异常交易数据的获取方法和装置与流程
本申请涉及互联网技术领域,特别涉及一种异常交易数据的获取方法和装置。
背景技术:
随着互联网的飞速发展,电子商务在整个商业领域的地位越来越重要。互联网交易中虚假交易也越来越多,且升级为多个用户团伙作弊的特征等更加隐蔽的模式,这对整个电子商务平台产生了严重的负面影响。现有的异常交易的识别技术已较难适应如今变化多端的团伙作弊模式。目前可通过以下方法发现异常交易方法:
1)收集大量异常交易数据作为识别正样本;
2)结合业务知识设计相关识别特征;
3)通过人工数据分析或机器学习分类算法挖掘相关模式与规则;
4)根据挖掘的模式规则,从原始交易数据中发现异常交易。
但是,上述方法需要人工判别数据,消耗的人力资源很多,尤其是在大数据背景下此问题尤为严重。其次,该方法需要结合大量的业务背景知识,针对不同业务场景设计不同的算法,得到的模型缺少可解释性。另外,对于团伙作弊的异常交易,由于其隐蔽性较高,因此基于交易表面特征的方法已经较难适应,召回率远不能满足现有业务场景的需求。
技术实现要素:
本申请旨在至少在一定程度上解决上述技术问题。
为此,本申请的第一个目的在于提出一种异常交易数据的获取方法,能够有效识别团伙作弊交易模式的异常交易,提高异常交易的召回率。
本申请的第二个目的在于提出一种异常交易数据的获取装置。
为达上述目的,根据本申请第一方面实施例提出了一种异常交易数据的获取方法,包括以下步骤:获取目标产品的用户交易数据,其中,所述用户交易数据包括用户信息和交易编号;根据所述用户信息对用户进行群组划分,为每一群组对应生成群组标签;根据各群组标签对应的用户交易数据获取所述目标产品的用户分布信息;根据所述用户分布信息计算用户分布的信息熵,判断所述用户分布信息是否符合预设分布;如果所述用户分布信息不符合所述预设分布,则根据各群组标签对应的交易数据的数量筛选出一个或多个群组;以所述筛选出的群组及其交易数据作为异常交易群组及其异常交易数据。
本申请实施例的异常交易数据的获取方法,可根据交易数据中的用户信息生成群组标签,并根据群组标签对用户进行群组划分,并根据各群组对应的用户交易数据获取目标产品的用户分布信息,并在用户分布信息不符合预设分布时,根据各群组标签对应的交易数据的数量筛选出异常交易数据对应,能够有效识别团伙作弊交易模式的异常交易,提高异常交易的召回率。
本申请第二方面实施例提供了一种异常交易数据的获取装置,包括:第一获取模块,用于获取目标产品的用户交易数据,其中,所述用户交易数据包括用户信息和交易编号;生成模块,用于根据所述用户信息对用户进行群组划分,为每一群组对应生成群组标签;第二获取模块,用于根据各群组标签对应的用户交易数据获取所述目标产品的用户分布信息;判断模块,用于根据所述用户分布信息计算用户分布的信息熵,判断所述用户分布信息是否符合预设分布;筛选模块,用于当所述用户分布信息不符合所述预设分布时,根据各群组标签对应的交易数据的数量筛选出一个或多个群组,并以所述筛选出的群组及其交易数据作为异常交易群组及其异常交易数据。
本申请实施例的异常交易数据的获取装置,可根据交易数据中的用户信息生成群组标签,并根据群组标签对用户进行群组划分,并根据各群组对应的用户交易数据获取目标产品的用户分布信息,并在用户分布信息不符合预设分布时,根据各群组标签对应的交易数据的数量筛选出异常交易数据对应,能够有效识别团伙作弊交易模式的异常交易,提高异常交易的召回率。
本申请的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
