一种空间点数据的处理方法及装置与流程
本发明涉及数据处理技术领域,尤其涉及一种空间点数据的处理方法及装置。
背景技术:
随着人类活动能够产生和捕捉到的数据量逐年膨胀,人类进入了大数据时代。这种以包含经纬度字段为特征的坐标点数据,例如GPS数据,静态地理位置元素坐标点数据等,数据种类和量也得到了前所未有的增长。以全国的建筑物、场所等的坐标点数据为例,可能就达到数亿条。面对如此海量的数据,传统的关系型数据库,即使建立经纬度坐标的联合索引,其空间范围查询响应时间有时也会达到数十秒;而新出现的诸多NoSQL库,虽然解决了普通海量属性数据访问性能的问题,但是对于这种空间数据,由于其中对大多对SQL并不支持,如果无法正确的建立索引表,空间范围查询时,也会面临数据扫描范围过大、功能单一、无法分页等问题。
现有技术中基于Key/Value型NoSQL数据库的矢量数据先序四叉树编码和索引方法包括:涉及一种基于Key/Value型NoSQL数据库的矢量数据先序四叉树编码和索引方法,这种方法使数据物理存储次序与空间范围连续性一致、数据主键次序与物理存储次序一致,从而在空间查询时能减少I/O操作,提高查询效率。这种方法包括如下步骤:完全四叉树空间划分与先序四叉树结点编码;矢量数据前缀编码和索引构建;先序四叉树索引。
但是,现有技术利用四叉树存储点数据的方案都是一种“自上而下”的方式,即随着点数据的写入,动态的划分网格,不同的网格位于不同的级别。这样做的缺点是:
针对范围查询一次性取出全部数据的情况,难以将多次的随机读转换为少量次数的连续读,在查询范围较大时,性能会相当的低;
写入空间点数据时,由于网格动态划分的存在,会随时修改已有的数据,会导致性能较低,在分布式的情况下,还需要额外开销保证其一致性;
翻页时采取随机网格的方式,难以保证翻页的稳定性。针对每次只需要取出少量数据的情况,如果按照原有的方法对取出的数据直接进行分页,可能产生如下两个不良后果:一、假定在数据量过大的情况下,一次将数据全部取出,再在客端分页的方式,可能导致内存溢出;二、如果使用数据库的限制取出前n条数据的方式,由于数据是按照网格编号存储的,导致的结果是,当查询范围较大时,每一页取出的数据条目均是集中在一个很小范围内的点,这对于地图撒点而言是不可接受的。
综上所述,现有技术中根据空间点的数量,动态划分网格,因此导致数据存储效率较低,不适用于海量数据存储。
技术实现要素:
本发明实施例提供了一种空间点数据的处理方法及装置,用以通过静态划分网格编号的方式存储空间点的数据,从而提高数据存储效率,适用于海量数据存储。
本发明实施例提供的一种空间点数据的处理方法,包括:
根据已知空间点的坐标所处的范围,确定网格范围,并根据已知空间点的数量,确定网格级别,根据所述网格范围和网格级别生成网格系统,该网格系统中包括多个网格;
针对每一已知空间点的坐标,根据该已知空间点的坐标,确定在所述网格系统中该已知空间点对应的网格编号;
将每一已知空间点的数据存储到在所述网格系统中对应的网格编号的网格中。
通过该方法,根据已知空间点的坐标所处的范围,确定网格范围,并根据已知空间点的数量,确定网格级别,根据所述网格范围和网格级别生成网格系统,该网格系统中包括多个网格;针对每一已知空间点的坐标,根据该已知空间点的坐标,确定在所述网格系统中该已知空间点对应的网格编号;将每一已知空间点的数据存储到在所述网格系统中对应的网格编号的网格中,因此实现了通过静态划分网格编号的方式存储空间点的数据,从而提高了数据存储效率,适用于海量数据存储。
较佳地,该方法还包括:
根据查询范围,确定在所述网格系统中需要查询的网格;
对所述需要查询的网格中存储的空间点的数据进行查询,确定查询结果。
较佳地,根据查询范围,确定在所述网格系统中需要查询的网格,具体包括:根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
对所述需要查询的网格中存储的空间点的数据进行查询,确定查询结果,具体包括:将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格之前,该方法还包括:根据查询范围的大小,将所述网格系统的级别进行简化,使得所述网格系统中的网络数量减少;
所述根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,具体包括:根据查询范围,确定在简化后的网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
所述将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内 存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果,具体包括:将在简化后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在简化后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
本发明根据查询范围的大小,动态提升(简化)网格编号的等级,从而达到简化查询实现,提高查询效率的目的。
