述超球面中心计算单元计算的中心和由所述最大超球面生成单元生成的最大超球面,生成判决超球面;以及分类单元,配置成将由所述判决超球面生成单元生成的所述判决超球面内的特征向量归类为正特征向量。根据本发明的第三方面,提供了一种对象检测方法,包括:支撑向量确定步骤,用于确定一组支撑向量;分类器训练步骤,用于基于所述支撑向量确定步骤中确定的所述一组支撑向量,利用根据第一方面所述的分类方法来训练分类器;以及对象检测步骤,用于利用所训练的分类器,从图像或视频中检测对象。根据本发明的第四方面,提供了一种对象检测装置,包括:支撑向量确定单元,配置成确定一组支撑向量;分类器训练单元,配置成基于所述支撑向量确定单元中确定的所述一组支撑向量,利用根据第一方面所述的分类方法来训练分类器;以及对象检测执行单元,配置成利用所训练的分类器,从图像或视频中检测对象。根据本发明的第五方面,提供了一种图像拍摄设备,包括:光学系统,配置成拍摄图像或视频;根据第四方面所述的对象检测装置;以及控制单元,配置成控制所述光学系统,以聚焦于由所述对象检测装置检测到的对象。根据本发明的第六方面,提供了一种图像处理设备,包括根据第四方面所述的对象检测装置。无论样本本身及其数量如何,本发明的分类和检测方法都能够将检测性能(例如,虚检率(falsepositiverate)或检出率(detectionrate))保持在预定水平,从而能够提供有效的对象检测。从参照附图的以下描述中,本发明的其他特性特征和优势将变得清晰。附图说明并入说明书并且构成说明书的一部分的附图图示本发明的实施例,并且与描述一起用于说明本发明的原理。图1是示出了示例目标对象的可能表观特征变化的示意图。图2A是示出了描述现有技术的支撑向量数据描述(SVDD)方法的示意图。图2B示意性地示出了现有技术的基于SVDD的分类方法的阈值随样本数量的变化趋势。图3A是示出了根据本发明的分类方法的原理的示意图。图3B示意性地示出了根据本发明的分类方法的阈值随样本数量的变化趋势。图4是例示了根据本公开实施例的分类方法的流程图。图5是例示了根据本公开实施例的超球面中心估计步骤的流程图。图6例示了根据本公开实施例如何判断最小可能超球面内是否只有一个特征向量。图7是例示了根据本公开实施例的判决超球面生成步骤的流程图。图8是例示了根据本公开实施例的对象检测方法的流程图。图9A和9B给出了利用本公开实施例的对象检测方法识别目标的示例。图10示出了根据本公开实施例的分类装置的功能框图。图11示出了根据本公开实施例的对象检测装置的功能框图。图12示出了可以实施本公开实施例的计算机系统的硬件配置的框图。图13是示出可以实施本公开实施例的图像拍摄设备的功能框图。具体实施方式现在将参照附图来详细描述本发明的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本发明的范围。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为授权说明书的一部分。在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。如前所述,为了实现仅基于少量样本就获得高鲁棒性和高辨别力的对象检测,需要提供一种分类器,其既能够覆盖目标对象的几乎所有表观特征变化,又能够足够准确地将目标对象与同一类别的其他对象区分开。支撑向量数据描述(supportvectordatadescription,SVDD)方法是单类分类方法的核心技术。如D.Tax和R.Duin在“Supportvectordomaindescription”(PatternRecognit.Lett.,vol.20,pp.1191-1199,1999)中所述,SVDD方法旨在找到一个包围尽可能多目标训练样本的最小体积的球面。图2A示出了描述SVDD法的示意图。在图2A所示的特征空间中,空心圆点(ο)代表对应于训练样本的特征向量,位于球面边界上的实心圆点(·)代表支撑向量。