本申请的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本申请一个实施例的异常交易数据的获取方法的流程图;
图2为根据本申请图1所示实施例中s104的流程图;
图3为根据本申请一个实施例的根据用户分布信息计算用户分布的信息熵的方法流程图;
图4为根据本申请一个实施例的拟合预估函数的流程图;
图5为根据本申请另一个实施例的异常交易数据的获取方法的流程图;
图6为根据本申请一个实施例的异常交易数据的获取架构图;
图7为根据本申请一个实施例的异常交易数据的获取装置的结构示意图;
图8为根据本申请另一个实施例的异常交易数据的获取装置的结构示意图。
具体实施方式
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本申请,而不能理解为对本申请的限制。
下面参考附图描述根据本申请实施例的异常交易数据的获取方法和装置。
图1为根据本申请一个实施例的异常交易数据的获取方法的流程图。
如图1所示,根据本申请实施例的异常交易数据的获取方法,包括以下步骤。
s101,获取目标产品的用户交易数据,其中,用户交易数据包括用户信息和交易编号。
其中,用户交易数据可为用户在互联网购物平台上的交易。例如,可以是购物交易等。用户信息可包括买家的账户、姓名、收货地址、联系方式、社交关系、用户的硬件信息、ip(internetprotocol,网络之间互连的协议)地址等。交易编号可为交易订单号等。举例来说,用户交易数据的数据格式可为:{交易id,产品id}。
s102,根据用户信息对用户进行群组划分,为每一群组对应生成群组标签。
其中,一个群组标签唯一标识一个用户群组。在本申请的一个实施例中,可针对目标产品收集大量用户交易数据,并根据用户交易数据中的用户信息生成群组标签。添加群组标签后用户交易数据的数据格式可为:{交易id,产品id,群组标签(grouptag)}。
在本申请的一个实施例中,可根据用户信息计算用户组群关系特征,并将用户组群关系特征作为群组标签。例如,可基于lpa(labelpropagationalgorithm,标签传播算法)、fnca(fastnetworkclusteringalgorithm,快速社区挖掘算法)等社区发现算法从用户信息中生成群组标签。举例来说,通过社区发现算法挖掘出两个交易数据a和b中的用户为同一用户或者为属于同一社交圈m的用户,则可为交易数据a和b生成群组标签“m”。
在本申请的另一个实施例中,如果用户信息为用户的硬件信息,则可根据用户的硬件信息生成群组标签。举例来说,如果两个交易数据c和d中用户的设备标识都是“n”,则可为交易数据c和d生成群组标签“n”。
或者,可将用户的ip地址等信息直接作为群组标签。
因此,可以看出,一个交易数据可具有一个或多个群组标签,一个群组标签中也可标记一个或多个交易数据中的用户群组信息。
需要说明的是,由于一个买家可以属于多个用户群组,因此同一买家可以以多个用户群组的身份完成针对同一产品的交易,由于无法获知买家是以哪一个群组(一个用户群组对应一个群组标签)的身份参加的交易活动,因此同一个交易id可以带有多个群组标签,即交易数据中存在交易id相同,但是群组标签不同的数据。
s103,根据各群组标签对应的用户交易数据获取目标产品的用户分布信息。
其中,用户分布信息为用户对应的交易数据基于各个群组标签的分布情况。本申请的实施例中,可根据交易数据中各个群组标签中的数量以及交易编号与用户信息的对应关系确定用户分布在各个群组中的数量,即用户分布信息。
s104,根据用户分布信息计算用户分布的信息熵,判断所述用户分布信息是否符合预设分布。
