电路自动综合方法、相关的设备和计算机程序与流程
本发明涉及电路的自动综合方法,包括把软件程序编译为借助管道互连的规则进程网络,根据该网络,每个管道是可寻址的物理存储器,所述进程中的每个进程,在与该进程相关联的迭代域的每次迭代过程中,从一个管道中施加数据的至少一次读取和/或在一个管道中施加数据的写入,并且调度函数针对每个进程的每个迭代值提供在执行位置暂时调度集合中选择的进程的执行位置。
背景技术:
这样的电路综合方法,或HLS(high-level synthesis)被用于根据要由电路执行的计算的算术描述(高级,诸如C或Matlab、Alpha语言)来自动生成(或编译)电路块(参见工具,诸如SpecC、HardwareC、HandelC、BashC、TransmogrifierC、CyberC、CatapultC)。所涉及的算法是各种各样的。例如信号处理算法。
电路必须尽可能有效同时最好地使用可用资源。所生成的电路块的性能因此尤其是通过在输入端提供的数据处理速度、能量消耗、占用硅的表面积、FPGA上的LUT单元、存储器读取等测量的。
性能的提高是通过把要执行的处理划分为并行实现的任务来获得的。大部分时间,任务不完全独立,并且必须彼此之间交流(写/读)中间结果,这尤其提出任务之间的同步的问题。
分为并行任务并且产生同步需要精细粒度计算的调度,也就是说算法操作的执行顺序和安排。为了准确,调度应该遵守操作之间的数据依赖性,以便确保例如数据在被读取之前产生。
现有大多数方法基于CFDG(控制/数据流图形)类型的图示,其表示句法结构之间的依赖性,也就是说在操作包之间的依赖性,这导致依赖性的过分粗略近似使得不能发现所关注的调度。
进程网络是自然表示计算的并行性的执行模型。为此,模型并用于表示并行系统,并且把并行系统到进程网络的转换允许研究、分析并测量与并行性(调度、负载平衡、分配、检查点、消耗等)相关的有问题的区别。
进程网络还构成用于电路自动综合设备的自然中间图示,其中“Front-End”块提取并行性并且产生进程网络,“后端”块朝向目标架构编译进程网络。
尽管对于前端方面(管道构建,布置/布线)实现了性能方面的众多进步,后端方面仍然是很初级的。
因此希望还改进自动生成的电路块的性能。
技术实现要素:
为此,根据第一方面,本发明提出前述类型的电路自动综合方法,其特征在于,该方法包括以下步骤:
准许称作生产者进程的唯一进程写数据到管道中,并且准许称作消费者进程的唯一进程读取所述管道中的数据;以及同步单元与所述管道相关联,并且使得在管道的生产者进程进行的每次新迭代的发起之前预先收集生产者进程的所述新迭代的值,并且在管道的消费者进程进行的每次新迭代的发起之前预先收集消费者进程的迭代的值;在分别收集到生产者进程和消费者进程的新迭代的值之后,所述同步单元根据对按照生产者进程和消费者进程各自的被收集的新迭代的值而确定的执行位置以及按照生产者进程和消费者进程各自的被收集的上一次迭代值而确定的执行位置进行的比较,来准许或中止所述生产者进程和消费者进程各自的所述新迭代的实施。
这样的方法允许快速并自动生成电路,该电路在计算速度和电路占用体积方面提供较高性能。
在实施方式中,根据本发明的该电路自动综合方法还包括一个或多个以下特征:
-所述同步单元使得通过在收集所述生产者进程的新迭代的值之后实施以下步骤来操控所述管道的生产者进程的运行:
-同步单元比较所收集值的新执行位置与收集的消费者进程的上一个迭代值的执行位置;以及
-如果该新迭代的执行位置在消费者进程的被收集的上一个迭代值的执行位置之后,则所述同步单元中止由生产者进程实施该新迭代,该中止被同步单元保持直到对消费者进程的未来迭代值的收集使得:该未来迭代值的执行位置在消费者进程的新迭代的所述执行位置之后。
-所述同步单元使得通过在收集所述消费者进程的新迭代的值之后实施以下步骤来操控所述管道的消费者进程的运行:
-同步单元从生产者进程的迭代值的执行位置确定执行位置,该执行位置导致应当在该新迭代时被消费者进程读取的数据被写入所述管道(c)中;以及
-如果所确定的执行位置在生产者进程的被收集的上一个迭代值的执行位置之后或相等,则所述同步单元中止由消费者进程实施该新迭代,该中止被同步单元保持直到对生产者进程的未来迭代值的收集使得:该未来迭代值的执行位置严格领先所确定的执行位置。
-每个管道的消费者进程或生产者进程,在所述进程的前次迭代结束之后并且在继前次迭代之后的新迭代的启动之前,向管道的同步单元给出进程的新迭代的迭代值,并且根据指示中止或准许的监视单元的操纵命令来实施进程的该新迭代;
-管道的消费者进程,在所述进程的前次迭代结束之后并且在继前次迭代之后的新迭代的启动之前,还向管道的同步单元给出生产者进程的导致应当在该新迭代时被消费者进程读取的数据被写入所述管道中的所述迭代值。
根据第二方面,本发明提出一种电路自动综合设备,能够通过生成借助于管道而互连的规则进程的网络来对软件程序进行编译,其中每个管道是能被寻址的物理存储器,所述进程中的每个进程能够在与该进程相关联的迭代域的每次迭代时应用在管道中的数据的至少一次读取和/或数据到管道中的写入,并且针对每个进程的每个迭代值,调度函数能够提供在执行位置时间调度集中选择的进程的执行位置;所述电路综合设备的特征在于:能够在所述编译过程中,生成以下内容并且将其与所述管道中的每个管道相关联:
称作生产者进程的唯一进程,其被准许写数据到管道中,以及称作消费者进程的唯一进程,其被准许读取所述管道中的数据;以及同步单元,与所述管道相关联,并且能够在管道的生产者进程进行的每次新迭代的发起之前预先收集生产者进程的所述新迭代的值,并且在管道的消费者进程进行的每次新迭代的发起之前预先收集消费者进程的迭代的值;在分别收集到生产者进程和消费者进程的新迭代的值之后,所述同步单元能够根据对按照生产者进程和消费者进程各自的被收集的新迭代的值而确定的执行位置以及按照生产者进程和消费者进程各自的被收集的上一次迭代值而确定的执行位置进行的比较,来准许或中止所述生产者进程和消费者进程各自的所述新迭代的实施。
根据第三方面,本发明提出一种综合电路,例如在实施根据本发明的第一方面的电路自动综合方法之后获得的综合电路,包括借助于管道而互连的规则进程的网络,其中每个管道是能被寻址的物理存储器,所述进程中的每个进程能够在与该进程相关联的迭代域的每次迭代时应用在管道中的数据的至少一次读取和/或数据到管道中的写入,并且针对每个进程的每个迭代值,调度函数能够提供在执行位置时间调度集中选择的进程的执行位置;
所述电路的特征在于包括:
称作生产者进程的唯一进程,与每个管道相关联并且被准许写数据到管道中,以及称作消费者进程的唯一进程,与每个管道相关联并且被准许读取所述管道中的数据;以及
同步单元,与所述管道相关联,并且能够在管道的生产者进程进行的每次新迭代的发起之前预先收集生产者进程的所述新迭代的值,并且在管道的消费者进程进行的每次新迭代的发起之前预先收集消费者进程的迭代的值;在分别收集到生产者进程和消费者进程的新迭代的值之后,所述同步单元能够根据对按照生产者进程和消费者进程各自的被收集的新迭代的值而确定的执行位置以及按照生产者进程和消费者进程各自的被收集的上一次迭代值而确定的执行位置进行的比较,来准许或中止所述生产者进程和消费者进程各自的所述新迭代的实施。
附图说明
参照附图,通过阅读仅以示例方式提供的以下描述,本发明的这些特征和优点变得清楚,在附图中:
-图1示出本发明的实施方式的电路自动综合设备;
-图2示出命名为Prog的程序的迭代和依赖性的域;
-图3示出Prog程序的执行顺序;
-图4是在执行prog程序的电路块的自动生成中实施的处理器、输入复用器、输出复用器、管道的示图;
-图5是示出Prog程序的两个处理器、这两个处理器之间的管道、和与管道相关联的同步单元的图。
