信息查询方法及系统与流程
本发明涉及移动通信领域,尤其涉及一种信息查询方法及系统。
背景技术:
在移动互联网中,移动终端如手机和PAD终端通过电信运营商进行无线方式接入,实现网络的访问。为了保障公共信息安全,电信运营商对通过CTNET、CTWAP或者WLAN方式接入,访问互联网业务的网络痕迹数据进行了留存。主要包含了两种类型痕迹数据,移动上网用户在接入互联网时认证登录过程中痕迹和移动上网用户在接入互联网后访问互联网时痕迹数据。
随着移动互联网的迅猛发展和智能手机终端的普及,移动上网的痕迹留存数据量由GB级别突破到TB级别。以福建电信900万C网用户,2014年1月的每天产生的原始上网痕迹数据为700G。按照至少保存3个月的中国工信部要求,那么数据总量在70T,而且有日益增长的趋势。
现有的技术解决架构为把上网痕迹数据关联匹配后,装载入关系型数据库,来实现对用户上网行为的查询和统计分析。当遍历查询的数据量在10TB以上时,集中式的关系型数据库处理系统,出现了数据查询定位缓慢,检索一个用户的一周上网痕迹数据时需要耗费接近6小时,对宏观的用户网络行为分析在现有架构下无法完成。即使目前互联网行业已大量采用hadoop大数据技术运用在用户行为分析上,但仍然需要因业务量快速增长而带来的分析数据量的海量增加,不断被动地手工调整云计算资源和存储资源。
因此,有必要提出一种高效的移动上网的痕迹留存数据留存和检索方法以解决上述技术问题。
技术实现要素:
本公开要解决的一个技术问题是如何提出一种高效的移动上网的痕迹留存数据留存和检索方法解决现有技术中海量数据存储与检索中存在的问题。
本公开提供一种信息查询方法,包括:在接收到查询用户发送的查询统计请求后,对查询统计请求进行任务分解以得到相应的map reduce任务;根据得到的map reduce任务,从分布式文件系统中相应的分布式数据存储节点读取数据;其中在分布式文件系统中的Hive数据仓库中,数据存储采用RcFile格式;根据各分布式数据存储节点读取的数据进行分布式计算;将各分布式数据存储节点的计算结果进行合并,以得到查询结果;将查询结果提供给查询用户。
进一步地,该方法包括:实时采集移动用户的上网痕迹数据;将采集到的上网痕迹数据装载到分布式文件系统中的Hive数据仓库中。
进一步地,该方法包括:在将采集到的上网痕迹数据装载到分布式文件系统中的Hive数据仓库中的步骤中,还包括:
在进行Hive数据仓库中数据表创建时,根据查询统计请求任务分解个数和系统能力确定分桶个数。
进一步地,该方法包括:利用公式
Buckets=min(data_total_size/dfs.block.size,map_count)
计算分桶个数Buckets,其中min()为取最小值函数,data_total_size为上网痕迹数据总量,dfs.block.size为分布式文件系统中配置的文件块大小,map_count为查询统计请求任务分解个数。
进一步地,该方法包括:上网痕迹数据包括DPI设备分类上传的认证信息和互联网访问信息、WAP网关分类上传的认证信息和互联网访问信息、防火墙的SYSLOG日志服务器上传的NAT地址转换信息。
本发明还提供一种信息查询系统,包括接口单元、查询驱动单元、数据处理单元和分布式文件系统,其中:接口单元,用于接收查询用户发送的查询统计请求;查询驱动单元,用于在接口单元接收到查询用户发送的查询统计请求后,对查询统计请求进行任务分解,以得到相应的 map reduce任务,并将得到的map reduce任务提供给数据读取单元;数据处理单元,用于根据得到的map reduce任务,从分布式文件系统中相应的分布式数据存储节点读取数据,根据各分布式数据存储节点读取的数据进行分布式计算,将各分布式数据存储节点的计算结果进行合并,以得到查询结果;并指示接口单元将查询结果提供给查询用户;分布式文件系统,用于存储分布式数据,其中在分布式文件系统中的Hive数据仓库中,数据存储采用RcFile格式。
