用于感兴趣目标的目标定位和姿态估计的方法与流程
本发明涉及视觉系统,和用于定位感兴趣目标和其姿态的方法。
背景技术:
已知的机器人感知系统通过工程设计具体的光照状态、构造观察状态和利用处理结构来实现期望的性能和可靠性。它们在仅工作在真实世界条件下的子组中的窄范围的条件下具有灵活性,且会因周围环境的微小改变而故障。此外,已知系统和相关技术的处理速度不足以实现高效的实时处理。一站式商业视觉系统(turnkey commercial vision system)在引入更宽灵活性时会变慢且通过严格地构造视域而能鲁棒地工作。例如,处理大的视野(FOV)以在非期望方位(占据FOV的5-10%)搜索目标会花费数秒或更多。这在搜索前/后/侧视野以精确地找到目标位置和姿态时会进一步复合。进而,与用于已知的用于机器人材料传递和操作应用的自动化方案的构造环境有关的成本是机器人装置相关成本的三倍到十倍。在已知自动化系统中可有效地操作的产品范围会受到限制且通常被限制为仅一些样式。进而,这种系统很重组起来笨重且针对不同种类的产品进行重构也很慢。由此,由于与投资、操作成本、灵活性和可重构性有关的问题,现有的自动化方案不易于处理具有丰富多样性的部件的组装操作。
技术实现要素:
描述一种用于定位和估计视觉系统视野中已知目标的姿态的方法,且方法包括开发已知目标的基于处理器的模型;捕获位图影像文件,其具有包括已知目标的视野的影像;和从位图影像文件提取特征。被提取特征与和已知目标的模型相关的特征相匹配。可以基于被提取特征在位图影像文件中定位一目标。被定位目标的被提取特征被聚类和合并。可以基于经合并的被聚类的被提取特征与已知目标的基于处理器的模型所作的比较而检测视野中的已知目标。基于已知目标的检测估计视野中被检测已知目标的姿态。
本发明提供一种用于定位和估计视觉系统的视野中已知目标的姿态的方法,已知目标包括具有预定特征的结构实体,所述预定特征包括空间尺寸,该方法包括:开发已知目标的基于处理器的模型;捕获位图影像文件,其具有包括已知目标的视野的影像;从位图影像文件提取特征;将被提取特征与和已知目标的模型相关的特征相匹配;基于被提取特征在位图影像文件中定位一目标;将所定位的目标的被提取特征聚类;将聚类的被提取特征合并;基于经合并的被聚类的被提取特征与已知目标的基于处理器的模型所作的比较而检测视野中的已知目标;和基于已知目标的检测估计视野中被检测已知目标的姿态。
在所述的方法中,从位图影像文件提取特征包括,采用尺度不变特征转换(SIFT)算法而从位图影像文件中的尺度不变关键点检测独特影像特征。
在所述的方法中,从位图影像文件提取特征包括,基于所述被提取特征和已知目标的基于处理器的模型中的被提取特征之间的对应,从位图影像文件中的尺度不变关键点提取独特影像特征。
在所述的方法中,基于被提取特征在位图影像文件中定位一目标包括,识别与已知目标的特征相关的在位图影像文件中的特征。
在所述的方法中,识别与已知目标的特征相关的在位图影像文件中的特征进一步包括,将数字窗口匹配在位图影像文件中的感兴趣区域周围,且仅在数字窗口中的位图影像文件的一部分中识别特征。
在所述的方法中,将数字窗口匹配在位图影像文件中感兴趣区域的周围包括,识别位图影像文件中的内围,其所包括的数据的分布可通过与已知目标相关的某组模型参数解释。
在所述的方法中,基于已知目标的检测估计视野中被检测的已知目标的姿态包括,执行粗糙-精细影像匹配步骤,以检测已知目标的姿态。
在所述的方法中,开发已知目标的基于处理器的模型包括:采用数字摄像头捕获相对于数字摄像头处于多个姿态下的已知目标的数字影像;在捕获的数字影像上执行特征追踪;基于特征追踪来构建与姿态相关的三维(3D)点云;从3D点云构造3D网格;和将外观描述符与3D网格关联。
