一种基于用户搜索内容的多媒体推荐方法及系统与流程
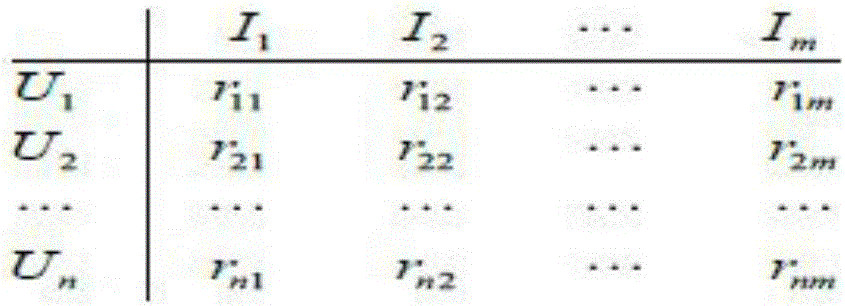
本发明涉及内容推荐领域,尤其涉及一种基于用户搜索内容的多媒体推荐方法及系统。
背景技术:
:个性化推荐系统目前已广泛用于书籍、论文、音乐和电影等商品及内容的推荐上,而且个性化推荐系统的内部结构也发生了巨大变化。随着推荐内容的多元化发展,原始的推荐技术也在与时俱进地快速发展,例如协同过滤、基于内容信息和迁移学习等推荐技术在这样的大环境下应运而生。个性化推荐系统根据推荐内容的不同可分为三种类型:第一类推荐系统应用于电子商务网站上,其向用户推荐符合自身喜好的商品,这类推荐系统称为电子商务个性化推荐系统或电商推荐系统,亚马逊、淘宝和京东等大型电商网站均使用这类推荐系统;第二类推荐系统应用于当今流行的社交网络上,其向用户推荐其相关的社会关系或兴趣圈子中可能会感兴趣的用户、群组和新闻等相关信息,如Facebook、新浪微博和人人网等社交网络门户均使用这类推荐系统;第三类推荐系统应用于垂直分享类门户网站中,其向用户推荐用户可能感兴趣的类目及内容,如Netflix、时光网和豆瓣网等多媒体消费类垂直门户均使用这类推荐系统。协同过滤推荐算法主要分为基于用户(User-based)的协同过滤和基于项目(Item-based)的协同过滤两种,两者的最大区别在于目标邻近集合的选取范围恰好相反。基于用户(User-based)的协同过滤算法是通过计算用户间的相似度以获得目标用户的最邻近用户集,并根据最邻近用户集的评分来预测目标用户对未知项目的评分,然后把预测评分较高的项目作为推荐项目反馈给目标用户;而基于项目的协同过滤算法则是通过计算不同项目间的相似性,然后选择与目标用户喜欢的项目具有较高相似性的项目作为推荐内容反馈给目标用户。传统的协同过滤推荐系统算法虽然在一定程度上完成了推荐功能,但也存在着以下问题:1、基于用户评估矩阵的相似性计算过程中,特征稀疏和冷启动问题比较突出;2、目前绝大部分个性化推荐系统主要是针对用户的显式输入数据如性别、年龄、住址、爱好标签等进行相似度的相关计算,而未考虑用户的隐式输入数据对相似度计算的影响;3、协同过滤算法自身不具备自适应性,用户评价项中的零值不能通过算法自身的调整来实现权值重赋,导致推荐精度的下降甚至无法推荐等问题。因此,现有技术还有待于改进和发展。技术实现要素:鉴于上述现有技术的不足,本发明的目的在于提供一种基于用户搜索内容的多媒体推荐方法及系统,旨在解决现有推荐方法存在冷启动、特征稀疏以及精度不足的问题。本发明的技术方案如下:一种基于用户搜索内容的多媒体推荐方法,其中,包括:步骤A、收集用户的搜索关键字记录和打分记录,并根据搜索关键字记录生成用户查询向量集,以及根据打分记录生成用户评分矩阵;步骤B、建立多媒体分类标签词典,根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵,然后根据所述查询-多媒体分类矩阵对用户评分矩阵的特征项进行赋权,得到改进后的用户评分矩阵;步骤C、遍历用户查询向量集中的每个用户查询向量,计算得到基于用户查询向量的用户相似性;并根据改进后的用户评分矩阵计算得到基于用户评分矩阵的用户相似性;步骤D、根据所述基于用户查询向量的用户相似性以及基于用户评分矩阵的用户相似性计算得到用户总体相似性,并依据用户总体相似性选取与目标用户相似度最大的若干个用户作为目标用户的近邻用户集;步骤E、根据近邻用户集中的用户对目标用户未评价项目的评价,预测目标用户对其未评价项目的评价,并按照评分从高到低排序,挑选排名靠前的若干多媒体内容作为推荐结果推送给目标用户。所述的基于用户搜索内容的多媒体推荐方法,其中,所述步骤B具体包括:B1、定义多媒体类别;B2、建立多媒体分类标签词典;B3、根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵;B4、根据所述查询-多媒体分类矩阵中的分类查询信息计算出用户对不同类别多媒体的偏好程度;B5、根据所述偏好程度对用户评分矩阵的特征项进行赋权得到改进后的用户评分矩阵。