数据存储的跳过的制作方法
本发明涉及数据存储,且更明确地说,涉及通用寄存器(GPR)中的数据存储技术。
背景技术:
处理单元,例如图形处理单元(GPU),包含具有通用寄存器(GPR)的处理核心,所述通用寄存器存储因指令的执行而产生的数据或执行指令所需的数据。举例来说,所述处理核心的处理元件包含算术逻辑单元(ALU),其执行多个算术运算。所述GPR可存储所述算术运算的结果和/或存储所述算术运算的运算元。
所述GPR可在处理单元的处理器核心本地。因此,存取GPR可需要比存取本地高速缓冲存储器或外部系统存储器少的电力。尽管比本地高速缓冲存储器或外部系统存储器更加电力高效,但将数据存储到GPR的确消耗电力。
技术实现要素:
一般来说,本发明描述用于跳过对通用寄存器(GPR)的存取使得不需要再次存取的不存储在所述GPR中。编译器可确定执行程序的后续指令是否不需要数据。如果执行后续指令不需要所述数据,那么所述编译器可指示执行后续指令不需要所述数据。处理单元可基于所述指示来确定执行后续指令不需要所述数据,作为响应,避免将所述数据存储所述GPR中(即,跳过将所述数据存储在所述GPR中)。以此方式,可通过避免对用于存储随后所需的数据的GPR的不必要存取来减少电力消耗。
在一个实例中,本发明描述一种在数据处理系统中处理值的方法,所述方法包括:接收程序的指令的多个子指令,其中所述指令定义多个运算,且其中所述子指令中的每一者定义所述多个运算的组成运算;接收通过所述子指令中的一者的执行而产生的至少一个中间值的指示,其指示所述中间值是否将存储在通用寄存器(GPR)中;至少部分地基于所述接收到的指示来确定所述中间值是否将存储在GPR中;以及如果确定所述中间值不将存储在所述GPR中,那么避免将所述中间值存储在所述GPR中。
在一个实例中,本发明描述一种用于处理数据的装置,所述装置包括:处理单元,其包括芯,所述芯包括指令存储库、通用寄存器(GPR)和至少一个处理元件,所述至少一个处理元件包括控制器以及具有多个执行级的管线结构,其中所述控制器经配置以:从所述芯的所述指令存储库接收程序的指令的多个子指令,其中所述指令定义多个运算,其中所述子指令中的每一者定义所述多个运算的组成运算,且其中所述子指令由所述管线结构的所述多个执行级执行;接收通过在所述多个执行级中的一者上执行所述子指令中的一者而产生的至少一个中间值的指示,其指示所述中间值是否将存储在所述GPR中;至少部分地基于所述接收到的指示来确定所述中间值是否将存储在所述GPR中;以及如果确定所述中间值将不存储在所述GPR中,那么避免将所述中间值存储在所述GPR中。
在一个实例中,本发明描述一种上面存储有指令的计算机可读存储媒体,所述指令在由一或多个处理单元执行时,致使所述一个或多个处理单元:接收程序的指令的多个子指令,其中所述指令定义多个运算,且其中所述子指令中的每一者定义所述多个运算的组成运算;接收通过所述子指令中的一者的执行而产生的至少一个中间值的指示,其指示所述中间值是否将存储在通用寄存器(GPR)中;至少部分地基于所述接收到的指示来确定所述中间值是否将存储在所述GPR中;以及如果确定所述中间值将不存储在所述GPR中,那么避免将所述中间值存储在所述GPR中。
在一个实例中,本发明描述一种用于处理数据的装置,所述装置包括:用于接收程序的指令的多个子指令的装置,其中所述指令定义多个运算,且其中所述子指令中的每一者定义所述多个运算的组成运算;用于接收通过所述子指令中的一者的执行而产生的至少一个中间值的指示的装置,所述指示指示所述中间值是否将存储在通用寄存器(GPR)中;用于至少部分地基于所述接收到的指示来确定所述中间值是否将存储在所述GPR中的装置;以及用于在确定所述中间值将不存储在所述GPR中的情况下避免将所述中间值存储在所述GPR中的装置。
在一个实例中,本发明描述一种编译方法,所述方法包括:确定来自程序的指令的多个子指令,其中所述指令定义多个运算,且其中所述子指令中的每一者定义所述多个运算的组成运算;确定通过所述子指令中的一者的执行而产生的至少一个中间值的最后一次使用,其中确定最后一次使用包括确定所述多个子指令不再需要所述中间值来从所述指令所定义的所述多个运算产生最终值;以及基于所述确定来指示所述至少一个中间值的最后一次使用。
附图和以下描述中陈述一或多个实例的细节。其它特征、目标和优点将从所述描述、图式以及所附权利要求书而显而易见。
附图说明
图1是说明根据本发明中所描述的一或多个实例技术的用于处理数据的实例装置的框图。
图2是更详细地说明图1中所说明的装置的组件的框图。
图3是更详细地说明图2的图形处理单元(GPU)的着色器核心的一个实例的框图。
图4是更详细地说明图3的着色器核心的处理元件的一个实例的框图。
图5是说明处理值的实例技术的流程图。
图6是说明编译的实例技术的流程图。
具体实施方式
并行处理单元,例如被配置成并行(例如同时)执行许多运算的图形处理单元(GPU)包含一或多个处理器核心(例如用于GPU的着色器核心),其执行一或多个程序的指令。为易于描述,相对于GPU或通用GPU(GPGPU)来描述本发明中描述的技术。然而,本发明中描述的技术可扩展到未必是GPU或GPGPU的并行处理单元,以及非并行处理单元(例如未具体配置成用于并行处理的并行处理单元)。
可用单指令、多数据(SIMD)结构来设计GPU。在SIMD结构中,着色器核心包含多个SIMD处理元件,其中每个SIMD处理元件执行相同程序的指令,但是对不同数据执行指令。在特定SIMD处理元件上执行的特定指令被称作线程。每个SIMD处理元件可被认为是执行不同线程,因为用于给定线程的数据可能是不同的;然而,在一个处理元件上执行的线程是与在其它处理元件上执行的指令相同的程序的相同指令。以此方式,SIMD结构允许GPU并行执行许多任务(例如同时)。
举例来说,对于顶点处理,所述GPU可针对每一顶点执行相同任务,但用于每一顶点的顶点数据可不同(例如不同坐标、不同色彩值等)。SIMD结构允许GPU在不同SIMD处理元件上执行顶点着色器的相同实例来并行处理许多顶点。在此实例中,每一SIMD处理元件可执行顶点着色器的线程,其中每一线程是所述顶点着色器的一个实例。
SIMD处理元件包含一或多个算术逻辑单元(ALU),且所述SIMD处理元件将结果存储在GPR中。GPR是用于存储来自一或多个SIMD处理元件的所得数据的专用寄存器。所述GPR可仅由包含处理元件的处理核心存取,而不可由GPU的其它单元(例如图形管线的硬件单元)存取。在此意义上,不应将GPR与GPU的可供GPU的所有单元使用的本地高速缓冲存储器或本地存储器混淆。
ALU基于所述线程中定义的算术运算来执行算术功能,例如加法、减法、乘法、除法等。在一些实例中,为了执行所述线程中所定义的算术运算,ALU产生可用于执行所述算术运算的中间值。举例来说,所述线程可定义将添加的三个值。在此情况下,ALU可将前两个值加在一起以产生中间值,并将所述中间值与所述第三值相加。ALU接着可将所述最终结果值存储在所述GPR中。