在所述的方法中,采用数字摄像头捕获相对于数字摄像头处于多个姿态下的已知目标的数字影像包括,捕获多个姿态下已知目标的视频影像;和其中在捕获的数字影像上执行特征追踪包括,在捕获的数字影像上执行帧间特 征追踪。
本发明提供一种用于检测视觉系统的视野中已知目标的方法,已知目标包括具有预定特征的结构实体,所述预定特征包括空间尺寸,该方法包括:开发已知目标的基于处理器的模型;捕获位图影像文件,其具有包括已知目标的视野的影像;从位图影像文件提取特征;将被提取特征与和已知目标的模型相关的特征相匹配;基于被提取特征在位图影像文件中定位一目标;将所定位的目标的被提取特征聚类;将聚类的被提取特征合并;和基于经合并的被聚类的被提取特征与已知目标的基于处理器的模型所作的比较而检测视野中的已知目标。
在所述的方法中,从位图影像文件提取特征包括,采用尺度不变特征转换(SIFT)算法而从位图影像文件中的尺度不变关键点检测独特影像特征。
在所述的方法中,从位图影像文件提取特征包括,基于所述被提取特征和已知目标的基于处理器的模型中的被提取特征之间的对应,从位图影像文件中的尺度不变关键点提取独特影像特征。
在所述的方法中,基于被提取特征在位图影像文件中定位一目标包括,识别与已知目标的特征相关的在位图影像文件中的特征。
在所述的方法中,识别与已知目标的特征相关的在位图影像文件中的特征进一步包括,将数字窗口匹配在位图影像文件中的感兴趣区域周围,且仅在数字窗口中的位图影像文件的一部分中识别特征。
在所述的方法中,将数字窗口匹配在位图影像文件中感兴趣区域的周围包括,识别位图影像文件中的内围,其所包括的数据的分布可通过与已知目标相关的某组模型参数解释。
在所述的方法中,开发已知目标的基于处理器的模型包括:采用数字摄像头捕获相对于数字摄像头处于多个姿态下的已知目标的数字影像;在捕获的数字影像上执行特征追踪;基于特征追踪来构建与姿态相关的三维(3D)点云;从3D点云构造3D网格;和将外观描述符与3D网格关联。
在所述的方法中,采用数字摄像头捕获相对于数字摄像头处于多个姿态下的已知目标的数字影像包括捕获多个姿态下已知目标的视频影像;和其中在捕获的数字影像上执行特征追踪包括在捕获的数字影像上执行帧间特征追踪。
本发明提供一种用于确定感兴趣目标的姿态的方法,包括:通过数字摄 像头产生视野的三维(3D)数字影像;在数字影像中执行目标识别,这包括检测至少一个被识别目标;提取与被识别目标对应的目标区块;从目标区块提取多个兴趣点;提取与目标区块相关联的3D点云和2D区块;将来自区块的兴趣点与来自多个训练影像每一个的兴趣点比较;选择多个训练影像中的一个,所述多个训练影像包括训练影像中的具有与来自目标区块的兴趣点类似的最大量兴趣点的那个影像;将与目标区块相关的3D点云和2D区块保存;和采用迭代最近点(ICP)算法计算与目标区块相关的3D点云和训练影像中所选择的一个之间的旋转和线性平移。
所述的方法进一步包括执行训练以产生多个训练影像,包括:在多个不同观察点使用数字摄像头捕获已知目标的多个训练影像;将训练影像每一个转换为位图影像文件;从位图影像文件每一个提取主区块;捕获用于主区块的特征和兴趣点;提取与主区块相关的3D点;和采用修改来识别和限定丢失深度点;其中训练影像包括用于主区块的被捕获特征和兴趣点和与主区块相关的被提取3D点。
在下文结合附图进行的对实施本发明的较佳模式做出的详尽描述中能容易地理解上述的本发明的特征和优点以及其他的特征和优点。
附图说明
