区块挖掘方法和装置与流程
本申请涉及于2013年11月19日申请的临时申请序列号61/906,310(“临时专利申请”),该临时专利申请的主题及其全部内容以引用的方式明确地并入本文,并在此根据37 CFR §1.78(a)(4)要求该临时专利申请的申请日的权益。
背景技术:
1. 技术领域
本发明涉及用于挖掘(mining)区块(block),尤其是区块链(block chain)中的区块,的方法和装置,尤其涉及用于加密货币(crypto currency)系统例如比特币(Bitcoin)挖矿系统中的方法和装置。
一般而言,在以下说明书中,我们将以斜体表示本领域技术人员应该熟悉的本领域的每个专用术语的第一次出现。另外,当我们首次介绍我们认为是新的或在我们认为是新的环境中将使用的术语时,我们将以粗体来表示该术语并且提供我们意图应用于该术语的定义。另外,在整个说明书中,当指出信号、信号标志、状态位或类似设备呈现为其逻辑真或逻辑假状态时,有时我们将分别使用术语断言(assert)和否定(negate),并且使用术语切换(toggle)来表示信号从一个逻辑状态到另一逻辑状态的逻辑反转。可选地,我们可以将互斥的布尔(boolean)状态称作逻辑0(logic_0)和逻辑1(logic_1)。当然,众所周知的是,通过对全部这样的信号的逻辑含义取反能够获得一致的系统操作,使得本文中描述为逻辑真的信号变成逻辑假,反之亦然(vice versa)。此外,在这种系统中,选择哪些具体电压电平来表示每个逻辑状态毫无关系。为了便于参考,我们将使用“设置”一词来表示视情况需要的零、一或大于一的集合。
一般地,分布式网络(decentralized network)可以存储并引用区块链中的公共信息。在一典型的区块链中,每个区块(block)包含大致出现于同一时间的通常被称为交易(transactions)的信息单元。使用一预定义的协议(protocol),区块可以通过将其散列值(hash values)插入区块链的下一个顺序区块的指定字段(field)而相连(linked)。
区块链的挖掘过程的设计,是为了让系统达成一致性,其中计算机网络的所有节点(nodes)都符合同一个区块链。已经提出了若干种区块链系统,且一些正被实施。其中最早的系统之一,且目前最广泛认可的,是比特币系统。根据比特币协议,第一个成功确定候选(candidate)区块的工作量证明(proof-of-work)的矿机(miner)有权将该区块添加到区块链(有时被称为分类账(ledger)),并有权生成(generate)新的加密货币单元作为奖励。
区块的工作量证明包含随机数(nonce)值,如果将其插入该区块的指定字段,则其将使该区块的加密散列值(cryptographic hash value)达到一定的难度目标(difficulty target)。由于加密散列函数(cryptographic hash function)实际上表现为随机指示(random oracle),除了简单地反复试验(trial-and-error)来查找正确的随机数,目前尚未发现更好的方法。因此挖掘过程是一个随机(stochastic)过程。在实践中,一个特定矿机成功开发一个区块(solving a block)的可能性,在任何特定的时间点,正比于该矿机的散列率(hash rate),其与整个网络的散列率相关。
众所周知,美国国家安全局(“NSA”)已经设计并公布了一组被称为安全散列算法(“SHA”,Secure Hash Algorithms)的加密散列函数。特别地,应用SHA-256的比特币协议以如下伪代码描述:
**********
注1:所有变量都是32位无符号整数,并且加法按模232计算
注2:对于每个循环,在消息表数组w[i]中有一个循环常数k[i]和一项记录,0≤i≤63
注3:压缩函数使用从a到h的8个工作变量
注4:在表达该伪码中的常数,以及从字节到字地解析消息块数据时,使用大字节序约定,例如,在填充后,输入消息”abc”的第一个字是0x61626380
