一种实时工业过程大数据压缩存储系统及方法与流程
本发明涉及大数据分析
技术领域:
,尤其涉及一种实时工业过程大数据压缩存储系统及方法。
背景技术:
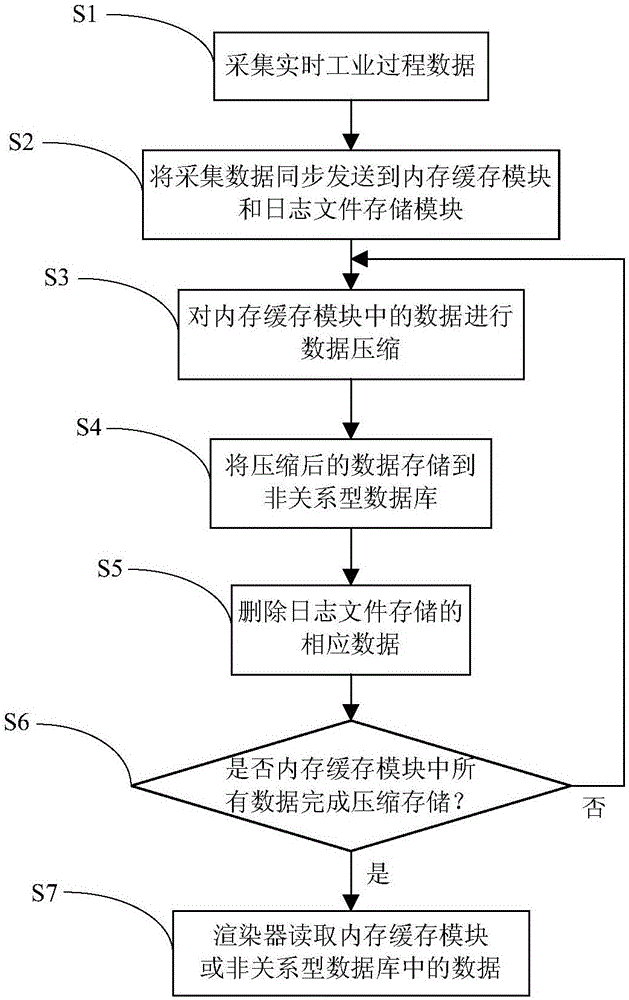
::随着计算机技术的不断发展,大数据应运而生,从而在全球范围掀起一股数字改革狂潮。数据已然成为了一种宝贵资源,而对这种资源的有效存储及利用,可以使得企业向智能生产和智慧决策转型升级。目前,工业过程实时大数据存储一般采用实时数据库及关系型数据库,而对工业企业来说,数据规模在以飞快的速度增长,在保证数据本身特性不丢失、保证存储的数据可以满足大数据分析的前提下,如何最大化的存储数据以及如何控制因为数据存储产生的高额成本对企业来说是一个巨大挑战,已然成为了企业发展的绊脚石。显然,只有采用低廉的数据存储方式,及在数据量一定,保证数据本身质量不受影响的前提下,对数据进行最大化的压缩,才能解决流程工业大数据存储的问题。随着现代工业生产规模的不断扩大,生产设备由就地分散的局部自动控制逐渐向综合自动化体系发展,而一般工业控制系统地域跨越性较大,相当一部分设备工作在户外,一些作业点分散,环境恶劣,因此需要对各种设备的运行状态、生产指标等参数做到实时监控。实时工业数据主要包括各种生产指标数据、工况数据以及状态信息数据。目前,在大数据压缩存储系统方面的专利主要有CN1853198A,该专利涉及压缩视频图像、音频数据,使用诸如小波变换或DTC的变换编码数据,通过最高有效位和/或位值对变换系数分组,以及一个组接一个组的传送它们,没有涉及到工业过程实时大数据的压缩存储,随着工业企业越来越重视其数据价值,企业正在逐步构建工业大数据采集、存储、分析系统,现有专利在工业过程实时大数据的压缩存储方面难以满足需求。技术实现要素::针对现有技术的缺陷,本发明提供一种实时工业过程大数据压缩存储系统及方法,一方面,本发明提供一种实时工业过程大数据压缩存储系统,包括数据采集模块、日志文件存储模块、内存缓存模块、数据压缩模块、非关系型数据库和渲染器;数据采集模块,用于采集实时工业过程数据,包括电子测量仪、PLC和采集客户端;电子测量仪,用于采集每个工业生产现场的生产数据,并发送到PLC;PLC用于逻辑控制和生产数据的采集;采集客户端用于将生产数据发送到内存缓存模块;日志文件存储模块,用于将采集客户端发送到内存缓存模块的数据写入磁盘,进行数据的持久化,以防止内存缓存模块失效而导致数据丢失;当内存缓存模块因失效而导致数据丢失的时候,日志文件存储模块会向内存缓存模块发送因内存缓存模块失效而丢失的数据,以确保生产数据不在内存缓存模块丢失;当内存缓存模块数据经过数据压缩模块压缩存储后,日志文件存储模块中对应的数据将会被删除,以节省数据存储空间;内存缓存模块,用于存储采集客户端发送的实时工业过程数据,一方面供渲染器直接读取内存缓存模块中的数据,满足实时性查询、计算需求,另一方面,为数据压缩模块提供内存数据进行压缩;数据压缩模块,用于对内存缓存模块中的实时工业过程数据按设定数据块大小进行压缩,包括块设定模块和压缩模块;设定模块用于设定所有采集数据项被用来进行一次数据压缩所采集的次数,即数据块的大小;压缩模块用于利用数据压缩方法对采集的工业过程数据进行压缩处理;非关系型数据库,是面向列存储的数据库,用于存储经数据压缩模块压缩后的大规模实时工业过程数据;渲染器,用于从内存缓存模块或非关系型数据库中读取数据,然后进行在线数据查询、计算、分析或可视化。进一步地,电子测量仪采集的数据为浮点型生产数据,PLC采集的数据为布尔类型生产数据。进一步地,压缩模块中的数据压缩方法为:结合工业过程数据时间采集标签,使用T,V二元组进行压缩表示,针对工业采集中数据的波动,设置数据波动范围,进行压缩。