参考附图通过例子描述一个或多个实施例,其中:
图1示意性地示出了根据本发明的视觉系统,其用于捕获、处理和存储视野(FOV)的三维(3D)影像,包括摄像头、已知物体和影像分类器;
图2示意性地显示了根据本发明的用于定位和估计示例性视觉系统的视野中已知目标姿态的过程;
图3显示了根据本发明的模型构建过程,其使用视频和帧间特征追踪快速构建代表已知目标的基于处理器的模型;
图4示意性地显示了根据本发明的用于定位和估计示例性视觉系统的视野中已知目标姿态的过程的第二实施例;
图5-1图形显示了根据本发明的FOV的3D影像,其包括已知目标,所述已知目标包括开关、扬声器和传感器;
图5-2图形显示了根据本发明的从图5-1所示的3D影像提取的区块,
图5-3图形显示了根据本发明的参考5-1所示的FOV的3D影像,其包 括具有相应提取特征的已知目标;
图6图形显示了根据本发明的在x、y和z轴线情况下已知目标的3D点云的3D影像实例;和
图7图形显示了根据本发明的在x和y轴线情况下已知目标的2D点云的2D影像实例。
具体实施方式
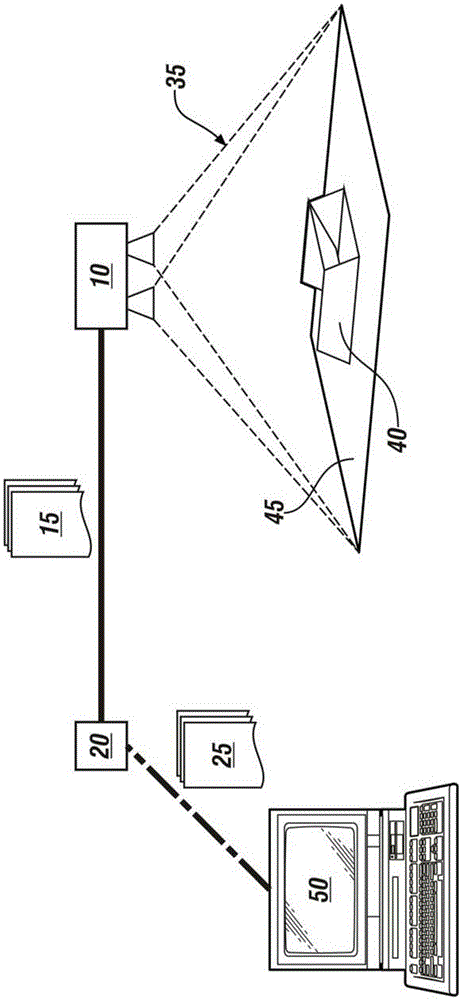
现在参见附图,其中描述仅是用于图示某些示例性实施例的目的而不是为了对其进行限制,图1示意性地示出了用于捕捉、处理和存储视野(FOV)的影像的示例性视觉系统,包括通过信号连接到编码器20的影像检测器(摄像头)10,所述编码器20通过信号连接到控制器50。摄像头10优选是立体装置,其能捕获三维(3D)影像。摄像头10可相对于FOV35中的已知目标40定位在任何位置和取向,已知目标40在平面45上取向。本文采用的术语“已知目标”代表具有预定物理特征的结构实体,例如包括空间尺寸、材料和表明反射率的表面光洁度等。
在一个实施例中,通过摄像头10捕获的3D影像15是24位立体影像形式的位图影像文件,其包括RGB(红色-绿色-蓝色)值和代表FOV35的深度值。3D影像15的其他实施例可包括显示3D FOV的黑白或灰度表现形式的3D影像,和没有限制的其他影像表现形式。摄像头10包括影像获取传感器,所述传感器信号连接到编码器20,该编码器在3D影像15上执行数字信号处理(DSP)。影像获取传感器以预定分辨率在FOV 35中捕获像素,且编码器20产生FOV 35的位图影像文件25,例如8位像素位图,其代表预定分辨率下的FOV 35。编码器20产生位图影像文件25,该文件被通信到控制器30。位图影像文件25在一个实施例中是存储在非瞬时数字数据存储介质中的编码数据文件。位图影像文件25包括3D影像的数字表现形式,其可以包括已知目标40中的一个或多个,且代表以摄像头10的原始分辨率捕获的FOV的原始影像。多个已知目标40可以全部具有相同设计,或可以具有不相似的设计。通过摄像头10捕获的已知目标40的3D影像15含有足够的信息以评估与摄像头10有关的已知目标40的位置。在与照明和反射率相关的影响已经被考虑且摄像头10已经被校准之后,已知目标40的形状取决于摄像头10和已知目标40之间的相对观察角度和距离。
控制器、控制模块、模块、控制装置、控制单元、处理器和相似的术语是指专用集成电路(一个或多个)(ASIC)、电子电路(一个或多个)、执行一个或多个软件或固件程序或例程的中央处理单元(一个或多个)(优选是微处理器(一个或多个))和相关联的内存和存储器(只读的、可编程只读的、随机存取的、硬驱动的等)、组合逻辑电路(一个或多个)、输入/输出电路(一个或多个)和器件、适当的信号调节和缓冲电路以及其他部件中的一个或多个的任何一种或多种组合,以提供所述的功能,包括数据存储和数据分析。软件、固件、程序、指令、例程、代码、算法和相似的术语是指任何控制器可执行的指令集,包括校准和查找表。术语‘模型’是指基于处理器的或处理器可执行的代码,其模拟了物理存在或物理过程。
