基于后验证的辅助控制方法及系统与流程
本发明涉及的是一种语义识别领域的技术,具体是一种基于后验证的辅助控制方法及系统。
背景技术:
通过语义识别使得人工智能能够更好地理解人类,并最终对硬件工作状态进行调整是目前工业自动化控制领域面临的主要难题。现有的语义识别主要基于自然语言理解,通常采用语法+关键词列表的正则表达式检索方法。比如:语法为:我要吃<slot1>;而关键词,即<slot1>为具体食物名称、饭店名称等。一般的识别方法在符合语法的情况下,将关键词“吃”后的所有字符与关键词列表进行逐一匹配,当存在匹配结果时才会进行后续操作。
虽然现有的语音/语义识别技术基本实现了识别用户语音内容中最关键信息,即意图。但对于附加与意图上的细节参数则很难精细识别。一旦知识库中没有记录过类似的关键词,则系统将会反馈报错、不知道用户在说什么或直接在网上搜索该字符作为后续操作。虽然可以通过不断对知识库进行更新以增加识别率,但自然语言的发展和理解速度发展则更快,因此而带来的不足非常明显:
1、识别同步性和占用资源两者之间难以兼顾:随着事物更新发展,关键词列表将会变得非常庞大。维护不同语法的对应关键词列表将导致巨大的工作量和系统资源,从而降低识别性能;关键词列表的维护同步度不高则将导致对新的关键词无法识别;如增加模糊检索则将进一步导致资源的占用和用户体验的下降。
2、语法表述的规范性:用户必须严格按照系统预设的方式进行语法表述,口语化的输入、倒置、后置或强调句式很难被明确地识别出正确的语义。使得实际识别过程中对用户的知识表达水平较高,限制了语音技术的普及。
3、存在歧义或匹配无结果时无法后续智能处理:当多个不同领域采用相同的语法时,关键词的理解上很容易由于歧义产生冲突。如同一个句型在多个领域都出现(如”我要听<slot>”会同时出现在音乐,电台,听书,课程,诗词等领域),那么这些领域有相同关键词的时候,从语义解析本身,他们之间是无法区分优先级的。如“我要听满江红”,“满江红”同时属于音乐,书,诗词。或者当关键词和语法本身产生歧义的时候,难以区分,如“我要听张三的歌”,当歌手的关键词里有“张三”,同时歌名的关键词里有“张三的歌”时,会同时匹配两个语法:我要听<slot1>的歌,我要听<slot2>。
综上,现有的识别技术虽然可以在一定程度上通过语法识别出用户的大致意图,但对于基于该意图的精确参数很难识别准确,识别的结果是直接将含有参数意义的内容判断为普通字符,使得用户输入的语义丢失。
技术实现要素:
本发明针对现有技术存在的上述不足,提出一种基于后验证的辅助控制方法及系统,在现有的语法检索基础上大幅度提高语义识别的准确度,通过模拟人类对语言的理解方式,将用户输入的口语化表达内容中所有可以提取的语义全部进行识别,能够显著提高识别率和用户体验。
本发明是通过以下技术方案实现的:
本发明涉及一种基于后验证的辅助控制方法,通过对原始输入进行按领域的语法模板匹配,得到至少一组领域信息及其对应的操作参数部分,然后对每一组所述领域信息对应的知识库对操作参数部分进行匹配,再对匹配结果进行后验证,将后验证优选的至少一组匹配结果通过中央处理单元进行操作,实现辅助控制。
所述的原始输入为多模态形式,包括影像、声音或其数字格式的文件、通过外部设备输入的字符串等,优选为声音或其数字格式的文件或其与字符串的组合。
所述的原始输入优选经类型判断和对应的预处理,以得到能够进行逻辑操作的字符,即待解析语句字符串。
所述的预处理,采用但不限于将原始输入中的声音或其数字格式统一调整为能够被现有的语音识别技术识别出的格式,并经特征提取后与模型匹配,得到对应的待解析语句字符串。