如图所示,支撑向量界定了SVDD方法获得的超球面,即确定了SVDD分类器的阈值。换言之,SVDD方法的目的在于求得如图所示的支撑向量。基于SVDD的传统对象检测方法的性能和精度依赖于训练样本集的可获得性。图2B示意性地示出了现有技术的基于SVDD的分类方法的阈值随样本数量的变化趋势。图2B中,空心圆点(ο)代表原始训练样本,实心方形(■)代表新添加的训练样本;实线圈代表基于原始训练样本获得的SVDD超球面,虚线圈代表在添加了新的训练样本之后获得的SVDD超球面。从图2B中可以看出,在较少数量的训练样本的情况下,一般来说训练样本的分散度较小,因此定义分类器阈值的SVDD超球面也比较小,如图2B中实线圈所示。显然,在这种情况下,训练出的分类器无法识别目标对象的很多表观特征变化,即检出率非常低,对象检测操作可能失败。例如,在诸如视频监测、图像检索等一些在线应用中,由于在初始状态下没有足够多的训练样本,因此传统的分类方法会因检出率过低而导致无法检测到目标对象。随着样本数量的增加,SVDD超球面不断增大,即分类器的阈值增大,如图2B中虚线圈所示。在超球面增大的情况下,检出率得到了提高,但虚检率也随之增大,即,将负样本判定为正样本的概率也增大。因此,传统的基于SVDD的对象检测方法的性能不稳定,而且在样本数量不够多时无法工作。如上面针对图1所述,在样本的特征空间中,一个样本(例如,图1中的矩形实线框所示的训练样本)仅占据很小的一个区域或者仅由一个特征向量来表征,而该样本的表观特征变化会占据特征空间中该样本周围的较大区域。为了仅根据一个或几个样本来检测出所有可能的表观特征变化,我们需要估计表观特征变化所占据的区域,即如图1中的实线椭圆圈所示出的区域。为了适当地估计特征空间中目标对象的表观特征变化所占据的区域,在本发明中,如图3A所示,首先基于支撑向量生成表观特征变化所占据的最大可能超球面(半径为Rmax);接着估计最小可能超球面(半径为Rmin),即估计出超球面的中心点;最后,利用生成的最大可能超球面和估计出的中心点,按照统计概率,生成判决超球面(半径为RT)作为分类器的阈值。无论样本数量如何,所生成的判决超球面的大小都基本上保持恒定。图3A右下角的图示意性地示出了f=R2在范围内的分布。如图3B所示,在添加了新训练样本之后,尽管支撑向量界定的超球面明显增大(如图3B中的实线圈与点划虚线圈所示),但新计算的判决超球面与原始的判决超球面相比大小基本上相同(如图3B中的两个虚点线圈所示)。下面将详细描述如何基于支撑向量生成判决超球面。需要说明的是,尽管在本公开中采用SVDD为例说明了如何训练分类器,但是本领域技术人员应当理解,本公开的分类方法也可以适用于采用支撑向量机(SupportVectorMachine,SVM)的分类器。图4例示了根据本公开实施例的分类方法的流程图。在获得目标训练样本之后,构建样本的特征空间。然后,利用SVDD方法获得包围尽可能多目标训练样本的最小体积的超球面边界,即,确定特征空间中的支撑向量。然后根据所确定的支撑向量生成可能的最大超球面(步骤10)。基于SVDD方法确定的超球面由下式表示:minR2+C∑iξi条件是||xi-a||2≤R2+ξi且ξi≥0(1)其中,a表示该超球面的中心,R表示该超球面的半径;C是惩罚因子,ξi是松弛误差,xi表示界定超球面的支撑向量。对公式(1)应用拉哥朗日(Lagrangian)乘子,可以得到下面的对偶问题:min∑i,jαiαjK(xi·xj)-∑iαiK(xi·xi)条件是0≤αi≤C且∑iαi=1(2)其中,K(·)是核函数,而且该函数值为非负。在本文中,核函数K(·)被选择为针对特征空间中的任意归一化特征向量z是恒定的,即K(z,z)是固定的。在一个实施例中,可以选择直方图交叉核(HIK)函数(参见http://c2inet.sce.ntu.edu.sg/Jianxin/projects/libHIK/libHIK_v2.pdf):其中,T和Q是特征的直方图,N是直方图维数。