日志分析装置、攻击检测装置、攻击检测方法以及程序与流程
本发明是涉及网络安全的技术,尤其涉及对Web服务器和Web应用进行攻击的访问分析访问并进行检测的技术。
背景技术:
使用了Web的系统以EC(Electronic Commerce:电子商务)为代表利用于社会的各种场合中。但是,因为这样的系统是一般的使用者所使用的平台,因此Web服务器经常暴露于攻击的危险性中。从而正在研讨各种对攻击Web服务器的访问进行检测的方法。
作为检测攻击的方式,一般是在WAF(Web Application Firewall:Web应用防火墙)中对访问内容进行分析的方式和对残留在Web服务器或应用服务器中的日志进行分析的方式。在攻击检测方法中,公知有签名(signature)型和异态(anomaly)型2种检测方法。
图17是用于说明以往的攻击检测方法的图。图17的(a)是示出签名型的攻击检测方法的图,图17的(b)是示出异态型的攻击检测方法的图。
如图17的(a)所示,签名型是从攻击代码中提取能够判定攻击的部分且检测与模式(pattern)一致的请求作为攻击的检测方法。因为在WebAP(Web Application:Web应用)中存在的漏洞增加,因此通过对每1个漏洞采取对策的签名型检测难以防止攻击。因此,正在进行针对异态检测的研究,在该异态检测中,对WebAP根据通常请求生成简档(profile)来检测异常。
如图17的(b)所示,异态型根据正常的请求生成简档,且计算与简档之间的相似度,检测不同的请求作为异常(参照非专利文献1和2)。以下将生成简档的处理称为学习处理,将使用简档来判定分析对象的请求是否是攻击的处理称为检测处理。
在非专利文献1和2所公开的方法中,基于WebAP的路径部,对该路径部所具有的参数生成具有一些特征量的简档。说明简档的生成方法。
在此,仅仅考虑被认为对检测结果带来的影响大的字符串的结构和字符串的类(class)的特征量。图18是用于说明简档的特征量的图。
将以字符串的结构为特征量的情况作为以往技术1,将以字符串的类为特征量的情况作为以往技术2,并对这些技术进行简单说明。
首先,说明以往技术1的以字符串结构为特征量的简档生成方法。图19是用于说明以往技术1的状态迁移模型的生成方法的图。
学习处理的步骤为如下。
(步骤1)以所出现的字符作为状态,生成列举了全部参数值的状态迁移模型。
(步骤2)从初始状态(s)起结合相同的状态,并直到无法结合为止进行重复,并将所完成的状态迁移模型作为简档(关于状态迁移模型的生成方法,参照非专利文献3)。
此外,当创建模型时必须考虑状态迁移的概率,但在以往技术1中,检测时并没有考虑概率,因此可以认为等同于生成未考虑迁移概率的模型。
在检测处理中,如果字符串不能从简档(状态迁移模型)输出则判定为异常。
接着,说明以往技术2的以字符串型为特征量的简档生成方法。图20是用于说明以往技术2的异常判定方法的图。
学习处理的步骤为如下。
(步骤1)预先定义字符串类(关于定义方法的一例,参照非专利文献4)。
(步骤2)对参数值整体判定是否符合该类,并将符合的类作为针对该参数的简档保持该类名。
在检测处理中,将参数值整体转换成类,在该类与简档的类不一致的情况下判定为异常。
现有技术文献
非专利文献
非专利文献1:Kruegel,Christopher,and Giovanni Vigna,"Anomaly Detection of Web-based Attacks",Proceedings of the 10th ACM conference on Computer and communications security,ACM,2003.
非专利文献2:ModSecurity,SpiderLabs,インターネット<URL:http://blog.spiderlabs.com/2011/02/modsecurity-dvanced-topic-of-the-week-real-time-application-profiling.html>,2012
非专利文献3:Stolcke,Andreas,and Stephen Omohundro,"Hidden Markov model induction by Bayesian model merging",Advances in neural information processing systems(1993):11-11.