所述的基于用户搜索内容的多媒体推荐方法,其中,所述步骤C中,计算得到基于用户查询向量的用户相似性的步骤具体包括:C1、将用户查询向量集中的各用户查询向量中的词语元素表示为8位编码形式;C2、遍历每个用户查询向量的所有词语元素,记录每个词语元素所在分支节点层的节点总数和其所在段落行的同义词项数;C3、根据所述节点总数和同义词项数,计算两个词语元素的义项之间的相似度;C4、根据所述义项的相似度,计算相应词语元素之间的相似度;C5、遍历全部的用户查询向量,记录每个用户查询向量的同义词集合以及该同义词集合中各同义词出现的数目,结合词语元素之间的相似度,计算任意两个用户查询向量之间的相似度,并作为基于用户查询向量的用户相似性Sims(U1,U2)。所述的基于用户搜索内容的多媒体推荐方法,其中,所述步骤C中,基于用户评分矩阵的用户相似性按如下公式计算:SimE(U1,U2)=Σk=1m(r1k-r1‾)*(r2k-r2‾)Σk=1m(r1k-r1‾)2*Σk=1m(r2k-r2‾)2]]>其中,(r11,r12,r13,..,r1m)为用户U1的评分向量,(r21,r22,r23,..,r2m)为用户U2的评分向量,分别表示用户U1、U2对多媒体各项目的平均评分值。所述的基于用户搜索内容的多媒体推荐方法,其中,所述步骤D中,用户总体相似性计算公式如下:Simuser(U1,U2)=ω×SimE(U1,U2)+(1-ω)×Sims(U1,U2),ω是调节系数,且ω<0.5。所述的基于用户搜索内容的多媒体推荐方法,其中,所述步骤E中,目标用户i对项目j的预测评分rij按照以下公式计算:其中,表示目标用户i对多媒体各项目给出的评分期望值,Simi,α表示目标用户i与近邻用户集中的用户α之间的相似度,rαj表示用户α对项目j的评分,表示用户α对多媒体各项目给出的评分期望值。一种基于用户搜索内容的多媒体推荐系统,其中,包括:初始化模块,用于收集用户的搜索关键字记录和打分记录,并根据搜索关键字记录生成用户查询向量集,以及根据打分记录生成用户评分矩阵;矩阵改进模块,用于建立多媒体分类标签词典,根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵,然后根据所述查询-多媒体分类矩阵对用户评分矩阵的特征项进行赋权,得到改进后的用户评分矩阵;相似性计算模块,用于遍历用户查询向量集中的每个用户查询向量,计算得到基于用户查询向量的用户相似性;并根据改进后的用户评分矩阵计算得到基于用户评分矩阵的用户相似性;近邻用户集选取模块,用于根据所述基于用户查询向量的用户相似性以及基于用户评分矩阵的用户相似性计算得到用户总体相似性,并依据用户总体相似性选取与目标用户相似度最大的若干个用户作为目标用户的近邻用户集;推荐模块,用于根据近邻用户集中的用户对目标用户未评价项目的评价,预测目标用户对其未评价项目的评价,并按照评分从高到低排序,挑选排名靠前的若干多媒体内容作为推荐结果推送给目标用户。所述的基于用户搜索内容的多媒体推荐系统,其中,所述矩阵改进模块具体包括:定义单元,用于定义多媒体类别;分类标签词典建立单元,用于建立多媒体分类标签词典;矩阵转换单元,用于根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵;偏好程度计算单元,用于根据所述查询-多媒体分类矩阵中的分类查询信息计算出用户对不同类别多媒体的偏好程度;矩阵改进单元,用于根据所述偏好程度对用户评分矩阵的特征项进行赋权得到改进后的用户评分矩阵。