初始化散列值:(前8位素数2…19的平方根的小数部分的前32位)
h0 := 0x6a09e667;
h1 := 0xbb67ae85;
h2 := 0x3c6ef372;
h3 := 0xa54ff53a;
h4 := 0x510e527f;
h5 := 0x9b05688c;
h6 := 0x1f83d9ab;
h7 := 0x5be0cd19;
初始化循环常数的数组:(前64位素数2…311的立方根的小数部分的前32位)
k[0..63] :=
0x428a2f98, 0x71374491, 0xb5c0fbcf, 0xe9b5dba5, 0x3956c25b,
0x59f111f1, 0x923f82a4, 0xab1c5ed5, 0xd807aa98, 0x12835b01,
0x243185be, 0x550c7dc3, 0x72be5d74, 0x80deb1fe, 0x9bdc06a7,
0xc19bf174, 0xe49b69c1, 0xefbe4786, 0x0fc19dc6, 0x240ca1cc,
0x2de92c6f, 0x4a7484aa, 0x5cb0a9dc, 0x76f988da, 0x983e5152,
0xa831c66d, 0xb00327c8, 0xbf597fc7, 0xc6e00bf3, 0xd5a79147,
0x06ca6351, 0x14292967, 0x27b70a85, 0x2e1b2138, 0x4d2c6dfc,
0x53380d13, 0x650a7354, 0x766a0abb, 0x81c2c92e, 0x92722c85,
0xa2bfe8a1, 0xa81a664b, 0xc24b8b70, 0xc76c51a3, 0xd192e819,
0xd6990624, 0xf40e3585, 0x106aa070, 0x19a4c116, 0x1e376c08,
0x2748774c, 0x34b0bcb5, 0x391c0cb3, 0x4ed8aa4a, 0x5b9cca4f,
0x682e6ff3, 0x748f82ee, 0x78a5636f, 0x84c87814, 0x8cc70208,
0x90befffa, 0xa4506ceb, 0xbef9a3f7, 0xc67178f2;
预处理:
在消息上追加比特'1';
追加k比特个'0';
其中,k是大于等于0的最小的数,使得所得到的消息长度(模512,单位为比特)为448
追加消息的长度;
(没有比特'1'或填充),以比特为单位,64位大字节序(这将使整个后处理的长度为512比特的倍数)
以连续512比特一块的方式处理消息:
将消息按512比特一块拆分;
对于每个块:
{
创建一个64条记录的为32位字的消息表数组w[0..63];
(w[0..63]的初始值并不重要,所以这里用许多零填充)
将块复制到消息表数组的第一个16个字w[0..15];
将第一个16个字扩大到消息表数组的其余48个字w[16..63]:
对于i,其从16到63:
s0 := (w[i-15] 右旋 7) xor (w[i-15] 右旋18) xor (w[i-15] 右移 3);
s1 := (w[i-2] 右旋17) xor (w[i-2] 右旋19) xor (w[i-2] 右移10);
w[i] := w[i-16] + s0 + w[i-7] + s1;
初始化工作变量为当前散列值:
a := h0;
b := h1;
c := h2;
d := h3;
e := h4;
f := h5;
g := h6;
h := h7;
压缩功能的主循环:
对(for) i ,从(from) 0到 63:
{
S1 := (e 右旋(rightrotate) 6) xor (e 右旋 11) xor (e右旋25);
ch := (e and f) xor ((not e) and g);
temp1 := h + S1 + ch + k[i] + w[i];