较佳地,所述根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格之后,该方法还包括:根据所述确定的在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,对所述网格系统的网格进行合并,并确定合并后的网格的编号;
所述将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果,具体包括:将在合并后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在合并后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
本发明通过对网格系统的网格进行合并,从而也可以达到简化查询实现,提高查询效率的目的,可以进一步降低读取数据时的开销。
较佳地,对所述需要查询的网格中存储的空间点的数据进行查询的过程中,每次查询一页数据,每页数据包括多个非连续编号的网格中存储的空间点的数据。
本发明通过该翻页策略,可以实现均匀化地图撒点,使得查询的结果在网格上的分布更加均匀。
本发明实施例提供的一种空间点数据的处理装置,包括:
第一单元,用于根据已知空间点的坐标所处的范围,确定网格范围,并根据已知空间点的数量,确定网格级别,根据所述网格范围和网格级别生成网格系统,该网格系统中包括多个网格;
第二单元,用于针对每一已知空间点的坐标,根据该已知空间点的坐标,确定在所述网格系统中该已知空间点对应的网格编号;
第三单元,用于将每一已知空间点的数据存储到在所述网格系统中对应的网格编号的网格中。
较佳地,该装置还包括第四单元,用于:
根据查询范围,确定在所述网格系统中需要查询的网格;
对所述需要查询的网格中存储的空间点的数据进行查询,确定查询结果。
较佳地,所述第四单元具体用于:
根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述第四单元具体用于:
根据查询范围的大小,将所述网格系统的级别进行简化,使得所述网格系统中的网络数量减少;
根据查询范围,确定在简化后的网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
将在简化后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在简化后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述第四单元具体用于:
根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
根据所述确定的在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,对所述网格系统的网格进行合并,并确定合并后的网格的编号;
将在合并后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在合并后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述第四单元对所述需要查询的网格中存储的空间点的数据进行查询的过程中,每次查询一页数据,每页数据包括多个非连续编号的网格中存储的空间点的数据。
附图说明
图1为本发明实施例提供的2级网格示意图;
图2为本发明实施例提供的2级网格的网格编号的走向顺序示意图;
图3为本发明实施例提供的2级网格的查询范围示意图;
图4为本发明实施例提供的2级网格简化为1级网格的示意图;
图5为本发明实施例提供的查询范围所对应的网格示意图;
图6为本发明实施例提供的对查询范围所对应的网格进行合并后的网格示意图;
图7为本发明实施例提供的翻页优化前的第一页查询的网格示意图;
图8为本发明实施例提供的翻页优化后的第一页查询的网格示意图;
图9为本发明实施例提供的一种空间点数据的处理方法流程示意图;
图10为本发明实施例提供的一种空间点数据的处理装置的结构示意图。
具体实施方式
本发明实施例提供了一种空间点数据的处理方法及装置,用以通过静态划分网格编号的方式存储空间点的数据,从而提高数据存储效率,适用于海量数据存储。
本发明实施例提供的技术方案利用四叉树网格对空间点数据进行索引和查询分页,具体的,利用四叉树,索引空间点数据,并通过一系列优化措施,提升查询效率,增强查询功能。该方法主要适用于支持随机读和连续读的NoSQL库。在数据总量可以承受的范围之内,也可用于SQL库。
总体而言,本发明实施例提供的整个方案可以分为存储和查询两个部分。存储过程可以分为建立网格、计算空间点所在的网格、写入数据几个步骤。查询可以从基本的查询方式开始优化,优化可以包含预简化网格、合并网格两种方式,优化的宗旨在于将多次的随机读转化为少量次数的连续读。另外,针对需要翻页的情况,本发明实施例提供的技术方案的翻页策略,可以使每页的空间点数据在查询范围内尽量保持均匀分布。
关于空间点数据的存储介绍如下:
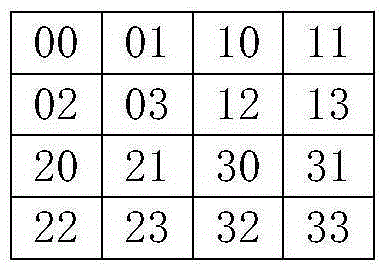