非专利文献4:OWSP Validation Regex Repository,[平成26年5月26日检索],因特网<URL:https://www.owasp.org/index.php/OWASP_Validation_Regex_Repository>
技术实现要素:
发明要解决的课题
参照图21说明以往技术的课题。
在以往技术1中存在如下问题:如图21的“课题1”所示,因为将在学习数据中出现的各字符作为状态来生成状态迁移模型,因此在不存于学习数据中的数据(学习数据少的情况)中发生很多误检测。
在以往技术2中存在如下问题:如图21的“课题2”所示,因为对1个参数仅生成1个字符串类,因此在具有复杂的结构的参数(例如,将多个预先定义的字符串类连接、复合的参数)的情况下无法生成简档。
另外,在以往技术2中存在如下问题:如图21的“课题3”所示,当人观察时知道是类似的,但严格来说具有不同的形式,在与所准备的字符串类的正则表达式不匹配的情况下,无法生成简档。
本发明就是为了解决如上所述的技术所具有的问题而完成的,其目的在于提供一种针对经由网络发送给Web服务器那样的信息处理装置的请求能够抑制将正常的数据判定为异常的日志分析装置、攻击检测装置、攻击检测方法以及程序。
用于解决课题的手段
用于实现上述目的的本发明的日志分析装置是从与网络连接的信息处理装置收集访问日志而进行分析的日志分析装置,该日志分析装置具有:
存储部,其用于保存简档,其中该简档是用于判定分析对象数据是否表示对所述信息处理装置的攻击的基准;
参数提取部,其从所述访问日志的请求中提取各参数;
类转换部,其针对由所述参数提取部提取的各参数,将参数值从开头字符起按照每个部分与预先定义的字符串类进行比较,且将该部分置换成与该字符串类一致的长度最长的字符串类,从而转换成依次排列有所置换的字符串类的类序列;
简档保存部,其在针对作为学习数据而正常的数据的所述访问日志由所述参数提取部和所述类转换部求出的所述类序列的集合中,将出现频度是规定值以上的类序列作为所述简档保存于所述存储部中;以及
异常检测部,其计算针对所述分析对象数据的所述访问日志由所述参数提取部和所述类转换部求出的所述类序列与所述简档之间的相似度,且按照该相似度判定是否发生了对所述信息处理装置的攻击。
另外,本发明的攻击检测装置是检测对与网络连接的信息处理装置的攻击的攻击检测装置,该攻击检测装置具有:
存储部,其用于保存简档,其中该简档是用于判定对所述信息处理装置的访问请求是否攻击该信息处理装置的基准;
参数提取部,其从所述访问请求中提取各参数;
类转换部,其针对由所述参数提取部提取的各参数,将参数值从开头字符起按照每个部分与预先定义的字符串类进行比较,且将该部分置换成与该字符串类一致的长度最长的字符串类,从而转换成依次排列有所置换的字符串类的类序列;
简档保存部,其在针对作为学习数据而正常的数据的所述访问请求由所述参数提取部和所述类转换部求出的所述类序列的集合中,将出现频度是规定值以上的类序列作为所述简档保存于所述存储部中;以及
异常检测部,其计算针对作为分析对象的所述访问请求由所述参数提取部和所述类转换部求出的所述类序列与所述简档之间的相似度,且按照该相似度判定是否发生了对所述信息处理装置的攻击。
另外,本发明的攻击检测方法是攻击检测装置执行的攻击检测方法,该攻击检测装置检测对与网络连接的信息处理装置的攻击,在所述攻击检测方法中,
从作为学习数据而正常的数据的对所述信息处理装置的访问请求中提取各参数,针对各参数,将参数值从开头字符起按照每个部分与预先定义的字符串类进行比较,且将该部分置换成与该字符串类一致的长度最长的字符串类,从而转换成依次排列有所置换的字符串类的类序列,且将该类序列的集合中的出现频度是规定值以上的类序列作为简档保存于存储部中,其中该简档是用于判定分析对象数据是否表示对所述信息处理装置的攻击的基准,