在一些技术中,所述ALU始终将所述中间值存储在所述GPR中,且接着用最终值来重写所述GPR中的中间值。然而,此类将中间值存储在GPR中并不始终必需的。通过不必要地将中间值存储在GPR中,GPU不必要地消耗电力。
如下文更详细地描述,本发明中描述的技术确定是否不再需要中间值来完成线程中所定义的算术运算。如果不再需要中间值,那么技术按此指示,且GPU可因而基于此指示来避免将中间值存储在所述GPR中(例如跳过所述存储)。以此方式,本发明中描述的技术减少将需要存取GPR的次数,从而节省电力。
举例来说,处理器,例如中央处理单元(CPU),经由编译器来编译将在GPU上执行的程序。作为所述编译的一部分,所述编译器可将线程所定义的算术运算分成若干组成运算。所述编译器可扫描通过所述组成运算,以确定是否不再需要所述组成运算所产生的中间值中的任一者来完整所述线程所定义的算术运算。对于确定为不再需要的中间值中的任一者,编译器可向所述GPU指示不再需要这些中间值。作为响应,GPU可跳过所述GPR中指示为所述线程所定义的算术运算不再需要的中间值的存储。
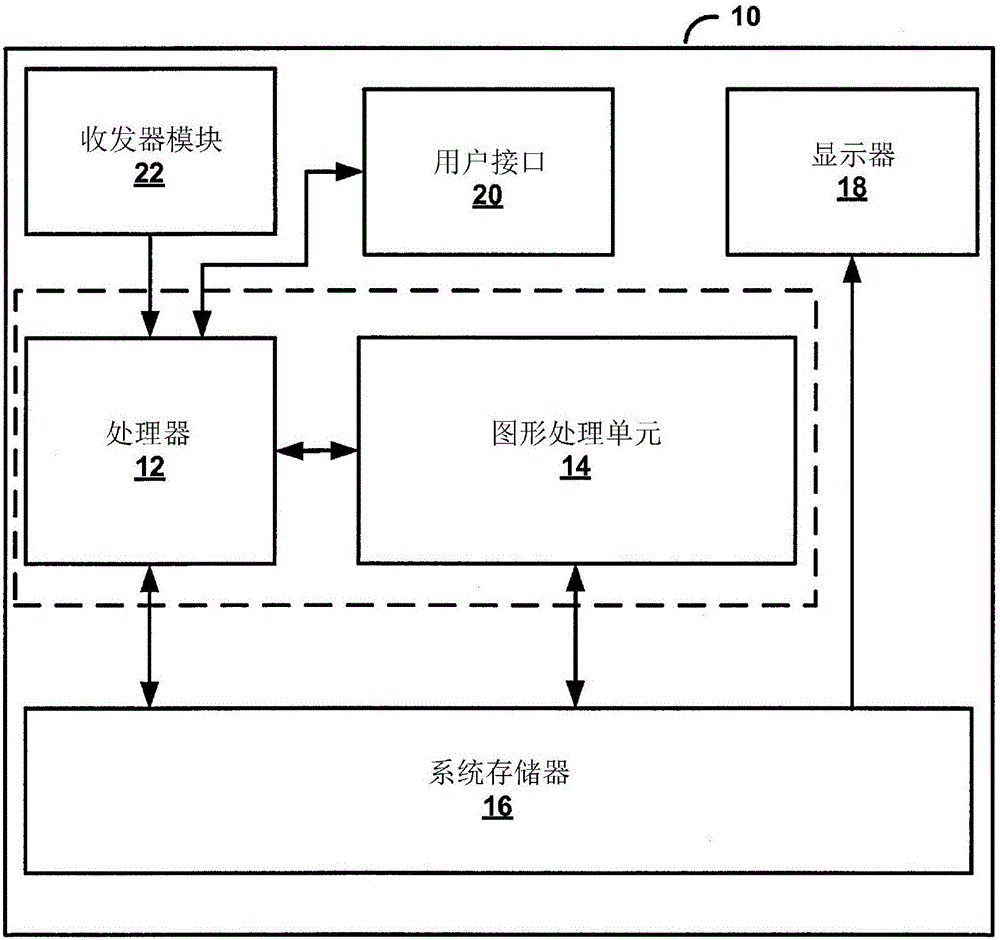
图1是说明根据本发明中所描述的一或多个实例技术的用于处理数据的实例装置的框图。图1说明装置10,装置10的实例包含(但不限于)例如媒体播放器、机顶盒、例如移动电话等无线手持机、个人数字助理(PDA)、桌上型计算机、膝上型计算机、游戏控制台、视频会议单元、平板计算装置等等视频装置。
在图1的实例中,装置10包含处理器12、图形处理单元(GPU)14和系统存储器16。在一些实例中,例如其中装置10是移动装置的实例,处理器12和GPU 14可形成为集成电路(IC)。举例来说,IC可被视为芯片封装内的处理芯片。在一些实例中,处理器12和GPU 14可收容在不同集成电路(即,不同芯片封装)中,例如装置10是桌上型或膝上型计算机的实例。然而,在装置10是移动装置的实例中,或许有可能处理器12和GPU 14收容在不同集成电路中。
处理器12和GPU 14的实例包含(但不限于)一或多个数字信号处理器(DSP)、通用微处理器、专用集成电路(ASIC)、现场可编程逻辑阵列(FPGA)或其它等效的集成或离散逻辑电路。处理器12可为装置10的中央处理单元(CPU)。在一些实例中,GPU 14可以是专用硬件,其包含集成和/或离散逻辑电路,所述集成和/或离散逻辑电路向GPU 14提供适合于图形处理的大规模并行处理能力。在一些情况下,GPU 14还可包含通用处理能力,且在实施通用处理任务(即,非图形相关任务)时可被称为通用GPU(GPGPU)。
出于说明的目的,用GPU 14来描述本发明中描述的技术。然而,本发明中描述的技术不受如此限制。本发明中描述的技术可扩展到其它类型的并行处理单元(例如提供大规模并行处理能力,即使不用于图形处理的处理单元)。并且,本发明中描述的技术可以扩展到未被具体配置成用于并行处理的处理单元。
处理器12可执行各种类型的应用程序。应用程序的实例包含网络浏览器、电子邮件应用程序、电子表格、视频游戏或产生可视对象以供显示的其它应用程序。系统存储器16可存储用于执行一或多个应用程序的指令。在处理器12上执行应用程序使得处理器12产生用于有待显示的图像内容的图形数据。处理器12可向GPU 14发射图像内容的图形数据以供进一步处理。
在一些非图形相关实例中,处理器12可产生较适合于由GPU 14处理的数据。此类数据不需要一定是图形或显示目的所需的。举例来说,处理器12可输出需要通过GPU 14对其执行矩阵运算的数据,并且GPU 14又可执行矩阵运算。
一般来说,处理器12可将处理任务分担给GPU 14,例如需要大规模并行运算的任务。作为一个实例,图形处理需要大规模并行运算,且处理器12可将此类图形处理任务分担到GPU 14。然而,例如矩阵运算等其它运算也可得益于GPU 14的并行处理能力。在这些实例中,处理器12可利用GPU 14的并行处理能力,以致使GPU 14执行非图形相关运算。
处理器12可根据特定应用处理接口(API)与GPU 14通信。此些API的实例包含的API、克罗诺斯(Khronos)小组的或OpenGL以及OpenCLTM;然而,本发明的各方面不限于DirectX、OpenGL或OpenCL API,且可扩展到其它类型的API。此外,本发明中描述的技术不需要根据API作用,且处理器12和GPU 14可利用任何通信技术。
系统存储器16可被视为装置10的存储器。系统存储器16可包括一或多个计算机可读存储媒体。系统存储器16的实例包含(但不限于)随机存取存储器(RAM)、电可擦除可编程只读存储器(EEPROM)、快闪存储器或可用于运载或存储呈指令和/或数据结构形式的所要程序代码且可通过计算机或处理器存取的其它媒体。
在一些方面中,系统存储器16可包含致使处理器12和/或GPU 14执行在本发明中归于处理器12和GPU 14的功能的指令。因此,系统存储器16可为上面存储有指令的计算机可读存储媒体,所述指令在被执行时,致使一或多个处理器(例如处理器12和GPU 14)执行各种功能。
举例来说,如在本发明中其它地方更详细描述,在处理器12上执行的编译器可确定通过在GPU 14上执行的着色器程序的指令产生的中间值是否不需要存储在GPU 14的着色器核心的通用寄存器(GPR),使得所述处理元件并不需要不必要地将值存储在所述GPR中。系统存储器16可存储编译器代码以及在GPU 14上执行的着色器程序的代码。作为另一实例,在处理器12上执行的应用程序致使GPU 14执行着色器程序,且系统存储器16可存储在处理器12上执行的应用程序的指令。
在一些实例中,系统存储器16可为非暂时性存储媒体。术语“非暂时性”可指示存储媒体未体现于载波或传播信号中。然而,术语“非暂时性”不应解释为意味着系统存储器16为非可移动的或其内容为静态的。作为一个实例,可从装置10移除系统存储器16,并将所述系统存储器移动到另一装置。作为另一实例,大体类似于系统存储器16的存储器可插入到装置10中。在某些实例中,非暂时性存储媒体可存储可随时间而改变的数据(例如,在RAM中)。
装置10还可包含显示器18、用户接口20和收发器模块22。为清楚起见,装置10可包含图1中未图示的额外模块或单元。举例来说,装置10可包含扬声器和麦克风(两者都不展示在图1中),以在装置10为移动无线电话的实例中实现电话通信。此外,装置10中所示的各种模块和单元可不必在装置10的每个实例中。举例来说,在其中装置10是桌上型计算机的实例中,用户接口20和显示器18可在装置10外部。作为另一实例,在显示器18为移动装置的触敏或存在敏感显示器的实例中,用户接口20可为显示器18的一部分。