需要注意的是,尽管在本实施例中以公式(3)给出的HIK函数为例进行了说明,但是本领域技术人员应当理解,还可以选择Hellinger’s核函数和Jensen-Shannon核函数。求解公式(2)的对偶优化问题,可以得到支撑向量集xi∈SVs和对应的权重αi。利用上述SVDD方法求得的支撑向量xi和权重αi,我们就可以计算最大可能超球面半径Rmax。对于给定的归一化特征向量z,其到超球面中心的距离计算如下:如果则特征向量z就位于该超球面内,并被分类为目标对象类。为了求解最大可能超球面的半径Rmax,根据上面的公式(4),我们得到:(5)如前所述,针对任意归一化特征向量z,K(z,z)是固定的。在根据公式(2)计算得出支撑向量xi∈SVs和对应的权重αi的情况下,是固定值。因此,求解fmax的关键在于求得的最小值。如前所述,核函数K(·)非负,因而故而,公式(5)简化为:至此,上述公式(6)确定了最大超球面的半径Rmax。接着,参照图4中的步骤20,计算所生成的最大超球面的中心,即确定最小距离fmin。图5是例示了根据本公开实施例的超球面中心估计步骤的流程图。如图5所示,首先,根据基于公式(2)计算得到的支撑向量,生成可能的最小超球面(步骤210)。根据上述公式(4),最小距离fmin表示如下:如前所述,在所有支撑向量确定的情况下,针对任何归一化特征向量z,fmax是固定的。因此,求解fmin就转变为求解的最大值。根据核函数的定义可知,必然是一个特定值,但不会是正无穷大。接下来,判断在最小超球面内是否只有一个特征向量(步骤220),即在特征空间中,是否只有一个特征向量z到超球面中心的距离满足如果在最小超球面内只有一个特征向量,这意味着该特征向量就是最小超球面和最大超球面的中心。如果不止有一个特征向量,则需要估计最小超球面和最大超球面的中心(步骤230),如下将更详细地描述。在本例中,选择HIK函数进行描述。为了加速计算,我们定义一个查找表lut:其中,xij∈Xi,XiSVs,M是支撑向量的个数,而N是特征向量的维数。如上述(8)可知,但是max(lut)不总是等于下面将详细说明。当max(lut)可以取到时,意味着在最小超球面内只有一个特征向量。这种情况下,我们将该特征向量确定为超球面的中心,并确定参照图6,在最小超球面中的特征向量不是唯一的时,在这种情况下,需要估计fmin,即,估计max(lut)。在HIK核函数的示例中,针对第j维,定义如下:j=1,2,3......N(9)定义Hj的平均值为根据公式(8),因此,针对N维特征向量zj来说,估计lut的最大值等同于估计lut的在N个维度上的平均值的最大值,即估计下面采用统计学上的样本估计理论来估计的范围。根据中心极限定律,在样本空间中的分布满足正态分布。因此,概率Φz是累积分布,具体地如下:根据中心极限定律,根据标准误和以及概率Φz,利用标准正态累积分布函数的查找表,可以求得λz,由此确定的范围在[μ-λzσe,μ+λzσe]之间,最后可以确定最后,将公式(11)的结果代入公式(7)中,我们可以估计得到fmin。接下来,返回到图4,在步骤30中,利用在步骤20中计算的fmin和在步骤10中计算的fmax,生成判决超球面。图7是例示了根据本公开实施例的判决超球面生成步骤的流程图。参见图7,在步骤310中,计算最大超球面的表面积:f(z)在[fmin,fmax]范围内是大体相同类型的分布。下面,假定参数P,即描述判决超球面与最大超球面的表面积之比的预定值,利用在步骤20中计算的Rmin和在步骤10中计算的Rmax,来生成判决超球面的半径RT(步骤320)。参数P定义如下:P=(fT(z)-fmin)/(fmax-fmin)(13)根据公式(13),可以确定判决超球面的半径RT为:根据上述公式(14),我们针对一个特征向量z估计了一个适当的阈值,即fT(z)。