S0 := (a右旋2) xor (a右旋13) xor (a右旋22);
maj := (a and b) xor (a and c) xor (b and c);
temp2 := S0 + maj;
h := g;
g := f;
f := e;
e := d + temp1;
d := c;
c := b;
b := a;
a := temp1 + temp2;
}
将压缩块添加到当前散列值:
h0 := h0 + a;
h1 := h1 + b;
h2 := h2 + c;
h3 := h3 + d;
h4 := h4 + e;
h5 := h5 + f;
h6 := h6 + g;
h7 := h7 + h;
}
产生最终的散列值(大字节序):
摘要 := 散列 := h0 追加(append) h1追加h2追加h3追加h4追加h5追加h6追加h7
**********
下文中,为了便于参考,我们可以使用上面伪代码中提出的术语来谈本发明的各方面。此外,通过举例的方式,本公开内容将集中讨论研究比特币协议,尽管我们意识到其他加密货币系统可能受益于本发明。
许多散列函数,包括SHA-1、SHA-2和RIPEMD家族,采用与SHA-256类似的方案。每种算法采用一种适于将输入消息(message)扩展(expand)到消息表(message schedule)的扩展函数(expansion function)(有时被称为扩展操作(expansion operation)),然后采用一种适于将消息表压缩(compress)成散列值(value)或结果(result)(有时被称为消息摘要(message digest),或者简单地称为摘要(digest))的压缩函数(compression function)(有时被称为压缩操作(compression operation))。通常情况下,压缩函数是可递归循环的(recursive),每次循环(round)压缩消息表中的一个字(word)。当应用于硬件实现时,这些函数的递归性质适合于公知的循环展开(loop unrolling)方法,结果得到计算元件(computational elements)的典型流水式(pipelined)配置。
通常,当在比特币内计算散列时,它被计算两次,即,SHA-256散列的SHA-256散列(有时被称为双SHA(double-SHA),或简单地SHA2)。大多数时候,只在例如散列的交易或区块头部(block headers)时使用SHA-256散列。然而,当更短的散列摘要是可取的时,例如,当对公钥(public key)散列以获得比特币地址(Bitcoin address)时,RIPEMD-160也可用于第二次散列。
通过设计,区块链具有竞争性。货币奖励正比于已开发(solved)的区块的数量,其反过来正比于散列率,而散列率与整个网络的散列率相关。随着竞争加剧,矿机都在积极寻求即使是改进小的散列率。一种改善散列率的已知方法是将散列查找(hash search)分散(scatter)到最大数量的散列引擎(hash engines),每种散列引擎适于独立地搜索(search)满足(satisfy)(例如,低于)所需难度目标的散列的整个随机数空间(nonce-space)的相应部分。
通常,当在比特币内计算散列时,正被散列的消息具有固定长度。这对于例如区块头部(headers)(80个字节(bytes))是这样的情况,无论何时,散列值(32个字节)本身正被散列。散列值在所有双SHA应用中都被散列。在Merkle树(Merkle tree)的信息中,以树数据结构(tree data structure)排列的散列值对(64个字节)被散列。一般情况下,适用于散列固定长度消息的散列引擎可能会更优于且不同于适用于散列任意长度消息的散列引擎。
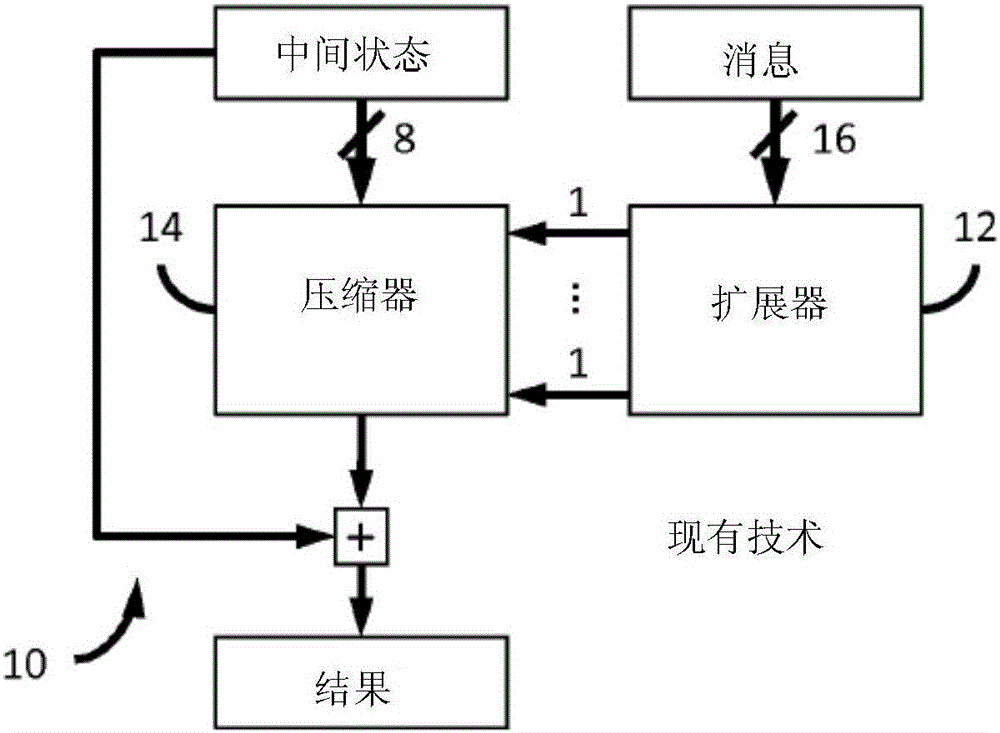
