用于内核间通信的信道大小调整的制作方法
本发明通常涉及集成电路,例如现场可编程门阵列(FPGA)。更具体地,本发明涉及用于集成电路(例如FPGA)上的内核通信的信道的动态大小调整。
背景技术:
此部分意在向读者介绍可能涉及本发明的各种方面的技术的各种方面,这些方面在下文中被描述和/或主张。相信此论述有助于向读者提供背景信息以促进对本发明的各种方面的更好理解。因此,应理解,应鉴于此来阅读这些陈述,而不是作为对现有技术的认可。
集成电路(IC)采用多种形式。例如,现场可编程门阵列(FPGA)是意在作为相对通用装置的集成电路。FPGA可以包括在制造后被编程(例如,被配置)以提供FPGA被设计以支持的任何所需功能的逻辑。因此,FPGA包括可配置为根据设计者的设计在FPGA上执行多种功能的可编程逻辑或逻辑块。另外,FPGA可以包括输入/输出(I/O)逻辑以及高速通信电路。例如,高速通信电路可以支持各种通信协议,并且可以包括高速收发器信道,FPAG可以通过所述高速收发器信道将串行数据发送到在FPGA外部的电路和/或接收来自在FPGA外部的电路的串行数据。
在IC(例如FPGA)中,通常使用低级编程语言(例如VHDL或Verilog)来配置可编程逻辑。遗憾的是,这些低级编程语言可能提供低水平抽象,并因此可能为可编程逻辑的设计者提供开发障碍。较高级编程语言(例如OpenCL)已变得可用于使可编程逻辑设计能够更简易。较高级程序用于生成对应于低级编程语言的代码。如本文中所使用,内核是指实施具体功能和/或程序的数字电路。内核可以用于将低级编程语言桥接(bridge)成可以通过集成电路执行的可执行指令。在IC上实施的每个内核可以独立于IC上的其它内核执行或与IC上的其它内核并行地(concurrently)执行。因此,OpenCL程序通常针对OpenCL程序中的每个内核要求至少单个硬件实施方式。可以独立地使内核平衡,并且数据可以使用两个内核之间的一个或多个数据流信道(例如先进先出(FIFO)信道)从一个内核流动到另一个内核。
数据流信道的大小可以是变化的以接受从一个内核流动到另一个内核的适当量的数据。传统上,用户指定信道的数据容量以解释受约束的执行模型(例如,单线程执行)。遗憾的是,这种用户指定的容量并未说明实施方式细节,因为用户通常仅使用较高级程序而不是低级编程语言进行工作。
技术实现要素:
在下文中阐述了本文中所公开的某些实施例的概述。应理解,提出这些方面仅仅是为了向读者提供这些特定实施例的简要概述,并且这些方面并非意图限制本发明的范围。实际上,本发明可以涵盖下文中可能并未阐述的多个方面。
本实施例涉及用于通过基于一个或多个因素的自动的内核间信道大小调整而增强机器实施的程序的性能的系统、方法及装置。特别地,本实施例可以基于IC上的当前实施方式、预测(predication)和/或调度不平衡而提供在集成电路(IC,例如FPGA)上的动态信道大小调整。自动大小调整(sizing)可以旨在增加内核执行之间的数据吞吐量。
上述特征的各种改进可以关于本发明的各种方面存在。其它特征同样也可以并入在这些各种方面中。这些改进和附加的特征可以单独地或以任何组合存在。举例来说,下文论述的关于所说明的实施例中的一个或多个的各种特征可以独自或以任何组合并入到本发明的上述方面的任何方面中。此外,上文所提出的简要概述仅意图在不限制所要求的主题的情况下,使读者熟悉本发明的实施例的某些方面和上下文。
附图说明