所述的基于用户搜索内容的多媒体推荐系统,其中,所述相似性计算模块具体包括:编码表示单元,用于将用户查询向量集中的各用户查询向量中的词语元素表示为8位编码形式;记录单元,用于遍历每个用户查询向量的所有词语元素,记录每个词语元素所在分支节点层的节点总数和其所在段落行的同义词项数;义项计算单元,用于根据所述节点总数和同义词项数,计算两个词语元素的义项之间的相似度;词语计算单元,用于根据所述义项的相似度,计算相应词语元素之间的相似度;相似性计算单元,用于遍历全部的用户查询向量,记录每个用户查询向量的同义词集合以及该同义词集合中各同义词出现的数目,结合词语元素之间的相似度,计算任意两个用户查询向量之间的相似度,并作为基于用户查询向量的用户相似性Sims(U1,U2)。所述的基于用户搜索内容的多媒体推荐系统,其中,所述相似性计算模块中,基于用户评分矩阵的用户相似性按如下公式计算:SimE(U1,U2)=Σk=1m(r1k-r1‾)*(r2k-r2‾)Σk=1m(r1k-r1‾)2*Σk=1m(r2k-r2‾)2]]>其中,(r11,r12,r13,..,r1m)为用户U1的评分向量,(r21,r22,r23,..,r2m)为用户U2的评分向量,分别表示用户U1、U2对多媒体各项目的平均评分值。有益效果:本发明通过提取并量化用户搜索关键字记录中蕴含的用户对特定多媒体类型的喜好程度信息,引入用户查询向量集,并作为目标用户对多媒体项目的初始评分,从而在解决了传统协同过滤算法的冷启动和特征稀疏的问题。另外本发明将用户查询向量的用户相似性以及基于用户评分矩阵的用户相似性相结合,计算得到用户总体相似性,解决了传统协同过滤算法的推荐精度不足的问题。附图说明图1为本发明一种基于用户搜索内容的多媒体推荐方法较佳实施例的流程图。图2为本发明中一个用户评分矩阵的示例。图3为本发明中一个用户搜索记录的示例。图4为本发明中一个用户查询向量集的示例。图5为本发明中一个电影分类标签词典的节选示例。图6为本发明中一个查询-电影分类矩阵的示例。图7为本发明中一个用户评分矩阵改进前的示例。图8为本发明中一个用户评分矩阵改进后的示例。图9为本发明中编码规则表的示例。图10为本发明一种基于用户搜索内容的多媒体推荐系统较佳实施例的结构框图。具体实施方式本发明提供一种基于用户搜索内容的多媒体推荐方法及系统,为使本发明的目的、技术方案及效果更加清楚、明确,以下对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。请参阅图1,图1为本发明一种基于用户搜索内容的多媒体推荐方法较佳实施例的流程图,如图所示,其包括:步骤S1、收集用户的搜索关键字记录和打分记录,并根据搜索关键字记录生成用户查询向量集,以及根据打分记录生成用户评分矩阵;步骤S2、建立多媒体分类标签词典,根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵,然后根据所述查询-多媒体分类矩阵对用户评分矩阵的特征项进行赋权,得到改进后的用户评分矩阵;步骤S3、遍历用户查询向量集中的每个用户查询向量,计算得到基于用户查询向量的用户相似性;并根据改进后的用户评分矩阵计算得到基于用户评分矩阵的用户相似性;步骤S4、根据所述基于用户查询向量的用户相似性以及基于用户评分矩阵的用户相似性计算得到用户总体相似性,并依据用户总体相似性选取与目标用户相似度最大的若干个用户作为目标用户的近邻用户集;步骤S5、根据近邻用户集中的用户对目标用户未评价项目的评价,预测目标用户对其未评价项目的评价,并按照评分从高到低排序,挑选排名靠前的若干多媒体内容作为推荐结果推送给目标用户。在所述步骤S1中,收集用户的搜索关键字记录和打分记录,其中的打分记录是指用户对多媒体内容的打分,其属于显式输入。本发明中后续实施例均以电影为例进行说明,显然,对于其他例如音乐、图片等多媒体内容也可通过本发明的方式实施。根据用户的打分记录生成用户评分矩阵,一个用户评分矩阵的示例如图2所示。其中,用户集合U={u1,u2,…,uN},电影集合I={I1,I2,…,IM},rij代表用户ui对电影Ij的满意度评分,整个用户评分矩阵表示为一个n*m的矩阵。