如果在专用集成电路(“ASIC”,application specific integrated circuit)中实现散列引擎时,设计目标的关键是改善功率、性能和面积。当许多相同的短长度的消息必须被散列时,采用流水式实现散列核心(core)是可能的。例如,图1示出了这种流水式的现有技术的一个程序块。在典型的ASIC中,在中央控制单元的控制下,若干个这样的流水式程序块被具现化并适于并行(parallel)或串行(serially)地操作,该中央控制单元(central control unit)可以是常规的微处理器单元(“MPU”,microprocessor unit)或是具现化于同一ASIC中的专用控制器(图未示出)。
在区块链的挖掘中,许多消息(区块)的散列仅在最后块(chunk)(即,该部分包含随机数)上不同。对于该特定类型的应用,压缩器(compressor)的中间状态(mid-state)(即,执行压缩功能的硬件部件)可被预先计算,只要它不依赖于随机数。然后,对于依赖于随机数的最后应用,可以使用如图1所示的流水式核心10。在图1中,我们已经使用常规符号表示总线宽度,用表示为32位的双字(“dwords”,double-words)作为单位。有时,根据使用环境,压缩器14可被称为半散列器(semi-hasher),而扩展器12和压缩器14的组合被称为全散列器(full-hasher)。对于本发明的目的,我们提出核心10可以流水线式(pipelined)或回旋式(rolled)具现化。
我们已于图2中示出了现有技术的回旋式核心(rolled core)10'的基本硬件结构。通常,在这种结构中,大约需要67个周期来计算一个SHA-256循环,包括64个计算周期加上少数的额外周期来加载具有初始值的寄存器。通常,若干核心10'之间共享常量(constants)的只读存储器(“ROM”,read-only-memory)。一般地,现有技术的专用回旋式核心10'可以概念化为如图3所示,其中散列计算硬件被描述成组合逻辑(combinational logic)云(cloud)。图4通过示例方式描述了现有技术中高度结构化的SHA2流水式核心10。在图5中,我们已经示出了一种典型的比特币SHA2引擎16的高级表示。
图6所示为比特币区块头部的格式,其中,标示的字段长度(field sizes)是以8比特字节标示。可以看出,在偏移(offset)36处,32字节的Merkle根字段跨越区块头部的Block[0](有时简称为"B0")和Block[1]("B1")之间的边界。例如,图7已经示出了一3级Merkle树,其具有包含4次交易(transactions)的树叶(leaf),但是可以认识到,根据被散列的交易的数量,典型的Merkle树可以具有另外的分层散列层级(hierarchical hash levels)。为了便于参考,图8中已经示出了比特币区块链内典型的3块序列,其中每个块包含一区块头部(请见图6)和各自的一组交易(以明文(clear text)方式呈现以便于区块浏览(block browsing))。在可用交易的数量小于二级工作证明(power-of-two)的情况,填充(padding)交易,例如其采用复制或虚设的方式,将被添加到树叶层级,以完成二级工作证明的树结构。根据比特币协议,每个区块的第一次交易常常是产量(generation)(或基于货币(coinbase))交易,其由将区块添加得到链的矿机而产出(generated)。
正如我们在临时申请中所解释的那样,已经提出了在区块头部(请见图6)划分4字节的版本(Version)字段,并使用例如高2字节部分作为附加随机数范围。可选地,比特币规范在基于货币(coinbase)或产量(generation)交易的格式中定义了extraNonce字段(请见图16b)。但是,比特币规范认可extraNonce字段的增加会导致Merkle树的重新计算,因为基于货币交易是最左边的叶节点。在这种方法中,每次增加extraNonce时,产生完整的Merkle根部,因此需要重新处理完整的区块头部。
