存储器中心数据库架构的制作方法
本发明一般地涉及数据存储系统和方法,更具体地涉及永久非易失性闪存数据库存储系统和方法。
背景技术:
永久半导体存储器,诸如闪速存储器(闪存,flash memory),的读/写性能正发展到一个点,它可能会很快替代一些应用中的内部存储器。预期随着时间的推移非易失性闪速存储器将变得跟DRAM一样快。这会为闪速存储器打开很多用于存储系统诸如数据库的独特和不同的应用。然而,闪速存储器可以被高效地用作数据库之前,需要解决很多不同的问题,这需要用于编程语言编译器诸如Java的不同的模型,以及极其不同的存储系统架构解决方案。
传统Java运行环境(JRE,Java runtime environment)目前没有能力永久地存储数据对象。所有的对象由构造函数在运行时创建并且存储在易失性存储器中(例如RAM)。这对闪速存储器是不利的,因为需要利用完全不同的方式创建、删除以及管理非易失性存储器中的永久对象。创建易失性存储器中的临时对象的优点在于,当应用关闭或被垃圾回收进程清除时,非引用对象可以被自动清除,这也会在运行时自动释放内存。这跟具有闪速存储器的情形不同,该情形中对于删除永久对象和释放内存来说确认动作是必须的。
另外,由于数据库中对象的数量可以很大,因此存在如何基于查询定义有效地发现并且检索闪存阵列中的对象的问题。当使用闪速存储器时需要解决的其它问题是如何确定对象的位置,从而可以对其引用,以及如何删除存储的对象和释放内存。寻找永久存储器中的对象需要不同于易失性存储器中使用的索引方法。确实,由于非易失性存储器正在取代内部存储器,因此有必要重新思考传统架构和技术。
传统数据库利用专用服务器产品将对象序列化成表结构,并且提供其它有益的能力以便于和加速查找,这些能力诸如事务模型、数据的一致视图、查询语言诸如SQL、更新单个数据域的能力,以及索引结构。这些能力涉及大量消耗会减慢软件方案。伴随的序列化/反序列化过程通常检查各个集线器(hub)和缓存,这会在中央处理器(CPU)和内存上导致很大的开销、低效率和增加存储成本。这对于闪存存储是不合适的,闪存存储中对象总是保存在存储器中。需要用于管理对象的不同的事务模型以及检索和删除对象的不同解决方案。
技术实现要素:
需要提供基于永久闪速存储器的新的以存储器为中心的数据库架构,其通过利用用于数据库架构的闪速存储器解决了前述和其它问题,并且这也是本发明期望的。
附图说明
图1是绘示了系统架构的方块图,该系统根据本发明的实施例提供全闪存编译器和运行时环境。
图2绘示了数据库存储的传统方案。
图3对比了根据本发明的全闪存数据库方案和图2中的传统数据库方案。
图4绘示了用于索引永久对象的根据本发明的全闪存编译器的操作。
图5绘示了根据本发明的全闪存数据库的索引结构的实施例。
图6绘示了根据本发明的用于管理全闪存数据库中的对象的处理的实施例。
图7A-C绘示了根据本发明的用于删除对象和压缩存储器的处理的实施例。
图8A-C绘示了根据本发明的用于删除全闪存数据库中永久对象的不同的方案。
具体实施方式
本发明利用永久非易失性闪速存储器提供新的和独特的以存储器为中心的数据库架构,其将传统数据库有益的特性、灵活性和多功能性与闪速存储器提供的速度、安全和方便结合在一起,同时获取了相对于传统存储器改进的性能。根据本发明,提供了用于闪速存储技术的新类型的编译器和优化的运行时(runtime)。本发明尤其非常适于与Java编程语言一起使用,以及用于数据库应用,本文将对此进行描述。因此,在描述本发明的实施例时,说明书将使用与描述“全闪存Java编译器”(all flash Java compiler,AFJC)、“全闪存Java运行环境”(all flash Java runtime environment,AFJRE)以及“全闪存数据库”(all flash database,AFDB)有关的术语诸如“全闪存”(all flash)。然而,应当理解基于Java的存储系统和方法只是绘示本发明的一个实例,本发明对于其他编程语言、环境和应用也有适应性。