显示器18可包括液晶显示器(LCD)、阴极射线管(CRT)显示器、等离子显示器、触敏显示器、压敏显示器或另一类型的显示装置。用户接口20的实例包含(但不限于)轨迹球、鼠标、键盘和其它类型的输入装置。用户接口20还可为触摸屏,且可作为显示器18的部分并入。收发器模块22可包含用以允许装置10与另一装置或网络之间的无线或有线通信的电路。收发器模块22可包含调制器、解调器、放大器和用于有线或无线通信的其它此类电路。
如上文所述,GPU 14提供大规模并行处理能力。GPU 14提供这样的并行处理能力的一种方式是经由单指令多数据(SIMD)结构。在SIMD结构中,GPU 14执行相同程序的多个例子。举例来说,图形处理和一些非图形相关处理需要执行相同操作,但是是对不同数据执行。
举例来说,GPU 14可执行着色器程序(简单地称为着色器),其执行图形或非图形相关任务。GPU 14包含至少一个着色器核心,并且着色器程序在着色器核心上执行。为了描述简洁容易起见,描述GPU 14执行图形相关任务,但是可类似地执行非图形相关任务。GPU 14可执行着色器程序的多个例子以一次处理多个图形数据值。着色器程序的一个实例是顶点着色器。GPU 14可执行顶点着色器的多个来自来一次处理多个顶点。一般来说,需要对顶点执行的运算与需要对其它顶点执行的运算相同;然而,所述顶点中的每一者的特定顶点值可不同。
为了执行着色器程序的多个例子,GPU 14的着色器核心包含多个处理元件,并且每个处理元件可执行着色器程序的一个例子的一个指令。举例来说,每一处理元件可执行着色器程序的第一指令。尽管处理元件正执行的指令是相同的,但指令在每一处理元件中对其操作的值可不同。在此意义上,每一处理元件可被认为是执行着色器程序的线程,其中所述线程是着色器程序用于给定数据的一个指令。因此,每一处理元件可执行不同线程,因为用于每一线程的数据可不同,但用于每一线程的基础指令可相同。
作为基本实例,着色器程序的指令可定义将三个值相加的运算。在此实例中,所述处理元件中的每一者可将三个值相加,但每一处理元件正相加的特定值可不同。因此,每一处理元件可执行着色器程序的线程,其中所述线程定义将三个值相加的运算。因此,所述指令可为相同的(即,将三个值相加),但用于每一处理元件的所述三个值中的一或多者可不同。在此实例中,通过同时在所述处理元件中的每一者行执行所述指令以将三个值相加,GPU 14可能够提供将三个值相加在一起的并行计算。
在一些情况下,作为执行由指令定义的运算的一部分,处理元件可产生中间值。举例来说,所述指令可定义多个运算(例如加法、减法、乘法和/或除法的组合)。在此情况下,所述多个运算中的每一运算可为组成运算。组成运算的结果可为中间值。举例来说,所述中间值不是所述多个运算的最终值,而是所述多个运算的组成运算中的一者的结果。
所述处理元件中的每一者可存储着色器核心的通用寄存器(GPR)中的处理元件所执行的运算的所得最终值。在一些实例中,因处理元件在GPR中执行组成运算而产生中间值的存储可能不是必需的。举例来说,所述处理元件可反馈中间值以用于额外处理(例如将中间值用作输入值来执行所述指令中所定义的额外组成运算)。然而,可能不会再次需要此中间值,且因此,可能不需要将所述中间值存储在GPR中。
如果中间值是反馈,且接着不再需要,那么中间值的寿命周期可被认为结束(例如所述中间值的最后一次使用)。对于此类中间值(例如寿命周期已结束的那些中间值),可通过不将中间值存储在GPR中(例如跳过所述存储)来获得功率效率。
举例来说,在具有结构的着色器系统(例如在SIMD结构中包含着色器核心的此类GPU 14)中,GPR结构通常较深且较宽,以获得较好的密度,使得每位成本较小。换句话说,处理元件的GPR可经配置以存储超过仅一个值。举例来说,假定处理元件所产生的值是8位。在此实例中,GPR可存储许多个32位值(例如较宽,因为32个位超过8个位,且较深,因为多于一个值可存储在GPR中)。
虽然具有深且宽的GPR可能是有益的,但是还可能有一些潜在的缺点。举例来说,对于大小较大的GPR,存取值(例如数据)所需的时间可较大,从而导致处理元件中的额外数据读取管道(例如,当正读取数据时,处理元件正闲置)。并且,存取GPR要求处理元件且因此GPU 14消耗电力。
举例来说,可存在其中GPU 14可存储数据(例如值)的各种单元。GPU 14可在系统存储器16中存储数据,或者可在本地存储器(例如高速缓冲存储器)中存储数据。着色器核心的GPR不同于系统存储器16和GPU 14的本地存储器两者。举例来说,系统存储器16可由装置10的各种组件存取,且这些组件使用系统存储器16来存储数据。GPU 14的本地存储器可能可通过GPU 14的各种组件存取,并且这些组件使用GPU 14的本地存储器来存储数据。然而,GPR可仅由着色器核心的处理元件或着色器的其它单元存取,且不可由着色器核心外部的单元存取。
如上文所描述,如果这是中间值的寿命周期的结束,那么此可不存储在GPR中。上文相对于GPU 14的结构来描述此实例技术。然而,本发明中描述的技术不限于SIMD结构。一般来说,本发明中描述的技术可适用于处理元件和GPR组合的实例,其中处理元件实施算术运算的管线化执行方案,如更详细描述。为易于描述,相对于SIMD结构来描述所述技术,并且还因为SIMD结构趋向于使用较大的GPR大小。
根据本发明中描述的技术,如果这是中间值的最后一次使用,那么处理元件可避免将所述中间值存储在GPR中。举例来说,处理元件可跳过将中间值存储在GPR中。在一些实例中,处理元件可仅反馈中间值作为所述指令所定义的运算的其它组成运算的运算元。如果这不是中间值的最后一次使用,或如果中间值不在反馈,即使这是中间值的最后一次使用,处理元件可将所述中间值存储在GPR中。
可存在各种方式来确定中间值的寿命周期是否结束。举例来说,处理器12可执行编译着色器程序(例如图形着色器程序)的编译器,所述着色器程序将在GPU 14的着色器核心上执行。作为所述编译的一部分,所述编译器可将着色器程序的指令中所定义的多个运算分成若干组成运算。编译器接着可通过扫描所述组成运算来确定中间值何时处于其寿命的结束(即,中间值的最后一次使用何时发生)。
当在处理器12上执行的编译器确定特定中间值的最后一次使用时,编译器可包含指示特定中间值的最后一次使用的指示。举例来说,所述编译器可包含与指示是否为中间值的最后一次使用的中间值相关联的旗标(例如所述旗标的值1指示最后一次使用,且所述旗标的值0指示不是最后一次使用,或反之亦然)。
在此些实例中,处理元件的控制器可读取与所述中间值相关联的旗标值,且基于旗标值来确定将存储还是不存储所述中间值(例如避免或跳过中间值的存储)。如果将不存储所述中间值,那么处理元件的控制器可跳过将中间值存储在GPR中(或阻止中间值的存储),且如果将存储所述中间值,那么处理元件的控制器将中间值存储在GPR中。