其中,rij的分数取值限制在特定的整数区间内,例如可以把rij设置为0到5的整数,其中0代表喜爱程度未知,1代表最不喜欢,5代表最喜欢,其他分值的喜爱程度在1至5之间即可。除了收集上述显式输入的信息之外,本发明还收集用户隐式输入的信息,隐式输入信息是指从用户登入系统到完成整个操作过程所留下的痕迹信息,例如搜索关键字记录、ip地址所在地、浏览记录和关注收藏记录等。这类输入信息间接反映了用户对于整个网站信息的关注偏好,同时也间接反映用户的自身信息。隐式输入信息对于用户是透明的。由于隐性输入的评价信息通常呈现非线性,传统协同过滤推荐系统不能直接处理,因此需要额外的跨领域技术对这类间接信息进行数据分析和提取,其过程复杂且时间开销较大,这是目前隐式输入信息普遍不被采用的直接原因。本发明所采用的方式则与传统方式有所不同,本发明是提取用户搜索记录,基于提取到的用户搜索记录来生成用户查询向量集,利用所述用户查询向量集作为参考,解决传统协同过滤算法的冷启动和特征稀疏的问题。具体来说,所述用户搜索记录是指用户在浏览网站或使用互联网电视时在网站或智能电视提供的搜索引擎中键入的关键字集合。图3为一份典型的电影个性化推荐系统的用户搜索记录示例。假设用户集合是U={u1,u2,…,uN},其每个用户对应的用户查询向量Qx={Q1,Q2,…,Qy},,其中对于每一个ux,其对应的用户查询向量Qx的维度是不一样的,某电影推荐系统一段时间内的一个用户查询向量集如图4所示。每个用户搜索向量维度并不相同,甚至有的用户查询向量为空。一方面用户查询记录与电影类目并无直接的数值关系,这对计算查询记录与项目类别之间的相关程度带来了挑战。另一方面不能采用传统协同过滤算法的用户相似性计算方法进行用户喜好相似性的计算。所以本发明在后续步骤中结合基于用户评分矩阵和用户查询向量的用户相似性进行计算,可提高推荐准确性,具体在后文详述。进一步,所述步骤S2具体包括:S21、定义多媒体类别;以电影为例,根据MoviesLens数据集的电影分类规则,把电影分为18种,分别是Action(动作)、Adventure(冒险)、Animation(动画)、Children's(儿童)、Comedy(戏剧)、Crime(犯罪)、Documentary(记录)、Drama(戏剧)、Fantasy(魔幻)、Film-Noir(黑色)、Horror(恐怖)、Musical(音乐)、Mystery(悬疑)、Romance(浪漫)、Sci-Fi(科幻)、Thriller(惊悚)、War(战争)和Western(西方)。S22、建立多媒体分类标签词典;在此步骤中,先爬取网络上的电影搜索标签;电影搜索标签的来源主要是豆瓣网和时光网的电影搜索版块,其中豆瓣网的热门标签每隔一个月更新一次,而时光网的热门标签则会每隔20天更新一次。然后对电影搜索标签进行去重、分类处理;具体可选取近1年在豆瓣网和时光网热门标签栏出现过的标签,剔除其中重复的部分,余下大约有2000条标签记录,然后对这些标签进行去重和分类处理,最终留下18类电影搜索标签约1000个。最后根据《同义词词林扩展版》对电影搜索标签进行同义词扩充,形成最终版本的电影分类标签词典,包含约1400个标签,电影分类标签词典节选如图5所示。其中,《同义词词林扩展版》(后续可简称词林或同义词词林)是哈工大信息检索实验室根据人民日报语料库中关于通用词语的词频统计,收录将近七万条词项。它将所有词语按照树状层次结构组织在一起,分为三大层。其中大类14个,中类97个,小类1400个。每个小类中又按照语义相关性分为多个群落,每个群落中又有若干行词汇。S23、根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵;例如,根据电影分类标签词典统计用户查询向量中出现的电影标签频数,从而将用户查询向量集转换为查询-电影分类矩阵。