进一步地,还包括:采集单元和数据装载单元,其中:
采集单元,用于实时采集移动用户的上网痕迹数据;
数据装载单元,用于将采集单元采集到的上网痕迹数据装载到分布式文件系统中的Hive数据仓库中。
进一步地,数据装载单元具体在进行Hive数据仓库中数据表创建时,根据查询统计请求任务分解个数和系统能力确定分桶个数。
进一步地,数据装载单元利用公式
Buckets=min(data_total_size/dfs.block.size,map_count)
计算分桶个数Buckets,其中min()为取最小值函数,data_total_size为上网痕迹数据总量,dfs.block.size为分布式文件系统中配置的文件块大小,map_count为查询统计请求任务分解个数。
进一步地,上网痕迹数据包括DPI设备分类上传的认证信息和互联网访问信息、WAP网关分类上传的认证信息和互联网访问信息、防火墙的SYSLOG日志服务器上传的NAT地址转换信息。
本公开提供的信息查询方法与系统,以自动资源适配的方式自动增加云资源计算节点,提升移动上网日志查询和分析的效率。
附图说明
图1示出本发明一个实施例的信息查询方法的流程图。
图2示出本发明一个实施例的信息查询系统的结构示意图。
图3示出本发明一个实施例的信息查询方法的流程示意图。
图4示出本发明一个实施例的信息查询方法的效果图。
图5示出本发明一个实施例的信息查询系统的结构框图。
图6示出本发明的另一个实施例的信息查询系统的结构框图。
具体实施方式
下面参照附图对本发明进行更全面的描述,其中说明本发明的示例性实施例。
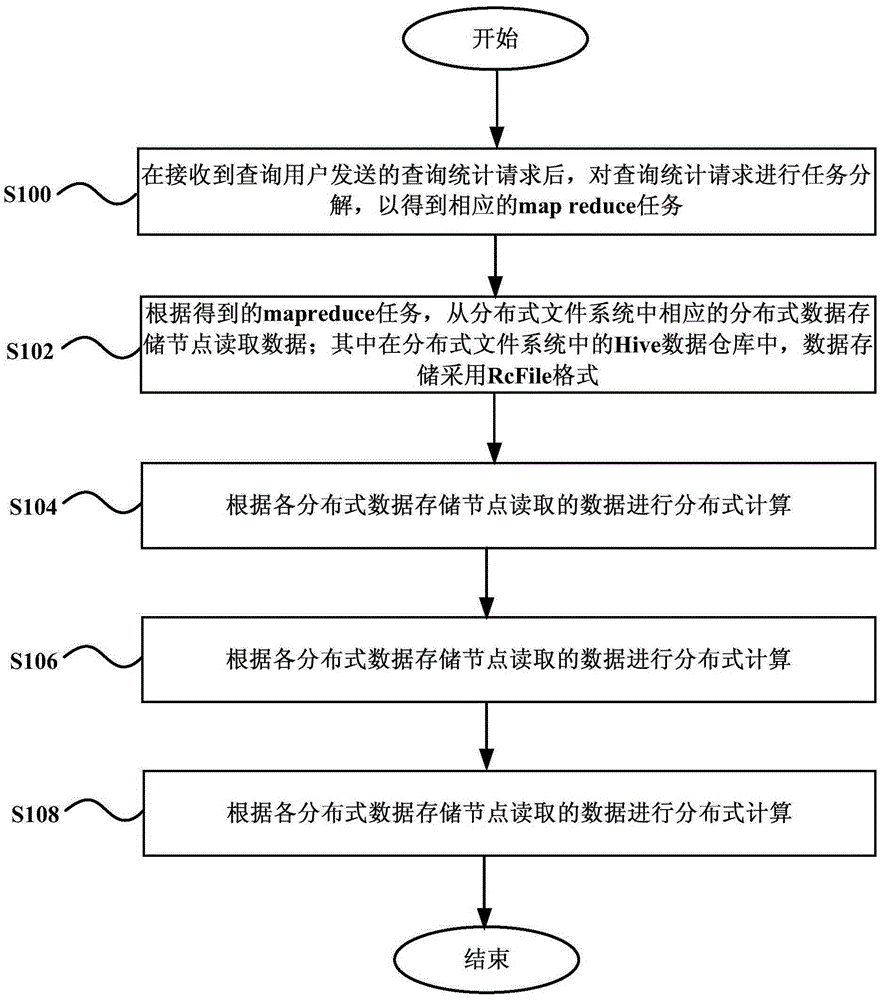
图1示出本发明一个实施例的信息查询方法的流程图。如图1所示,该方法主要包括:
步骤100,在接收到查询用户发送的查询统计请求后,对查询统计请求进行任务分解,以得到相应的map reduce任务。
步骤102,根据得到的map reduce任务,从分布式文件系统中相应的分布式数据存储节点读取数据;其中在分布式文件系统中的Hive数据仓库中,数据存储采用RcFile格式。
在一个实施例中,实时采集移动用户的上网痕迹数据;将采集到的上网痕迹数据装载到分布式文件系统中的Hive数据仓库中。
在一个实施例中,上网痕迹数据包括DPI设备分类上传的认证信息和互联网访问信息、WAP网关分类上传的认证信息和互联网访问信息、防火墙的SYSLOG日志服务器上传的NAT地址转换信息。
在一个实施例中,在进行Hive数据仓库中数据表创建时,根据查询统计请求任务分解个数和系统能力确定分桶个数。
在一个实施例中,可以利用公式
Buckets=min(data_total_size/dfs.block.size,map_count)
计算分桶个数Buckets,其中min()为取最小值函数,data_total_size为上网痕迹数据总量,dfs.block.size为分布式文件系统中配置的文件块大小,map_count为查询统计请求任务分解个数。这样,以自动资源适配的方式自动增加云资源计算节点,有利于后期进行检索。
步骤104,根据各分布式数据存储节点读取的数据进行分布式计算。具体地可以根据分桶算法形成的存储节点进行分布计算,这样可以 提升移动上网日志查询和分析的效率。
步骤106,将各分布式数据存储节点的计算结果进行合并,以得到查询结果。
步骤108,将查询结果提供给查询用户。
