文本分类方法以及装置与流程
本发明涉及文本分类方法以及装置。
背景技术:
随着信息技术的不断发展,人类所面临的文本信息量与日剧增,并且获取文本信息的渠道也越来越多,例如,通过浏览网页、利用搜索引擎进行信息检索、接收邮件等。然而,在用户可获得的海量的文本信息中,文本信息的价值(有效信息量)却参差不齐。因此,按照文本信息中所包含的价值(有效信息量)的大小对文本信息进行分类是组织和管理文本信息的一个有效手段,可用于过滤大量文本信息中的垃圾文本,为用户分级分类具有不同的价值(有效信息量)的文本信息,以利于对具有较高价值的文本信息的进一步加工和利用,减少对具有较低价值的文本信息的处理带来的浪费,提高用户的便利性,操作有效性以及减少成本。
在现有的文本分类方法中,通常是基于文本中所包含的具有实际意义的词汇来进行特征表示,然后通过特定分类算法的处理,得到所需分类的文本的分类结果。
然而,这样的分类方法存在的问题是认为文本所包含的各个词汇之间是相互独立的,而不考虑词汇与词汇之间的彼此关联性和相互影响。因为词汇之间的随机组合以及相邻的词汇之间的组合能够体现文本的语义,所以文本的各词汇之间是彼此关联并相互影响的。因而,若想对文本进行更精确有效的分类,需要考虑到词汇之间的随机关联性以及邻域关联性,即,也需将词汇之间的随机组合以及相邻的词汇之间的组合作为文本表示来进行特征表示。而且,若采用多种文本表示(例如,各单位词汇、各单位词汇随机组合以及各单位词汇相邻组合)并对各种文本表示进行特征表示,还能够按照文本的价值(有效信息量)的大小,对文本进行分级分类。
技术实现要素:
本发明是为了解决上述至少一个问题而完成的,其目的是提供一种能够更精确有效地分类文本,并且能够按照文本的价值(有效信息量)的大小,对文本进行分级分类的文本分类方法以及能够执行该文本分类方法的文本分类装置。
为达上述目的,根据本发明的一个方面,提供了一种文本分类方法,包括:
a.建立训练文本集,并基于训练文本集生成第一文本分类器和第二文本分类器,其中,第一文本分类器具有过滤阈值,第二文本分类器具有分类参数集,分类参数集包括第一分类参数、第二分类参数和第三分类参数;
b.采用预设的替换字符串替换待分类文本中的文本噪声来对待分类文本进行预处理,文本噪声包括标点、停用词、链接;
c.统计替换字符串在经过预处理的待分类文本中出现的概率,当概率大于等于过滤阈值时,待分类文本被划分为普通文本,当概率小于过滤阈值时,执行以下步骤;
d.对经过预处理的待分类文本进行分词处理,获得待分类文本的词矢量文本;
e.分别建立待分类文本的第一文本表示、第二文本表示以及第三文本表示,其中,第一文本表示是由待分类文本的词矢量文本中的所有单位词汇构成的单位词汇集,第二文本表示是由待分类文本的词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集,以及第三文本表示是由待分类文本的词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集;
f.基于特征表示的方法,计算待分类文本的第一文本表示的特征表示作为第一文本特征表示,计算待分类文本的第二文本表示的特征表示作为第二文本特征表示,以及计算待分类文本的第三文本表示的特征表示作为第三文本特征表示;以及
g.基于待分类文本的第一文本特征表示、第二文本特征表示以及第三文本特征表示,根据第二分类器的分类规则对待分类文本进行分类。
根据本发明的实施例所提供的文本分类方法通过考虑文本所包含的词汇之间的关联性和相互影响能够更精确有效地对文本进行分类,并且通过采用多种文本表示(即,各单位词汇、各单位词汇随机组合以及各单位词汇相邻组合)并对各种文本表示进行特征表示,还能够按照文本的价值(有效信息量)的大小,对文本进行分级分类。在分级分类中,具有相似的价值(有效信息量)的文本被划分到同一级别的类中。
根据本发明的另一个方面,提供一种文本分类装置,包括:
分类器训练模块,分类器训练模块用于建立训练文本集,并基于训练文本集生成第一文本分类器和第二文本分类器,其中,第一文本分类器具有过滤阈值,第二文本分类器具有分类参数集,分类参数集包括第一分类参数、第二分类参数和第三分类参数;
文本预处理模块,文本预处理模块采用预设的替换字符串替换待分类文本中的文本噪声来对待分类文本进行预处理,文本噪声包括标点、停用词、链接;
第一文本分类模块,所述第一文本分类模块统计替换字符串在经过预处理的待分类文本中出现的概率,当概率大于等于过滤阈值时,将待分类文本划分为普通文本;
文本分词模块,当概率小于过滤阈值时,文本分词模块对经过预处理的待分类文本进行分词处理,获得待分类文本的词矢量文本;
文本表示模块,文本表示模块分别建立待分类文本的第一文本表示、第二文本表示以及第三文本表示,其中,第一文本表示是由待分类文本的词矢量文本中的所有单位词汇构成的单位词汇集,第二文本表示是由待分类文本的词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集,以及第三文本表示是由待分类文本的词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集;
文本特征表示模块,文本特征表示模块基于特征表示的方法,计算待分类文本的第一文本表示的特征表示作为第一文本特征表示,计算待分类文本的第二文本表示的特征表示作为第二文本特征表示,以及计算待分类文本的第三文本表示的特征表示作为第三文本特征表示;以及
第二文本分类模块,第二分类模块基于待分类文本的第一文本特征表示、第二文本特征表示以及第三文本特征表示,根据第二分类器的分类规则对待分类文本进行分类。。
如上所述,采用根据本发明的实施例的文本分类方法以及文本分类装置,能够更精确有效地分类文本,并且能够按照文本的价值(有效信息量)的大小,对文本进行分级分类。
附图说明
图1显示根据本发明的实施例的文本分类方法的实现流程;
图2显示图1的步骤S101的详细处理流程;
图3显示根据本发明的实施例的文本分类器的更新流程;
图4显示根据本发明的实施例的文本分类装置的结构示意图;以及
图5显示根据本发明的实施例的文本分类装置中分类器训练模块401的结构示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,以下结合附图和具体实施例对本发明进行详细描述。