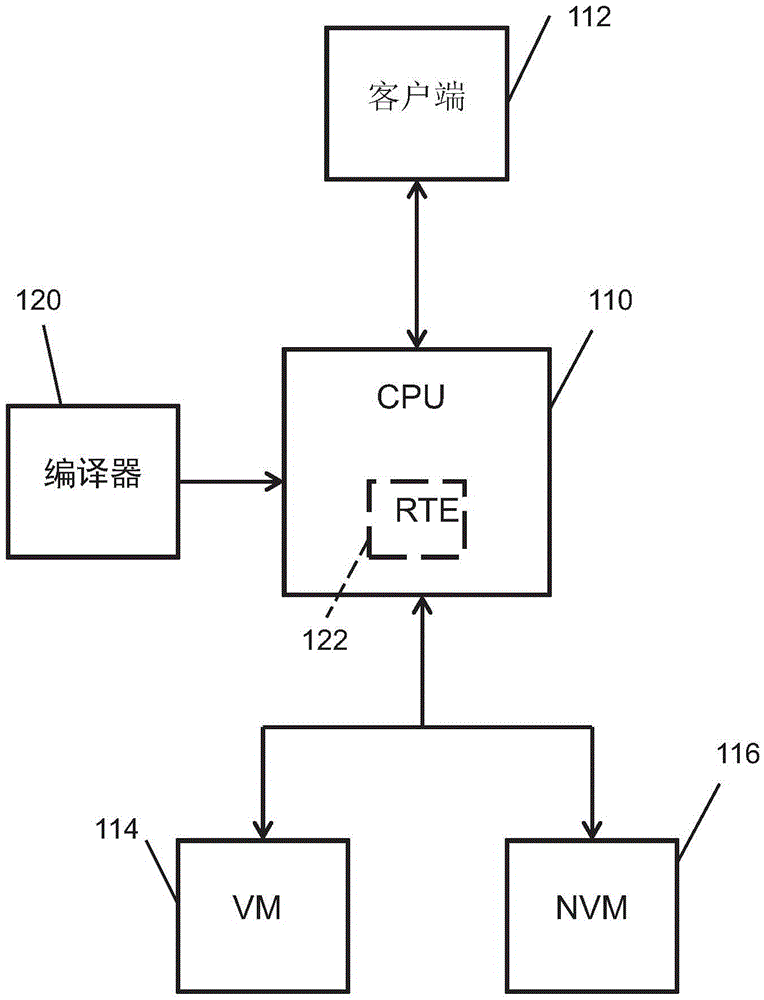
图1绘示了根据本发明的实施例的系统的架构,该系统提供用于根据本发明的实施例的全闪存存储阵列的编译器和运行时环境。如图中所示,该系统包括连接至客户端112的计算机系统(CPU)110、易失性存储器114和非易失性存储器116。该易失性存储器和非易失性存储器可以包括用于存储控制程序的计算机可读介质,该控制程序包括用于控制该计算机系统110的操作的可执行指令。该非易失性存储器可以包括形成数据库的全闪存存储阵列。编译器120可以是编译Java指令的Java编译器,该Java指令是用于闪存永久存储阵列而根据本发明定制的。该指令由计算机系统110执行以创建Java运行时环境122。Java编译器将称为全闪存Java编译器(AFJC),并且Java运行时环境将称为全闪存Java运行时环境(AFJRE)。
如将要详细描述的,本发明提供数据库架构和永久数据模型,它们与传统数据库架构和模型是非常不同的。传统数据库被按照表进行组织。存储和访问这样的传统数据库中的数据需要多个步骤,以在存储器单元(memory locations)和各个页面与存储器缓存之间移动数据对象。反之,根据本发明,提供新的永久数据模型,其中将数据对象直接存储于永久存储器中,并且在永久存储器中直接对其管理。这不同于所谓的对象数据库,对象数据库试图通过将数据库映射到不同的已知数据模型而使数据管理透明。将要被永久存储的对象在创建时就被明确地限定和识别,并且可以明确地指明需要删除的对象。另外,本发明提供事务管理模型,其中在单个事务中多个对象可以被自动地修改。如将要描述的,为了实施需要的新的实时行为,本发明的AFJC具体化该新的和不同的Java编译器功能,该功能根据本发明的永久对象和事务管理模型而定制。
当基于提供给编译器的指示而创建对象时,AFJC(编译器)120可以决定将哪些对象存储在易失性存储器中,以及将哪些对象存储在永久闪速非易失性存储器中。有很多不同的方法可以用于提供该功能。根据第一种方法,可以缺省将所有的对象存储在非易失性存储器116中。当创建新的对象时,可以将它们自动存储在闪存阵列中。该方法的优点为,现有的应用可以受益于AFJRE而不需要重新编译。由于利用该方法,临时对象和永久对象之间没有区别,可以在AFJRE中创建用于清理不需要的对象的新的垃圾回收器(GC),其具有新的堆实现方式(heap implementation)存储闪存阵列116中的对象。
根据第二种优选的方法,提供指示给编译器,决定将哪些对象存储在非易失性存储器中,这被包含在对象定义中。可以利用Bean注释指明哪些对象应该存储在闪存阵列中,以及哪些对象应该存储在易失性存储器中。可以将Bean注释应用于类定义,它在使附加信息被包括进来方面是有利的,该附件信息诸如如何保存对象或对象的类,例如:
@flash-storage
Public Class MyObject{
String name;
Date date;
}
另外,可以将应用重新编译,并且将bean注释添加到程序中。该方法还影响AFJRE的其他方面。这些方面包括删除对象和查找对象。
永久存储器中的对象不会被自动删除。缺省地,未被引用的对象可能被垃圾回收器删除。为了避免对需要对象的删除,可以采用垃圾回收方法,其中被引用的对象会免于被删除。另外,如果不能发现永久对象,就不能使用该对象,优选地,本发明执行索引和查询方案。索引将提供对对象的至少一个引用,这可以防止其被删除。可选地,可以利用Java命令诸如object.delete()和object.finalize()控制垃圾回收器将特定对象从闪存阵列中删除。如将要描述的,查询方法可以利用由索引定义创建的索引查找存储阵列中的对象。