另一方面本发明还提供一种实时工业过程大数据压缩存储方法,该方法利用上述的一种实时工业过程大数据压缩存储系统实现,包括如下步骤:步骤1、利用数据采集模块采集实时工业过程数据,采集过程如下:步骤1.1、设定电子测量仪采集每个工业生产现场生产数据的周期;步骤1.2、电子测量仪和PLC采集每个工业生产现场的生产数据;步骤1.3、采集客户端读取电子测量仪和PLC采集的生产数据;步骤2、采集客户端将步骤1.3读取的数据同步发送到内存缓存模块和日志文件存储模块,具体发送与存储方法如下:步骤2.1、定义内存缓存模块中的数据标识项;步骤2.1.1、对工业生产过程的工序进行编号;步骤2.1.2、对采集的生产数据按采集数据项进行编号;步骤2.1.3、利用步骤2.1.1和步骤2.1.2产生的编号,生成内存缓存的数据标识项,数据标识项由两部分组成,前一部分是步骤2.1.1中的工序编号,后一部分是步骤2.1.2中的采集数据项编号;步骤2.2、采集客户端将步骤1.3读取的数据同步发送到内存缓存模块和日志文件存储模块进行存储;步骤2.2.1、确定采集数据项在内存缓存模块中的存储位置;步骤2.2.2、将步骤1.3读取的数据按采集数据项对应存储到步骤2.2.1确定的存储位置,形成键值对数据;步骤2.2.3、将步骤1.3读取的数据发送到日志文件存储模块中存储;步骤2.3、判断对内存缓存模块中存储数据的处理方式,若要进行压缩,则转到步骤3;若直接对数据进行在线查询、计算或可视化,则转到步骤7;步骤3、对内存缓存模块中的数据进行数据压缩处理,压缩过程如下:步骤3.1、设定压缩数据块的大小;步骤3.2、判断内存缓存模块中是否有因内存缓存模块失效而丢失的数据,若有,则执行步骤3.3;若没有,则直接执行步骤3.4;步骤3.3、日志文件存储模块向内存缓存模块发送因内存缓存模块失效而丢失的数据,然后执行步骤3.4;步骤3.4、从内存缓存模块中读取所设定数据块大小的数据;步骤3.5、对读取的数据块进行编号,形成数据组<编号,数据块内容>;步骤3.6、将待压缩数据块中的采样数据项的采样时刻与该数据块中采样数据项初始采样时刻的偏差作为时间偏移量,即该时间偏移量为采样周期的整数倍,对读取的数据块中的采样数据项按采集数据项的编号依次进行压缩,具体步骤为:步骤3.6.1、对该数据块中的待压缩的采集数据项的数据进行压缩,判断该采集数据项的数据类型,若是浮点型生产数据,则对浮点型生产数据进行压缩处理,若是布尔型生产数据,则对布尔型生产数据进行压缩处理;步骤3.6.2、判断是否该数据块的所有数据采集项完成压缩,若是,则执行步骤4;若否,则采集数据项编号后移一位,对该数据块的下一个采集数据项的数据进行压缩,执行步骤3.6.1;步骤4、将步骤3.6压缩后的数据存储到非关系型数据库中,存储方法如下:步骤4.1、在非关系型数据库中建立数据存储表;步骤4.2、设置所述数据存储表的行关键字;步骤4.2.1、根据工业过程,以生产工序作为行关键字;步骤4.2.2、对行关键字进行编码,按照工艺流程先后顺序,使得工序的关键字编码按照字典顺序排列,以保证相连工序的数据存储在相邻位置;步骤4.3、设置所述数据存储表的列族;步骤4.4、设置每个所述列族下的列名;步骤4.5、将步骤3.6压缩后的数据按照生产工序分类,存储到对应的表单元中;步骤4.6、判断压缩后的数据是否成功存储到非关系型数据库中,若成功存储,则执行步骤5;若没有成功存储,则返回步骤4.5,重新进行数据存储;步骤5、将日志文件存储模块中对应的已成功存储到非关系型数据库中的数据删除;步骤6、判断是否内存缓存模块中的所有数据都完成压缩与存储处理,若是,则执行步骤7;若否,则返回执行步骤3.4,从内存缓存模块中读取新的数据块,进行新数据块的压缩与存储;步骤7、渲染器读取内存缓存模块或非关系型数据库中的数据,进行在线数据查询、数据计算、数据分析或可视化的处理。