在本发明以下的说明中,以一句话或者几句话或者短句作为一个文本的实例。然而,需要说明的是,这样做只是为了便于描述实施例,而不能认为是实际处理情况。实际上, 在实际应用过程中,较佳地,以一段话、一篇文章作为一个文本来进行处理。
采用根据本发明的实施例所提供的文本分类方法,可根据文本的价值(有效信息量)的大小将文本划分为普通文本和有价值文本,其中,普通文本被认为是价值(有效信息量)较小,即,没有什么价值的文本,而有价值文本被认为是价值(有效信息量)较大的文本。而有价值文本基于其的价值(有效信息量)的大小被分类为一般价值文本、较有价值文本以及最有价值文本。
图1显示根据本发明的实施例的文本分类方法的实现流程。如图1所示,本发明的实施例所提供的文本分类方法包括如下步骤:
步骤S101:建立训练文本集,并基于训练文本集生成第一文本分类器和第二文本分类器,其中,第一文本分类器具有过滤阈值,第二文本分类器具有分类参数集,分类参数集包括第一分类参数、第二分类参数和第三分类参数。
实施例中,用作训练文本集中的训练文本是经过预处理(详见以下描述)的训练用文本。对于一个需要进行分类处理的整体文本集,作为训练用文本的文本是该整体文本集中的文本。实施例中,最初开始对整体文本集进行分类处理时,首先会从该整体文本集中随机选择一部分文本作为训练用文本,而另一部分文本或者整体文本集中的所有文本作为待分类文本。并且,当某一个或者某一些待分类文本的分类处理完成之后,该些完成分类处理的文本也会被用作训练用文本,用于训练文本集的更新。
例如,在进行步骤S101的处理时,用作训练用文本的是如下7个文本:
1、还好还好,蛋糕还好,饮料还好,炒饭也还好吧,呵呵。
2、还不错,蛮好吃的。
3、最喜欢吃芝士蛋糕。还不错,好吃的………大人和小孩满意而回。
4、蛋糕还好,不错,味道好,小贵。
5、东西还不错。
6、环境还不错啦,蛋糕也还好。
7、很不错的。
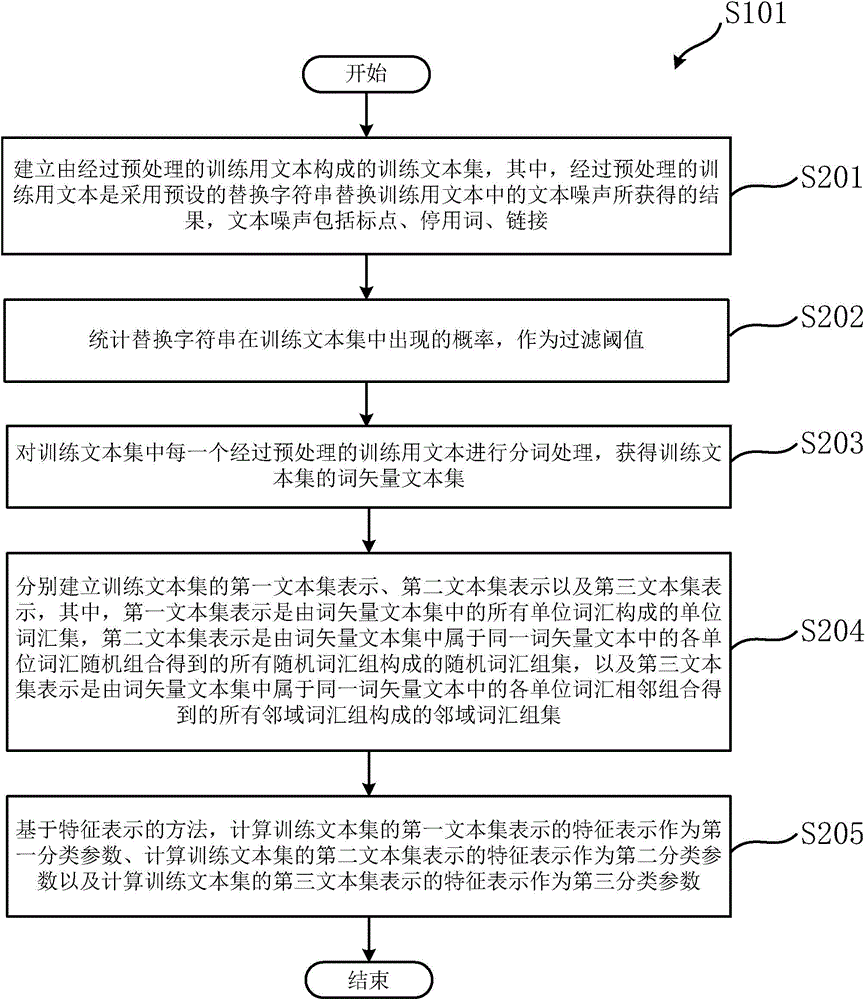
以下,参考图2,对步骤S101中执行的处理进行进一步的详细说明。
如图2所示,在步骤S201中,建立由经过预处理的训练用文本构成的训练文本集,其中,经过预处理的训练用文本是采用预设的替换字符串替换训练用文本中的文本噪声所获得的结果,文本噪声包括标点、停用词、链接。
具体地,在该步骤中,通过引用词库,采用预设的替换字符串“##”替换训练用文本 中的标点、停用词、链接等文本噪声来对训练用文本进行预处理。这里,停用词是指出现频率较高但是没有实际意义的词,例如“的”、“了”、“得”等。实施例中,用作预设的替换字符串的是“##”,但本发明并不限于此,可以采用不是文字、字母和数字的其它任何字符串。
例如,上述7个训练用文本经过预处理之后,得到如下7个经过预处理的训练用文本:
1、还好还好##蛋糕还好##饮料还好##炒饭##还好########
2、##不错####好吃####
3、##喜欢吃芝士蛋糕####不错##好吃######大人##小孩满意而回##
4、蛋糕还好##不错##味道好##小贵##
5、东西##不错##
6、环境##不错####蛋糕##还好##
7、##不错####
因而,在步骤S201中,建立由该7个经过预处理的训练用文本所构成的训练文本集。
随后,在步骤S202中,统计替换字符串在训练文本集中出现的概率,作为过滤阈值。
例如,在上述训练文本集中,替换字符串“##”的个数为36个,且其中文字的个数为64,因此,可统计出替换字符串“##”在该训练文本集中出现的概率P0:
P0=36/(36+64)=0.36
因而,在步骤S202中,该概率P0=0.36被作为第一文本分类器的过滤阈值。
随后,在步骤S203中,对训练文本集中每一个经过预处理的训练用文本进行分词处理,获得训练文本集的词矢量文本集。
具体地,在该步骤中,去除训练文本集中每一个经过预处理的训练用文本中的替换字符串后再进行分词处理。
例如,对上述训练文本集中7个经过预处理的训练用文本进行分词处理,得到如下7个词矢量文本:
1、还好 还好 蛋糕 还好 饮料 还好 炒饭 还好
2、不错 好吃
3、喜欢 吃 芝士 蛋糕 不错 好吃 大人 小孩 满意而回
4、蛋糕 还好 不错 味道 好 小贵
5、东西 不错
6、环境 不错 蛋糕 还好
7、不错
因此,在该步骤S203中,获得由该7个词矢量文本构成的词矢量文本集。
随后,在步骤S204中,分别建立训练文本集的第一文本集表示、第二文本集表示以及第三文本集表示,其中,第一文本集表示是由词矢量文本集中的所有单位词汇构成的单位词汇集,第二文本集表示是由词矢量文本集中属于同一词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集,以及第三文本集表示是由词矢量文本集中属于同一词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集。
需要说明的是,本发明中所涉及的随机词汇组和邻域词汇组中至少包括两个单位词汇。实施例中,以单位词汇进行两两组合为例,但本发明并不限于此,可以对单位词汇进行三三组合、四四组合等等。
具体地,在该步骤中,首先,建立训练文本集的第一文本集表示,第一文本集表示是由步骤S203中的词矢量文本集中的所有单位词汇构成的单位词汇集。
例如,在上述7个词矢量文本构成的词矢量文本集中,共有8+2+9+6+2+4+1=32个单位词汇,因此在该步骤中建立由该32个单位词汇构成的单位词汇集D11作为训练文本集的第一文本集表示。
之后,建立训练文本集的第二文本集表示,第二文本集表示是由词矢量文本集中属于同一词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集。
例如,在上述7个词矢量文本构成的词矢量文本集中,以其中的词矢量文本6为例,对词矢量文本6中的各单位词汇进行两两随机组合,可得到随机词汇组:(环境,不错)、(环境,蛋糕)、(环境,还好)、(不错,蛋糕)、(不错,还好)、(蛋糕,还好),共C42=6个随机词汇组。同样,对其中的每一个其它词矢量文本中的各单位词汇进行两两随机组合,可得到其它的随机词汇组。因此,共可获得C82+C22+C92+C62+C22+C42=87个随机词汇组,因此,在该步骤中建立由该87个随机词汇组构成的随机词汇组集D12作为训练文本集的第二文本集表示。
随后,建立训练文本集的第三文本集表示,第三文本集表示是由词矢量文本集中属于同一词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集。
