文件系统中的元数据索引搜索的制作方法
本发明要求2015年8月20日递交的发明名称为“文件系统中的元数据索引搜索(METADATA INDEX SEARCH IN A FILE SYSTEM)”的美国非临时申请案14/831,292和2014年8月28日递交的发明名称为“用于文件系统中的元数据索引搜索的系统和方法(SYSTEM AND METHOD FOR METADATA INDEX SEARCH IN A FILE SYSTEM)”的美国临时专利申请案62/043,257的在先申请优先权,该在先申请的两个内容以引用方式并入本文中,如同全文复制一般。
技术领域
无
背景技术:
在计算时,文件系统是用于组织文件且将文件存储在硬盘驱动器、闪存驱动器或任何其它存储设备上的方法和数据结构。文件系统将存储设备上的数据分成称为文件的单件。另外,文件系统可以存储关于文件的数据,例如,文件名、权限、创建时间、修改时间和其它属性。文件系统可以进一步提供编索引机构,使得用户可以访问存储于存储设备中的文件。例如,文件系统可以组织成多级目录,所述多级目录是文件系统对象,例如文件和/或子目录的集合。为了到达文件系统中的特定文件系统对象,路径可以用于指定文件系统中的文件系统对象存储位置。路径包括指示目录、子目录和/或文件名的字符串。存在多个不同类型的文件系统。不同类型的文件系统可以具有不同结构、逻辑、速度、灵活性、安全性和/或大小。
技术实现要素:
在一个实施例中,本发明包含一种装置,所述装置包括:输入/输出(input/output,IO)端口,用于耦合到可大规模扩展的存储设备;存储器,用于存储所述可大规模扩展的存储设备的文件系统的多个元数据数据库(database,DB),其中所述多个元数据DB包括具有空值的密钥值对;以及处理器,耦合到所述IO端口和所述存储器,其中所述处理器用于按时间顺序将所述文件系统中的目录进行分组以将所述文件系统分成多个分区,并且将不同分区的元数据作为密钥分别存储在独立的元数据DB中以为所述文件系统编索引。
在另一实施例中,本发明包含一种装置,所述装置包括:IO端口,用于耦合到可大规模扩展的存储设备;存储器,用于存储包括所述可大规模扩展的存储设备的文件系统的一部分的元数据编索引信息的关系DB以及包括所述元数据编索引信息的至少一部分的表示的布隆过滤器;以及处理器,耦合到所述IO端口和所述存储器,其中所述处理器用于接收文件系统对象的查询并且将所述布隆过滤器应用于所述查询以确定是否搜索所述所查询文件系统对象的所述关系DB。
在又一实施例中,本发明包含一种用于搜索可大规模扩展的存储文件系统的方法,包括:接收文件系统对象的查询,其中所述查询包括所述所查询文件系统对象的路径名的至少一部分;将布隆过滤器应用于所述所查询文件系统对象的所述路径名的所述部分,其中所述布隆过滤器包括在所述可大规模扩展的存储文件系统的特定部分中的路径名的表示;当所述布隆过滤器传回肯定结果时,在包括所述特定文件系统部分的元数据编索引信息的关系DB中搜索所述所查询文件系统对象;以及当所述布隆过滤器传回否定结果时,跳过搜索所述关系DB中的所述所查询文件系统对象。
从以下结合附图以及权利要求书进行的详细描述将更清楚地理解这些以及其它特征。
附图说明
为了更透彻地理解本发明,现参考结合附图和具体实施方式而描述的以下简要说明,其中相同参考标号表示相同部分。
图1是文件存储系统的实施例的示意图。
图2是用作网络中的节点的网络元件(network element,NE)的实施例的示意图。
图3是文件系统子树的实施例的示意图。
图4是散列表产生方案的实施例的示意图。
图5是散列表产生方法的实施例的流程图。
图6是布隆过滤器产生方案的实施例的示意图。
图7是元数据索引搜索查询方案的实施例的示意图。
图8是元数据索引搜索查询方法的实施例的流程图。
图9是日志构造合并(Log-Structured Merge,LSM)树存储方案的实施例的示意图。
图10是文件系统元数据更新方法的实施例的流程图。
具体实施方式
首先应理解,尽管下文提供一个或多个实施例的说明性实施方案,但所揭示的系统和/或方法可以使用任何数目的技术来实施,无论该技术是当前已知还是现有的。本发明决不应限于下文所说明的说明性实施方案、附图和技术,包含本文所说明并描述的示例性设计和实施方案,而是可以在所附权利要求书的范围以及其等效物的完整范围内修改。
由于文件系统达到数十亿个文件、数百万个目录和千兆字节数据,因此用户组织、寻找和管理其文件变得愈加困难。尽管分层命名方案可以易化文件管理并且可以通过采用多级目录和命名规范而减少文件名冲突,但是分层命名方案的益处在可大规模扩展的文件系统中受限。在可大规模扩展的文件系统中,基于元数据的搜索方案可能对于文件管理和分析更实用且信息量大。文件系统元数据是指与文件有关的任何数据和/或信息。元数据的一些实例可以包含文件类型(例如,文本文档类型和申请案类型)、文件特征(例如,音频和视频)、文件扩展名(用于文档的.doc以及用于可执行文件的.exe)、所有者、组、创建日期、修改日期、链接数和大小。然而,在具有数十亿文件的可大规模扩展的文件系统中,基于元数据的搜索可能较慢。