从所述分析对象数据的所述访问请求中提取参数,
基于所述字符串类,将所提取的参数的值转换成所述类序列,
计算所述类序列与所述简档之间的相似度,
按照所述相似度判定是否发生了对所述信息处理装置的攻击。
而且,本发明的程序使检测对与网络连接的信息处理装置的攻击的计算机执行下述步骤:
从作为学习数据而正常的数据的对所述信息处理装置的访问请求中提取各参数,针对各参数,将参数值从开头字符起按照每个部分与预先定义的字符串类进行比较,且将该部分置换成与该字符串类一致的长度最长的字符串类,从而转换成依次排列有所置换的字符串类的类序列,且将该类序列的集合中的出现频度是规定值以上的类序列作为简档保存于存储部中的步骤,其中该简档是用于判定分析对象数据是否表示对所述信息处理装置的攻击的基准;
从所述分析对象数据的所述访问请求中提取参数的步骤;
基于所述字符串类,将所提取的参数的值转换成所述类序列的步骤;
计算所述类序列与所述简档之间的相似度的步骤;以及
按照所述相似度判定是否发生了对所述信息处理装置的攻击的步骤。
发明效果
根据本发明,针对经由网络输入到信息处理装置的请求将从请求中提取的参数值抽象化成与各种形态的参数值对应的类序列,且判定分析对象的数据是正常的还是不正常的,因此能够减少将分析对象的正常数据判定为异常的误检测的可能性。
附图说明
图1是示出包含第1实施方式的WAF的通信系统的一个结构例的框图。
图2是示出第1实施方式的WAF的一个结构例的框图。
图3是示出第1实施方式的WAF执行的攻击检测方法的处理的流程的图。
图4是示出第1实施方式中的简档形成部进行的学习处理的步骤的流程图。
图5是用于说明图4所示的步骤103和105的处理的详细情况的图。
图6是用于说明在第1实施方式中与简档之间的相似度的计算方法的图。
图7是示出第1实施方式的实施例的图。
图8是用于说明第2实施方式中的变形例3的图。
图9是示出第2实施方式中的简档形成部进行的学习处理的步骤的流程图。
图10是用于说明在第2实施方式中与简档之间的相似度的计算方法的图。
图11是示出第2实施方式的实施例的图。
图12是用于说明第3实施方式的简档生成方法的图。
图13是用于说明第3实施方式中的相似度计算的图。
图14是示出第3实施方式中的简档形成部进行的学习处理的步骤的流程图。
图15是示出第3实施方式的实施例的图。
图16是示出包含本发明的攻击检测装置作为日志分析服务器的日志分析系统的一个结构例的框图。
图17是用于说明以往的攻击检测方法的图。
图18是用于说明简档的特征量的图。
图19是用于说明以往技术1的状态迁移模型的生成方法的图。
图20是用于说明以往技术2的异常判定方法的图。
图21是用于说明以往技术的课题的图。
图22是用于说明以往技术1的另一课题的图。
具体实施方式
本发明涉及对攻击Web服务器的访问进行检测的信息处理装置和计算机,在以下的实施方式中,对信息处理装置为WAF的情况进行说明,但信息处理装置也可以是分析针对Web服务器的访问内容(也可以是日志)的日志分析装置。
(第1实施方式)
说明包含本实施方式的WAF的通信系统的结构。
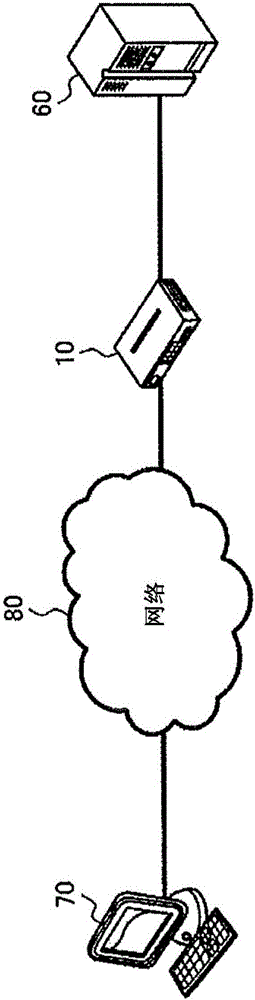
图1是示出包含本实施方式的WAF的通信系统的一个结构例的框图。
如图1所示,通信系统具有Web服务器60和WAF 10,其中,Web服务器60是经由网络80对客户端70提供服务的信息处理装置的一种,WAF 10检测针对Web服务器60的攻击。WAF 10设置于网络80与Web服务器60之间。客户端70经由网络80和WAF 10而与Web服务器60连接。
图2是示出本实施方式的WAF的一个结构例的框图。
如图2所示,WAF 10具有输入部11、存储部12、控制部13以及检测结果输出部14。输入部11具有学习数据输入部21和分析对象数据输入部22。
