用于零样本学习的多模态流形嵌入方法与流程
本发明涉及一种零样本学习的特征嵌入方法。特别是涉及一种用于零样本学习的多模态流形嵌入方法。
背景技术:
随着现实应用的需要,零样本学习获得了大量的关注。其常用方法是将已见过类别的图像模态和文本模态转换到一个公共的嵌入空间,并将未见过类别的图像模态映射到公共空间寻找其对应的文本模态。以此来判断其所属的类别。
从嵌入空间的角度看,零样本学习可以分为三种类别:基于属性特征的方法,基于文本向量的方法以及同时利用属性特征和文本向量的方法。
基于属性特征的方法:基于属性的方法在零样本学习中已经有较长时间,这种方法首先对已见过类别和未见过类别建立一个属性空间,然后仅利用他们的描述对未见过类别进行分类,这种基于属性特征的方法的缺点是在训练和测试的时候需要用到可观测样本和未观测样本的属性特征,这种特征需要人工标注,因此不适用于大规模的零样本学习。
基于文本矢量的方法:随着语言技术的快速发展,基于文本矢量的方法在零样本学习中流行起来。许多神经语言模型的提出,使得能将一个文本转换成一个连续的矢量。利用神经语言模型,将一个词或者一个句子表示成一个连续的矢量,这样所有的类别名字都可以嵌入到一个文本矢量空间中。通常来说,如果两个词在语义上相似,其对应的文本矢量在矢量空间中也相似。因此基于文本特征的零样本学习的关键就是如何将图像特征转换到文本失量空间。基于文本特征的方法不需要对特征进行人工标注,所以可以避免基于属性特征的方法的缺点。
属性特征和文本矢量特征相结合的方法:属性特征和文本矢量特征在零样本学习中可以互补,为了挖掘更多的语义信息,当前许多研究将属性特征和文本特征相结合以获得更好的分类效果,但这种方法同样存在着与基于属性特征方法的缺点,不能应用于大规模的零样本学习中。
技术实现要素:
本发明所要解决的技术问题是,提供一种可以将不同模态的特征映射到一个公共空间,在这个空间中可以计算不同模态之间相似度的适用于大规模零样本学习的用于零样本学习的多模态流形嵌入方法。
本发明所采用的技术方案是:一种用于零样本学习的多模态流形嵌入方法,包括如下步骤:
1)输入训练样本的图像特征X=[X1,...,Xi,…,Xn],图像所对应的文本向量特征以及权重参数α,β,λ,
其中,Xi是第i类的训练样本的图像特征,yi是第i类的文本向量特征,q是文本向量特征的维度,n是文本向量的个数;
2)分别计算每一类训练样本的对角矩阵和边缘权重矩阵以及每一类训练样本对应的拉普拉斯矩阵Li=Di-Si
其中,Di是第i类的训练样本的对角矩阵,ti是第i类的样本个数,是第i类的第j个样本和第k个样本的相似度,的计算公式为其中,σ是带宽,Si是第i类的边缘权重矩阵;
3)利用每一类的拉普拉斯矩阵Li构建所有类别的拉普拉斯矩阵L=diag{L1,...,Li,...,Ln};
4)利用公式计算多模态流形嵌入矩阵W,其中I是单位矩阵。
步骤1)中所述的α,β和λ是用于调节目标函数中不同目标之间的权重。
所述的α,β和λ是在实验中通过交叉验证的方法获得的。