进一步地,对浮点型生产数据进行压缩处理的方法如下:步骤3.6.1.1、设定该浮点型生产数据的数值波动范围;步骤3.6.1.2、根据数据块中的该浮点型采集数据项第一个采样时刻,即+0采样时刻的数值,判断该采集数据项第m个采样时刻的数值是否超出所设定的波动范围,若是,则执行步骤3.6.1.3;若否,则执行步骤3.6.1.4;步骤3.6.1.3、记录对应采样时刻的时间偏移量tm和该采样时刻的前一个采样时刻的数值vm-1,写入该浮点型采集数据项对应的数据库T,V二元组形式的压缩数据对{T[],V[]}中,为{T[+0,tm],V[vm-1]},执行步骤3.6.1.4;步骤3.6.1.4、判断m是否等于n,n表示该采集数据项的所有采样时刻的个数,若不等于,则将m加1,返回步骤3.6.1.2;若等于,则判断压缩数据对{T[],V[]}中是否为空,若为空,则将最后一个采样时刻的时间偏移量tn和对应的数值vn写入压缩数据对{T[],V[]}中,为{T[+0,tn],V[vn]},再执行步骤3.6.2,若不为空,则执行步骤3.6.2。进一步地,对布尔型生产数据进行压缩处理的方法如下:计算数据块中该布尔型采集数据项两种状态0和1的个数,提取出所有数据状态个数少的采样时刻的时间偏移量和该状态数据,写入该布尔型采集数据项对应的数据库T,V二元组形式的压缩数据对{T[],V[]}中,再执行步骤3.6.2。由上述技术方案可知,本发明的有益效果在于:本发明提供的一种实时工业过程大数据压缩存储系统及方法,能有效解决实时工业过程大数据的存储问题,对实时工业过程大数据最大化压缩,并采用非关系型数据库进行存储,既有效地解决对实时工业过程数据的存储,又能为企业节省存储实时工业过程大数据产生的巨额成本,可以使企业实现经济利益最大化;非关系型数据针对某一列或者某几列的查询有非常大的IO优势,可以快速响应数据的在线查询、计算等。附图说明:图1为本发明实施例提供的系统结构框图;图2为本发明实施例提供的方法总流程图;图3为图2中步骤S2的方法流程图;图4为图2中步骤S3的方法流程图;图5为图4中步骤S3.6.1的方法流程图;图6为图2中步骤S4的方法流程图。图中:1、数据采集模块;2、数据压缩模块。具体实施方式:下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。本实施例对选矿工业进行实时监控,共采集14个生产数据,包括运行状态数据、工作环境数据、物料信息数据。选用的大数据框架为Hadoop集群,版本为2.6.0,包括1个主节点Master,19个从节点Slave1、Slave2、…、Slave19,选用的节点为Ubuntu13.04操作系统,8G内存。在20个服务器中均搭建Zookeeper+Kafka集群,为实时工业过程大数据分析处理提供需要的环境,Zookeeper用来做资源管理,Kafka用来传送数据,并创建一个Topic主题,用于存放实时生产数据,开启20台Kafka集群服务器,Kafka的版本号为2.9.1-0.8.2.2,当一台服务器出现故障时,可以换做另一台服务器提供服务,防止因服务器出现故障而影响数据传输;Zookeeper的版本为3.4.8,包括1个leader和19个follower,为分布式应用提供一致性服务,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。本实施例对选矿工业进行实时监控的工业过程大数据进行压缩存储的系统,如图1所示,一种实时工业过程大数据压缩存储系统,包括数据采集模块1、日志文件存储模块、内存缓存模块、数据压缩模块2、非关系型数据库和渲染器。