图2示意性地显示了用于对示例性视觉系统的视野中的已知目标205进行定位和估计姿态的姿态估计过程200的第一实施例。其可以包括采用摄像头10以捕获FOV 35中已知目标40的位图影像文件25,如参考图1所述的。显示了通过摄像头捕获的位图影像文件的一个示例性视觉描述,且其包括RGB值影像225,所述影像包括已知目标205。与姿态估计过程200的步骤相关的具体要素包括特征提取210、特征匹配220、快速目标定位230、关键点聚类(keypoint clustering)240、粗略目标检测250、聚类合并260、精细目标检测270和姿态过滤280,以估计已知目标205的姿态。
用于已知目标205的特征提取步骤210是采用尺度不变特征转换(scale-invariant feature transform,SIFT)在包括已知目标205的RGB值影像225中检测和描述局部特征的过程。SIFT算法从捕获在RGB值影像225的位图影像文件中的关键点来识别特别的尺度不变影像特征,显示为SIFT特征227。优选地,识别大量关键点,每一个关键点特点是对于不同零件和对于相同零件来说能容易地重复,例如已知目标205,提供可被容易地提取和匹配的已知目标205的代表性取向和尺度。SIFT过程和算法是已知的且由此不在本文详细描述。
特征匹配步骤220从包括工作环境在内的FOV的样本影像中提取SIFT特征,使用简单的近似最近邻技术可随时间对该工作环境进行追踪。这形成了被提取特征和已知目标205的模型中的一个或多个被提取特征之间的对应。图3显示了用于开发代表已知目标的基于处理器的模型的一个过程。在这种情况下可采用神经网络或其他合适程序。
快速目标定位步骤230使用提取的SIFT特征227,以找出FOV中的一个或多个已知目标205。这改善处理速度,因为随后的步骤仅需要在FOV的可能区域中执行而不是在整个FOV中执行。快速目标定位步骤230是基于外观的过程,其中SIFT特征227在测试影像上被检测且与之前训练的外观模型对照,所述之前训练的外观模型将属于已知目标205的特征与属于背景的噪声的特征区分开。数字窗口237被匹配在感兴趣区域周围,所述感兴趣区域比整个影像的尺寸小许多,其中感兴趣区域被识别作为包括SIFT特征227的RGB值影像225的一部分。使用数字窗口237将数据分析限制为仅是与包含在窗口237中的、RGB值影像225的位图影像文件的内围相关的数据部分,且将未包含在窗口237中的RGB值影像225的位图影像文件的影像数据文件部分从分析中排除。这种处理通过限制对特征匹配的搜索空间和随机样本一致性(RANSAC)算法的执行而增强了已知目标205的最终姿态估计质量且减少运行时间。RANSAC是非决定性的算法,其在合理的可能性(其随迭代的执行而增加)内产生结果。运行假定是,数据包括内围和外围,即内围即是其分布可通过与已知目标205相关的某组模型参数解释的数据,尽管会经历噪声影响,外围是与模型不匹配的数据。外围是噪声极值的结果,或来自不正确的测量或来自与数据解译有关的不正确臆测。RANSAC还假设,给定的小组别的内围,存在可估计模型参数的过程,所述模型最佳地解释或匹配与窗口237相关的数据。RANSAC算法是已知的且由此不在本文描述。数字窗口237数字界定了构成包含在数字窗口237中的内围的数据。