在本申请的一个实施例中,可通过目标产品对应的用户分布的信息熵来判断用户分布信息是否符合预设分布。用户分布的信息熵越大,则表示目标产品的用户越近似随机分布,用户分布的信息熵越小,则表示目标产品的用户存在个别群组聚集的情况。
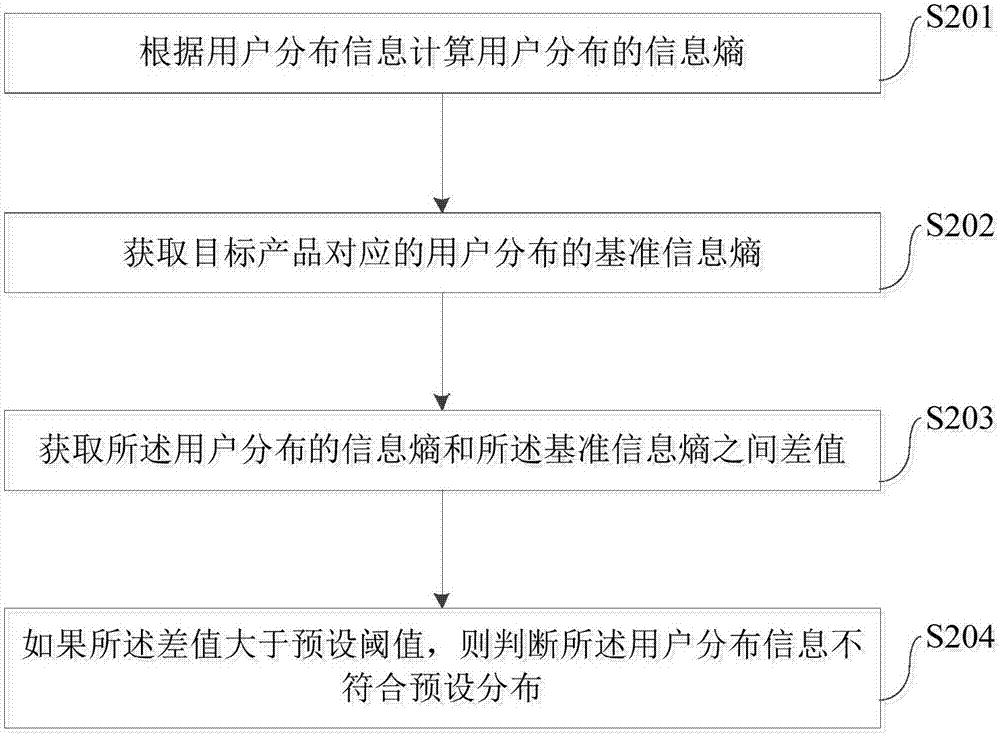
具体地,在本申请的一个实施例中,s104可具体包括步骤s201-s204。
s201,根据用户分布信息计算用户分布的信息熵。
考虑到现实数据中,同一个用户在不同的时间窗口内可以属于不同的用户群组,交易数据中存在交易粒度的重复数据。因此在本申请的一个实施例中,可采用基于最大化用户群体的二次哈希方法,削弱多标签数据在计算用户分布的信息熵的过程中引入的噪音,从而强化隐性团体的用户聚集度,使用户分布接近真实分布,并且适合多标签这类复杂识别模式。图3为根据本申请一个实施例的根据用户分布信息计算用户分布的信息熵的流程图。
如图3所示,根据用户分布信息计算用户分布的信息熵,包括以下步骤。
s301,以群组标签为主键、交易编号为值对用户交易数据进行整理,以生成第一交易列表。
其中,群组标签用grouptag表示,交易编号用biz表示。
具体地,以grouptag为主键对所有用户交易数据进行哈希map存储,生成第一交易列表,其中,第一交易列表中的主键为grouptag,值为与grouptag对应的交易编号biz列表。举例来说,第一交易列表的存储格式可为:
其中,该哈希map的主键grouptagi表示目标产品的第i组买家对应的群组标签,bizi,j表示第i组买家购买的第j笔交易的交易编号,其中,i=1,...,m1,j=1,...,mi,m1表示第一交易列表中群组标签grouptag的总数,mi表示第i组群组标签对应的交易编号列表大小。
也就是说,第一交易列表中包括m1个群组标签,其中,第i个群组标签对应有mi个交易编号。
s302,以交易编号为主键、群组标签为值对用户交易数据进行整理,以生成第二交易列表。
具体地,与步骤s301类似,以biz为主键对所有用户交易数据进行哈希map存储生成第二交易列表。其中,第二交易列表的主键为biz,值为与biz对应的群组标签grouptag列表。举例来说,第二交易列表的存储格式可为:
其中,该哈希map的主键bizp表示目标产品的第p笔交易的交易编号,bizp,q表示第p笔交易的第q个群组标签,q=1,...,np,np表第p笔交易具有的群组标签的总数。
s303,根据预设条件对第二交易列表中每个交易编号对应的群组标签进行压缩,以使第二交易列表中每个交易编号具有唯一对应的群组标签。
具体地,可对bizmap进行压缩,即取交易编号bizp对应的最大组群(具有最大交易量的标签)作为交易编号bizp所属的组群,具体可通过以下公式进行筛选:
其中,
举例来说,交易编号bizp属于3个组群,即具有3个群组标签,分别为1、2、3,其中,根据第一交易列表知道群组标签1、2、3分别对应5个、10个、6个交易编号。则可将群组标签2作为bizp唯一对应的群组标签。
由于同一个用户可以存在于多个群组,因此交易数据中存在具有多标签的交易数据,即同一个biz可以属于不同的grouptagi。为此,本申请的实施例中采用最大化群组的思想,即将该biz归属于目标产品的最大群组的方法来弱化同一个买家属于不同群组在计算产品特征熵过程中带来的噪音。由此,能够提高群组的聚集性,最大化异常群体。
s304,以群组标签为主键、交易编号为值对压缩后的第二交易列表进行整理,以生成第三交易列表。