数据采集模块1:用于采集实时工业过程数据,包括电子测量仪、PLC和采集客户端。电子测量仪,用于采集每个工业生产现场的生产数据,并发送到PLC,本实施例中,采用ME96NSR的多功能电子测量仪,采集的数据为浮点型生产数据;PLC用于逻辑控制和生产数据的采集,本实施例中,采用型号为FOXBOROBK3493MANUAL系列的PLC,采集的数据为布尔类型生产数据;采集客户端用于将生产数据发送到内存缓存模块,本实施例中,采用OPCClient作为采集客户端,数据采集模块1采用高性能分布式数据采集群的形式进行工业现场的数据采集。日志文件存储模块,用于将采集客户端发送到内存缓存模块的数据写入磁盘,进行数据的持久化,以防止内存缓存模块失效而导致数据丢失。当内存缓存模块因失效而导致数据丢失的时候,日志文件存储模块会向内存缓存模块发送因内存缓存模块失效而丢失的数据,以确保生产数据不在内存缓存模块丢失。当内存缓存模块数据经过数据压缩模块2压缩存储后,日志文件存储模块中对应的数据将会被删除,以节省数据存储空间。内存缓存模块,用于存储采集客户端发送的实时工业过程数据,一方面供渲染器直接读取内存缓存模块中的数据,满足实时性查询、计算需求,另一方面,为数据压缩模块2提供内存数据,供其对进行数据压缩。本实施例中,内存缓存的工作方式为分布式缓存技术,采用redis,实现实时工业过程大数据的缓存处理。数据压缩模块2,用于对内存缓存模块中的实时工业过程数据按设定数据块大小进行压缩,包括块设定模块和压缩模块;设定模块用于设定所有采集数据项被用来进行一次数据压缩所采集的次数,即数据块的大小;压缩模块用于利用数据压缩方法对采集的工业过程数据进行压缩处理,结合工业过程数据时间采集标签,使用T,V二元组进行压缩表示,针对工业采集中数据的波动,设置数据波动范围,进行压缩。非关系型数据库,是面向列存储的数据库,用于存储经数据压缩模块2压缩后的大规模实时工业过程数据,本实施例中,非关系型数据库采用HBase,版本为1.2.0。渲染器,用于从内存缓存模块或非关系型数据库中读取数据,然后进行在线数据查询、计算、分析或可视化。采用上述的系统对工业过程实时大数据进行压缩存储的方法,如图2所述,包括如下步骤。S1、利用数据采集模块1采集实时工业过程数据,采集过程如下:S1.1、设定电子测量仪采集每个工业生产现场生产数据的周期为1s;S1.2、电子测量仪和PLC采集工业生产现场的生产数据,其中,电子测量仪采集浮点型数据,PLC采集布尔型数据;S1.3、采集客户端OPCClient读取电子测量仪和PLC采集的生产数据。S2、采集客户端将步骤S1.3读取的数据同步发送到内存缓存模块和日志文件存储模块,如图3所示,具体发送与存储方法如下:S2.1、定义内存缓存模块中的数据标识项;S2.1.1、对工业生产过程的工序进行编号,如表1所示;表1生产工序编号表生产工序名称生产工序编号原矿筛分A竖炉焙烧B弱磁磨矿及选别C强磁磨矿及选别D精矿浓缩E精矿过滤FS2.1.2、对采集的生产数据按采集数据项进行编号,本实施例的14个采集数据项如表2所示;表2采集数据项编号表S2.1.3、利用步骤S2.1.1和步骤S2.1.2产生的编号,生成内存缓存的数据标识项,所述数据标识项由两部分组成,前一部分是步骤S2.1.1中的工序编号,后一部分是步骤S2.1.2中的采集数据项编号,本实施例中的数据标识项如表3所示;表3数据标识项编号表数据标识项采集数据项名称数据标识项采集数据项名称AID0001选矿综精品位(TFe)DID0008强磁入磨品位AID0002选矿综精水分DID0009高梯度尾矿品位BID00031-2旋溢粒度超出(-200目