图2和图3绘示和对比了从存储器中的数据结构(图2)中的传统数据库中检索对象与访问本发明(图3)的AFDB中的永久对象的之间的区别。
图2绘示了步骤的顺序和伴随的开销(attendant overhead),以及发生在从存储器中的数据结构中的传统数据库存储阵列中检索对象的低效率。应当理解,低效率的程度将依赖于数据库的实际实现。参考图2,构造函数可以在Java虚拟机(JVM)的栈212上创建引用,以从存储阵列216访问对象的数据页214。数据库客户端218可以请求与来自数据库服务器222的对象对应的数据页。该数据库服务器操作系统224可以从存储设备检索数据页214,并且将这些页存储在存储阵列的块缓存230中。然后可以将这些页搬运到操作系统224页缓存和数据库服务器222页缓存中。Java虚拟机中的查询引擎可以处理这些页,并且创建结果集230,该结果集230被填充到该Java虚拟机的Java对象堆232中。
反之,根据本发明,如图3所示,构造函数可以在Java虚拟机(JVM)310的栈312上创建引用,以从全闪存阵列316访问永久对象314。该JVM310可以直接访问对象314而不需要大量和各种类型的翻译操作(translation operation),这在图2中的传统数据库中是需要。因此,该操作不像传统数据库中那样,不需要多个翻译或发生附带的低效率。访问对象时,JVM310可以 使用或根据需要修改该对象。
Java提供用于在存储器堆中查找对象的对象查询语言(OQL)。本发明可以基于查询定义利用该能力并结合索引系统定位全闪存阵列中的对象。本发明可以利用几种方法定位对象。一种方式为全扫描整个闪存阵列并且测试所有对象。由于阵列中对象的数量可能很大,因此这种方法是低效的。因此,全扫描通常用于保守搜索(sparingly search)或优选地只用于一次性搜索。并且,由于闪存阵列中没有对象边界,因此本发明可以创建构造函数以用注册表注册阵列上的对象,该注册表使用对象的开始位置和其比特数量的长度。然后,全扫描会扫描整个注册表以定位正确的对象。
本发明使用的第二种优选的并且更有效的方法为创建一个或多个专用索引结构,诸如B-trees或倒置索引,以使对象被更容易地定位。可以利用对象定义上的Bean注释识别对象属性,可以利用该对象属性创建该索引结构。可以将该索引结构存储在存储阵列数据库中,并且将其注册到注册表中,从而可以查找到它们。单个bean定义可以保持多个索引,并且产生用于各个索引的索引管理的多个对应的代码块。索引可以是单键、组合键或倒序索引,并且可以被同步地或异步地更新。单键索引可以定义在对象属性层,而组合索引定义在对象层。图4-6绘示了该方案的实施例。
参考图4,索引定义可以被定义在Java bean代码402中,并且被提供给本发明的全闪存编译器404,该全闪存编译器将读取该注释以创建索引管理字节码406。该字节码可以创建索引410、更新索引412、删除索引414或执行索引查找416。生成的码可以维护关于码源自哪个索引定义的信息,从而处理类定义和索引定义变化。因此,该索引管理字节码可以存储索引信息,该索引信息包括类名、类版本识别符和索引定义的组合。用于单键同步B-tree索引的bean注释的例子为:
@flash-storage
Public Class MyObject{
int id;@flash-index(synchronous,btree)
String name;
Date date;
}
用于组合键同步索引的例子为:
@flash-storage
@flash-composite-index(synchronous,btree)[id,date]
Public Class MyObject{
int id;
String name;
Date date;
}
用于倒序异步索引的例子为:
@flash-storage
@flash-composite-
index(synchronous,