也就是说,将压缩后的第二交易列表bizmapmax中的数据以群组标签为主键、交易编号为值进行哈希map存储,得到第三交易列表grouptagmapmax,其存储格式可为:
其中,该哈希map的主键grouptagi表示目标产品的第i组买家对应的群组标签,bizi,j表示第i组买家购买的第j笔交易的交易编号,其中,i=1,...,m2,j=1,...,li,m2表示第三交易列表中群组标签grouptag的总数,li表示第i组群组标签对应的交易编号列表大小。
由于压缩后的第二交易列表bizmapmax中,每个交易编号具有唯一对应的群组标签,也就是说,在对第二交易列表进行压缩的过程中,删除了一部分群组标签与交易编号的对应关系。因此,当以群组标签为主键、交易编号为值对压缩后的第二交易列表bizmapmax进行整理之后,得到的第三交易列表相对于第一交易列表来说,群组标签与交易编号的对应关系也相应减少,且部分群组标签对应的交易编号的数量也相应减少。也就是说,上述m2≤m1,且li与mi也不一定相等。
s305,获取各群组标签在所述第三交易列表中的出现概率,并根据各出现概率计算所述用户分布的信息熵。
具体地,可基于grouptagmapmax中的grouptag数据按照如下公式计算用户分布的信息熵:
其中,entropy(grouptag)为所述用户分布的信息熵,p(grouptagj)为j第组群组标签在第三交易列表中的出现频率,j=1,...,m2,m2为第三交易列表中所包括的群组标签的总数。
举例来说,如果grouptagmapmax中的数据为:
{a:1,2,3,4},{b:5,6},也就是说,grouptagmapmax包括a和b两个群组标签,则群组标签a的出现频率为p(a)=4/6,群组标签b标签的出现频率为p(b)=2/6。
应当理解,上述示例是将交易数据为粒度进行群组标签划分,在本申请的其他实施例中,也可以用户为粒度进行划分,即每个买家的多笔交易仅算一笔交易的方式进行划分,来计算产品特征熵,效果类似。
s202,获取目标产品对应的用户分布的基准信息熵。
在现实的电子商务场景下,一般情况下商品的交易过程中买家应该具有近似随机的群组分布,然而在团伙刷单等异常交易场景中买家的分布在个别特征中体现出聚集性。用户分布的信息熵,作为一种衡量用户分布信息混乱程度的指标,能够恰如其分的刻画这种场景。当商品交易过程中买家用户近似随机分布时,用户分布的信息熵具有最大值,而当存在个别的团体聚集时,上述用户分布的信息熵的值将大幅度的减小。
因此,在本申请的实施例中,可将买家用户随机分布时的用户分布的信息熵作为用户分布的基准信息熵,并通过实际交易过程中实际的用户分布的信息熵与该基准信息熵进行比对来判断是否存在个别的团体聚集的情况。如果存在,则可判断出现了异常交易。
那么,首先需要获取目标产品的用户分布的基准信息熵。在本申请的一个实施例中,获取目标产品对应的用户分布的基准信息熵可具体包括:获取目标产品对应的产品交易量,根据预先拟合的预估函数和产品交易量生成目标产品对应的用户分布的基准信息熵。其中,预估函数为表示产品交易量与用户分布的基准信息熵函数关系的曲线。因此,可将目标产品的产品交易量带入预估函数,得到目标产品对应的用户分布的基准信息熵。
图4为根据本申请一个实施例的拟合预估函数的流程图。
如图4所示,根据本申请一个实施例,可通过以下步骤拟合预估函数。
s401,获取目标产品的样本交易数据。
具体地,可在用户交易数据中大规模采样得到各个产品的样本交易数据,其中,样本交易数据中包括交易编号、用户信息以及产品标识。
s402,根据交易数据样本分别获取目标产品在多个交易量下对应的用户分布的信息熵。