在阅读以下详细描述并且参考附图之后可以更好地理解本发明的各个方面,在附图中:
图1是根据实施例的利用信道大小调整逻辑来影响机器实施的程序的系统的框图;
图2是根据实施例的可编程逻辑器件的框图,所述可编程逻辑器件可以包含用于实施信道大小调整逻辑的逻辑;
图3是根据实施例图示说明图1的主机和集成电路的元件的框图;
图4是根据实施例图示说明使用多个自动调整大小的信道的内核间通信的框图;
图5是根据实施例图示说明基于预测对信道进行自动大小调整的框图;
图6是根据实施例图示说明基于调度不平衡对信道进行自动大小调整的框图;
图7是根据实施例的用于求解整数线性编程问题以确定自动信道深度的过程;以及
图8是根据实施例图示说明使用整数线性编程(ILP)对信道进行自动大小调整的框图。
具体实施方式
下文将描述一个或多个具体实施例。在努力提供这些实施例的简明描述的过程中,不是实际实施方式的所有特征都在说明书中进行描述。应了解,在任何此类实际实施方式的开发中,如同在任何工程或设计项目中,必须制定许多实施方式特定的决策以实现研发者的特定目标,例如与系统相关和企业相关约束的一致性,这可以从一个实施方式改变到另一实施方式。此外,应了解,此研发工作可能是复杂且耗时的,但仍是从本发明中获益的所属领域的技术人员从事的设计、制作和制造的常规任务。
如下文更详细地论述,本发明的实施例大体上涉及用于增强在集成电路(IC)上实施的机器可读程序的性能的电路。具体地说,可以基于一个或多个因素自动地修改内核间通信信道大小调整。例如,可以基于IC上的当前程序实施方式、预测和/或调度不平衡来作出这些修改。
考虑到上述内容,图1图示说明利用信道大小调整逻辑来影响机器实施程序的系统10的框图。如上文所论述,设计者可能需要在集成电路12(IC,例如现场可编程门阵列(FPGA))上实施功能。设计者可能指定待实施的高级程序(例如OpenCL程序),其可使设计者能够更高效地及更容易地提供编程指令以实施用于IC 12的一组可编程逻辑,而不需要特别了解低级计算机编程语言(例如,Verilog或VHDL)。举例来说,因为OpenCL非常类似于其它高级编程语言(例如C++),相比被要求学习不熟悉的低级编程语言以在IC中实施新功能的设计者,熟悉此类编程语言的可编程逻辑设计者可以具有降低的学习曲线。
所述设计者可以使用设计软件14(诸如AlteraTM的Quartus版本)来实施其高级设计。设计软件14可以使用编译程序16来将高级程序转化为低级程序。此外,编译程序16(或系统10的其它组件)可以包含信道大小调整逻辑17,所述信道大小调整逻辑17自动地对将被实施以用于两个或多个内核之间的内核间通信的信道进行大小调整。
编译程序16可以将表示高级程序的机器可读指令提供到主机18及IC 12。例如,IC 12可以接收描述应被存储在IC中的硬件实施方式的一个或多个内核程序20。此外,可以通过信道大小调整逻辑17提供信道大小调整定义21,所述信道大小调整逻辑17可以自动定义一个或多个内核程序20之间的信道的大小调整。如上文所提及,自动大小调整可以基于各种因素,包括:程序实施方式、预测和/或内核调度不平衡。下文将更详细地论述基于这些因素对信道的大小调整。
主机18可以接收可以通过内核程序20实施的主机程序22。为了实施主机程序22,主机18可以经由通信链路24将指令从主机程序22传送到IC 12,所述通信链路24可以为例如直接存储器存取(DMA)通信或高速外围组件互连(PCIe)通信。在接收内核程序20和信道大小调整定义21后,内核和/或信道实施方式可以在IC 16上被执行并由主机18控制。如下文将更详细描述,主机18可以添加、移除或调换(swap)来自适配的逻辑26的内核程序20以便执行性能可以被增强。