本发明的用于零样本学习的多模态流形嵌入方法,对当前的多模态嵌入方法进行了改进,充分利用了数据之间的流形信息,达到了有效利用数据信息,提高分类效果的目的,是一种适用于多模态分类和检索相关领域的嵌入方法。本发明的方法属于基于文本矢量的方法,可以将不同模态的特征映射到一个公共空间,在这个空间中可以计算不同模态之间的相似度。本发明主要优势体现在:
1、新颖性:把流形信息引入到多模态映射中,并在此基础上充分利用数据之间的判别信息,将同类样本之间类内紧致性以及不同类样本之间的类间分离性加入到目标函数中,充分挖掘数据之间的判别信息和流形信息,提出了适合零样本学习的特征映射方法。
2、多模态性:所提供的方法是基于多模态嵌入的特征转换方法。本发明是将一种特征空间中的特征转换到另一种空间中的方法,以达到计算不同空间的特征之间相似度的目的。
3、有效性:通过实验证明了与线性回归方法和其他未利用流形方法相比较,本发明设计的多模态流形映射算法在零样本学习中的性能明显占优,因此更适用于多模态嵌入学习。
4、实用性:简单可行,本发明时间复杂度低,速度快。可以应用在其他的多模态分类和检索等相关领域。
附图说明
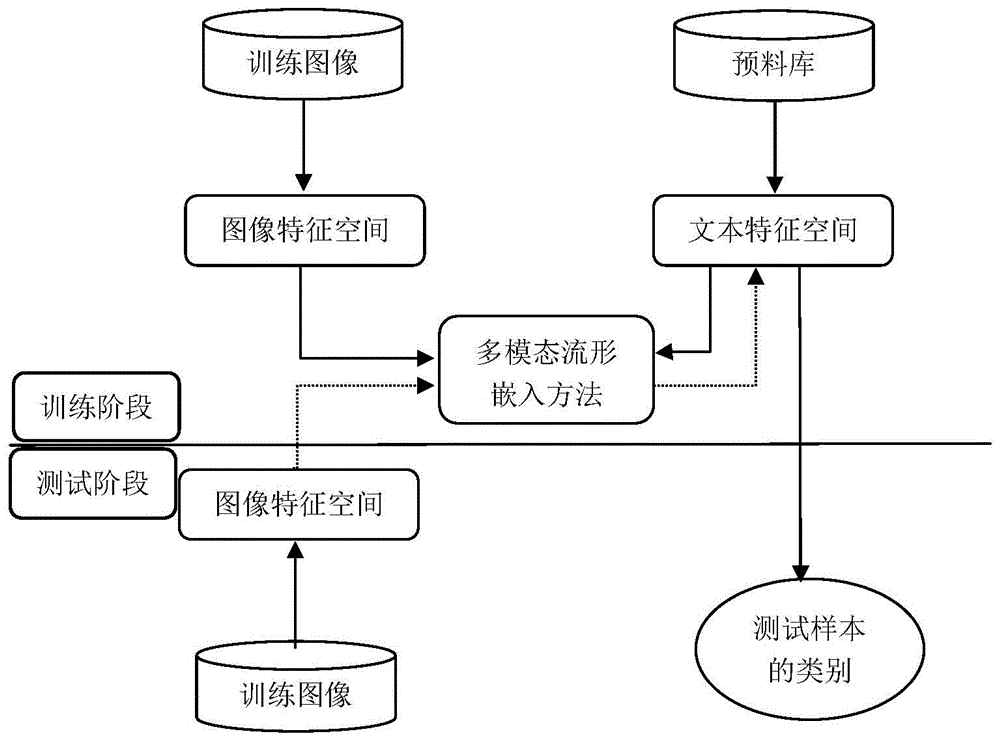
图1是本发明用于零样本学习的多模态流形嵌入方法实际应用的流程图;
图2是本发明中计算多模态流形嵌入矩阵的流程图。
具体实施方式
下面结合实施例和附图对本发明的用于零样本学习的多模态流形嵌入方法做出详细说明。
本发明的用于零样本学习的多模态流形嵌入方法,主要是在传统的最小二乘回归方法的基础上,加入了局部流形约束,将同一模态样本之间的流形信息在映射前后进行保持,同时在目标函数中加入类内紧致性和类间分离性,使映射后的样本靠近对应模态下的同类样本,并与对应模态下的不同类样本相分离。下面利用图像模态和文本模态作为两个具体的模态来阐述本发明所提的方法。
训练样本的图像特征矩阵用X=[X1,...,Xn]表示,其中表示第i类的数据,ti为第i类的训练样本数,表示第i类第j个样本的图像特征。表示已见过类别对应的文本向量矩阵。本发明的目的是利用训练样本集ΨS={(Xi,si),1≤i≤n}学习一个映射函数将图像特征映射到文本向量空间,然后在测试时,利用映射函数yt=F(xt)将测试样本xt映射到文本向量空间,将与yt最近的文本类别名作为测试样本的类别。其中映射函数可以分为线性和非线性两种,本发明采用的是线性函数,其表达式是:yt=WTxt,W为多模态嵌入矩阵。
本发明的目标包含三个部分分别是:类内紧致性,类间分离性,局部流形结构保持,其中,类内紧致性是指嵌入向量应该与视觉样本对应的文本向量特征越近越好;而与此相对应,类间分离性是指嵌入向量应与其他类别的文本向量相分离;局部流形结构保持是指在特征空间转换前后样本之间的空间几何结构保持不变,即在原始空间中距离近的两个样本其对应的嵌入空间中的样本之间的距离依然很近,在原始空间中距离远的两个样本在嵌入空间中的距离依然很远。三个部分具体是:
1)图像特征转换到文本空间中的嵌入向量与对应的文本向量之间的类内紧致性:
假设我们的线性嵌入矩阵是这样我们就可以得到图像样本特征的嵌入向量即类内紧致性是指:嵌入向量应该与图像样本对应的文本向量特征yi越近越好,所以我们最小化目标函数J1来表示类内紧致性:
2)图像特征转换到文本空间中的嵌入向量与其他的文本向量之间的类间分离性;与类内紧致性相对应,一个类所有的图像特征样本转换后的嵌入向量应该与其他类别的文本向量越远越好,所以我们最大化目标函数J2来表示类间的分离性:
3)图像特征在转换前后要保持其局部流形结构,即在图像特征空间中两个距离相近的样本在转换到文本向量空间后仍然相近,距离远的两个样本在转换到文本向量空间仍然远。除了最小化类内紧致性和类间的分离性,数据本身的内部几何结构在转换前后保持不变。利用最小化目标函数J3来实现局部保持的目标:
其中是相似度矩阵,是测量图像样本和之间相似性的热核函数,为对角矩阵,Li=Di-Si是拉普拉斯矩阵,L=diag{L1,...,Ln}。
通过以上分析,最终的目标函数为:
J=J1-αJ2+βJ3+λ||W||2, (4)
其中||W||2为正则项,α,β和λ是用于调节目标函数中不同目标之间的权重。
经过数学推导后可以得到最终嵌入矩阵的显示表达式为:
其中I为单位矩阵,可以看出嵌入矩阵只与训练样本的图像特征X和文本向量特征Y有关。
如图2所示,本发明的用于零样本学习的多模态流形嵌入方法,包括如下步骤:
1)输入训练样本的图像特征X=[X1,...,Xi,…,Xn],图像所对应的文本向量特征以及权重参数α,β,λ,
其中,Xi是第i类的训练样本的图像特征,yi是第i类的文本向量特征,q是文本向量特征的维度,n是文本向量的个数,所述的α,β和λ是用于调节目标函数中不同目标之间的权重,所述的α,β和λ是在实验中通过交叉验证的方法获得的;
2)分别计算每一类训练样本的对角矩阵和边缘权重矩阵以及每一类训练样本对应的拉普拉斯矩阵Li=Di-Si
其中,Di是第i类的训练样本的对角矩阵,ti是第i类的样本个数,是第i类的第j个样本和第k个样本的相似度,的计算公式为其中,σ是带宽,Si是第i类的边缘权重矩阵;
3)利用每一类的拉普拉斯矩阵Li构建所有类别的拉普拉斯矩阵L=diag{L1,...,Li,...,Ln};
4)利用公式计算多模态流形嵌入矩阵W,其中I是单位矩阵。
将本发明的用于零样本学习的多模态流形嵌入方法应用到零样本学习中。如图1所示,在训练阶段,首先分别对图像和文本提取特征,对图像提取图像特征并利用神经语言模型从语料库中提取与图像对应的文本向量。然后利用本发明的用于零样本学习的多模态流形嵌入方法将图像和文本两个空间中的特征映射到多模态流形嵌入矩阵;在测试阶段,首先提取未见过类别的测试图像的图像特征,然后利用学习到的嵌入矩阵将图像特征映射到文本向量空间,并将与映射向量最近的文本向量作为测试图像的类别。
- 还没有人留言评论。精彩留言会获得点赞!