一种结合机器学习和自动规划的动作知识提取方法与流程
本发明属于机器学习技术领域,具体涉及一种结合机器学习与自动规划实现数据驱动的动作知识提取技术,主要利用线下预处理和在线搜索技术来解决机器学习中的动作知识提取问题。
背景技术:
机器学习研究的重点是提高预测模型的泛化精度和效率。许多模型如支持向量机、随机森林、深层神经网络已经提出并取得了很大的成功。然而,在许多应用中出现严重缺失的是模型可实施性,即把预测的结果转化为动作知识的能力。例如在客户关系管理、临床预测、广告投放等应用中,用户不仅需要精确的预测,而且也需要将输入转变成理想目标的可执行动作,例如,更高的利润偿还、更低的患病率、更高的广告命中率。
知识提取在管理和市场科学领域主流的理论是采用统计学的方法对用户的行为进行分析并找出特定的规则,比如针对商业利益或投资开发各种评分机制。在机器学习和数据挖掘领域,主要采用模型后续分析技术,比如通过考虑相似度来进行剪枝和综合学习规则。这两类方法的主要缺点在于他们是从建立模型全部数据入手来提取知识,并不是针对某个单独的记录(客户)提取其可用的动作知识。比如,对于一个经常商务出差的客户,提供飞行里程促销更有可能提高其使用信用卡的次数和金额,从而可能更明显地提高给公司带来的利润。其次,这些方法在提取知识的同时都没有考虑更改客户属性所带来的成本。最近几年,一些科学家还提出了一种从单棵决策树或一组决策树搜索动作知识的方法,以及一种利用整数线性优化方法提取动作知识的方法。这两种方法的缺点是在线搜索的效率不够高,因为知识提取问题本质上是np-hard问题,搜索空间非常大,无法高效地在短时间内获得一个最优动作序列。
技术实现要素:
本发明的目的是通过结合人工智能的两个核心领域,即通过结合机器学习与自动规划实现数据驱动的动作知识提取,从而把机器学习模型的预测结果转化为动作知识的能力,提高模型的可实施性,同时该方法可以提高在线提取动作知识的效率,具有广泛的应用范围和极强的实用性。
为了解决上述技术问题,本发明提供一种结合机器学习和自动规划的动作知识提取方法,步骤如下:步骤1,形式化定义动作知识提取问题:给定一个训练数据集,建立一个随机森林模型h,并在随机森林模型h的基础上形式化定义动作知识提取问题;步骤2,线下预处理寻找近似最优目标状态集合:针对随机森林模型h,根据其所有决策树中的分割点离散化所有特征变量为有限整数值域,以离散化后的特征变量建立状态空间图;对该状态空间图上所有可能的输入状态,利用a*搜索找到一个近似最优目标状态,把所有<输入状态,近似最优目标状态>二元组保存为近似最优目标状态集合;步骤3,对任意输入数据向量,通过在线搜索得到一个近似最优动作序列:使用近似最优目标状态集合建立相似度模型,对任意输入数据,在状态相似度模型的基础上把动作知识提取问题表示为sas+格式的自动规划问题,并把该自动规划问题编码为wpmax-sat问题,再使用wpmax-sat求解器快速求解得到一个近似最优动作序列,作为动作知识提取的输出结果。
进一步,步骤1中,随机森林模型h的预测函数如下所示,
其中,x为任意输入数据向量,y为随机森林模型h在输入数据向量为x的情况下输出的预测分类,c为期望分类目标,d为第d棵决策树,d为随机森林中决策树的总棵数,wd为第d棵决策树的权重,od(x)为第d棵决策树在输入x的情况下对应的输出,i(od(x)=c)为指示函数,p(y=c|x)表示在输入数据向量为x的情况下输出的预测分类为c的概率;训练随机森林模型阶段。给定一个训练数据集,建立一个随机森林模型h;
将动作知识提取问题πoap形式化定义为:
πoap={h,xi,c,ο}:
subjecttop(y=c|x*)>z