本文揭示用于可大规模扩展的文件系统的有效文件元数据索引搜索方案的各种实施例。文件元数据索引搜索方案采用用于将文件系统的元数据保持在多个元数据数据库(database,DB)中的编索引引擎以及用于基于用户的文件系统元数据查询搜索文件系统对象的搜索引擎。编索引引擎通过基于地点的时间顺序散列目录而将文件系统分成多个分区。例如,可大规模扩展的文件系统可以分成具有约2万(20K)个目录和/或约1百万个文件的分区。可以通过爬行或扫描文件系统的目录执行编索引。可以按路径名的顺序执行初始爬行(例如,深度优先搜索)。可以按更改时间的顺序执行后续爬行或进行中的爬行。因此,基于爬行时间或更改时间组织分区。在初始爬行期间产生元数据DB并且在后续爬行期间更新元数据DB。不同分区的元数据存储于不同元数据DB中。另外,不同类型的元数据(例如,路径名、链接数、文件特性、自定义标签)存储于不同元数据DB中。因此,可以通过使同一组的文件系统对象相关联而使多个元数据DB相关,其中多个元数据DB可以被称为关系DB。通过采用但具有空值的密钥值对存储模型来实施元数据DB。空值密钥值对的采用实现存储器的更高效使用并且允许更快搜索。在实施例中,元数据DB通过采用LSM树技术实现有效书写和/或更新来存储密钥值记录。基于LSM的DB的实例是levelDB。搜索引擎采用布隆过滤器来减小查询的搜索空间,例如,排出与查询不相关的分区和/或元数据DB。在实施例中,不同布隆过滤器用于不同分区。在初始爬行期间在从目录的散列创建分区之后产生布隆过滤器,并且在后续爬行之后更新布隆过滤器。布隆过滤器可以对路径名或任何其它类型的元数据操作。在接收查询之后,搜索引擎将布隆过滤器应用于查询以识别可能载送与查询相关的数据的分区。当特定分区的布隆过滤器指示查询的肯定匹配时,搜索引擎进一步搜索与特定分区相关联的元数据DB。由于布隆过滤器可以消除约百分之(%)90至95时间的不必要搜索,因此文件元数据查询时间可以显著减少,例如,查询的搜索时间可以约为秒。因此,所揭示的文件元数据索引搜索方案允许快速和复杂文件元数据搜索,并且可以提供良好可扩展性以用于可大规模扩展的文件系统中。应注意,在本发明中,目录名和路径名是等效的并且可以互换使用。
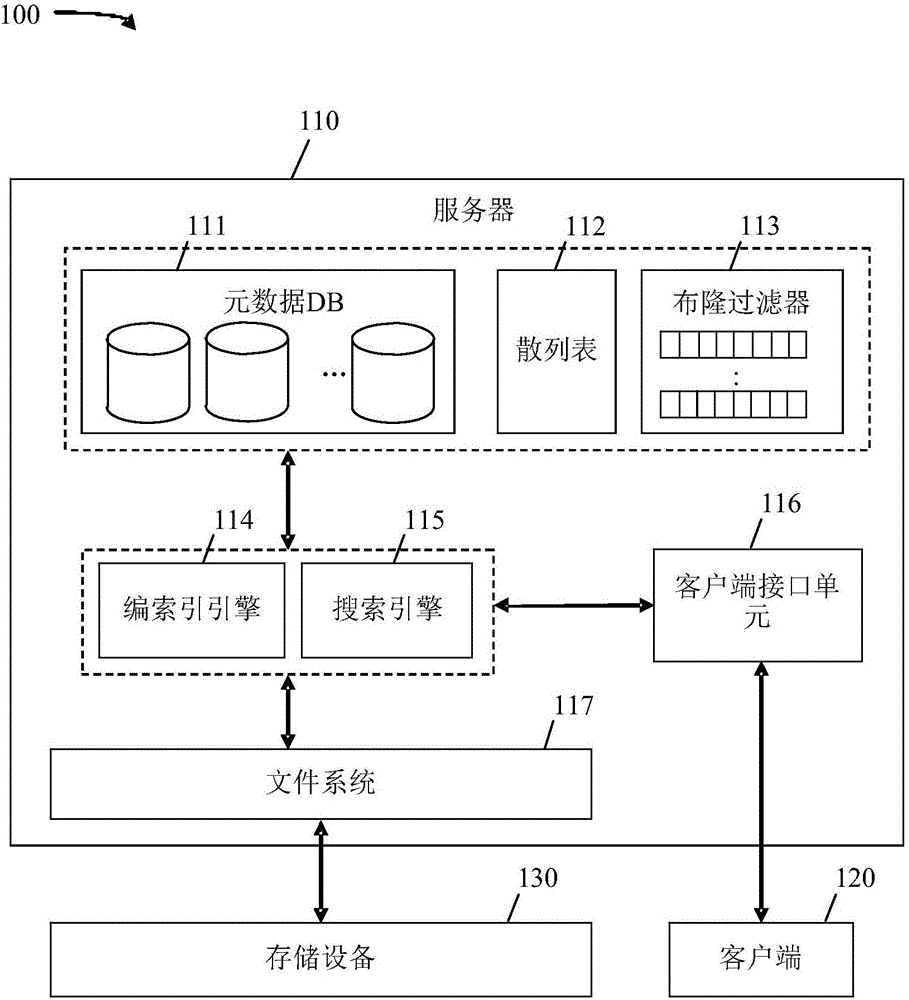
图1是文件存储系统100的实施例的示意图。系统100包括服务器110、客户端120和存储设备130。服务器110以通信方式耦合到存储设备130和客户端120。存储设备130是适用于存储数据的任何设备。例如,存储设备130可以是硬盘驱动器或快闪驱动器。在实施例中,存储设备130可以是存储数十亿个文件、数百万个目录和/或千兆字节数据的可大规模扩展的存储设备和/或系统。尽管存储设备130说明为服务器110的外部组件,但是存储设备130可以是服务器110的内部组件。服务器110管理存储设备130以用于文件存储和访问。客户端120是向服务器110查询存储于存储设备130中的文件的用户或用户程序。另外,客户端120可以将文件添加到存储设备130,修改存储设备130中的现有文件和/或从存储设备130删除文件。在一些实施例中,客户端120可以通过网络耦合到服务器110,所述网络可以是任何类型的网络(例如,电网络和/或光网络)。
服务器110是虚拟机(virtual machine,VM)、计算机器、网络服务器或用于管理存储设备130上的文件存储、文件访问和/或文件搜索的任何设备。服务器110包括多个元数据DB 111、散列表112、多个布隆过滤器113、编索引引擎114、搜索引擎115、客户端接口单元116和文件系统117。文件系统117是软件组件,所述软件组分例如通过输入/输出(input/output,IO)端口接口以通信方式耦合到存储设备130并且用于管理存储设备130中的文件的命名和存储位置。例如,文件系统117可以包括到存储在存储设备130上的文件的多级目录和路径。编索引引擎114是用于管理存储在存储设备130上的文件的编索引的软件组件。编索引引擎114通过元数据为文件编索引,所述元数据可以包含文件的基本名、文件的路径名和/或任何文件系统属性,例如,文件类型、文件扩展名、文件大小、文件访问时间、文件修改时间,文件更改时间、与文件相关联的链接数、用户ID、组ID和文件权限。例如,对于在目录/a/b/c下存储的文件数据.c,基本名是.c且路径名是/a/b/c。另外,元数据可以包含自定义属性和/或标签,例如,文件特征(例如,音频和视频)和/或基于内容的信息(例如,运动图像专家组层4视频(mpeg4))。自定义属性是为文件定制的特定元数据,例如,通过用户或客户端120产生的元数据。