具体实施方式
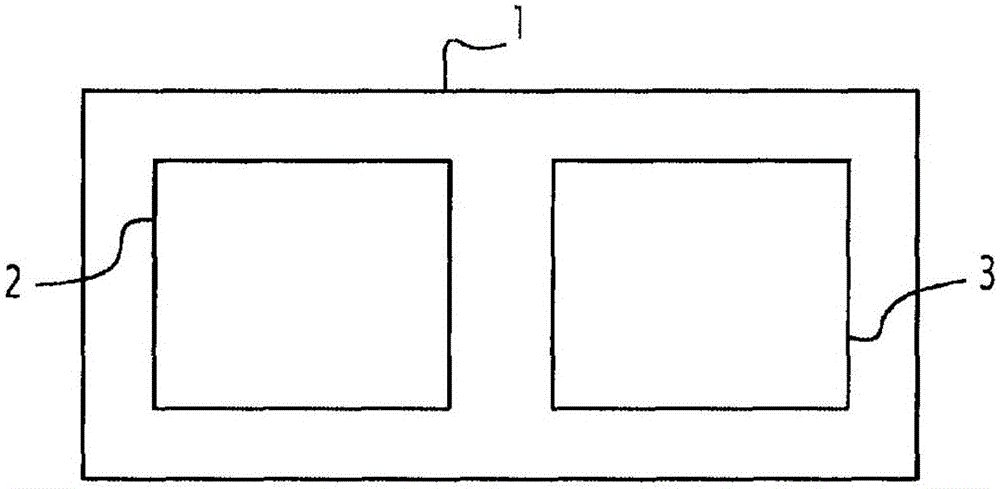
图1是本发明的实施方式中的高级电路自动综合设备1的图。该设备1包括称为“前端”的块2和称为“后端”的块3。
“前端”块2分析在设备1的输入端提供的程序的算法描述以便从中提取并行性并且产生进程网络作为对应电路的中间图示。
“后端”块3把由“前端”块2产生的电路的中间图示转换为物理电路。
下面现回顾在根据本发明的高级电路自动综合设备并且在“前端”块2中使用的概念和处理。
概念和处理
多面体模型
多面体模型是要静态控制的计算机程序的分析和优化工具。要静态控制的程序仅操纵静态表和简单类型的变量(不是指针),并且因此控制被限制为“if”和“for”循环。主要特征是表索引函数,“if”测试和循环的边界是包含性的“for”循环的计数器的仿射函数。
赋值S的迭代矢量是由包括赋值S的循环的计数器形成。执行请求被称为运算。运算是多面体分析的基础单元。赋值的迭代域是在执行期间所有迭代值的集合。在这些约束(“for”循环,“if”,仿射约束)下,赋值的迭代域确切地是凸多面体,其形状不依赖于分配输入。然后可以静态计算,并且应用各种多面体运算(几何运算、线性优化、计算等)以便构建程序的静态分析和转换。
下面,在每次运算W=f(R1,...,Rn)中区分读取(R1,……,Rn)和写入(W)。对于要静态控制的程序P,把Ω(P)标注为如此得到的基本运算的集合。pseq是关于的顺序执行的阶。约定:运算的读取在写入之前执行:最后,把M(P)标注为由每个基本运算XEΩ(P)存取的存储器位置的集合。把μ(X)标注为由X,μ:Ω(P)->M(P)存取(读或写)的位置。
为便于描述,下文中,称基本运算为运算。
依赖性,调度
当X在Y之前执行时并且当X和Y存取相同的存储器位置(μ(X)=μ(Y))时,在这两个运算X,Y∈Ω(P)之间存在依赖性X->Y。根据X和Y的性质(读或写),说说流依赖性(W然后R)、反依赖性(R然后W)、或输出依赖性(W然后W)。反依赖性和输出依赖性仅表示对存储器的存取冲突并且可以通过修改存储器的使用来消除。事实上,仅考虑流依赖性,其表示由程序实施的计算。更确切地,我们关注流依赖性W->R,其中W是在R之前的μ(R)的最后一次写入,换句话说,W定义由R读取的值。该W是唯一的,被称作R的源。我们把它标识为s(R)。
操作符∧表示“和”。
调度是应用θ,其把执行时间与程序的每次运算相关联,其属于总体安排的集合,θ:Ω(P)->(T,<<)。
大多数程序变换(优化等)可以与调度函数写在一起。多面体模型提供用于计算仿射调度的技术,其中<<表示词典式的顺序。如果调度遵守依赖性因果关系,则它是正确的,因果关系即如果在两个运算X、Y之间存在X->Y依赖性即X的执行顺序先于Y的执行顺序。由θ引起的执行顺序标注为通过在必要时在与上述的s(R)相关的关系中用替换定义Sθ。
作为示例,考虑由高级语言表示的以下Prog程序:
该Prog程序是执行迭代二项式松弛计算的要静态控制的Jacobi1D程序。表的边界被初始化(分配I1和I2),然后,迭代计算三个格子(分配S和T)的每个窗口上的平均值。最后,收集结果(R分配)。
分配的迭代域在图2给出。分配域I1、I2和R缩减为一点。分配域S和T是矩形,它们在此重叠以便于表示。黑点表示S的迭代,并且叉号表示T的迭代。
该程序包括所有类型的依赖性,图中的箭头示出若干示例。
-流依赖性:(I1,)->(S,t,),(I2,)->(S,t,N-2),(S,t,i)->(T,t,i),
(T,t,i)->(S,t+1,i-1),(T,t,i)->(S,t+1,i),(T,t,i)->(S,t+1,i+1),(T,K-1,1)->>(R,)。
-反依赖性(虚线):
(S,t,i)->(T,t,i-1),(S,t,i)->(T,t,i),(S,t,i)->(T,t,i+1),(T,t,i)->(S,t+1,i)