以此方式,所述技术可减少将数据存储到GPR的时间量,从而促进电力节省。举例来说,向GPR的每一存储可消耗相对极少的电力。然而,因为GPU 14提供大规模并行处理能力,存在对每一GPR的许多写入。通过使用在不需要存储的情况下避免(例如跳过)将数据存储在GPR中的方案,与一些其它技术相比,可存在GPU 14得电力使用的总体降低。
在一些其它技术中,处理元件将始终将中间值存储在GPR中。举例来说,这些其它技术无法辨别中间值是否处于其寿命周期的结尾,将中间值存储在GPR中可能不存在看得出的益处,且存储处于其寿命周期的结尾的中间值可能存在负面影响。此外,这些其它技术无法辨别可利用编译器来确定中间值的寿命周期的结尾,且可使用编译器来识别何时是所述中间值的最后一次使用(例如识别所述中间值的寿命周期的结尾何时将出现,例如用旗标来识别,作为一个实例)。这些其它技术可不使用GPU 14的着色器核心中的处理元件的控制器来确定何时识别到中间值的最后一次使用所识别,且在此些情况下避免存储所述中间值。
图2是更详细地说明图1中所说明的装置的组件的框图。如图2中所示,GPU 14包含着色器核心28和固定功能管线30。着色器核心28和固定功能管线30可一起形成用以执行图形或非图形相关功能的处理管线。处理管线执行由GPU 14上执行的软件或固件定义的功能,并且由经硬接线以执行特定功能的固定功能单元执行功能。
如上文所描述,在GPU 14上执行的软件或固件可被称为着色器程序(或仅着色器),且所述着色器程序可在GPU 14的着色器核心28上执行。尽管仅说明一个着色器核心28,但在一些实例中,GPU 14可包含类似于着色器核心28的一或多个着色器核心。固定功能管线30包含固定功能单元。着色器核心28和固定功能管线30可从彼此发射和接收数据。举例来说,处理管线可包含在着色器核心28上执行的着色器程序,其从固定功能管线30的一个固定功能单元接收数据,并且向固定功能管线30的另一固定功能单元输出经处理数据。
着色器程序为用户提供功能灵活性,这是因为用户可设计所述着色器程序以按任何可想象的方式来执行期望任务。然而,固定功能单元针对固定功能单元执行任务的方式而硬接线。因此,固定功能单元可不提供大量功能灵活性。
着色器程序的实例包含顶点着色器32、片段着色器34和计算着色器36。顶点着色器32和片段着色器34可为用于图形相关任务的着色器程序,且计算着色器36可为用于非图形相关任务的着色器程序。在一些实例中,仅仅可使用如顶点着色器32和片段着色器34这样的图形相关着色器程序。在一些实例中,可仅使用如计算着色器36这样的非图形相关着色器程序。存在例如几何形状着色器的着色器程序的额外实例,出于简洁目的未予描述。
如下文所述,在处理器12上执行的图形驱动程序26可经配置以实施应用程序编程接口(API)。在此些实例中,着色器程序(例如顶点着色器32、片段着色器34和计算着色器36)可根据与图形驱动程序26相同的API来配置。尽管未说明,但系统存储器16可存储用于图形驱动程序26的代码,处理器12从系统存储器16检索所述代码来执行。在虚线框中说明图形驱动程序26以指示在此实例中,图形驱动程序26是在硬件(例如处理器12)上执行的软件。然而,图形驱动程序26的功能性中的一些或全部可实施为处理器12上的硬件。
在一些实例中,系统存储器16可存储用于顶点着色器32、片段着色器34和计算着色器36中的一或多者的源代码。在这些实例中,在处理器12上执行的编译器24可编译这些着色器程序的源代码,以创建GPU 14的着色器核心28在运行时(例如,在这些着色器程序需要在着色器核心28上执行的时间)期间可执行的对象或中间代码。在一些实例中,编译程序24可预编译着色器程序,并且在系统存储器16中存储着色器程序的对象或中间代码。
类似于图形驱动程序26,尽管未说明,但系统存储器16可存储用于编译器24的代码,处理器12从系统存储器16检索所述代码来执行。在此实例中,以虚线框来说明编译器24,以指示编译器24是在硬件(例如处理器12)上执行的软件。然而,在一些实例中,编译程序24的一些功能性可实施为处理器12上的硬件。
图形驱动程序26可经配置以允许处理器12和GPU 14彼此通信。举例来说,当处理器12将图形或非图形处理任务卸载到GPU 14时,处理器12经由图形驱动程序26将此些处理任务卸载到GPU 14。
举例来说,处理器12可执行产生图形数据的游戏应用程序,且处理器12可将此图形数据的处理分担给GPU 14。在此实例中,处理器12可将图形数据存储在系统存储器16中,且图形驱动程序26可指令GPU 14何时检索所述图形数据,从系统存储器16中何处检索所述图形数据,以及何时处理所述图形数据。并且,游戏应用程序可要求GPU 14执行一或多个着色器程序。举例来说,游戏应用程序可能要求着色器核心28执行顶点着色器32和片段着色器34以产生有待(例如在图1的显示器18上)显示的图像。图形驱动程序26可指令GPU 14何时执行着色器程序,并且指令GPU 14从何处检索着色器程序所需的图形数据。以此方式,图形驱动程序26可在处理器12与GPU 14之间形成链路。
图形驱动程序26可根据API配置;但图形驱动程序26不需要限于根据特定API配置。在装置10是移动装置的实例中,可根据OpenGL ES API来配置图形驱动程序26。OpenGL ES API具体被设计成用于移动装置。在装置10是非移动装置的实例中,可根据OpenGL API来配置图形驱动程序26。
在本发明中描述的技术中,着色器核心28可经配置以并行地执行同一着色器程序的同一指令的许多例子。举例来说,图形驱动程序26可指令GPU 14检索多个顶点的顶点值,并且指令GPU 14执行顶点着色器32以处理所述顶点的顶点值。在此实例中,着色器核心28可执行顶点着色器32的多个例子,并且通过针对顶点中的每一者在着色器核心28的一个处理元件上执行顶点着色器32的一个例子而执行此操作。
着色器核心28的每一处理元件可在相同例子执行顶点着色器32的同一指令;然而,特定顶点值可能是不同的,因为每一处理元件在处理不同的顶点。如上文所述,每一处理元件可被认为是在执行顶点着色器32的线程,其中线程是指正在处理特定顶点的顶点着色器32的一个指令。以此方式,着色器核心28可执行顶点着色器32的许多例子以并行(例如同时)处理多个顶点的顶点值。
着色器核心28可类似地执行片段着色器34的许多例子以并行处理多个像素的像素值,或者执行计算着色器36的许多例子以并行处理许多非图形相关数据。以此方式,着色器核心28可用单指令多数据(SIMD)结构配置。为易于描述,相对于通用着色器程序描述下文,通用着色器程序的实例包含顶点着色器32、片段着色器34、计算着色器36和其它类型的着色器,例如几何形状着色器。