编索引引擎114通过将文件系统117分成多个分区、限制分区的最大大小以及由分区产生元数据索引来提供灵活性和可扩展性。例如,在具有约十亿个文件的可大规模扩展的存储设备中,假设每一目录具有约50个文件的平均值,则编索引引擎114可以将文件系统117分成具有约1百万个文件或约2万(20K)个目录的约1000个分区。通过将文件系统117分成多个分区,可以更有效地执行搜索,如下文更充分地描述。编索引引擎114通过将散列函数应用于目录名而将文件系统117分成分区。例如,编索引引擎114可以采用提供均匀随机分布的任何散列方案,例如,通过将位移和异或函数应用于伪随机数字而产生散列值的BuzHash方案。编索引引擎114基于地点的时间顺序执行分割和编索引。在文件系统117的初始爬行或第一时间爬行期间,编索引引擎114类似于深度优先搜索技术按路径名的顺序穿越或扫描文件系统117。深度优先搜索开始于目录树的根处,例如,通过选择根节点开始,并且在回溯之前尽可能深地沿着每个分支穿越。因此,通过按路径名的顺序扫描和编索引,在初始爬行期间的分割根据扫描时间分组文件和/或目录。在后续爬行期间,文件编索引引擎114按更改时间的顺序穿越文件系统117并且因此根据更改时间穿越文件和/或目录。文件编索引引擎114在散列表112中生成每个文件系统目录的条目。例如,散列表112可以包括将目录名和/或路径名映射到对应于分区的散列码的条目,如下文更充分地论述。
在将文件系统117分成分区之后,编索引引擎114产生用于分区的布隆过滤器113。例如,针对每个分区产生布隆过滤器113。布隆过滤器113使搜索引擎115能够快速识别可能载送与查询相关的数据的分区,如下文更充分地论述。布隆过滤器113是最初设定成零的位向量。可以通过将k个(例如,k=4)散列函数应用于元素以在位向量中产生k个位位置并且将位设定成1而将元素添加到布隆过滤器113。元素可以是目录名(例如,/a/b/c)或目录名的一部分(例如,/a,/b,/c)。随后,可以通过用相同散列函数k次散列元素以获得k个位位置并且检查对应的位值来测试元素(例如,目录名)是否出现或存在于集合(例如,分区)中。如果位中的任一个包括零值,元素肯定不是集合的成员。否则,元素在集合中或是误报。
除了产生布隆过滤器113之外,编索引引擎114产生元数据DB 111,用于存储与文件系统117相关联的元数据。在扫描目录时,编索引引擎114可以产生元数据。因此,基于与目录的扫描相同的时间顺序为文件系统117编索引并且组织元数据DB 111,其中时间顺序在初始爬行期间基于扫描时间并且在后续爬行期间基于更改时间。在实施例中,编索引引擎114例如通过采用Unix系统调用stat()来检索文件属性而单独地检查文件系统117中的每个文件以产生文件的元数据。编索引引擎114将元数据映射到索引节点(inode)数目和设备数目。设备数目识别文件系统117。索引节点数目在文件系统117内是唯一的并且识别文件系统117中的文件系统对象,其中文件系统对象可以是文件或目录。例如,文件可以与多个字符串名称和/或路径相关联,文件可以由索引节点数目和设备数目的组合唯一地识别。在一些实施例中,服务器110可以包括对应于一个或多个存储设备130的多个文件系统117。在此类实施例中,编索引引擎114可以单独地分割每个文件系统117并且针对每个文件系统117单独地产生和保持散列表112、元数据DB 111和布隆过滤器113。
举例来说,具有索引节点数目12和设备数目2048的命名为“/proj/a/b/c/data.c”的文件的不同类型元数据可以存储于不同元数据DB111中。例如,文件的路径名可以存储于第一元数据DB 111中,表示为PATH元数据DB。与文件相关联的多个链接可以存储于第二元数据DB 111中,表示为LINK元数据DB。文件的不同名称与文件的索引节点数目和设备数目之间的反向关系可以存储于第三元数据DB 111中,表示为INVP元数据DB。例如,可以创建硬链接以使文件与不同名称“/proj/data.c”相关联。文件的自定义元数据可以存储于第四元数据DB 111中,表示为CUSTOM元数据DB。例如,文件可以用自定义数据(例如,非文件系统属性),例如,mpeg-4格式标记。元数据DB 111将每个条目存储在具有空值的密钥值对中。空值配置使能够更快地搜索元数据DB 111并且可以提供有效存储。下表示出元数据DB 111中的条目的实例:
表1-元数据DB 111条目的实例