关键点聚类步骤240从进入聚类247的局部区域捕获SIFT特征227,其匹配存储在存储器中的已知目标205的模型。这包括一一对应的释放,允许聚类过程结合和识别已知目标205,所述已知目标具有很少的清楚外观特征。这是通过扩大可能匹配的列表实现的,以包括相似性阈值以下的所有匹配。
粗略目标检测步骤250包括粗略-精细影像匹配步骤,以检测已知目标205的姿态。这包括采用RANSAC算法和线性建模(LM),以检测已知目标205的粗略姿态。RANSAC算法采用迭代方法,以从一组观察数据估计数学模型的参数,例如从关键点聚类步骤240输出的聚类247,其包含外围。
聚类合并步骤260包括将跨过已知目标中的一个的多个聚类合并,因为 与单个已知目标205相关的数据可以包含在多个聚类247中。精细目标检测步骤270包括检测精细目标,假定每一个聚类247含有来自单个已知目标205的特征。其也可采用RANSAC算法。姿态过滤步骤280移除虚假检测且精细调节已知目标205的估计姿态,这可用于机器人手臂或其他用于进行抓持、处理等动作的装置。已知目标205和已知目标205的估计姿态287用图形示出。
图3显示了模型构建过程300,其使用视频和帧间特征追踪来快速构建代表已知目标的基于处理器的模型。以这种方式,目标可变成已知目标。数字摄像头10在与数字摄像头(310)相关的多个姿态处捕获目标的数字视频形式的数字影像,这种视频显示为图片325,所述摄像头可包括捕获数字影像的多线程视频装置。在捕获的数字影像上执行特征追踪,包括采用Lucas-Kanade(LK)方法,以使用空间强度信息,以指引影像搜索用于产生与影像(320)的最佳匹配的目标的姿态。LK方法是用于光流估计的已知微分方法,其估计对于所研究的点p来说两个视频帧之间的影像中像素的位移很小且基本恒定。基本的光流方程使用最小二乘标准对在附近的所有像素进行求解。通过将来自几个邻近像素的信息进行组合,LK方法求解光流等式中的模糊度(ambiguity)且对影像噪声相对不敏感。LK方法不提供影像均匀区域内部的流信息。
帧间特征追踪被已知的光束法平差程序使用,以针对数字摄像头(310)构建与目标具体姿态相关的3D点云,示例性3D点云显示为图片335。LK方法不采用典型特征描述符。代替地,几何模型的外观描述符是与用于姿态估计的多目标姿态估计和检测(MOPED)兼容的输入。MOPED是可扩展的且是低延时目标辨识和姿态估计系统。另外,找出表面法线以支持姿态优化。为了实现这两点,且最大程度地是模型构建自动化,在接收光束法平差过程结果之后执行操作。过程并入不具有相关的外观描述符的3D点。在对不明显的目标使用特征追踪时,许多点不具有除了追踪点颜色以外的清楚SIFT描述符或任何描述符。通过增加一些项而将这种信息并入到LM姿态优化中,所述项通过模型点颜色和模型-点颜色的重投影之间的差对目的功能进行罚操作(penalize)。以此方式,甚至没有基于影像的匹配的那些点也可告知(inform)姿态估计。者包括并入与模型表面法线有关的信息,因为没有明确的匹配所以这是必要的,必须确定模型点是否可见或其被目标挡住(即面 向其他方向)。这是通过确定用于感兴趣点的表面法线是否面对摄像头或背离摄像头实现的。面对摄像头的感兴趣点是有效的,且背离摄像头的感兴趣点是无效的,为手头的任务提供充分的近似。在任何给定步骤,仅未被挡住的点会在姿态优化过程中被考虑,因为没有数据可用于测量假定被挡住点的颜色差异。模型构建过程采用视频追踪加视觉特征,以更快地构建更密集的模型。这些模型最终可实时构建。可添加在姿态优化过程中与平滑姿态细化匹配的简单描述符,且可并入直接距离数据(direct range data)。由此,2D再投影和3D背投影可在姿态的单个优化过程中组合。封闭边界可被找出且被用于过滤跨界描述符,由此使得描述符损坏最小化。这种操作允许系统识别对用于已知目标的姿态估计来说最有用的具体特征和零件。