如上文还描述,着色器核心28包含通用寄存器(GPR),以存储处理元件所产生的数据(例如值)。举例来说,处理元件可包含多个执行级。这些执行级可以管线方式形成(例如一个执行级将数据馈入到下一执行级以供处理)。最后一个执行级的输出可输出到GPR以进行数据存储。
在一些实例中,在处理着色器程序的指令时,所述执行级可产生中间值。可能仅临时需要此中间值,且因此,可能不需要将所述中间值存储在GPR中。然而,归因于处理元件的管线配置,一些技术要求将中间值存储在GPR中,即使此类存储不是必需的。当此类存储不是必需的时,此类存储可不必要地消耗将值存储到GPR的电力。
在本发明中描述的技术中,处理器12经由编译器24可确定需要将中间值存储在GPR中,还是不需要存储在GPR中。如果不需要将中间值存储在GPR中,那么处理器12可经由编译器24这样指示。作为一个实例,处理器12经由编译器24可包含与中间值相关联的旗标。所述旗标指示中间值是否将存储在GPR中。着色器核心28的处理元件内的控制器可基于所述旗标来确定是否将存储所述中间值,且可基于所述旗标将所述中间值存储或不存储在GPR中。换句话说,控制器可至少部分地基于接收到的指示(例如旗标)来确定中间值是否将存储在GPR中。如果确定不将中间值存储在GPR中,那么所述控制器可避免将中间值存储在GPR中。如果确定中间值将存储在GPR中,那么控制器可将所述中间值存储在GPR中。
举例来说,着色器程序的指令可定义多个运算(例如相乘、相除、相加、相减或组合的变量)。在着色器程序的编译期间,编译器24可将所述多个运算分成若干组成运算,并创建子指令,以处理所述组成运算中的每一者。
作为一个实例,着色器程序的指令(被称作DP4指令)可定义以下运算:DP4=X0*X1+Y0*Y1+Z0*Z1+W0*W1。在此实例中,X0*X1、Y0*Y1Z0*Z1和W0*W1可各自被视为由DP4指令定义的所述多个运算的组成运算,因为这些运算中的每一者是由DP4指令定义的所述多个运算的一部分。
在此说明性实例中,编译器24可将DP4指令分成以下子指令:
子指令1:R0=X0*X1;
子指令2:R1=Y0*Y1;
子指令3:R2=Z0*Z1+R0;
子指令4:R3=W0*W1+R1;
子指令5:R4=R2+R3。
在此实例中,R4等于DP4指令的最终值,其是通过执行多个子指令来产生的。举例来说,处理元件的执行级可以管线方式执行上述实例子指令,其中每一子指令从用以产生最终值的组成运算产生中间值。举例来说,在以上实例中,R0、R1、R2和R3是被计算为确定最终值R4的一部分的所有中间值,但不是最终值本身。在以上实例中,GPR可存储作为DP4指令的结果的R4的值。
从在子指令3之后的上文子指令可看出,不再需要中间值R0,在子指令4之后,不再需要中间值R1,且在子指令5之后,不再需要中间值R2和R3。然而,在一些技术中,归因于着色器核心28的处理元件的管线结构,中间值R0、R1、R2和R3存储在GPR中,即使在不再需要它们之后。
在本发明中所描述的技术中,编译器24可扫描通过所述子指令,以确定是否不需要将任何中间值存储在GPR中,且可针对不需要存储在GPR中的任何中间值这样指示。举例来说,在以上实例中,编译器24可确定在子指令3之后不再需要中间值R0,在子指令4之后不再需要中间值R1,且在子指令5之后不再需要中间值R2和R3。
在一些实例中,处理器12经由编译器24可包含具有中间值的指示,其指示执行由着色器程序指令定义的运算不再需要的中间值。举例来说,当不再需要中间值时,编译器24可指示这是所述中间值的最后一次使用(LU),表示所述中间值的寿命周期的结尾。作为一个实例,编译器24可包含LU旗标,其指示所述中间值在所述子指令中的最后一次使用。举例来说,以下子指令包含LU旗标,其表示所述中间值的寿命周期的结尾。
子指令1':R0=X0*X1;
子指令2':R1=Y0*Y1;
子指令3':R2=Z0*Z1+(LU)R0;
子指令4':R3=W0*W1+(LU)R1;
子指令5':R4=(LU)R2+(LU)R3
在本发明中描述的技术中,处理元件内的控制器可读取所述LU旗标,以确定中间值将不存储在GPR中。在这些实例中,控制器可跳过将所述中间值存储(例如避免存储)在GPR中,这反过来可减少GPU 14所消耗的电力的量。然而,如果对于某些中间值不断言所述LU旗标,那么控制器可确定中间值将存储在GPR中,且可将中间值存储在GPR中。
图3是更详细地说明图2的GPU的着色器核心的一个实例的框图。举例来说,图3说明GPU 14的着色器核心28的一个实例。着色器核心28可包含控制单元38、指令存储库40、一或多个处理元件42A到42H(统称为“处理元件42”)和通用寄存器(GPR)44。GPR 44可存储数据,且因此还可被称作数据存储库。尽管图3说明八个处理元件42,但在其它实例中,可存在多于或少于八个处理元件42。处理元件42是对其并行执行着色器程序的例子的处理元件的实例。
控制单元38可控制着色器28的功能性。举例来说,控制单元38可检索将由处理元件42执行的指令,并将所述指令存储在指令存储库40中。并且,控制单元38可检索处理元件42将处理的值(例如数据),并将所述值存储在数据存储库44中。
指令存储库40可为能够存储指令的任何类型的存储器,例如(但不限于)易失性存储器、非易失性存储器、高速缓冲存储器、随机存取存储器(RAM)、静态RAM(SRAM)、动态RAM(DRAM)等。控制单元38可为着色器核心28的控制着色器核心28的组件的硬接线电路。然而,控制单元38可有可能为着色器核心28的在硬件上执行的软件或固件。
处理元件42经配置以执行着色器程序的线程。处理元件42中的每一者可执行不同线程。举例来说,处理元件42中的每一者可相对于潜在地不同的数据项执行着色器程序的指令的例子。处理元件42可为单指令多数据(SIMD)处理元件。SIMD处理元件指代当被激活时经配置以相对于不同数据同时执行同一指令的处理元件。这样可允许处理元件42相对于不同数据项并行执行着色器程序的多个线程。在一些情况下,处理元件42中的每一者可基于指向指令存储库40中包含的指令的共用程序计数器执行着色器程序的指令。
如果处理元件42中的一或多者由控制单元38解除激活,那么此些处理元件42在给定指令循环中并不执行程序指令。在一些情况下,控制单元38可解除激活处理元件42中的一或多者以实施条件性分支指令,其中分支条件对于一些线程得到满足且对于其它线程不得到满足。
在一些实例中,处理元件42中的每一者可包含和/或对应于一或多个算术逻辑单元(ALU)。在其它实例中,处理元件42中的每一者可实施ALU功能性。ALU功能性可包含加法、减法、乘法等。
