一种大数据环境下异构数据实时检索方法与流程
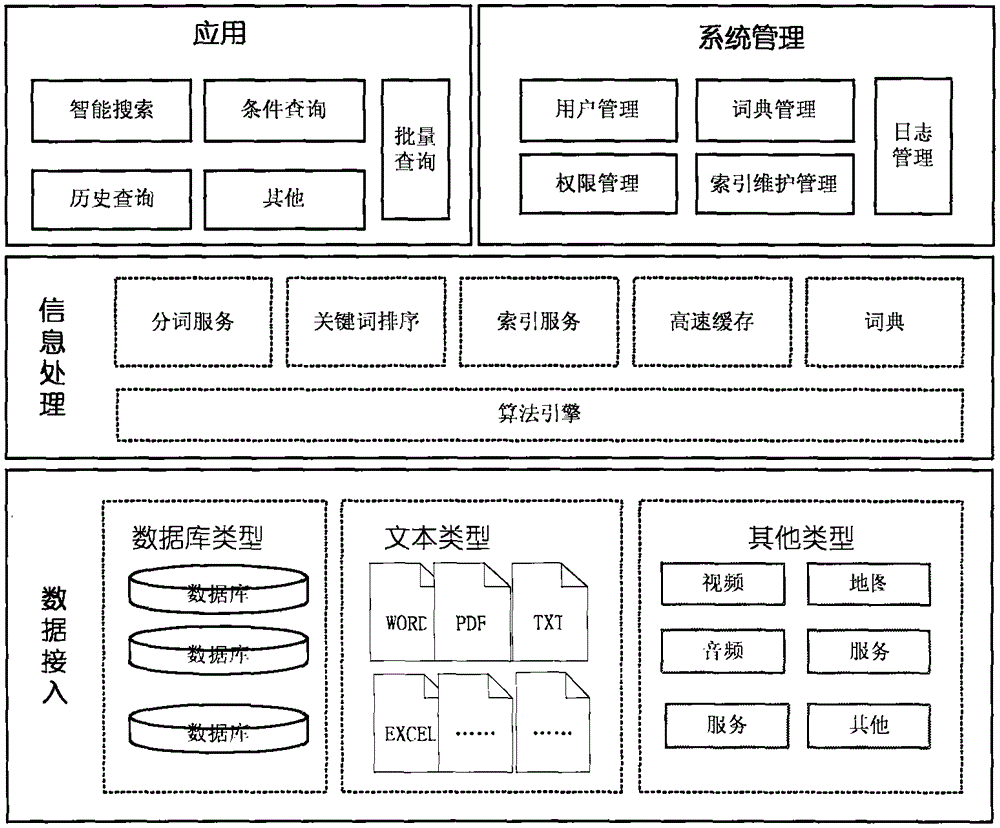
本发明涉及一种大数据环境下异构数据实时检索方法,主要应用领域包括平安城市、智慧交通、智慧城市等多个领域,不局限于特定的应用场景,适用范围广阔。
背景技术:
随着信息化技术应用日益普及,信息化系统呈现逐年上升的趋势,为此这些信息化系统产生的数据也将越来越广泛。尤其随着平安城市、智慧城市等新兴平台的诞生,对数据整合和数据快速响应提出了更高的要求。传统模式下检索技术实现方式,应用场景比较单一,对数据源环境也提出了较为苛刻要求,数据检索的结果集(或者是索引库)存储模式不够灵活,不利于解决数据持续增长带来的检索膨胀问题。如何在海量数据中快速响应用户检索要求,即用户的实时响应;如何在海量数据的范围内,在满足检索效率的同时,提高检索内容的准确性,即提高用户检索内容的准确性,是目前面临的技术难题。
技术实现要素:
本发明的目的在于提供一种大数据环境下异构数据实时检索方法,立足解决现有技术存在的问题,在完善现有技术应用同时,也针对具体的应用场景进行检索机制的优化。通过运行机制的创新,调度控制算法的优化,及特征词算法的优化,实现其目的。
本发明的技术方案如下:
一种大数据环境下异构数据实时检索方法,其特征在于,包括以下步骤:
步骤1:搭建海量数据索引云服务,实现索引存储负载的均衡化;搜索请求开始后,根据总控制台指令,分别向各个shard分片进行搜索;获取各自检索的记录;汇集各分片初始结果集;对初始结果集进行排序,按照预置条件要求,返回符合条件的记录;通过上一阶段获取的信息,进行字段值选择;并行执行任务,去各个shard获取字段值信息;汇总各个shard的字段值信息;收集各分片的最终结果;合并结果,统一返回;
步骤2:优化异构数据内容解析算法,使其解析更准确;在运用textrank时考虑到每一个顶点即词的权重,再进行下一步的投票以及迭代的操作来获取文章的特征词;在进行taxtrank提取关键词之前,先对数据集中的文档进行每个词的权重计算,之后将这个词的权 重值作为textrank每个词输入,进行下一步的计算。
本发明在实际应用场景中取得了良好的反馈,成功解决大数据环境下异构数据高效检索的问题,能够兼容不同数据源,实现各类数据的统一接入,并与其建立规范的同步机制。通过结合索引云服务和优化算法实施,实现快速检索同时也提高检索的准确性。根据本发明的实验室数据,通过建立5shard索引分片集群,检索结果平均提升了近3倍,准确性也得到了提升。
附图说明
图1为本发明总体架构图;
图2为索引服务集群执行示意图。
具体实施方式
图1为本发明总体架构图。本发明在综合分析目前的成熟的技术架构基础上,采用了扩展性技术架构,能够为未来的数据的增长提供预留空间。
图2为索引服务集群执行示意图,具体的技术实现方案主要包括以下步骤:
步骤1:搭建海量数据索引云服务,实现索引存储负载的均衡化。
图2中详细执行过程大体说明如下:
A箭头表示搜索请求开始
B表示根据总控制台指令,分别向各个shard分片进行搜索。
C表示获取各自检索的记录
D汇集各分片初始结果集。
E对初始结果集进行排序,按照预置条件要求,返回符合条件的记录。
F通过上一阶段(E)获取的信息,进行字段值选择。
G并行执行任务,去各个shard获取字段值信息。
H汇总各个shard的字段值信息。
I收集各分片的最终结果。
J合并结果,统一返回。
步骤2:优化异构数据(文档、数据表、音频等数据)内容解析算法;使其解析更准确。
在运用textrank考虑到了在图2中每一个顶点即词的权重,再进行下一步的投票以及迭代的操作来获取文章的特征词。因此在进行taxtrank提取关键词之前,我们先对数据集中的文档进行每个词的权重计算,之后将这个词的权重值作为textrank每个词输入,进行下一步的计算。具体计算方法如下公式:
W(Vi)表示当前顶点的权重,在对于总体文档的关键字提取的技术中我们还是选取比较常用的TFIDF的方法进行每个词的权重的计算,但在计文档权重过程中,TFIDF的数值比较小,一旦输入textrank中进行迭代,会影响实验的效果,所以在这里我们将TFIDF值进行归一化的处理后,输入textrank中进行权值计算。归一化公式如下:
通过采用改进后的算法进行解析工作,整体数据的特征词提取准确性得到极大提高。
- 还没有人留言评论。精彩留言会获得点赞!