我们可以察知到,当前的硬件平台设计存在一个问题,每个散列核心需要适于独立于实例化的硬件中的其他所有散列核心来进行完整的SHA-256。需要一种方法和装置来让多个压缩器时刻共享单个扩展器时刻。
技术实现要素:
在本发明的一种实施例中,我们提供一种用于区块挖掘的方法,区块包括区块头部,作为应用在区块头部的选定的散列函数的函数,选定的散列函数包括扩展操作和压缩操作。根据我们的方法,首先开发m个中间状态,每个中间状态作为有选择地改变区块头部的选定的第一部分的函数;然后对区块头部的选定的第二部分执行扩展操作以产生消息表;最后对于m个中间状态中的每一个,对中间状态与消息表执行压缩操作以产生相应的m个结果中的一个。
在另一种实施例中,我们提供用于执行我们区块挖掘方法的装置。
在又一实施例中,我们的用于区块挖掘的方法可以具现化于包含可执行指令的计算机可读介质,可执行指令在处理系统中执行时,使处理系统执行我们方法的步骤。
附图说明
本发明可以通过一些优选实施方式以及附图的描述得以更全面的理解,其中附图包括:
图1以框图形式示出了现有技术中专用SHA流水线;
图2以框图形式示出了现有技术中专用SHA回旋式核心;
图3以框图形式示出了现有技术中另一专用SHA回旋式核心;
图4以框图形式示出了现有技术中具有流水式核心的比特币SHA2散列引擎;
图5以框图形式示出了现有技术中具有回旋式核心或流水式核心的比特币SHA2散列引擎;
图6以表格方式示出了比特币区块头部的格式;
图7以框图形式示出了比特币协议中采用的多层Merkle树;
图8以框图形式示出了包含区块链的比特币区块的通用格式;
图9以框图形式示出了根据我们的临时专利申请中公开的本发明构造的比特币SHA2散列引擎;
图10以框图形式示出了根据我们的临时专利申请中公开的本发明的一种可行的硬件具现化;
图11以逻辑流程图形式示出了根据我们的临时专利申请中公开的本发明的用于操作图10的实施例的一种可行的方法;
图12以框图形式示出了根据我们的临时专利申请中公开的本发明的一种可行的并行消息表共享(message schedule sharing)实施例;
图13以框图形式示出了根据本发明的一种可行的级联型(cascaded)消息表共享实施例;
图14以框图形式示出了根据本发明的一种替代的流水式消息表预计算(message schedule pre-computation)实施例;
图15包含图15a和图15b,以框图形式示出了适于用在例如图14的可行的消息表预计算引擎;
图16包含图16a和图16b,以框图形式示出了用于图7的多层Merkle树的若干可行形式;
图17以流程图形式示出了根据本发明的一种用于产生多个Merkle根部的可行方法;
图18以框图形式示出了根据本发明的一种具有回旋式核心的可行的级联型消息表共享实施例;以及
图19以框图形式示出了根据本发明的具有回旋式核心的消息表预计算实施例。
在附图中,相似元件将尽可能标记相似。然而,该做法仅是为了便于参考并且避免不必要的附图标记的激增,而并不意在暗示或提示本公开内容要求若干实施方式中的功能或结构的一致性。
具体实施方式
图9以高层次形式示出根据我们的临时专利申请中公开的本发明构造的比特币SHA2散列引擎16。图10介绍了我们临时专利申请中公开的本发明的基本实现。优选的实施例是以ASIC形式具现化散列引擎16',其包含选定的多个例如200个SHA-256半散列器12以及相应的多个全SHA-256散列器14。每个半散列器12与相应的每个全散列器14进行流水处理。每个散列器流水线,其将一个半散列器12和一个全散列器14组合起来,输出结果为每时钟周期(clock tick)一个SHA2。每个半散列器12具有12字节中间状态寄存器18和64*4字节预计算的消息表寄存器20,其中,中间状态寄存器包含预计算的中间状态,消息表寄存器包含预计算的消息表,并且所有SHA循环展开(unrolled),并用硬件实现。按照常规,每个全散列器14包含消息表创建逻辑,以在每个时钟周期从输入区块获得消息表;并且循环也是展开的。