本发明实施例提供的信息查询方法,可以充分发挥云计算资源池和Hadoop分布式大数据处理两种技术优势,在数据仓库Hive使用优化数据分桶算法,并且对上网痕迹类型数据采用Rcfile压缩格式存储,其中,Hive RcFile压缩存储格式的使用,相比Hadoop中自然TextFile格式,相同数量数据可节省2/3存储空间;Hive使用优化数据分桶算法,相比Hive自然中不分桶存储,业务查询时间大幅提升。
图2示出本发明一个实施例的信息查询系统的结构示意图。本发明提供一种构建在X86架构云计算资源池上的HADOOP分布式大数据处理系统,以自动资源适配的方式,自动增加云资源计算节点,提升移动上网日志查询和分析的效率。如图2所示,该系统包括:日志采集模块27、X86架构的云计算资源池21,HDFS分布式文件系统22、map reduce23、PIC查询模块25、HIVE统计分析模块26。其中,日志采集模块27是负责移动上网痕迹数据采集的模块,移动上网痕迹数据采集模块部署在具备高速网络接入的物理设备上,负责把分组域的DPI设备分类上传认证信息和互联网访问信息、WAP网关分类上传认证信息、互联网访问信息(包括代理信息)、防火墙的SYSLOG日志服务器上传NAT地址转换信息进行收集和关联。
大数据查询分析模块部署在x86架构的云计算资源池21上,充分利用云计算Iaas的灵活计算资源调度能力,大数据查询分析模块将移动上网痕迹数据采集模块中关联完毕的痕迹数据装载进入Hive数据仓库,数据存储采用RcFile格式,Hadoop平台系统中常用的文件存储格式有支持文本的TextFile和支持二进制的SequenceFile等,它们都属于行存储方式。RCFile(Record Columnar File)存储结构遵循的是“先水平划分,再垂直划分”的设计理念。
首先,RCFile具备相当于行存储的数据加载速度和负载适应能 力;其次,RCFile的读优化可以在扫描表格时避免不必要的列读取,测试显示在多数情况下,它比其他结构拥有更好的性能;再次,RCFile使用列维度的压缩,因此能够有效提升存储空间利用率,一般而言,Hive RcFile压缩存储格式的使用,相比Hadoop中自然TextFile格式,相同数量数据可节省2/3存储空间。
在进行数据表创建时分桶个数计算公式如下:
Buckets=min(data_total_size/dfs.block.size,map_count)
其中buckets为分桶个数;data_total_size为数据总大小;dfs.block.size为hdfs中配置的文件快大小。map_count为业务查询任务分解个数。
按照上述公式确定分桶个数,进行数据仓库Hive中数据表创建时,可以充分考虑后续业务查询分解和现有系统能力配置的匹配,经过同量数据的反复测试,达到了时间和资源的优化平衡,可以有效的缩短后期检索所使用的时间。
图3示出本发明一个实施例的信息查询方法的流程示意图。如图3所示,该方法包括:
步骤301,用户通过Web interface31发送查询统计请求。
处理用户通过web interface发送的查询统计请求,并将所述查询统计请求发送给Hive Drive32。
步骤302,Hive Drive32分解任务引擎。
具体地,Hive Drive32分解和翻译查询统计请求,将该查询统计请求分解和翻译为map reduce(映射归约)任务。
步骤303,Map reduce33根据任务的依赖关系,执行各种mapreduce任务。
具体地,一个mapreduce任务都被序列化到一个plan.xml文件中,然后加载到job cache中,并且各部分解析plan.xml(反序列化),并执行相关操作,将结果放入临时的位置,再由DML(数据操纵语言)转移到指定位置。
步骤304,HDFS(Hadoop Distributed File System,分布式文件系 统)调取分布式数据存储节点数据进行分布式计算,其中该分布式存储节点的数据是根据分桶算法得到的数据。
