基于智能药箱的药品信息预警系统的制作方法
本发明涉及智能药箱领域,特别是涉及一种基于智能药箱的药品信息预警系统。
背景技术:
随着人们健康意识的逐步提高,实现疾病(尤其是心脏病、高血压、糖尿病等)自我防治手段之一的智能药箱也获得逐步发展。目前智能药箱的研发多数集中在药箱存储格局、药箱温湿度控制等方面,而缺少对智能药箱药品信息预警的研发,尤其缺少对药品库存预警、药品效期预警、用药时间预警的研发。
现有智能药箱存储药品存在一些不合理的问题:智能药箱存储药物短缺时,因无法及时有效地预警导致各种危害身体健康的风险;智能药箱存储药物积压时,因无法及时有效地预警导致资源浪费。
现有智能药箱缺少对药品效期的预警,不仅使人们由于粗心或者遗忘导致误服过期药品带来各种危害身体健康的风险,而且还会造成资源浪费甚至环境污染。
现有智能药箱对用药时间的提醒多数采用蜂鸣器的技术方案,一定程度上起到了预警的效果,但用药者尤其是老年人在关闭蜂鸣器后仍然会忘记服药,导致各种危害身体健康的风险,同时也不利于家人对用药者尤其是老年人服药情况的了解。
技术实现要素:
为解决现有技术问题,本发明采用以下技术方案:
基于智能药箱的药品信息预警系统,包括智能药箱终端数据发送模块、数据采集模块、数据挖掘分析模块、药品知识库模块、业务模块(包括药品库存预警模块、药品效期预警模块、用药时间提醒模块);
智能药箱终端数据发送模块发送药品信息、药箱信息、用户操作信息等到数据采集模块;
数据采集模块,基于智能药箱的地理位置,更加精准有效的实现数据的定向传输、实时传输,同时采集智能药箱或者其他终端发送过来的家庭用户信息和药品库存信息、药品效期信息、用药时间的数据,储存到分布式的数据库,并进行数据备份和数据有效性的过滤;
数据挖掘分析模块,以云计算平台作为支撑,大数据分析为手段。通过云计算平台,云计算平台结合虚拟化结构与云计算技术等来实现大数据分析。对终端传输过来的海量数据过滤后,进行数据挖掘和分析,获得用户行为和药品使用情况的特征值数据、用户的药箱终端存药上下限数据、知识库的药品信息数据;
药品知识库模块,是分类存储的药品种类、生产厂家、药效、注意事项等信息的数据知识库,可根据数据采集模块采集的数据,获取最新的药品信息,并通过各种方式完善新增药品的各项属性。除了为预警分析提供专业数据支持以外,还可以供患者查询,通过药箱终端或者其他终端,比如手机、平板、电脑,方便患者更全面的了解和掌握药品的药效和对应症状、服用方法等,亦可为鉴别药品真伪提供帮助;
药品库存预警模块,是根据药箱使用者和所有药品的历史用药记录进行数据挖掘分析,得到终端药箱设备当前所存储药品的上下限值。当存药量超出上下限范围,实时进行预警,减少患者因为药品短缺导致的各种危害身体健康的风险以及因为药物积压导致的资源浪费;
药品效期预警模块,是对实时同步到分布式数据库的药箱存储药品数据进行挖掘分析,提取不同药品的生产日期和有效期、生产厂家,结合药品知识库、云计算平台计算出差异化的回收期值,在有效期之前,进行药品即将过期的预警和回收,既防止了患者因为粗心或者遗忘导致的过期药品误服的危险,又能合理的回收资源,保护环境;
用药时间提醒模块,可以根据历史用药时间数据分析出合理恰当的时间值,通过各种途径和方式提醒用药者或者其家人,或者在药箱终端自行设置,或者其他更便捷的方式,如手机等,可随时随地查询用药时间,并结合数据采集模块采集的药箱开启信息,确定是否重复提醒。
附图说明
为了更清楚地说明本发明的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单介绍。下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的功能模块结构图;
图2是本发明实施例的流程图;
图3是本发明实施例的技术架构图。
具体实施方式
为了使本发明能够更为明显易懂,下面结合附图对本发明的具体实施方式做详细地说明。
在以下描述中阐述了具体细节以便于充分理解本发明。但是本发明能够以多种不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广。因此本发明不受下面公开的具体实施方式的限制。