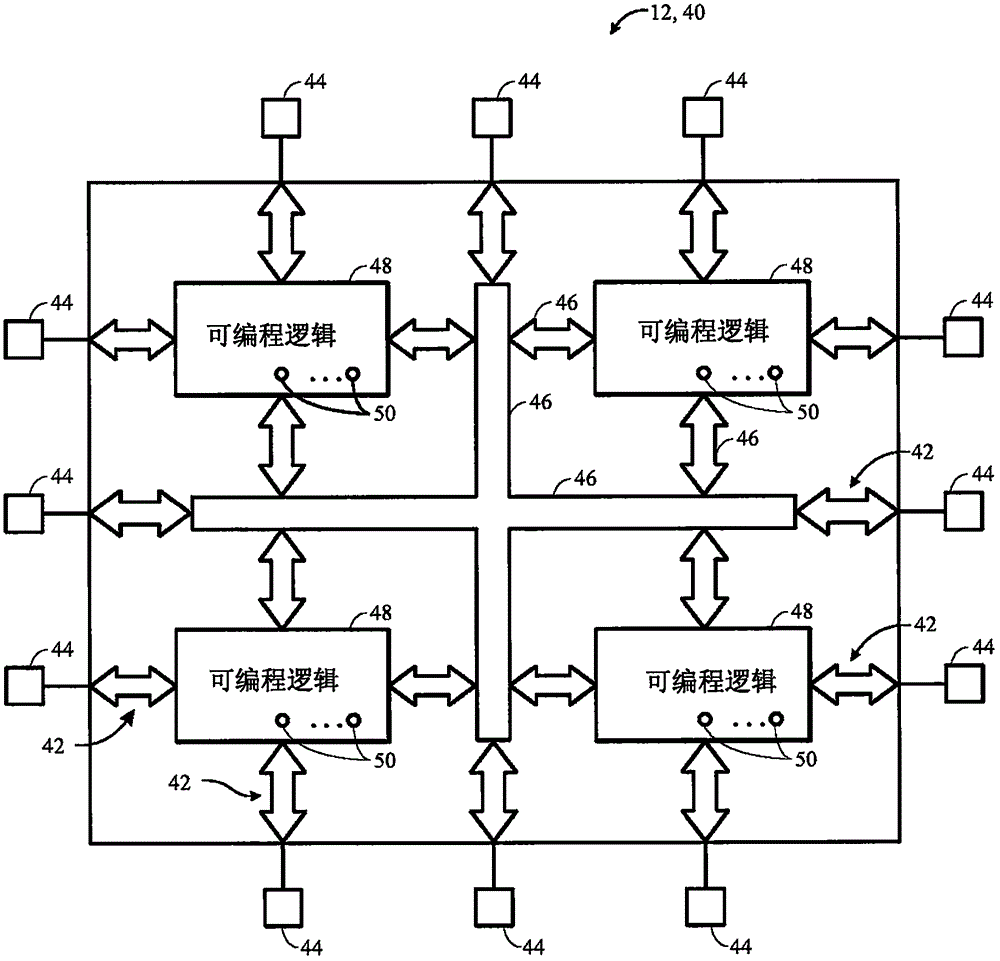
现在转向IC 12的更详细论述,图2图示说明IC器件12,其可以为可编程逻辑器件,例如现场可编程门阵列(FPGA)40。出于本示例的目的,器件40被称作FPGA,但应了解,所述器件可以为任何类型的可编程逻辑器件(例如,专用集成电路和/或专用标准产品)。如图所示,FPGA40可以具有用于经由输入/输出引脚44从器件40驱离信号并接收来自其它装置的信号的输入/输出电路42。互连资源46(例如,全局和局部的垂直及水平导线和总线)可以用于在装置40上路由信号。另外,互连资源46可以包括固定互连件(导线)和可编程的互连件(即,在相应的固定互连件之间的可编程连接)。可编程逻辑48可以包括组合和时序逻辑电路。例如,可编程逻辑48可以包括查找表、寄存器或多路复用器。在各种实施例中,可编程逻辑48可以被配置为执行自定义逻辑功能。与互连资源相关联的可编程互连件可以被视为可编程逻辑48的一部分。如下文更详细论述,FPGA 40可以包括自适应逻辑,其使能FPGA 40的部分重配置,使得内核可以在FPGA 40的运行期间被添加、移除和/或调换。
可编程逻辑器件(例如FPGA 40)可以包括可编程元件50以及可编程逻辑48。例如,如上文所论述,设计者(例如客户)可以对可编程逻辑48进行编程(例如配置)以执行一个或多个期望的功能。例如,一些可编程逻辑器件可以通过使用掩模编程布置来配置其可编程元件50而被编程,所述掩模编程布置在半导体制造期间被执行。其它可编程逻辑器件在半导体制造操作完成之后被配置,例如,通过使用电编程或激光编程对其可编程元件50进行编程。通常,可编程元件50可以基于任何合适的可编程技术,例如,保险丝、反熔丝、电可编程只读存储器技术、随机存取存储器单元、掩模编程元件等等。
大多数可编程逻辑器件以电气方式(electrically)被编程。通过电编程布置,可编程元件50可以由一个或多个存储器单元形成。例如,在编程期间,使用引脚44和输入/输出电路42将配置数据加载到存储器单元50中。在一个实施例中,存储器单元50可以被实施为随机存取存储器(RAM)单元。基于RAM技术的存储器单元50的使用在本文被描述意在仅为一个示例。此外,因为这些RAM单元在编程期间被加载有配置数据,所以它们有时被称为配置RAM单元(CRAM)。这些存储器单元50可以均提供相对应的静态控制输出信号,所述静态控制输出信号控制可编程逻辑48中的相关联逻辑组件的状态。举例来说,在一些实施例中,输出信号可以被施加至可编程逻辑48内的金属氧化物半导体(MOS)晶体管的栅极。
可以使用任何合适的体系结构来组织FPGA 40的电路。作为示例,FPGA40的逻辑可以以一系列的行和列的较大可编程逻辑区域而被组织,所述较大可编程逻辑区域中的每个可以包括多个较小的逻辑区域。FPGA 40的逻辑资源可以通过互连资源46(例如,相关联的垂直及水平导体(conductor))互连。举例来说,在一些实施例中,这些导体可以包括跨越基本上全部FPGA 40的全局导线、跨越器件40的部分的部分线(例如,半分线或四分线)、特定长度(例如,足以互连若干逻辑区域)的交错线、较小的局部线或任何其它合适的互连资源布置。此外,在进一步的实施例中,FPGA 40的逻辑可以以更多级或层被布置,其中多个大区域被互连以形成逻辑的更大部分。更进一步地,器件布置可以使用以不同于行和列的方式被布置的逻辑。