如图所示,密钥中的不同字段或元数据通过分隔符(示为冒号)分隔开。应注意,分隔符可以是不用于路径名的任何字符(例如,统一码字符)。搜索引擎115可以使用分隔符以在搜索期间检查不同元数据字段。除了上述实例元数据DB 111之外,编索引引擎114可以产生用于例如文件类型、文件大小、文件更改时间等的其它类型的元数据DB 111。存储同一文件系统对象的元数据索引的元数据DB 111(例如,PATH元数据DB、LINK元数据DB和INVP元数据DB)的组可以共同形成关系DB,其中可以在元数据DB 111的组之中建立定义明确的关系。或者,与同一文件系统对象相关联的不同类型的元数据可以作为驻留在单个元数据DB 111中的单独表(例如,PATH表、LINK表和INVP表)存储,所述单个元数据DB是关系DB。
编索引引擎114可以另外将文件的所有元数据集中在第五元数据DB 111中,表示为MAIN元数据DB。然而,MAIN元数据DB包括非空值。表2说明用于由索引节点数目12和设备数目2048识别的文件的MAIN元数据DB条目的实例。例如,文件是具有权限0644的常规文件(例如,呈八进制格式)。通过用户标识符(user identifier,ID)100识别的用户以及通过组ID101识别的组拥有所述文件。文件含有65,536个字节并且包括1000000001秒的访问时间、1000000002秒的更改时间以及1000000003秒的修改时间。
表2-MAIN元数据DB条目的实例
客户端接口单元116是用于连接查询且查询客户端120与搜索引擎115之间的结果的软件组件。例如,当客户端接口单元116从客户端120接收文件查询时,客户端接口单元116可以解析和/或格式化查询,使得搜索引擎115可以对查询操作。当客户端接口单元116从搜索引擎115接收查询结果时,客户端接口单元116可以例如根据服务器-客户端协议格式化查询结果并且将查询结果发送到客户端120。
搜索引擎115是用于执行以下操作的软件组件:通过客户端接口单元116从客户端120接收查询;通过布隆过滤器113确定包括与查询相关的数据的分区;搜索与分区相关联的元数据DB 111;以及通过客户端接口单元116将查询结果发送到客户端120。在实施例中,布隆过滤器113对路径名或目录名操作。因此,文件的查询可以包含路径名的至少一部分,如下文更充分地论述。当搜索引擎115接收查询时,搜索引擎115将布隆过滤器113应用于查询。如上所述,可以根据布隆过滤器113散列函数散列查询。当布隆过滤器113对于散列后的位位置全部传回1时,对应于布隆过滤器113的分区可能载送与查询相关的数据。随后,搜索引擎115可以进一步搜索与对应分区相关联的元数据DB 111。
随后,当在文件系统117中更改文件或目录时,编索引引擎114可以执行另一爬行来更新散列表112、布隆过滤器113和元数据DB 111。在实施例中,元数据DB 111实施为levelDB,levelDB可以采用LSM技术来提高有效更新,如下文更充分地论述。应注意,系统100可以如图所示构造成或可替代地如由本领域普通技术人员所确定构造成实现类似功能。
图2是在例如系统100的文件存储系统中用作节点的NE 200,例如服务器110、客户端120和/或存储设备130的实例实施例的示意图。NE 200可以用于实施和/或支持本文中所描述的元数据编索引和/或搜索机制。NE 200可以在单个节点中实施或NE 200的功能可以在多个节点中实施。本领域的技术人员将认识到,术语“NE”涵盖宽广范围的设备,其中NE 200仅仅是一个实例。出于清楚地论述的目的,包含NE 200,但绝非意图将本发明的应用限制于特定NE实施例或NE实施例的类别。本发明中描述的特征和/或方法中的至少一些可以在例如NE 200等的网络装置或模块中实施。举例来说,本发明中的特征和/或方法可以使用硬件、固件和/或被安装成在硬件上运行的软件来实施。如图2中所示,NE 200可以包括一个或多个IO接口端口210和一个或多个网络接口端口220。处理器230可以包括可以用作数据存储装置、缓存器等的一个或多个多核处理器和/或存储器设备232。处理器230可以实施为通用处理器或可以是一个或多个专用集成电路(application specificintegrated circuits,ASIC)和/或数字信号处理器(digital signal processor,DSP)的一部分。处理器230可以包括文件系统元数据索引和搜索处理模块233,其可以执行服务器或客户端的处理功能并且实施如下文更充分地论述的方法500、800和1000以及方案300、400、600、700和900和/或本文论述的任何其它方法。因此,包含文件系统元数据索引和搜索处理模块233以及相关联方法和系统能提供NE 200的功能性的改进。此外,文件系统元数据索引和搜索处理模块233实现特定物品(例如,文件系统)到不同状态的变换。在替代实施例中,文件系统元数据索引和搜索处理模块233可以实施为可以由处理器230执行的存储于存储器设备232中的指令。存储器设备232可以包括用于临时存储内容的高速缓冲存储器,例如,随机存取存储器(random-access memory,RAM)。另外,存储器设备232可以包括用于相对更长地存储内容的长期存储装置,例如,只读存储器(read-only memory,ROM)。