去往Web服务器60的正常数据作为学习数据从网络80输入到学习数据输入部21。分析对象数据从网络80输入到分析对象数据输入部22,该分析对象数据是作为是否是攻击Web服务器60的判定对象的数据。
在存储部12中保存有简档,其中该简档是用于判定分析对象数据是否表示针对Web服务器60的攻击的基准。
控制部13具有简档形成部40和分析对象数据处理部50。简档形成部40具有参数提取部31、字符串类转换部32以及简档保存部43。分析对象数据处理部50具有参数提取部31、字符串类转换部32以及异常检测部53。参数提取部31与字符串类转换部32参与简档形成部40和分析对象数据处理部50的处理。
控制部13具有存储程序的存储器(未图示)和按照程序执行处理的CPU(Central Processing Unit:中央处理单元)(未图示)。CPU按照程序执行处理,由此在WAF 10中构成参数提取部31、字符串类转换部32、简档保存部43以及异常检测部53。另外,在存储器(未图示)中,存放有针对从访问请求中提取的参数的值规定了如何将字符串分成类的字符串类的信息。关于字符串类的详细情况,在后面说明。
参数提取部31从经由学习数据输入部21从Web服务器60输入的作为学习数据的访问请求中提取访问的各参数而向字符串类转换部32输出。另外,参数提取部31从经由分析对象数据输入部22从网络80输入的作为分析对象数据的访问请求中提取访问的各参数而向字符串类转换部32输出。
字符串类转换部32针对学习数据,将从参数提取部31收到的参数的值基于字符串类转换成类序列而向简档保存部43输出。另外,字符串类转换部32针对分析对象数据,将从参数提取部31收到的参数的值基于字符串类转换成类序列而向异常检测部53输出。
简档保存部43针对学习数据,若收到由字符串类转换部32转换后的类序列的集合,则从各参数的类序列的集合中选择最频繁出现的类序列,且将所选择的类序列作为参数的简档保存于存储部12中。
异常检测部53针对分析对象数据,若收到由字符串类转换部32转换后的类序列,则计算该参数的与简档之间的相似度,对所计算出的相似度与预先决定的阈值进行比较,由此检测访问是否异常。异常检测部53向检测结果输出部14通知该检测结果。具体而言,异常检测部53在所计算出的相似度比阈值大的情况下,判定为正常,在相似度比阈值小的情况下,判定为异常。即,判定为对Web服务器60或者对Web服务器60的WebAP发生了攻击。
检测结果输出部14输出从异常检测部53收到的检测结果。
接着,说明本实施方式的WAF的动作。
图3是示出本实施方式的WAF执行的攻击检测方法的处理的流程的图。
在本实施方式中,在“用于简档的生成的特征量”、“学习时的简档的生成方法以及所生成的简档(的结构、数据)”以及“检测时的简档与分析对象的比较、对照的方法”中存在特征。
本实施方式的攻击检测方法分为学习处理和检测处理2个阶段。
在学习处理中,学习数据输入部21从网络80获取访问请求(学习数据)。简档形成部40从所获取的访问请求中提取各参数(参数提取部31),且将参数的值转换成类序列(字符串类转换部32)。接着,从各参数的类序列的集合中选择最频繁出现的类序列而作为参数的简档(简档保存部43)。
在检测处理中,分析对象数据输入部22从网络80获取访问请求(分析对象数据)。分析对象数据处理部50从所获取的分析对象数据的访问请求中与学习处理同样地提取参数而转换成类序列(参数提取部31、字符串类转换部32),且计算该参数的类序列与简档的类序列之间的相似度,利用阈值检测异常(异常检测部53)。之后,检测结果输出部14输出异常检测部53的检测结果。
此外,作为提取请求的参数的原数据,也可以使用分组捕获(packet capture)等而不是访问请求。