如上文所论述,FPGA 40可以允许设计者创建能够执行并实施定制的功能的定制设计。每个设计可以具有其自己的硬件实施方式以在FPGA 40上被实施。举例来说,在FPGA 40的设计中,每个内核需要单个硬件实施方式。进一步,一个或多个信道可以被实施以用于内核间通信。在一些实施例中,这些信道可以包括可用于两个或多个内核之间的数据流的一个或多个先进先出(FIFO)缓冲器。内核间通信信道可以基于各种因素被自动地调整大小,如下文更详细描述。
现参考图3,提供了说明系统10的框图,其进一步详述图1的主机18和IC 12的元件。如图所示,IC 12可以包括固定组件60和可配置组件62。一些IC(例如的V FPGA)提供部分重配置功能。举例来说,在一些实施例中,可配置组件可以包括存储于IC12(例如图2的FPGA 40)上的若干(N个)部分重配置(PR)块64。PR块64可以证明重配置IC 12的一部分而器件的剩余部分继续工作的能力。PR块64可以包括至芯片上存储器互连件和芯片外互连件两者的端口(分别为端口66和端口68)。PR块64不受限于特定协议;但是,IC 12内的PR块64中的每个可以对共同协议达成共识。例如,PR块64中的每个可以使用存储器映射(Avalon-MM)接口,其可以允许IC 12中的组件之间的简单互连。
PR块64的大小和数目可以通过硬件实施方式和在IC 12上可用的可编程逻辑的量来定义。例如,用于每个内核20和/或内核间通信信道21的硬件实施方式26可以被置于一个或多个PR块64中。在某些实施例中,硬件实施方式26可以被置于不是部分重配置块64的可编程逻辑中。例如,内核20和/或信道定义(例如,信道大小调整21)可以由编译程序16(例如,利用图1的信道大小调整逻辑17)提供。
现转向对固定逻辑60的论述,固定逻辑60可以包括芯片上存储器互连件70、仲裁网络72、本地存储器74、芯片外互连件76、外部存储器和物理层控制器78和/或PCIe总线80。芯片上存储器互连件70可以经由PR块64的芯片上存储器互连端口66连接到PR块64。芯片上存储器互连件70可以促进PR块64与本地存储器74之间经由仲裁网络72的存取。此外,芯片外存储器互连件76可以经由PR块64的芯片外存储器互连端口68连接到PR块64。芯片外互连件76可以促进PR块64与主机通信组件(例如,外部存储器和物理层控制器78以及PCIe总线80)之间的通信。外部存储器和物理层控制器78可以促进IC 12与外部存储器(例如,主机18的存储器82)之间的存取。此外,PCIe总线80可以促进IC 12与外部处理器(例如,主机12的处理器84)之间的通信。如将更显而易见的是,基于以下论述,主机18与IC 12之间的通信在使能IC 12上的自适应逻辑上非常有用。
图4为根据实施例图示说明内核与自动调整大小的信道的实施方式26的示例的框图。图4的实施方式26的示例包括三个内核20A、20B及20C。内核26A的输出经由两个内核间通信信道100A及100B被转发到内核20B。此外,内核20B的输出经由内核间通信信道100C被提供到内核20C。来自内核20C的输出经由内核间通信信道100D作为输入被提供到内核20B。