例如一个用户查询向量是(宗教,犯罪,人性,爱情,法国,恐怖片,梦工厂,吴宇森,冒险),则其查询关键字分属于Action、Fantasy、Horror、Romance和War类型的标签数值(这里只从18种类型标签中节选中其中5个类型)分别是2、1、2、2和3。一个查询-电影分类矩阵的示例如图6所示。S24、根据所述查询-多媒体分类矩阵中的分类查询信息计算出用户对不同类多媒体的偏好程度;例如,根据查询-分类矩阵中用户的分类查询信息就可以计算出用户对18类电影的偏好程度。假设查询-分类矩阵为T={T1,T2,…,Tp},18类电影分类集合是M,则用户ui对电影类型MTj的偏好程度L(ui,MTj)即特征权重值可由以下公式计算得出:其中:rij是用户Ui的用户查询向量Ti中包含电影类型MTj的标签频数,|M|是指电影分类集合中的类别个数;其中L(ui,MTj)的值被限制在【0,5】之间,增量单位为0.5;λ为调节系数,通常的取值为0.5。S25、根据所述偏好程度对用户评分矩阵的特征项进行赋权得到改进后的用户评分矩阵。将前述计算的偏好程度作为原始用户评分矩阵中用户对未评分电影项的打分,即对原来是零值的特征项重新赋权,得到改进后的用户评分矩阵。以图7的用户评分矩阵为例,其中这10个用户评价的电影集合由10部电影组成,分别是《异形》、《蝙蝠侠前传2黑夜骑士》、《无间道》、《警察故事》、《当幸福来敲门》、《无人区》、《罗马假日》、《拯救大兵》、《千与千寻》以及《那些年我们一起追过的女孩》,其原始的用户评分矩阵十分稀疏。结合电影分类标签词典和公式1计算出用户查询向量所反映的用户偏好,将原来的评分项重新赋予特征权重,得到改进后的用户评分矩阵,如图8所示。在所述步骤S3中,计算两种用户相似性,一个是基于用户查询向量的用户相似性;另一个是基于用户评分矩阵的用户相似性。对于基于用户评分矩阵的用户相似性SimE(U1,U2),其计算公式如下:在上述公式2中,(r11,r12,r13,..,r1m)为用户U1的评分向量,(r21,r22,r23,..,r2m)为用户U2的评分向量,分别表示用户U1、U2对多媒体各项目的平均评分值。以图2中的电影为例,表示用户U1对电影I1、I2、I3…Im的平均评分值。对于基于用户查询向量的用户相似性计算方法,具体包括:S31、将用户查询向量集中的各用户查询向量中的词语元素表示为8位编码形式;根据《同义词词林扩展版》,将用户查询向量中的元素全部表示为8位编码形式,而未在《同义词词林扩展版》中出现的元素则将其从所属向量中移除。《同义词词林扩展版》中每个群落行的词汇均采用8位编码表示。编码规则表如图9所示,大类表示为一位大写字母,中类表示为一位小写字母,小类是两位十进制数,小类中的群落表示为一位大写字母,段落中的一行表示为两位十进制数。至于第八位则采用三种不同的符号表示段落行中词语的相关度,“=”表示行中词汇语义相等或同义;“#”代表行中词汇是同类,即相关词汇;“@”表示行中词汇既没有相关词又没有同义词,是孤立词。例如“Ee29C01”编码表示的就是“轻浮浮漂浮轻飘轻狂张狂轻举妄动心浮虚浮”这一行段落词汇行。由于同义词词林中词语的组织方式是层次树状结构,所以两个词语元素的相似度可以用两个词语节点的距离来表示,而词语节点的距离可以用词语的8位编码来描述。通过判断8位词语编码来判断两个词语是否在同一层分支中,从第一层开始依次从词语编码中判断两个词语的所属层次关系,例如“Ga01A04=”和“Ga01A05=”两个编码就同属于词林的第五个分支S32、遍历每个用户查询向量的所有词语元素,记录每个词语元素所在分支节点层的节点总数n和其所在段落行的同义词项数m;S33、根据所述节点总数n和同义词项数m,计算两个词语元素的义项之间的相似度;在同义词词林中,由于一个词语元素往往会存在多个意思,所以一个词语元素可能会存在多个编码项,即义项。显然,通过义项的相似性可以得到词语的相似性。