接着,详细地说明简档形成部40的学习处理的步骤。
图4是示出本实施方式中的简档形成部的学习处理的步骤的流程图。
简档形成部40按照学习对象的每个参数p实施如下的处理来生成该参数p的简档L。
当输入了与该参数相关的所有学习数据(参数值:d1~dn)时(步骤101),简档形成部40取出未处理的学习数据(dx)(步骤102)。然后,简档形成部40基于预先规定的字符串类的定义,将该学习数据dx转换成类序列cx而记录(步骤103)。
简档形成部40判定是否有未处理的学习数据(步骤104),在有未处理的学习数据的情况下,返回步骤102,在没有未处理的学习数据的情况下,进入步骤105。在步骤105中,简档形成部40仅选择所记录的所有类序列中的出现次数最大的类序列(步骤105)。之后,简档形成部40将L作为参数p的简档记录于存储部12中(步骤106)。
使用具体例详细地说明图4所示的流程图中的步骤103和步骤105的处理。图5是用于说明图4所示的步骤103和105的处理的详细情况的图。
图5的上段示出将表示同种参数值的多种字符串分类成1个类的字符串类的定义的一例。在字符串类中例如有“numeric”或“space”等类。
图5的中段示出了从参数值的开头字符到最后的字符按照每个部分与字符串类进行比较、且将该部分置换成与字符串类一致的长度最长的字符串类而转换成依次配置有字符串类的类序列的情形。图5的下段示出了采用如上所述的方式而按照每个参数求出类序列、且针对类序列的集合计算每个类序列的出现频度而将出现频度最大的类序列作为简档保存的情形。
参照图4说明上述的动作。
在步骤103中,简档形成部40在将参数值转换成类序列时,针对预先准备的字符串类的正则表达式,将类与参数值匹配的部分字符串最长地一致的部分判定为1个类,且从左开始依次将所有字符串转换成类。由此,也能够将多个在以往的定义中定义成1个字符串类的字符串类连接的参数、复合的参数等具有复杂的结构的参数分类成任意的类。
在步骤105中,简档形成部40在选择类序列时,选择出现频度最大的类序列,并将其作为简档保存。
此外,具体而言,步骤103的处理在字符串类转换部32中执行,步骤105的处理在简档保存部43中执行。另外,字符串类的定义的信息也可以存放于存储部12中。
接着,说明分析对象数据处理部50中的检测处理。
图6是用于说明在本实施方式中与简档之间的相似度的计算方法的图。分析对象数据处理部50的异常检测部53按照下面的步骤进行检测判定。在此,在分析对象数据中使用测试数据。
(步骤1)与学习处理同样地将参数值转换成类序列。
(步骤2)求出与简档的类序列相似度。作为相似度计算方法,例如能够使用图6所示的LCS(最长共同部分序列)。
(步骤3)在相似度S比阈值St小的情况下,判定为异常,否则判定为正常。
说明本实施方式的实施例。图7是示出本实施方式的实施例的图。在本实施例中,说明file参数的情况。另外,作为分析对象数据而使用测试数据。
在学习处理中,简档形成部40选择1个出现频度最大的类序列。在检测处理中,分析对象数据处理部50进行了类序列转换后,进行相似度计算,且根据该结果判定是正常还是异常。
根据本实施方式,在利用了Web应用的参数值的字符串结构的WAF中,利用参数所具有的特性和字符串的格式,由此将参数值抽象化成与各种形态的参数值对应的类序列,来判定分析对象的数据是正常还是不正常,因此能够减少将不存在于学习数据中的正常数据判定为异常的误检测的可能性。
(第2实施方式)
在第1实施方式中,在类序列的选择中仅仅选择1个出现频度最大的类序列而将该类序列作为简档,但在本实施方式中,作为类序列的选择方法的其他方案,应用下面变形例1~3的任意方案。
(变形例1)按照出现频度从大到小的顺序选择u个类序列。
(变形例2)选择出现频度为v%以上的类序列。