可以基于一个或多个因素而自动地对信道100A、100B、100C及100D中的每个进行大小调整。多种信道100A至100D实施方式可以被实施。举例来说,可以使用寄存器、使用低延时(latency)组件、使用高延时组件、使用块随机存取存储器(RAM)(例如专用RAM)等在IC上实施信道100A至100D。信道100A至100D的延时可以根据这些信道100A至100D的实施方式的体系结构而变化。信道100A至100D的延时可以影响吞吐量,并且因此所述延时是可用于信道100A至100D的自动大小调整的一个实施方式因素。延时在本文中被定义为写入信道(例如,信道100A至100D)的数据将在信道100A至100D的另一端处被读取所花费的循环次数。换言之,延时是“不满”(not-full)状态传播到信道(例如,信道100A至100D)的写入位置(site)所花费的循环次数。为了保证信道100A至100D的适当大小调整,信道100A至100D的深度可以被设置大小,使得其深度大于信道100A至100D的延时。例如,编译程序(例如,图1的编译程序16)可以确定信道100A至100D实施方式的延时和/或可以基于信道实施方式的归属延时检索信道100A至100D的已知延时。编译程序可以确保信道100A至100D的大小调整大于其对应的延时。这可有助于确保在数据传播到信道100A至100D的另一端的时间之前数据未被请求。在一些实施例中,编译程序可以首先确定期望的信道深度并基于所确定的期望的信道深度来选择信道实施方式(例如,通过选择具有比期望的信道深度低的延时的信道实施方式)。不管实施方式延时确定信道的深度还是期望的信道深度确定信道实施方式,编译程序可以维持其中信道深度大于实施方式的延时的关系。
用于自动大小调整的替代因素可以包括预测和/或调度不平衡。举例来说,信道实施因素(例如信道100A至100D的延时)可以影响信道100A至100D的吞吐量。预测(信道读取和/或写入不是在每个执行循环被执行)可以影响内核间通信的吞吐量。例如,在作出写入满信道100A至100D的尝试时可以发生暂停。暂停的长度是信道100A至100D在将发生写入的位置处变得“不满”所花费的时间(例如,信道100A至100D的延时)。为抵消暂停,额外的深度可以自动地被添加到信道100A至100D以说明信道100A至100D的延时,如将关于图5更详细地论述。
现转向预测示例120,图5是根据实施例图示说明基于预测的信道122A和/或122B的自动大小调整的框图。在示例120中,内核124A和124B经由基于FIFO缓冲器的信道122A及122B通信地被连接。内核122A和122B针对内核124A的多路复用器(MUX)128和内核124B的多路分用器(DEMUX)130使用相同的选择逻辑126。
MUX 128及DEMUX 130示出在两个信道122A及122B上的共享预测逻辑。例如,MUX 128的选择的输出经由信道122A或信道122B被提供至DEMUX 130。由于选择逻辑126可以引起信道122A和/或122B的读取和/或写入不是在每个循环(例如,所述信道被预测)执行,所以暂停(stall)可以发生(例如,当尝试写入至满的信道122A和/或122B时)。举例来说,在当前示例中,信道122A和122B中的每个具有5个单元(element)的容量,如由单元容器126所示。如果选择逻辑引起前五个单元被写入至信道122A,第六个单元被写入信道122B,并且第七个单元被写回至信道122A,那么在第七次写入时将出现暂停。出现暂停是因为第七个单元不能够被写入到装满单元1至5的信道122A,是因为当写入第六个单元时内核124B从信道122B接收数据,由于用于MUX 128和DEMUX 130的选择逻辑126是相同的。