)EID0010选矿综精烧损IgBID00042-2旋溢粒度超出(-200目)EID0011焙烧矿品位CID0005三磁精品位FID0012选3#CID0006浮选给矿SiO2FID0013块1#CID0007弱磁浮精SiO2FID0014粉2#S2.2、采集客户端将步骤S1.3读取的数据同步发送到内存缓存模块和日志文件存储模块进行存储;S2.2.1、确定采集数据项在内存缓存模块中的存储位置;S2.2.2、将步骤S1.3读取的数据按采集数据项对应存储到步骤S2.2.1确定的存储位置,形成键值对数据,具体如表4所示;表4键值对数据表<AID0001,采集数据项数值><DID0008,采集数据项数值><AID0002,采集数据项数值><DID0009,采集数据项数值><BID0003,采集数据项数值><BID0010,采集数据项数值><BID0004,采集数据项数值><BID0011,采集数据项数值><CID0005,采集数据项数值><FID0012,采集数据项数值><CID0006,采集数据项数值><FID0013,采集数据项数值><CID0007,采集数据项数值><FID0014,采集数据项数值>S2.3、判断对内存缓存模块中存储数据的处理方式,若要进行压缩,则转到步骤S3;若直接对数据进行在线查询、计算或可视化,则转到步骤S7。S3、对内存缓存模块中的数据进行数据压缩处理,压缩过程如图4所示,具体方法如下:S3.1、设定压缩数据块的大小,本实施例中,设定30次采集的实时工业过程数据量作为数据块的大小,每个数据块包含表2中的14个采集数据项;S3.2、判断内存缓存模块中是否有因内存缓存模块失效而丢失的数据,若有,则执行步骤S3.3;若没有,则直接执行步骤S3.4;S3.3、日志文件存储模块向内存缓存模块发送因内存缓存模块失效而丢失的数据,然后执行步骤3.4;S3.4、从内存缓存模块中读取所设定数据块大小的数据;S3.5、对读取的数据块进行编号,形成数据组<编号,数据块内容>,如;<B1,数据块>;S3.6、将待压缩数据块中的采样数据项的采样时刻与该数据块中采样数据项初始采样时刻的偏差作为时间偏移量,对读取的数据块中的采集数据项按采集数据项的编号依次进行压缩,如图5所示,具体方法为:S3.6.1、对该数据块中的待压缩的采集数据项的数据进行压缩,判断该采集数据项的数据类型,若该采集数据项是浮点型生产数据,则执行步骤S3.6.1.1至步骤S3.6.1.4,对浮点型生产数据进行压缩处理;若该采集数据项是布尔型生产数据,则执行步骤S3.6.1.5,对布尔型生产数据进行压缩处理;本实施例中,第一个数据块的14个采集数据项、每个采集数据项的30个数值分别如表5所示。表5第一个数据块压缩后的数值表表5续表一表5续表二表5续表三本实施例中,第一个数据块的第一个采集数据项AID0001为浮点型生产数据,则执行步骤S3.6.1.1至步骤S3.6.1.4。S3.6.1.1、设定该浮点型生产数据的数值波动范围为±3%,即所判断的数值在基础数值的97%到103%之间,为没有超出波动范围;S3.6.1.2、根据数据块中的该浮点型采集数据项第一个采样时刻的数值,即+0时刻的数值,判断该采集数据项第m(m>1)个采样时刻的数值相对于+0采样时刻的数值是否超出所设定的波动范围,若是,则执行步骤S3.6.1.3;若否,则执行步骤S3.6.1.4;本实施例中,采集数据项AID0001的第一个采样时刻的数值为8.29,m=2时,第二个采样时刻即+1采样时刻的数值为8.14,8.29×97%<8.14<8.29×103%,相对于+0采样时刻的数值8.29没有超出所设定的波动范围±3%,则执行步骤S3.6.1.4;S3.6.1.3、记录对应采样时刻的时间偏移