具体地,可根据产品标识对样本交易数据进行划分。从而,可得到不同产品对应的样本交易数据。对于每个产品,可提取出不同数量的交易数据,即得到多个不同交易量的交易数据,并计算与各个交易量相应的用户分布的信息熵。由此,可得到不同交易量下的用户分布的信息熵。不同交易量下的用户分布的信息熵的计算方法可参见图1所示实施例。交易量值可用d表示,用户分布的信息熵可用ef表示。
在样本中正常交易占绝大多数的假设下,可通过统计方法计算出各产品在不同交易量下的用户分布的信息熵,并分别作为不同交易量下的用户分布的基准信息熵。
举例来说,通过统计学方法,假设选取了n个不同的交易量进行统计分析,交易量d下的产品分布服从高斯分布n(μd,δd),取(d,max(0,μd-λδd))点为交易量d下的用户分布的信息熵的边界点,并作为交易量d下的用户分布的基准信息熵,其中λ∈(0,3)为衡量偏离度的参数。经过统计学计算后得到产品交易量与用户分布的基准信息熵的样本:
di=1:n:{xi=d,yi=max(0,μd-λδd)},其中,n为选取的不同交易量的个数。
s403,构建基准信息熵拟合函数。
其中,基准信息熵拟合函数可为
s404,根据多个交易量和多个交易量分别对应的用户分布的信息熵对基准信息熵拟合函数进行参数估计,以得到预估函数。
举例来说,为提高模型的泛化能力,可采用如下所示参数估计的方法:
首先,根据基准信息熵拟合函数的参数向量构建如下损失函数:
然后,根据多个交易量和多个交易量分别对应的用户分布的信息熵对上述损失函数进行优化,得到基准信息熵拟合函数的参数向量,由此得到参数确定的基准信息熵拟合函数,即预估函数。具体地,可基于损失函数采用各类成熟的优化算法(例如,拟牛顿、梯度下降、随机搜索算法等)进行优化求解,得到预估函数。
需要解释的是,上述统计学方法仅为示例性的,不应理解为对本申请的限制。计算用户分布的基准信息熵的方法可以用任何其他有效的统计学分析方法代替,并且上述各交易量下产品的分布可以采用如学生分布等其他各类适合具体业务的分布代替。上述参数估计方法也可用目前或未来可实现的任何有效的参数估计算法代替。
s203,获取所述用户分布的信息熵和所述基准信息熵之间差值。
s204,如果所述差值大于预设阈值,则判断所述用户分布信息不符合预设分布。
s105,如果所述用户分布信息不符合预设分布,则根据各群组标签对应的交易数据的数量筛选出一个或多个群组。
s106,以所述筛选出的群组及其交易数据作为异常交易群组及其异常交易数据。
在当前用户交易数据中异常交易数据和正常交易数据混杂的情况下,影响用户分布信息熵的往往是具有最大规模的群组,其在产品买家用户分布中呈现峰值状态,即用户在某一群组中具有高聚集度的特点。因此,在本申请的一个实施例中,可筛选出交易数据的数量最大的一个或多个群组,并以交易数据的数量最大的群组作为异常交易群组,以异常交易群组的交易数据作为异常交易数据。
其中,可根据上述第三交易列表
由此,可通过实际交易过程中的目标产品的用户分布的信息熵与相应的基准信息熵进行比对来判断是否存在异常交易数据,并进行提取,可解释性强,能够有效识别团伙作弊交易模式(如团伙刷单等)的异常交易,提高异常交易的召回率。
本申请实施例的异常交易数据的获取方法,可根据交易数据中的用户信息生成群组标签,并根据群组标签对用户进行群组划分,并根据各群组对应的用户交易数据获取目标产品的用户分布信息,并在用户分布信息不符合预设分布时,根据各群组标签对应的交易数据的数量筛选出异常交易数据对应,能够有效识别团伙作弊交易模式(如团伙刷单等)的异常交易,提高异常交易的召回率。