举例来说,高速缓冲存储器和长期存储装置可以包含动态RAM(dynamic RAM,DRAM)、固态驱动器(solid-state drive,SSD)、硬盘或其组合。存储器设备232可以用于存储例如元数据DB 111的元数据DB、例如散列表112的散列表以及例如布隆过滤器113的布隆过滤器。IO接口端口210可以耦合到IO设备,例如存储设备130,并且可以包括用于从IO设备读出数据和/或将数据写入到IO设备的硬件逻辑和/或组件。网络接口端口220可以耦合到计算机数据网络并且可以包括用于从网络中的其它网络节点,例如客户端120接收数据帧和/或将数据帧传输到其它网络节点的硬件逻辑和/或组件。
应理解,通过将可执行指令编程和/或加载到NE 200上,处理器230和/或存储器设备232中的至少一个改变,从而将NE 200部分地变换为具有本发明所教示的新颖功能性的特定机器或装置,例如,多核转发架构。对于电力工程和软件工程技术来说重要的是,可以通过将可执行软件加载到计算机中而实施的功能性可以通过熟知设计规则转换为硬件实施方案。在软件还是硬件中实施概念之间的决策通常取决于对设计的稳定性和待产生的单元的数目的考虑,而非从软件域转移到硬件域所涉及的任何问题。通常,仍在经受频繁改变的设计可以优选在软件中实施,因为重改硬件实施方案比重改软件设计更为昂贵。一般来说,将以较大量产生的稳定的设计可以优选在硬件中实施,例如在ASIC中实施,因为运行硬件实施方案的大型生产可能比软件实施方案便宜。通常,设计可以软件形式开发和测试,并且随后通过熟知设计规则转换为用于硬线连接软件的指令的ASIC中的等效硬件实施方案。以与由新ASIC控制的机器为特定机器或装置相同的方式,同样,已经编程和/或加载有可执行指令的计算机可以被看作特定机器或装置。
图3是文件系统分割方案300的实施例的示意图。文件服务器编索引引擎,例如,服务器110中的编索引引擎114采用方案300来将例如文件系统117的文件系统分成多个分区,用于编索引和搜索。当创建和/或更新文件系统对象时执行方案300。方案300通过采用散列函数320将文件系统目录310映射到分区330(例如,分区1至N)。如图所示,方案300开始于扫描(例如,爬行)文件系统目录310并且将散列函数320应用于每个文件系统目录310。例如,深度优先搜索技术可以用于扫描文件系统目录310,如下文更充分地论述。散列函数320产生每个目录的散列值。散列函数320可以是产生均匀随机分布的任何类型的散列函数。例如,散列函数320可以是通过旋转随机数以及对随机数进行异或运算而产生散列值的BuzHash函数。散列至同一值的文件系统目录310被分组到同一分区330中,如下文更充分地论述。在实施例中,方案300将文件系统分成具有约20K个目录的分区330。文件系统目录330或目录名存储于散列表340,例如散列表112中。例如,被分配到同一分区的文件系统目录310可以存储在对应于分区330的散列代码下。随后,当更新文件系统目录310(例如,添加和/或删除文件和/或子目录或重定位目录)时,方案300可以应用于更新分区330。在后续扫描或爬行期间,文件系统目录310根据更改时间重新分割。因此,方案300按时间顺序创建分区330,这基于在初始创建期间的扫描时间并且基于在后续更新期间的更改时间。应注意,分区330的大小可以可替代地如由本领域普通技术人员所确定构造成实现类似功能。
图4是文件系统扫描方案400的实施例的示意图。当首次将文件系统分成分区,例如分区330时(例如,在初始爬行期间),文件服务器编索引引擎,例如服务器110中的编索引引擎114采用方案400来扫描例如文件系统117的文件系统中的所有目录410,例如,文件系统目录310。方案400可以与方案300结合使用。例如,方案400可以用于将文件系统目录310馈送到方案300中的散列函数320中。如图所示,方案400可以对包括目录A、B和C 410的文件系统操作。目录A 410包括目录A.1和A.2 410。目录B 410包括目录B.1 410。目录C 410包括目录C.1 410。方案400通过采用深度优先搜索技术扫描目录410,在到达分支的最大深度之前,所述深度优先搜索技术逐分支扫描目录410。在步骤421处,扫描目录A 410。在步骤422处,在扫描目录A410之后,扫描目录A.1 410。在步骤423处,在扫描目录A.1 410之后,扫描目录A.2 410。在步骤424处,在扫描目录A.2 410之后,扫描目录B 410。在步骤425处,在扫描目录B 410之后,扫描目录B.1 410。在步骤426处,在扫描目录B.1 410之后,扫描目录C 410。在步骤427处,在扫描目录C 410之后,扫描目录C.1 410。