例如,在上述7个词矢量文本构成的词矢量文本集中,对其中词矢量文本6中的各单位词汇进行两两相邻组合,可得到邻域词汇组:(环境,不错)、(不错,蛋糕)、(蛋糕,还好),共4-1=3个邻域词汇组。同样,对其中的每一个其它词矢量文本中的各单位 词汇进行两两相邻组合,可得到其它的邻域词汇组。因此,共可获得(8-1)+(2-1)+(9-1)+(6-1)+(2-1)+(4-1)=25个邻域词汇组,因此,在该步骤中建立由该25个邻域词汇组构成的邻域词汇组集D13作为训练文本集的第三文本集表示。
接下来,在步骤S205中,基于特征表示的方法,计算训练文本集的第一文本集表示的特征表示作为第一分类参数、计算训练文本集的第二文本集表示的特征表示作为第二分类参数以及计算训练文本集的第三文本集表示的特征表示作为第三分类参数。
对于特征表示方法,例如可以采用信息熵或者加权TF-IDF的平均值。这里,词汇集/词汇组集的信息熵或者加权TF-IDF的平均值可以用于度量词汇集/词汇组集的价值(有效信息量)的大小,即,可以用于度量文本或者文本集的价值(有效信息量)的大小。实施中,以信息熵作为实例来进行详细说明。对于加权TF-IDF的平均值可参考公知技术,本发明在此省略对其的详细说明。
具体地,在该步骤中,当采用信息熵的特征表示的方法时,首先,统计训练文本集第一文本集表示(单位词汇集)中每一种单位词汇的词频(这里指的是,在第一文本集表示中出现的次数),基于每一种单位词汇的词频计算每一种单位词汇的信息量,并基于每一种单位词汇的信息量计算第一文本集表示的信息熵作为第一分类参数;其次,统计训练文本集第二文本集表示(随机词汇组集)中每一种随机词汇组的词频(这里指的是,在第二文本集表示中出现的次数),基于每一种随机词汇组的词频计算每一种随机词汇组的信息量,并基于每一种随机词汇组的信息量计算第二文本集表示的信息熵作为第二分类参数;再次,统计训练文本集第三文本集表示(邻域词汇组集)中每一种邻域词汇组的词频(这里指的是,在第三文本集表示中出现的次数),基于每一种邻域词汇组的词频计算每一种邻域词汇组的信息量,并基于每一种邻域词汇组的信息量计算第三文本集表示的信息熵作为第三分类参数,其中,第一文本集表示的信息熵是其中各种单位词汇的信息量的加权平均值,第二文本集表示的信息熵是其中各种随机词汇组的信息量的加权平均值,第三文本集表示的信息熵是其中各种邻域词汇组的信息量的加权平均值。
训练文本集的第j(j=1,2,3)种文本集表示中的第i(i>=1)种单位词汇或者随机/邻域词汇组Xij的信息量Sij采用如下公式计算:
Sij(Xij)=-ln(Pij)
其中,pij表示第j种文本集表示中第i种单位词汇或者随机/邻域词汇组Xij在第j种文本集表示中出现的概率。
进而,求解第j种文本集表示中的各种单位词汇或者随机/邻域词汇组的信息量的加 权平均值,得到第j种文本集表示的信息熵μj如下:
例如,在该步骤中,首先对于作为训练文本集的第一文本集表示的单位词汇集D11(共32个单位词汇,有17种单位词汇),统计出每一种单位词汇的词频如下:
还好:7次,蛋糕:4次,饮料:1次,炒饭:1次,不错:6次,好吃:2次,喜欢:1次,吃:1次,芝士:1次,大人:1次,小孩:1次,满意而回:1次,味道:1次,好:1次,小贵:1次,东西:1次,环境:1次
因而,基于统计出的每一种单位词汇的词频,可以得到每一种单位词汇出现的概率为:
还好:7/32,蛋糕:4/32,饮料:1/32,炒饭:1/32,不错:6/32,好吃:2/32,喜欢:1/32,吃:1/32,芝士:1/32,大人:1/32,小孩:1/32,满意而回:1/32,味道:1/32,好:1/32,小贵:1/32,东西:1/32,环境:1/32
进而,可以计算每一种单位词汇的信息量:
S11(还好)=-ln(7/32),S21(蛋糕)=-ln(4/32),S31(饮料)=-ln(1/32),……,S161(东西)=-ln(1/32),S171(环境)=-ln(1/32)
基于上述得到的每一种单位词汇的信息量,计算出第一文本集表示的信息熵μ1:
μ1=-(7/32)ln(7/32)-(4/32)ln(4/32)-(1/32)ln(1/32)-……
-(1/32)ln(1/32)-(1/32)ln(1/32)
=-[(7/32)ln(7/32)+(4/32)ln(4/32)+13*(1/32)ln(1/32)
+(6/32)ln(6/32)+(2/32)ln(2/32)]
=2.4875
因此,该信息熵μ1=2.4875被作为第二分类器的第一分类参数。
其次,对于作为训练文本集的第二文本集表示的随机词汇组集D12(共87个随机词汇组,有60种随机词汇组),统计出每一种随机词汇组的词频如下:
(蛋糕,还好):7次,(饮料,还好):5次,(炒饭,还好):5次,(还好,还好):10次,(不错,好吃):2次,(蛋糕,不错):3次,(不错,还好):2次,其他53种随机词汇组各:1次
因而,基于统计出的每一种随机词汇组的词频,可以得到每一种随机词汇组出现的概率为:
(蛋糕,还好):7/87,(饮料,还好):5/87,(炒饭,还好):5/87,(还好,还好):10/87,(不错,好吃):2/87,(蛋糕,不错):3/87,(不错,还好):2/87, 其他53种随机词汇组各为:1/87
进而,可以计算每一种随机词汇组的信息量:
S12((蛋糕,还好))=-ln(7/87),S22((饮料,还好))=-ln(5/87),S32((炒饭,还好))=-ln(5/87),……,S592((…,…))=-ln(1/87),S602((…,…))=-ln(1/87),
基于上述得到的每一种随机词汇组的信息量,计算出第二特征集表示的信息熵μ2:
μ2=-(7/87)ln(7/87)-(5/87)ln(5/87)
-(5/87)ln(5/87)-……-(1/87)ln(1/87)-(1/87)ln(1/87)
=-[(7/87)ln(7/87)+2*(5/87)ln(5/87)+(10/87)ln(10/87)
+2*(2/87)ln(2/87)+(3/87)ln(3/87)+53*(1/87)ln(1/87)]
=3.7924
因此,该信息熵μ2=3.7924将被作为第二分类器的第二分类参数。
再次,对于作为训练文本集的第三文本集表示的邻域词汇组集D13(共25个邻域词汇组,有22种邻域词汇组),统计出每一种邻域词汇组的词频如下:
(蛋糕,还好):3次,(不错,好吃):2次,其他20种邻域词汇组各:1次