所述的特征,优选采用MFCC(Mel‐frequency Cepstrum Coefficients,梅尔倒谱系数)。
所述的模型,包括但不限于:隐马尔可夫模型、混合高斯模型、深度神经网络模型、卷积神经网络模型等。
所述的语法模板匹配是指:以常见句式中所包含的关键字生成对应的正则表达式,以DFA(确定性有穷自动机)方式进行匹配,匹配后根据关键字将原始输入进行切分,并得到领域信息和由至少一个子参数体组成的操作参数部分。
所述的控制对象包括但不限于:通过网络无线或有线连接的能够接收外部指令和参数的任何设备,优选为普通终端的外部设备,如音响、显示器、GPS定位模块、NFC模块、具有可调控制器的家用电器、载具等;也可以是普通终端的内部模块或程序,如导航模块、闹钟模块等。
对应地,上述领域信息中包含有用户选择的具体某一个确定的控制对象;操作参数部分则是针对该控制对象的具体调整要求,如将音响音量调大/小,将显示器调亮/暗,开启导航软 件并设置目的地进行导航等。
每一个所述的领域信息对应至少一个正则表达式,不同的领域信息的正则表达式可以相同。
所述的后验证是指:根据所述正则表达式确定的操作参数部分,在领域信息对应的实体知识库和/或行为知识库中进行匹配,再根据匹配结果对应的分值计算出后验证结果评价指标。本发明通过以至少一个语法匹配的方式得到至少一个原始输入的语义判断后,再通过前述后验证的方法评估多个语义判断中的最接近结果。
优选地,所述的领域信息包括子参数体的类型,即实体知识库类型或行为知识库类型。
优选地,所述的领域信息进一步包括其所对应的正则表达式的用于计算出后验证结果评价指标的分值。
优选地,所述的匹配,预先对操作参数进行预处理后再进行匹配。
所述的预处理包括但不限于:对操作参数部分进行字符增加冗余、删除首字符、删除尾字符、字符重排、拼音前后鼻音调整或方言拼音替换等,优选地,预处理所采用的操作与领域信息子参数体的类型相关,即根据自参数体的类型进行对应的预处理操作。
所述的匹配,将自参数体与实体知识库和/或行为知识库进行匹配,并得到匹配结果分值。
所述的实体知识库包括名词性的单词,其包括但不限于:通讯录或网络常见的人名、地名、时间、商品名等等。
所述的实体知识库通过全文搜索引擎、关键词索引的方式实现匹配,并对匹配相似度进行赋值。
所述的关键词索引优选包括所有关键词的拼音索引。
所述的行为知识库包括动词性的单词及其短句,该行为知识库通过建立特征向量并比较其与子参数体之间的欧氏距离或通过全文搜索引擎、关键词索引的方式实现匹配。
所述的实体知识库和/或行为知识库优选配置有程度知识库,该程度知识库包括形容词或副词性的单词,其包括但不限于:根据名词性的单词的种类或参数的描述、根据动词性的单词及其短句的程度的描述等。
所述的程度知识库通过全文搜索引擎、关键词索引的方式实现匹配,并对匹配相似度进行赋值。
所述的后验证结果评价指标采用但不限于:将上述所有分值累加或加权累加所得到的结果。
所述的加权优选采用程度知识库的对应赋值实现。
所述的后验证优选是指:将至少一组领域信息及其对应的操作参数部分的后验证结果评价指标与预设值进行比较、或将多组领域信息及其对应的操作参数部分的后验证结果评价指标之间进行比较,或其组合。
优选地,所述的预设值在每次后验证后进行更新。
进一步优选地,所述的预设值对应不同的领域信息各不相同。
例如:在歌曲知识库中,以切分词为“的”,当外部对象为“张学友的歌”时,则提取到的外部子对象为“张学友”,后验证方法将把“张学友的歌”和"张学友"均作为歌曲名,同时将张学友作为歌手名,在歌曲知识库中进行匹配,则“张学友”作为歌手名的返回结果数量较多,以“张学友”是歌手名作为操作参数。