图5是文件系统分割方法500的实施例的流程图。通过文件服务器编索引引擎,例如服务器110中的编索引引擎114以及NE 200实施方法500。当创建和/或更新文件和/或目录时,实施方法500。方法500类似于方案300,其中散列技术用于通过目录名分割文件系统,例如,文件系统117。方法500可以通过分区,例如分区330将目录名存储在例如散列表112的散列表中。例如,散列表可以包括由散列代码编索引的多个集合,其中每个集合可以对应于分区并且可以存储对应于分区的目录名。在步骤510处,通过应用BuzHash函数计算目录名的散列值,以用于举例说明。在步骤520处,确定是否在计算出的散列值与散列表中的散列代码之间找到匹配。如果找到匹配,接下来在步骤560中,目录名存储在由所匹配散列代码识别的分区(例如,集合)中。例如,可以产生用于将目录名映射到所匹配散列代码的条目。否则,方法500前进到步骤530。在步骤530处,确定当前操作分区是否包括多于20K个目录(例如,分区的最大大小)。如果当前操作分区包括少于20K个目录,接下来在步骤570处,目录名存储于当前操作分区中。例如,可以产生用于将目录名映射到当前操作分区的散列代码的条目。否则,方法500前进到步骤540。应注意,最大分区大小可以可替代地如由本领域普通技术人员所确定构造成实现类似功能。
在步骤540处,创建新分区并且在计算出的散列值下为所述新分区编索引。在步骤550处,目录名存储在新分区中。例如,可以产生用于将目录名映射到计算出的散列代码的条目。因此,当方法500首先应用于分割文件系统时,取决于第一扫描目录用散列值为第一分区编索引,并且在第一分区达到最大分区大小之前,可以将后续目录放入同一分区中。对于文件系统中的下一目录,可以重复方法500。如上所述,在文件系统的初始爬行期间,例如通过采用方案400基于目录名扫描目录。因此,按目录名的顺序并且基于爬行时间分割文件系统。由于文件和/或目录更新引起的后续爬行基于更改时间。因此,在初始分割之后按更改时间的顺序分割文件系统。
图6是布隆过滤器产生方案600的实施例的示意图。文件服务器搜索引擎,例如,服务器110中的搜索引擎115采用方案600。在例如文件系统117的文件系统670例如通过采用如在方案300和400以及方法500中描述的类似机构分成多个分区630,例如分区330之后实施方案600。在当文件和/或目录被创建和/或插入文件系统时的初始分割以及当更改文件系统时的重新分割期间,可以采用方案600。例如,分区630的目录名存储于例如散列表112和340的散列表中。在方案600中,针对每个分区630产生布隆过滤器640,例如布隆过滤器113。布隆过滤器640是被设计成测试元素(例如,目录名)是否存在于集合(例如,在分区630中)中的概率型结构数据。布隆过滤器640允许误报匹配,但不允许漏报匹配。因此,布隆过滤器640减少查询搜索所需的分区630的数目(例如,减少约90%至95%)。在实施例中,当分区630包括约30K个目录时,布隆过滤器640可以构造成约32K个位长的位向量。为了产生布隆过滤器640,首先将布隆过滤器640中的所有位初始化为零并且将对应分区630中的目录名添加到布隆过滤器640以创建集合。为了将目录名添加到布隆过滤器640,k次散列目录名(例如,通过k个散列函数)以在布隆过滤器640的位向量中产生k个位位置并且位设定成1,其中k可以约为4。在一个实施例中,每个目录名作为一个元素添加到布隆过滤器640,其中k个散列函数应用于全部目录名。在一些其它实施例中,目录名(例如,/a/b/c)可以分成多个元素(例如,/a,/b,/c),并且每个元素作为单独元素添加在布隆过滤器640中,其中k个散列函数单独应用于每个元素。应注意,取决于分区630中的目录名的数目以及误报匹配的所需可能性,布隆过滤器640可以配置有不同长度和/或不同数目的散列函数。
图7是元数据索引搜索查询方案700的实施例的示意图。文件服务器搜索引擎,例如,服务器110中的搜索引擎115可以采用方案700。当例如从客户端,例如客户端120接收文件系统对象(例如,文件或目录)的查询760时实施方案700。例如,例如文件系统117和670的文件系统分成多个分区,例如分区330和630,针对每个分区产生布隆过滤器740,例如布隆过滤器113和640,并且针对每个分区产生一个或多个元数据DB 750,例如元数据DB 111。可以通过采用如在方案300和400以及方法500中所描述的类似机构来分割文件系统。可以通过采用如在方案600中所说明的类似机构来产生布隆过滤器740。如上所述,可以基于目录名分割文件系统并且可以通过散列对应分区中的目录名以产生对应分区中的目录名的表示(例如,编码后的散列信息)来产生布隆过滤器740。例如,布隆过滤器B(P1)至B(PN)740分别是文件系统的分区P1至PN中的目录名的表示。在方案700中,在接收查询760之后,查询760可以穿过每个布隆过滤器740以测试对应分区是否可以包括与查询760相关的数据。