因而,基于统计出的每一种邻域词汇组的词频,可以得到每一种邻域词汇组出现的概率为:
(蛋糕,还好):3/25,(不错,好吃):2/25,其他20种邻域词汇组各为:1/25
进而,可以计算每一种邻域词汇组的信息量:
S13((蛋糕,还好))=-ln(3/25),S23((不错,好吃))=-ln(2/25),
……S213((…,…))=-ln(1/25),S223((…,…))=-ln(1/25)
基于上述得到的每一种邻域词汇组的信息量,计算出第三文本集表示的信息熵μ3:
μ3=-(3/25)ln(3/25)-(2/25)ln(2/25)-……
-(1/25)ln(1/25)-(1/25)ln(1/25)
=-[(3/25)ln(3/25)+(2/25)ln(2/25)+20*(1/25)ln(1/25)]
=3.0328
因此,该信息熵μ3=3.0328将被作为第二分类器的第三分类参数。
由此,可以获得第二文本分类器的分类参数集U:
U={μ1,μ2,μ3}={2.4875,3.7924,3.0328}
接下来,返回图1,继续描述根据本发明的实施例的文本分类方法。
步骤S102:采用预设的替换字符串替换待分类文本中的文本噪声来对待分类文本进 行预处理,文本噪声包括标点、停用词、链接。步骤S102中的预处理与步骤S201中的预处理类似。
例如,若当前是对文本(a)“很好,很不错,很赞!很好,很不错,很赞!”进行分类,则当前文本(a)为待分类文本(a),因而在该步骤S102中使用“##”替换待分类文本(a)中的标点、停用词,链接等,得到如下经过预处理的待分类文本(a):
##好####不错####赞####好####不错####赞##
若当前是对文本(b)“性价比不错,只是人一多,服务就有些跟不上了。”进行分类,则当前文本(b)为待分类文本(b),因而在该步骤S102中使用“##”替换待分类文本(b)中的标点、停用词,链接等,得到如下经过预处理的待分类文本(b):
性价比不错##只是人一多##服务##有些跟不上####
若当前是对文本(c)“榴莲芝士蛋糕是吃过的最好吃的。”进行分类,则当前文本(c)为待分类文本(c),因而在该步骤S102中使用“##”替换待分类文本(c)中的标点、停用词,链接等,得到如下经过预处理的待分类文本(c):
榴莲芝士蛋糕是吃过####好吃####
若当前是对文本(d)“还好,不错”进行分类,则当前文本(d)为待分类文本(d),因而在该步骤S102中使用“##”替换待分类文本(d)中的标点、停用词,链接等,得到如下经过预处理的待分类文本(d):
还好##不错
步骤S103:统计替换字符串在经过预处理的待分类文本中出现的概率。
例如,若对于上述经过预处理的待分类文本(a),可统计出替换字符串“##”在其中出现的概率:
P=12/(12+8)=0.6
若对于上述经过预处理的待分类文本(b),可统计出替换字符串“##”在其中出现的概率:
P=5/(5+17)=0.227
若对于上述经过预处理的待分类文本(c),可统计出替换字符串“##”在其中出现的概率:
P=4/(4+11)=0.267
若对于上述经过预处理的待分类文本(d),可统计出替换字符串“##”在其中出现的概率:
P=1/(1+4)=0.2
步骤S104:判断步骤S103中统计出的概率是否大于等于过滤阈值,如果是,则执行步骤S105,若否,则执行步骤S106。
例如,由于上述步骤S103中统计出的替换字符串“##”在经过预处理的待分类文本(a)中出现的概率P=0.6>P0=0.36,因此将执行步骤S105。
由于上述步骤S103中统计出的替换字符串“##”在经过预处理的待分类文本(b)中出现的概率P=0.227<P0=0.36,因此将执行步骤S106。
由于上述步骤S103中统计出的替换字符串“##”在经过预处理的待分类文本(c)中出现的概率P=0.267<P0=0.36,因此将执行步骤S106。
由于上述步骤S103中统计出的替换字符串“##”在经过预处理的待分类文本(d)中出现的概率P=0.2<P0=0.36,因此将执行步骤S106。
步骤S105:将待分类文本划分为普通文本。
例如,在该步骤中,上述待分类文本(a)被划分为普通文本。而此时对于待分类文本(b)、(c)、(d)还无法确定它们的所属类别,需要执行后面的步骤来进行确定。
可以看出,通过步骤S103统计替换字符串在经过预处理的待分类文本中出现的概率,并根据步骤S104中该概率与第一分类器的过滤阈值之间的相对大小关系确定执行步骤S105还是步骤S106,实际上是直接过滤掉没有太大价值(即,没有什么有效信息量)的待分类文本而不再通过执行后续的处理来对其进行分类的过程。由于替换字符串出现的概率越大,说明待分类文本中包含的文本噪声越多,相应地,待分类文本的价值(有效信息量)也就越小,因而,通过后续的步骤进一步确定其的价值(有效信息量)再对其进行分类也就变得没有特别大的意义,而且,通过将其直接确定为普通文本而不再执行后续步骤的处理还能够提高文本分类执行的效率,节约时间和内存资源的消耗等。
步骤S106:对经过预处理的待分类文本进行分词处理,获得待分类文本的词矢量文本。步骤S106的处理与步骤S203的处理类似。
例如,若对于上述经过预处理的待分类文本(b),在该步骤中,对其进行分词,得到如下的词矢量文本(b):
性价比 不错 只是 人一多 服务 有些 跟不上
若对于上述经过预处理的待分类文本(c),在该步骤中,对其进行分词,得到如下的词矢量文本(c):
榴莲 芝士 蛋糕 是 吃过 好吃
若对于上述经过预处理的待分类文本(d),在该步骤中,对其进行分词,得到如下的词矢量文本(d):
还好不错
步骤S107:分别建立待分类文本的第一文本表示、第二文本表示以及第三文本表示,其中,第一文本表示是由待分类文本的词矢量文本中的所有单位词汇构成的单位词汇集,第二文本表示是由待分类文本的词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集,以及第三文本表示是由待分类文本的词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集。步骤S107的处理与步骤S204的处理类似。
具体地,在该步骤中,首先,建立待分类文本的第一文本表示,第一文本表示是由步骤S106中的待分类文本的词矢量文本中的所有单位词汇构成的单位词汇集;之后,建立待分类文本的第二文本表示,第二文本表示是由待分类文本的词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集;随后,建立待分类文本的第三文本表示,第三文本表示是由待分类文本的词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集。