最后,针对所有的支撑向量Xi∈SVs来估计fT:fT即为经训练分类器的阈值,无论训练样本有多少或怎样,都能够通过参数P将分类器的虚检率控制在稳定的水平下,即任何正特征向量落在所生成的判决超球面内的概率固定。需要说明的是,参数P本身并非表示任何正特征向量落在判决超球面内的概率,但是在参数P给定的情况下,上述概率也是固定的。最终,如图4的步骤40所示,如果特征空间中的一个特征向量处于判决超球内,则将其判定为正特征向量;反之,则将其判定为负特征向量。利用如上所述的分类方法,能够仅利用少量样本实现高鲁棒性和高辨别力的对象检测。图8是例示了根据本公开实施例的对象检测方法的流程图。首先,在步骤50中确定一组支撑向量。在一个实施例中,该组支撑向量是基于接收的一个或几个样本确定的。在另一实施例中,该组支撑向量是从其他训练好的分类器提取出的。为了保证经训练的分类器具有较高的辨别力和鲁棒性,支撑向量的数量要保持在预定水平之上。在一个示例中,要求支撑向量的个数不少于30个。因为一般来说一个特征向量对应于一个样本,所以要求样本的个数不少于预定值。在样本个数少于预定值的情况下,可以基于已有样本进行模拟操作,以扩展样本集直至样本个数满足预定值。例如,可以采用在M.Sheelagh、T.Carpendale、DavidJ.Cowperthwaite和F.DavidFracchia的“InformationVisualization“(SimonFraserUniversity,1997)中描述的3D变形方法来模拟样本集。接着,设置固定的概率参数P,并利用在图4中描述的分类方法来训练分类器,由此获得无论输入样本数量如何均保持稳定的检测性能的分类器(步骤60)。利用在步骤60中训练好的分类器,就能够从图像或视频中检测对象(步骤70)。首先根据图像或视频帧生成多个局部区域。在一个实施例中,可以先设定大小与正样本相同的搜索窗。接着,在图像或视频的帧上逐步移动搜索窗,并提取搜索窗内包含的像素以生成输入图像的一部分。在搜索窗移动通过整个输入图像之后,重新调整输入图像的尺寸。重复尺寸调整和移动步骤,直到达到预定限值。其次,从每个生成的局部区域提取特征向量,并将其输入到训练好的分类器。最后,记录所有检测到正样本的局部区域,并对对象的位置和大小进行分组。由此,可以利用少量样本就能够实现高鲁棒性和高辨别力的对象检测。图9A和9B给出了利用本公开实施例的对象检测方法识别目标的示例。选取一只波美拉尼亚狗在诸如背景、照明条件和视角等不同情形下的7个视频进行试验。从每个视频中选择一个训练样本,如图9A所示。图9B示出了本发明的方法与现有技术基于SVDD的方法相比的性能差别,其中横坐标表示每图像的虚检率,即将负样本误判为正样本的概率,纵坐标表示检出率,即正样本被检出的概率。虚检率越低且检出率越高,表明对象检测方法的性能越好。从图9B可见,现有技术的方法随着样本数量增加而虚检率增大,而在本发明中,虚检率基本上保持稳定。另外,现有技术的方法在样本数量较少时检出率非常低,而本发明的方法的检出率保持在较高的水平。图10示出了根据本公开实施例的分类装置2000的功能框图。分类装置2000的功能模块可以由实现本发明原理的硬件、软件或硬件和软件的结合来实现。本领域技术人员可以理解的是图10中所描述的功能模块可以组合起来或者划分成子模块,从而实现上述发明的原理。因此,本文的描述可以支持对本文描述的功能模块的任何可能的组合、或者划分、或者更进一步的限定。分类装置2000能够识别出特征空间中的正特征向量。特征空间可以包括一个或多个特征向量。在一个实施例中,可以利用SVDD方法来基于输入样本的特征向量而确定支撑向量。在另一实施例中,支撑向量可以是从其他训练好的分类器提取出的。分类装置2000可以包括最大超球面生成单元2010、超球面中心计算单元2020、判决超球面生成单元2030以及分类单元2040。最大超球面生成单元2010可以根据支撑向量在特征空间中生成可能的最大超球面。