(变形例3)按照从大到小的顺序对出现频度fx进行排序(f'1,f'2,f'3…),并选择出现频度之和(贡献率)第一次超过Ft的(f'1+f'2+…+f'u>Ft)u个类序列(c'1,c'2,…c'u)。
图8是用于说明本实施方式中的变形例3的图。
简档保存部43根据表示出现频度的图标而对出现频度进行排序,并提取满足图8所示的式的u个类序列。
说明本实施方式中的简档形成部的学习处理。
图9是示出本实施方式中的简档形成部进行的学习处理的步骤的流程图。
在本实施方式中,在图4所示的流程图中,代替步骤105的处理而执行图9所示的步骤105-abc的处理。在本实施方式中,对步骤105-abc的处理进行说明,并省略其他步骤的处理的说明。
在步骤105-abc中,简档形成部40在所记录的所有类序列中通过变形例1~3的方法中的任意的方法选择多个类序列。
说明本实施方式中的检测时的相似度计算。图10是用于说明在本实施方式中与简档之间的相似度的计算方法的图。
在变形例1~3中选择了u个类序列的情况下,关于在检测中的相似度,从简档的类序列与u个类序列中的各个类序列之间的相似度(s1,s2,…,su)中将最大的相似度Smax=max(s1,s2,…su)作为与简档之间的相似度。
该例的情况下,测试数据与简档之间的相似度S是0.8。
说明本实施方式的实施例。图11是示出本实施方式的实施例的图。即使在本实施例中,也说明file参数的情况。
在学习处理中,简档形成部40使用变形例1~3中的任意的方案来选择多个类序列。在检测处理中,分析对象数据处理部50进行了类序列转换后,进行相似度计算,且根据该结果判定是正常还是异常。
(第3实施方式)
在第1实施方式中,将单独的类序列作为简档,在第2实施方式中将多个类序列作为简档,但在本实施方式中选择对简档使用多个类序列(以下称为“类序列集合”)还是使用不考虑类的顺序的类集合。
此外,也可以在本实施方式中应用在第2实施方式中选择的多个类序列,另外,在本实施方式中,能够应用在第2实施方式中说明的变形例1~3的任意方案。
在此,说明以往技术1的另一课题。在以往技术1中,因为生成在学习数据中实际出现的每1个字符的状态迁移模型,因此存在在字符串的自由度高的参数中发生很多误检测的问题。将该问题作为“课题4”。在图22中示出课题4的一例。
说明本实施方式的简档生成方法。
图12是用于说明本实施方式的简档生成方法的图,示出利用了压缩率R的简档的生成方法。
在本实施方式中,如图12所示,图2所示的简档保存部43求出类序列集合的压缩率(R)是否比阈值Rt小,在压缩率比阈值小的情况下,将类序列的集合作为简档。
另一方面,在压缩率比阈值大的情况下,简档保存部43将类集合作为简档。类集合是出现的唯一的类的集合,类的出现顺序未被保持。即,在类集合中,类序列的集合所包含的字符串类(alpha、numeric等)不重叠,另外,出现的顺序也未确定。
在本实施方式中,类序列的集合考虑字符串类的顺序,但在类集合中不考虑字符串类的顺序。
说明本实施方式中的检测时的相似度计算。图13是用于说明本实施方式中的相似度计算的图。
在本实施方式中,在利用类序列集合生成简档的情况下、以及在利用类集合生成简档的情况下,需要变更检测中的相似度计算方法。
图13的(a)示出简档是类序列集合型的情况下的相似度计算方法,图13的(b)示出简档是类集合型的情况下的相似度计算方法。
(1)在简档是类序列集合型的情况下,关于在检测中的相似度,从简档的类序列与u个类序列中的各个类序列之间的相似度(s1,s2,…,su)中将最大的相似度Smax=max(s1,s2,…su)作为与简档之间的相似度(与变形例1~3的相似度计算方法相同)。
(2)在简档是类集合型的情况下,在类集合包含于简档的类集合时,将相似度S作为1.0,在不一致时,将相似度S作为0.0。