btree)[id,date]Public
Class MyObject{
int id;
String name;@flash-
index(asynchronous,
inverted)Date date;
}
索引定义的例子为:
″com.emc.ecd.MyObject″,123456,flash-composite-index(synchronous,btree)[id,date],IndexByteCode″com.emc.ecd.MyObject″,123456,flash-index(synchronous,btree)[id],IndexByteCode
类版本标示符由Java运行时基于类定义产生,并且是版本识别的(version aware)。可以将其用于快速检测类在加载到AFJRE期间是否发生了变化。该AFJRE将创建索引结构并在运行时加载类时将该索引结构注册进全闪存阵列。 该注册过程只需要发生一次,并且被绑定到类版本识别符,通过该类版本识别符与索引注册到一起。优选地,在永久映射中的对象堆中管理索引结构以快速定位索引结构。图5绘示了该过程以及产生的全闪存阵列中的索引结构。
如图5所示,Java虚拟机500可以包括对象堆502和索引堆504。该对象堆和索引堆可以管理全闪存阵列510中的永久索引结构。该全闪存阵列可以具有用于存储索引结构的索引定义结构512和514,分别用于索引以数据对象516和518为首的多个索引数据对象(IDOs)。该图只绘示了两个这样的数据对象结构,但应当理解可以具有很多这样的数据对象结构。
本发明提供创建、更新和删除对象以及他们的相关索引的过程。当创建了对象时,AFJRE可以确定是否具有与该对象类定义相关的索引。如果具有,则也应当为新数据更新该索引。AFJRE可以从索引堆中查找合适的索引定义、发现对索引定义的引用并且更新永久索引数据结构。当修改了对象时,AFJRE将跟踪bean中的变化,并且确定是否具有需要更新的相关索引。它将从索引堆中查找合适的索引定义、发现对索引数据对象的引用并且更新永久索引数据结构。当删除对象时,AFJRE将确定需要更新的相关索引,并且将被删除对象的索引条目删除。可以利用查找方法直接检测到这些索引。AFJRE可以查找索引堆中的索引定义、加载索引字节码并且执行用于这些索引的查找方法。
图6绘示了根据本发明的用于创建、更新和删除对象的过程的例子。类加载器602将在604从字节码获取索引定义,并且在606从索引堆获取索引定义。在608该过程将判断是否具有任何新的索引定义,并且在610如果发现新的索引定义,将在612锁定该索引堆,在614将注册该新的索引定义,并且在616解锁该索引堆。在620该过程将查找被改变的索引定义。在622,如果有任何索引定义已改变了,则在624将该索引堆再次锁定。在626可以放弃该索引,并且在628注册被改变的索引定义。在630再次将索引堆解锁。在632可以注册用于重索引的后台工作(background job)。
本发明采用事务模型用于管理对象,该事务模型不同于一般Java运行时环 境中的事务模型,在一般Java运行时环境中不需要事务管理,因为存储器内更新总是成功的或者产生异常。然而,本发明的AFJRE是不同的,并且采用了不同的事务模型。本发明提供两种不同的模型,分别用于隐性事务和显性事务。
如果AFJRE没有检测到显性事务内容,那么它会采用隐性模型,在隐性模型中bean上的域更新是原子的(atomic)。相同的或不同的bean上的多个更新不能保证事务一致性。这意味着,例如这样的操作:
{
object.id=123
}
将是闪存阵列上的原子操作,但是操作:
{
object.id=123
object.name=″foo″
}
将不是原子的,并且在两个更新之间可以被中断,从而只有第一个更新是永久的。
在显式事务模型中,事务是显示地执行的,例如:
{