步骤305,Map reduce33合并各个节点的计算结果。
步骤306,Hive Drive32返回展现结果给Web interface31,以通过Web interface31将展现结果展现给查询用户。
图4示出本发明一个实施例的信息查询方法的效果图,以福建电信移动上网痕迹数据的采集分析为例。福建电信900万C网用户,2014年1月的每天产生的原始上网痕迹数据为700G,按照至少保存3个月的中国工信部要求,数据总量在70T,按照本发明的架构,日志采集模块和各个数据源通过光纤高速互联,并且使用物理服务器,实现数据的汇聚和关联。
本发明的主要核心模块,承载在福建电信业务云计算资源池,使用vmware vspher的虚拟化计算平台,开通6个处理节点。采用本发明实施例的分桶算法进行存储时,针对用户的漫游访问模型、提篮临近模型、最高访问目的模型等实现了行为分析,在对100亿条的数据查询,测试查询结果为1201秒,相比原集中式关系数据库处理系统,有了大幅提升。
图5示出本发明一个实施例的信息查询系统的结构框图,该系统500包括接口单元501、查询驱动单元502、数据处理单元503和分布式文件系统504,其中:接口单元501用于接收查询用户发送的查询统计请求;查询驱动单元502用于在接口单元接收到查询用户发送的查询统计请求后,对查询统计请求进行任务分解,以得到相应的map reduce任务,并将得到的map reduce任务提供给数据读取单元;数据处理单元503,用于根据得到的map reduce任务,从分布式文件系统中相应的分布式数据存储节点读取数据,根据各分布式数据存储节点读取的数据进行分布式计算,将各分布式数据存储节点的计算结果进行合并,以得到查询结果;并指示接口单元将查询结果提供给查询用户;分布式文件系统504,用于存储分布式数据,其中在分布式文件系统中的Hive数据仓库中,数据存储采用RcFile格式。
在一个实施例中,接口单元501可以为Web interface,查询驱动单元502可以为Hive Drive,数据处理单元可以为Map reduce,分布式文件系统可以为HDFS。
在一个实施例中,该装置还包括:采集单元505和数据装载单元506,其中:采集单元505,用于实时采集移动用户的上网痕迹数据;数据装载单元506,用于将采集单元采集到的上网痕迹数据装载到分布式文件系统中的Hive数据仓库中。
在一个实施例中,数据装载单元506具体在进行Hive数据仓库中数据表创建时,根据查询统计请求任务分解个数和系统能力确定分桶个数。
在一个实施例中,数据装载单元506利用公式
Buckets=min(data_total_size/dfs.block.size,map_count)
计算分桶个数Buckets,其中min()为取最小值函数,data_total_size为上网痕迹数据总量,dfs.block.size为分布式文件系统中配置的文件块大小,map_count为查询统计请求任务分解个数。
在一个实施例中,上网痕迹数据包括DPI设备分类上传的认证信息和互联网访问信息、WAP网关分类上传的认证信息和互联网访问信息、防火墙的SYSLOG日志服务器上传的NAT地址转换信息。
图6示出本发明的另一个实施例的信息查询系统的结构框图,该信息查询系统600可以是具备计算能力的主机服务器、个人计算机PC、或者可携带的便携式计算机、移动终端或其他终端等。本发明具体实施例并不对计算节点的具体实现做限定。
信息查询系统600包括处理器(processor)601、通信接口(Communications Interface)602、存储器(memory)603和总线604。其中,处理器601、通信接口602、以及存储器603通过总线604完成相互间的通信。