说明本实施方式中的简档形成部的学习处理。在此,说明第2实施方式中的变形例2的情况。
图14是示出本实施方式中的简档形成部的学习处理的步骤的流程图。
在本实施方式中,在图9所示的流程图中,将步骤105-abc作为与变形例2对应的步骤105-b,在步骤105-b与步骤106的处理之间,如图14所示地追加了步骤111~113。在本实施方式中,对步骤105-b和步骤111~113的处理进行说明,并省略其他步骤的处理的说明。
在步骤105-b中,简档形成部40根据所记录的所有类序列(c1~cn)计算压缩率R。在步骤111中,简档形成部40判定压缩率R是否比预先规定的压缩率阈值Rt小。
在步骤111的判定中R<Rt的情况下,简档形成部40将所记录的所有类序列中的唯一的类序列(类序列集合)作为简档L(步骤112)。另一方面,在步骤111的判定中R>Rt的情况下,简档形成部40将所记录的类序列所表示的所有类的唯一的集合(类集合)作为简档L(步骤113)。
说明本实施方式的实施例。图15是示出本实施方式的实施例的图。在本实施例中,说明file参数的情况。
在学习处理中,简档形成部40通过变形例1~3的方法中的任意的方法来选择多个类序列。之后,因为压缩率R<Rt而保存类序列集合。在检测处理中,分析对象数据处理部50进行了类序列转换后,因为简档是类序列而用类序列进行相似度计算,且根据该结果判定是正常还是异常。
与参照图21和图22说明的课题1~4进行对比来说明本发明的攻击检测装置的作用。
相对于参照图21说明的课题1,在本发明中,通过将字符串抽象化成类进行处理而能够进行考虑了下标的不同等的异常判定,因此能够减少误检测。另外,当检测时使用类序列的LCS相似度,由此,即使在学习时的数据中出现附加了下标那样的数据也表示高相似度,因此能够减少误检测。
相对于参照图21进行说明的课题2,在本发明中,因为在字符串类转换部中认为参数是将多个字符串类连接、复合的参数来生成类序列,因此能够生成适合于该参数的简档。
相对于参照图21进行说明的课题3,在本发明中,通过在字符串类中定义url、ip等复杂的字符串类以外还定义单纯字符串类numeric、alpha等,即使不能将字符串"2014.1.1"判定为date型也能够将类序列(numeric,symbol,numeric,symbol,numeric)作为简档来生成。
相对于参照图22进行说明的课题4,在第3实施方式中说明的发明中,通过引入类集合的概念,针对自由度较高的参数,不是以类的顺序而是以降低了限制的是否出现类的条件来判定是否异常,因此能够减少误检测。
根据本发明,通过在针对Web应用的攻击检测方法中利用参数值的字符串结构且利用参数所具有的特性和字符串的格式,由此能够减少将不存在于学习数据中的正常数据判定为异常的误检测和自由度高的参数中的误检测的可能性。
此外,也可以将在上述的实施方式中说明的包含WAF应用于作为日志分析服务器的日志分析系统中。图16是示出包含本发明的攻击检测装置作为日志分析服务器的日志分析系统的一个结构例的框图。
日志分析系统具有Web服务器60、日志服务器90以及日志分析服务器15。日志服务器90与Web服务器60连接。日志服务器90定期地从Web服务器60获取访问日志的信息而保存于本装置的存储部中。
日志分析服务器15与日志服务器90连接。日志分析服务器15具有在上述的实施方式中说明的WAF 10的功能,通过从访问日志中读出访问请求而进行分析,对向Web服务器60的攻击进行检测。
标号说明
10:WAF;15:日志分析服务器;13:控制部;12:存储部;31:参数提取部;32:字符串类转换部;40:简档形成部;43:简档保存部;50:分析对象数据处理部;53:异常检测部;60:Web服务器。
- 还没有人留言评论。精彩留言会获得点赞!