根据本发明中描述的技术,编译器24可将定义多个运算的指令分成若干子运算,且指示不需要将中间值存储在相应处理元件42的GPR。举例来说,指令存储库40可存储具有与中间值相关联的旗标值的子指令,所述旗标值指示其是否为中间值的最后一次使用,其中从定义多个运算且执行组成运算中的一者的指令导出所述子指令。相应处理元件42内的控制器可确定所述中间值是否存储在GPR中,且如果不需要存储所述中间值,那么跳过存储(例如避免存储),如由所述旗标值指示,或存储是否需要存储。
图4是更详细地说明图3的着色器核心的处理元件的一个实例的框图。举例来说,图4说明处理元件42A。处理元件42B到42H可包含与相对于处理元件42A描述的那些组件类似的组件。如所说明,处理元件42A包含管线结构46、控制器48、转发逻辑(FW)54A和54B,以及时钟56。管线结构46包含执行级50A到50C(共同称为执行级50)。如所说明,管线结构46包含三个执行级50。然而,在不同实例中,管线结构46可包含多于或少于三个执行级50。
执行级50中的每一者对于来自时钟56的每时钟循环执行一个功能。举例来说,执行级50中的每一者可经配置以执行算术运算,例如由着色器程序的指令定义的所述多个运算的组成运算。执行级50中的每一者可在时钟56的上升或下降沿上将算术运算的结果发射到执行级50中的下一执行级。以此方式,执行级50形成管线结构46,其中以管线方式执行由指令定义的所述多个运算的组成运算。
控制器48可经配置以发射执行级50中的每一者将执行的子指令。举例来说,如上文所描述,着色器核心28的控制单元38可将着色器程序的所述指令(包含如由编译器24确定的子指令)加载到指令存储库40中。处理元件42A的控制器48接着可从指令存储库40检索子指令,以及形成用于组成运算的操作数的数据值。控制器48可将所述运算元(例如数据值)馈入到执行级50中的对应执行级。并且,如果执行级50中的任一者将处理因执行级50中的另一者产生的数据,那么来自执行级50中的另一者的数据也可为到组成运算中的将执行的运算元。
如还说明,管线结构46可包含转发逻辑,例如转发逻辑54A和转发逻辑54B。转发逻辑54A和54B可被认为是内部ALU转发逻辑。举例来说,在管线结构46中,可存在能够将执行级50中的一者的结果发射回到执行级50中的较早一者的一些益处。举例来说,执行级50中的一者可产生中间值,其形成为在管线结构46中较早的另一组成运算的运算元。通过转发逻辑54A和54B,执行级50中的一者可能够将所述值转发回到管线结构46中的执行级50中的较早执行级。
此外,尽管图4中未说明,但在一些实例中,处理元件42A可包含额外转发逻辑以补偿与存取GPR 44相关联的等待时间。举例来说,此类等待时间补偿转发逻辑单元可允许执行级50C的输出反馈到执行级50A。
在一些其它技术中,即使在包含等待时间补偿转发逻辑的那些技术中,GPR 44始终存储执行级50C的输出,即使此类存储是不必要的。举例来说,在管线结构46中,来自执行级50中的前一者的所有值继续进行到执行级50中的下一者。这可为真实的,即使所述值被转发也是如此。举例来说,执行级50C的输出可反馈到转发逻辑54B,且可发射到GPR 44。因此,所有中间值可行进通过执行级50,且在这些其它技术中,中间值将存储在GPR 44中。
作为说明,指令的上述实例是X0*X1+Y0*Y1+Z0*Z1+W0*W1,其中以下子指令:
子指令1:R0=X0*X1;
子指令2:R1=Y0*Y1;
子指令3:R2=Z0*Z1+R0;
子指令4:R3=W0*W1+R1;
子指令5:R4=R2+R3。
在伪码中,从执行级50A的角度来看,执行级50可如下处理上述情况:
循环0:R0=X0*X1;
循环1:R1=Y0*Y1;
循环2:R2=Z0*Z1+R0;//R0在FW 54B上转发
循环3:R3=W0*W1+R1;//R1在FW54B上转发
循环4:NOP;//将R0写入到GPR 44
循环5:NOP;//将R1写入到GPR 44,R2在FW54A上转发
循环6:R4=R2+R3;//将R2写入到GPR 44,R3在FW54B上转发
循环7:NOP;//将R3写入到GPR 44
在以上实例中,分别在循环4、5、6和7中将R0、R1、R2和R3写入到GPR 44是不必要的。举例来说,在循环2之后,不再需要R0,在循环3之后,不再需要R1,且在循环6之后,不再需要R2和R3。然而,在这些其它技术中,分别在循环4、5和6将R0、R1和R2写入到GPR 44,且在不再需要这些值来确定指令DP4的最终值之后,且在循环7将R3写入到GPR 44,即使不再需要R3来确定指令DP4的最终值。
下表是说明执行级50中的每一者对于上述实例所执行的功能的实例。
表1.通过执行级的运算的时序
如表1中所说明,在时间T1,执行级50A经由控制器48从数据存储库40接收X0和X1的值。在时间T2,控制器48向执行级50B提供子指令,其致使执行级50B通过使X0与X1相乘来确定中间值R0,且在时间T2,执行级50A经由控制器48从数据存储库40接收Y0和Y1的值。
在时间T3,执行级50C接收中间值R0,且控制器48向执行级50B提供子指令,其致使执行级50B通过使Y0与Y1相乘来确定中间值R1。并且,在时间T3,执行级50A经由控制器48从数据存储库40接收Z0和Z1的值。另外,经由FW 54B将中间值R0转发到执行级50B。在此实例中,执行级50C将中间值R0(不必要地)写入到GPR 44。
在时间T4,执行级50C接收中间值R1,且执行级50C经由FW 54B将R1转发到执行级50B。并且在时间T4,控制器48向执行级50B提供子指令,其致使执行级50B通过将Z0与Z1相乘并将结果与R0相加来确定中间值R2。另外,在时间T4,执行级50A经由控制器48从数据存储库40接收W0和W1的值。在此实例中,执行级50C将中间值R1(不必要地)写入到GPR 44。
在时间T5,执行级50C接收中间值R2,且在此实例中,执行级50C将中间值R2(不必要地)写入到GPR 44。控制器48向执行级50B提供子指令,其致使执行级50B通过将W0与W1相乘并将结果与R3相加来确定中间值R3。
在时间T6,执行级50C将中间值R3(不必要地)写入到GPR 44,将中间值R3转发到执行级50B,且执行级50A接收中间值R2。在时间T7,执行级50B将R4计算为等于中间值R2加中间值R3。在时间T8,执行级50C将值R4存储到GPR 44。
在以上实例中,将中间值R0、R1、R2和R3存储到GPR 44是不必要的,因为在最后一次使用之后,不需要这些值。然而,这些中间值仍经过各个执行级50,以最终存储在GPR 44中。在本发明中描述的技术中,编译器24可确定中间值的寿命周期的结尾(例如最后一次使用),且包含与所述中间值相关联的指示(例如旗标)。在这些实例中,即使中间值将不存储在GPR 44中,仍行进通过执行级50。然而,控制器48读取与所述中间值相关联的旗标,且基于所述旗标的所述值,不将所述中间值存储在GPR 44中(例如跳过所述中间值的存储)。