图5为根据本申请另一个实施例的异常交易数据的获取方法的流程图。
如图5所示,根据本申请实施例的异常交易数据的获取方法,包括步骤s501-s506。其中,s501-s506与图1所示实施例中s101-s106相同。进一步地,还可包括以下步骤。
s507,将异常交易数据从交易数据中删除,并更新产品交易量。
s508,根据更新后的产品交易量更新相应的基准信息熵。
从而,可根据删除异常交易数据后的交易量对应的用户分布的信息熵与更新后的交易量对应的基准信息熵进行比对,以判断是否存在异常数据。如果存在,则继续删除,并再次判断。
图6为根据本申请一个实施例的异常交易数据的获取架构图。如图6所示,可将用户交易数据输入群组标签挖掘模块,得到带群组标签的交易数据,并根据交易数据或者用户等粒度进行商品粒度汇总,得到商品交易数据。由商品特征熵计算模块根据商品交易数据计算目标产品的用户分布的信息熵。另外,基准熵预测模块根据基准熵拟合模块拟合出的预估函数预测目标产品的基准信息熵。通过异常特征熵判别模块将目标产品的用户分布的信息熵与基准信息熵进行比对以判断目标产品的用户分布的信息熵是否异常,如果异常,则通过异常交易剔除模块删除异常交易数据,并输出异常交易数据,同时更新剩余交易量(也可称为剩余销量),以便于商品特征熵计算模块继续根据更新后的交易量重新计算更新交易量后的用户分布的信息熵,并继续判断。
可以看出,可根据上述方法从用户交易数据中获取异常交易数据,并删除异常交易数据的过程可以是一个迭代过程,即删除之后,再次判断是否存在异常交易数据,如果存在则继续删除,并再次判断。直至用户交易数据中不再有异常交易数据,或者用户交易数据中包括的交易量小于预设的交易量阈值。具体迭代过程,可如下:
1)令i=1,
2)基于特征熵计算模块计算目标产品当前的用户分布的信息熵ef,i,并将商品的交易量di作为输入预估函数
3)若ed>ε且di>δ则基于grouptagmapmaxi剔除具有最大biz列表的grouptag数据(用grouptagk表示),即按如下方式更新:
其中,ε为控制目标产品的用户分布的信息熵与基准信息熵差值的预设阈值,δ为控制交易量(间接反映团伙规模)大小的参数,lj为该grouptagk对应的交易量。
4)更新剩余交易量di+1=di-lk,转2);否则算法终止。其中,lk为删除的异常交易数据对应的交易量。
5)输出3)、4)过程中删除的grouptag对应的全部交易作数据为异常交易数据。
本申请实施例的异常交易数据的获取方法,通过不断剔除目标产品的用户交易数据中最大规模的具有团伙特征的交易数据(异常交易数据)的贪心算法,不断剔除与输出异常交易数据,商品异常交易数据与正常交易数据的区分更加准确,能够挖掘具有高聚集度的团伙用户以及其对应的异常交易数据。
与上述实施例提供的异常交易数据的获取方法相对应,本申请还提出一种异常交易数据的获取装置。
图7为根据本申请一个实施例的异常交易数据的获取装置的结构示意图。
如图7所示,根据本申请实施例的异常交易数据的获取装置,包括:第一获取模块10、生成模块20、第二获取模块30、判断模块40和筛选模块50。
具体地,第一获取模块10用于获取目标产品的用户交易数据,其中,用户交易数据包括用户信息和交易编号。
其中,用户交易数据可为用户在互联网购物平台上的交易。例如,可以是购物交易等。用户信息可包括买家的账户、姓名、收货地址、联系方式、社交关系、用户的硬件信息、ip(internetprotocol,网络之间互连的协议)地址等。交易编号可为交易订单号等。举例来说,用户交易数据的数据格式可为:{交易id,产品id}。