例如,对于上述词矢量文本(b),共有7个单位词汇,因此首先建立由该7个单位词汇构成的单位词汇集D21作为待分类文本(b)的第一文本表示;之后,对词矢量文本(b)中的各单位词汇进行两两随机组合共得到C72=21个随机词汇组,因此,建立由该21个随机词汇组构成的随机词汇组集D22作为待分类文本(b)的第二文本表示;随后,对词矢量文本(b)中的各单位词汇进行两两相邻组合共得到(7-1)=6个邻域词汇组,因此,建立由该6个邻域词汇组构成的邻域词汇组集D23作为待分类文本(b)的第三文本表示。
对于上述词矢量文本(c),共有6个单位词汇,因此首先建立由该6个单位词汇构成的单位词汇集D21作为待分类文本(c)的第一文本表示;之后,对词矢量文本(c)中的各单位词汇进行两两随机组合共得到C62=15个随机词汇组,因此,建立由该15个随机词汇组构成的随机词汇组集D22作为待分类文本(c)的第二文本表示;随后,对词矢量文本(c)中的各单位词汇进行两两相邻组合共得到(6-1)=5个邻域词汇组,因此,建立由该5个邻域词汇组构成的邻域词汇组集D23作为待分类文本(c)的第三文本表示。
对于上述词矢量文本(d),共有2个单位词汇,因此首先建立由该2个单位词汇构成的单位词汇集D21作为待分类文本(d)的第一文本表示;之后,对词矢量文本(d)中的各单位词汇进行两两随机组合共得到C22=1个随机词汇组,因此,建立由该1个随机词 汇组构成的随机词汇组集D22作为待分类文本(d)的第二文本表示;随后,对词矢量文本(d)中的各单位词汇进行两两相邻组合共得到(2-1)=1个邻域词汇组,因此,建立由该1个邻域词汇组构成的邻域词汇组集D23作为待分类文本(d)的第三文本表示。
步骤S108:基于特征表示的方法,计算待分类文本的第一文本表示的特征表示作为第一文本特征表示,计算待分类文本的第二文本表示的特征表示作为第二文本特征表示,以及计算待分类文本的第三文本表示的特征表示作为第三文本特征表示。
具体地,在该步骤中,当采用信息熵的特征表示的方法时,首先,统计待分类文本的第一文本表示(单位词汇集)中每一种单位词汇的词频,基于每一种单位词汇的词频计算每一种单位词汇的信息量,并基于每一种单位词汇的信息量计算第一文本表示的信息熵作为第一文本特征表示;其次,统计待分类文本的第二文本表示(随机词汇组集)中每一种随机词汇组的词频,基于每一种随机词汇组的词频计算每一种随机词汇组的信息量,并基于每一种随机词汇组的信息量计算第二文本表示的信息熵作为第二文本特征表示;再次,统计待分类文本的第三文本表示(邻域词汇组集)中每一种邻域词汇组的词频,基于每一种邻域词汇组的词频计算每一种邻域词汇组的信息量,并基于每一种邻域词汇组的信息量计算第三文本表示的信息熵作为第三文本特征表示。
这里,需要说明的是,该步骤中,统计每一种单位词汇、随机词汇组或者邻域词汇组的词频以及计算每一种单位词汇、随机词汇组或者邻域词汇组的信息量时,结合利用上述步骤S101的步骤S205中所统计出的训练文本集的第一文本集表示至第三文本集表示中的各种单位词汇和随机/邻域词汇组的词频,具体如下:
若训练文本集的第一文本集表示中存在待分类文本的第一文本表示中的某种单位词汇,则该步骤中,待分类文本的第一文本表示中该种单位词汇的词频采用步骤S101的步骤S205中统计出的训练文本集第一文本集表示中该种单位词汇的词频(即,该种单位词汇在第一文本集表示中出现的次数);相反,若训练文本集的第一文本集表示中不存在待分类文本的第一文本表示中的某种单位词汇,则该步骤中,待分类文本的第一文本表示中该种单位词汇的词频记为1。相应地,对于待分类文本的第二/第三文本表示中随机/邻域词汇组的词频的统计采用类似的方法,在此不再详细赘述。
此外,该步骤中,计算每一种单位词汇、随机词汇组以及邻域词汇组的信息量时结合使用训练文本集第一文本集表示、第二文本集表示以及第三文本集表示中的单位词汇、随机词汇组以及邻域词汇组的总数目。
因此,在该步骤中,待分类文本的第k(k=1,2,3)种文本表示中的第l(l>=1)种单位词 汇或者随机/邻域词汇组Ylk的信息量Slk’采用如下公式计算:
Slk(Ylk)'=-ln(Plk')
其中,plk’=nlk/Nk,nlk是统计出的待分类文本的第k种文本表示中的第l种单位词汇或者随机/邻域词汇组Ylk的词频,Nk是训练文本集第k种文本集表示中的单位词汇或者随机/邻域词汇组的总数目。
进而,求解待分类文本的第k种文本表示中的各种单位词汇或者随机/邻域词汇组的信息量的加权平均值,得到第k种文本表示的信息熵λk如下:
其中,Plk是第k种文本表示中第l种单位词汇或者随机/邻域词汇组在第k种文本表示中出现的概率。
例如,对于上述待分类文本(b),在该步骤中,首先对于作为待分类文本(b)的第一文本表示的单位词汇集D21(共有7种单位词汇),统计出每一种单位词汇的词频如下:由于单位词汇“不错”在训练文本集的第一文本集表示(单位词汇集D11)中出现了,所以,这里“不错”的词频使用步骤S101的步骤S205中对其统计出的词频6,由于其它6种单位词汇“性价比”、“只是”、“人一多”、“服务”、“有些”、“跟不上”在第一文本集表示中没有出现,所以这6种单位词汇的词频分别记为1。又由于训练文本集的第一文本集表示中共有32个单位词汇,因此,基于上面统计出的每一种单位词汇的词频以及训练文本集的第一文本集表示中单位词汇的总数目,可以得到待分类文本(b)的第一文本表示中每一种单位词汇的信息量:
S11’(性价比)=-ln(1/32),S21’(不错)=-ln(6/32),S31’(只是)=-ln(1/32),S41’(人一多)=-ln(1/32),S51’(服务)=-ln(1/32),S61’(有些)=-ln(1/32),S71’(跟不上)=-ln(1/32),
基于上述得到的每一种单位词汇的信息量,计算出待分类文本(b)的第一文本表示的信息熵λ1:
λ1=-(1/7)ln(1/32)-(1/7)ln(6/32)-(1/7)ln(1/32)-(1/7)ln(1/32)
-(1/7)ln(1/32)-(1/7)ln(1/32)-(1/7)ln(1/32)
=-[6*(1/7)ln(1/32)+(1/7)ln(6/32)]
=3.2097