举例来说,编译器24可扫描通过着色器程序的指令的子指令1到5。如果在前一子指令(例如是中间值)产生运算元(例如到子指令的输入),那么编译器24可确定所述指令的最终值何时不再需要所述中间值。举例来说,编译器24可确定所述子指令中的中间值的最后一次使用。基于所述所确定的最后一次使用,编译器24可包含具有中间值的最后一次使用(LU)旗标。换句话说,LU旗标指示在其被使用(例如读取)之后,数据生命周期结束,不管是从转发管道、等待时间补偿逻辑还是GPR 44读取。
控制器48可经配置以读取与中间值相关联的旗标值,且确定所述中间值是否将存储在GPR 44中。举例来说,如上文所描述,各种执行级50可经由转发逻辑54A或54B和/或经由等待时间补偿逻辑单元转发数据。在一些实例中,控制器48可确定是否正转发所述中间值。如果控制器48确定与中间值相关联的旗标指示所述中间值的最后一次使用,且控制器48确定正转发所述中间值(例如转发逻辑54A或54B和一或多个等待时间补偿逻辑单元在“作用中”),那么控制器48可确定所述中间值并不需要存储在GPR44中。在这些实例中,控制器48可跳过将所述中间值存储(例如避免存储)在GPR 44中。
如上文所描述,在一些实例中,除确定是否断言LU旗标(例如数字一)之外,控制器48还可确定是否正转发与LU旗标相关联的中间值。在一些实例中,只有在断言相关联LU旗标且正转发中间值的情况下,控制器48才可避免存储所述中间值。举例来说,即使断言LU旗标,但不在转发中间值,控制器48也仍可将所述中间值存储在GPR 44中。换句话说,如果控制器38确定不转发中间值,那么控制器48可将所述中间值存储在GPR中,即使指示所述中间值不存储在所述GPR中也是如此。举例来说,在一些实例中,归因于指令获取等待时间或如果处理元件42A失去对另一线程的仲裁,那么所述中间值可需要存储在GPR 44中,但不转发。因此,在一些实例中,如果断言LU旗标并且确定中间值将转发,那么控制器48可避免存储所述中间值。
作为说明,在其中中间值不必要地存储在GPR 44中的实例中,本发明描述用于正通过执行级50处理的值的伪码。以下伪码说明最后一次使用(LU)旗标,以及指示正转发中间值,作为控制器48确定中间值不需要存储的一种方式。以下伪码是基于包含LU旗标的子指令,其如上文所描述是:
子指令1':R0=X0*X1;
子指令2':R1=Y0*Y1;
子指令3':R2=Z0*Z1+(LU)R0;
子指令4':R3=W0*W1+(LU)R1;
子指令5':R4=(LU)R2+(LU)R3
具有LU旗标的伪码如下:
循环0:R0=X0*X1;
循环1:R1=Y0*Y1;
循环2:R2=Z0*Z1+(LU)R0;//R0在FW 54B上转发
循环3:R3=W0*W1+(LU)R1;//R1在FW54B上转发
循环4:NOP;//跳过R0写入到GPR 44,因为FW 54B上发生转发
循环5:NOP;//跳过R1写入到GPR 44,因为FW 54B发生转发
循环6:R4=R2+R3;//跳过R2写入到GPR 44,因为接下来将发生等待时间补偿逻辑单元上的转发
循环7:NOP;//跳过R3写入到GPR 44,因为等待时间补偿逻辑单元上发生转发,R2经由等待时间补偿逻辑单元中的第一者转发,R3经由等待时间补偿逻辑单元中的第二者转发。
如上文所描述,在一些实例中,控制器48可确定是否发生中间值的转发,作为确定是否避免将中间值存储在GPR 44中的一部分。举例来说,假定在上述伪码中,存在从指令存储库40检索用于循环2的Z0*Z1的子指令部分的三个循环的延迟。此延迟可归因于指令获取等待时间,或控制单元38确定较高优先级线程应在处理元件42A上执行,作为两个实例,且所述延迟的其它原因是可能的。
在此情况下,可仍需要中间值R0,但断言LU旗标。因为R0将尚未转发,所以控制器48可确定中间值R0应存储在GPR 44中,即使断言LU旗标也是如此。换句话说,在此情况下,即使断言LU旗标,控制器48也无法避免跳过中间值R0的存储。然而,如果不存在延迟,那么将转发中间值R0,且将断言其相关联的LU旗标(例如视具体情况设定成1或0,以指示其是否为所述数据的最后一次使用);因此,控制器48将避免将中间值R0存储在GPR 44中。
在图4中,说明三个执行级50和两组转发逻辑54A和54B。在一些实例中,包含额外执行级50和额外转发逻辑可进一步减少需要写入到GPR 44的数据的量。举例来说,编译器24可能够执行子指令的较深扫描(例如扫描较多子指令),因为存在较多的几率转发中间值。由于存在较多的几率来转发中间值,编译器24可识别其中控制器48可跳过将中间值存储在GPR 44中的较多情况。举例来说,编译器24可能够识别具有较短生命周期的较多中间值(其趋向于为针对许多着色器程序的情况),或编译器24可最佳化着色器程序,使得对于具有较短寿命周期的中间值,存在较多情况。
此外,因为存在对GPR 44的较少读取和写入,但不仅所述技术减少电力消耗,而且本发明中描述的技术可以其它方式增强性能。举例来说,出于例如纹理读取、存储器加载/存储等目的,与在其它技术中,处理元件42A可较早可用。举例来说,在其它技术中,处理元件42A可不必要地将数据存储到GPR 44,其致使将处理元件42A分配到特定线程的时间量增加。对于本发明中描述的技术,处理元件42A较早可用于处理下一线程,例如用于纹理读取或存储器加载/存储的线程,较早因为处理元件42A无法存储随后不需要的数据。以此方式,性能的增加还允许GPR 44将较早可用于写入和读取以供其它写入/读取客户存取,因为较少写入和读取发生,且GPR 44较早变为释放以用于此类处理。
图5是说明处理值的实例技术的流程图。在图5中示出的实例中,处理元件接收程序(例如着色器程序)的指令的多个子指令(100)。所述指令定义多个运算,且所述子指令中的每一者定义所述多个运算的组成运算。举例来说,处理单元(例如GPU 14)包含核心(例如着色器核心28)。所述核心包含指令存储库(例如指令存储库40)、GPR(例如GPR 44)以及至少一个处理元件(例如处理元件42中的至少一者),且所述至少一个处理元件包含控制器(例如控制器48),以及具有多个执行级(例如执行级50)的管线结构(例如管线结构46)。
举例来说,控制器48经配置以接收着色器程序的指令(例如DP4指令)的多个子指令(例如子指令1'到5')。子指令1'到5'各自定义由DP4指令定义的多个运算的组成运算。并且,在此实例中,处理元件42中的每一者可经配置以同时(例如并行)执行同一指令的相同子指令1'到5'。