超球面中心计算单元2020可以根据支撑向量,计算由最大超球面生成单元2010生成的最大超球面的中心。判决超球面生成单元2030可以利用由超球面中心计算单元2020计算的中心和由最大超球面生成单元2010生成的最大超球面,生成判决超球面。该判决超球面即为分类装置2000的阈值。分类单元2040可以将由判决超球面生成单元2030生成的判决超球面内的特征向量归类为正特征向量。在一个实施例中,判决超球面被生成为使得特征空间中的任何正特征向量落在所生成的判决超球面内的概率固定。在一个实施例中,超球面中心计算单元2020进一步可以包括最小超球面生成单元2022、超球面中心判断单元2024和超球面中心确定单元2026。最小超球面生成单元2022可以根据支撑向量,在特征空间中生成可能的最小超球面。超球面中心判断单元2024可以判断在最小超球面内是否只有一个特征向量。如果在最小超球面内只有一个特征向量,则超球面中心确定单元2026将该特征向量确定为最大超球面的中心。如果在最小超球面内有超过一个的特征向量,则超球面中心确定单元2026估计最小超球面的中心,作为最大超球面的中心。在一个实施例中,判决超球面生成单元2030进一步包括最大超球面表面积计算单元2032和判决超球面确定单元2034。最大超球面表面积计算单元2032可以计算最大超球面的表面积。判决超球面确定单元2034可以将判决超球面确定为使得该判决超球面的中心即为所计算的最大超球面的中心,且该判决超球面与最大超球面表面积计算单元2032计算出的最大超球面的表面积之比是预定值。在一个实施例中,最大超球面生成单元2010、超球面中心计算单元2020和判决超球面生成单元2030采用核函数K(·)。该核函数被选择为针对所述特征空间中的任意归一化特征向量z是恒定的。例如,核函数K(·)包括直方图交叉核。图11示出了根据本公开实施例的对象检测装置3000的功能框图。对象检测装置3000的功能模块可以由实现本发明原理的硬件、软件或硬件和软件的结合来实现。本领域技术人员可以理解的是图11中所描述的功能模块可以组合起来或者划分成子模块,从而实现上述发明的原理。因此,本文的描述可以支持对本文描述的功能模块的任何可能的组合、或者划分、或者更进一步的限定。对象检测装置3000可以包括支撑向量确定单元3010、分类器训练单元3020和对象检测执行单元3030。支撑向量确定单元3010可以确定一组支撑向量。在一个实施例中,支撑向量确定单元3010可以包括用于接收一个或多个样本的样本接收单元3012和用于基于样本接收单元3012接收到的样本计算所述一组支撑向量的支撑向量计算单元3014。另选地或另外地,支撑向量确定单元3010可以包括用于从其他训练好的分类器提取支撑向量的支撑向量提取单元3016和用于基于支撑向量提取单元3016提取出的训练好的分类器的支撑向量而选择一组支撑向量的支撑向量选择单元3018。分类器训练单元3020可以基于支撑向量确定单元3010确定的一组支撑向量,利用图4所述的分类方法来训练分类器。对象检测执行单元3030可以利用训练好的分类器,从图像或视频中检测对象。图12示出了可以实施本公开实施例的计算机系统1000的硬件配置的框图。例如,计算机系统1000可以被实现为诸如台式计算机、平板计算机、膝上型计算机、报警设备、智能手机、游戏机等的图像处理设备。如图12所示,计算机系统包括计算机1110。计算机1110包括经由系统总线1121连接的处理单元1120、系统存储器1130、固定非易失性存储器接口1140、可移动非易失性存储器接口1150、用户输入接口1160、网络接口1170、视频接口1190和输出外围接口1195。系统存储器1130包括ROM(只读存储器)1131和RAM(随机存取存储器)1132。BIOS(基本输入输出系统)1133驻留在ROM1131中。操作系统1134、应用程序1135、其它程序模块1136和某些程序数据1137驻留在RAM1132中。诸如硬盘之类的固定非易失性存储器1141连接到固定非易失性存储器接口1140。