生成模块20用于根据所述用户信息对用户进行群组划分,为每一群组对应生成群组标签。
其中,一个群组标签唯一标识一个用户群组。在本申请的一个实施例中,可针对目标产品收集大量用户交易数据,并根据用户交易数据中的用户信息生成群组标签。添加群组标签后用户交易数据的数据格式可为:{交易id,产品id,群组标签(grouptag)}。
在本申请的一个实施例中,生成模块20可用于:可根据用户信息计算用户组群关系特征,并将用户组群关系特征作为群组标签。例如,可基于lpa(labelpropagationalgorithm,标签传播算法)、fnca(fastnetworkclusteringalgorithm,快速社区挖掘算法)等社区发现算法从用户信息中生成群组标签。举例来说,通过社区发现算法挖掘出两个交易数据a和b中的用户为同一用户或者为属于同一社交圈m的用户,则可为交易数据a和b生成群组标签“m”。
在本申请的另一个实施例中,如果用户信息为用户的硬件信息,生成模块20可用于根据用户的硬件信息生成群组标签。举例来说,如果两个交易数据c和d中用户的设备标识都是“n”,则可为交易数据c和d生成群组标签“n”。
或者,生成模块20可将用户的ip地址等信息直接作为用户标签。
第二获取模块30用于根据各群组标签对应的交易数据获取目标产品的用户分布信息。
其中,用户分布信息为用户对应的交易数据基于各个群组标签的分布情况。本申请的实施例中,第二获取模块30可根据交易数据中各个群组标签中的数量以及交易编号与用户信息的对应关系确定用户分布在各个群组中的数量,即用户分布信息。
判断模块40用于根据用户分布信息计算用户分布的信息熵,判断所述用户分布信息是否符合预设分布。
在本申请的一个实施例中,判断模块40可通过目标产品对应的用户分布的信息熵来判断用户分布信息是否符合预设分布。用户分布的信息熵越大,则表示目标产品的用户越近似随机分布,用户分布的信息熵越小,则表示目标产品的用户存在个别群组聚集的情况。
具体地,在本申请的一个实施例中,判断模块40可包括:计算单元41、第一获取单元42、第二获取单元43和判断单元44。
其中,计算单元41用于根据所述用户分布信息计算用户分布的信息熵。
考虑到现实数据中,同一个用户在不同的时间窗口内可以属于不同的用户群组,交易数据中存在交易粒度的重复数据。因此在本申请的一个实施例中,可采用基于最大化用户群体的二次哈希方法,削弱多标签数据在计算用户分布的信息熵的过程中引入的噪音,从而强化隐性团体的用户聚集度,使用户分布接近真实分布,并且适合多标签这类复杂识别模式。
计算单元41用于执行图3所示的步骤以根据用户分布信息计算用户分布的信息熵。
第一获取单元42用于获取所述目标产品对应的用户分布的基准信息熵。
在现实的电子商务场景下,一般情况下商品的交易过程中买家应该具有近似随机的群组分布,然而在团伙刷单等异常交易场景中买家的分布在个别特征中体现出聚集性。用户分布的信息熵,作为一种衡量用户分布信息混乱程度的指标,能够恰如其分的刻画这种场景。当商品交易过程中买家用户近似随机分布时,用户分布的信息熵具有最大值,而当存在个别的团体聚集时,上述用户分布的信息熵的值将大幅度的减小。
因此,在本申请的实施例中,可将买家用户随机分布时的用户分布的信息熵作为用户分布的基准信息熵,并通过实际交易过程中实际的用户分布的信息熵与该基准信息熵进行比对来判断是否存在个别的团体聚集的情况。如果存在,则可判断出现了异常交易。