假设两个义项分别是w1和w2,其相似度是Simsense(w1,w2),基于同义词词林的义项相似性计算公式如下:(1)如果两个义项不在同一棵树上,则Simsense(w1,w2)=f(2)如果两个义项同在第一层分支,则Simsense(w1,w2)=a×cosπn1180×1n1]]>(3)如果两个义项同在第二层分支,则Simsense(w1,w2)=1×b×cosπ(n1+n2)180×1n2]]>(4)如果两个义项同在第三层分支,则Simsense(w1,w2)=1×1×c×cosπ(n1+n2+n3)180×1n3]]>(5)如果两个义项同在第四层分支,则Simsense(w1,w2)=1×1×1×d×cosπ(n1+n2+n3+n4)180×1n4]]>(6)如果两个义项同在第五层分支,则Simsense(w1,w2)=1×1×1×1×e×cosπ(n1+n2+n3+n4+n5)180×1n5×1m×0.5]]>上述公式中,a,b,c,d,e,f分别是相似性调节系数,经验取值如下:a=0.5,b=0.75,c=0.82,d=0.90,e=0.96,f=0.05。n1~n5是各分支层的节点总数,m是词语元素所在段落行的同义词项数;分别用于计算同一树节点的节点密度,用于计算同一段落行的义项密度。S34、根据所述义项的相似度,计算相应词语元素之间的相似度;两个词语元素的相似性是其各自义项间相似度的数学平均。假设两个词语元素分别为W1和W2,W1的义项集合表示为W2的义项集合表示为和和分别表示相应集合的项目数,则基于同义词词林的词语元素相似性计算公式如下:Simword(W1,W2)=Σi∈{n∈NW1},j∈{n∈NW2}Simsense(wi,wj)|NW1|×|NW2|]]>S35、遍历全部的用户查询向量,记录每个用户查询向量的同义词集合以及该同义词集合中各同义词出现的数目,结合词语元素之间的相似度,计算任意两个用户查询向量之间的相似度,并作为基于用户查询向量的用户相似性Sims(U1,U2)。具体来说,遍历全部用户查询向量,记录每个用户查询向量的同义词集合以及该集合中各同义词出现的数目计算任意两个用户查询向量之间的相似度当两个用户查询向量之间存在同义词时,用户查询向量之间的相似度与两个向量中同时存在的同义词数量呈正比;当两个用户查询向量之间不存在同义词时,用户查询向量之间的相似度与两个向量中各自存在的同义词数量呈反比。两个用户查询向量和其维度分别为n和m,相似度的计算公式如下:(1)当存在相同的同义词时:Simsearch(U1→,U2→)=Σi∈{n∈U1→},j∈{n∈U2→}Simword(Wi,Wj)n×m×ΣWk∈{W|W∈Syn(U1→,U2→)}nWk|Syn(U1→,U2→)|+α]]>(2)当不存在相同的同义词时:Simsearch(U1→,U2→)=Σi∈{n∈U1→},j∈{n∈U2→}Simword(Wi,Wj)n×m×|Syn(U1→)|×|Syn(U2→)|+β(ΣWk∈{W|W∈Syn(U1→)}nWk)×(ΠWl∈{W|W∈Sym(U1→)}nWl)]]>是指共同存在的同义词集合;和分别指中数量大于1的同义词集合;是指该同义词集合包含的词语元素数量;是指该同义词集合中各个词语元素出现的次数;∝,β是相应的调节参数,通常取值均为0.5。在步骤S4中,基于用户评分矩阵计算得到的用户相似性为SimE(U1,U2),基于用户查询向量计算得到的用户相似性为SimS(U1,U2),则用户总体相似性Simuser(U1,U2)计算公式如下:Simuser(U1,U2)=ω×SimE(U1,U2)+(1-ω)×SimS(U1,U2)ω是调节系数,通常取小于0.5的数值,即,ω<0.5,这里取ω=0.35。然后依据用户总体相似性Simuser(U1,U2)选取与目标用户相似度最大的若干个用户作为目标用户的近邻用户集;在步骤S5中,得到目标用户的近邻用户集之后,就可以根据近邻用户集中的用户对目标用户未评价项目的评价,预测目标用户对其未评价项目的评价打分,按照评分分值从高到低排序,挑选出前若干个电影作为推荐结果推送给用户。