AFTransaction.begin()
object.id=123
object.name=″foo″
AFTransaction.commit()
}
Java堆是存储器单元的集合,其中由程序根据需要分配和释放动态程序数据。Java虚拟机的堆存储由运行的Java应用创建的所有对象。根据本发明的AFDB Java堆构造以实现用于需要快速定位的对象的瞬时数据(instance data),并且在方法区中提供对象的类数据的访问,该对象的类数据被给予对对象的引用。优选地,本发明具有利用AFDB的单个堆,并且优选地,在具有 直接指针引用的堆的顶端实施Java方法区。当虚拟机需要用于新加载类的存储器时,其可以从对象在的相同的AFDB堆占用存储器。可以利用不同的方法检测对象并回收存储器空间。例如,可以删除未被引用的对象。垃圾回收器释放未被引用的对象所占据的存储器,也可以用于查找并释放(卸载)未被引用的类。可以在易失性存储器中栈的内部管理对象引用,并且对象引用可以指向AFDB堆中的对象。本发明可以查询AFDB堆以基于指针引用检索对象。
为了释放存储器,本发明还提供用于永久数据的不同的垃圾回收方案。永久数据上的垃圾回收只有在删除对象操作的情况下是相关的。例如,删除操作可以是启动使用的对象管理器接口,诸如:ObjectManager.delete(Object object)。在大多数情况下,删除操作本质上是事务性的。然而,在有些情形中这是不可能。例如,如果其他并发进程或应用使用了对象,那么就不希望删除该对象。然而,在永久队列中可以将其标记为删除,并且后台进程可以异步移除该对象。另外,一些对象可以被其它对象引用,对象删除将打断引用完整性。在一些情况中,本发明可以采用强制删除来删除对象,而不管对该对象的引用的存在。
图7A-C绘示了利用垃圾回收器删除对象以及删除后压缩存储器以释放存储器的例子。参考图7A,假设AFDB中的永久存储器700的块存储了六个对象O1-O6,并且在702中将对象O5标记为删除。如图7B所示,垃圾回收(GC)之后,如虚线指示的702中的对象O5被删除,并且如虚线所指示的,之前由对象O5占据的永久存储器700中的单元704现在是空的。继删除对象O5之后,可以执行存储器压缩操作以压缩存储器700。如图7C所示,710中,压缩可以移动对象06至存储器单元704,该存储器单元704之前由被删除的对象O5占据,从而释放存储器单元712,该存储器单元712原先由对象O6占据。如所示的,这会将对象O1-O4和O6压缩到存储器700中连续的单元。
图8A-C绘示了将对象指示为删除的不同方式。一种删除对象的方式为通过中断引用。图8A-B对此进行了绘示。参考图8A,在802中,对象O5可以 引用804中的对象O2和806中的对象O3,如由810和812指示的。如图8B所示的,分别中断对对象O2和O3的引用810和812之后,802中的对象O5不再有引用,并且可以被垃圾回收进程删除。
图8C绘示了指示对象删除的另一种方案。如所示的,820中的对象O5可以引用一对对象即822中的对象O2和832中的对象O3,如826和828所指示的。在下一个垃圾回收中可以将肯定地将O5标记为删除,并且如830和832所示的可以将其此分别传递给对象O2和O3。在下一个垃圾回收中,从而可以将对象O5肯定地删除。如果需要,可以执行以上所述的存储器压缩。
从前述可以理解,本发明利用永久非易失性闪速存储器提供用户数据库的新的并且不同的以存储器为中心的架构,其利用了闪速存储器的独特特点和效率,同时解决了对灵活性、易于数据管理和性能的要求,这对于在事务性环境中采用的数据库是很重要的。因此,基于该架构的全闪存数据库提供了极为简单和更有效的数据库存储方法。
虽然以上所述引用了本发明的特定实施例,但是应当理解在不背离本发明的原则的情况下可以修改这些实施例,本发明的范围由随附的权利要求限定。
- 还没有人留言评论。精彩留言会获得点赞!