那么,首先需要获取目标产品的用户分布的基准信息熵。在本申请的一个实施例中,第一获取单元42可用于:获取目标产品对应的产品交易量,根据预先拟合的预估函数和产品交易量生成目标产品对应的用户分布的基准信息熵。其中,预估函数为表示产品交易量与用户分布的基准信息熵函数关系的曲线。因此,可将目标产品的产品交易量带入预估函数,得到目标产品对应的用户分布的基准信息熵。
第二获取单元43用于获取所述信息熵和所述基准信息熵之间差值。
判断单元44用于如果所述差值大于预设阈值,则判断所述用户分布信息不符合预设分布。
筛选模块50用于如果所述用户分布信息不符合预设分布,则根据各群组标签对应的交易数据的数量筛选出一个或多个群组,并以所述筛选出的群组及其交易数据作为异常交易群组及其异常交易数据。
在当前用户交易数据中异常交易数据和正常交易数据混杂的情况下,影响用户分布信息熵的往往是具有最大规模的群组,其在产品买家用户分布中呈现峰值状态,即用户在某一群组中具有高聚集度的特点。因此,在本申请的一个实施例中,筛选模块50可具体用于筛选出交易数据的数量最大的一个或多个群组,并以所述筛选出的群组及其交易数据作为异常交易群组及其异常交易数据,。即以交易数据的数量最大的群组作为异常交易群组,以异常交易群组的交易数据作为异常交易数据。
其中,可根据上述第三交易列表
由此,可通过实际交易过程中的目标产品的用户分布的信息熵与相应的基准信息熵进行比对来判断是否存在异常交易数据,并进行提取,可解释性强,能够有效识别团伙作弊交易模式(如团伙刷单等)的异常交易,提高异常交易的召回率。
本申请实施例的异常交易数据的获取装置,可根据交易数据中的用户信息生成群组标签,并根据群组标签对用户进行群组划分,并根据各群组对应的用户交易数据获取目标产品的用户分布信息,并在用户分布信息不符合预设分布时,根据各群组标签对应的交易数据的数量筛选出异常交易数据对应。
图8为根据本申请另一个实施例的异常交易数据的获取装置的结构示意图。
如图8所示,根据本申请实施例的异常交易数据的获取装置,包括:第一获取模块10、生成模块20、第二获取模块30、判断模块40和筛选模块50和更新模块60。
更新模块60用于将异常交易数据从交易数据中删除,并更新产品交易量,并根据更新后的产品交易量更新相应的基准信息熵。
从而,可根据删除异常交易数据后的交易量对应的用户分布的信息熵与更新后的交易量对应的基准信息熵进行比对,以判断是否存在异常数据。如果存在,则继续删除,并再次判断。
本申请实施例的异常交易数据的获取装置,通过不断剔除目标产品的用户交易数据中最大规模的具有团伙特征的交易数据(异常交易数据)的贪心算法,不断剔除与输出异常交易数据,商品异常交易数据与正常交易数据的区分更加准确,能够挖掘具有高聚集度的团伙用户以及其对应的异常交易数据。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,"计算机可读介质"可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(ram),只读存储器(rom),可擦除可编辑只读存储器(eprom或闪速存储器),光纤装置,以及便携式光盘只读存储器(cdrom)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管已经示出和描述了本申请的实施例,本领域的普通技术人员可以理解:在不脱离本申请的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本申请的范围由权利要求及其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!