自动话的过程找出以几何平面,在该几何平面上放置已知目标以用于影像捕获,以执行模型细化(340),显示为图片345。仅在该平面上方的点被认为是模型的一部分。在一个实施例中,随后的手动点去除图形用户界面(GUI)能让用户除去剩余的离群3D点。通过用户与GUI互动以除去剩余离群3D点不是必须或必要的。得知平面的法线还允许模型的自动轴线对准。用通过模型细化产生的点云模型构造3D网格(350),在一个实施例中其是凸壳(convex hull)。该3D网格成为一表面,新的3D特征可从训练影像投射到该表面。
外观描述符与几何模型相关(360)。这包括计算用于每一个所选择训练影像的SIFT特征。对于每一个所选择视野中的这些SIFT特征每一个,仅选择背投影与3D模型相交的那些SIFT特征。在一个实施例中,这包括找出每个视野中2D模型投影的凸壳和仅引入位于内部的SIFT特征,以增强处理速度。引入的SIFT特征具有经计算的背投影,且新的3D点被添加到模型中,其中SIFT中心与用于已知目标的网格3D模型相交。新的模型被输出,优选是XML格式且含有3D特征,具有从不具有SIFT描述符的原始3D模型获得的SIFT关联。
图4示意性地显示了过程400的第二实施例,其用于在示例性视觉系统的视野中定位和估计已知目标的姿态,例如含有通过摄像头10捕获的3D影像15的位图影像文件,所述摄像头是24位立体影像的形式,其包括RGB(红色-绿色-蓝色)值和代表FOV的深度值。
过程400包括训练部分(步骤410-418)和测试部分(步骤420,等)。 训练部分包括采用摄像头从‘n’个不同观察点捕获‘n’个量的已知目标训练影像(410),训练影像被转换为为位图影像文件。位图影像文件被分析且由此提取主区块(412)。区块是数字影像的一区域,在该区域中一些性能是恒定的或在预定的值范围内变化。区块中的所有点被认为是彼此类似的。区块可以是分开的且被分别识别以用于评估。通过作为解释过程400的操作的一部分的例子的方式,图5-1图形显示了包括已知目标的FOV的3D影像525,已知目标包括开关505、扬声器507和传感器509,图5-2图形显示了从包括图5-1所示的已知目标505、507和509的FOV的3D影像525提取的主区块515。图5-3图形显示了包括用于已知目标的外部特征的FOV的3D影像525,所述已知目标包括具有相应被提取特征506的开关505、具有相应被提取特征508的扬声器507和具有相应被提取特征510的传感器509。
再次参见图4,感兴趣点形式的特征从主区块捕获(414),所述主区块是从位图影像文件提取的。可采用局部特征检测符(local feature detector)算法,例如SIFT或SURF(Speeded Up Robust Features:加速鲁棒特征)。一个已知的SURF算法使用整数近似,以捕获兴趣点。与主区块相关的多个3D点被提取且采用修改(interpolation)来识别和限定丢失的深度点(416)。与主区块相关的3D点和兴趣点被保存在非易失存储装置中,作为用于特定角度(specific perspective)的已知目标的第n个的训练影像(418)。针对‘n’个训练影像每一个执行训练过程。
