一种用于时序数据库的数据块存储方法与流程
本发明涉及时序数据存储领域,可用于gps、环境温度、湿度、风向、pm2.5等带时间标签数据的存储。
背景技术:
时序数据库广泛应用于各个领域,例如gps、环境温度、湿度、风向、pm2.5等带时间标签的数据。同时,时序数据库有很多类型,例如ptimedb、蜂鸟数据库、inflluxdb时序数据库等。其中,ptimedb是唯一在相关行业中有商业应用的时序数据库,具有较高的吞吐量和并发效率。但是,这些时序数据库存在着不同的缺点,例如没有明确适应的时序数据类型、并发量不够、吞吐量不够、查询效率不能满足某些应用等。
针对gps类型的时序数据库,要求有很高的插入效率与实时查询效率。例如,100万量车每秒提交gps数据,这样就需要100万每秒的插入效率,而一天就需要存储860亿个gps数据;如果前端有10万个用户就需要10万次每秒的查询效率,一天需要执行86亿次查询。gps数据的查询很多需要区域查询,如果使用上文提到的数据库均很难满足要求。如果使用数据块的存储方法,先将数据在内存中组织成块,等大块内存都用完后将数据写入文件中,能够有效地解决大量数据的插入与查询问题。
技术实现要素:
本发明提供一种用于时序数据库的数据块存储方法,以解决时序数据写入与查询的问题。
具体步骤如下:
s1:如图1,分配一大块内存,按一个记录的大小分为n块,然后将这n块内存按照链表的方式按顺序组织起来,该链表称为空闲链表。
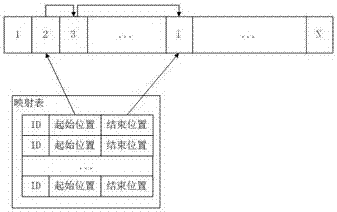
s2:如图2,使用映射表的方式记录id、起始位置和结束位置的关系。
s3:接收数据更新,首先判断在映射表中是否有当前id。没有转到s4,否则转到s7。
s4:判断空闲链表是否为空;不为空转到s5,为空转到s6。
s5:从空闲链表中取出头结点,并将数据写入当前结点。在映射表中增加记录id,起始位置和末尾位置都为该结点位置。转s3继续更新数据,转s10进行数据查询。
s6:如图3,将整块数据写入文件,在索引文件中追加前数据块的起始时间、结束时间、数据块在文件中的位置和数据块大小;再重新按链表的方式按顺序组织n块内存,清空映射表。转s3则继续处理当前接收的数据。
s7:判断空闲链表是否为空,不为空转到s8,为空转到s9。
s8:从空闲链表中取出头结点,并将数据写入当前结点。更新映射表中对应id的结束位置为该结点位置。转s3继续更新数据,转s10进行数据查询。
s9:将整块数据写入文件,在索引文件中追加记录当前数据块的起始时间和结束时间。转s3继续处理当前接收的数据。
s10:接收查询请求,判断查询请求中有没有指定时间。有认为查询历史数据,转到s11;否则查询实时数据,转到s13。
s11:打开索引文件,在索引文件中找到指定时间的数据块信息。
s12:在数据文件中读取指定的数据块到内存中。
s13:初始化结果集r。判断是否有指定条件,若没有指定,则将当前内存中的数据赋值到结果集r中,转到s15;若有指定条件,则转到s14。
s14:根据条件1,查询当前内存中的记录,并将结果记录在r中。条件2及以上条件在r中查找,并将查询到的数据重新写入r中。
s15:将结果集r返回。
附图说明
图1是数据块的内存组织关系。
图2是映射表与数据块组织的关系。
图3是历史数据块的存储方式。
具体实施方式
运动中的车辆包含id、实时gps和实时速度信息,以下结合运动中的车辆信息对本发明作进一步详细说明,但不作为对本发明的限定。
包括步骤如下:
s1:如图1,分配一个100mb的内存,一个记录需要100字节,将这100mb内存分为n个100字节的内存块,然后将这n个内存块按照链表的方式按顺序组织起来,该链表称为空闲链表。
s2:如图2,使用哈希映射表的方式记录id、起始位置和结束位置的关系。
s3:接收数据更新,首先判断在哈希映射表中是否有当前id。没有转到s4,否则转到s7。
s4:判断空闲链表是否为空,不为空转到s5,为空转到s6。
s5:从空闲链表中取出头结点,并将接收的id、gps和速度信息写入当前结点。在哈希映射表中增加记录当前id,起始位置和末尾位置都为该结点的内存地址。转s3继续更新数据,转s10进行数据查询。
s6:如图3,将整块数据写入记录文件,在索引文件中追加前数据块的起始时间、结束时间、数据块在文件中的位置和数据块大小。重新按链表的方式按顺序组织n块内存,清空映射表。转s3继续处理当前接收的数据。
s7:判断空闲链表是否为空,不为空转到s8,为空转到s9。
s8:从空闲链表中取出头结点,并将数据写入当前结点。更新映射表中对于id的结束位置为该结点位置。转s3继续更新数据,转s10进行数据查询。
s9:将整块数据写入文件,在索引文件中追加记录当前数据块的起始时间和结束时间。转s3继续处理当前接收的数据。
s10:接收查询请求,判断查询请求中有没有指定时间。有认为查询历史数据转到s11;否则查询实时数据,转到s13。
s11:打开索引文件,在索引文件中找到指定时间的数据块信息。
s12:在数据文件中读取指定的数据块到内存中。
s13:初始化结果集r。判断是否有指定条件,若没有指定,则将当前内存中的数据赋值到结果集r中,转到s15;若有指定条件,则转到s14。
s14:根据条件1,查询当前内存中的记录,并将结果记录在r中。条件2及以上条件在r中查找,并将查询到的数据重新写入r中。
s15:将结果集r返回。
上述说明示出并描述了本发明的若干优选实施例,但如前所述,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
技术特征:
技术总结
本发明公开了一种用于时序数据库的数据块存储方法,如图2,使用大块连续的内存记录时序数据,然后在大块内存的写入文件中,这样极大地提高了时序数据库的吞吐量。由于更新数据和实时数据查询这些频繁的操作,而操作的是大块连续的内存,其处理效率也较为理想,能够满足大型时序数据的处理要求。在保存时序数据时,先保存索引,再保存实际数据块,如图3。在索引文件中每个数据库的记录都是按时间增加的,所以在查找时可以直接使用二分法的方法查找指定时间数据库,历史数据查找高效。
技术研发人员:吴建凰
受保护的技术使用者:吴建凰
技术研发日:2016.06.24
技术公布日:2018.01.05
- 还没有人留言评论。精彩留言会获得点赞!