消息表移位寄存器12a适于执行类似扩展器流水线,来以16双字滑动窗口(sliding windows)(有时也称为通道(slots))的64深度下推堆栈(push-down stack)顺序地开发输入区块的消息表,其中,在堆栈中,消息的每个新的双字进入顶部,而最早的双字于底部被移除。在操作中,每个滑动窗口被向下推导下一个更深的通道,以跟随与通道相对应的散列循环。在全散列器14的循环61处,我们提供专用的中间比较逻辑模块22,以在进行所有64次循环之前检查区块的解决方案。如果发现解决方案,则唤起(raised)中断(interrupt)(“IRQ”);可选地,所有全散列器14可以被循序继续搜索其他的解决方案,或者可以停止以节省功率。采用外部的微处理器(“MPU”,microprocessor)来处理异常,读取全散列器14的输出,并从中找到一个可以解决区块的全散列器。此外,我们提供最后32比特的检查器26,以便于为预计算重用散列器流水线。
根据本发明的一个实施例,我们直接提出了选择性地改变位于Block[0](请见图6)的Merkle根部的28字节部分。我们的方法要求矿机先执行准备阶段(preparation stage),在该阶段构建许多不同的有效Merkle根部。然而,与通常的做法相反,我们的目标是要找到若干候选Merkle根部,其以相同的4字节格式结束。例如,一种方式是选择预定的固定格式(例如4个零字节)。另一种方式是为每种格式存储Merkle根部候选,直至发现足够的侯选根部以所需格式结束。
如我们在临时专利申请中所述,散列引擎16'的操作的功能流程如图11所示。这里通过伪代码形式(用缩进表示for循环(for-loop)结构)解释其工作:
**********
1. 通过将SHA的第一块处理应用于区块头部来预计算s个中间状态MS0,..,MSs-1,该区块头部是通过设置Merkle根部字段到s个Merkle根部MR0,..,Mrs-1来修改。
2. 为固定格式创建具有B1集合的最前面32比特的B1,所有MR_i的各自最后4个字节共用。为B1的其它字段(|比特|和|时间|)设置适当的值。
3. 对于每个随机数v,
3.1. 在B1中存储随机数,并为B1预计算消息表Wv。
3.1 对于从0到s-1的每个i:
3.1.1 使用预计算消息表Wv使中间状态成为完整SHA实施,以获得中间的摘要Ti,v。
3.1.2. 将第二SHA操作应用到Ti,v,已得到双SHA摘要Di,v。
3.1.3. 比较Di,v和目标(如果最后一轮优化在使用中,该比较将在第二SHA实施引擎内完成)。
**********
为了快速计算许多有效的候选根部,一种方式是通过增加extraNonce字段并重新计算树上的父节点直至根节点的散列来构造它们。另一种方式是通过交换子节点(例如左和右)来重新排列Merkle树的子树,并重新计算父节点直至根节点;这种方法可以包括置换(permuting)交易树叶。每计算一个新的候选根部,要重新检查所需的格式,如果不匹配,则丢弃候选根部,否则将它存储起来。正如我们在临时专利申请中指出的,当Merkle树种包含Q个交易时,这种技术要求矿机执行大约s*2^32*log2(Q)次SHA2散列摘要以获得相同结果的元素。
如我们在临时专利申请所解释的,我们提出通过组合两组预生成的Merkle子树来实现更高的性能(虽然可以动态地组合所生成的Merkle子树,但是我们发现这通常更糟)。我们的准备阶段分三个步骤进行:
1. 在准备阶段的第一步,我们通过有选择地重新排列Merkle树种的交易集合,或者,也许还可以通过从所有待处理的交易池中选择不同组的交易,开发K1个节点散列,这可以在大约(K1+1)*log2(#Q1)次SHA2操作中完成,其中Q1是一组交易散列,#Q1是该组(即,左节点)的交易散列的数量,由于一旦建立Q1交易的树,则,通过交换子节点可以获得新的根部,并且每个父节点的计算需要平均log2(Q1)次SHA2散列摘要。只有父节点散列需要保存,而实际的树随后可以从内存中去除。