首先,根据已知空间点(待存储数据的空间点)的坐标所在范围划定网格范围,划定的网格范围应当包含所有的有效点,即覆盖所有的已知空间点的坐标。根据已知空间点的数量,确定网格级别,已知空间点的数量越多,确定网格级别越高;根据所述网格范围和网格级别生成网格系统,该网格系统中包括多个网格。网格级别假设为n,则n级的网格指的是,在整个网格系统范围内,分别在经度和纬度方向上,将整个网格系统的范围平均划分为2^n份,也就是说,整个网格系统有4^n个网格。每一网格按照四叉树编码,网格有多少级,编码便有多少位。如图1所示,为一个2级的网格,有16个网格。
图2示出了该2级网格的网格编号的走向顺序,即依次编号为00、01、02、03、10、11、12、13、20、21、22、23、30、31、32、33。
此处构建的网格系统实例,只包含对其边界范围和级别的描述,不存储每个网格的编码。
之后,存入空间点的数据的过程中,根据已知空间点的坐标,确定对应的网格编号,即针对每一已知空间点的坐标,根据该已知空间点的坐标,确定在所述网格系统中该已知空间点对应的网格编号,具体包括:
按照网格划分逐级计算出网格编号的每一位的编码。针对每一空间点,首先计算出该空间点的坐标的经度与整个网格系统最西经度坐标的差值的绝对值,记作offsetX,并且计算出该空间点的坐标的纬度值与整个网格系统最北纬度坐标的差值的绝对值,记作offsetY。之后,从网格编号的第一位编码(从左至右开始的第一位)开始计算:计算第一位时,考虑网格只有一级的情况,算出每个一级网格的经度跨度dividesXLength和纬度跨度dividesYLength,之后使用offsetX除以dividesXLength,得出的结果向下取整后记作xSpan,并且使用offsetY除以dividesYLength,得出的结果向下取整后记作ySpan。当xSpan和ySpan分别为奇奇、偶奇、奇偶、偶偶时,网格编号的第一位编码分别记作3、2、1、0。即:当xSpan和ySpan都为奇数时,网格编号的第一位编码为3;当xSpan和ySpan分别为偶数、奇数时,网格编号的第一位编码为2;当xSpan和ySpan分别为奇数、偶数时,网格编号的第一位编码为1;当xSpan和ySpan都为偶数时,网格编号的第一位编码为0。网格编号的第二位编码以及之后的编码等依此类推,最终得到的网格编号位数应当与网格级别相同。
例如:以一个二级的网格为例,假定该网格的四至为116°E,38°N,120°E,40°N,需要计算空间点117.2°E,39.3°N所在的网格中的网格编号。那么,首先计算出该空间点的offsetX,offsetY分别为1.2°,0.7°。之后,计算第一位网格编码,第一级网格中,单一网格的经纬度跨度dividesXLength和dividesYLength分别为(120°E-116°E)/(2^1)=2°,(40°E-38°E)/(2^1)=1°,之后使用offsetX除以dividesXLength,使用offsetY除以dividesYLength,得出的结果分别向下取整,xSpan和ySpan均为0,偶数,所以第一位编号为0。之后计算第 二位网格编码,第二级网格中,单一网格的经纬度跨度dividesXLength和dividesYLength分别为(120°E-116°E)/(2^2)=1°,(40°E-38°E)/(2^2)=0.5°,之后使用offsetX除以dividesXLength,使用offsetY除以dividesYLength,得出的结果分别向下取整,xSpan和ySpan均为1,奇数,所以第二位编号为3。所以确定该空间点的数据需要存储在编号为03的网格中,即该空间点对应的网格为编号为03的网格。针对有更多级别的网格,依此类推。
最后,将每一已知空间点的数据存储到在网格系统中对应的网格编号的网格中。
其中,存入数据过程中,对于一个键可以对应多个值的库,将网格编号作为键,空间点的数据字段值作为值存入到库中。对于一个键仅对应一个值的库,采用网格编号+空间点数据主键作为键,空间点数据所有字段值作为值存入到库中。
关于空间点数据的查询介绍如下:
每次查询,首先根据查询范围,计算与该查询范围相交和该查询范围内部的网格的编号(无法确定关系的都可以按相交网格计算),得到两个集合。然后再使用网格编号查询数据库。使用查询范围内部的网格(即该查询范围完全覆盖的网格)编号集合查询出的空间点的数据可以直接加入最终结果,使用相交网格的编号集合查出的空间点的数据,还需要判断该空间点是否位于查询范围中,位于查询范围的空间点的数据可以加入最终结果。例如,参见图3,图中矩形框为查询范围,则网格编号为{02,03,12,13,20,31,22,23,32,33}的网格为相交网格集合,网格编号为{21,30}的网格为内部网格集合。图3中仅为示例,通常应用中,内部网格的数量远大于相交网格。
关于查询优化方案:
按照上述查询方式,可能有效率上和内存溢出的隐患。主要发生在两个阶段,一个是根据查询范围计算得到的相交网格和内部网格的编号集合的过程,如果查询范围过大,会导致计算较慢,甚至由于网格过多导致内存溢出的风险; 另一个是根据网格编号集合查询数据的过程,如果随机读的次数太多的话,降低效率。因此,本发明实施例还提出了如下两种简化方式:
预简化策略:
在根据查询范围,确定在网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格之前,该方法还包括:根据查询范围的大小,将网格系统的级别进行简化,使得网格系统中的网络数量减少;
然后根据查询范围,确定在简化后的网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
将在简化后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在简化后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
例如,参见图4,在计算网格编号之前,可以根据查询范围的大小,将整个网格系统适当级别的简化,将2级简化为1级,简化后剩4个网格,分别编号为0、1、2、3。
本发明实施例根据查询范围的大小,动态提升(简化)网格编号的等级,从而达到简化查询实现,提高查询效率的目的。
合并网格策略:
根据查询范围,确定在网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格之后,该方法还包括:根据确定的在网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,对网格系统的网格进行合并,并确定合并后的网格的编号;
然后将在合并后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在合并后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
也就是说,除了使用上面提到的预简化策略外,对于计算完成的查询范围所对应的网格编号集合,还可以使用合并网格的方式进一步简化,这两种简化方式可以使用一个也可以在一个方法中都使用。例如,由于使用的是四叉树,所以当四个兄弟节点(例如编号为30、31、32、33的四个网格)全部存在时,可以将四个节点替换为其父节点,例如,若根据查询范围,确定在网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,如图5所示,则合并后的网格及其编号如图6所示,即将编号为30、31、32、33的四个网格合并为一个网格,该网格编号为3。
网格合并策略,进一步降低读取时的开销。
关于翻页介绍如下:
本发明实施例中,对需要查询的网格中存储的空间点的数据进行查询的过程中,每次查询一页数据,每页数据包括多个非连续编号的网格中存储的空间点的数据。
具体地,可以预简化查询范围,得到对应的网格编号集合后,可以采用将被简化的后n位编号作为页号的方式,作为后缀添加到网格编号中。例如,假定查询范围包含编号分别为00、01、02、03、10、11、12、13、20、21、22、23、30、31、32、33的共16个网格,预简化了1级网格编号,则查询范围包含编号分别为0、1、2、3的网格,如果要用到翻页,则其第一页包含的网格编号为{00,10,20,30},依此类推。
至于每页数据条数不固定的问题,可以在客户端做缓存层解决。
例如,参见图7,翻页优化前,查询的第一页数据大致所在的网格范围为编号00、01、02、03的网格,参见图8,翻页优化后,查询的第一页数据所在的网格范围为编号00、10、20、30的网格,由此可见,翻页优化后,均匀化地图撒点。
综上所述,参见图9,本发明实施例提供的一种空间点数据的处理方法,包括:
S101、根据已知空间点的坐标所处的范围,确定网格范围,并根据已知空间点的数量,确定网格级别,根据所述网格范围和网格级别生成网格系统,该网格系统中包括多个网格;
S102、针对每一已知空间点的坐标,根据该已知空间点的坐标,确定在所述网格系统中该已知空间点对应的网格编号;
S103、将每一已知空间点的数据存储到在所述网格系统中对应的网格编号的网格中。
较佳地,该方法还包括:
根据查询范围,确定在所述网格系统中需要查询的网格;
对所述需要查询的网格中存储的空间点的数据进行查询,确定查询结果。
较佳地,根据查询范围,确定在所述网格系统中需要查询的网格,具体包括:根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
对所述需要查询的网格中存储的空间点的数据进行查询,确定查询结果,具体包括:将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格之前,该方法还包括:根据查询范围的大小,将所述网格系统的级别进行简化,使得所述网格系统中的网络数量减少;
所述根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,具体包括:根据查询范围,确定在简化后的网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