由于布隆过滤器740是目录名的表示,因此查询760可以包括目录名的至少一部分。例如,为了搜索文件/a/b/c/data.c,查询760可以包含路径名的至少一部分,例如/a、/a/b或/a/b/c。查询760可以另外包含其它元数据,例如与文件data.c相关联的文件基本名(例如,data.c)、文件类型、用户ID、组ID、访问时间和/或自定义属性,如下文更充分地论述。为了测试特定分区中的匹配,k次散列查询760以获得k个位位置。当布隆过滤器740对于所有k个位传回值1时,特定分区可以包括用于查询760的可能匹配。当k个位中的任一个包括零值时,特定分区肯定不包括与查询760相关的数据。因此,如果对应布隆过滤器740指示可能匹配,可以仅进行特定分区中的进一步搜索。例如,当布隆过滤器B(P1)740传回查询760的可能匹配时,搜索分区P1的元数据DB 750。否则,搜索跳过分区P1的元数据DB 750。在实施例中,Unix系统调用strtok()可以用于从存储于元数据DB 750中的密钥提取路径名,其中密钥可以类似于表1中所示的密钥。应注意,布隆过滤器740可以可替代地用于表示其它类型的元数据,其中查询760可以用于包含由布隆过滤器740表示的与元数据相关联的至少一个元素。
图8是元数据索引搜索查询方法800的实施例的流程图。文件服务器搜索引擎,例如,搜索引擎115以及NE 200实施方法800。方法800采用如在方案700中所描述的类似机构。当搜索例如文件系统117的可大规模扩展的存储文件系统中的文件系统对象时实施方法800。例如,可以通过采用方案300和方法500将文件系统分成多个分区,例如,分区330和630。当例如从例如客户端120的客户端接收文件系统对象的查询时,方法800开始于步骤810处。文件系统对象可以是文件或目录。通过路径名识别文件系统对象。查询包含路径名的至少一部分。在步骤820处,在接收查询之后,布隆过滤器应用于所查询文件系统对象的路径名的部分。布隆过滤器类似于布隆过滤器113、640和740。布隆过滤器包括例如通过采用方案600产生的可大规模扩展的存储文件系统的特定部分的文件系统对象路径名的表示。在步骤830处,确定布隆过滤器是否传回指示所查询文件系统对象可能映射到特定文件系统部分的肯定结果。在一个实施例中,可以通过添加每个路径名的条目来产生布隆过滤器。在此实施例中,查询包括所查询文件系统对象的路径名并且布隆过滤器应用于所查询文件系统对象路径名。在另一实施例中,可以通过添加路径名(例如,/a/b/c)的每个组分(例如,/a、/b和/c)的条目来产生布隆过滤器。在此实施例中,所查询文件系统对象路径名(例如,/x/y/z)被分成多个组分(例如,/x、/y和/z)并且布隆过滤器应用于每个路径名组分。肯定结果对应于所有路径名组分的肯定匹配。否定结果对应于路径名组分中的任一个的否定匹配。
如果布隆过滤器传回肯定结果,接下来在步骤840处,针对所查询文件系统对象搜索包括特定文件系统部分的元数据编索引信息的关系DB。关系DB可以类似于元数据DB 111。例如,关系DB可以包括多个表,其中每个表可以存储与特定文件系统部分中的文件系统对象相关联的特定类型的元数据。表可以存储密钥值对中的元数据,如在上述表1和2中示出。例如,元数据类型可以与基本名、完整路径名、文件大小、文件类型、文件扩展名、文件访问时间、文件更改时间、文件修改时间、组ID、用户ID、权限和/或自定义文件属性相关联。在实施例中,查询可以包括文件系统对象的路径名和文件系统对象的元数据,其中下文更充分地描述查询的格式。可以通过首先定位与所查询文件系统对象的路径名对应的设备数目和索引节点数目(例如,根据PATH表)来搜索关系DB。随后,可以通过定位具有设备数目和索引节点数目的条目以及确定是否在所查询元数据与所定位条目之间找到匹配来检索关系DB中的其它表。
如果布隆过滤器在步骤830处传回指示所查询文件系统对象未映射到特定文件系统部分的否定结果,方法800前进到步骤850。在步骤850处,跳过对关系DB中的所查询文件系统对象的搜索。应注意,布隆过滤器可以传回误报匹配,但不可以传回漏报匹配。对于表示文件系统的另一部分的另一布隆过滤器,可以重复步骤820至850。