2. 在准备阶段的第二步,我们开发了一组节点子树的一组K2父节点散列摘要,其中交易的集合是Q2,交易(左节点)的数量是#Q2=#Q1(如上所述,这通常是可能的,因为比特币Merkle根部使用重复的交易散列来填充树的空节点)。注意,集合Q1和Q2不相交(intersect),并且通过将Q1的订单与Q2的任意订单级联(concatenation)而创建的交易的任何订单必须是有效的交易订单。另请注意,Q1的几乎所有可能的订单一般都是有效的,因为大多数矿机不产生那种具有依赖于区块内其他交易的交易区块(唯一例外的是,产量交易永远是第一位)。
对于Q1,左子树的可能候选根部的数量是(#Q1-1)!(存在3628800种可能的订单)。
对于Q2,为简单起见,我们可以假设没有重复的交易散列(即#Q1+#Q2是二级工作证明)。因此,右子树的可能候选根部的数量是(#Q2)!。如果我们选择#Q1=#Q2=11,那么存在至少2^46个可能的候选根部,其可以通过将左边集合的元素与右边集合的元素相组合而简单计算出。注意K1和K2并不需要很大,且能够表示一个小的可能订单的子集,并可使用#Q1和#Q2的更高的值。
3. 在准备阶段的第三步(其通常用我们的散列引擎16'来执行),第一组的一个父节点的散列反复地与第二组的一个父节点组合(一个左节点组合一个右节点),然后进行SHA2散列,得到根部节点散列。每次组合只需要从表中获得2个散列并执行SHA2操作。
图12所示为适用于图9的系统的核心10,其包括一个适于共享相同消息表的扩展器12以及一对同步运行的压缩器14a和14b。如上所述,每个压缩器14从使用例如我们的候选根部生成处理来生成的唯一的中间状态开始。随着散列过程通过压缩器14继续同步向下进行,消息表字流并行地通过扩展器12向下。一旦完成,每个压缩器14提供一个相应的唯一的输出状态。如在我们的基本结构那样,中间状态在完全随机数范围内保持恒定,而消息表字内的随机数在全流水线时钟速率时增加。与传统结构形成鲜明对比的是,我们的散列引擎16'只需要单个共用的扩展器12,从而不仅总系统硬件明显减少,而且功耗也明显降低。
图13所示为适用于图9的系统的通用级联核心10,其包括一个适于共享相同消息表的扩展器12以及多个同步运行的压缩器14a-14b。在这个核心10中,若干个压缩器14按级联方式连接,每个消息表元素从压缩器到压缩器顺序地传递,每个压缩器存在一个延迟间隔(适用于特定的硬件实现)。每个压缩器14从唯一的中间状态开始,一旦完成,可提供各自的唯一输出状态;然而,对应相同消息的输出状态岁时间相隔一个延迟间隔而顺序提供。需要注意的是,这种设置包括谨慎协调的2维流水线以及从上到下、从左到右的工作流程。在操作中,在每一个周期,所有压缩器14产生各自的输出状态,但对应不同消息。
在图14已经示出了我们消息表预计算方法的通用级联形式,其中散列引擎16包含适于动态地为多个压缩器14中的每一个生成唯一的中间状态的中间状态生成器28,以及适于延迟相应的中间状态到相应的压缩器14的最后级的64级延迟FIFO 30。中间状态生成器28在每一压缩器的管道时钟必须开发新的中间状态,而每个中间状态要在相同的管道时钟频率沿这一连串的压缩器传递。在我们的消息表预计算散列引擎16的实施例中,通过合适的消息表预计算引擎32动态地开发消息表字W0-W63,其例子我们已在图15中示出。在散列引擎16中,消息表字和随机数在相对长的时间内恒定。在图15a所示的实施例中,输出的字存储于和每个压缩器14相关的一组64个消息表寄存器34中。虽然我们在图15a中示出了单个共享的回旋式消息扩展器32a,但每个压缩器14具有本地的回旋式消息扩展器32a(未示出)。在图15b所示的替代实施例中,每个压缩器14具有与其关联的适于动态生成消息表字的组合逻辑云32b;因此,在这个实施例中不需要寄存器34。由于消息表寄存器34的更新相对不频繁,应该有足够的时间来解决深逻辑32b。