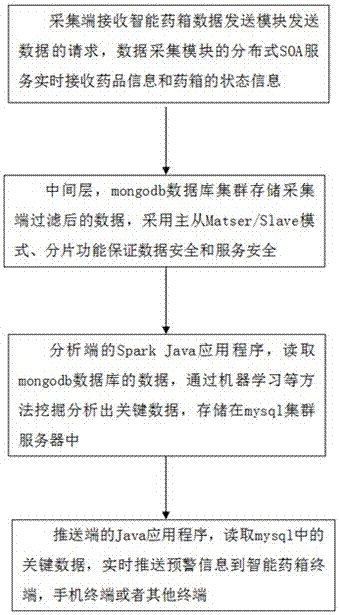
本发明利用云计算平台,包括:采集端、中间层、分析端和推送端,各部分协同高效工作。不同于过去单机、局域网、服务器模式,更能适应全球化、大数据的需要。采集端负责数据采集,中间层进行数据的存储,分析端进行大数据的分析,推送端实现业务需求。
参考图2对于采集端,采用soa架构,针对不同数据的采集和不同的采集频率,定义不同的接口,启动不同的服务,当药箱状态数据采集接口为了满足业务需要或者药箱升级时,必须变更接口,这时只需要依次更新对应的接口服务,并不会影响其他接口服务的使用。通讯协议采用传统的http,敏感数据接口采用https,针对带有敏感数据的接口,本系统还将采用aes加密,保证数据不会被窃取和篡改。在系统成长过程中,最终势必将面临大量、高并发的请求,会发生在不同地区、不同时段,针对这种情况,系统选择nginx反向代理作为负载均衡,在一台高带宽的服务器ecs上部署nginx,在配置文件中配置代理到其他ecs上,上面部署有一个或者多个tomcat服务,提供相同或者不同的接口服务,当更新接口或者ecs宕机时,不会影响整个系统的正常运行。
参考图2对于中间层,采用社区版开源的关系型数据库系统mysql和现在比较成熟的非关系型数据mongodb相结合的方式,根据不同的业务需求,针对mysql和mongodb各自的特点,取长补短,发挥其特点,协作完成对数据的存储和查询。在数据安全方面,采用集群、主从同步、分区分片来保证数据的实时读写和云服务的正常运行。
进一步地,针对mysql和mongodb的使用,根据业务数据的不同,系统将药箱终端的状态记录等这种固定间隔、时间连续的数据存储在mongodb,mongodb作为非关系型数据库,对于大数据量、高并发、弱事务的应用,可以应对自如,mongodb内置的水平扩展机制提供了从百万到十亿级别的数据量处理能力,完全可以满足本系统的数据存储需求。mysql中则存储经过数据挖掘分析之后的关键数据,作为一个成熟的关系型数据库,其拥有管理、检查、优化数据库操作的管理工具,开源免费,社区活跃,更可以根据业务需要,进行二次开发。具体地系统采用innodb事务型的mysql5.6版本,支持acid事务,支持行级锁定,能高效、安全地保证数据的一致性。
进一步地,mysql的搭建采用主从、集群、读写分离的模式,每个主数据库配备多个从数据库,防止断电、意外、不可抗拒等因素导致的问题,导致单个或者多个机器出现问题,可以快速自动的切换到其他数据库服务器,保证系统的正常运行。主从数据库采用mysql自带的master、slaver模式,mongodb也采用自带的matser/slave模式,进行数据的同步,业务模块只在从库读取数据,数据采集服务连接主库,进行实时写入数据。业务模块包括药品库存预警模块、药品效期预警模块、用药时间提醒模块。
进一步地,集群实现方式如下,在mongodb上,系统采用mongodb自带的分片sharding功能,针对数据的分配,mongodb自动维护数据在不同服务器之间的均衡,只需要把分片的机器加入到mongodb的集群当中,mongodb会确保新加入的机器分得均等的数据,总得来说,mongodb拥有以下特点:不可见,自动路由分配数据存储;能保证集群总是可读写;易于扩展。以上特点很适合本系统采集数据的实时存储。安全上,mongodb提供了三种replication方式,matser/matser,matser/slave,replicasets,本系统采用matser/slave,来保证数据的一致性,避免单点故障的发生。在mysql上,系统采用成熟的开源的mysql分布式中间件cobar,cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分,cobar也支持将不同的表放入不同的库,具体地,用户行为和药品使用情况的特征值数据业务表、用户的药箱终端的存药上下限数据业务表、知识库的药品信息数据业务表分别放在不同的数据库实例,每张业务表对应的历史数据和最新数据放在不同的数据库实例。cobar的主备切换有两种触发方式,一种是用户手动触发,一种是cobar的心跳语句检测到异常后自动触发。那么,当心跳检测到主机异常,切换到备机,如果主机恢复了,需要用户手动切回主机工作,cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常,针对这个缺点,业务应用程序会在主机宕机时,开启监听,当主机恢复时,通知cobar切换回主机,系统会在业务应用层面做处理,改善cobar主机恢复不会自动切换回主机的问题。