所述的中央处理单元辅助控制,包括但不限于:当存在一条匹配结果时将其生成辅助控制指令输出至对应的控制对象,当存在两条以上匹配结果时向用户进行进一步问答以筛选其一后再生成辅助控制指令,或当没有匹配结果时调整语法模板或对知识库进行更新等。
本发明还涉及一种基于后验证的辅助控制系统,包括:
语法匹配单元,用于将原始输入与不同领域的语法模板进行匹配并得到对应原始输入的领域信息和操作参数部分;
知识库组,用于将操作参数部分在对应领域信息的知识库中进行匹配;
后验证单元,用于将知识库的匹配结果进行加权计算,以及
控制器,用于对至少一个加权计算结果进行判断并生成完整语义。
所述的语法匹配单元包括:
内置语法模板的语法库,以及
用于进行正则匹配的匹配单元,根据原始输入与所述语法模板进行正则匹配,并将匹配语法模板后得到的匹配结果,即领域信息和操作参数部分输出至知识库。
所述的知识库组包括若干个对应不同领域的实体知识库、行为知识库以及程度知识库。
所述的实体知识库中内置汉字、拼音以及方言的索引。
所述的行为知识库中内置欧氏距离计算单元,通过计算操作参数部分与匹配模板特征向量之间的欧氏距离并输出距离最短的匹配模板。
技术效果
与现有技术相比,本发明能够纠正语音识别时由于噪声带来的识别错误,并能够在语义识别过程中在发生字面名称不在知识库中的情况下理解该字面的语义,从而有效消除歧义。
附图说明
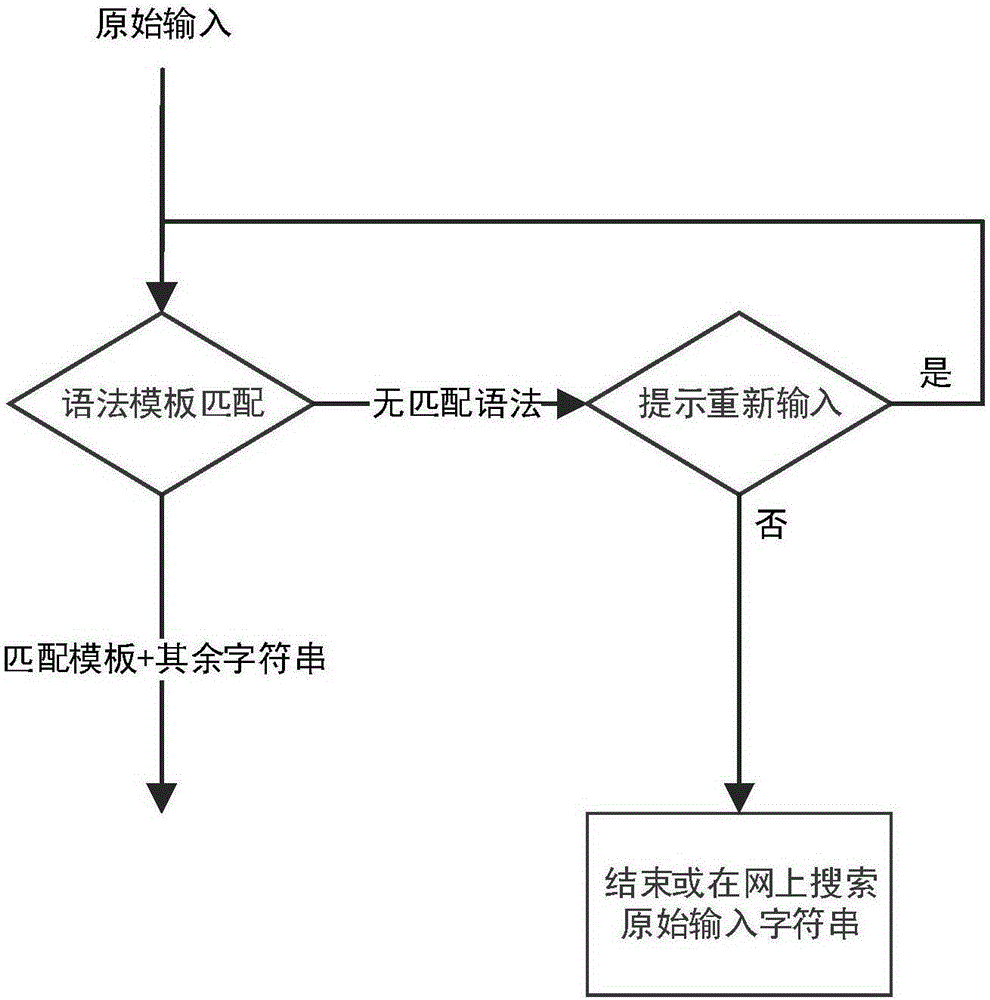
图1为现有技术示意图;
图2为本发明后验证方法实施例1示意图;
图3为本发明后验证方法实施例2示意图;
图4为本发明后验证方法实施例3示意图;
图5为本发明系统示意图;
图6为指令采集设备示意图;
图7为语法匹配单元示意图;
图中:100指令采集设备、101影像采集设备、102触摸设备、103音频采集设备、104其他外部设备、105指令类型识别单元、106预处理单元、200辅助控制指令生成系统、201控制器、202语法匹配单元、2021匹配单元、2022语法库、203后验证单元、204知识库、300中央处理单元。
具体实施方式
如图1所示,为现有大部分语义解析示意图。如图可见,现有技术通过正则表达式的语法模板对原始输入进行关键词切分,当无法切分出关键词时一般只能提示不明白用户的输入并提示重新输入,或完成操作并将用户原始输入作为字符串在浏览器中的搜索引擎中进行搜索并返回结果,这样的反馈对用户的认知水平要求较高,且需要对语法模板定期进行更新和添加。
另一方面,当该技术通过上述方式切分到关键词,则常见的方式是直接将关键词以外的字符串部分作为备注,而不去进一步分析其语义。例如使用闹钟提醒时,当匹配到关键词为“提醒”或“设置闹钟”时,则自动将关键词前或后的字符串进行时间日期格式判断,一旦判断成功,则将原始输入的其他部分,即关键词后或前的内容作为字符串的备注内容设置提醒。
这样的匹配方式对于较为简单的闹钟程序或家用设备而言勉强可行,但如果关键词的语音由于噪音导致识别错误时,该技术不具有任何可以容错或纠错的机制;或当原始输入部分除了意图外的内容中包含了较为重要的信息时,简单的程序将直接判定其为字符串而不进行进一步的解析,使得语义被丢失或识别不全。随着科技的发展,越来越多的软硬件具备各种可调的接口参数或自定义的模块功能,这势必将导致用户输入的语句复杂度和待解析的语义数量将大幅度提升。
实施例1
如图2所示,为本发明具有后验证的辅助控制方法的实施,具体包括以下步骤:
1)本实施例对原始输入进行语法模板匹配的过程中,记录至少一个配准语法模板的领域信息;例如,当原始输入为:我要听你讲故事。则:
A.以“我要听|<>”作为语法模板进行匹配,可以配准得到以音频播放器作为领域信息的结果;或者
B.以“听你讲|<>|故事”作为语法模板进行匹配,可以直接配准得到以音频播放器播放故事集为领域信息的结果。
2)然后将配准后得到的操作参数部分在上述领域信息所对应的实体知识库中进行匹配,其中的操作参数部分,即语法模板中的“<>”,对应原始输入的“你讲故事”。在音频播放器对应的实体知识库,包括歌曲名、歌手名、专辑名组成的全文搜索引擎中进行拼音模糊搜索。
3)将所得的领域信息的分值与实体知识库的搜索结果分值相乘,如步骤1.A中没有匹配到“你讲故事”这首歌,则分值为零,相应后验证结果为零,而步骤1.B没有操作参数部分,则分值为1,相应后验证结果大于方案A的解析。
4)根据步骤3)的结果生成相应辅助控制指令启动播放器播放故事集中任一一个文件。
在其他情况下,可能根据不同的原始输入,在不同的语法模板下均能够得到一个或多个后验证结果,例如:原始输入为:来段西游记。根据上述方式进行后验证结果时,可能同时出现专辑名为“西游记”的歌曲和对应的音频播放器,以及名称为西游记的视频和视频播放器,此时将以“西游记”在音频播放器和视频播放器分别对应的不同实体知识库中的分值高低影响最终后验证结果。
当后验证结果较为近似时,最简单的方式是直接选择后验证结果最高的领域信息和语义生成辅助控制指令,但在知识库建立初期,或在控制对象较为复杂的情况下,也可以通过补充输入的方式或通过检索历史偏好数据的方式进一步选择出用于生成辅助控制指令的后验证结果。比如:等待用于进一步输入语音信息、等待用户从候选结果中挑选一个等等。
在另一种情况下,如原始输入为:我要听张三的歌。那么在音频播放器对应的实体知识库中会返回两条匹配的结果,即歌名为张三的歌以及歌手为张三。因为实体知识库中的分值将依照网络搜索关键词热度或其他依据而不同,故“张三的歌”和歌手为“张三”的后验证结果将会不同,由此可以进一步采用上述方式进行后续决策。
在另一种情况下,原始输入可能由于噪音或方言导致识别错误,如识别的结果为:我要听清华祠,而用户实际希望进行辅助控制的是“我要听青花瓷”,那么通过实体知识库中的全文拼音索引可以得到后验证结果较高的歌曲(名称为青花瓷),而地名清华祠在音频播放器对应的实体知识库中可能并没有匹配结果,这样可以将后验证结果较高的辅助控制指令以较为明显的方式显示给用户进行二选一。如后续决策依旧选择“清华祠”则将启动如图3所示的更新步骤,在互联网浏览器中搜索含有“清华祠”的歌曲,并根据搜索结果对音频播放器对应的实体知识库进行更新。
实施例2
在一些更为复杂的场合下,原始输入的语义包含了多个种类且数量众多。本实施例则根 据图3给出了一种辅助控制指令的生成方法,在实施例1的基础上进一步判断原始输入中各个部分的具体语义。
例如,原始输入为:明天上午十点到十二点和小王在徐家汇吃饭,提前15分钟提醒我。
1)通过语法模板“<>|提醒|<>”匹配得到领域信息为闹钟或提醒程序,并根据正则表达式的方式得到对应领域信息的参数为“提前15分钟”,子参数体为“明天上午十点到十二点和小王在徐家汇吃饭”
2)针对子参数体“明天上午十点到十二点和小王在徐家汇吃饭”采用行为知识库,与其中每个特征向量进行欧氏距离的计算和匹配,得到其中欧氏距离最短的特征向量对应的行为短语为“…和…在…吃饭”。
3)对步骤2中的子参数体采用匹配特征向量进一步划分,得到子参数体“明天上午十点到十二点”、“小王”、“徐家汇”,分别采用实体知识库对上述三个子参数体进行匹配,得到对应的一个或多个匹配结果。