处理元件还可接收通过执行子指令中的一者而产生的至少一个中间值的指示,其指示所述中间值是否将存储在GPR中(102)。举例来说,子指令1'产生了中间值R0。在此实例中,控制器48接收到对子指令3'中的中间值R0的指示(例如LU旗标),其指示中间值R0是否将存储在GPR 44中。对于中间值R1、R2和R3,但相对于不同子指令,发生相同情况。
所述控制器可至少部分地基于所述接收到的指示来确定中间值是否将存储在GPR中(104)。举例来说,当正在执行级50中的一者上执行子指令3'时,控制器48可基于与中间值R0相关联的LU旗标,来确定中间值R0是否将存储在GPR 44中。控制器48可类似地确定中间值R1、R2和R3是否将存储在GPR 44中。举例来说,当所述指示为控制器48指示中间值将不存储在GPR 44中,那么所述指示(例如LU旗标)还指示所述中间值在所述多个子指令中的最后一次使用。在最后一次使用之后,其它子指令中的任一者不再需要所述中间值来从所述指令所定义的所述多个运算确定最终值。
在一些实例中,控制器48还可确定所述中间值是否从执行了产生所述中间值的子指令的执行级转发到前一执行级。举例来说,执行级50布置为管线结构46中的管线。控制器48可确定中间值R0正经由转发逻辑54B转发到前一执行级。作为另一实例,控制器48可确定中间值R2和R3正经由等待时间补偿转发逻辑单元转发。在此些实例中,控制器48可至少部分地基于所述接收到的指示以及是否转发所述中间值的确定,来确定所述中间值是否将存储在GPR 44中。换句话说,如果确定所述中间值不转发到所述前一执行级,那么控制器48可将所述中间值存储在GPR 44中,即使指示所述中间值将不存储在GPR 44中也是如此。
如果确定不将中间值存储在GPR中,那么控制器可避免所述中间值的存储(106)。举例来说,控制器48可基于以下确定来跳过将中间值存储在GPR 44中:基于所述指示,所述中间值将不存储在GPR中,以避免不必要地将数据存储到GPR 44。然而,如果确定所述中间值将存储在GPR 44中(例如无LU旗标),那么控制器48可将所述中间值存储在GPR 44中。在本发明中描述的技术中,执行级50执行子指令以从所述指令所定义的所述多个运算产生最终值,其中所述最终值是从充当子指令中的一者的运算元的中间值产生的。虽然控制器48无法将不需要存储的中间值存储在GPR 44中,但控制器48可将最终值存储在GPR 44中,如在所述子指令结束时由执行级50C输出。
图6是说明编译的实例技术的流程图。在图6中示出的实例中,在处理器12上执行的编译器24可确定来自程序的指令的多个子指令(110)。所述指令定义多个运算,且所述子指令中的每一者定义所述多个运算的组成运算。举例来说,在处理器12上执行的编译器24可确定来自DP4指令的子指令1到5。
在处理器12上执行的编译器24可确定将通过子指令中的一者的执行而产生的至少一个中间值的最后一次使用(112)。举例来说,编译器24可确定所述多个子指令不再需要所述中间值来从所述指令所定义的所述多个运算产生最终值。举例来说,在子指令3处,编译器24可确定所述多个子指令不再需要中间值R0(例如没有循环将再次需要中间值R0)来从DP4指令所定义的所述多个运算产生最终值。举例来说,为了产生R4,不再需要中间值R0,因为中间值R2已经包含中间值R0的值(例如R2是从中间值R0产生)。
编译器24经由处理器12可基于所述确定来指示所述至少一个中间值的最后一次使用(114)。举例来说,编译器24可包含指示使用中间值作为运算元的子指令中的一者中的至少一个中间值的最后一次使用的旗标。举例来说,在子指令3中,中间值R0是运算元。在此实例中,编译器24可包含具有中间值R0的LU旗标以产生子指令3'。子指令3'中具有中间值R0的LU旗标指示中间值R0的最后一次使用。换句话说,子指令3'是使用中间值R0作为运算元的最后一个指令。
另外,如上文所描述,指示所述至少一个中间值的最后一次使用还指示所述至少一个中间值不需要存储在GPR中。举例来说,控制器48可读取LU旗标,且确定与所述LU旗标相关联的中间值不需要存储在用于GPU 14的着色器核心28的执行所述子指令的处理元件42A的GPR 44中。
处理器12可将经编译的子指令(例如子指令1'到5')存储在系统存储器16中,作为着色器程序代码。当受图形驱动程序28指令时,GPU 14可从系统存储器16检索所述着色器程序的指令,包含子指令1'到5'。处理元件42中的每一者可同时(例如并行)执行子指令1'到5'。
在一或多个实例中,所描述的功能可用硬件、软件、固件或其任何组合来实施。如果用软件实施,那么所述功能可作为一或多个指令或代码在计算机可读媒体上存储或传输,且由基于硬件的处理单元执行。计算机可读媒体可包含计算机可读存储媒体,其对应于例如数据存储媒体等有形媒体。以此方式,计算机可读媒体可一般对应于非暂时性的有形计算机可读存储媒体。数据存储媒体可为可由一或多个计算机或一个或多个处理器存取以检索用于实施本发明中描述的技术的指令、代码和/或数据结构的任何可用媒体。计算机程序产品可包含计算机可读媒体。
作为实例而非限制,此类计算机可读存储媒体可包括RAM、ROM、EEPROM、CD-ROM或其它光盘存储装置、磁盘存储装置或其它磁性存储装置、快闪存储器或可用来存储呈指令或数据结构的形式的所要程序代码并且可由计算机存取的任何其它媒体。应理解,计算机可读存储媒体和数据存储媒体并不包含载波、信号或其它暂时性媒体,而是针对非暂时性有形存储媒体。如本文中所使用,磁盘和光盘包含压缩光盘(CD)、激光光盘、光学光盘、数字多功能光盘(DVD)、软性磁盘和蓝光光盘,其中磁盘通常以磁性方式再现数据,而光盘利用激光以光学方式再现数据。以上各项的组合也应包含在计算机可读媒体的范围内。
可由例如一或多个数字信号处理器(DSP)、通用微处理器、专用集成电路(ASIC)、现场可编程逻辑阵列(FPGA)或其它等效集成或离散逻辑电路等一或多个处理器来执行指令。因此,如本文中所使用的术语“处理器”可指前述结构或适合于实施本文中所描述的技术的任一其它结构中的任一者。另外,在一些方面中,本文中所描述的功能性可在经配置用于编码和解码的专用硬件和/或软件模块内提供,或者并入在组合编解码器中。而且,所述技术可完全实施于一或多个电路或逻辑元件中。
本发明的技术可在各种各样的装置或设备中实施,包含无线手持机、集成电路(IC)或一组IC(例如,芯片组)。本发明中描述各种组件、模块或单元是为了强调经配置以执行所揭示的技术的装置的功能方面,但未必需要由不同硬件单元实现。实际上,如上文所描述,各种单元可结合合适的软件和/或固件组合在编码解码器硬件单元中,或者通过互操作硬件单元的集合来提供,所述硬件单元包含如上文所描述的一或多个处理器。
已描述了各种实例。这些和其它实例在所附权利要求书的范围内。
- 还没有人留言评论。精彩留言会获得点赞!