通信接口602用于与网络设备通信,其中网络设备包括例如虚拟机管理中心、共享存储等。
处理器601用于执行程序。处理器601可以是一个中央处理器 CPU,或者可以是专用集成电路ASIC(Application Specific Integrated Circuit),或者是被配置成实施本发明实施例的一个或多个集成电路。
存储器603用于存放文件。存储器603可以包含高速RAM存储器,也可还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。存储器603也可以是存储器阵列。存储器603还可能被分块,并且块可按一定的规则组合成虚拟卷。
在一种实施方式中,上述程序可为包括计算机操作指令的程序代码。该程序具体可用于:在接收到查询用户发送的查询统计请求后,对查询统计请求进行任务分解,以得到相应的map reduce任务;根据得到的map reduce任务,从分布式文件系统中相应的分布式数据存储节点读取数据;其中在分布式文件系统中的Hive数据仓库中,数据存储采用RcFile格式;根据各分布式数据存储节点读取的数据进行分布式计算;将各分布式数据存储节点的计算结果进行合并,以得到查询结果;将查询结果提供给查询用户。
在一个具体地实施方式中,该方法还包括:实时采集移动用户的上网痕迹数据;将采集到的上网痕迹数据装载到分布式文件系统中的Hive数据仓库中。
在一个具体地实施方式中,在将采集到的上网痕迹数据装载到分布式文件系统中的Hive数据仓库中的步骤中,还包括:在进行Hive数据仓库中数据表创建时,根据查询统计请求任务分解个数和系统能力确定分桶个数。
在一个具体地实施方式中,利用公式
Buckets=min(data_total_size/dfs.block.size,map_count)
计算分桶个数Buckets,其中min()为取最小值函数,data_total_size为上网痕迹数据总量,dfs.block.size为分布式文件系统中配置的文件块大小,map_count为查询统计请求任务分解个数。
在一个具体地实施方式中,上网痕迹数据包括DPI设备分类上传的认证信息和互联网访问信息、WAP网关分类上传的认证信息和互联网访问信息、防火墙的SYSLOG日志服务器上传的NAT地址转换信息。
本领域普通技术人员可以意识到,本文所描述的实施例中的各示例性单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件形式来实现,取决于技术方案的特定应用和设计约束条件。专业技术人员可以针对特定的应用选择不同的方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
如果以计算机软件的形式来实现功能并作为独立的产品销售或使用时,则在一定程度上可认为本发明的技术方案的全部或部分(例如对现有技术做出贡献的部分)是以计算机软件产品的形式体现的。该计算机软件产品通常存储在计算机可读取的非易失性存储介质中,包括若干指令用以使得计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各实施例方法的全部或部分步骤。而前述的存储介质包括U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
本发明的描述是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显然的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
- 还没有人留言评论。精彩留言会获得点赞!