其中,xi为初始输入数据向量,c为期望分类目标,ο为可执行的动作集合,a为需要寻找的最优动作序列,ai为最优动作序列a中任意一个动作,π(ai)为动作ai的代价,f(a)为所有动作ai的代价总和,z为一个常数阈值,x*为从初始输入数据向量xi执行最优动作序列a中所有动作之后改变成为的向量结果。
进一步,步骤2中,对于任意输入数据向量x的每一个特征变量xi,i=1,..,m,m为特征变量的个数,按如下规则进行离散化处理:
1)如果特征变量xi为类别型,并且类别数目为n,则把特征变量xi分为n个分区;
2)如果特征变量xi为数值型,且在随机森林模型h的所有决策树中分支节点个数为n,则把特征变量xi分为n+1个分区;假设ni表示特征变量xi分区的数量,pi表示特征变量xi的分区索引,把特征变量xi转换成一个离散变量zi,zi的值阈为dom(zi)=ni,所有离散化处理后的有限值域变量集合记为ζ;
所述状态空间图g=(v,e),v是所有的状态节点,e是边集,有限整数值域变量集合ζ上的任意一个输入数据向量z对应所有状态节点v中的一个状态节点s;假设s1和s2分别表示v中任意两个状态节点,则s1和s2之间有一条边当且仅当有一个动作a把状态s1转变为s2,其中a为可执行的动作集合ο中任意一个动作。
所述获得近似最优目标状态集合的过程为:对任意一个输入数据向量xi,假设其离散处理后的数据向量为zi,对应状态空间图g上的节点为si,以节点si为初始状态,采用a*搜索寻找一个满足动作知识提取问题形式化定义的近似最优动作序列,假设该近似最优动作序列对应的最优目标状态为s*,保存二元组<si,s*>;对所有可能输入数据向量xi,按照前述操作,得到所有二元组<si,s*>组成一个近似最优目标状态集合。
进一步,步骤3中,所述相似度模型包括特征变量的相似度和状态的相似度;
给定两个状态s(z1,...zm)和s'(z'1,...z'm),zj为状态s的第j个特征变量,用ξj(s,s')表示第j个特征变量的相似度,则特征变量的相似度定义为:
1)如果第j个特征变量为分类型,当zj=z'j时,ξj(s,s')=1,否则ξj(s,s')=0;
2)如果第j个特征变量为数值型,则
给定两个状态s(z1,...,zm)和s'(z'1,...,z'm),则状态的相似度为:
其中,
进一步,将动作知识提取问题πoap={h,xi,c,ο}编码为sas+格式的自动规划问题πsas={χ,ο,si,sg}的步骤如下:
对数据向量x的所有特征变量离散化处理得到变量集χ;记xi离散化处理后得到的初始状态为si;根据相似度模型寻找初始状态si的k个最相似近邻,并记为s1,...,sk,从二元组<输入状态,近似最优目标状态>集合中找到他们对应的近似最优目标状态
进一步,将sas+格式的自动规划问题πsas={χ,ο,si,sg}编码为wpmax-sat问题ψ={u,c}的过程为:给定一个sas+格式的自动规划问题πsas={χ,ο,si,sg}和时间跨度l,则按如下步骤进行编码:
变量集u定义三种类型变量:
1)转移变量:uδ,t,
2)动作变量:ua,t,
3)目标变量:
其中,δ是变量转移,t是时刻,a是动作,s*为近似最优目标状态集合sg中的任意一个目标状态;
约束集c包含两种类型的约束:软约束和硬约束,
软约束集cs的组成为:
硬约束集ch包括以下九种类型的约束:
1)初始状态约束:
2)目标状态约束:
3)前向传导约束:
4)反向传导约束:
5)转移变量互斥约束:对每一对互斥的转移变量(δ1,δ2),t∈[1,l],
6)动作互斥约束:对每一对互斥的动作(a1,a2),t∈[1,l],
7)动作包含性约束:
8)动作存在性约束:对每一个次要的转换δ∈τ,