量tm和该采样时刻的前一个采样时刻的采集数据项的数值vm-1,写入该浮点型采集数据项对应的数据库T,V二元组形式的压缩数据对{T[],V[]}中,为{T[+0,tm],V[vm-1]},执行步骤S3.6.1.4;S3.6.1.4、判断m是否等于n,n表示该数据块中该采集数据项的所有采样时刻的个数,即步骤S3.1中设定数据块大小时,数据块中该采集数据项的采集次数30,若不等于,则将m加1,返回步骤S3.6.1.2;若等于,则判断压缩数据对{T[],V[]}中是否为空,若为空,则将最后一个采样时刻的时间偏移量tn和对应的数值vn写入压缩数据对{T[],V[]}中,为{T[+0,tn],V[vn]},再执行步骤S3.6.2,若不为空,则执行步骤S3.6.2;m加1后,m=3,进行第三个采样时刻数值的判断,采集数据项AID0001的第三个采样时刻即+2采样时刻的数值为8.19,8.29×97%<8.19<8.29×103%,相对于+0采样时刻的数值8.29也没有超出所设定的波动范围,则继续执行步骤S3.6.1.4,到最后一个采样时刻+29为止,m=n,n=30,第一个采集数据项AID0001所有采样时刻的数值均未超出设定的波动范围,即对应的压缩数据对{T[],V[]}中为空,则将最后一个采样时刻的时间偏移量+29和对应的数值8.28写入压缩数据对{T[],V[]}中,压缩结果为:{T[+0,+29],V[8.28]},表示第一个采集数据项AID0001的第一个采样时刻+0至第三十个采样时刻+29之间的数据(包括+0采样时刻和+29采样时刻)全部按照8.28进行存储,渲染器在读取非关系型数据库时,该采集数据项的数据为8.28,第一个采集数据项AID0001压缩完成后再转到步骤S3.6.2,进行第二个采集数据项的压缩处理;S3.6.1.5、计算数据块中该布尔型采集数据项两种状态0和1的个数,提取出所有数据状态个数少的采样时刻的时间偏移量和该状态数据,写入该布尔型采集数据项对应的数据库T,V二元组形式的压缩数据对{T[],V[]}中,再执行步骤S3.6.2;S3.6.2、判断是否该数据块的所有数据采集项完成压缩,若是,则执行步骤4;若否,则采集数据项编号后移一位,对该数据块的下一个采集数据项的数据进行压缩,执行步骤3.6.1。本实施例中,第一个采集数据项AID0001完成压缩处理后,执行步骤S3.6.2,采集数据项编号后移一位,对第二个采集数据项AID0002的压缩处理,重新执行步骤S3.6.1,判断采集数据项AID0002为浮点型生产数据,则执行步骤S3.6.1.1至步骤S3.6.1.4。采集数据项AID0002第一个采样时刻的数值为0.34,判断该数据项下一个采样时刻即第二个采样时刻的数值0.32,超出所设定的波动范围,执行步骤S3.6.1.3,记录此时的时间偏移量+1和前一个采样时刻的数值0.34,写入压缩数据对{T[+0,+1],V[0.34]}中,表示第一个到第二个采样时刻之间的数值均按照0.34存储,继续比较该数据项下一个采样时刻即第三采样时刻的数值0.31,超出所设定的波动范围,执行步骤S3.6.1.3,记录此时的时间偏移量+2和前一个采样时刻的数值0.32,写入压缩数据对{T[+0,+1,+2],V[0.34,0.32]}中,依次继续比较该数据项下一个采样时刻的数值,直到第七个采样时刻的数值0.32,相对于第一个采样时刻的数值0.34,均超出所设定的波动范围,记录之间所有的时间偏移量及其对应的前一个采样时刻的数值,写入压缩数据对{T[+0,+1,+2,+3,+4,+5,+6],V[0.34,0.32,0.31,0.32,0.32,0.32]}按此过程,直至比较完该数据块中该数据项所有采样时刻的数据,压缩后的结果为:{T[+0,+1,+2,+3,+4,+5,+6,+8,+9,+10,+11,+13,+14,+19,+20,+21,+22,+23,+27,+28,+29],V[0.34,0.32,0.31,0.32,0.32,0.32,0.35,0.31,0.31,0.30,0.33,0.32,0.33,0.32,0.31,0.31,0.31,0.33,0.31,0.31]}。