4)根据步骤3得到的匹配结果采用与实施例1相同的方式进行后验证,从而实现将原始输入中的所有语义均通过本方法匹配出至少一个行为以及至少一个实体。本领域技术人员通过后续的信息处理、计算则能够生成完全符合原始输入意图的辅助控制指令。相比之下现有的大部分技术只能讲本实施例中的子参数体“明天上午十点到十二点和小王在徐家汇吃饭”判断为一字符串,而其中的语义则被完全丢弃。
实施例3
在某些特定情况下,原始输入将进一步包含程度方面的副词,如“很”、“一定”、“有可能”等本身不具有特定行为或实体描述,但对其修饰的对象存在优先级或分类方面的调整。
由于这样的程度描述语义数量有限,因此本实施例则针对实体知识库库和行为知识库设置对应的程度知识库,当实体知识库或行为知识库匹配不到结果时,采用程度知识库进行匹配,并且进一步对程度知识库中的各个匹配结果赋予定值,作为行为知识库或实体知识库匹配结果的加权由于后验证计算。
实施例4
在某些情况下,原始输入经过多次语法模板匹配依旧不能得到大于零的后验证结果时,可以对语法模板和/或知识库进行更新,添加原始输入。这种情况在语法模板数量较少、某些新兴领域的情况下比较常见。
如图5~图8所示,即为一种能够实现上述方法的具体装置,其中含有:指令采集设备100、辅助控制指令生成系统200和中央处理单元300。
如图6所示,所述的指令采集设备100可以是包括了影像采集设备101、触摸设备102、 音频采集设备103、其他常见的工业领域的外部输入设备104中的一种或多种的并联。
当存在多种外部设备并联的情况时,指令采集设备100中进一步需要设置指令类型识别单元105,用于判断不同类型的外部输入并相应打包后输出至辅助控制指令生成系统200。
当存在音频采集设备103时,指令采集设备100中进一步设置预处理单元106,用于对音频模拟信号进行必要的数字化处理和语音识别,以便获得字符化的数字信息。
所述的辅助控制指令生成系统200包括:控制器201、语法匹配单元202、后验证单元203和知识库组204。
所述的控制器201用于将来自指令采集设备100的原始输入交由语法匹配单元202进行语法模板匹配,并将相应的子参数体和领域信息输出至知识库组204进行匹配。
如图7所示,所述的语法匹配单元202包括:用于进行正则匹配的匹配单元2021以及提供语法模板的语法库2022。
所述的语法库2022在特定情况下可以接收来自后台的语法模板更新调整。
所述的知识库组204包括实体知识库、行为知识库、程度知识库等,根据实际需要可以进一步针对某领域单独设置对应的知识库以提高该领域的语义识别。
所述的后验证单元203根据不同知识库反馈得到的语义加权计算得到后验证结果并反馈至控制器201。由控制器201判断得出后验证结果最高的一组语义并交由中央处理单元300生成辅助控制指令。
本实施例中的辅助控制指令生成系统200可以全部或部分通过硬件实现,且辅助控制指令生成系统200并不局限于同一设备内部。
所述的控制器201可以通过嵌入式芯片、移动终端处理器或台式计算机处理器实现。
所述的知识库组204可以通过带有各种匹配算法的云端服务器实现,该知识库组204与控制器201、语法匹配单元202以及后验证单元203之间可以通过有线或无线的网络相连。
所述的中央处理单元300可以通过网络与上述知识库组204相连以进行对应知识库的更新。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 还没有人留言评论。精彩留言会获得点赞!