-输出依赖性:(S,t,i)->(S,t+1,i)(T,T-1,1)->(R,),所有依赖性被包括在流依赖性中,因此不被示出。
有效调度是θ(|1,)=θ(|2,)=(0),θ(S,t,i)=(1,2t+i,t,0),θ(T,t,i)=(1,2t+i+1,t,1),θ(R,)=(2)。
对应的执行顺序如下。首先在相同时间执行I1和I2。然后,间隔地执行示例S和T,如图所示。最后,执行R。
在满足所有依赖性的意义上,该调度是有效的。例如,遵守第一反依赖性,因为θ(S,t,i)=(1,2t+i,t,0)<<θ(T,t,i-1)=(1,2t+i-1+1,t,1)=(1,2t+i,t,1)。
存储器分配,唯一指定
存储器分配是应用σ,应用σ把存储器位置的新集合M’中的交替位置σ(m)与由P寻址的每个存储器位置m∈M(P)相关联,σ:M(P)->M’。在确定调度θ的情况下,如果存在W1、W2、R1、R2∈M(P),其中μ(W1)=μ(R1)=m,μ(W2)=μ(R2)=m’,θ(W1)<<(R2),以及θ(W2)<<θ(R1),则两个存储器位置m和m’∈M(P)θ互相干扰。然后注意m><θm′。存储器分配σ是θ正确的,如果的话。
变换的程序完全由以下数据描述:程序P的运算Ω(P),有效调度θ,以及θ正确分配σ:(Ω(P),θ,σ)。初始程序可以写为(Ω(P),θseq,Id),并且获得计算的等价物:(Ω(P),θsep,Id)=(Ω(P),θ,σ),ID是数据的初始分配。
如果每个写入操作写不同的存储器位置,换句话说对于W1,W2εΩ(P),σ(W1)=σ(W2)=>W1=W2,则程序处于唯一指定。为了把程序过渡为唯一指定,我们使用源函数s来读取好位置。形成M’={W,W∈Ω(P)},并且对于Ω(P)的每次写入W我们定义σ(W)=W和对于每次读取我们定义σ(R)=s(R)。经变换的程序(Ω(P),θ,σ)因此是唯一指定。
作为示例,为了使程序Prog过渡为唯一指定,开始计算源函数s(.)。
-s((I1,):a[0])=a[0],运算(I1,)的读取a[0]的源在程序中不存在,因此保存a[0]的值作为输入。
-出于相同原因:s((I2,):a[N-1])=a[N-1]。
-对于(S,t,i)的读取,我们获得以下源函数:
在边界(i=1或i=N-2)上,源是通过初始化分配(I1或I2)给出的。当t=0时,源是表的初始值(如第一项)。此外,值是通过T的示例T((T,t-1,i-1)或(T,t-1,i)或(T,t-1,i+1))产生的。
通过向Prog程序应用唯一分配,就获得以唯一分配对Prog程序的读取值,其中读取值被完全扩展:
如此(在向S应用了分配(t,i)→(t%1,i%1)之前),程序不再包括流依赖性,并因此可被调度为θ(S,t,i)=(1,t+i,t,0),θ(T),t,i)=(1,t+i,t,1)。I1、I2和R的调度是不变的。
图3示出描述执行顺序。
各个格子的寿命的间隔S[t][i]是分开的,因此可以向S应用分配σ(S[t][i]=S′[t%1][i%1]。下面描述在不按照阶数θ的情况下在存储器分配之后程序Prog的变换阶段:
仅T维度是活跃的。分配函数(因此所用的存储器空间)依赖于所选的调度。
规则进程网络
规则进程网络R是以下元素的数据:
-P,进程集合。
-Cens={C1,...Cn},称作管道的物理存储器的集合,每个管道Cj是可寻址的缓存存储器,j=1到n。管道被分为段,被叫作格子。
-连接P×M×P的集合。
-对于每个管道C∈Cens,写入的历史w(C)=W1C,...,WpC和读取的历史R(C)=R1C,...,RpC是不变的。该约束意味着每个进程的执行轨迹是固定的。特别地,进程可以被但不仅被要静态控制的程序描述。