因此,该信息熵λ1=3.2097被作为待分类文本(b)的第一文本特征表示。
其次,对于作为待分类文本(b)的第二文本表示的随机词汇组集D22(共有21种随 机词汇组),统计出每一种随机词汇组的词频如下:由于没有任何一种随机词汇组在训练文本集的第二文本集表示(随机词汇组集D12)中出现,所以这21种随机词汇组的词频分别记为1。又由于训练文本集的第二文本集表示中共有87个随机词汇组,因此,基于上面统计出的每一种随机词汇组的词频以及训练文本集的第二文本集表示中随机词汇组的总数目,可以得到待分类文本(b)的第二文本集表示中各种随机词汇的信息量:
S12’((…,…))=S22’((…,…))=S32’((…,…))=……=S202’((…,…))=S212’((…,…))=-ln(1/87)
基于上述得到的每一种随机词汇组的信息量,计算出待分类文本(b)的第二文本表示的信息熵λ2:
λ2=-(1/21)ln(1/87)-(1/21)ln(1/87)-(1/21)ln(1/87)-……
-(1/21)ln(1/87)=-21*(1/21)ln(1/87))
=4.4659
因此,该信息熵λ2=4.4659被作为待分类文本(b)的第二文本特征表示。
再次,对于作为待分类文本(b)的第三文本表示的邻域词汇组集D23(共有6种邻域词汇组),统计出每一种邻域词汇组的词频如下:由于没有任何一种邻域词汇组在训练文本集的第三文本集表示(随机词汇组集D13)中出现,所以这6种邻域词汇组的词频分别记为1。又由于训练文本集的第三文本集表示中共有25个邻域词汇组,因此,基于上面统计出的每一种邻域词汇组的词频以及训练文本集的第三文本集表示中邻域词汇组的总数目,可以得到待分类文本(b)的第三文本集表示中各种邻域词汇的信息量:
S13’((…,…))=S23’((…,…))=S33’((…,…))=S43’((…,…))=S53’((…,…))=S63’((…,…))=-ln(1/25)
基于上述得到的每一种邻域词汇组的信息量,计算出待分类文本(b)的第三文本表示的信息熵:
λ3=-(1/6)ln(1/25)-(1/6)ln(1/25)-(1/6)ln(1/25)
-(1/6)ln(1/25)-(1/6)ln(1/25)-(1/6)ln(1/25))
=-6*(1/6)ln(1/25)
=3.2189
因此,该信息熵λ3=3.2189被作为待分类文本(b)的第三文本特征表示。
类似地,对于上述待分类文本(c),在该步骤中,首先对于作为待分类文本(c)的第一文本表示的单位词汇集D21(共有6种单位词汇),统计出每一种单位词汇的词频如 下:“芝士”、“蛋糕”、“好吃”分别使用步骤S101的步骤S205中分别对它们统计出的词频1,4,2,其它3种单位词汇的词频分别记为1。
基于上面统计出的每一种单位词汇的词频以及训练文本集的第一文本集表示中单位词汇的总数目32,可以得到待分类文本(c)的第一文本表示中各种单位词汇的信息量,以及基于得到的每一种单位词汇的信息量,计算出待分类文本(c)的第一文本表示的信息熵:λ1=3.1191。
因此,该信息熵λ1=3.1191被作为待分类文本(c)的第一文本特征表示。
其次,对于作为待分类文本(c)的第二文本表示的随机词汇组集D22(共有15种随机词汇组),统计出每一种随机词汇组的词频如下:该15种随机词汇组的词频分别记为1。
基于上面统计出的每一种随机词汇组的词频以及训练文本集的第二文本集表示中随机词汇组的总数目87,可以得到待分类文本(c)的第二文本表示中各种随机词汇组的信息量,以及基于得到的每一种随机词汇组的信息量,计算出待分类文本(c)的第二文本表示的信息熵:λ2=4.4659。
因此,该信息熵λ2=4.4659被作为待分类文本(c)的第二文本特征表示。
再次,对于作为待分类文本(c)的第三文本表示的邻域词汇组集D23(共有5种邻域词汇组),统计出每一种邻域词汇组的词频如下:该5种邻域词汇组的词频分别记为1。
基于上面统计出的每一种邻域词汇组的词频以及训练文本集的第三文本集表示中邻域词汇组的总数目25,可以得到待分类文本(c)的第三文本集表示中各种邻域词汇的信息量,以及基于得到的每一种邻域词汇组的信息量,计算出待分类文本(c)的第三文本表示的信息熵:λ3=3.2189。
因此,该信息熵λ3=3.2189被作为待分类文本(c)的第三文本特征表示。
同样,对于上述待分类文本(d),在该步骤中,首先对于作为待分类文本(d)的第一文本表示的单位词汇集D21(共有2种单位词汇),统计出每一种单位词汇的词频如下:“还好”、“不错”分别使用步骤S101的步骤S205中对它们统计出的词频7,6。
基于统计出的每一种单位词汇的词频以及训练文本集的第一文本集表示中单位词汇的总数目32,可以得到待分类文本(d)的第一文本表示中各种单位词汇的信息量,以及基于得到的每一种单位词汇的信息量,计算出待分类文本(d)的第一文本表示的信息熵:λ1=1.5969。
因此,该信息熵λ1=1.5969被作为待分类文本(d)的第一文本特征表示。
其次,对于作为待分类文本(d)的第二文本表示的随机词汇组集D22(共有1种随机 词汇组),统计出其的词频使用步骤S101的步骤S205中对其统计出的词频2。
基于上面统计出的该种随机词汇组的词频以及训练文本集的第二文本集表示中随机词汇组的总数目87,可以得到待分类文本(d)的第二文本表示中的随机词汇组的信息量,以及基于得到的该随机词汇组的信息量,计算出待分类文本(d)的第二文本表示的信息熵:λ2=3.7728。
因此,该信息熵λ2=3.7728被作为待分类文本(d)的第二文本特征表示。
再次,对于作为待分类文本(d)的第三文本表示的邻域词汇组集D23(共有1种邻域词汇组),统计出该邻域词汇组的词频记为1。
基于统计出的该种邻域词汇组的词频以及训练文本集的第三文本集表示中邻域词汇组的总数目25,可以得到待分类文本(d)的第三文本集表示中该种邻域词汇的信息量,以及基于得到的该种邻域词汇组的信息量,计算出待分类文本(d)的第三文本表示的信息熵:λ3=3.2189。
因此,该信息熵λ3=3.2189被作为待分类文本(d)的第三文本特征表示。
步骤S109:基于待分类文本的第一文本特征表示、第二文本特征表示以及第三文本特征表示,根据第二分类器的分类规则对待分类文本进行分类。
具体地,实施例中,在该步骤中将待分类文本的第一文本特征表示与第二分类器的第一分类参数进行比较、将待分类文本的第二文本特征表示与第二分类器的第二分类参数进行比较、以及将待分类文本的第三文本特征表示与第二分类器的第三分类参数分别进行比较,并基于比较的结果,按照第二分类器的分类规则对待分类文本进行分类。