固定非易失性存储器1141例如可以存储操作系统1144、应用程序1145、其它程序模块1146和某些程序数据1147。例如,如关于图11所述的对象检测装置3000可以作为一个应用程序模块而驻留在系统存储器1130或固定非易失性存储器1141中。诸如软盘驱动器1151和CD-ROM驱动器1155之类的可移动非易失性存储器连接到可移动非易失性存储器接口1150。例如,软盘1152可以被插入到软盘驱动器1151中,以及CD(光盘)1156可以被插入到CD-ROM驱动器1155中。诸如鼠标1161和键盘1162之类的输入设备被连接到用户输入接口1160。计算机1110可以通过网络接口1170连接到远程计算机1180。例如,网络接口1170可以经由局域网1171连接到远程计算机1180。或者,网络接口1170可以连接到调制解调器(调制器-解调器)1172,以及调制解调器1172经由广域网1173连接到远程计算机1180。远程计算机1180可以包括诸如硬盘之类的存储器1181,其存储远程应用程序1185。视频接口1190连接到监视器1191。输出外围接口1195连接到打印机1196和扬声器1197。图12所示的计算机系统仅仅是说明性的并且决不意图对本发明、其应用或用途的任何限制。图12所示的计算机系统可以被实施于任何实施例,可作为独立计算机,或者也可作为设备中的处理系统,可以移除一个或更多个不必要的组件,也可以向其添加一个或更多个附加的组件。在一个示例中,计算机系统1000的用户可以通过诸如键盘1162的输入设备与计算机系统1000交互,来指定例如固定非易失性存储器1141中存储的一个或几个图像样本作为要检测的目标对象,并且指定要检测的样本范围。然后,系统存储器1130或固定非易失性存储器1141中存储的对象检测模块按照图4所示的方法进行学习。接着,利用学习好的对象检测模块,从用户指定的样本范围中检测目标对象。最后,将样本范围中检测出的目标对象呈现给用户。图13是示出可以实施本公开实施例的图像拍摄设备4000的功能框图。例如,图像拍摄设备4000可以被实现为照相机、摄像机等。如图13所示,图像拍摄设备4000包括配置成拍摄图像或视频的光学系统4010、能够根据图8所示的方法操作的对象检测装置4020,以及配置成控制光学系统4010以聚焦于由对象检测装置4020检测到的对象的控制单元4030。在一个示例中,图像拍摄设备4000的用户可以在图像拍摄设备4000开机后且在进行图像拍摄之前,指定图像拍摄设备4000的存储设备(未示出)中存储的一个或几个图像样本作为要追踪的目标对象,然后根据图4所示的方法训练对象检测装置4020中包括的分类器。接下来,在图像拍摄期间,对象检测装置4020可以自动搜索预览图像(例如,照相机的取景器中呈现的图像)以确定其中是否包括要检测的目标对象,如果包括的话则定位该目标对象的位置。最后,控制单元4030控制光学系统4010以聚焦于由对象检测装置4020检测到的目标对象。在另一示例中,用户对于某一目标对象的指定可以记录在图像拍摄设备4000的存储设备中。可以通过许多方式来实施本发明的方法和设备。例如,可以通过软件、硬件、固件、或其任何组合来实施本发明的方法和设备。上述的方法步骤的次序仅是说明性的,本发明的方法步骤不限于以上具体描述的次序,除非以其他方式明确说明。此外,在一些实施例中,本发明还可以被实施为记录在记录介质中的程序,其包括用于实现根据本发明的方法的机器可读指令。因而,本发明还覆盖存储用于实现根据本发明的方法的程序的记录介质。虽然已通过示例详细展示了本发明的一些具体实施例,但是本领域技术人员应当理解,上述示例仅意图是说明性的而不限制本发明的范围。本领域技术人员应该理解,上述实施例可以被修改而不脱离本发明的范围和实质。本发明的范围是通过所附的权利要求限定的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1