-写入和读取之间的优先顺序被扩展以表示对于每个管道的写入(wjc如果i<j)和读取如果i<j)的顺次顺序。下文中,把Ω(R)标记为由网络R执行的运算的集合Ω(R)=∪C∈Cens R(C)∪W(C)。
R运算的调度θobs是可观察的,如果其描述R运算的可能执行的话,换句话说,如果对于的话。
要静态控制的程序P的到规则进程网络的编译是以下元素的数据。
-放置
-分配管道
-同步集合,这确保对于每个进程或者的优先顺序以及遵守流依赖性
程序P的每次分配产生进程。
如果网络的所有结束的执行产生与P相同的计算,也就是如果完全在Ω(R)上定义的在R中的可观察的调度是P的正确调度,则网络就部分地等效于P。此外,如果网络被确保无互锁,可称作网络等效于P并且编译是正确的。
根据本发明的DNP进程网络和编译
根据本发明的电路自动综合方法和设备在由“前端”块2实施的处理中使用称为DPN(数据唤醒进程网络)的特定进程网络。
“前端”块2事实上在DPN进程网络中对在输入端提供的要静态控制的程序执行编译。
DPN是满足以下条件的规则进程网络:
-每个管道接纳一个唯一源进程(即,被准许在管道中写入的唯一进程)和一个唯一目的地进程(即,被准许在管道中读取的唯一进程,在实施方式中,甚至存在唯一目的地进程的单个输入端)。
-管道是读写阻塞存储器;即,这是随机读写存取存储器使得如果其中存在的内容未被读出则进程不能写入,并且相反地,如果要读取的内容未被写入则不能读出。
要静态控制的程序P向DPN的编译方案应该满足以下条件:
-对于管道的每次读取,在同一管道写入源:如果(P1,C,P2)是经由管道C从P1向P2的连接,则
-选择在Ω(R)上引起的顺序全面的正确调度θ,并且选择θ正确的分配σ。
-在每个进程上优先顺序是全面的,并且不在别处定义,
-对于每个写入W,最后一个写入释放由W写入的格子σ(W)。格子σ(W)然后应该重新写入以便能够被读取。
这样的编译是正确的:所得的DPN是与原程序P部分等效的并且从不产生互锁。。
简单的DPN包括三类进程:
-LD进程,读取进入中央存储器的数据。
-ST进程,把最终计算结果写入中央存储器中。
-正确地说,负责计算的Cal进程。
我们考虑要通过“前端”块2翻译为DPN的程序P和有效的调度θ。
为了容易构建LD和ST进程,“前端”块2,针对在远程主存储器的输入上读取到的每个数据表a,在程序P上增加以下操作系列:。
其中是Ω是表a的索引集合。
对于每个所写的表b,“前端”块2在程序上添加以下操作系列,其中d是任意矢量变量:
其中Ω是表b的索引的集合。
约定操作LDa在P的开始执行,操作STb在P的结束执行。因此,对于P的每个原始操作该属性可被多维调度指定。
“前端”块2通过在不同的进程上放置每个分配P={S1,...,Sn}来创建DPN网络,并且其中W、R1、…、Rn是通过分配实现的操作S:W=f(R1,...,Rn)。特别地,通过读取的表a创建进程LDa,通过读取的表b创建进程STb。这些进程到计算进程的连接被使用源功能s自然获得。
“前端”块2使每个进程具有以下部件:
-输入端口,由进程实施的分配读取基准。输入端口是复用器,负责收集好的管道中的基准的值。
-输出端口,发出由进程计算的值。输出端口是解复用器,其把由进程计算的值写入好的管道中。
为了构建DPN,“前端”块2计算这些部件并且分配每个管道(函数σ)就够了。
复用,解复用
当编译程序P时,“前端”块2针对每次读取计算源函数。
对于一个操作(T的迭代域):W=f(R1,...,Rn),从中读取R的源表现为以下形式:
其中Dk是闭合的凸多面体,uk是仿射函数,并且Tk是程序的分配。
对于使得S写入由基准R和T读取的表的每对分配(S,T),“前端”块2创建一个管道CS,T,R。如果D是S的迭代域,则CS,T,R是与D的维度dim D相等的维度的表。
这些管道然后被“前端”块2经由输入端口和输出端口通过如下方式进行连接到进程。