保证了数据的安全和完整之后,参考图2,分析端是对数据的分析和挖掘,从大量的数据中通过算法搜索隐藏于其中的信息的过程是非常复杂耗时耗力的,需要通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现,具体使用hadoop和spark技术来实现。
进一步地,hadoop的框架最核心的设计就是:hdfs和mapreduce。hdfs为海量的数据提供了存储,mapreduce为海量的数据提供了计算。本系统部分采用mapreduce,使用google的数据中心模式,利用廉价的linuxpc机组成集群,具体是,可以将大多数分布式运算抽象为mapreduce操作。map是把输入input分解成中间的key/value对,reduce把key/value合成最终输出output,这两个函数由程序员提供给系统,下层设施把map和reduce操作分布在集群上运行,并把结果存储在gfs上。这中间,本系统使用spark来替代hadoop的mapreduce,spark是ucberkeleyamplab所开源的类hadoopmapreduce的通用并行框架,spark不同于mapreduce的是job中间输出结果可以保存在内存中,从而不再需要读写hdfs,因此spark能更好地适用于数据挖掘与机器学习等需要迭代的mapreduce的算法。
进一步地,在本系统中,机器学习具体用于对用户行为和所处环境历史信息的学习,即对用户行为和所处环境历史信息按不同的特征进行分类,并按类别汇总统计共有特征的特征值,比对用户行为的特征值与分类的特征值相似度,从而实现对用户的药箱终端的存药上下限的预测,更准确、高效、智能的进行预警。
通过上述技术,本系统能从海量的数据中整理出有价值的关键数据,为系统正确高效地对药品库存、药品效期、用药时间的预警提供有力的数据支撑,更能迅速准确的扩充药品知识库。关键数据,包括但不限于用户行为和药品使用情况的特征值数据、用户的药箱终端的存药上下限数据、知识库的药品信息数据。
本系统以上述数据采集、存储、分析为根本,来支撑药品库存预警、药品效期预警、用药时间提醒业务需求。预警要求很高的实时性和到达率,在这方面,针对不同的终端,系统采用不同的技术和通讯协议。
针对高效、实时的预警业务需求,传统的建立终端和服务器之间的socket技术,面对大量终端,会出现socket数量不足、io吞吐量的瓶颈问题,导致需要增加大量机器,这使得系统的资源和人力成本无休止的增长,为后期维护和管理带来很多麻烦和隐患。所以,参考图2,推送端采用mqtt协议,mqtt是ibm针对物联网推出的一种轻量级协议,建立于tcp/ip层协议之上。其是物联网的重要组成部分,可能会成为物联网的事实标准。其具有qos,能够缓冲消息,并通过重传机制保证终端设备收到消息;其消息格式极其简化,最短是两个字节;其提供订阅和发布模式,可高效推送消息。mqtt有c/c++语言和java包实现,本系统采用java包实现,推送预警信息到智能药箱。移动端手机,则采用第三方成熟的推送服务。对于预警的通知方式,除了智能药箱自带的蜂鸣音或者音乐模块播放音乐之外,本系统可对患者、患者家人或者关系密切的人,进行手机app通知、短信通知、电话通知等,而且可以根据使用者意愿自行设置通知方式。
可以理解的是,对于本领域的普通技术人员来说,可以根据本发明的技术构思做出其它各种相应的改变与变形,而所有这些改变与变形都应属于本发明权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!