换言之,在尝试写入第七个数据单元之前,由于内核122A的延时,来自信道122A的表明其“未满”的控制信号将不会到达内核124A。因此,当内核124A尝试写入第七个数据单元时,将看到信道122A是满的,从而引起暂停。
为了抵消所述暂停,信道122A和/或122B可以自动地被大小调整(例如经由图1的信道大小调整逻辑17)以包括足够用于所实施的信道容量(例如在此为五个单元)加上信道122A和/或122B的延时的空间。如上文所提及,以写入到信道122A和/或122B的数据将在信道122A和/或122B的另一端处读取所花费的循环次数来定义信道122A和/或122B的延时。换言之,延时是“不满”状态传播到信道的写入位置所花费的时间。因此,在当前示例中,可将额外的单元添加到信道122A,因为在第七次写入尝试时,选择逻辑126选择来自信道122A的数据,用于在DEMUX 130处读取,从而引起一个循环中的空单元容器126。通过向所实施的容量添加延时,可以避免由于预测所导致的潜在暂停。
自动信道大小调整还考虑了内核中的调度不平衡,使得可以实现吞吐量效率。如上文所提及,内核中的每个可以独立地被平衡。实际上,内核的小部分可以单独地被调度以创建有效的运行时间。因为每个内核包括其自己的调度和/或延时并且因为将所有通信间内核一起作为单个实体调度将导致运行时间的显著增加,所以可以对信道进行大小调整以适应基于内核的调度不平衡。
图6是根据实施例图示说明基于调度不平衡对信道进行自动大小调整的示例140的框图。图7是求解整数线性编程问题以定义信道深度的过程。出于清楚起见将一起论述图6和图7。
在图6的示例140中,第一内核142经由两个信道(例如,基于FIFO缓冲器的信道144A及144B)将数据提供到第二内核142B。在内核142A写入到缓冲器144A及144B之间存在延时146。例如,当数据流经内核142A时(如由箭头148所示),数据首先被写入到信道144A(如由箭头150所示)。数据连续流动达延时146时段(如由箭头148所示)且第二片数据被写入到信道144B(如由箭头152所示)。
如可以认识到,在内核142B读取来自信道144A和144B的数据之间也存在对应的延时154。例如,当数据在内核142B中流动时(如由箭头156所示),首先读取来自信道144A的数据(如由箭头150所示)。数据流动在延时154时段内继续(如由箭头156所示)。在延时154时段后,从信道144B发生第二数据读取(如由箭头152所示)。
为了对信道进行大小调整,编译程序可以首先针对信道的每个端点(例如,每个读取位置和写入位置)计算最大延时和最小容量(图7的块172)。所述延时是线程从内核开始到达此端点将会花费的时间量。最小容量是在端点前沿该路径可以是活的(1ive)线程的最小数目。换言之,延时是线程到达特定点所花费的时间量并且容量是可以在管线(pipeline)中的线程的数目。
接下来,变量用于表示内核的任何调度松弛(slack)(图7的块174)。松弛可以表示内核相对于其它内核的延迟启动。当内核启动时,可以存在一些初始暂停,因为内核可能正等待将由前任(predecessor)内核处理的初始数据。然而,在稳态操作中,暂停可以被减到最少和/或移除。