例如,目标用户i的近邻用户集为Un={u1,u2,…,uk},目标用户i对项目j的预测评分按照以下公式计算:其中,表示目标用户i对多媒体各项目(如所有电影)给出的评分期望值,Simi,α表示目标用户i与近邻用户集中的用户α之间的相似度,rαj表示用户α对项目j(即电影j)的评分,表示用户α对多媒体各项目给出的评分期望值。基于上述方法,本发明还提供一种基于用户搜索内容的多媒体推荐系统较佳实施例,如图10所示,其包括:初始化模块100,用于收集用户的搜索关键字记录和打分记录,并根据搜索关键字记录生成用户查询向量集,以及根据打分记录生成用户评分矩阵;矩阵改进模块200,用于建立多媒体分类标签词典,根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵,然后根据所述查询-多媒体分类矩阵对用户评分矩阵的特征项进行赋权,得到改进后的用户评分矩阵;相似性计算模块300,用于遍历用户查询向量集中的每个用户查询向量,计算得到基于用户查询向量的用户相似性;并根据改进后的用户评分矩阵计算得到基于用户评分矩阵的用户相似性;近邻用户集选取模块400,用于根据所述基于用户查询向量的用户相似性以及基于用户评分矩阵的用户相似性计算得到用户总体相似性,并依据用户总体相似性选取与目标用户相似度最大的若干个用户作为目标用户的近邻用户集;推荐模块500,用于根据近邻用户集中的用户对目标用户未评价项目的评价,预测目标用户对其未评价项目的评价,并按照评分从高到低排序,挑选排名靠前的若干多媒体内容作为推荐结果推送给目标用户。进一步,所述矩阵改进模块200具体包括:定义单元,用于定义多媒体类别;分类标签词典建立单元,用于建立多媒体分类标签词典;矩阵转换单元,用于根据多媒体分类标签词典将用户查询向量集转换为查询-多媒体分类矩阵;偏好程度计算单元,用于根据所述查询-多媒体分类矩阵中的分类查询信息计算出用户对不同类别多媒体的偏好程度;矩阵改进单元,用于根据所述偏好程度对用户评分矩阵的特征项进行赋权得到改进后的用户评分矩阵。进一步,所述相似性计算模块300具体包括:编码表示单元,用于将用户查询向量集中的各用户查询向量中的词语元素表示为8位编码形式;记录单元,用于遍历每个用户查询向量的所有词语元素,记录每个词语元素所在分支节点层的节点总数和其所在段落行的同义词项数;义项计算单元,用于根据所述节点总数和同义词项数,计算两个词语元素的义项之间的相似度;词语计算单元,用于根据所述义项的相似度,计算相应词语元素之间的相似度;相似性计算单元,用于遍历全部的用户查询向量,记录每个用户查询向量的同义词集合以及该同义词集合中各同义词出现的数目,结合词语元素之间的相似度,计算任意两个用户查询向量之间的相似度,并作为基于用户查询向量的用户相似性SimS(U1,U2)。进一步,所述相似性计算模块300中,基于用户评分矩阵的用户相似性按如下公式计算:SimE(U1,U2)=Σk=1m(r1k-r1‾)*(r2k-r2‾)Σk=1m(r1k-r1‾)2*Σk=1m(r2k-r2‾)2]]>其中,(r11,r12,r13,..,r1m)为用户U1的评分向量,(r21,r22,r23,..,r2m)为用户U2的评分向量,分别表示用户U1、U2对多媒体各项目的平均评分值。关于上述模块单元的技术细节在前面的方法中已有详述,故不再赘述。综上所述,本发明通过提取并量化用户搜索关键字记录中蕴含的用户对特定多媒体类型的喜好程度信息,引入用户查询向量集,并作为目标用户对多媒体项目的初始评分,从而在解决了传统协同过滤算法的冷启动和特征稀疏的问题。另外本发明将用户查询向量的用户相似性以及基于用户评分矩阵的用户相似性相结合,计算得到用户总体相似性,解决了传统协同过滤算法的推荐精度不足的问题。应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1