在图16a中,为便于参考,我们已经描述了一简单的三级二进制Merkle树,其具有4个叶节点,即交易[1::4]。根据我们的发明,寻求产生尽可能多的候选根部散列,然后确定和存储那些最后双字匹配的。一种我们称之为分而治之("D&C",divide-and-conquer)的方法的工作原理的伪代码形式如下:
**********
D&C算法:
输入:Q=2^n交易的集合(即树的叶)。
输出:L=k个根节点散列值的列表。
1. 将叶集合划分成大小为2^(n-1)的两组Q1和Q2;
2. 产生散列摘要列表L1,其中每个元素为通过置换树的节点而从Q1创建的Merkle树的根节点
3. 产生散列摘要列表L2,其中每个元素为通过置换树的节点而从Q2创建的Merkle树的根节点
3.1 对于L1中的所有x1:
3.1.1 对于L2中的所有x2:
3.1.1.1 计算x=SHA2(x1||x2),并追加到L;
4. 返回包含#L1*#L2根部的列表L。
**********
注释:
1)本流程在图17中示出。在内部循环步骤2.1.1,我们使用"::"符合表示追加操作。
2)我们的基本交易交换机制通过例如图16a的示例示出,其中右子树Q2的交易3已经与右子树Q2的交易4的交换。
3)在图16b中,我们已强调产量交易必须始终是最左侧的交易。因此在我们的D&C算法的步骤1中,产量交易被限制留在Q1。
4)由于k1、k2可以相对较小(需要大约1M列表元素的订单),我们优选以驻留在MPU 24内的软件模块来实现所有步骤,除了我们的D&C算法的外部递归外,即步骤2。一旦开发完,L1和L2可能会转发到散列核心10的流水线,以产生根部散列,然后搜索列表L中满足我们标准(大约1T列表元素的订单)的根部。
一种快速开发一组候选根部散列的可替代的方法是,在每个产量交易中增加可用的extraNonce字段(请见图16b)。由于extraNonce字段是从2到100个字节的可变长度,所以通过简单地使用extraNonce字段可以容易且快速地生成很大的候选根部散列池。虽然迄今已建议使用extraNonce字段来增加挖掘操作的有效随机数范围,但是我们并不知道任何方案所得的一组根部散列的结果,其使用预定的过滤函数(filter function)进行过滤(filtered),该过滤函数特别适用于识别那些最后4字节匹配给定标准的散列,例如我们已在我们的临时专利申请中揭露的全零或任何其他给定值。我们方法的基本优点是,只有B0受影响,允许B1的消息表被预先计算。要记住的是,最终的目标是为了方便我们的两个主要机制:消息表共享以及消息表预计算。
在图18中,我们已经说明了根据本发明采用回旋式核心结构,来使用我们的消息表共享方法。在示出的核心10'中,由单个消息扩展器12开发的消息表,并行地应用到多个同步运行的压缩器14。如图12的实施例那样,每个压缩器14用不同的中间状态初始化;这是有效的,因为一般在已经用尽随机数范围之后,新中间状态的需求相对不频繁。
在图19中,我们已经说明了如何根据本发明的采用回旋式核心结构,来使用我们的消息表预计算方法。在示出的核心10'中,由单个消息扩展器12开发的消息表,并行地应用到多个级联的压缩器14。如图14的实施例那样,生成的中间状态级联地向下通过一组相应的中间状态寄存器,经由总线运行于大约核心频率/67的频率。在这个实施例中,由于消息表更新相对不频繁,我们可以在寄存器文件中增加常数以及存储预计算的总和。
虽然我们已经通过具体实施方式描述了本发明,但是本领域普通技术人员将容易地认识到,这些实施方式可以作出许多修改,以适用于特定的实现。在未来,如果比特币区块头部的其他部分可以用作扩展的随机数空间,例如前个区块散列(previous block hash)的前32位,那么我们的方法和装置还可以使用这些额外的随机数空间,以创建本发明所需的一组中间状态。
因此,我们已经提供了区块挖掘的改进方法和装置。特别地,我们提出的新方法和装置允许一个单一的扩展时刻由多个压缩器时刻的共享。此外,我们提出的方法和设备提供了总体上优于最好的现有技术的性能。
- 还没有人留言评论。精彩留言会获得点赞!