接下来,为每个信道添加约束(图7的块176)。所述约束规定内核在信道的读取侧上的松弛减去内核在写入侧上的松弛应大于或等于开始读取所花费的最大延时减去写入侧上的最小容量。换言之,在最坏情况下,当一个内核能够比另一内核消耗更多线程时,这种约束计算需要保持在信道中的线程的数目。
接着使用信道的宽度计算每个管线的成本函数(图7的块178)。例如,如果一个信道发送32比特的数据并且另一个信道发送512比特的数据,那么创建关于512比特的数据的深度将昂贵得多。
随后可设置信道的深度(图7的块180)。所述深度可以是内核的读取端点与写入端点之间的相对差加上最大延时与最小容量之间的差。
图8是根据实施例图示说明的使用整数线性编程(ILP)对信道进行自动大小调整的框图200。成本函数可以被最小化,从而产生使用IC可编程逻辑的最小区域的实施方式。
在框图200中,存在两个内核k1 202A及k2 202B。信道204A被命名为FIFOA且具有32比特的宽度。信道204B被命名为FIFO B且具有16比特的宽度。点Aw是写入至FIFO A 204A所发生的位置。点Ar是从FIFO A 204A进行读取所发生的位置。点Bw是写入至FIFO B 204B发生的位置,并且点Br是从FIFO B进行读取所发生的位置。格式m(n)可以表示在内核202A和/或202B中的具体点的最大延时和最小容量。举例来说,5(10)可以表示特定点处的最大延时55和最小容量10。因此,在Aw处,最大延时和最小容量两者均为1。在Bw处,最大延时是1并且最小容量是10。在Ar处,最大延时是5并且最小容量是1。在Br处,最大延时和最小容量两者均为5。这些值可以(例如)由编译程序在运行时间期间来确定。
为求解ILP问题,将内核k1 202A的成本确定为-32+(-16)=-48且将内核k2 202B的成本确定为32+16=48。随后最小化成本函数(-48k1+48k2)。添加FIFO A信道204A约束(k2-k1>=5-1>=-4)。另外添加FIFO B信道204B约束(k2-k1>=10-5>=5)。随后,为了使问题可解,创建虚拟节点(例如“源”)并添加额外的约束:k1-源>=1000000及源-k2>=1000000。虽然当前示例使用1000000,但可使用任何大成本系数。成本系数可以是大的,使得其对此方程式的求解的影响是可忽略的。随后,ILP问题被求解以得到k2-k1=5。这个差被用于FIFO A信道204A及FIFO B信道204B的深度计算中。FIFO A信道204A的深度可以被设置成5+5-1=9并且FIFO B信道204B的深度可以被设置成5+5-10=0。
通过实施自动信道大小调整逻辑,内核间信道通信吞吐量可以被增强。举例来说,如果信道的大小调整未考虑实施方式因素、预测和/或调度不平衡,那么到满的内核间通信信道的写入尝试可能出现。这可以引起不必要的数据暂停而减少吞吐量。因此,通过允许编译程序(或其它组件)基于各种实施方式因素、预测和/或调度不平衡而自动地对这些信道进行大小调整,吞吐量效率可以被获得。
尽管在本发明中阐述的实施例可以容易有各种修改和替代形式,但是具体实施例已经在附图中通过示例的方式被示出并且在本文中已经对其进行了详细描述。然而,应理解,本公开不旨被限制到公开的特定形式。本公开将涵盖落入由以上所附权利要求书定义的本公开的精神和范围内的所有的修改、等同和替代。
- 还没有人留言评论。精彩留言会获得点赞!