对于每次分配T∈{T1,...,Tn},对于T的每次读取R,对于每个子句源s((T,i)的(Sk,uk(i)):R),“前端”块2执行以下操作:
-在与R相对应的输入端添加到管道CSk,T,R的连接,并且添加复用子句其在当前迭代满足时控制管道CSk,T,R的格子的读取;
-在输出端添加向管道CSk,T,R的连接,并且添加复用子句其在当前迭代满足时控制计算出的值到管道CSk,T,R的在格子的写入。
根据构造,每个管道CSk,T,R具有唯一源(Sk)以及唯一目的地(T)的单个端口。
用于分配T的每个输入端口的复用器被调整以确定与分配的当前迭代矢量相对应并且提供恰当管道及其用于该迭代值的格子的复用子句,并且以读取该管道的该格子。
用于分配S的每个输出端口的解复用器被调整以确定与分配的当前迭代矢量相对应并且提供恰当管道及其用于该迭代值的格子的解复用子句,并且以将结果写入该管道的该格子。
随后,进程LD和ST被连接到DPN。实际上,当Tk是进程LDa时,涉及进程的输入值,并且由前端块2进行的编译自然的创建复用以便把好的值收集到由LDa写入的管道中。
此外,输出进程STb的复用器在其管道中收集用于b的每个格子的最终值。
举例而言,图4示出由前端块2进行的Prog程序的编译的结果。进程被具有黑线轮廓而无内部图案的盒体表示,进程LDa和ST(LOAD和STORE)由具有黑线轮廓并有内部图案的盒体表示。管道被具有细线轮廓并具有内部图案点的盒体表示,复用器和解复用器被细线轮廓表示而无内部图案。
每个计算进程具有一个或更多个输入端口。每个输入端口设置在其所专属的复用器(在图4上根据进程称作“MUX”、“MUX1”、“MUX2”、“MUX3”)和进程之间。
复用器确定哪个是用于当前迭代的恰当的管道以及管道的格子,并且读取恰当管道的该格子中的数据。
类似地,每个进程具有一个输出端口,其向解复用器传送当前的计算结果,在图4上称作“DEMUX”。解复用器确定哪个是用于当前迭代的恰当的管道以及管道的格子并且把结果写入一个或多个管道。
例如,在Prog程序中,计算与b[i]=a[i-1]+a[i]+a[i+1]对应的分配S的进程具有三个输入端口,其值分别为a[i-1]、a[i]、a[i+1]。对于a[i-1]的读取,复用器MUX 1借助于源函数s((S,t,i):a[i-1])来确定当i≥2∧t=0时,源是(LDa,i-1),其中选择来自LOAD(a)的管道。与进程LOAD(a)对应的解复用器被由[(t,i)→i-1](i≥2Λt=0)=i≥1给出。
DPN已经被获得并且针对每次赋值的每次读取的每个源类似地操作。
在下文中,执行赋值S的进程被称为“进程S”并且执行赋值T的进程被称为“进程T”。
管道的分配
“前端”块2还被调整以便在针对程序P编译DPN网络时创建用于每个管道的分配函数σ。
σ被用作管道寻址函数。向管道的任何请求都实际上通向管道
分配表现为模块化仿射函数的坐标对应于管道CTk,S,Rk的不同尺度的尺寸,这现在可以被前端块2有效地构建。
作为示例,与DPN网络的构建有关,对于Prog程序,为了在S和T之间分配管道C,其中θ(S,t,i)=(t+i,t,0),θ(T,t,i)=(t+i,t,1)。前端块2计算分配函数σ(t,i)=(t mod 1,i mod 1),例如如在以下文献中描述的那样:“Lattice-Based Arrary Contraction:From Theory to Practice”,Christophe Alias,Fabrice Baray,Alain Darte,Research Report RR2007-44,平行信息实验室,ENS-里昂,2007年11月。换句话说,CS,T,b[i]是尺寸为1×1的二维管道,其以后被用σ访问。
其可以通过简单的寄存器实现。
管道的同步