本发明与现有技术相比,其显著优点在于:(1)本发明充分利用机器学习和自动规划的特性,使得在线实时提取动作知识更加高效;(2)本发明中基于自动规划方法提出了一种线下预处理策略,可以通过大量时间的线下预处理更准确地找到更接近最优动作序列的目标状态,有效地改进了在有限时间内找到近似最优动作序列的准确率。(3)本发明利用高效的wpmax-sat求解器求解动作知识提取问题,可以大大提高在线搜索的效率。
附图说明
图1是本发明方法动作知识提取流程示意图。
图2是本发明中在线搜索阶段的流程示意图。
具体实施方式
容易理解,依据本发明的技术方案,在不变更本发明的实质精神的情况下,本领域的一般技术人员可以想象出本发明结合机器学习和自动规划的动作知识提取方法的多种实施方式。因此,以下具体实施方式和附图仅是对本发明的技术方案的示例性说明,而不应当视为本发明的全部或者视为对本发明技术方案的限制或限定。
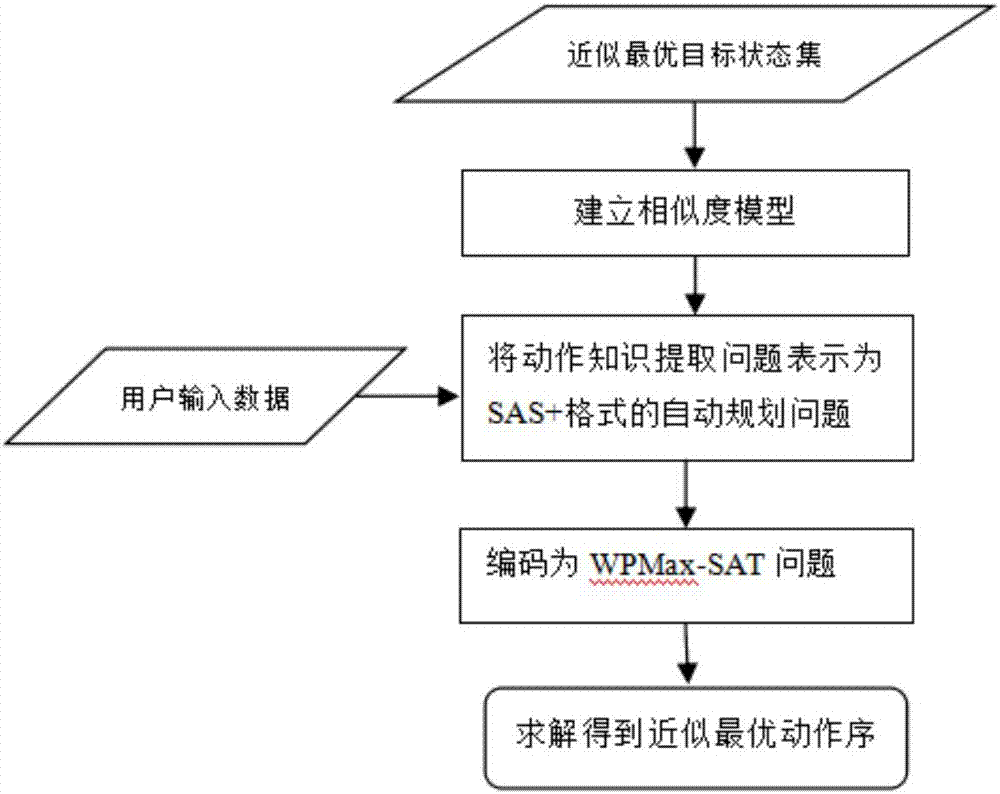
结合图1,本发明方法包括:输入训练数据、形式化定义动作知识提取问题、线下预处理寻找近似最优目标状态集合、用户输入数据、在线搜索求解近似最优动作序列、输出近似最优动作序列。具体地讲包含三个步骤:
步骤1,形式化定义动作知识提取问题:给定一个训练数据集,建立一个随机森林模型h,并在随机森林模型h的基础上形式化定义动作知识提取问题;
步骤2,线下预处理寻找近似最优目标状态集合:针对随机森林模型h,根据其所有决策树中的分割点离散化所有特征变量为有限整数值域,以离散化后的变量建立状态空间图;对该状态空间图上所有可能的输入状态,利用a*搜索找到一个近似最优目标状态,把所有<输入状态,近似最优目标状态>二元组保存为近似最优目标状态集合;
步骤3,对任意输入数据,通过在线搜索得到一个近似最优动作序列:使用线下预处理阶段得到的近似最优目标状态集合建立相似度模型,对任意输入数据,在状态相似度模型的基础上把动作知识提取问题表示为sas+格式的自动规划问题,并把该自动规划问题编码为wpmax-sat问题,再使用wpmax-sat求解器快速求解得到一个近似最优动作序列,作为动作知识提取的输出结果。本步骤如图2所示。
现有技术中,动作知识提取技术主要基于统计学模型、决策树搜索、以及整数线性优化方法,而本发明结合了机器学习和自动规划技术,利用线下预处理和在线实时搜索来高效地自动提取动作知识,提出一种包含线下预处理和在线搜索的框架,为当前动作知识提取领域提供了一种新的方法。以下对本发明每一个步骤作具体说明:
步骤1:形式化定义动作知识提取问题。
1.1训练随机森林模型阶段。给定一个训练数据集,建立一个随机森林模型h。假设训练数据集为{x,y},x为输入数据向量集合,y为输出类别标记集合,建立的随机森林模型h的预测函数如下所示,
其中,x为任意输入数据向量,y为随机森林模型h在输入数据向量为x的情况下输出的预测分类,c为期望分类目标,d为第d棵决策树,d为随机森林中决策树的总棵数,wd为第d棵决策树的权重,od(x)为第d棵决策树在输入x的情况下对应的输出,i(od(x)=c)为指示函数,p(y=c|x)表示在输入数据向量为x的情况下输出的预测分类为c的概率;
1.2在该随机森林模型h的基础上形式化定义动作知识提取问题。本发明将动作知识提取问题形式化定义为:
πoap={h,xi,c,ο}:
subjecttop(y=c|x*)>z
其中,xi为初始输入数据向量,c为期望分类目标,ο为可执行的动作集合,a为需要寻找的最优动作序列,ai为最优动作序列a中任意一个动作,π(ai)为动作ai的代价,z为一个常数阈值,x*为从初始输入数据向量xi执行最优动作序列a中所有动作之后改变成为的向量结果。
步骤2:线下预处理寻找近似最优目标状态集合。
2.1输入数据向量离散化处理。任意输入数据向量x的每一个特征变量xi,i=1,..,m,m为特征变量的个数,按如下规则进行离散化处理:
1)如果特征变量xi为类别型,并且类别数目为n,则把特征变量xi分为n个分区;
2)如果特征变量xi为数值型,且在随机森林模型h的所有决策树中分支节点个数为n,则把特征变量xi分为n+1个分区;假设ni表示特征变量xi分区的数量,pi表示特征变量xi的分区索引,本发明把特征变量xi转换成一个离散变量zi,zi的值阈为dom(zi)=ni,所有离散化处理后的有限值域变量集合记为ζ。经过这样的离散化处理,任意输入数据向量x被转换为一个定义在有限值域变量集合ζ上的输入数据向量z。
2.2建立状态空间图。在离散化变量集合ζ的基础上,本发明定义状态空间图g=(v,e),v是所有的状态节点,e是边集。有限整数值域变量集合ζ上的任意一个输入数据向量z对应v中一个状态节点s。假设s1和s2分别表示v中任意两个状态节点,则s1和s2之间有一条边当且仅当有一个动作a把状态s1转变为s2,其中a为步骤1.2所述的可执行的动作集合ο中任意一个动作。
2.3对任意一个输入数据向量xi,假设其离散处理后的数据向量为zi,对应状态空间图g上的节点为si,以节点si为初始状态,采用a*搜索寻找一个满足步骤1.2中动作知识提取问题形式化定义的近似最优动作序列,假设该近似最优动作序列对应的最优目标状态为s*,保存二元组<si,s*>。
2.4对所有的可能输入数据向量xi,执行步骤2.3,得到的所有二元组<si,s*>即组成一个近似最优目标状态集合。
步骤3:在线搜索求解近似最优解。
3.1建立相似度模型。
3.1.1特征变量的相似度:给定两个状态s(z1,...zm)和s'(z'1,...z'm),zj为状态s的第j个特征变量,用ξj(s,s')表示第j个特征变量的相似度,其定义为:
1)如果第j个特征变量为分类型,当zj=z'j时,ξj(s,s')=1,否则ξj(s,s')=0;
2)如果第j个特征变量为数值型,则
3.1.2状态的相似度:给定两个状态s(z1,...,zm)和s'(z'1,...,z'm),其相似度为:
其中,
3.2将动作知识提取问题πoap={h,xi,c,ο}编码为sas+格式的自动规划问题πsas={χ,ο,si,sg},具体步骤如下:
3.2.1对数据向量x的所有特征变量离散化处理得到变量集χ;
3.2.2记xi离散化处理后得到的初始状态为si;
3.2.3根据相似度模型寻找初始状态si的k个最相似近邻,并记为s1,...,sk,从二元组<输入状态,近似最优目标状态>集合中找到他们对应的近似最优目标状态
3.2.4对每一个动作a∈ο,δ为状态转换,定义一组变量转移a={δ1,...,δ|a|},如果a把z从f转变为g,则变量转移τ=(z,f,g)∈a,把该变量转移记为
3.3将sas+格式的自动规划问题πsas={χ,ο,si,sg}编码为wpmax-sat问题ψ={u,c}。给定一个sas+格式的自动规划问题πsas={χ,ο,si,sg}和时间跨度l,则按如下步骤进行编码:
3.3.1变量集u定义三种类型变量:
1)转移变量:uδ,t,
2)动作变量:ua,t,
3)目标变量:
其中,δ是变量转移,t是时刻,a是动作,s*为近似最优目标状态集合sg中的任意一个目标状态。
3.3.2约束集c包含两种类型的约束,软约束和硬约束。
软约束集cs的组成为:
在硬约束集ch中的每个约束的权重是+∞,因此它必须是正确的。硬约束集ch有以下的九种类型的约束:
1)初始状态约束:
2)目标状态约束:
3)前向传导约束:
4)反向传导约束:
5)转移变量互斥约束:对每一对互斥的转移变量(δ1,δ2),t∈[1,l],
6)动作互斥约束:对每一对互斥的动作(a1,a2),t∈[1,l],
7)动作包含性约束:
8)动作存在性约束:对每一个次要的转换δ∈τ,
- 还没有人留言评论。精彩留言会获得点赞!