第二个采集数据项AID0002完成压缩处理后,执行步骤S3.6.2,采集数据项编号后移一位,对第三个数据项BID0003的数据进行压缩,重新执行步骤S3.6.1,判断该数据项为布尔型数据,执行步骤S3.6.1.5。计算数据块中该布尔型生产数据两种状态的个数,将TRUE状态标记为1,FAUSE标记为0,则0状态的个数为23,1状态的个数为8,1状态个数少,提取出所有该状态的采样时刻的时间偏移量和该状态数据1,写入压缩数据对{T[],V[]}中,压缩结果为:{T[+3,+7,+8,+11,+16,+19,+20,+26],V[1]};重复执行以上步骤,直至第一个数据块压缩完毕,第一个数据块压缩完成后的T,V二元组压缩数据对如表6所示,与表5相比,数据量明显减小。表6第一个数据块压缩后的结果S4、将步骤S3.6压缩后的数据存储到非关系型数据库中,如图6所示,存储方法如下:S4.1、在非关系型数据库中建立数据存储表;S4.2、设置所述数据存储表的行关键字;S4.2.1、根据工业过程,以生产工序作为行关键字;S4.2.2、对行关键字进行编码,按照工艺流程先后顺序,使得工序的关键字编码按照字典顺序排列,以保证相连工序的数据存储在相邻位置;S4.3、设置所述数据存储表的列族,包括:原矿筛分列族、竖炉焙烧列族、弱磁磨矿及选别列族、强磁磨矿及选别列族、精矿浓缩列族,精矿过滤列族;S4.4、设置每个所述列族下的列名,如表7所示;表7表7续表S4.5、将步骤S3.6压缩后的数据按照生产工序分类,存储到数据存储表对应的表单元中;S4.6、判断压缩后的数据是否成功存储到非关系型数据库中,若成功存储,则执行步骤S5;若没有成功存储,则返回步骤S4.5,重新进行数据存储。第一数据块压缩存储后如表8所示。表8表8续表S5、将日志文件存储模块中对应的已成功存储到非关系型数据库中的数据删除。S6、判断是否内存缓存模块中的所有数据都完成压缩与存储处理,若是,则执行步骤S7;若否,则返回执行步骤S3.4,从内存缓存模块中读取新的数据快,进行新数据块的压缩与存储。第一个数据块完成压缩与存储处理后,继续从内存缓存模块中按设定的30次采集的实时工业过程数据的数据块大小读取第二个数据块,按照第一个数据块相同的方法进行压缩,压缩后均按照生产工序分类,存储到数据存储表对应的表单元中,依次完成内存缓存模块中的所有数据的压缩与存储。所有数据块完成压缩与存储后,非关系数据库中存储的结果如表9所示,其中B1、B2、……表示数据块编号。表9表9续表S7、渲染器读取内存缓存模块或非关系型数据库中的数据,进行在线数据查询、数据计算、数据分析或可视化的处理。渲染器读取非关系型数据库时为压缩后的数据,读取内存缓存模块中的数据时为实时的工业过程数据。本发明提供的一种实时工业过程大数据压缩存储系统及方法,能有效解决实时工业过程大数据的存储问题,对实时工业过程大数据最大化压缩,并采用非关系型数据库进行存储,既有效地解决对实时工业过程数据的存储,又能为企业节省存储实时工业过程大数据产生的巨额成本,可以使企业实现经济利益最大化;非关系型数据针对某一列或者某几列的查询有非常大的IO优势,可以快速响应数据的在线查询、计算等。最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1