在根据本发明的DPN网络中,管道的读写阻塞:管道的格子在被(其源)写入之前不可读取并且格子在其当前存储的值在上一次未被读取之前不能被写入。
根据本发明,管道中的读写是同步的,以便强行获得该属性。
“前端”块2因此被调整以针对每个管道c构建同步单元Sc,管道c连接生产者进程P的输出端口到消费者进程C的输入端口Rk。
在管道c中的生产者的每次迭代W(写入)和消费者的每次迭代R(读取),在其执行之前,导致向同步单元Sc提供执行请求,同步单元Sc决定是否授权其执行。
为了强制流依赖性,在本发明的实施方式中,同步单元决定如果想读取的数据还未产生则停止消费者的执行。为了强制反依赖性,在本发明的实施方式中,同步单元决定如果想删除在上次还未读取的数据则停止生产者的执行。注意不必强制输出依赖性,因为所有写入都以调度顺次顺序被生产者执行。
这两个事件在以下方式中例如表现为同步单元使用同步单元的以下函数Sc,其中表示(即,θ(X)是先于或等于θ(Y))并且s()是源函数,以便确定对消费者进程C的请求的响应是用于进程C的Freeze(C)信号,或确定对生产者进程P的请求的响应是用于进程P的Freeze(P)信号:
Freeze(C)信号中止消费者进程C的执行,并且Freeze(P)中止消费者进程P的执行。
在实施方式中,Freeze信号存在的时间与其条件为真的时间一样长。当其条件变为假,则其停止被发射,并且进程恢复执行。
在另一实施方式中,在被测试的条件为真时,响应于进程的请求,Freeze信号被发射一次。当条件为假或从其为假时起,向进程发射准许信号。
在上文的Sc的公式中的第一条件意味着消费者的执行在要读取的数据还未被写入时中断,换句话说,当生产者P执行在由R读取的数据的写入s(R)之前的写入W。
第二条件意味着生产者P的执行在未完成读取的数据的删除点时中止。
换句话说,在生产者P试图写入还应该被R’稍后读取的格子σc(W)时。
源函数s(R)已经被读取管道c的进程C的复用器计算出来。
Freeze(P)条件可以以保守的方式被简化为(实际上,如果Freeze(P)是真的,则必有)。
验算:如果Freeze(P)是真,则存在R”,其中可通过的传递性获得结果。
该定理意味着每当应该阻塞生产者时,变真。。相反,可在要写入的格子已被无用地阻塞生产者的消费者释放之后的多次迭代继续为真。特别地,当时,生产者应该预料R在执行。最后,生产者严格遵守由用户指定的调度θ,而不过分执行。因此,提供尽可能并行的调度是用户的责任。
同步单元Sc遵守数据依赖性并且不产生互锁。
作为示例,参照图5,重新考虑在进程S(生产者)和T(消费者)之间的管道c=CS,T,b[i]。
在启动每个新的迭代(tc,ic)之前,消费者进程T向管道c(该管道c中其复用器已确定应该读取基准)的同步单元传送新的迭代的执行准许请求,新的迭代的标识符(tc,ic),以及生产者进程S的预期对应迭代(ts,is)的标识符,即其导致该基准在管道c中的写入。(ts,is)是通过源函数s获得的,“s”从中而来。消费者进程只要未被同步单元准许就不开始该新迭代。
类似地,生产者进程S,在开始每个新迭代(tp,ip)之前,向管道c(在该管道c中其解复用器已经确定应该写入结果)的同步单元传送新迭代的执行准许请求和新迭代的标识符(tp,ip)。只要同步单元不准许生产者进程就不开始该新迭代。
考虑同步单元刚接收到消费者进程T的新迭代(tc,ic)的执行准许请求,其新迭代(tc,ic)的标识符,以及生产者进程S的预期对应迭代(ts,is)的标识符。
如果θ(S,tS,iS)<<θ(S,tP,iP)((tP,iP)是由S传送到同步单元的生产者进程S的上一个迭代标识符)并且θ是调度函数,则同步单元准许消费者T的新迭代(tc,ic)。对应命令SmdT因此被同步单元作为响应传送到消费者进程T(如前所述,该命令因此是准许信号或者缺少根据前述实施方式的Freeze(C)类型的信号)。