实施例中,分类规则如下:
(1)当第一文本特征表示小于第一分类参数,第二文本特征表示小于第二分类参数以及第三文本特征表示小于第三分类参数时,将待分类文本划分为普通文本;
(2)当第一文本特征表示不小于第一分类参数,第二文本特征表示小于第二分类参数以及第三文本特征表示小于第三分类参数,或者第一文本特征表示小于第一分类参数,第二文本特征表示不小于第二分类参数以及第三文本特征表示小于第三分类参数,或者第一文本特征表示小于第一分类参数,第二文本特征表示小于第二分类参数以及第三文本特征表示不小于第三分类参数时,将待分类文本划分为一般价值文本;
(3)当第一文本特征表示不小于第一分类参数,第二文本特征表示不小于第二分类参数以及第三文本特征表示小于第三分类参数,或者第一文本特征表示不小于第一分类参数,第二文本特征表示小于第二分类参数以及第三文本特征表示不小于第三分类参数,或 者第一文本特征表示小于第一分类参数,第二文本特征表示不小于第二分类参数以及第三文本特征表示不小于第三分类参数时,将待分类文本划分为较有价值文本;
(4)当第一文本特征表示不小于第一分类参数,第二文本特征表示不小于第二分类参数以及第三文本特征表示不小于第三分类参数时,将待分类文本划分为最有价值文本。
例如,若当前是对上述待分类文本(b)进行分类,那么在该步骤中,由于λ1=3.2097>μ1=2.4875,λ2=4.4659>μ2=3.7924,λ1=3.2189>μ3=3.0328,所以,待分类文本(b)被划分为最有价值文本;若当前是对上述待分类文本(c)进行分类,那么在该步骤中,由于λ1=3.1191>μ1=2.4875,λ2=4.4659>μ2=3.7924,λ3=3.2189>μ3=3.0328,所以,待分类文本(c)被划分为最有价值文本;若当前是对上述待分类文本(d)进行分类,那么在该步骤中,由于λ1=1.5969<μ1=2.4875,λ2=3.7728<μ2=3.7924,λ3=3.2189>μ3=3.0328,所以,待分类文本(d)被划分为较有价值文本。
在根据本发明的实施例中,当完成对待分类文本的分类处理之后,该完成分类处理的文本也被用作训练用文本,用于对当前的训练文本集的更新。在完成对某一文本或者某些文本的分类之后,通过将经过预处理的该文本或者该些文本添加至当前的训练文本集,可得到更新的训练文本集。基于更新的训练文本集,可对当前的文本分类器进行自适应的更新。文本分类器的更新会使文本分类器更适应于整体文本集,也更适应于更普遍的文本集,从而能够提高文本分类方法的准确性。
在对文本分类器进行更新时,既要考虑文本分类器的分类准确性和科学性,同时也要考虑整个算法执行的效率,因此不适合每完成对某一个文本的分类之后就立即更新文本分类器,因为当训练文本集很大时,更新文本分类器会带来很大的时间消耗,同时也会消耗巨大的系统内存,从而影响算法执行效率。本发明的实施例中,当基于文本分类器完成对一定数量的文本的分类时,才对文本分类器进行更新,但本发明不限于此。
图3显示根据本发明的实施例的文本分类器的更新流程。
首先,在步骤S301中,计算基于当前的文本分类器完成分类处理的待分类文本的数量占该些文本与当前的训练文本集中的经过预处理的训练用文本的总数量的比例。
具体地,若当前的训练文本集中的经过预处理的训练用文本的数量为H,基于该训练文本集所生成的第一文本分类器的过滤阈值为P0,第二文本分类器的分类参数集U={μ1,μ2,μ3},且基于当前的分类器完成对I个文本的分类。因此,该步骤中统计出已完成分类的文本的数量I在该些文本与当前的训练文本集中的经过预处理的训练用文本的总数量(I+H)的比例P1:
P1=I/(I+H)
例如,当前的训练文本集是由前面所述的实例中经过预处理的7个训练用文本构成,如之前所述的,基于该训练文本集生成的第一文本分类器具有过滤阈值P0=0.36,生成的第二文本分类器具有分类参数集U={2.4875,3.7924,3.0328}。同样,基于当前的文本分类器,完成了如之前所述的4个待分类文本(a)、(b)、(c)和(d)的分类。因此,在该步骤中可统计出该4个完成分类的文本的数量占该些文本与当前的训练文本集中的经过预处理的7个训练用文本的总数量(7+4)的比例P1:
P1=4/(7+4)=0.364
之后,在步骤S302中,判断步骤S301中计算出的比例是否大于第一文本分类器的过滤阈值,若大于过滤阈值,则执行步骤S303,开始对当前的文本分类器进行更新,若不大于过滤阈值,则当前不对文本分类器进行更新。
例如,对于上述在步骤S301中计算出的比例P1,由于P1=0.364>P0=0.36,因而执行步骤S303。
在步骤S303中,将完成分类处理的待分类文本经过预处理的结果作为经过预处理的训练用文本添加至训练文本集。
例如,在该步骤中,将如上所述的待分类文本(a)、(b)、(c)和(d)经过预处理的结果作为经过预处理的训练用文本添加至当前由7个经过预处理的训练用文本构成的训练文本集,获得由11个经过预处理的训练用文本构成的更新的训练文本集。
之后,在步骤S304中,统计替换字符串在更新的训练文本集中出现的概率,并利用该概率值更新第一文本分类器的过滤阈值。
例如,根据上述更新的训练文本集,可统计出替换字符串“##”在其中出现的概率P0’如下:
P0’=(36+12+5+4+1)/(100+20+22+15+5)=58/162=0.358
利用该概率值更新第一文本分类器的过滤阈值,得到此时第一文本分类器的过滤阈值P0:
P0=0.358
随后,在步骤S305中,对更新的训练文本集中每一个经过预处理的训练用文本进行分词处理,获得更新的训练文本集的词矢量文本集。步骤S305中的处理参考步骤S203。
随后,在步骤S306中,分别建立更新的训练文本集的第一文本集表示、第二文本集表示以及第三文本集表示。步骤S306中的处理参考步骤S204。
例如,在上述更新的训练文本集中的11个词矢量文本,共有53个单位词汇,因此在该步骤中,首先建立由该53个单位词汇构成的单位词汇集D11’作为更新的训练文本集的第一文本集表示。
之后,对11个词矢量文本中的每一个词矢量文本中的各单位词汇进行两两随机组合,共可得到139个随机词汇组。因此,在该步骤中建立由该139个随机词汇组构成的随机词汇组集D12’作为更新的训练文本集的第二文本集表示。