所述将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内 存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果,具体包括:将在简化后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在简化后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格之后,该方法还包括:根据所述确定的在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,对所述网格系统的网格进行合并,并确定合并后的网格的编号;
所述将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果,具体包括:将在合并后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在合并后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,对所述需要查询的网格中存储的空间点的数据进行查询的过程中,每次查询一页数据,每页数据包括多个非连续编号的网格中存储的空间点的数据。
参见图10,本发明实施例提供的一种空间点数据的处理装置,包括:
第一单元11,用于根据已知空间点的坐标所处的范围,确定网格范围,并根据已知空间点的数量,确定网格级别,根据所述网格范围和网格级别生成网格系统,该网格系统中包括多个网格;
第二单元12,用于针对每一已知空间点的坐标,根据该已知空间点的坐标,确定在所述网格系统中该已知空间点对应的网格编号;
第三单元13,用于将每一已知空间点的数据存储到在所述网格系统中对应 的网格编号的网格中。
较佳地,该装置还包括第四单元,用于:
根据查询范围,确定在所述网格系统中需要查询的网格;
对所述需要查询的网格中存储的空间点的数据进行查询,确定查询结果。
较佳地,所述第四单元具体用于:
根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
将在所述网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在所述网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述第四单元具体用于:
根据查询范围的大小,将所述网格系统的级别进行简化,使得所述网格系统中的网络数量减少;
根据查询范围,确定在简化后的网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
将在简化后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在简化后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述第四单元具体用于:
根据查询范围,确定在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格;
根据所述确定的在所述网格系统中与该查询范围相交的网格和该查询范围完全覆盖的网格,对所述网格系统的网格进行合并,并确定合并后的网格的编号;
将在合并后的网格系统中该查询范围完全覆盖的网格内存储的空间点的数据作为查询结果;以及,对于在合并后的网格系统中与该查询范围相交的网格内存储的空间点的数据,滤除不属于所述查询范围的空间点的数据,将剩余的空间点的数据作为查询结果。
较佳地,所述第四单元对所述需要查询的网格中存储的空间点的数据进行查询的过程中,每次查询一页数据,每页数据包括多个非连续编号的网格中存储的空间点的数据。
以上各个所述单元,均可以由处理器等实体装置实现其功能。
本发明实施例提供的技术方案中,根据网格编号存储空间点数据,是静态划分网格编号存储空间点数据的方式,区别于以往的根据网格中点数量,动态划分四叉树网格的方式。网格在查询过程中的预简化策略。根据查询范围的大小,动态提升(简化)网格编号的等级,从而达到简化查询实现,提高查询效率的目的。翻页策略中,均匀化地图撒点。利用预简化策略,将被简化的后n位编号作为页号的方式,作为后缀添加到网格编号中,获取指定页号的数据的方式。关于范围查询网格预简化,此种方式可以简化网格编号集合的计算和内存占用,也可减少读取数据阶段随机读的次数。假定简化的级别数为n,则读取数据阶段,将原有的4^n次随机读,转换为1次连续读(1次连续读的开销略大于两次随机读)。网格合并策略,进一步降低读取时的开销。翻页策略相对原有的四叉树方案,简化了方案实现的难度,既达到了减少单次数据传输、又达到了打散数据的目的。同时保证了翻页的稳定性(每次分页,页面数量、每页结果均是相同的)。
本发明提供的方案适用于需要高速存储、范围查询海量数据、及随机获取查询范围内的少量点的场景;而现有技术中动态划分四叉树的方案,适用于随机获取查询范围内的少量点,及需要精确获取点周边数据的场景。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结 合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!