如果相反并且该表达式保持为真((tp,ip)是由S传送到同步单元的生产者进程S的上一个迭代标识符),则同步单元不准许消费者T的新迭代(tc,ic)。对应命令SmdT因此被同步单元作为响应传送到消费者进程T(如前所述,该命令因此是根据前述实施方式的连续或点状的Freeze(C)类型的信号)。
现在考虑同步单元刚接收生产者进程S的新迭代的执行准许请求和新迭代的标识符(tp,ip)。
如果(tc,ic)是由T传送到同步单元的消费者进程T的上一个迭代标识符),则同步单元准许生产者S的新迭代(tp,ip)。对应命令Smds因此被同步单元作为响应传送到生产者进程S(如前所述,该命令因此是准许信号或者缺少根据前述实施方式的Freeze(P)类型的信号)。
如果相反θ(T,tC,iC)<<θ(S,tP,iP),并且该表达式保持为真,则同步单元不准许生产者进程S的新迭代(tp,ip)。对应命令Smds因此被同步单元作为响应传送到消费者进程T(如前所述,该命令因此是根据前述实施方式的连续或点状的Freeze(P)信号)。
通过把在前面示例中指出的与用于Prog程序的DPN网路的构建有关的函数作为调度函数,S是生产者进程并且T是消费者进程,则前面指出的与Freeze(C)和Freeze(P)有关的表达式变为:
Freeze(C),如果并且只要即
如果并且只要(tP+iP<ts+iS)∨(tP+iP=tS+iS∧tP<tS)∨(tP+iP=tS+iS∧tP=tS);
∨表示“或者”。
Freeze(P),如果并且只要(tC+iC,tC,1)<<(tP+iP,tP,0),即,
如果并且只要tC+iC<tP+iP)∨(tC+iC=tP+iP∧tC<tP)。
本质上,词典式的顺序(<<)产生极其多余的表达式,这允许产生极其简单的测试电路。
注意在其他实施方式中,其他同步规则被同步单元实施以便在与同一管道相关联的生产者进程和消费者进程之间进行同步。
在“前端”块2基于Prog程序的算术表达转换为如此实现的DPN中间表达之后,该中间表达被提供给“后端”块3。
已知,后端”块3实际上基于该DPN中间表达构成电路块。可使用例如现有的综合工具,如C2H,如在以下文献中描述的那样:Christophe Alias,Alain Darte,和Alexandru Plesco.Optimizing DDR-SDRAM Communications at C-Level for Automatically-Generated Hardware Accelerators.An Experience with the Altera C2H HLS Tool.In 21st IEEE International Conference on Application-specific Systems,Architectures and Processors(ASAP'10),雷恩,法国,329-332页,July 2010.IEEE Computer Society。每个进程、管道、复用器被描述作为C2H函数。每个函数被C2H在具体模块中表示。模块之间的连接是在C2H通过使用连接编译指示指定的。每个连接被C2H在标准具体总线中表现。
根据本发明的电路自动综合设备允许自动生成电子电路,所述电子电路快速并且通过要求有限的占用物理体积来实施高级语言编写的程序P的计算。
存在以进程网络(KPN、SDF等)形式的多种并行执行模型。本发明提出根据适于电路综合具体约束的并行执行模型(其中数据与远程存储器的转移是显式的)来编译为DPN进程网络(数据感知处理网络)。到DPN的这种编译是可靠的,这是因为其把顺序程序转换为等效、有保障而无互锁的DPN进程网络。输入/输出(即,数据与远程存储器的转移)是显式的并且通信管道是比FIFO更少约束的等同性能的缓存存储器,由同步单元控制。
- 还没有人留言评论。精彩留言会获得点赞!