图9是元数据DB存储方案900的实施例的示意图。文件服务器编索引引擎,例如,服务器110中的编索引引擎114采用方案900来实施例如元数据DB 117和670的文件系统元数据DB,用于文件系统编索引。方案900采用LSM树技术以通过推迟更新以及分批更新提供有效的编索引更新。在方案900中,元数据dB由两个或多于两个树状组分数据结构910(例如,C0至Ck)组成。数据结构910包括类似于在上述表1和2中所示的条目的密钥值对。如图所示,第一级数据结构C0 910存储于例如文件服务器110的文件服务器或NE 200的本地系统存储器981,例如存储器设备232中,其中本地系统存储器可以提供快速访问。在后续级中的数据结构C1至Ck 910存储在例如硬盘驱动器的磁盘982上,所述磁盘与本地系统存储器981相比可以包括较慢访问速度。驻留在本地系统存储器981中的数据结构C0 910的大小通常小于存储在磁盘982上的数据结构C1至Ck 910。另外,对于每个后续级,数据结构C1至Ck 910的大小可以增加。数据结构C0 910用于存储最近更新的元数据。当数据结构C0 910达到特定大小时或在特定时间之后,数据结构C0 910移转到磁盘982中。当数据结构C0 910转移到磁盘982中时,数据结构C0 910合并到下一级数据结构C1 910中并且在下一级数据结构C1 910中分类。对于后续级的数据结构C2至Ck-1 910,可以重复合并-分类过程。因此,当采用LSM树技术来实施元数据DB时,延迟更新并且分批执行更新。当检索元数据DB时,搜索可以首先扫描驻留在本地系统存储器981中的数据结构C0 910。当未找到匹配时,搜索可以继续到下一级数据结构910。因此,方案900还可以允许有效搜索。应注意,levelDB是采用方案900中所示的LSM技术的数据库的类型。
图10是文件系统元数据更新方法1000的实施例的流程图。通过文件服务器编索引引擎,例如服务器110中的编索引引擎114以及NE 200实施方法1000。在文件服务器编索引引擎已为文件系统编索引之后实施方法1000。例如,可以通过如在方案300和400以及方法500中所描述的散列技术由目录名分割文件系统。例如分区330和630的分区可以存储在例如散列表112和340的散列表中。另外,例如通过采用方案600和方法800产生分区的布隆过滤器,例如,布隆过滤器113、640和740。此外,例如可以通过采用方案900产生分区的元数据DB,例如,元数据DB 111和750。当在例如文件系统117的文件系统中检测到更改时,方法1000开始于步骤1010处。更改可以是文件或目录移除、添加、移动或文件更新。一些操作系统(例如,Unix和Linux)可以提供应用程序编程接口(application programming interface,API)或系统调用(例如,inotify()),以监视文件系统更改。在步骤1020处,在检测到文件系统更改之后,通过更新散列表,例如通过采用如在方案300和方法500中所示的类似机构重新分割文件系统。在步骤1030处,在重新分割文件系统之后,例如通过采用方案600更新一个或多个对应布隆过滤器。例如,当移动目录时,前一个路径名可以从前一个分区移除并且更新后的路径名可以添加到更新后的分区。因此,可以更新与前一个分区和更新后的分区对应的布隆过滤器。在步骤1040处,通过更新对应于更新后的分区的一个或多个元数据DB,例如通过采用方案900来为文件系统重新编索引。
在实施例中,例如客户端120的客户端可以将例如查询760的查询发送到例如文件服务器110的文件服务器,以搜索例如文件系统117的文件系统中的文件系统对象(例如,文件或目录)。可以如下所示格式化查询:
<Variable><relop><constant>&<variable><relop><constant>,
其中变量可以是任何类型的文件系统元数据,例如,路径名、基本名、用户ID、组ID、文件大小、与文件相关联的多个链路、权限(例如,八进制0644)、文件类型、文件访问时间、文件更改时间、文件修改和自定义文件属性。下表概括查询变量:
表3-查询变量的实例
relop可以表示关系运算符,例如大于(例如,>)、大于或等于(例如,>=)、小于(例如,<)、小于或等于(例如,<=)、等于(例如,=)或不等于(例如,)。应注意,当文件服务器基于路径名采用布隆过滤器,例如布隆过滤器113时,查询可以包括对应于所查询文件系统对象的路径名的至少一部分的至少一个变量。例如,查询中的第一变量可以是路径名变量。因此,当执行元数据索引搜索时可以采用前缀搜索。以下列出查询的一些实例:
path=/proj/a/b/c/&base=random.c
path=/proj/a/b/c/&links>1。
虽然本发明中已提供若干实施例,但应理解,在不脱离本发明的精神或范围的情况下,所揭示的系统和方法可以以许多其它特定形式来体现。本发明的实例应被视为说明性而非限制性的,且本发明并不限于本文本所给出的细节。例如,各种元件或组件可以在另一系统中组合或合并,或者某些特征可以省略或不实施。
另外,在不脱离本发明的范围的情况下,各种实施例中描述和说明为离散或单独的技术、系统、子系统和方法可以与其它系统、模块、技术或方法进行组合或合并。展示或论述为彼此耦合或直接耦合或通信的其它项也可以采用电方式、机械方式或其它方式通过某一接口、设备或中间组件间接地耦合或通信。变化、替代和改变的其它实例可以由本领域的技术人员在不脱离本文所揭示的精神和范围的情况下确定。
- 还没有人留言评论。精彩留言会获得点赞!