之后,对11个词矢量文本中的每一个词矢量文本中的各单位词汇进行两两相邻组合,共可得到42个邻域词汇组。因此,在该步骤中建立由该42个邻域词汇组构成的邻域词汇组集D13’作为更新的训练文本集的第三文本集表示。
随后,在步骤S307中,基于特征表示的方法,计算更新的训练文本集的第一文本集表示的特征表示、第二文本集表示的特征表示、以及第三文本集表示的特征表示。步骤S307的处理参考步骤S205。
例如,在该步骤中,基于信息熵的特征表示的方法,计算出上述更新的训练文本集的第一文本集表示(单位词汇集D11’)的信息熵μ1’=2.8934,计算出上述更新的训练文本集的第二文本集表示(随机词汇组集D12’)的信息熵μ2’=4.4098,以及计算出上述更新的训练文本集的第三文本集表示(邻域词汇组集D13’)的信息熵μ3’=3.5602。
随后,在步骤S308中,分别利用更新的训练文本集的第一文本集表示的特征表示、第二文本集表示的特征表示、以及第三文本集表示的特征表示更新第二文本分类器的第一分类参数,第二分类参数以及第三分类参数。
例如,在该步骤中,利用上述计算到的μ1’、μ2’和μ3’的值分别对第二文本分类器的第一分类参数μ1=2.4875、第二分类参数μ2=3.7924、以及第三分类参数μ3=3.0328进行更新,得到此时第二文本分类器分类参数集U={μ1,μ2,μ3}={2.8934,4.4098,3.5602}。
由上述实施例可以看出,实施例所提供的文本分类方法除了考虑文本中所包含的各单位词汇,还结合考虑到各单位词汇的随机组合和相邻组合,因而考虑了词汇与词汇之间的相互影响和相互关联,提高文本分类的准确性和有效性。此外,通过采用多种文本表示(单位词汇集、随机词汇组集、邻域词汇组集),能够按照文本的价值(有效信息量)的大小,对文本进行分级分类,使得具有相似的价值(有效信息量)的文本被划分到同一级别的类中,以利于用户针对不同级别的价值量的文本进行后续深加工和挖掘利用。
与上述文本分类方法相对应,本发明的是实施例还提供了一种文本分类装置。图4显 示根据本发明的实施例的文本分类装置的结构示意图。如图4所示,本发明的实施例所提供的文本分类装置包括:
分类器训练模块401,分类器训练模块401用于建立训练文本集,并基于训练文本集生成第一文本分类器和第二文本分类器,其中,第一文本分类器具有过滤阈值,第二文本分类器具有分类参数集,分类参数集包括第一分类参数、第二分类参数和第三分类参数;
文本预处理模块402,文本预处理模块402采用预设的替换字符串替换待分类文本中的文本噪声来对待分类文本进行预处理,文本噪声包括标点、停用词、链接;
第一文本分类模块403,第一文本分类模块403统计替换字符串在经过预处理的待分类文本中出现的概率,当概率大于等于过滤阈值时,将待分类文本划分为普通文本;
文本分词模块404,当上述概率小于过滤阈值时,文本分词模块404对经过预处理的待分类文本进行分词处理,获得待分类文本的词矢量文本;
文本表示模块405,文本表示模块405建立待分类文本的第一文本表示、第二文本表示以及第三文本表示,其中,第一文本表示是由待分类文本的词矢量文本中的所有单位词汇构成的单位词汇集,第二文本表示是由待分类文本的词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集,以及第三文本表示是由待分类文本的词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集;
文本特征表示模块406,文本特征表示模块406基于特征表示的方法,计算待分类文本的第一文本表示的特征表示作为第一文本特征表示,计算待分类文本的第二文本表示的特征表示作为第二文本特征表示,以及计算待分类文本的第三文本表示的特征表示作为第三文本特征表示;以及
第二文本分类模块407,第二分类模块407基于待分类文本的第一文本特征表示、第二文本特征表示以及第三文本特征表示,根据第二分类器的分类规则对待分类文本进行分类。
图5显示根据本发明的实施例的文本分类装置中分类器训练模块401的结构示意图。如图5所示,分类器训练模块401包括:
训练文本集建立模块4011,训练文本集建立模块4011建立由经过预处理的训练用文本构成的训练文本集,其中,经过预处理的训练用文本是采用预设的替换字符串替换训练用文本中的文本噪声所获得的结果,文本噪声包括标点、停用词、链接;
概率统计模块4012,概率统计模块4012统计替换字符串在训练文本集中出现的概率,作为第一文本分类器的过滤阈值;
文本集分词模块4013,文本集分词模块4013对训练文本集中每一个经过预处理的训练用文本进行分词处理,获得训练文本集的词矢量文本集;
文本集表示模块4014,文本集表示模块4014分别建立训练文本集的第一文本集表示、第二文本集表示以及第三文本集表示,其中,第一文本集表示是由词矢量文本集中的所有单位词汇构成的单位词汇集,第二文本集表示是由词矢量文本集中属于同一词矢量文本中的各单位词汇随机组合得到的所有随机词汇组构成的随机词汇组集,以及第三文本集表示是由词矢量文本集中属于同一词矢量文本中的各单位词汇相邻组合得到的所有邻域词汇组构成的邻域词汇组集;以及
文本集特征表示模块4015,文本集特征表示模块4015基于特征表示的方法,计算训练文本集的第一文本集表示的特征表示作为第一分类参数、计算训练文本集的第二文本集表示的特征表示作为第二分类参数以及计算训练文本集的第三文本集表示的特征表示作为第三分类参数。
根据本发明的实施例的文本分类装置,当基于第一文本分类器和第二文本分类器完成对一定数量的待分类文本的分类处理之后,分类器训练模块401将该一定数量的待分类文本经过预处理后的结果添加至训练文本集用于训练文本集的更新。
由上述实施例可以看出,实施例所提供的文本分类装置除了考虑文本中所包含的各单位词汇,还结合考虑到各单位词汇的随机组合和相邻组合,因而考虑了词汇与词汇之间的相互影响和相互关联,提高文本分类的准确性和有效性。此外,通过采用多种文本表示(单位词汇集、随机词汇组集、邻域词汇组集),能够按照文本的价值(有效信息量)的大小,对文本进行分级分类,使得具有相似的价值(有效信息量)的文本被划分到同一级别的类中,以利于用户针对不同级别的价值量的文本进行后续深加工和挖掘利用。
虽然经过对本发明结合具体实施例进行描述,对于本领域的技术技术人员而言,根据上文的叙述后作出的许多替代、修改与变化将是显而易见。因此,当这样的替代、修改和变化落入附后的权利要求的精神和范围之内时,应该被包括在本发明中。
- 还没有人留言评论。精彩留言会获得点赞!