通过捕获影像并识别目标(例如已知目标)的存在而运行测试过程(420)。一个或多个目标区块(即对应于已知目标的区块)被从影像的主区块提取(422)且在去除任何外围之后用于目标区块的兴趣点检测符被提取(424)。与每一个目标区块相关的3D点云被提取和识别作为‘P1’,且与已知目标相关的2D区块被提取和识别作为‘B2’(426)。兴趣点检测符与用于在训练部分期间确定的已知目标的所有训练影像相比较(428),且训练影像和具有与目标区块相关的3D点云对应的最大量兴趣点的相应观察点中的一个被识别和捕获(430)。与目标区块相关的3D点云被识别作为目标区块‘P2’且被保存在非易失存储装置中,且相应2D区块被识别作为‘B2’且也被保存(430)。执行迭代最近点(ICP)算法,以确定目标区块相对于P1到P2的旋转和平移(432)。在与3D点云P1和P2相关的数据被认为存在太多噪声时,确定相对于B1到B2的旋转和平移(434)。在相同旋转平面 中发生训练和测试之间的所有旋转和平移(即目标在相同表面上且摄像头未改变其位置或运动)时,该分析过程是足够的。
图6图形显示了影像610和620的3D示例,显示了分别在x、和z轴线602、604和606的情况下的已知目标的3D点云。影像610是显示了在当前测试姿态下的已知目标的3D点云,且影像620是显示了在多个训练姿态中的一个下的已知目标的3D点云,影像620代表与影像610最近似的训练姿态。影像610被显示为相对于影像620旋转和平移(615)。
图7图形显示了影像710和720的2D示例,其显示了分别在x和y轴线702和704情况下的已知目标的2D点云。影像710是显示了在当前测试姿态下的已知目标的2D点云,且影像720是显示了在多个训练姿态中的一个下的已知目标的2D点云,影像720代表与影像710最近似的训练姿态。影像710被显示为相对于影像720旋转和平移(715)。
如在本文所述的,可通过理解人视觉系统如何在有妨碍性的因素(例如照明、视野角度、距离和阻挡)的情况下仍保持不变性而开发过程和相关算法,以用于鲁棒的低水平视觉感知。
如在本文所述的基于视觉的方法自动地定位FOV中的感兴趣目标且估计其姿态。通过在目标的环境中提取与目标有关的属性并通过对各种的目标和状态、范围、照明、观察点、阻挡、背景和空间认知进行灵活匹配,这种能力使得装置(例如机器人手臂)能定位目标以用于抓持和/或操作。本文所述的方法将外观和几何结构二者进行协调,以定位和识别目标的姿态,且可将来自深度传感器的距离信息用于姿态优化算法,以提高准确性。通过并入多感知凝视机制(attention mechanisms)和通过开发用于快速解析各种目标的分类器分类标准,使用多感知技术能加速分类和搜索。
这有助于通过提供高水平的灵活性和可重构性而设置自动化系统。所提出的原理允许灵活性和可变换性,其在组装操作(例如箱体拾取或材料操作)中使用具有一定程度的第一代拟人机器人自动化技术的最少基础设施。其还实现鲁棒和自主的组装能力,在较少结构化的环境中找出零件、视觉确认任务,且能准备好处理复杂和柔性的零件。本文所述的系统使得机器人手臂能在组装线上补充人的角色且降低工人在例行的、非关键、重复的组装过程功能上花费的时间(所述功能属于灵巧拟人机器人的短期能力)。本文所述的系统使得机器人手臂能操作搁置形状和形式的半刚性、刚性、棱柱零件,快 速检测许多目标,且具有以半自动的方式学习新目标的模型的能力。这种能力对实现可使用相同工艺基础设施而与工人协同工作的机器人来说是必要且关键的。
附图中的详细的描述和显示是对本发明的支持和描述,而本发明的范围仅通过权利要求限定。尽管已经对执行本发明的较佳模式进行了详尽的描述但是本领域技术人员可得知在所附的权利要求的范围内的用来实施本发明的许多替换设计和实施例。
- 还没有人留言评论。精彩留言会获得点赞!